第二章主要讲 OceanBase 内存分布、存储原理、合并和转储管理。
2.1 内存管理
OceanBase会占据物理服务器的大部分内存并进行统一管理。
2.1.1 OBServer 整体内存分配
通过参数设定 OBServer 占用的内存上限
- memory_limit
- memory_limit_percentage
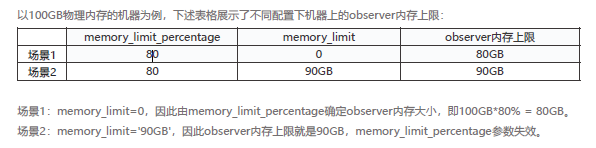
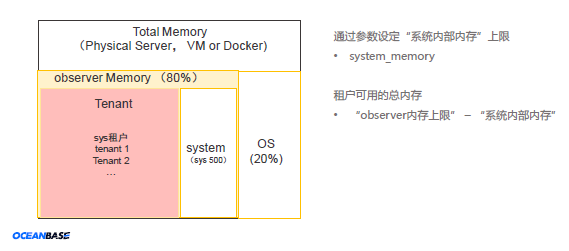
每一个 OBServer 都包含多个租户(sys租户和业务租户)的数据,但 OBServer 的内存并不是全部分配给租户。 OBServer 中有些内存不属于任何租户,属于所有租户共享的资源,称为"系统内部内存"。
系统内部内存可使用的内存上限是通过 system_memory 系统参数配置的,它的含义是系统内部可使用 OceanBase 内存上限。例如,假设OceanBase 内存上限为80 GB, system_memory 的值为8G,可用于租户分配的内存就是剩下80-8=72 GB。
OBServer 整体内存分配示意图
2.1.2 租户内部内存分配
租户内部内存分配示意图
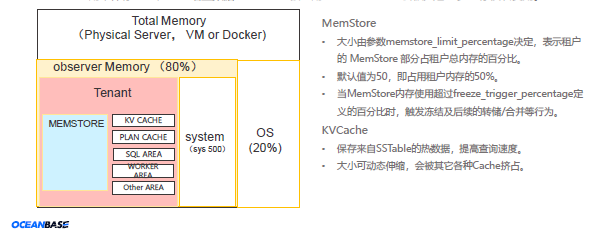
每个租户内部的内存分模块划分,需要关注的主要是包括
- 不可动态伸缩的内存:MemStore
- 可动态伸缩的内存:KVCache
- 执行计划缓存:PLAN CACHE
- 执行 SQL 内存:SQL AREA,主要是 parser 和优化器 使用
- 工作线程内存:WORKER AREA
MemStore用来保存DML产生的增量数据 ,空间不可被占用;KVCache空间会被其它众多内存模块复用。
除去 MemStore 和 KVCache ,其他模块的内存使用大小默认不超过10G。
查看内存使用大于 10G 的其它模块,SQL 样例:
select * from gv$memory where
used > 1024*1024*1024*10
and `context` not in ('OB_MEMSTORE','OB_KVSTORE_CACHE');查看内存占用最大的 10 个模块,SQL 样例
select
`CONTEXT`,
ROUND(USED / 1024 / 1024 / 1024, 2) as USED_GB
from gv$memory
group by `CONTEXT`
ORDER BY USED DESC
limit 10;2.1.3 常见内存问题处理
2.1.3.1 ERROR 4030 (HY000): OB4030: Over tenant memory limits
遇到 Over tenant memory limits 错误时,首先需判断是不是MemStore 内存超限,当MmeStore 内存超限时,需要检查数据写入是否过量或未做限流。当遇到大量写入且数据转储跟不上写入速度的时候就会报这种错误。运行下述语句查看内存状态。
select /*+ READ_CONSISTENCY(WEAK), query_timeout (100000000) */
TENANT_ID,
round(ACTIVE / 1024 / 1024 / 1024, 2) ACTIVE_GB,
round(TOTAL / 1024 / 1024 / 1024, 2) TOTAL_GB,
round(FREEZE_TRIGGER / 1024 / 1024 / 1024, 2) FREEZE_TRIGGER_GB,
round(TOTAL / FREEZE_TRIGGER * 100, 2) percent_trigger,
round(MEM_LIMIT / 1024 / 1024 / 1024, 2) MEM_LIMIT_GB
from
gv$memstore
where
tenant_id > 1000
or TENANT_ID = 1
order by
tenant_id,
TOTAL_GB desc;该问题的紧急应对措施是增加租户内存。问题解决之后需要分析原因,如果是因为未做限流引起,需要加上相应措施,然后回滚之前加上的租户内存动作。如果确实因为业务规模增长导致租户内存不足以支撑业务时,需要根据转储的频度设置合理的租户内存大小。
如 MemStore 内存未超限,判断是 MemStore 之外的哪个 module 占用内存空间最高
select tenant_id, svr_ip, mod_name, sum(hold) module_sum
from __all_virtual_memory_info
where tenant_id > 1000 and hold <> 0
and mod_name not in ('OB_KVSTORE_CACHE', 'OB_MEMSTORE')
group by tenant_id, svr_ip, mod_name
order by module_sum desc;模块内存超限,可能需要先调整单独模块的内存,如
- ob_sql_work_area_percentage (排序、分布式中间结果)
- ob_interm_result_mem_limit (分布式中间结果)
如租户内存过小,也需要加租户内存。
2.1.3.2 500 租户内存超限
tenant_id =500 的租户是 OB 内部租户,简称 500 租户。
500 租户的内存使用量没有被 vmemory 和 gvmemory 统计,需要查询 __all_virtual_memory_info 表。
select * from __all_virtual_memory_info where tenant_id=500;2.1.3.3 OBServer 错误日志 allocmemory 或 allocate memory
报错的原因,通常是系统内存耗尽,或者已经达到了内存使用的上限。
日志样例
...... alloc memory failed ( 4013, size=65536, mem=NULL, label_="OB_SQL_HASH_SET", ctx_id _=
...... oops, alloc failed , tenant_id =1001 ctx_id =9 hold=266338304 limit=268435455
...... allocate memory failed nbyte =213552, operator type="PHY_MULTI_PART_INSERT")处理方式
- 模块内存超限,先调整单独模块的内存
- 租户内存过小,加租户内存
2.2 存储管理
2.2.1 LSM Tree
用一句话来简单描述的话, LSM Tree 就是一个基于归并排序的数据存储思想。
LSM Tree(The Log-Structured Merge-Tree)
- 将某个对象(Partition)中的数据按照 "key-value" 形式在磁盘上有序存储(SSTable);
- 数据更新先记录在MemStore中的MemTable里,然后再合并(Merge)到底层的 ssTable 里;
- SSTable 和 MemTable 之间可以有多级中间数据,同样以key-value 形式保存在磁盘上,逐级向下合并。
SSTable
- SSTable将数据按照主键或者隐含列(不可见)的顺序在磁盘上有序排列,以B+ Tree数据结构实现"key-value"存储。
- 数据被分成2MB的固定大小宏块(Macro Block),每个宏块包含一定key值范围的数据。
- 为了避免读取少量数据时的"读放大",每个宏块内部又分为多个微块(Micro Block),大小一般配为16KB(可变);微块内的记录数和具体的数据特征相关。
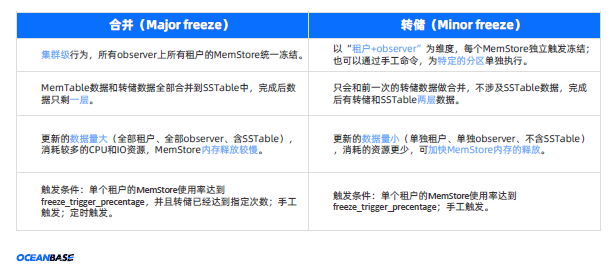
2.2.2 合并
OceanBase 中最简单的 LSM Tree只有C0层(MemTable)和C1层(SSTable)。两层数据的合并过程如下:
- 将所有 OBServer 上的MemTable 数据做大版本冻结(Major Freeze),其余内存作为新的 MemTable 继续使用;
- 将冻结后的 MemTable 数据合并(Merge)到 SSTable 中,形成新的 SSTable,并覆盖旧的 SSTable;
- 合并完成后,冻结的MemTable内存才可以被清空并重新使用。
合并示意图
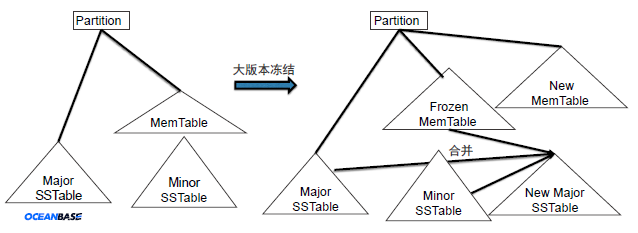
合并操作(Major Freeze)是将动静态数据做归并,也就是产生新的C1层的数据,会比较费时。当转储产生的增量数据积累到一定程度时,通过 Major Freeze 实现大版本的合并。由于在合并的过程中为了保证数据的一致性,就需
要在合并的过程中暂停正在被合并的数据上的事务,这对性能来说是会有影响的,OceanBase 对合并操作进行了细化,分为增量合并,轮转合并和全量合并。
2.3.3 转储
为什么有转储?原因是合并存在一系列问题
- 资源消耗高,对在线业务性能影响较大。
- 单个租户 MemStore 使用率高会触发集群级合并,其它租户成为受害者。
- 合并耗时长,MemStore内存释放不及时,容易造成MemStore满而数据写入失败的情况。
为了解决 2 层 LSM Tree 合并时引发的问题(资源消耗大,内存释放速度慢等),引入了"转储"机制:
- 将 MemTable 数据做小版本冻结(Minor Freeze)后写到磁盘上单独的转储文件里,不与SSTable数据做合并;
- 转储文件写完之后,冻结的 MemTable 内存被清空并重新使用;
- 每次转储会将 MemTable 数据与前一次转储的数据合并(Merge),转储文件最终会合并到 SSTable 中。
转储的设计思路
- 每个 MemStore 触发单独的冻结(freeze_trigger_percentage)及数据合并,不影响其它租户;也可以通过命令为指定指定租户、指定OBServer 、指定分区做转储。
- 只和上一次转储的数据做合并,不和 SSTable 的数据做合并。
转储示意图
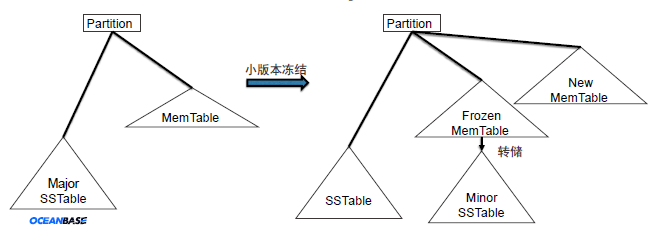
可以看到转储引入了一层 Minor SSTable,其原理是把内存中的增量数据会被以 MemTable 的方式保存在磁盘中。
转储的优势
- 每个租户的转储不影响 OBServer 上其它的租户,也不会触发集群级转储,避免关联影响。•
- 资源消耗小,对在线业务性能影响较低。
- 耗时相对较短,MemStore 更快释放,降低发生 MemStore 写满的概率。
转储的副作用
- 数据层级增多,查询链路变长,查询性能下降。
- 冗余数据增多,占用更多磁盘空间。
2.2.4 合并管理
三种合并触发方式
- 定时合并
- MemStore 使用率达到阈值自动合并
- 手动合并
2.2.4.1 定时合并(每日合并)
定时合并也叫做每日合并,通过系统参数 major_freeze_duty_time 设置每日合并触发时间。
-- 缺省的每日合并时间为凌晨 2:00
-- 查看
show parameters like 'major_freeze_duty_time' \G
-- 设置
alter system set major_freeze_duty_time='02:00'控制每日合并策略相关系统参数
- enable_manual_merge:是否开启手动合并(默认值False);
- enable_merge_by_turn:是否开启自动轮转合并(默认值True);
- zone_merge_order:指定自动轮转合并的合并顺序(默认值NULL);
- major_freeze_duty_time:每日合并触发时间,有效的格式为
HH:SS, 值为 disable****时,不执行每日合并。
2.2.4.2 MemStore 使用率达到阈值合并
当租户的 MemStore 内存使用率达到 freeze_trigger_percentage参数的值, 并且转储的次数已经达到了major_compact_trigger/minor_freeze_times 参数的值,会自动触发合并。
相关 SQL 命令
-- 查看 MemStore
select * from oceanbase.v$memstore;
-- 相关系统参数
alter system set freeze_trigger_percentage = 40;
alter system set major_compat_trigger = 100;
alter system set minor_freeze_times = 100;注意:任意一个租户 的 MemStore 写到一定的比例会后会自行发起集群冻结。
所谓 MemStore ,是指租户申请的内存资源中有多少可以来存放更新数据, 比如一个租户可使用的内存为 8G (建立租户时,Resource Unit 的 min_memory), 系统参数 memstore_limit_percentage 控制有多少内存可以用来存写入的数据(其余的内存会被用作其它用途,比如缓存)。
2.2.4.3 手动合并
手动发起合并 SQL 命令(本质上是发起冻结)
alter system major freeze;注意这个命令是发起 冻结,其执行结果是把集群的冻结版本号 +1,合并是 OceanBase 集群对冻结版本变化的自动响应行为。这个命令可以重复调用,调用几次冻结版本号就增加几,不受当前是否正在合并状态的影响。
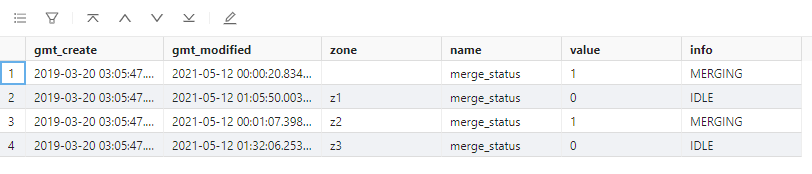
可以通过 __all_Zone 表查看合并状态
select * from __all_zone where name = 'merge_status';结果样例, Zone 为空表示集群的合并状态
2.2.4.5 轮转合并
借助自身天然具备的多副本分布式架构,OceanBase引入了轮转合并机制:
- 一般情况下,OceanBase会有3份(或更多)数据副本;可以轮流为每份副本单独做合并;
- 当一个副本在合并时,这个副本上的业务流量可以暂时切到其它没有合并的副本上;
- 某个副本合并完成后,将流量切回这个副本,然后以类似的方式为下一个副本做合并,直至所有副本完成合并。
轮转合并相关系统参数:
- 通过参数 enable_merge_by_turn 开启或者关闭轮转合并;
- 通过参数 zone_merge_order 设置合并顺序,设置为空表示取消自定义轮转顺序;
- 通过参数 zone_merge_concurrency 设置轮转合并并发度,默认为 3,表示最多有 3 个 Zone 可以一起合并。
关于轮转合并的更多说明
- 以ZONE为单位轮转合并,只有一个ZONE合并完成后才开始下一个ZONE的合并;合并整体时间变长;
- 某一个ZONE的合并开始之前,会将这个ZONE上的Leader服务切换到其它ZONE;切换动作对长事务有影响;
- 由于正在合并的ZONE上没有Leader,避免了合并对在线服务带来的性能影响;
轮转合并性能更友好,非轮转合并也有优势,因为非轮转合并是所有Zone一起进行合并,相对于轮转合并:
- 非轮转合并不做切主操作,而 OceanBase 切主过程会
- 影响长事务执行,比如可能会因此遇到事务超时
- 导致表的自增列 ID 增加自增不长(缺省值为 100W)
- 非轮转合并不受合并并发度的限制
2.2.4.6 其它合并控制系统参数
参数 merge_thread_count 控制合并线程数
- 控制可以同时执行合并的分区个数;单分区暂不支持拆分合并,分区表可以加快合并速度。
- 默认值为0,实际取值为min(10,cpu_cnt * 0.3)。
- 最大取值不要超过48:值太大会占用太多CPU和IO资源,对OBServer 的性能影响较大;而且容易触
- 发系统报警,比如CPU使用率超过90%可能会触发主机报警。
- 如对合并速度没有特殊要求,建议使用默认值0 。
参数 max_kept_major_version_number 控制STable中保留的数据合并版本个数
- 调大参数值可以保留更多历史数据,但同时占用更多的存储空间。
- 在 hint 中利用 frozen_version(<major_version>)指定历史版本。
参数zone_merge_timeout定义超时阈值
- 默认值为'3h'(3个小时)。
- 如果某个ZONE的合并执行超过阈值,合并状态被设置为TIMEOUT。
参数data_disk_usage_limit_percentage定义数据盘空间使用阈值
- 默认值90。
- 当数据盘空间使用量超过阈值后,合并任务打印ERROR警告日志,合并任务失败;需要尽快扩大数据盘物理空间,并调大data_disk_usage_limit_percentage参数的值。
- 当数据盘空间使用量超过阈值后,禁止数据迁入。
2.2.4.7 ✨查看 Zone 合并记录和状态
通过 __all_rootservice_event_history 表,查看合并记录 SQL 样例:
select * from __all_rootservice_event_history where module = 'daily_merge' limit 100 ;通过 __all_Zone 表查看合并状态。__all_Zone 表是类似 key/value 的设计。行转列查看每个 Zone 合并详情 SQL 样例:
SELECT `zone`,
MAX(CASE `name` WHEN 'region' THEN `info` ELSE '' END ) `region`,
MAX(CASE `name` WHEN 'idc' THEN `info` ELSE '' END ) `idc`,
MAX(CASE `name` WHEN 'status' THEN `info` ELSE '' END ) `status`,
MAX(CASE `name` WHEN 'merge_status' THEN `info` ELSE '' END ) `merge_status`,
MAX(CASE `name` WHEN 'broadcast_version' THEN `value` ELSE 0 END ) `broadcast_version`,
MAX(CASE `name` WHEN 'all_merged_version' THEN `value` ELSE 0 END ) `all_merged_version`,
MAX(CASE `name` WHEN 'last_merged_version' THEN `value` ELSE 0 END ) `last_merged_version`,
MAX(CASE `name` WHEN 'merge_start_time' THEN `value` ELSE 0 END ) `merge_start_time`,
MAX(CASE `name` WHEN 'last_merged_time' THEN `value` ELSE 0 END ) `last_merged_time`,
MAX(CASE `name` WHEN 'is_merge_timeout' THEN `value` ELSE 0 END ) `merge_timeout`
FROM oceanbase.__all_zone WHERE `zone` <> '' GROUP BY `zone`;Zone 相关信息
- all_merged_version 表示本 Zone 最近一次已经合并完成的版本
- broadcast_version 表示本 Zone 收到的可以进行合并的版本
- is_merge_timeout 如果在一段时间还没有合并完成,则将此字段置为 1 ,表示合并时间太长
- 具体时间可以通过系统参数 zone_merge_timeout 来控制
- merge_start_time / last_merged_time 分别表示合并开始、结束时间
- last_merged_version 表示本 Zone 最近一次合并完成的版本
- merge_status 表示本 Zone 的合并状态,取值有:IDLE/MERGING/TIMEOUT/ERROR
- suspend_merging 表示是否暂停合并,有时候因为合并造成压力过大或其它原因,我们想暂停合并
- 通过 alter system suspend merge 来暂停合并
- 通过 alter system resume merge 来恢复合并
Zone 为空时表示整个集群的状态,查看集群合并详情 SQL 样例
SELECT
MAX(CASE `name` WHEN 'cluster' THEN `info` ELSE '' END ) `cluster`,
MAX(CASE `name` WHEN 'merge_status' THEN `info` ELSE '' END ) `merge_status`,
MAX(CASE `name` WHEN 'global_broadcast_version' THEN `value` ELSE 0 END ) `global_broadcast_version`,
MAX(CASE `name` WHEN 'frozen_version' THEN `value` ELSE 0 END ) `frozen_version`,
MAX(CASE `name` WHEN 'last_merged_version' THEN `value` ELSE 0 END ) `last_merged_version`,
MAX(CASE `name` WHEN 'frozen_time' THEN `value` ELSE 0 END ) `frozen_time`,
MAX(CASE `name` WHEN 'is_merge_error' THEN `value` ELSE 0 END ) `merge_error`
FROM oceanbase.__all_zone WHERE `zone` = '';全局信息:
- frozen_time 表示冻结时间,在上面的例子里,这个值为0,说明系统还没有发生过冻结。
- frozen_version 表示版本号,从1开始。
- global_broadcast_version 表示这个版本已经通过各ObServer进行合并。
- is_merge_error 表示合并过程中是否出现错误。1表示合并遇到了问题,这种情况一般需要手工处理。
- last_merged_version 表示上次合并完成的版本。
- try_frozen_version 表示正在进行哪个版本的冻结,如果 try_frozen_version 和
- frozne_version 相等,则表示该版本已经完成冻结。
- merge_list 表示 ZONE 的合并顺序。
2.2.4.9 ✨查看 OBServer 合并状态
通过 __all_virtual_Partition_sstable_image_info 表查看 OBServer 合并状态
SELECT /*+read_consistency(weak) QUERY_TIMEOUT(60000000) */
zone, svr_ip, svr_port, major_version AS `version`,
merge_start_time AS start_time, merge_finish_time AS finish_time
FROM oceanbase.__all_virtual_partition_sstable_image_info
ORDER BY zone,svr_ip, svr_port, major_version一般的, __all_virtual_Partition_sstable_image_info 表会保存2个冻结版本号的统计信息,如果 start time 不为 null, 而 end_time 列为 null,表示 OBServer 的合并尚未完成。
2.2.6 转储管理
2.2.6.1 转储相关系统参数
major_compact_trigger /minor_freeze_times
• 控制两次合并之间的转储次数,达到此次数则自动触发合并(Major Freeze)。
• 设置为0表示关闭转储,即每次租户MemStore使用率达到冻结阈值(freeze_trigger_percentage)
都直接触发集群合并。
minor_merge_concurrency
• 并发做转储的分区个数;单个分区暂时不支持拆分转储,分区表可加快速度。
• 并发转储的分区过少,会影响转储的性能和效果(比如MemStore内存释放不够快)。
• 并发转储的分区过多,同样会消耗过多资源,影响在线交易的性能。
2.2.6.2 转储适用场景
转储功能比较适用于以下场景
- 批处理、大量数据导入等场景,写MemStore的速度很快,需要MemStore内存尽快释放。
- 业务峰值交易量大,写入MemStore的数据很多,但又不想在峰值时段触发合并(Major Freeze),
- 希望能将合并延后。
转储场景的常用配置方法
- 减小 freeze_trigger_percentage的值(比如40)
- 使MemStore尽早释放,进一步降低MemStore 写满的概率。
- 增大major_compact_trigger /minor_freeze_times的值
- 尽量避免峰值交易时段触发合并(Major Freeze),将合并的时机延后到交易低谷时段的每日合并(major_freeze_duty_time)。
2.2.6.3 手动触发转储
手动触发转储命令语法
ALTER SYSTEM MINOR FREEZE
[{TENANT[=] ('tt1' [, 'tt2'...]) | PARTITION_ID [=] 'partidx%partcount@tableid'}]
[SERVER [=] ('ip:port' [, 'ip:port'...])];几个可选的控制参数
- tenant : 指定要执行minor freeze的租户
- Partition_id : 指定要执行minor freeze的Partition
- Server : 指定要执行minor freeze的OBServer
当什么选项都不指定时,默认对所有OBServer 上的所有租户执行转储。
手动触发的转储次数不受参数minor_freeze_times的限制,即手动触发的转储次数即使超过设置的
次数,也不会触发合并(Major Freeze)。
2.2.6.4 ✨查看转储记录和状态
通过 __all_rootservice_event_history 查看转储记录
SELECT * from __all_rootservice_event_history
where event = 'root_minor_freeze' limit 10;通过 gv$memstore 查看上一次合并之后到现在为止租户转储次数
-- 注意这里排除了 500 租户,500 租户的 MEM_LIMIT 是无限制的
select
tenant_id,
concat(ip, port) as server,
freeze_cnt as freeze_count,
round(ACTIVE/1024/1024/1024, 2) as ACTIVE_GB,
round(TOTAL/1024/1024/1024, 2) as TOTAL_GB,
round(MEM_LIMIT/1024/1024/1024, 2) as LIMIT_GB
from gv$memstore
where tenant_id <> 500
order by freeze_count desc;2.2.7 合并与转储对比