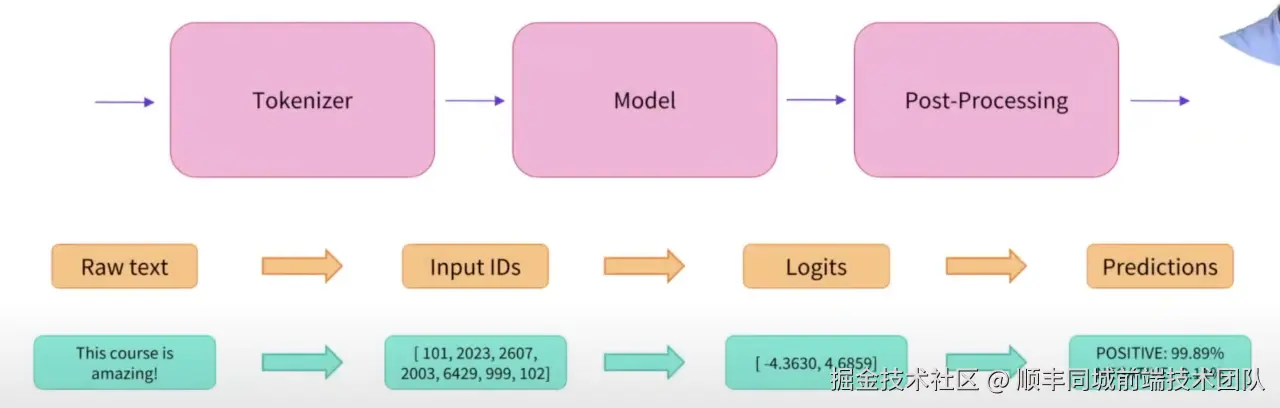
说在前面 ,大模型主要做了什么?
基于概率的token预测系统
基础知识
token
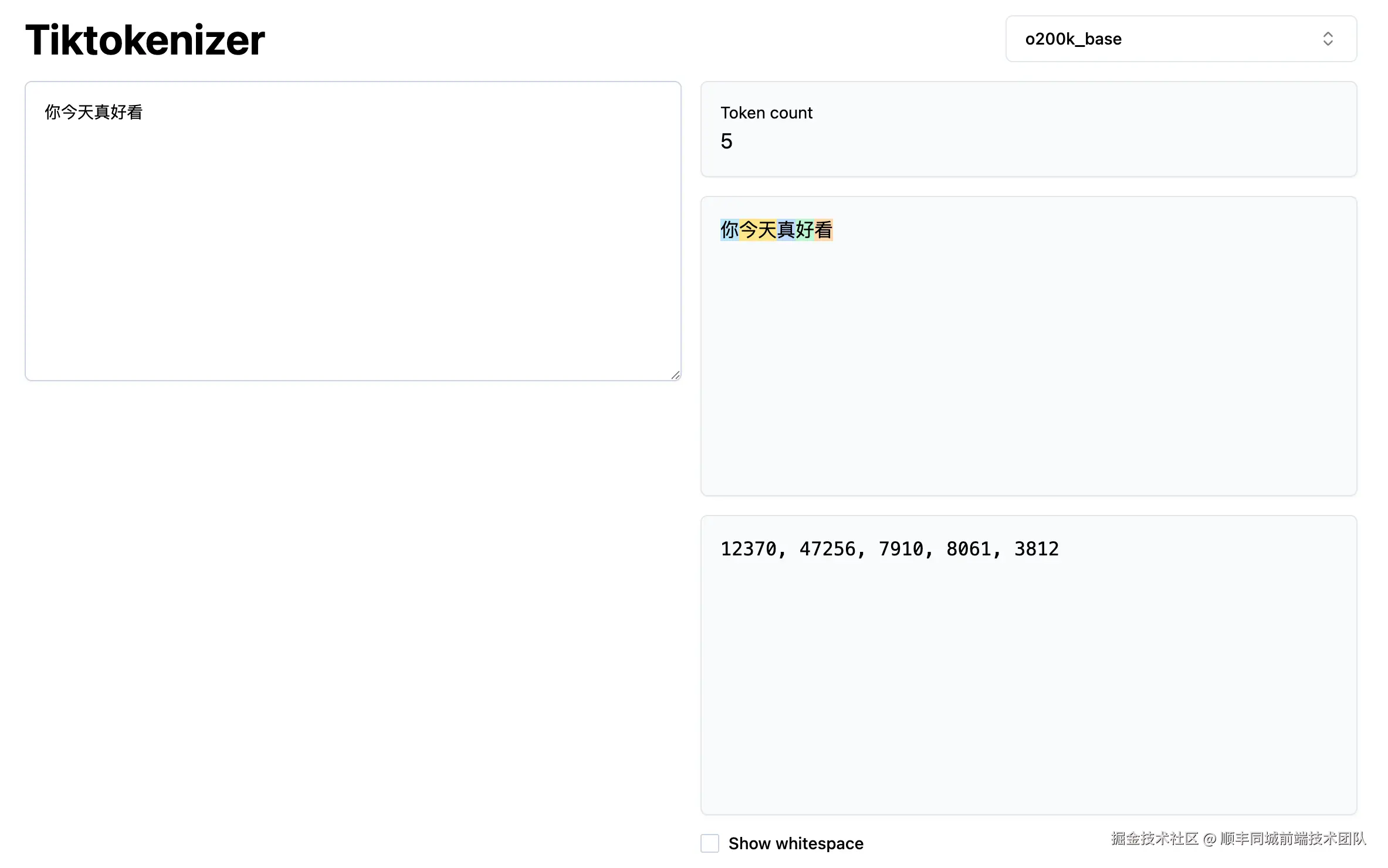 我们不要理解token有具体意义,可以把它理解为
我们不要理解token有具体意义,可以把它理解为 const a = '今天'里的a,它只具有代表意义(数字运算),而不具有实质意义,只有当输出时再根据字典输出时才具有实质的意义。
那么你可能好奇,token从哪来的?
首先,在我们预训练模型时,会先通过白名单的模型,通过爬虫从互联网上搜索了巨量的数据(44tb),尽量删除错误营销、暴力、黄色的内容,而且有语言侧重的数据
举个栗子🌰 我们爬取html文件时,会去除标签,样式,js,只保留文本
html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Document</title>
</head>
<body>
<header>你今天真好看</header>
<section>
<p>Lorem ipsum dolor sit amet consectetur adipisicing elit. Quisquam, quos.</p>
<p>Lorem ipsum dolor sit amet consectetur adipisicing elit. Quisquam, quos.</p>
</section>
</body>
</html>最后保留下来的只有
Document 你今天真好看
Lorem ipsum dolor sit amet consectetur adipisicing elit. Quisquam, quos.
Lorem ipsum dolor sit amet consectetur adipisicing elit. Quisquam, quos.
再通过bpe等分词方法,将单词或汉字转换为数字/向量的形式,并存储为字典表。 这样做的好处,节省大量存储空间而且方便计算概率。
Transformer架构
我祭出了祖传图片 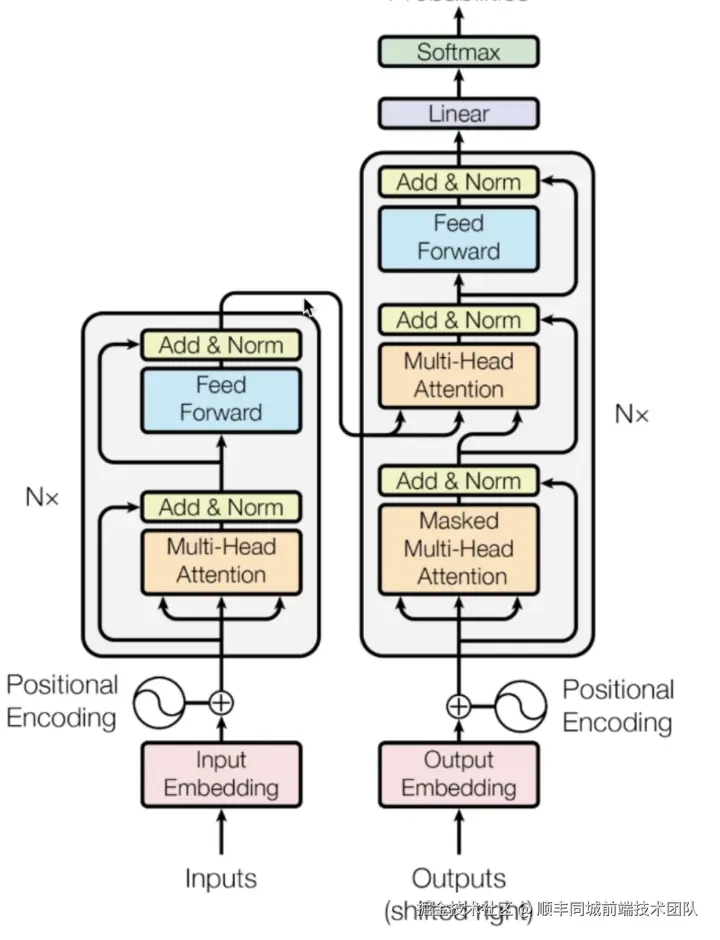
无论你第几次看到这张图,可能都是如下表情

我们可以将他拆分,一点一点看起就会轻松很多
首先砍半,我们先看encoder部分
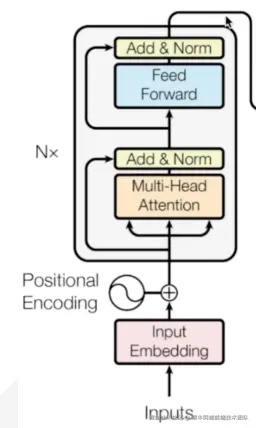
从下往上看,当输入进来时,首先会将文字转换为token/向量,这里是为了节约更多存储空间,也方便运算。但随之我们就发现了问题,我在上海/我在海上,他们token输入后的意义是相近的,位置信息也是我们信息的一部分。所以有了Positional Encoding来绑定token和位置信息。接着我们又发现了问题,我买了一筐苹果/我买了苹果的股票,这里的苹果指代的意义需要通过上下文词的贡献度推理得出,所以有了自注意力机制,这个能在分析每个token时将上下文关联上。
decoder阶段相对于encoder阶段并没有太多的不同,增加了有遮蔽性的上下文,也就是让每次模型生成的token再结合之前的上下文一起进行计算。
总结下来Transformer架构主要做了以下三点

Transformer对比Deepseek-MoE
因为众所周知的原因,国内没有更高级别的显卡
但大模型大模型,突出的就是一个大,如果能在有限的资源内,训练更多的语料数据是不是会更好
让我们聚焦到上文说到的Transformer架构中的Feed Forward层,MoE主要就是对这一层的修改,将传统模型中的稠密模型替换为了MoE中的稀疏模型
稠密模型 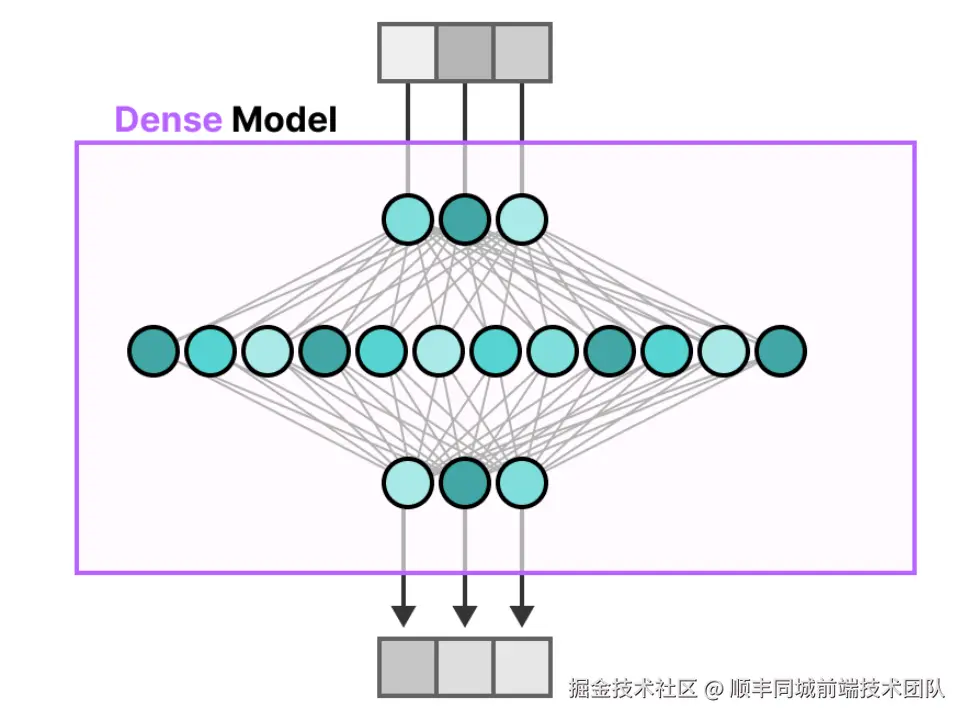
稀疏模型 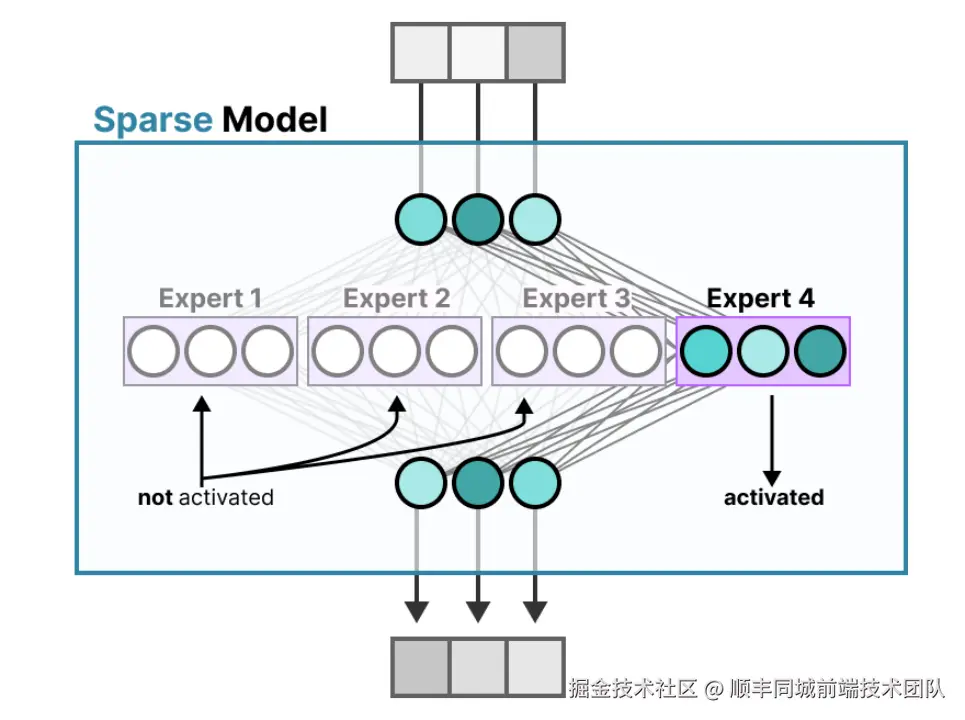
有了以上的模糊概念后,我们可以用大白话详细来看下MoE层的运行机制
假设你开了一家诊所,有 8 个不同科室的医生(专家)。当患者来看病时,前台护士(门控系统)会先问症状,然后把患者分配到最合适的科室(比如发烧去内科,骨折去骨科)。每个科室的医生只处理自己擅长的病例,这样效率更高。
这样做的好处是将原有计算量/(n*(TopK export + Shared Export) 。以此来达到能训练更多语料的前提下,但计算量没有增加。

学习资料