自我介绍
大家好,我是志辉,10 年大数据架构,目前专注 AI 编程
1、背景
这个很早我就想写了 App 了,我也是痛风患者,好多年,深知这里面的痛呀,所以我想给大家带来一个好的通风管家的体验,但宏伟目标还是从小点着手,那么就有了今天的主角,痛风伴侣 H5。
目录大纲
前面都是些开胃小菜,看官们现在我们就正式开始正文,那么整体目前是分的 6 个阶段。
前四个阶段可以分为一个大家的阶段,就完成了你的产品工作
最后就是收尾工作,以及后续的维护。
废话少说,就正式开始吧。
第零阶段:介绍
产品开发流程图

这是一个传统的软件开发流程,从需求的讨论开始到最后的产品上线,总共需要的六大步骤,包括后续的迭代升级维护。
成本测算
这里面其实最大的就是投入的人力成本,还不算使用的电脑、软件这些,还包括最大的就是时间成本。
我们按按照基本公司业务项目的项目来迭代看
-
人力成本
-
产品:1~2 人,有些大项目合作的会更多,跨大部门合作的。
-
UI :1 人
-
研发:
- 前端:1~2人
- 后端:2~3人
-
测试:1~2 人
-
合计:这里面最少都是 6 人
-
-
时间成本
- 这里不用多少,大家如果有经验的,基本公司项目一般的需求都是至少一个月 才能上线一个版本,小需求快的也就是半个月上线。
-
沟通成本
- 这个就用说了,大家都是合作项目,产品和 UI,产品和研发,研发和测试,这就是为啥会有那么多会的缘故,不同的工种,面对的是不同

时间成本感受
个人创业感想
那这里你就可能要较真了,你这个功能简单,哪能跟公司的项目比了。
那我就想起我之前跟我同学一起创业搞 app 的时候,那个时候我不会 app、也不会前端,我是主战大数据的,其实对后端有些框架不也太熟。
那会儿我们四个人,1 个 app、1 个后端+前端、1 个产品,也是足足搞了 1 个多月才勉强上了第一个小版本。
但是我们花的时间很多,虽然一个月,但那一个月我没睡过觉,不会就得学呀,哪像现在不会你找个 AI 帮手帮你搞,你就盯着就行,那会一边学前端,一遍写代码,遇到问题只能搜索引擎查,要么就是硬看源码去找思路解决。
想想就是很痛苦。
公司工作感想
本职工作是大数据架构,设计的都是后端复杂的项目通信,整体底层架构设计,但是也需要去做一些产品的事情。
但是大数据产品就不像业务系统配比那么豪华,一整个公司就两三个人,那么有时候就的去做后端服务、前端界面,就为了把我们的产品体验做好。
每天下班疯狂学习前端框架,从最基本的 html、css、js 学起,不然问题解决不了,花了大量的时间,并且做项目还要学习各种框架,不然报错了你都不知道咋去搜索。
这样能做大功能的事情很少,也就是修修补补做些小功能。
产品感想
这也是我最近用了 AI 编程后的感想,最近公司的数据产品项目,我基本都是 AI 编程搞定。
以前复杂的画布拖拉拽,我基本搞不定到上线的质量,现在咔咔的一下午就搞定开发,再结合 AI 的部署模板,一天就基本完成功能。效率太快。
也是这样,我在现在的公司的产出一周顶的上以前的一个月(这真不是吹牛,开会的半个小时,大数据的首页的 landing page 我就做好了🤦♂️) ,但是时间完全不用一周(偷偷的在这了讲,老板知道了,就。。。所以我要多做一些,让老板留下我)。
我现在感想的就是现在更加需要的就是你的创意、你的想法,现在的 AI 能力让更多的人提效的同时,也降低了普通人实现自己产品的可能性。这在以前是无法想象的,毕竟很多门槛是无法跨越,是需要时间磨练的。
效果展示
然后再多来几张美美的截图(偷偷告诉你,这就是我的背景图片工具做出来的。)

第一阶段:需求
1、需求思考
做产品最开的就是需求了,如果你是产品经理,那么我理解这一阶段是不需要 AI 来帮你忙的。
虽然大家基本对产品或多或少都有一些理解,那么专业性肯定比不了,那么我们就需要找专业的帮忙了。
所以我这里找的是 ChatGPT,大家找 DeepSeek,或者是 Gemin,或者是 Claude 都可以的。
markdown
我目前准备为痛风患者开发一个拍照识别食物嘌呤的h5应用,我的需求如下:
1. 这个h5底部有3个tab: 识别、食物、我的
2. 在【识别】页面,用户可以选择拍照或者选择相册上传,然后AI识别食物,并且给到对应的嘌呤的识别结果和建议。
3. 在【食物】页面,用于展示不同升糖指数的常见食物,顶部有一个筛选,用户可以筛选按嘌呤含量高低的食物,下方显示食物照片/名称/嘌呤/描述
4. 【我的】页面顶部有一个折线图,用户记录用户的尿酸历史;下方显示近3次的尿酸数据:包括平均、最低、最高的数据;还有记录尿酸和历史记录的列表。
在技术上,【我的】页面尿酸历史记录保存在本地localStorage中,【食物】的筛选也是通过本地筛选,拍照识别食物嘌呤的功能,采用通义千问的vl模型。
请你参考我的需求,帮我编写一份对应的需求文档。发给 ChatGPT

这样就给我们回复了。
2、思考
你说我不会像你写那么多好的提示词,一个我也是借鉴别人的,一个就是继续找 AI 帮你搞定,比如你不知道 localstoreage 是什么,没关系,这个都是可以找 AI 问出来的。

或者是说你只有一个想法,而不知道这个产品要做成什么,也可以问 AI。
GPT 会告诉你每个阶段该做哪些功能,这样看看哪些对你合适,然后通过不断的多轮对话,来让他输出最后的需求文档。

3、创建需求工作空间
我们在电脑新建个目录,用来存放暂时的需求文档和一些前置工作的文件
Step 1: 在电脑的某个目录下创建前期我们需要的工作项目的目录,这里我叫 h5-food-piaoling
Step 2: Cursor 打开这个目录
Step 3: 创建 docs 目录
Step 4: docs 目录下创建 prd.md 文件,把刚刚 GPT 生成的需求文档拷贝过来。
我这里是后截图的,所以文件很多,不要受干扰了

4、重要的一步
到这里需求文档就创建好了,那么我们是不是马上就可以开发了,哦,NO,这里还有很重要的一步。
那么就是需要仔细看这个 GPT 给我们生成的需求文档,还是需要人工审核下的,避免一些小细节的词语、或者影响的需要修改的。
比如这里,我已经恢复不出来了,这里原来有些 "什么一页的文章,适合老年人的这些文字",这些其实不符合我那会儿想的需求的,所以我就删除了。

比如这里用到的一些技术,如果你懂的话,就可以换成你懂的技术,也是需要考虑到后面迭代升级的一些事情。

总结:其实这里就是需要人工审查下,避免一些很不符合你想的那些,是需要修改/删除的,这个会影响后面生成 UI/交互的逻辑。
不过这个步骤不做问题也不大,这一步也是需要长久锻炼出来,后面等真实的页面出来后,你再去修改也行。
第二阶段:数据准备
这里的一步也是我认为比较特别的点,这个步骤的点可以借鉴到其他场景里面。
1、哪里找数据
你的产品里的数据的可信度在哪里?特别是关乎于健康的,网上的信息纷繁复杂,大家很难分清哪些是真的,哪些是假的。
我之前查食物的嘌呤的时候,就遇见了,同样一个食物,app 上看到的,网上看到的都不一样,我就黑人问号了???
所以,这里就涉及到数据的权威性、真实性了。那么权威机构发布的可信度会更强。
所以我找到了卫健委颁发的数据。
地址:www.nhc.gov.cn/sps/c100088...

另外还可以看到不止痛风的资料有,还有青少年、肥胖、肾病的食养指南。
这些病其实都是慢性病,不是吃药就能马上好起来,需要长期靠饮食、运动来恢复的。
可以把这些数据用起来,后面挖掘更多需求。
2、下载数据
这一步周就是把数据下载下来,直接点击上面的

下载来后是个pdf 的文件,那么这一步我们就准备好了。
这里我附带一份,大家可以作为参考
暂时无法在飞书文档外展示此内容
3、处理数据
这一步是为什么了,是因为目前在所有的 AI 编程工具里面,pdf 是读取不了的,特别是 Cursor 里面。
目前能够读取的是 markdown 格式的数据
markdown 格式的数据很简单,就是纯文本,加上一些符号,就可以做成标题显示
不懂的可以直接问题 AI 工具就行了。
这里就可以看到大模型给我们的解释了。
插曲
我不懂 markdown 是什么,帮我解释下,我一点都不懂这个在 Cursor 里面使用 ask 模式来提问

下面就是一个回答的截图,如果你对里面的文字不清楚的,那么就继续问 AI 就可以了。多轮对话。

处理数据
这里就是需要把 pdf 转为 markdown 的数据
这里推荐使用:mineru.net/
重点在于免费,直接登录注册进来后,点击上传我们刚下载的 pdf。
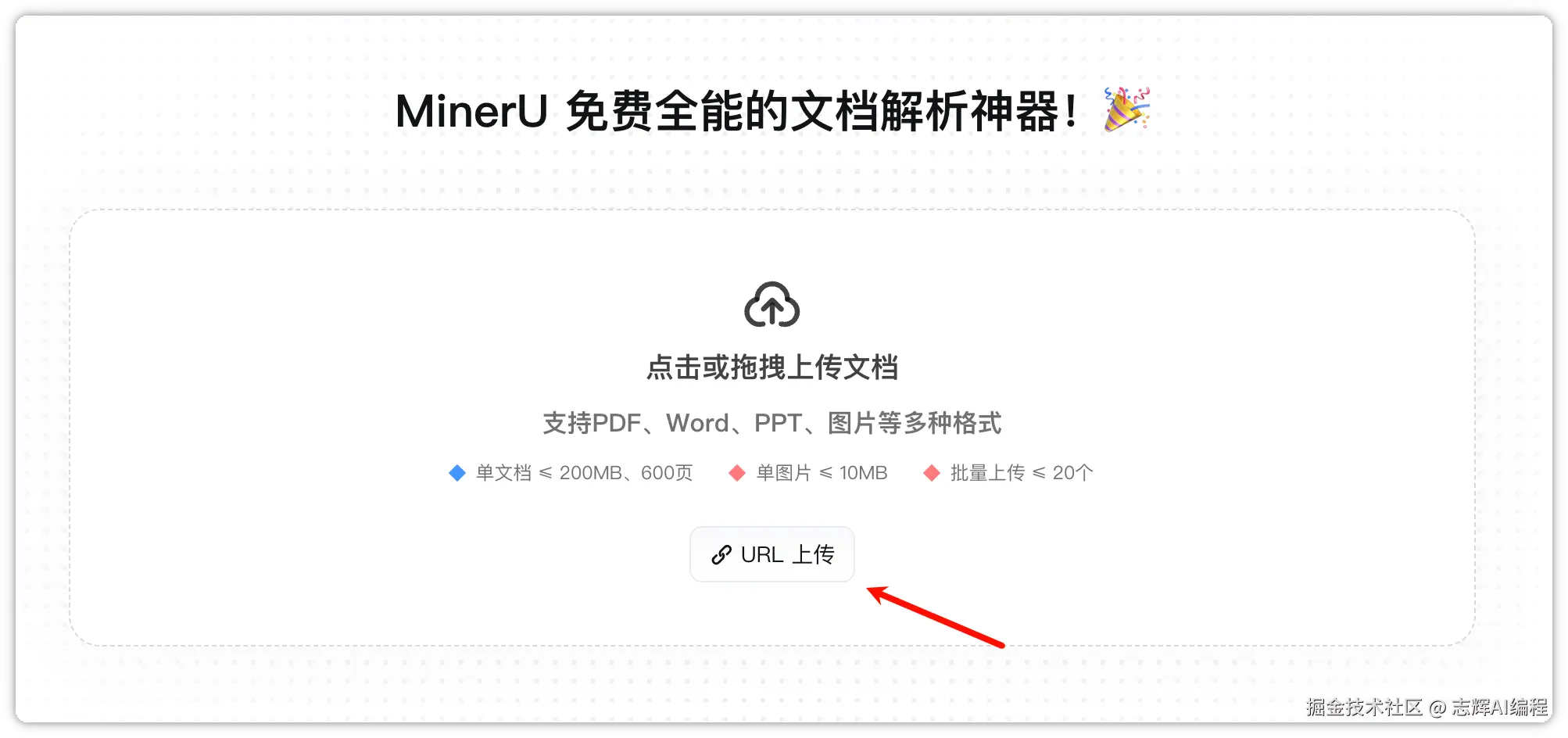
等待上传转换完成,下一步就是在文件里面,看到转换的文件了。
点击右侧下载,就是 markdown 格式。

把下载好的 markdown 文件放入到项目里面的 data 目录,待会儿会需要数据处理。

4、修正需求文档
那么让 Cursor 给我们重新生成需求文档,这样食物的分类,还有统计,会更准确,因为现在是基于权威数据来的。
swift
食物数据库目前是存储在 json 文件里,请根据 @成人高尿酸血症与痛风食养指南 (2024 年版).md 的食物嘌呤数据,再根据 @prd.md 里面的食物数据结构,生成一份数据,并获取对应的 image 图片,保存在 imgs 目录下
5、生成数据文件
前面我们不是讲到了。食物列表的数据需要存储在本地,也就是客户端,形式我们就采用 json 的形式
同样你不知道 json 是个啥的话,找 AI 问,或者直接 Cursor 里面提问就行了。
左边是提示词,右侧就是创建的 json 文件
swift
食物数据库目前是存储在 json 文件里,请根据 @成人高尿酸血症与痛风食养指南 (2024 年版).md 的食物嘌呤数据,再根据 @prd.md 里面的食物数据结构,生成一份数据,并获取对应的 image 图片,保存在 imgs 目录下

结果:

6、继续调整文件
上一步骤发现,其实只给我们列觉了 53 种食物,并不全
我需要全部的数据,那么继续
swift
总结的有 53 种食物,但是我看 @成人高尿酸血症与痛风食养指南 (2024 年版).md 下的"表1-2 常见食物嘌呤含量表" 应该不止这么多,请再次阅读然后补全数据到 @foods.json 文件里。
最后发现,总文档里总结了 180 种的食物

最后生成的数据文件如下:

6、图片问题
不过这里有个问题就是,食物对应的图片是没有办法在这里一次性完成的
我也尝试了在 Cursor 里让他帮我完成,结果些了一大堆的代码,下来的图片还对应不上。
尝试了很多方案,都不太理想。
那你说了,去搜索引擎下载了,我也想到了,不过想起来你要去搜索,然后找图片,下载,有 180 多种了,还要命名好图片名字,最后保存到目录。
想到这里,我就头大,索性干脆自己写一个,其他流程系统都帮我搞定,暂时目前只需要我人工确认图片,保证准确性。
Claude Code + 爬虫碰撞什么样的火花,3 小时搞定我的数据需求
这个小系统也还是有很大的挖掘潜力,后面也还可以做很多事情
到这里基本需求阶段就完成了,数据也准备的差不多了,下面就是进入开发阶段了。
不要看前面的文字多,那都是前戏,下面就是正戏,坐稳扶好,开奔。
第三阶段:开发+联调+测试
这里是主要的开发、联调、测试阶段,也就是在传统开发流程中会占据大部分的时间,基本一个软件/系统的开发大部分的时间都在这个里面,所以我们看看结合 AI 它的速度将会达到什么样。
== 1、前端 ==
步骤一:bolt 开发
说下为什么采用 bolt 工具来做第一步工作。
其实线下 v0、bolt、lovable 很多这种前端设计工具,那么他与 Cursor 的区别在哪里了?
1、首先通过简单的提示词,它生成的功能和 UI 基本都是很完善的,UI 很美、交互也很舒服。这种你在 Curosr 里面从零开始些是很难的。
2、这种工具一般都可以选择界面的上的元素(比如 div、button,这个就比较难),然后进行你的提示词修改,很精准,这个你在 Cursor 里面比较难做。
3、还有一个点就是前端开发的界面的定位这些大模型很难听得懂你在说啥的,所以我感觉也是这块的难度采用了上面那么多的类似的工具的诞生。
当然,如果不用这些工具,直接让 Cursor 给你出 ui 设计,然后使用 UI 设计出前端代码也可以的。
这个我看看后面用其他例子来讲解。
把上面的需求步骤的 prd.md 的需求直接粘贴到提示词框里。没问题,就可以直接点击提交了。
小技巧:看左下角有个五角星的图标,是可以美化提示词的,这个目前倒是 bolt 都有的功能。
另外还可以通过 Github 或者 Figma 来生成项目图片。

下面就是嘎嘎开始干活了。

等他写完,就可以在界面的右侧看到写完的H5程序。
界面很简单,左侧就是对话区域,右侧就是产品的展示区域
小细节:在使用移动端展示的时候,还可以选择对应的手机型号

步骤二:调整
1、错误修复
这个交互我觉得做的特别好,不用粘贴错误,直接就在界面上点击"Attempt fix"就可以了,这真的是纯 vibe coding ,粘贴复制都不用了。🤦♂️
如果有错误,继续就可以了。

2、UI 调整:主题
刚开始其实 UI 并不是太好看,我的主题色是绿色的,所以我也不知道让它弄什么样的好看。
再帮我美化下 UI 界面就输入了上面一句话,刚开始的 UI 如下图

最后看下对比效果
左边是最开始生成的,右边是我让他优化后的样子。还是有很多细节优化的。

3、UI 修复方式一:截图
另外如果样式有问题,可以截图粘贴到对话框,然后输入提示词修改。

4、UI 修复方式二:选择元素
这里就是我要说的可以选择界面上的元素,然后针对某些元素进行改写
bolt 的方式这几输入提示词
v0 比较高级,选择后,可以直接修改 div 的一些样式参数,比如:宽高、字体、布局、背景、阴影。精准调节。(低代码+vibe coding)

经过多轮修复,觉得功能差不多了,就可以转战本地 Cursor 就继续下一步了。
步骤三:本地 Cursor 修改
1、同步代码到 Github
点击右上角的「Integrations」里的 Github。

下面就会提示你链登录 Github

接着授权就可以

然欧输入你需要创建的项目名称
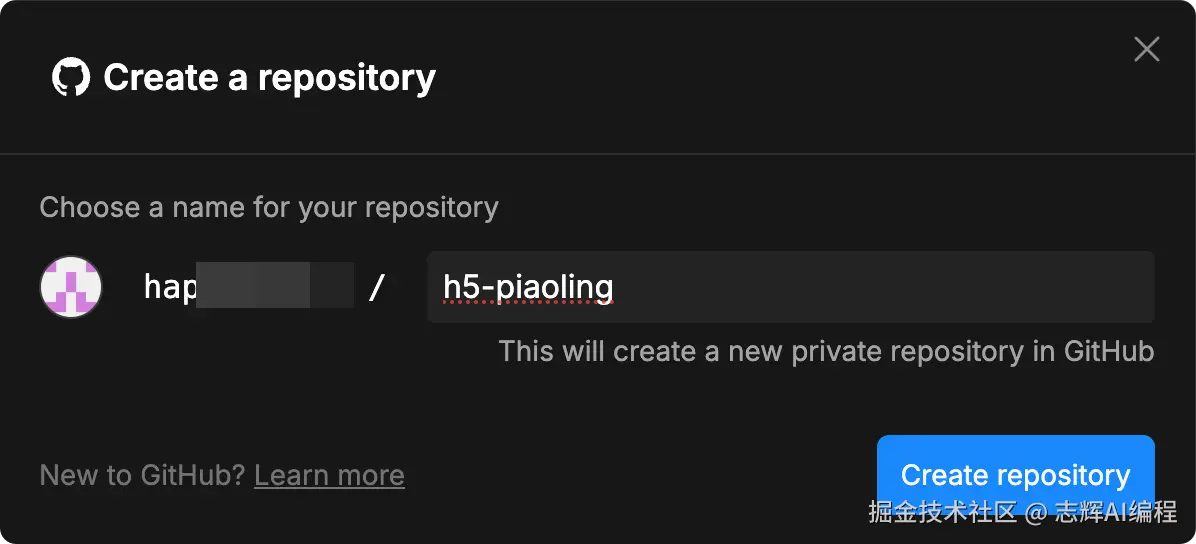
2、本地下载代码
使用 git 工具把代码下载到本地
git 就类似游戏的存档工具,每一个步骤都可以存档,当有问题的时候,就可以从某个存档恢复了。
当然:这里需要提前安装好 Git,如果有不懂的可以联系我,我来帮你解决。这你就不多说了
打开你的 Github 仓库页面,复制 HTTPS 的地址

然后使用下面的命令,就可以下载到本地了。
bash
git clone 你的代码仓库地址
下一步就是安装代码的依赖包
这里需要 nodejs 环境,同样就不多说了,不懂的可以私聊

下一步就是启动

接着就是浏览器打开上面的地址:http://localhsot:3000,就可以看见上面写好的页面。
默认打开是按照 pc 的全屏显示的,可能看着有些别扭

我们打开 F12,打开调试窗口,如下图
点击右侧类似电脑手机的按钮,就可以调到移动端模式显示了,还可以选择对应的机型。

xx 小插曲 xx
原本不想放这里的,结果还是放一下吧,刚好是解决了一个很大的问题
刚开始在 bolt 上面修改的时候,修改后一直报个错误,结果修复了很多次,还是没有解决。

没办法,我就在本地 Cursor 上仔细看了下代码,发现是个引号的问题。

我就在本地 Cursor 中快速修复了下

但是后面惊悚的事情来了,我去 bolt 上调整了下界面样式,结果又给我写成了引号的问题
最后我就发现,可能 bolt 目前对这类的错误还是没有意识。并且看它界面的代码,每次都是从头开始写(难怪要等好一段时间才弄完,究竟是什么设计了?)
最后索性,我仔细看了下代码,删除掉了,没啥大的影响。
目前来看 bolt 这种工具还是有点门槛,解决错误的能力还是没有 Cursor 强大,一不小心页面上的错误就在一起存在,你也不知道它改了啥。
这就需要你对代码还是有基本的认识。
步骤四:使用本地数据
首先就是把前面下载准备好的图片放到 imgs 目录下

在 Cursor 中让从 imgs 目录中显示图片。

不过这里 Cursor 还是很智能的,访问后都是 404

那么就直接告诉 Cursor 让他解决这个问题。
结果他一下子就找到问题所在了,需要放在 public 目录下,这个放以前你需要去搜索引擎里面找问题,并且有时候你拿让 AI 解决的问题,去搜索引擎找,基本都是牛头不对马嘴的回答。
最后还要去找官方文档看资料,不断的尝试。


** 前端小结 **
到这里,基本前端的事情就搞完了
1、识别:识别流程,现在都是走前端模拟的流程
2、食物:这里目前应该是很全的功能了,读取本地的 json 数据,有分类标识,还有图片的展示
3、我的:个人中心有尿酸的记录,有曲线图,还有基本的体重指数记录。
== 2、后端 ==
步骤零:阿里云大模型准备
背景:需要使用大模型来识别图片,然后返回嘌呤的含量,所以我们需要选择一个大模型的 API 来对接。
这里选择阿里的 qwen 来对接。
登录百炼平台:bailian.console.aliyun.com/
访问API-kEY 的地址:bailian.console.aliyun.com/?tab=model#...
创建一个 API-kEY,并保存好你的 key 信息。

步骤一:创建必要的配置
先访问找到通义千问 API 的文档的地方

这里我们采用直接复制上面页面的内容,保存到项目下的 docs 目录在的 qwen.md 里面

这里顺便把之前的 prd.md 文档从之前的项目目录拷贝过来了
步骤二:创建后端服务模板代码
直接使用下面的提示词,就可以创建一个后端的服务
这里要想为什么要创建后端服务,
一方面主要是需要调用大模型的 API,用到一些KEY 信息,这些是需要保密的,不能在前端被人看到了。
另外一方面,后面如果需要一些登录注册服务,还有食物数据都是需要后端来存储,提供给前端。
vbscript
请在项目的根目录下创建 backend 目录,在这个 backend 目录下创建一个基于fastify框架的server,保证服务没有问题同样的不知道什么fastify技术的,找大模型聊就行。



步骤三:API 文档+后端业务服务开发
重点来了,这里我就写到一个提示词里面,让他完成的
bash
帮我接入图像理解能力,参考 @qwen.md :
1. 现在在 @/backend 的后端服务器环境中调用ai能力,
2. 使用 .env 文件保存API_KEY,并使用环境变量中的DASHSCOPE_API_KEY.并且.env文件不能提交到git上,提交到git的可以用.env.example文件作为举例供供用户参考
3. 要求使用openai的sdk,并且前端上传base64的图片
4. 后端返回值要求返回json格式,返回的数据能够渲染识别结果中的字段,包括:食物/嘌呤值/是否适合高尿酸患者/食用建议/营养成分估算
5. 在 @/backend 目录下创建 api.md 文件,记录后端接口文档这里我把 api.md 高亮了,这个是关键,是后面前后端联调的关键,不然 Cursor 是不知道请求字段和响应字段该怎么对接的,到时候数据不对,再来调试就比较麻烦。
所以接口文档务必保证 100% 准确,后面的调试就会很容易。
截图如下:



很贴心的完成功能后,最后帮我们些了 api.md 接口文档,还进行了一些列测试,保证功能是完整的。
这里放出来,Cursor 看是怎么帮我们写这个代码的
- 帮我们组装好了提示词
- 根据 qwen.md 的接口文档,组装请求数据和返回数据,字段都我们的项目符合

== 3、联调 ==
其实这里的联调很简单了。就是一句话的事情。
因为之前的前端的拍照图片都是走的模拟的接口,没有真正的调用后端的接口,所以需要换成真正的后端接口。
刚好前面的后端服务写好了 api.md 接口文档
java
前端修改点,前端目录是当前根目录
1. 也需要加入请求后端的 url 的环境变量,本地调试就默认使用 localhost,线上发布的时候设置环境变量后,前端服务从环境变量获取 url 然后请求到对应的后端服务
2. 食物识别的接口参考 @api.md 文档,请修改需要适配的地方,食物识别的代码在 @identify-page.tsx代码中。


这里要说的是:前面的 api.md 接口文档些的非常准备,这一步的前端请求后端接口,基本都是一遍过,所以后端提供的接口文档一定要准确,这样前端就可以很准确的调用接口传参和取返回值了。
== 4、测试 ==
其实到这里,基本测试的工作也就完成了。
基本的流程到现在都是跑通的。
不过还是需要多实际测试,这里下面的例子就是,我上传了「黄瓜」的照片,结果没识别,按理说不应该呀。
这里上了点专业的技巧,通过 F12 的调试窗口,看下接口返回的数据。
按照以往经验来说,估计是字段对应不上

所以我就直接和 Cursor 说,可能是字段对应不上。请帮我修复。
java
测试黄光的食物的时候,后台接口返回的数据是 "purine_level": "low(低嘌呤<50mg)",但是 @getPurineLevel() @getPurineLevelText 没有识别到,请帮我修复最后从前后端都给我做了修复,字段的匹配对应上了。

最后的总结如下:

== 4、总结 ==
其实到这里基本功能就完成了。
-
前端使用 bolt 工具等生成,快速生成漂亮的 UI 界面和基本完整的前端功能
- bolt工具调整样式、UI 等细节(擅长的)
- Cursor 精修前端小细节
-
Cursor 开发完整后端功能
- 写清楚需求,如果知道具体技术栈是最好的
- 写好接口文档,最好人工校验下
-
前后端联调
- @使用后端的接口文档,最好写改动的接口的地方,前后精准对接
- 学会使用浏览器的 F12 调试窗口,特备是接口的请求参数和响应值的学习。
就目前来看,如果你是零基础,那么基本的术语不明白的话,有些问题可能会不好解决
- 寻求 AI 的帮助,遇事不决问 AI,它可以帮你搞定
- 寻求懂行的人来帮助你,比如环境的事情、按照的事情有时候一句话就可以给你讲明白的。
第四阶段:部署+上线
部署这一块其实对普通人门槛还比较高的,问题比较多。
- 域名问题
- 服务器问题
- 如何部署,如何配置
这里我们采用云厂商的部署服务,简化配置文件和部署的流程
但是域名申请还是需要提前准备好的,不过现在我们用的这个云服务暂时现在没有的域名,也有临时域名可以先用。
到这里,其实如果你只是本地看的话,就已经可以了,那么这里我们教一个上线部署的步骤,傻瓜式的,不需要各种配置环境。
我相信大家如果搞独立开发的 Vercel 肯定都熟悉了。这里也介绍下类似的工具,railway.com/,他不仅可以部署前端静态页面,还有后端服务,PostgreSQL、Redis 等数据库也支持一键部署。

1、项目的配置文件
railway 部署是需要一些配置文件的,当然我们可以让 Cursor 帮我们搞定。
直接告诉 Cursor 我们需要部署到 railway 上,看还需要什么工作可以做的。
后端
bash
@/backend 这个后端项目现在需要在railway上去部署,请帮我看看需要哪些部署配置


前端
也是一样,让 Cursor 给我们生成部署的配置文件
当前目录是前端目录,也需要添加railway的部署相关配置


Cursor 会帮我们创建需要的配置文件,那么就可以进入下一步部署了。
2、提交代码
记得要提交代码,在 Cursor 的页面添加提交代码,推送代码到 Github 上,这样 railway 才可以拉取到代码。
提交代码的时候,可以使用 AI 生成提交信息,也可以自己填写信息


记得还要同步更改


3、railway 页面操作
现在会有赠送的额度,并且免费就用也有 512M 的内存机器使用。对于当前下的足够了。
注册登录后,选择 Dashboard 后,点击添加,就可以看到如下的页面,
添加 Github 项目,后续就会授权等操作,继续完成就可以。

下一步就一个你的项目
然后就会跳转到工作区间,会自动部署。

记得不要忘记环境变量

就是在「Variables」标签下,直接添加变量就行。
添加完记得需要重新部署下。
后端环境变量

前端环境变量

当然不过你有错误,可以把 log 里面的错误复制,粘贴到 Cursor 里面,让他解决,我之前部署的项目有个就有问题,通过这个方式,帮我解决了。
4、大功告成
部署完成后怎么访问了,切换到 settings 页面,有个 Networking 部分,可以生成一个 railway 自带的域名,用这个域名就可以访问了,如果你有自己的域名还可以添加一个自己的域名,添加完以后就可以自己访问了。

5、总结
很开心,跟我走到了这里,基本到这里,算是完成一大步,也就是我们的 MVP 完成了。
现在我们再来总结下前面整体的步骤
1、前端我们通过 bolt 来生成代码,加速前端的设计,让 bolt 这种工具提供我们更多的能力,发挥他的有点
2、后端使用 Cursor 来开发,纯业务逻辑通过提示词还是很好的达到效果。
3、前后端联调,写好接口文档,让 Cursor 必须阅读接口文档,前端再写接口
4、部署配置文件也可以通过 Cursor 来搞定,无所不能
5、中间有任何问题,有任何不懂的都可以找 Cursor 使用 ask 模式搞定。
第五阶段:运营维护+推广
分了「优化」「安全」「推广」三个部分来说这个事情。
- 其实到这里是后续的常态,你不要不断的推广你的产品,去增加访问量。
- 另外就是不断的迭代优化你的功能,提升用户体验,加强本身产品的竞争力。
- 最后、最后、最后就是安全,这个不要忘记了,后面我也会加强后,然后去推广下我的产品,安全很重要,提前做好可以更保护你的服务器和大模型的 API-KEY。
优化
这个是上线了后发现的,就是使用手机拍的照片,一般都比较大,这张图片请求后端的时候,数据量比较大,接口超时了。
那么解决办法:
1、增加后端的请求体的大小
2、压缩图片,然后再请求后端接口
安全
其实这里还是蛮重要的,因为你的服务,还有你的大模型的 KEY,如果服务器被攻击是要付出代价的,最重要的是花掉你的钱呀。
所以这块我还在做,目前想的就是让 Cursor 正题 revivew 代码,看下有什么安全隐患,给我一些解决方案。
推广
如果你的产品上线后,需要写文章、发小红书去推广,首先从你的种子用户开始,你的微信群,你的朋友圈都是可以的。
后面积极听取用户心声,持续解决痛点需求,满足用户的痛点,产品就会越来越好。
第六阶段:成本计算
时间成本
从开始到结束上线,手机使用正式的域名访问,大概就是整一天的时间,从早上开始,忙到晚上我就开启了测试,晚上搞完还去外面遛弯了一大圈回来的。
我们就算:10 小时
人力成本
哈哈哈哈,很清楚,就我一个人
软件成本
bolt:20 元优惠包月(海鲜市场),就算正式渠道,20 刀一个月,当然有免费额度,调整不多,基本够用
Cursor:150教育优惠(海鲜市场),就算正式渠道,20 刀一个月,足足够用
域名:32首年
我们就算满的,折算成人民币,也就是 300 块。
想想 300 块一天你就做出来一个系统(前后端+部署),何况软件都是包月的,一个月你可以产出很多东西,不止这个一个系统。
对比公司开发,一个月的成本前后端两个人,毕业生也的上万了吧,何况还是 5 年经验开发的(市面上的抢手货)。
总结
能走到这里的,我希望你给自己一个掌声,确实不容易。
我希望你也有可以通过编程来实现自己的想法和创意。
虽然目前编程对于零基础的人来说确实可能会有些吃劲,但是你我差距也不大,我现在遇到了很多在搞 AI 编程的都是程序员,有房地产行业的、也有产品的。
遇事不决,问 AI
我希望你可以记住这句话,自己的创意+基本问题找 AI,你基本就可以解决 99% 的问题,剩下的 1% 你基本遇不到,遇到了,也不要慌,身边这么多牛人总会有人知道。