PDFOCR识别重命名工具1.3 使用教程
工具简介
PDFOCR识别重命名工具1.3是一款专业针对PDF文档的智能重命名工具,通过OCR技术自动识别PDF文件中的文字内容,并提取关键信息作为新文件名。目前采用业界领先PP-OCRv5算法。
软件特点
(1)多线程处理文件,高效率,不限制文件数量
(2)支持多个区域识别,可以通过模板选择多个区域进行识别,理论支持无限多个区域进行识别
(3)离线识别,采用离线进行识别,识别性能依据自己电脑性能决定无需担心自己资料泄漏和使用次数限制,也无需联网或者申请各种api进行识别。
(4)支持先试用,符合要求再正常使用该工具,觉得不行可以不用,试用不满意也无需付费。
系统要求
- Windows操作系统,且>=windows10
- 建议配置:8GB以上内存,硬盘可用容量>=1GB
界面功能说明
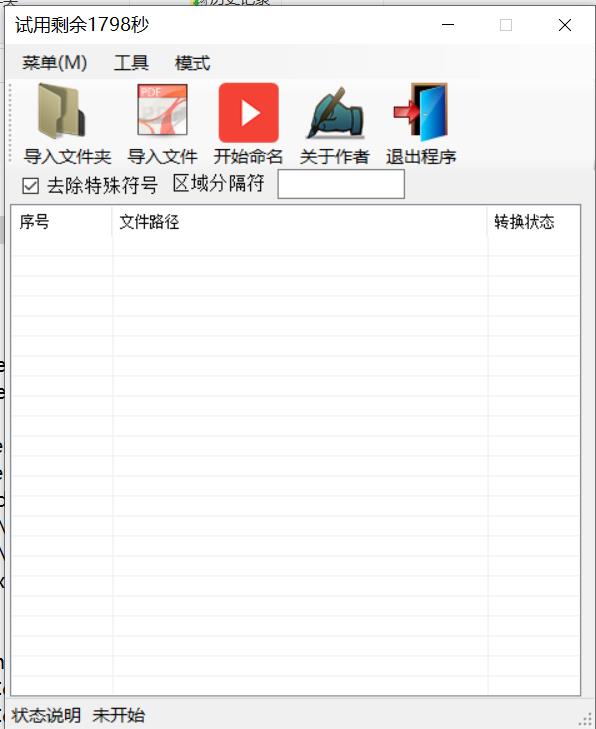
- 顶部菜单栏:包含"菜单(M)"、"工具"、"模式"三个主菜单
- 功能按钮区 :
- 导入文件夹
- 导入文件
- 开始命名
- 关于作者
- 退出程序
- 选项设置区 :
- ☑ 去除特殊符号(默认勾选)
- 区域分隔符(可自定义设置)
- 文件列表区 :
- 序号:文件处理顺序
- 文件路径:原始文件位置
- 转换状态:显示处理进度
- 状态栏 :
- 显示"未开始"、"处理中"、"已完成"等状态
- 试用剩余时间提示
详细使用步骤
第一步:导入PDF文件
方法1:单个文件导入
- 点击"导入文件"按钮
- 在文件选择窗口中选择目标PDF文件
- 点击"打开"完成导入
方法2:批量文件夹导入
- 点击"导入文件夹"按钮
- 选择包含PDF文件的文件夹
- 工具会自动扫描文件夹内所有PDF文档
第二步:设置重命名选项
-
去除特殊符号(推荐):
- 默认已勾选
- 自动过滤文件名中的非法字符(如/😗?"<>|等)
-
区域分隔符设置(可选):
- 可自定义不同识别区域间的分隔符
- 如设置为"_",则"区域1_区域2"形式命名
第三步:开始OCR识别与重命名
- 确认文件列表中的PDF文件无误
- 点击"开始命名"按钮启动处理
- 工具将执行以下操作:
- 对PDF每页进行OCR文字识别
- 提取关键文字信息(如标题、首段文字等)
- 根据设置生成规范化的新文件名
- 执行文件重命名操作
第四步:查看处理结果
-
在文件列表区查看"转换状态"列:
- "等待处理":尚未开始的文件
- "处理中":正在识别的文件
- "已完成":成功重命名的文件
- "失败":识别失败的文件(可尝试重新处理)
-
状态栏显示:
- 实时更新处理进度
- 剩余试用时间倒计时
高级使用技巧
-
优先处理重要文件:通过调整文件列表中文件的顺序(数字序号)控制处理优先级
-
批量中断/继续:在"工具"菜单中可以暂停或继续批量处理
-
日志查看:在"菜单"中可查看详细处理日志,了解每个文件的重命名详情
注意事项
-
试用时间限制:注意试用倒计时,处理大量文件时建议分批操作
-
文件类型:仅支持PDF格式文档,其他格式需先转换
-
识别效果:
- 扫描版PDF识别效果取决于扫描质量
- 文字版PDF识别准确率接近100%
- 复杂排版可能需要手动调整
-
特殊符号处理:建议保持"去除特殊符号"选项开启,避免文件名非法字符
常见问题解答
Q:为什么有些PDF识别效果不好?
A:可能是扫描分辨率低、文字倾斜或背景复杂导致,建议使用300dpi以上的清晰扫描件。
Q:试用时间结束后如何处理剩余文件?
A:试用版不支持更名只能查看识别结果,确认能识别到才是重命名关键。
Q:重命名后的文件名不满意怎么办?
A:可在"工具"菜单中选择"撤销重命名"恢复原文件名(需在处理后立即操作)。
本教程基于PDFOCR识别重命名工具1.3版本编写,适用于常规PDF文档的批量重命名需求。建议首次使用时先处理少量文件测试效果,再开展大批量操作。