文章目录
- [Makefile 的通用模板](#Makefile 的通用模板)
-
- [1. Makefile 的推导原则](#1. Makefile 的推导原则)
- [2. 设计 Makefile 的通用模板](#2. 设计 Makefile 的通用模板)
- [3. 通用模板代码(可以直接拿来用)](#3. 通用模板代码(可以直接拿来用))
- [Linux 第一个系统程序-进度条(7-3.00.00)](#Linux 第一个系统程序-进度条(7-3.00.00))
-
- [1. 补充回车与换行](#1. 补充回车与换行)
- [2. 行缓冲区](#2. 行缓冲区)
- [3. 倒计时小程序](#3. 倒计时小程序)
Makefile 的通用模板
1. Makefile 的推导原则
以程序的翻译作为例子来引出
Makefile的推导原则。在Makefile中可以用警号(#)去注释
bash
code:code.o
gcc code.o -o code
code.o:code.s
gcc -c code.s -o code.o
code.s:code.i
gcc -S code.i -o code.s
code.i:code.c
gcc -E code.c -o code.i
.PHONY:clean
clean:
rm -rf *.o *.i *.s code 
- 在
make时,code是依赖code.o的,可code.o文件在当前路径下存在吗?不存在,就向下去推导。 code.o是依赖code.s的,可code.s文件在当前路径也不存在,又向下推导,最终来到了code.c,发现在当前路径下存在该文件。- 就依次形成了
code.i,code.s,code.o,code。所以make会进行依赖关系的推导,直到依赖文件是存在的 - 这就类似于将依赖方法不断入栈,推导完毕,出栈执行方法,这就是
makefile的推导原则

2. 设计 Makefile 的通用模板
通用做法:先将该路径下的所有.c文件全部编译成.o文件,再与动静态库进行链接,最终形成可执行程序,并不是直接将所有.c文件一股脑的形成可执行程序

1. 第一代版本,并不具备通用性,只适用于code.c这一个源文件
bash
1 code:code.o
2 gcc code.o -o code
3 code.o:code.c
4 gcc -c code.c -o code.o
5
6 .PHONY:clean
7 clean:
8 rm -rf *.o code #下面的图片写错了
2. 第二代版本,用变量的形式去进行替换,但也不是很通用,只适用于编译一个文件
bash
1 BIN=code #可执行程序
2 SRC=code.c #源文件
3 OBJ=code.o
4 CC=gcc #编译器
5 RM=rm -rf #删除命令
6
7 # $(变量)->内容,比如:$(BIN)->code
8 # 照着下面改即可
9 $(BIN):$(OBJ)
10 $(CC) $(OBJ) -o $(BIN)
11 $(OBJ):$(SRC)
12 $(CC) -c $(SRC) -o $(OBJ)
13
14 .PHONY:clean
15 clean:
16 $(RM) $(BIN) $(OBJ)
17
18 #code:code.o
19 # gcc code.o -o code
20 #code.o:code.c
21 # gcc -c code.c -o code.o
22 #
23 #.PHONY:clean
24 #clean:
25 # rm -rf *.o code
3. 第三代版本,如果在当前目录下有一百个或一千个源文件呢?怎么保证你的代码写的更加通用呢?
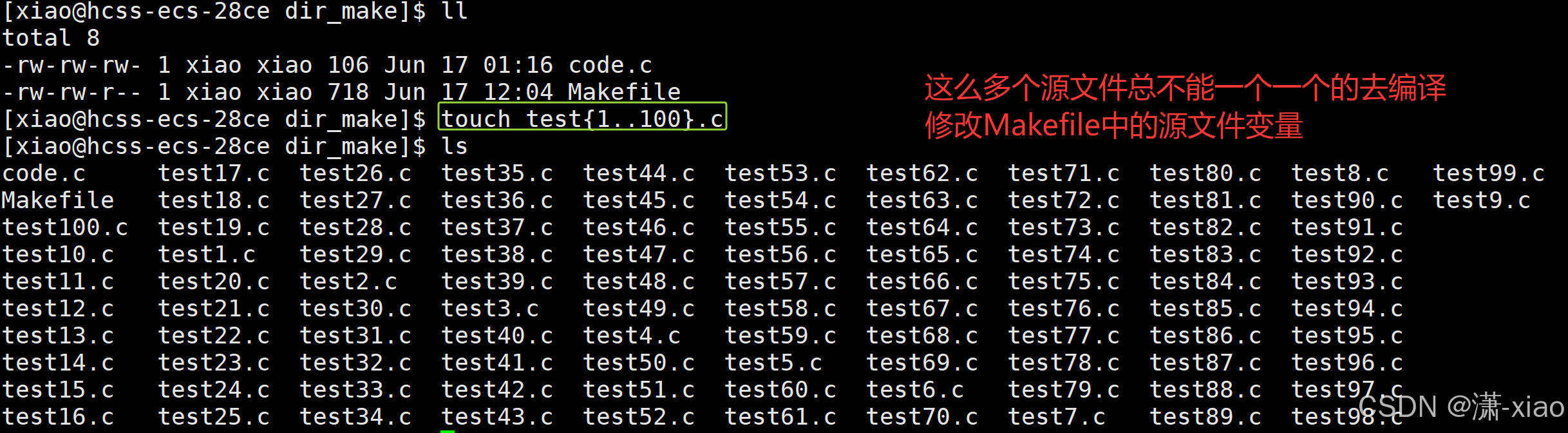
- 既然源文件从一个变成了100个,那赋值给变量也需要进行相应的修改。
SRC=code.c→$(shell ls *.c),把所有罗列出来的.c文件全部放到SRC里面 - 如何验证变量
SRC里面放置了100个源文件列表呢?用依赖方法:echo $(SRC),打印到显示器上 - 命令前面带上
@符号,可以不用回显命令执行的过程,只显示命令执行的结果

- 想将100个源文件放置到变量
SRC也可以:SRC→$(wildcard *.c)。这里的wildcard就相当于一个函数,两种用法是等价的 - 源文件的变量(
SRC)发生改变,则对应的OBJ也要发生变化。OBJ=code.o→OBJ=$(SRC:.c=.o),这是Makefile自己的语法,要求将SRC所有的源文件的.c换成.o,再赋值给OBJ,这个对于SRC和源文件是没有影响的

- 接着就是依赖关系(
$(BIN):$(OBJ))+ 依赖方法(gcc $(OBJ) -o $(BIN))。这里的依赖方法还有另外一种写法:gcc $^ -o $@,$^→$(OBJ),$@→$(BIN)

- 根据
Makefile的推导原则,当前路径下并没有.o文件,会向下推导。因此要形成.o文件,依赖关系(%.o:%.c)+ 依赖方法($(CC) -c $<) - 这里的
%符号就是Makefile中的通配符,%.o与%.c分别匹配所有的.o与.c文件。$<就是把%.c中的文件一个一个的拿出来交给对应的命令,再被gcc一个一个的编译成同名.o文件

- 一个依赖关系后面是可以跟多个依赖方法的

3. 通用模板代码(可以直接拿来用)
bash
BIN=code #可执行程序
SRC=$(wildcard *.c)
#SRC=$(shell ls *.c) #源文件列表放到变量SRC中
OBJ=$(SRC:.c=.o)
CC=gcc #编译器
RM=rm -rf #删除命令
$(BIN):$(OBJ)
@#gcc $(OBJ) -o $(BIN) 虽然加了警号,但不带@,也会进行命令回显
@$(CC) $^ -o $@ #加上@符号不让命令回显
@echo "链接 $^ 成 $@"
%.o:%.c
@$(CC) -c $<
@echo "编译... $< 成 $@"
.PHONY:clean
clean:
@$(RM) $(BIN) $(OBJ)
.PHONY:test
test:
@echo $(BIN)
@echo $(SRC) #不会让命令进行回显
@echo $(QBJ) Linux 第一个系统程序-进度条(7-3.00.00)
1. 补充回车与换行

回车和换行是两个动作,回车:先回到开头,换行:新启一行
2. 行缓冲区
通过有没有带
\n的变化来引出行缓冲区的存在
c
#include<stdio.h>
#include<unistd.h>
int main()
{
printf("hello world");
sleep(2);
return 0;
} - 发现了一个现象:当字符串没带
\n时,hello world不会立即显示出来。当带了\n则会立即显示出来hello world - 程序执行永远是从上至下依次执行,那肯定是先打印(
printf)hello world,再去sleep,可结果好像是sleep了再打印? - 其实
printf这条语句已经执行完了,字符串是被存储到了缓冲区(在内存处)中,而printf打印是将字符串打印到显示器上 - 只不过显示器的刷新策略是:行刷新(带上
\n,就会将缓冲区的字符串刷新到显示器上)。不带\n,要么程序结束时进行刷新,要么手动强制进行刷新 - 手动强制进行刷新,可以用到函数
fflush,它的参数类型是FILE*。FILE* stdin(键盘),FILE* stdout(显示器),传入参数fflush(stdout)可立即刷新

c
#include<stdio.h>
#include<unistd.h>
int main()
{
printf("hello world\n");
sleep(2);
fflush(stdout);
return 0;
} 3. 倒计时小程序
- 光标控制,当向光标所在位置写入一个字符后,光标会自动地向后移动。那就可以先往光标处打印9,再让光标回车到开头显示8,将这个过程循环往复,直至光标处显示0

- 为了解决上面的问题,可以用到回车符(
\r),因为显示器的刷新策略,还得进行手动强制刷新:fflush(stdout)

- 但是当程序从两位数开始倒计时(
cnt = 10),就会依次打印10,90,80,...。这是因为显示器它只认字符,比如当你往显示器打印1234时,并不是打印整数1234,而是一个字符一个字符的打印1,2,3,4 - 这也是为啥显示器叫字符设备的缘故,
printf("%d\n", 1234),printf打印要对这个整数进行格式化,格式化是将这个整数转成字符再进行输出 - 所以从两位数倒计时,
cnt必须占两个字符(printf("%2d\r", cnt),只不过格式化输出定长控制的时候,不足对应的位置默认是右对齐的(空格在左边),所以2前面得加个负号,就能居左对齐
c
int main()
{
int cnt = 15;
while(cnt >= 0)
{
printf("%-2d\r", cnt);
fflush(stdout);
cnt--;
sleep(1);
}
printf("\n");
return 0;
}