基本设置
python
import torch
from torch import nn
from d2l import torch as d2l
python
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)初始化模型
为什么不直接使用 Tensor 而是用 nn.Parameter 函数将其转换为 parameter呢?
- nn.Parameter 函数会向宿主模型注册参数,从而在参数优化的时候可以自动一起优化。
- 此外,由于内存在硬件中的分配和寻址方式,选择2的若干次幂作为层宽度会使计算更高效。
python
num_inputs, num_outputs, num_hiddens = 784, 10, 256
# 输入层参数
W1 = nn.Parameter(torch.randn(
num_inputs, num_hiddens, requires_grad=True) * 0.01)
b1 = nn.Parameter(torch.zeros(num_hiddens, requires_grad=True))
# 隐藏层参数
W2 = nn.Parameter(torch.randn(
num_hiddens, num_outputs, requires_grad=True) * 0.01)
b2 = nn.Parameter(torch.zeros(num_outputs, requires_grad=True))
params = [W1, b1, W2, b2]激活函数
python
def relu(X): # 自定义 ReLU 函数
a = torch.zeros_like(X)
return torch.max(X, a)模型
由于忽略了空间结构,我们调用 reshape 函数将每个二维图像转换成长度为 num_inputs 的向量
python
def net(X):
X = X.reshape((-1, num_inputs))
H = relu(X @ W1 + b1) # 输入层运算+激活 这里"@"代表矩阵乘法
return (H @ W2 + b2) # 隐藏层运算损失函数
python
loss = nn.CrossEntropyLoss(reduction='none') # 使用交叉熵损失函数训练
python
num_epochs, lr = 10, 0.1
updater = torch.optim.SGD(params, lr=lr) # 优化算法
d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, updater)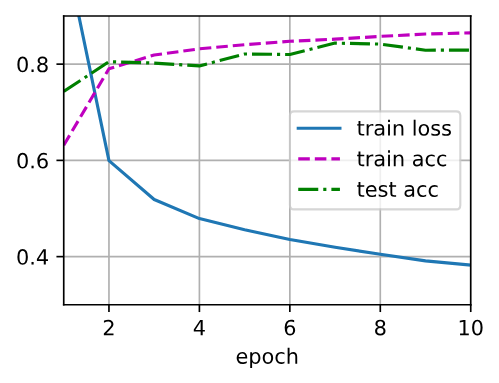
python
d2l.predict_ch3(net, test_iter) # 在一些测试集上运行一下这个模型