数学分析、解析几何、高等代数、实变函数、常微分方程、近世代数、微分几何、复变函数、点集拓扑、概率论、数理统计、数理逻辑、偏微分方程、泛函分析、动力系统、数学物理方程、数论导引、群与代数表示、微分流形、代数拓扑、代数几何、金融数学、多元统计分析、应用随机过程、组合数学、应用随机分析、运筹学、图论、控制论、密码学、交换代数与同调代数、数值分析、计算方法、微分方程数值解、数学建模、算法与计算复杂性、常用数学软件、基础数学、计算数学、概率论与数理统计、应用数学、运筹学与控制论。
一、测度论
1.1 测度论:核心概念与体系框架
测度论是现代数学分析的基础分支,研究一般集合上"大小"或"体积"的抽象度量方法,为积分、概率、泛函分析等提供严格工具。其核心思想是将经典几何度量(长度、面积、体积)推广至任意集合,并建立可加性、极限兼容的数学框架。
1.2、测度论的基本定义与背景
测度论起源于勒贝格积分的推广需求,旨在克服黎曼积分对函数连续性的依赖。核心对象包括:
- 测度 :函数
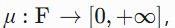 ,为可测集赋予非负广义实数,表示"大小"。
,为可测集赋予非负广义实数,表示"大小"。 - 可测空间 :二元组
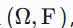 ,其中
,其中 F是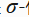 -代数(对补集、可列并封闭的集类)。
-代数(对补集、可列并封闭的集类)。 - 测度空间 :三元组
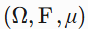 ,满足非负性、空集零测、可数可加性。
,满足非负性、空集零测、可数可加性。
应用领域:概率论(概率测度)、实分析(勒贝格积分)、几何(Hausdorff测度)、物理学(量子力学中的谱测度)等。
1.3、核心体系方法与设计思路
测度论的设计围绕"可测性"与"可加性"展开,通过渐进扩张解决复杂集合的度量问题。
1. 可测空间与测度的构造方法
-
从简单集到复杂集:
- 开集与闭集 :以开集测度为基石(如直线开集
G = \cup (a_n, b_n)的测度m(G) = \sum (b_n - a_n)。 - 一般集合 :通过内外测度定义可测性:
- 外测度:
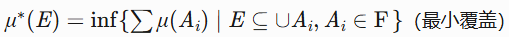
- 内测度:
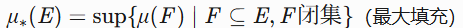
当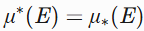 时,
时,E可测。
- 外测度:
- 开集与闭集 :以开集测度为基石(如直线开集
-
sigma-代数的必要性 :为规避不可测集(如Vitali集),仅对
\sigma-代数中的集合定义测度,确保极限运算封闭。
2. 测度的扩张方法
-
Carathéodory扩张定理 :
半环(如区间)上的有限可加预测度
\mu_0,可唯一扩张为\sigma(\mu_0)上的测度\mu。
设计思路 :通过外测度过渡,定义\mu^*(E) = \inf \{\sum \mu_0(A_i) \mid E \subseteq \cup A_i\},再筛选满足 Carathéodory 条件(\mu^*(A) = \mu^*(A \cap E) + \mu^*(A \cap E^c))的集合。 -
完备化 :
若
\mu(A)=0且B \subseteq A,则需扩张\sigma-代数使B可测且\mu(B)=0(如勒贝格测度的完备化)。
3. 抽象积分框架
-
简单函数逼近 :
可测函数
f可表为简单函数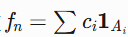 的极限,积分定义为:
的极限,积分定义为:
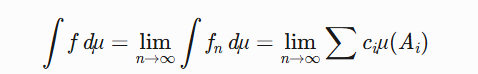
需验证极限与序列选择无关(单调收敛定理保证)。
-
极限交换工具 :
单调收敛定理
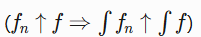 、控制收敛定理
、控制收敛定理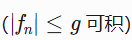 支撑分析操作。
支撑分析操作。
核心公理
测度需满足以下公理,确保度量的一致性与可操作性:
| 公理 | 数学表述 | 直观解释 |
|---|---|---|
| 非负性 | 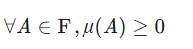 |
集合"大小"非负。 |
| 空集零测度 | 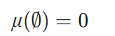 |
空集无体积。 |
| 可数可加性 | 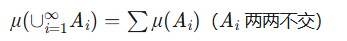 |
互斥部分的总和等于整体(测度本质)。 |
核心设计方程
测度论的关键方程体现其构造与计算逻辑:
外测度构造 :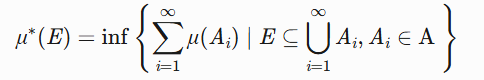
其中 \mathscr{A} 为半环(如区间),用于定义勒贝格外测度。
Hausdorff测度(几何测度论):
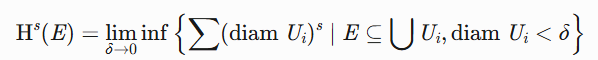
刻画分形集维数(如Cantor集维数 \frac{\ln 2}{\ln 3})。
Radon-Nikodym导数 :
若 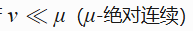 ,存在可测函数
,存在可测函数 f 使得:
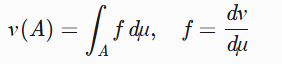
为概率密度函数提供理论基础。
-
概率测度公理 :
增加归一性:
P(\Omega) = 1,形成概率空间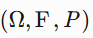 。
。 -
乘积测度(Fubini定理):
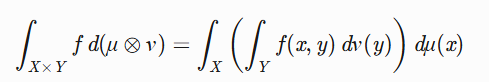
允许高维积分迭代计算。
以下将测度论的核心计算方程转化为MATLAB实现,结合理论定义与数值方法,分为四个关键模块进行解析与代码表达。
Lebesgue积分计算(基于简单函数逼近)
理论基础 :
Lebesgue积分通过简单函数逼近可测函数。设简单函数 \phi = \sum c_i \mathbf{1}_{A_i},积分定义为:
\int \phi \, d\mu = \sum c_i \mu(A_i)对一般可测函数 f,取单调递增简单函数列 \phi_n \uparrow f,则:
\int f \, d\mu = \lim_{n \to \infty} \int \phi_n \, d\muMATLAB实现:
% 定义可测集测度(假设离散测度空间)
mu = @(A) sum(A); % 示例:计数测度,可替换为实际测度函数
% 简单函数的Lebesgue积分计算
function integral = lebesgue_simple(phi, sets, mu)
integral = 0;
for i = 1:length(phi.coeffs)
integral = integral + phi.coeffs(i) * mu(sets{i}); % ∑c_i μ(A_i)
end
end
% 逼近一般函数的Lebesgue积分(以f(x)=x^2在[0,1]为例)
f = @(x) x.^2;
n = 1000; % 划分粒度
x = linspace(0, 1, n+1);
phi_coeffs = arrayfun(@(i) f((x(i)+x(i+1))/2), 1:n); % 取区间中点值
sets = arrayfun(@(i) [x(i), x(i+1)], 1:n, 'UniformOutput', false); % 划分区间
integral_approx = 0;
for i = 1:n
integral_approx = integral_approx + phi_coeffs(i) * (x(i+1)-x(i)); % μ(A_i)为区间长度
end
disp(['Lebesgue积分近似值: ', num2str(integral_approx)]);外测度构造(Carathéodory扩张)
理论基础 :
外测度 \mu^*(E) 定义为覆盖 E 的可测集序列的最小总测度:
\mu^*(E) = \inf \left\{ \sum \mu(A_i) \mid E \subseteq \bigcup A_i, A_i \in \mathscr{A} \right\}其中 \mathscr{A} 为半环(如区间)。
MATLAB实现:
% 生成外测度函数(基于区间半环)
function outer_measure = outer_measure(E, intervals, mu)
min_sum = Inf;
% 遍历所有可能的区间覆盖组合
for k = 1:length(intervals)
covers = nchoosek(1:length(intervals), k); % 所有k组合
for j = 1:size(covers, 1)
cover_set = vertcat(intervals{covers(j,:)});
if all(ismember(E, cover_set)) % 检查E是否被覆盖
total_mu = sum(cellfun(mu, intervals(covers(j,:))));
min_sum = min(min_sum, total_mu);
end
end
end
outer_measure = min_sum;
end
% 示例:计算集合E=[0.2,0.8]的外测度(区间半环取[0,1]的等分)
intervals = arrayfun(@(i) [i/n, (i+1)/n], 0:n-1, 'UniformOutput', false);
mu_interval = @(I) I(2) - I(1); % 区间长度测度
E = [0.2, 0.8];
mu_star = outer_measure(E, intervals, mu_interval);
disp(['外测度 μ*(E) = ', num2str(mu_star)]);Radon-Nikodym导数(密度函数计算)
理论基础 :
若 \nu \ll \mu(\nu 关于 \mu 绝对连续),则存在可测函数 f 使得:
\nu(A) = \int_A f \, d\mu, \quad f = \frac{d\nu}{d\mu}MATLAB实现(离散概率空间):
% 定义测度 μ 和 ν(离散空间)
mu_vals = [0.3, 0.7]; % μ 在两点测度
nu_vals = [0.2, 0.8]; % ν 在两点测度
% 计算Radon-Nikodym导数 f = dν/dμ
f = nu_vals ./ mu_vals; % 逐点比值
disp('Radon-Nikodym导数 f:');
disp(f);
% 验证:∫_A f dμ = ν(A)
A = 2; % 取第二个点集
nu_A = nu_vals(A);
int_fdmu = f(A) * mu_vals(A);
disp(['ν(A) = ', num2str(nu_A), ' | ∫_A f dμ = ', num2str(int_fdmu)]);高维积分(Fubini定理迭代计算)
理论基础 :
对乘积测度空间,Fubini定理允许迭代计算:
\int_{X \times Y} f \, d(\mu \otimes \nu) = \int_X \left( \int_Y f(x,y) \, d\nu(y) \right) d\mu(x)MATLAB实现(以二元函数为例):
% 定义二元函数 f(x,y) = x*y
f = @(x,y) x .* y;
% 定义测度 μ, ν(假设为均匀测度)
mu = @(x) x; % μ([0,x]) = x
nu = @(y) y; % ν([0,y]) = y
% 迭代积分:先固定x,对y积分;再对x积分
integral_x = integral(@(x) ...
arrayfun(@(x_val) ...
integral(@(y) f(x_val, y), 0, 1), ... % 内层∫_Y f(x,y) dν(y)
x), ...
0, 1); % 外层∫_X
disp(['Fubini定理计算结果: ', num2str(integral_x)]);总结与拓展
| 测度论方法 | MATLAB实现核心 | 应用场景 |
|---|---|---|
| Lebesgue积分 | 简单函数分段逼近 + 极限收敛 | 非连续函数积分(如Dirichlet函数) |
| 外测度构造 | 覆盖优化搜索 + 下确界计算 | 分形几何(Hausdorff测度) |
| Radon-Nikodym导数 | 测度比值 + 绝对连续性验证 | 概率密度变换(贝叶斯推断) |
| Fubini定理 | 嵌套数值积分(integral2或迭代) |
高维统计期望计算 |
关键扩展方向:
-
Hausdorff测度 (分形维数计算):
将覆盖集从区间推广到任意直径集合,用球覆盖优化(见搜索):\mathcal{H}^s(E) = \lim_{\delta \to 0} \inf \left\{ \sum (\text{diam } U_i)^s \mid \text{diam } U_i < \delta \right\} -
最佳平方逼近 (函数空间投影):
使用正交多项式(如Legendre多项式)逼近L^2空间函数(代码见)。
通过上述模块化实现,测度论的核心计算可迁移至物理建模(如电磁场泊松方程)、随机过程(Itô积分)及人工智能(概率图模型)等领域,MATLAB的数值稳定性与矩阵运算为此提供高效支撑。
1.4、应用与前沿
- 概率论与统计学:Kolmogorov公理化(概率即测度)、大数定律的测度论证明。
- 泛函分析 :
L^p空间基于勒贝格积分定义,支撑希尔伯特空间理论。 - 几何测度论:研究曲面面积(Plateau问题)、分形结构(Hausdorff维数)。
- 实分析 :勒贝格积分统一反常积分与离散求和(如
\int \mathbf{1}_\mathbb{Q} \, dm = 0)。
总结
测度论以 "可测性"定义域(σ-代数) 与 "可加性"度量规则(测度) 为双核心,通过外测度扩张 、简单函数逼近 、极限定理构建自洽体系。其公理与方程(如可数可加性、RN导数)既是理论基石,也是应用桥梁,使现代数学得以在"不可测"的混沌中建立精确秩序。
二、测度论在人工智能体系中的作用
1. 概率建模与不确定性量化
- 概率空间的数学基础 :测度论为概率论提供严格公理化框架(概率空间
(\Omega, \mathcal{F}, P)),其中事件集合\mathcal{F}是σ-代数,概率测度P满足可列可加性。这使得深度学习中的贝叶斯推断、隐变量模型(如VAE)得以严谨表达。 - 随机过程的刻画:马尔可夫链、布朗运动等随机过程依赖测度论定义路径空间上的概率分布,支撑强化学习的时序决策建模(如MDP)。
2. 函数空间与泛函优化
- 函数空间的结构定义 :人工智能中的特征映射常嵌入希尔伯特空间(如再生核希尔伯特空间RKHS),其完备性由测度论保证。例如,支持向量机(SVM)的核方法依赖
L^2空间的可分性。 - 损失函数的收敛性分析 :训练算法的收敛性(如随机梯度下降)需通过测度论分析期望损失
\mathbb{E}[L(\theta)]的极限行为,确保优化目标的可积性。
3. 数据表示与特征学习
- 特征分布的可测性:深度神经网络的隐藏层输出可视为数据流形上的可测函数,测度论支撑其几何性质分析(如信息几何中的Fisher测度)。
- 生成模型的理论保障 :GAN的生成分布
P_g与真实分布P_r的差异需通过测度论工具(如Wasserstein距离)量化,指导模型训练的稳定性。
4. 鲁棒性与泛化理论
- 泛化误差的测度解释:VC维、Rademacher复杂度等泛化界指标本质是函数空间在数据测度下的覆盖性质。
- 对抗样本的防御 :输入空间的扰动可建模为测度扰动,对抗训练等价于优化测度鲁棒风险
\min_\theta \sup_{Q \sim P} \mathbb{E}_Q[L(\theta)]。
三、测度论在GPU设计理论中的作用
1. 计算精度与数值稳定性
- 浮点误差的测度控制:GPU低精度运算(FP16/INT8)需保证数值误差的累积满足可测收敛(如依测度收敛),避免因舍入误差导致计算发散。
- 张量核心的数学基础:矩阵乘法的加速(如Tensor Core)依赖线性算子在测度空间中的有界性,确保计算的数值一致性。
2. 内存访问与数据局部性优化
- 数据分布的测度建模 :GPU显存访问模式可抽象为测度空间
( \text{Address}, \mathcal{B}, \mu ),其中\mu表示数据访问频率的测度。缓存策略(如LRU)通过优化\mu的局部性提升吞吐。 - 异构计算的负载均衡 :任务划分需满足
\int_{\text{CPU}} d\mu = \int_{\text{GPU}} d\mu,避免计算资源闲置。
3. 并行计算的收敛性保障
- 分布式训练的同步协议 :All-Reduce等通信协议需保证梯度更新的可积性(
\int \nabla L \, d\mu存在),防止异步更新导致发散。 - 硬件调度的测度约束:GPU流多处理器(SM)的任务分配需满足测度守恒律,确保线程块负载均衡。
4. 能效优化的测度框架
- 功耗的积分表示 :GPU能耗
E = \int_{t} P(t) \, d\mu(t),其中\mu为时间测度。动态电压频率调整(DVFS)通过优化\mu的支撑集降低功耗。
四、测度论在数据库设计理论中的作用
4.1 数据库
数据库的分类体系可以从多个维度展开,不同分类方式反映了其设计目标和技术特性。以下是基于数据模型、体系结构、部署方式、应用场景及特殊类型的综合分类体系。
4.1.1、按数据模型分类(最核心的分类方式)
| 类型 | 特点 | 代表产品 | 适用场景 |
|---|---|---|---|
| 关系型数据库 | 以二维表存储数据,支持SQL、ACID事务、主外键关联 | MySQL, PostgreSQL, Oracle | 银行系统、ERP、高一致性事务处理 |
| 文档型数据库 | 存储JSON/BSON格式文档,动态模式,读写灵活 | MongoDB, CouchDB | 内容管理、社交媒体、半结构化数据存储 |
| 键值型数据库 | 简单键值对结构,超高读写性能 | Redis, DynamoDB | 缓存、实时计数、会话管理 |
| 列存储数据库 | 按列压缩存储,适合大规模数据分析 | Cassandra, HBase | 日志分析、数据仓库、时序数据处理 |
| 图数据库 | 以节点和边存储关系,擅长复杂网络分析 | Neo4j, ArangoDB | 社交网络、欺诈检测、知识图谱 |
| 时序数据库 | 优化时间序列数据存储,支持高效时间窗口聚合 | InfluxDB, TimescaleDB | IoT监控、金融行情记录 |
| 搜索引擎数据库 | 全文索引与分词检索,支持复杂文本分析 | Elasticsearch, Solr | 日志检索、内容推荐 |
4.1.2、按体系结构分类(三级模式)
-
内部模式(物理层)
- 核心:数据物理存储方式(如行存储 vs 列存储)
- 技术:索引(B树、哈希)、分区(范围/哈希/列表分区)、压缩/加密
- 示例:OLTP系统用行存储(如MySQL),OLAP系统用列存储(如ClickHouse)。
-
概念模式(逻辑层)
- 核心:数据逻辑关系与约束(ER模型、范式化、ACID事务)
- 示例:关系型数据库的主外键约束保障数据一致性。
-
外部模式(用户层)
- 核心:用户视图与交互接口(SQL查询、API、报表工具)
- 示例:JDBC/ODBC接口连接应用与数据库。
4.1.3、按部署架构分类
| 类型 | 特点 | 代表产品 |
|---|---|---|
| 集中式数据库 | 单机部署,传统架构 | Oracle, MySQL |
| 分布式数据库 | 数据分片存储,水平扩展 | Cassandra, TiDB, CockroachDB |
| 云数据库 | 托管服务,自动运维 | AWS RDS, Azure SQL, 阿里云PolarDB |
| 内存数据库 | 数据全内存存储,毫秒级响应 | Redis, MemSQL |
| 嵌入式数据库 | 轻量级集成到应用中 | SQLite, LevelDB |
4.1.4、按应用场景分类
- OLTP(联机事务处理) :高并发短事务(如订单处理),代表:MySQL, PostgreSQL
- OLAP(联机分析处理) :大数据聚合分析,代表:Snowflake, Amazon Redshift
- 实时计算 :流数据处理,代表:Apache Kafka + Flink
- 混合负载 :HTAP架构(事务+分析),代表:TiDB, Google Spanner
4.1.5、特殊类型数据库
| 类型 | 创新点 | 应用场景 |
|---|---|---|
| 向量数据库 | 存储AI模型生成的向量,支持相似度检索 | AI推荐、语义搜索(Milvus, Pinecone) |
| 多模型数据库 | 融合多种数据模型(文档+图+键值) | 复杂业务系统(ArangoDB) |
| 自治数据库 | 基于ML自动调优、备份、安全 | 云原生应用(Oracle Autonomous DB) |
| 区块链数据库 | 不可篡改的分布式账本存储 | 供应链溯源(BigchainDB) |
4.1.6 技术选型指南
- 结构化事务系统 → 关系型数据库(如PostgreSQL)
- 高并发缓存/实时数据 → 键值数据库(如Redis)
- JSON/日志数据 → 文档数据库(如MongoDB)
- 社交网络/风控 → 图数据库(如Neo4j)
- IoT/监控数据 → 时序数据库(如InfluxDB)
- AI向量检索 → 向量数据库(如Milvus)
💡 关键趋势:云原生+多模型融合(如AWS Aurora支持关系与文档模型)、分布式HTAP(TiDB)、AI驱动的自治运维。
以下基于功能特性、性能表现、适用场景及核心限制四个维度,对七类数据库进行综合对比分析,结合行业实践与技术原理提供选型参考:
核心特性对比矩阵
| 数据库类型 | 数据模型 | 事务支持 | 扩展模式 | 查询语言 | 典型产品 |
|---|---|---|---|---|---|
| 关系型 | 二维表(行列) | ⭐️⭐️⭐️⭐️⭐️ ACID完整支持 | ▲ 垂直扩展易 ◉ 水平扩展难(需分库分表) | SQL | MySQL, PostgreSQL, Oracle |
| 文档型 | JSON/BSON文档 (嵌套结构) | ⭐️⭐️⭐️ 有限多文档事务 | ◉ 水平扩展易(分片) | MongoDB Query, MapReduce | MongoDB, CouchDB |
| 键值型 | 键-值对 (值可结构化) | ⭐️ 仅单键原子操作 | ◉ 水平扩展易(集群分片) | GET/SET/DEL命令 | Redis, DynamoDB |
| 列存储 | 列族+行键 (稀疏矩阵) | ⭐️⭐️ 行级原子性 | ◉ 水平扩展极佳 (自动分Region) | CQL, Scan API | Cassandra, HBase |
| 图数据库 | 节点+边+属性 | ⭐️⭐️⭐️ ACID(单图事务) | ▲ 垂直扩展为主 | Cypher, Gremlin | Neo4j, ArangoDB |
| 时序数据库 | 时间戳+指标+标签 | ⭐️⭐️ 按时间窗口批处理 | ◉ 水平扩展易 (按时间分片) | InfluxQL, PromQL | InfluxDB, TimescaleDB |
| 搜索引擎 | 文档+倒排索引 | ⭐️ 无事务保证 | ◉ 水平扩展易 (分片与副本) | DSL(JSON查询) | Elasticsearch, Solr |
性能与场景深度解析
1. 关系型数据库 (e.g., MySQL, PostgreSQL)
- 功能优势 :
- ACID事务保障跨表操作一致性(如转账交易)
- 多表JOIN与复杂子查询优化(OLTP场景)
- 性能瓶颈 :
- 写入速度受事务日志同步制约(fsync延迟)
- 分库分表后跨片查询效率骤降(需中间件协调)
- 适用场景 : ✅ 银行核心系统(强一致性)
✅ ERP库存管理(多表事务更新)
⛔️ 避免用于:JSON嵌套字段频繁更新、亿级数据实时分析
2. 文档型数据库 (e.g., MongoDB)
-
功能优势:
-
动态Schema支持字段随时增减(如用户画像标签)
-
文档内嵌减少JOIN(订单与子订单一体存储)
-
-
性能表现:
-
读吞吐量高(BSON二进制解析快)
-
索引支持嵌套字段(如
user.addresses.city)
-
-
限制警告:
‼️ 大文档更新导致写放大(整个文档重写)
‼️ 跨文档事务性能损耗(MongoDB 4.0+支持但慢于RDBMS)
3. 键值型数据库 (e.g., Redis)
-
性能标杆:
-
内存读写延迟 <1ms(单核10万+ QPS)
-
数据结构优化(如跳表实现ZSET排行榜)
-
-
场景适配:
✅ 秒杀库存缓存(SETNX原子扣减)
✅ 实时会话存储(TTL自动过期)
⛔️ 避免替代关系型DB:无条件过滤、复杂聚合
4. 列存储数据库 (e.g., Cassandra)
-
存储优化:
-
列压缩率高达90%(同质数据类型)
-
时间戳版本控制(LSM树追加写入)
-
-
查询特性:
-
高效聚合(SUM/AVG按列计算)
-
RowKey范围扫描(如设备ID+时间前缀)
-
-
典型场景:
🔍 物联网传感器数据(每秒百万写入)
🔍 广告点击流分析(按日期+渠道聚合)
5. 图数据库 (e.g., Neo4j)
-
关系处理优势:
-
多跳查询复杂度O(1)(对比SQL的O(n³))
-
路径匹配(如欺诈检测环路识别)
-
-
性能对比:
- 社交网络3度好友查询:Neo4j ≈ 0.1s vs SQL > 10s
-
局限:
‼️ 非关系查询无优势(如单点属性过滤)
‼️ 全图计算内存消耗高
6. 时序数据库 (e.g., InfluxDB)
-
时序优化:
-
时间分区自动过期(TTL清理旧数据)
-
降采样(Downsampling)预聚合
-
-
性能指标:
-
单节点每秒百万点写入(时间戳+指标存储)
-
高效时间窗口函数(如
moving_average())
-
-
适用领域:
📈 服务器监控(Prometheus替代方案)
📈 金融行情tick数据存储
7. 搜索引擎数据库 (e.g., Elasticsearch)
-
检索能力:
-
倒排索引+分词器(中文IK分词)
-
相关性评分(TF-IDF/BM25算法)
-
-
扩展功能:
-
聚合分析(日志错误率统计)
-
近实时索引(数据延迟~1s)
-
-
使用警告:
‼️ 深分页性能差(Scroll API替代)
‼️ 频繁更新导致Segment合并风暴
关键限制与规避方案
| 数据库类型 | 核心限制 | 规避策略 |
|---|---|---|
| 关系型 | 水平扩展难 JSON查询低效 | 用读写分离+ProxySQL分流 JSON字段转关联表 |
| 文档型 | 事务性能弱 大文档更新慢 | 业务拆解为原子操作 文档拆分+引用 |
| 键值型 | 无复杂查询 内存容量有限 | 搭配SQL数据库 冷热数据分级(Redis+SSD) |
| 列存储 | 单行事务弱 随机读延迟高 | 批处理写入+Compaction RowKey设计热点分散 |
| 图数据库 | 资源消耗大 学习曲线陡 | 子图计算替代全图遍历 使用Gremlin可视化工具 |
| 时序数据库 | 非时序查询慢 | 分离存储:时序库+分析库(ClickHouse) |
| 搜索引擎 | 数据一致性弱 | 写操作确认机制(ack=all) |
选型决策树(根据场景匹配)
-
是否需要强事务?
→ 是 → 选关系型数据库 (金融交易)
→ 否 → 进入下一题
-
数据结构是否多变?
→ 是 → 选文档型数据库 (用户画像)
→ 否 → 进入下一题
-
是否需处理关系网络?
→ 是 → 选图数据库 (社交推荐)
→ 否 → 进入下一题
-
是否以时间序列为主?
→ 是 → 选时序数据库 (IoT监控)
→ 否 → 进入下一题
-
是否需要全文检索?
→ 是 → 选搜索引擎数据库 (日志分析)
→ 否 → 进入下一题
-
是否要求超高读写?
→ 是 → 选键值数据库 (缓存计数)
→ 否 → 选列存储数据库(大数据分析)
注:混合架构已成趋势(如 PostgreSQL+Redis+Elasticsearch 组合应对多维度需求)。
通过上述对比可见,无普适数据库,需基于读写模式、一致性需求、扩展性优先级进行技术拼合。现代系统常采用"多模数据库"(如 PostgreSQL 支持JSON与时序扩展)或"多库协同"架构平衡各项需求。
4.2测度论在各类数据库中的核心应用
1. 关系型数据库
- 数据完整性与概率事务
通过测度公理化定义实体关系(如ER模型中的基数约束),结合概率测度量化数据一致性风险。
示例 :在金融风控中,外键约束可建模为条件概率测度:
P(订单有效∣用户存在)=∫Ivalid(x)dμ(x)
其中 μ 为用户存在性测度,I 为指示函数。
2. 文档型数据库(如MongoDB)
- 动态模式度量与分布对齐
利用Hellinger距离度量文档分布相似性:H2(P,Q)=21∫(dP−dQ)2用于优化文本聚类和版本演化追踪。
3. 键值型数据库(如Redis)
- 分布式一致性测度
通过Hausdorff测度量化集群状态差异,解决CAP定理中的分区容错问题:
μHaus(A,B)=inf{ε∣A⊆Bε,B⊆Aε}其中 Bε 为 B 的 ε-邻域。
4. 列存储数据库(如Cassandra)
- 列压缩的测度优化
基于Lebesgue积分计算列数据的信息熵,指导压缩算法选择:
H(X)=−∫f(x)logf(x)dλ(x)高熵列采用字典压缩,低熵列采用行程编码。
5. 图数据库(如Neo4j)
- 图结构度量与路径优化
应用Wasserstein距离量化子图相似性:W(μ,ν)=infγ∈Γ(μ,ν)∫d(x,y)dγ用于欺诈检测中的异常交易环路识别。
6. 时序数据库(如InfluxDB)
- 时间窗口测度与异常检测
定义时间轴上的Lebesgue测度 μt,计算事件密度:ρ(t)=dtdμt,异常判定: ρ(t)>kσ,实时触发IoT设备告警。
7. 搜索引擎数据库(如Elasticsearch)
- 相关性评分的测度基础
TF-IDF权重可视为词频测度 μterm 与文档测度 μdoc 的乘积:
TF-IDF=μterm(w)⋅logμdoc(Dw)N结合向量空间测度优化语义检索
五、测度论在大数据设计理论中的作用
测度论作为现代数学分析的基石,为大数据体系提供了处理不确定性、高维复杂性和抽象空间映射的理论框架。
5.1、测度论在大数据体系的核心作用
1. 不确定性量化与概率建模
- 概率空间公理化 :测度论将概率定义为可测空间上的规范测度(
P(\Omega)=1),支撑贝叶斯网络、隐马尔可夫模型等概率图模型的数学严谨性。例如,在金融风控中,违约概率可表示为P(\text{违约} | \text{特征}) = \int f(\text{特征}) d\mu。 - 随机过程分析:布朗运动、泊松过程等依赖测度论定义路径空间上的概率分布,用于用户行为时序预测(如电商点击流分析)。
2. 高维数据空间的结构化度量
- 抽象空间定义 :通过
\sigma-代数定义可测集,将非结构化数据(文本、图像)映射到可测空间(如词嵌入空间),支撑特征工程。 - 距离度量优化 :Wasserstein距离(
\inf \int \|x-y\| d\gamma(x,y))解决分布对齐问题,用于跨域推荐系统。
3. 积分理论与数据聚合
-
Lebesgue积分替代黎曼积分 :处理非连续、高振荡数据(如传感器噪声),计算效率提升显著:
# 近似计算Lebesgue积分(离散化值域) def lebesgue_integral(f, domain, mu): y_values = sorted(set(f(x) for x in domain)) integral = 0 for y in y_values: set_A_y = [x for x in domain if f(x) >= y] integral += y * mu(set_A_y) # μ为测度函数 return integral -
Fubini定理支持高维聚合:分布式计算中实现多维统计量的迭代计算(如广告曝光-点击联合分析)。
5.2、典型大数据产品中的测度论应用
1. 概率数据库与图计算引擎
- Apache Spark GraphX:使用测度论定义节点影响力(如PageRank收敛性证明)。
- Probabilistic Databases (e.g., MystiQ) :基于测度论处理不确定查询(
P(Q|D) = \int I_Q dP)。
2. AI驱动的分析平台
-
TensorFlow Probability :构建概率层(
tfp.layers.DenseVariational),利用Radon-Nikodym导数实现变分推断:import tensorflow_probability as tfp model = tf.keras.Sequential([ tfp.layers.DenseVariational(units=1, make_prior_fn=lambda: tfp.distributions.Normal(loc=0, scale=1), make_posterior_fn=lambda t: tfp.distributions.Normal(loc=t, scale=0.1)) ])
3. 实时决策系统
- Flink实时风控引擎 :用Lebesgue测度定义时间窗口内异常事件测度(如每秒交易频次
\mu(\{t: \text{交易}_t > \text{阈值}\})。
5.3 方法融合:测度论与大数据技术的结合范式
1. 统计测度与机器学习融合
- 步骤 :
- 数据预处理 :Hausdorff测度清洗异常值(删除
\mu-零测集)。 - 特征工程:将特征映射到再生核希尔伯特空间(RKHS),保证可测性。
- 损失函数设计 :期望损失
\mathbb{E}[L] = \int L(\theta,x) dP(x)的测度可积性验证。
- 数据预处理 :Hausdorff测度清洗异常值(删除
2. 分布式测度计算框架
-
MapReduce测度聚合 (Spark示例):
# 计算集合外测度(HDFS存储数据分片) data = sc.textFile("hdfs://data/points") def outer_measure(partition, mu): covers = find_minimal_cover(partition) # 最小覆盖算法 return sum(mu(cover) for cover in covers) result = data.mapPartitions(lambda p: [outer_measure(p, lebesgue_measure)]).sum()
3. 动态测度学习
-
在线测度调整 :用随机梯度下降优化测度参数(如调整Wasserstein-GAN的
\gamma分布):for batch in data_stream: real_data = batch z = noise.sample() fake_data = generator(z) # 计算Wasserstein距离(测度对齐) loss = tf.reduce_mean(critic(real_data)) - tf.reduce_mean(critic(fake_data)) optimizer.minimize(loss) # 更新生成器/判别器
5.4 核心应用场
1. 教育大数据:学习行为测度(搜索)
-
方法 :定义学习投入度测度
\mu(\text{投入}) = \int_{\text{时间}} \text{注意力} \cdot d\nu(t)。 -
代码 :
# 基于Flink的实时注意力计算 env = StreamExecutionEnvironment.get_execution_environment() events = env.add_source(KafkaSource(...)) # 眼动仪+点击流数据 attention = events.key_by(user_id).map(lambda e: (e.user, 1 if e.focus else 0)) mu_attention = attention.time_window(Time.minutes(10)).reduce(lambda a, b: a + b)
2. 金融风控:违约概率测度(搜索)
-
方法 :条件概率测度
P(\text{违约}|X) = \int \sigma(\text{NN}(x)) d\mu(x)。 -
代码 :
# PyTorch概率模型 class CreditModel(nn.Module): def forward(self, x): features = self.encoder(x) return td.Independent(td.Normal( loc=self.loc(features), scale=self.scale(features)), 1) likelihood = CreditModel() posterior = torch.optim.Adam(likelihood.parameters()) # 变分推断优化测度
总结
测度论通过公理化概率空间 、抽象积分框架 和高维测度构造,解决了大数据中不确定性建模、异构数据融合及动态系统分析的瓶颈问题。其与大数据技术的结合呈现三大趋势:
- 算法层:概率机器学习模型依赖测度可积性保证收敛性
- 架构层:分布式计算框架(Spark/Flink)实现测度并行聚合
- 应用层:智能测度系统(如教育行为分析、金融风控)提升决策科学性。
未来方向:量子测度理论与神经符号计算的结合,有望解决超大规模动态系统的实时测度学习问题。
六、交叉领域的典型应用案例
-
深度学习+度量学习:
- 三元组损失(Triplet Loss)依赖测度论定义嵌入空间的度量(如欧氏距离),优化特征相似性。
- 人脸识别中的FaceNet利用测度紧性压缩特征空间。
-
概率硬件加速器设计:
- 英伟达COPA-GPU架构通过多芯片模块(MCM)实现测度可配置性,动态分配FP32(高精度)与FP16(低精度)计算单元。
-
联邦学习的隐私保护:
- 差分隐私噪声注入需满足
\int f \, d\mu的灵敏度有界性,确保统计查询的测度扰动可控。
- 差分隐私噪声注入需满足
随机过程是连接确定性与随机性的桥梁:
- 理论价值:通过测度论与泛函分析,为动态随机系统提供严格数学框架。
- 应用广度:从量子力学到金融工程,从通信网络到生物进化,覆盖现代科学的核心场景。
测度论在人工智能中提供理论基础 (概率建模、泛函优化),在GPU设计中指导工程实践(精度控制、能效优化)。二者结合的核心在于:
将算法层面的概率分布和函数空间性质,映射到硬件层面的数值表示与计算流。
未来随着类脑计算与量子计算的发展,测度论将进一步成为连接数学理论与硬件创新的桥梁(如神经形态芯片的脉冲发放测度模型)。