要理解 FlatBuffers 为什么比 Protobuf 快,我们可以从数据存储方式 和使用流程两个核心角度来通俗解释:
数据存储方式对比:像 "压缩包" vs "货架商品"
1. Protobuf 的 "压缩包" 式存储

plaintext
[字段1标记(类型+长度)] [字段1值] [字段2标记] [字段2值] ... [字段N标记] [字段N值]- 特点:字段按顺序紧凑排列,每个字段前都有 "标记"(类似快递包裹上的面单,写着 "里面是什么、有多大")。
- 读取场景 :比如要读 "字段 3",必须先拆前面的包裹:
→ 先读字段 1 的标记→算字段 1 值的位置→跳过字段 1→读字段 2 的标记→算字段 2 值的位置→跳过字段 2→才能找到字段 3 的值。
(就像拆快递时,必须按顺序拆完前两个包裹,才能拿到第三个)
2. FlatBuffers 的 "货架商品" 式存储

plaintext
[索引表(vtable)] → 记录每个字段的位置:字段1在偏移量100,字段2在偏移量200...
[字段1值](地址100)
[字段2值](地址200)
...
[字段N值](地址N00) - 特点:字段像货架上的商品,每个都有固定 "货架号"(地址),索引表就是 "商品目录",直接写着每个商品的位置。
- 读取场景 :读 "字段 3" 时,直接查索引表→找到地址 300→直接去地址 300 拿值,完全不用管前面的字段。
(就像去超市买可乐,直接看目录找货架号,直奔目标,不用逛完整个超市)
数据处理流程对比:"直接用" vs "复制后用"
1. Protobuf 的处理流程(想象成 "搬家")
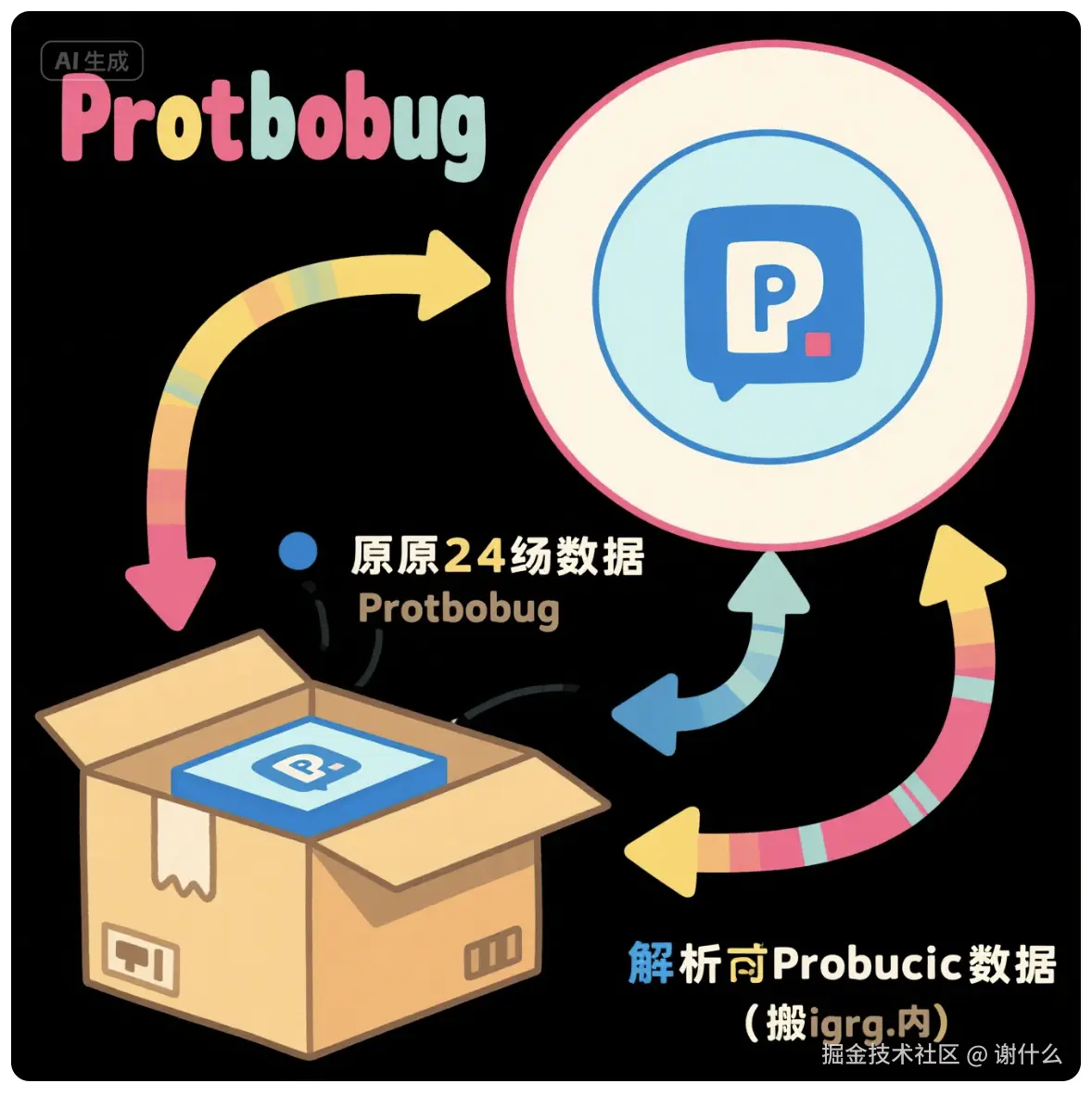
plaintext
原始二进制数据 → 解析时,把数据"搬"到Protobuf对象里(复制) → 通过对象.getXXX() 拿数据 - 就像你网购了一批零食(原始数据),必须先从快递箱(二进制)里拿出来,逐个放到零食盒(对象)里,想吃的时候再从盒子里拿 ------ 多了 "搬家"(复制)这一步。
2. FlatBuffers 的处理流程(想象成 "直接开吃")
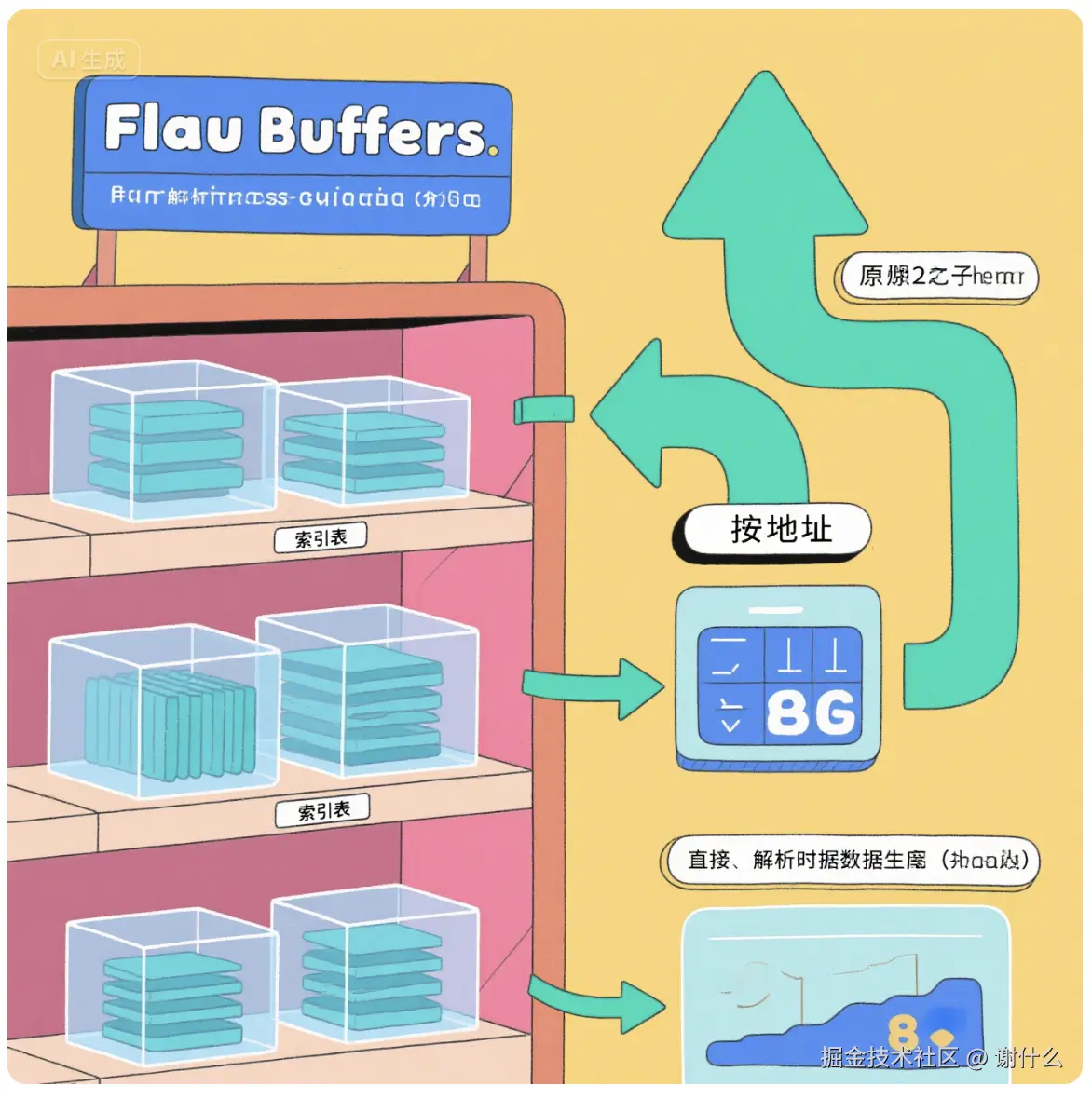
plaintext
原始二进制数据 → 解析时,生成"索引表"(画地图) → 直接从原始数据里"按地址"拿值 - 就像零食直接摆在透明贩卖机上(原始数据),给你一张货架地图(索引表),想吃哪个直接按地图坐标伸手拿,不用拆包装、不用搬家 ------ 少了所有额外步骤。
关键差异总结图
| 操作 | Protobuf | FlatBuffers |
|---|---|---|
| 读字段 | 按顺序解析所有前置字段 | 直接查索引表定位地址 |
| 数据复制 | 需要复制到对象(有开销) | 直接操作原始数据(无复制) |
| 速度关键 | 解析顺序依赖 + 复制开销 | 随机访问 + 零复制 |
通过这两个场景的对比,应该能更直观地理解:FlatBuffers 的 "随机访问" 和 "零复制" 特性,让它在读取效率上远超需要 "顺序解析" 和 "数据复制" 的 Protobuf~