计算机网络:(九)网络层(下)超详细讲解互联网的路由选择协议、IPV6与IP多播
- 前言
- 一、互联网的路由选择协议
-
- [1. 什么是"路由"?](#1. 什么是“路由”?)
- [2. 理想的路由算法](#2. 理想的路由算法)
- [3. 为什么"最佳路由"没有标准答案?](#3. 为什么“最佳路由”没有标准答案?)
- [4. 路由算法怎么应对网络变化?两种策略](#4. 路由算法怎么应对网络变化?两种策略)
-
- [(1) 静态路由选择(手动设定的固定路线)](#(1) 静态路由选择(手动设定的固定路线))
- (2)动态路由选择(能自动改道的智能导航)
- [二、内部网关协议 RIP](#二、内部网关协议 RIP)
-
- [1. 为什么网络需要分层管理?](#1. 为什么网络需要分层管理?)
- 2.什么是自治系统(AS)?
- [3. 内部网关协议RIP](#3. 内部网关协议RIP)
-
- (1)RIP怎么判断好路线?看"跳数"
- (2)RIP怎么交换路线信息?
- [(3) 路由表更新:怎么根据邻居的信息改路线?](#(3) 路由表更新:怎么根据邻居的信息改路线?)
- [4. RIP的问题](#4. RIP的问题)
-
- [1. 好消息:新通路马上传开](#1. 好消息:新通路马上传开)
- [2. 坏消息:断路了,大家反应慢](#2. 坏消息:断路了,大家反应慢)
- [5. RIP的优缺点与适合什么样的网络?](#5. RIP的优缺点与适合什么样的网络?)
- [三、内部网关协议 OSPF](#三、内部网关协议 OSPF)
-
- [1. 为什么需要OSPF?](#1. 为什么需要OSPF?)
- [2. OSPF的核心逻辑(共享地图)](#2. OSPF的核心逻辑(共享地图))
-
- [(1) 什么是"链路状态"?](#(1) 什么是“链路状态”?)
- [(2) 洪泛法:让"路况"传遍全网](#(2) 洪泛法:让“路况”传遍全网)
- [3. 链路状态数据库(全网共用一张地图)](#3. 链路状态数据库(全网共用一张地图))
- [4. 区域划分:给大网络"分片区"管理](#4. 区域划分:给大网络“分片区”管理)
- [5. OSPF的传输方式:直接发IP包,简单可靠](#5. OSPF的传输方式:直接发IP包,简单可靠)
- 6.OSPF的五种消息类型
- [7. OSPF的其他能力](#7. OSPF的其他能力)
- [8. OSPF vs RIP:](#8. OSPF vs RIP:)
- [四、外部网关协议 BGP](#四、外部网关协议 BGP)
-
- [1. 为什么AS之间需要专门的BGP协议?](#1. 为什么AS之间需要专门的BGP协议?)
- [2. BGP的核心任务:找到"可达且合适"的跨AS路径](#2. BGP的核心任务:找到“可达且合适”的跨AS路径)
- [3. BGP怎么工作?](#3. BGP怎么工作?)
-
- (1)BGP发言人:
- [2. 用TCP建立"专线电话"](#2. 用TCP建立“专线电话”)
- 4、BGP的"路径向量":
- [6. BGP交换信息的特点:](#6. BGP交换信息的特点:)
-
- [1. 只交换必要的路由信息](#1. 只交换必要的路由信息)
- [2. 路由选择靠"策略"而非"技术指标"](#2. 路由选择靠“策略”而非“技术指标”)
- [7. BGP的四种报文类型](#7. BGP的四种报文类型)
- [8. BGP和内部协议(RIP/OSPF)的核心区别](#8. BGP和内部协议(RIP/OSPF)的核心区别)
- 五、路由器的构成
-
- [1. 路由器到底是干什么的?](#1. 路由器到底是干什么的?)
- 2.路由器的两大部分协同工作
-
- (1)路由选择部分:路由器的控制中心
- [(2) 分组转发部分:路由器的执行部门](#(2) 分组转发部分:路由器的执行部门)
-
- 2.1输入端口:"收货窗口"
- [2.2 交换结构:"传送带"](#2.2 交换结构:“传送带”)
- [2.3 输出端口:"发货窗口"](#2.3 输出端口:“发货窗口”)
- [3. "转发"和"路由选择"不是一回事](#3. “转发”和“路由选择”不是一回事)
- [4. 数据分组在路由器里的流程](#4. 数据分组在路由器里的流程)
- [5. 为什么会丢包?](#5. 为什么会丢包?)
- [6. 交换结构:路由器的传送带的三种设计](#6. 交换结构:路由器的传送带的三种设计)
-
- (1)通过存储器交换:"先存再取"
- [(2) 通过总线交换:"共用一条传送带"](#(2) 通过总线交换:“共用一条传送带”)
- [(3) 纵横交换结构:"立交桥式交换"](#(3) 纵横交换结构:“立交桥式交换”)
- 六、IPV6
-
- [1. 为什么需要IPv6?](#1. 为什么需要IPv6?)
- [2. IPv6的基本首部:](#2. IPv6的基本首部:)
- [3. IPv6的地址](#3. IPv6的地址)
-
- [(1) IPv6地址长什么样?](#(1) IPv6地址长什么样?)
- [(2) IPv6地址的类型:三种"通信方式"](#(2) IPv6地址的类型:三种“通信方式”)
- [(3) 特别的"本地地址"](#(3) 特别的“本地地址”)
- [4. 从IPv4向IPv6过渡](#4. 从IPv4向IPv6过渡)
-
- [1. 双栈技术](#1. 双栈技术)
- [2. 隧道技术](#2. 隧道技术)
- [3. NAT64](#3. NAT64)
- [5. ICMPv6:IPv6的"助手协议"](#5. ICMPv6:IPv6的“助手协议”)
- [七、IP 多播](#七、IP 多播)
-
- [1. 什么是IP多播?](#1. 什么是IP多播?)
- 2.在局域网上进行硬件多播
-
- [1. 多播MAC地址:给多播数据贴"专属标签"](#1. 多播MAC地址:给多播数据贴“专属标签”)
- [2. 交换机如何处理多播数据?](#2. 交换机如何处理多播数据?)
- [4. 网际组管理协议IGMP](#4. 网际组管理协议IGMP)
-
- [(1) 加入多播组:"我要进群"](#(1) 加入多播组:“我要进群”)
- (2)维持成员关系"
- [(3) 退出多播组](#(3) 退出多播组)
- [5. 多播路由选择协议](#5. 多播路由选择协议)
前言
-
前面我们讲解了计算机网络中网络层的相关知识,包括网络层转发分组的过程、网际控制报文协议(ICMP),以及网络层的重要概念和网际协议(IP)。
-
接下来,我们继续讲解计算机网络中网络层的其他知识。
我的个人主页,欢迎来阅读我的其他文章
https://blog.csdn.net/2402_83322742?spm=1011.2415.3001.5343我的计算机网络专栏,欢迎来阅读
https://blog.csdn.net/2402_83322742/category_12909527.html
一、互联网的路由选择协议
1. 什么是"路由"?
-
想象你要从家寄一封信到外地朋友家,信件会经过邮局、中转站,最终到达目的地。

-
在互联网中,当你发送一条消息(比如微信消息、邮件),数据也需要类似的"导航",找到从源设备到目标设备的路径------这就是"路由"的作用。
而"路由选择协议",就是给网络设备(比如路由器)制定的一套"导航规则",让它们知道该怎么选择数据传输的路径。
2. 理想的路由算法
就像我们希望导航软件好用一样,理想的路由算法也有几个标准:

-
正确又完整:最基本的要求。就像导航不能把你导到沟里,路由算法必须保证数据能准确到达目的地,不能丢包或绕错路。
-
计算简单:如果导航软件每次规划路线都要卡10分钟,你肯定不会用。路由算法也一样,不能太复杂,否则会拖慢网络速度。
-
能适应变化(自适应性):比如前方路段突然堵车,导航会立刻重新规划路线。好的路由算法也能根据网络状态(比如某条线路突然断了、流量太大)自动调整路径。
-
稳定:不会频繁、无规律地改变路径。就像导航不能一会儿让你左转,下一秒又让你右转,否则数据会在网络里"晕头转向"。
-
公平:不能只照顾某一部分数据。比如不能让视频数据一直霸占快车道,而文字消息总是被挤到慢车道。
-
尽量最佳:在当时的条件下,选一条最适合的路。注意这里的"最佳"不是绝对的,后面会详细说。
3. 为什么"最佳路由"没有标准答案?
你可能会想:"直接选最短的路不就行了?"但网络里的"最佳"没这么简单:
- 网络里的"距离"不只是物理长度,还可能考虑带宽(就像马路宽度)、延迟(数据传输的时间)、线路负载(是否拥堵)等。
- 网络状态是随时变化的:比如某条线路突然出故障、用户突然大量下载东西导致拥堵,这些情况往往没法提前预测。
- 路由选择是所有设备共同协作的结果,单个设备的"最佳选择"可能不是整个网络的最佳选择。
所以"最佳路由"其实是"相对最佳"------根据具体需求(比如优先快还是优先稳)选一条最合适的路。
4. 路由算法怎么应对网络变化?两种策略
网络状态总在变(比如突然多了很多设备联网,或者某根网线断了),路由算法应对变化的方式有两种:
(1) 静态路由选择(手动设定的固定路线)
特点:
就像你每天上班上学都走同一条固定路线,不管路上有没有堵车。静态路由是人工提前设置好的路径,网络设备会一直按这个路径转发数据,不会自己改。
优缺点:
- 优点:简单好操作,几乎不消耗网络资源(就像记死一条路不用费脑子)。
- 缺点:不能适应变化。如果固定路线突然断了,数据就会"迷路",必须人工重新设置。
适用场景:
适合小网络,比如家里或小公司(设备少、线路稳定,很少出意外)。
(2)动态路由选择(能自动改道的智能导航)
特点:
- 类似手机导航的实时规划功能。
- 路由器会通过"路由选择协议",定期和其他路由器交换信息(比如"我这边到A地很快""B线路堵了"),自动更新路径。
优缺点:
- 优点:灵活,能及时应对网络变化(比如某条线路断了,立刻换另一条)。
- 缺点:复杂,需要路由器不断交换信息,会消耗一定的网络资源(就像导航要一直联网更新路况)。
适用场景:
适合大网络,比如城市级、国家级的网络(设备多、线路复杂,变化频繁)。
二、内部网关协议 RIP
1. 为什么网络需要分层管理?
- 想象一下,如果全世界的快递都由一家公司管理,一旦出问题就会瘫痪。
- 互联网也是如此------全球网络太庞大了,必须分而治之。
- 这就像一个国家分为省、市、县,每层有自己的管理规则,互联网的"分层路由协议"就是这个道理。
互联网的分层管理有三个特点:
- 自适应:网络出问题能自动调整(比如某条线路断了,自动换路)
- 分布式:没有"总指挥",每个路由器自己判断路线,同时和邻居沟通
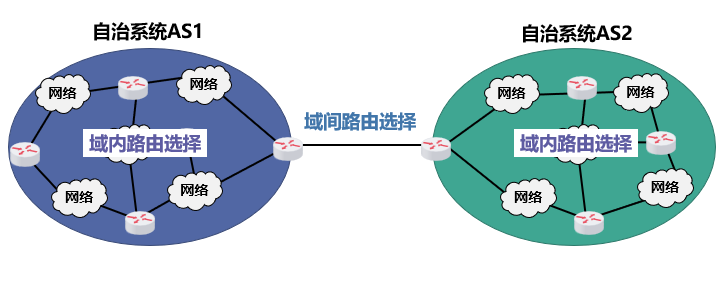
- 分层次:划分为"自治系统(AS)",就像不同的"快递片区",片区内和片区外用不同规则
2.什么是自治系统(AS)?
我们可以把AS理解为"网络里的独立王国":
- 每个AS是由一组路由器组成的"小团体",有自己的管理者(比如一家公司、一个学校的网络)
- 团体内用"内部规则"(内部网关协议)送信,团体间用"外交规则"(外部网关协议)通信
- 比如:中国移动的网络是一个AS,中国联通的网络是另一个AS,它们内部各有一套路由规则,但之间也有合作的通信规则
关键是:不管AS内部多复杂,对外都像一个"统一的整体"。就像一家公司,部门再多,对外只有一个联系方式。
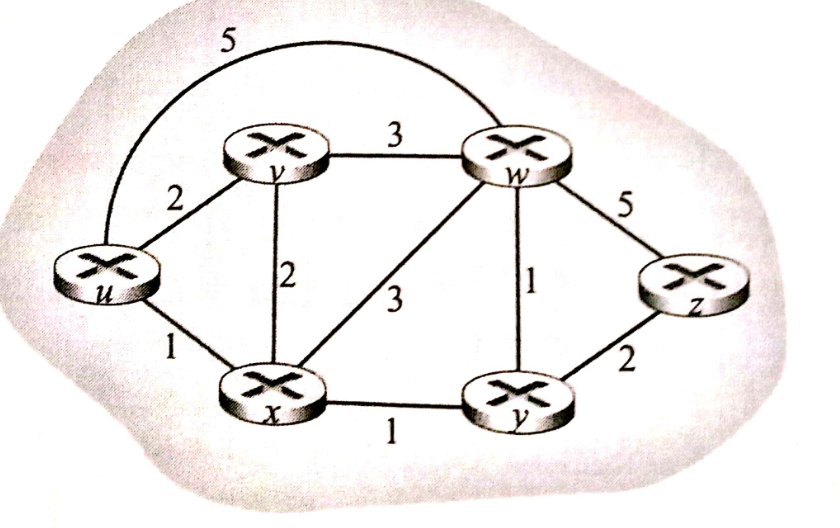
3. 内部网关协议RIP
RIP是最经典的"内部规则"之一,就像AS内部的"导航软件"。
(1)RIP怎么判断好路线?看"跳数"
RIP眼里的"最佳路线"很简单:谁经过的路由器少,谁就好。这里的"经过路由器数量"叫"跳数"。
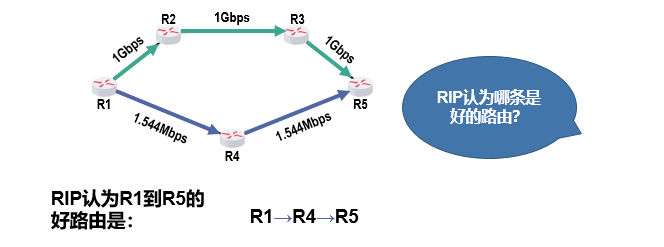
比如:
- 路线A:经过2个路由器(跳数2)
- 路线B:经过5个路由器(跳数5)
不管路线B的带宽多快,RIP一定选路线A------就像导航只看"经过几个红绿灯",不看马路宽窄。
(2)RIP怎么交换路线信息?
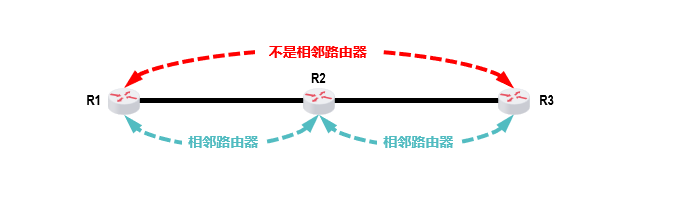
RIP的工作方式很像邻居间互相通报路况:
- 只和隔壁路由器聊:比如你家只和左右邻居交流,不跟小区外的人直接聊
- 聊啥内容:自己知道的所有路线(完整路由表),比如"我到A地要3跳,走XX路"
- 啥时候聊 :
- 定期聊:每30秒跟邻居报一次路况
- 突发情况立刻聊:比如发现某条路断了,马上通知邻居
(3) 路由表更新:怎么根据邻居的信息改路线?
举个生活化的例子:
- 假设你(路由器A)原来知道到"Net6"需要8跳,走F路线。
- 有一天邻居C告诉你:"我到Net6只要4跳"。
- 你一算:从你到C是1跳,加上C到Net6的4跳,总共5跳------比原来的8跳近!
- 于是你就把到Net6的路线改成"经过C,5跳"。
这就是路由表更新的核心逻辑:谁给的路线更近(跳数更少),就用谁的。
4. RIP的问题
1. 好消息:新通路马上传开
比如突然开通了一条更近的路,路由器们会像传八卦一样,很快全知道了。
- 路由器R1发现到"网1"只要1跳(直接到)
- 邻居R2一听,立刻更新自己的路线:"我到网1要2跳(经R1)"
- 很快,所有路由器都知道了这条近路
2. 坏消息:断路了,大家反应慢
但如果一条路断了,麻烦就来了:
- 假设R1到"网1"的路断了,但R2还记着"经R1到网1要2跳"
- R3问R2:"到网1怎么走?" R2说:"经我到R1,总共3跳"
- R1又问R3:"到网1怎么走?" R3说:"经我到R2,总共4跳"
- 这样互相"忽悠",要过好几分钟才能让所有路由器知道"网1断了"
这就是"坏消息传播得慢",就像一群人传错话,要很久才能纠正过来。
5. RIP的优缺点与适合什么样的网络?
优点:简单好上手
- 就像用计算器算加减乘除,逻辑简单,路由器不用费太多劲就能运行
- 对小网络来说,足够用了
缺点:规模小、效率低
- 最多15跳:超过15个路由器的路,RIP就认为"太远了,到不了"(16跳=不可达)。所以大型网络(比如全国性网络)用不了
- 信息太多:路由器之间要交换完整的路由表,网络大了之后,就像每天都要群发几百页的通讯录,太耗资源
- 坏消息反应慢:出问题时,整个网络要等很久才能恢复正常
三、内部网关协议 OSPF
1. 为什么需要OSPF?
前面我们知道,RIP协议像个"一根筋"的导航:只认"跳数"(经过的路由器数量),最大支持15跳,而且坏消息传播得慢。
- 但随着网络规模扩大(比如校园网、企业大网),
-
- RIP就不够用了------这就像用自行车导航来规划跨城市路线,效率太低。
于是,OSPF(开放最短路径优先)应运而生。它就像升级后的智能导航,能解决RIP的很多问题,适合更大规模的网络。
2. OSPF的核心逻辑(共享地图)
(1) 什么是"链路状态"?
RIP会把自己的完整路由表发给邻居,而OSPF更"聪明":每个路由器只分享自己直接连接的链路状态。
- 链路状态="我身边的路况":包括"和我直接相连的路由器是谁""这条链路的代价是多少"。
- "代价"怎么算? 不是固定的跳数,而是综合了带宽、距离、延迟等(比如带宽越高,代价越低)。举个例子:
- 100Mbps的网线,代价=100÷100=1
- 10Mbps的网线,代价=100÷10=10
显然,OSPF会优先选代价低(带宽高)的路线,比RIP只看跳数合理多了。
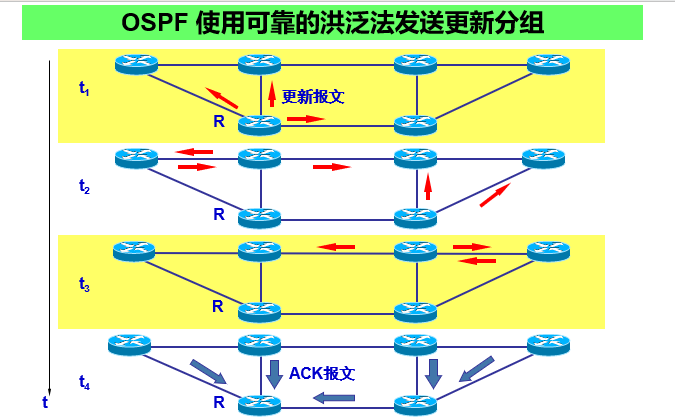
(2) 洪泛法:让"路况"传遍全网
OSPF的信息传播方式叫"洪泛法",就像小区里有人发现路坏了,挨家挨户通知:
- 每个路由器收到"链路状态"信息后,会立刻转发给所有邻居(除了发来信息的那个),直到全网都知道。
- 只在链路状态变化时才广播(比如新路开通、旧路断掉),平时不瞎折腾,比RIP每隔30秒发一次完整路由表省多了。
3. 链路状态数据库(全网共用一张地图)
所有路由器通过洪泛法交换信息后,会形成一个 全网统一的"地图",这就是"链路状态数据库"。
- 这张地图包含整个网络的拓扑结构(谁和谁相连,链路代价多少),而且所有路由器的地图完全一致(称为"同步")。
就像小区里每户人家都有一张实时更新的小区地图,哪条路堵了、哪条路修好了,所有人的地图同时更新------这就是OSPF"收敛快"的秘密(网络出问题后,几秒内就能让所有路由器知道)。
4. 区域划分:给大网络"分片区"管理
OSPF能管好大规模网络,关键在于"区域划分",就像把一个大城市分成多个区:
- 每个自治系统(AS)可以分成多个"区域",每个区域有自己的编号(类似小区编号)。
- 单个区域里的路由器最好不超过200个(太多了信息交换会乱)。
- 好处:区域内的路由器只需要知道本区域的详细地图,跨区域的路由信息由"区域边界路由器"统一处理,减少了信息传输量。
比如:北京的网络分成"海淀区域""朝阳区域",海淀区的路由器不用知道朝阳每条小路的细节,只需知道去朝阳的总入口就行。
5. OSPF的传输方式:直接发IP包,简单可靠
- RIP用UDP协议传信息,而OSPF更直接:直接打包成IP数据报发送,不用中间商。
- 为什么这样更好?OSPF的报文都很短(就像发短消息),不容易丢失;就算丢了,重传也方便。而长报文(像长邮件)容易被拆成多个片段,丢一个片段就得重传整个报文,效率低。
6.OSPF的五种消息类型
OSPF定义了五种分组(可以理解为五种"消息类型"),让路由器之间能顺畅沟通:
| 分组类型 | 功能类比(邻里沟通版) |
|---|---|
| 问候(Hello) | 每天跟邻居打招呼:"嘿,你在吗?"------确认对方在线 |
| 数据库描述 | 跟邻居说:"我有这些地图信息(摘要)" |
| 链路状态请求 | 对邻居说:"你刚才说的那条路,能告诉我细节吗?" |
| 链路状态更新 | 广播消息:"大家注意!XX路刚修好了,代价是2!" |
| 链路状态确认 | 收到消息后回复:"收到你的更新了,谢谢!" |
7. OSPF的其他能力
-
支持"差异化路由":就像马路上有快车道(给视频通话)、慢车道(给文字消息),OSPF能根据数据类型(比如视频需要高速,文字可以普通)选择不同代价的链路。
-
负载平衡:如果两条路代价一样(比如都是3),OSPF会让数据"分两路走",避免一条路拥堵(就像两辆车走平行的两条路,同时到达)。
-
更安全:自带"身份验证"功能,防止陌生路由器乱发假消息(就像小区只认住户的门禁卡)。
-
适配灵活网络:支持可变长子网(VLSM)和无分类编址(CIDR),不管网络怎么划分,都能准确识别地址。
8. OSPF vs RIP:
- RIP像"自行车导航":简单、适合小地方(最多15跳),但功能弱、反应慢。
- OSPF像"汽车导航":智能、适合大城市(无跳数限制),能实时更新路况、选最优路线,但实现稍复杂。
所以,小规模网络用RIP够了,而企业网、校园网等大规模网络,几乎都会选OSPF------因为它更可靠、更高效,能应对复杂的网络环境。
四、外部网关协议 BGP
前面我们讲了OSPF,它解决的是一个"门派"(自治系统AS)内部的路由问题,就像门派内弟子之间怎么传递消息。
- 但互联网是由无数个"门派"(比如中国移动、中国联通、校园网、企业网等)组成的,这些不同门派之间怎么通信呢?
这就需要一个跨门派的沟通规则------外部网关协议BGP (可以理解为"门派外交协议")。
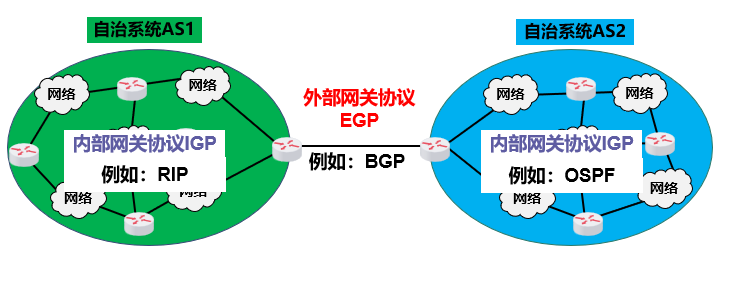
1. 为什么AS之间需要专门的BGP协议?
内部协议(如RIP、OSPF)的目标是找"最优路径"(比如最快、跳数最少),但AS之间的路由选择要复杂得多:
(1)跨AS的"代价"没法统一算
每个AS是独立的"门派",各自的网络成本、带宽、延迟标准都不一样。比如:
- 甲AS的100Mbps链路可能成本很低
- 乙AS的100Mbps链路可能成本很高
你没法像算内部路由那样,用统一的"代价"比较跨AS的路径,所以BGP不追求"绝对最优",只保证"能到且合理"。
(2)策略比技术更重要
AS之间的路由往往受"商业合作"影响,就像快递网点之间的合作:
- 甲公司和乙公司有合作,数据可以优先走乙公司的线路
- 甲公司和丙公司没合作,即使丙公司的线路更快,也可能不用
BGP必须能理解和执行这些"策略性规则",这是内部协议不需要考虑的。
2. BGP的核心任务:找到"可达且合适"的跨AS路径
BGP不纠结"哪条路最快",而是解决两个问题:
- 可达性:从我的AS能不能到达目标AS?(就像"从丐帮能不能送信到武当派?")
- 合适性:根据策略,选一条双方都认可的路径(比如"走少林中转,因为我们和少林有合作")
3. BGP怎么工作?
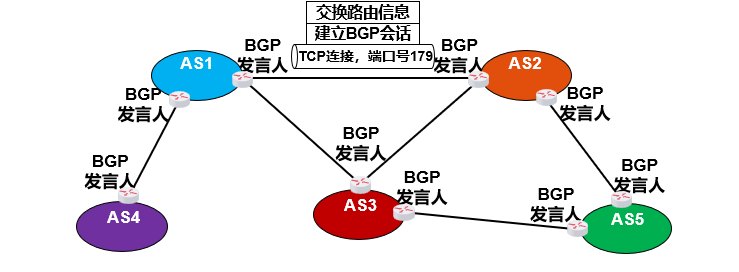
(1)BGP发言人:
每个AS会选一个或几个路由器作为"对外发言人"(BGP发言人),就像每个门派的"外交大使"。他们的职责是:
- 代表本AS和其他AS的发言人沟通
- 收集本AS内部的路由信息(通过OSPF、RIP等内部协议)
- 向其他AS通报"我们AS能到达哪些网络"
2. 用TCP建立"专线电话"
不同AS的发言人之间要沟通,需要先建立一条可靠的"专线":
- 他们会通过TCP协议(端口179)建立连接,就像拉了一根专用电话线
- 为什么用TCP?因为TCP能保证消息不丢失、不混乱(跨AS通信太重要,不能出岔子)
- 建立连接后,发言人之间就形成了"邻居关系"(对等站),可以开始交换路由信息了
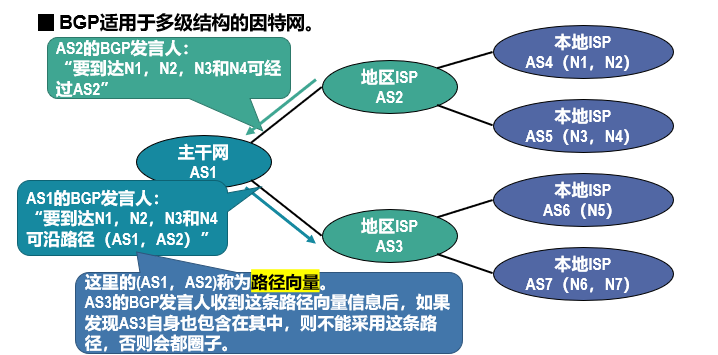
4、BGP的"路径向量":
内部协议(如OSPF)用"链路状态"记录详细拓扑,而BGP用**"路径向量"** 记录跨AS的路线,简单说就是"我到目标网络,要经过哪些AS"。
举个例子:
- 假设目标网络在AS2里,AS1的发言人会告诉邻居:"要到AS2的网络,走(AS1→AS2)这条路"
- 如果AS3的发言人从AS1那里收到这个信息,会补充成:"要到AS2的网络,走(AS3→AS1→AS2)这条路"
关键功能:防止绕圈
路径向量里记录了所有经过的AS,一旦发现路径里出现了自己的AS(比如AS1收到一条路径是"AS1→AS3→AS1"),就会立刻丢弃这条路径------这就避免了数据在AS之间绕圈子。
6. BGP交换信息的特点:
1. 只交换必要的路由信息
BGP初始会交换一次完整的路由表(就像初次见面交换名片),之后只更新变化的部分(比如"某条路断了""新增了一条路"),不会像RIP那样频繁发送完整信息,节省带宽。
2. 路由选择靠"策略"而非"技术指标"
比如:
- 优先选择"经过AS数量少"的路径(少打交道更简单)
- 优先选择"和本AS有商业合作"的AS路径(符合策略)
- 可以手动配置"禁止走某条路径"(比如竞争对手的AS)
7. BGP的四种报文类型
BGP发言人之间沟通有四种"文书",就像外交沟通的不同场景:
| 报文类型 | 功能(类比外交场景) |
|---|---|
| 打开(OPEN) | 初次见面打招呼:"我是XX AS的发言人,想和你建立联系" |
| 保活(KEEPALIVE) | 定期发消息维持关系:"我还在线,别断了连接" |
| 更新(UPDATE) | 通报路线变化:"我们到XX网络的路径变了,新路径是......" |
| 通知(NOTIFICATION) | 报错或终止联系:"你发的信息有问题,我要断开连接了" |
8. BGP和内部协议(RIP/OSPF)的核心区别
| 对比项 | 内部协议(RIP/OSPF) | 外部协议BGP |
|---|---|---|
| 适用范围 | 单一AS内部 | 不同AS之间 |
| 目标 | 找"最优路径"(快、近) | 找"可达且符合策略"的路径 |
| 关注重点 | 技术指标(跳数、带宽等) | 商业策略、AS关系 |
| 信息交换方式 | 广播/洪泛(内部全知道) | 仅在发言人之间点对点交换 |
| 路径记录 | 记录下一跳路由器 | 记录经过的AS序列(路径向量) |
五、路由器的构成
1. 路由器到底是干什么的?
想象你开车从北京到上海,会经过无数个十字路口,每个路口都有交通标志指引方向。
- 互联网里的"数据分组"(可以理解为"网络小包裹")从一个设备到另一个设备,也需要类似的"指引"------路由器就是干这个的。
路由器的核心作用有两个:
- 连通不同网络:比如把你家的WiFi(局域网)和电信的宽带网(广域网)连起来。
- 选路:给数据分组选一条通畅的路,让它们快点到达目的地,就像交通指挥官指挥车辆走最优路线。
2.路由器的两大部分协同工作
路由器虽然看起来像个小盒子,但内部有明确的"分工",主要分为两部分,就像一个公司有"决策部门"和"执行部门":
(1)路由选择部分:路由器的控制中心
这部分是路由器的"决策核心",由"路由选择处理机"(可以理解为"智能大脑")负责,主要做两件事:
- 学路线:通过路由协议(比如之前讲的RIP、OSPF、BGP)和其他路由器"沟通",了解网络拓扑(谁和谁相连,哪条路通)。
- 记路线:根据学到的信息,生成并更新"路由表"(相当于"地图手册",记录到每个目标网络该走哪条路)。
简单说,这部分负责"规划路线",就像导航软件计算从起点到终点的最佳路径。
(2) 分组转发部分:路由器的执行部门
这部分负责实际"搬运"数据分组,由三个部件组成,就像快递站的"收货窗口、传送带、发货窗口":
2.1输入端口:"收货窗口"
输入端口是数据分组进入路由器的"入口",就像快递站的收货窗口,主要做两件事:
- 拆包检查:数据分组外面有"包装"(数据链路层的帧头帧尾),输入端口会先拆掉包装,露出里面的"地址信息"(网络层的IP地址)。
- 查地址:根据地址查"转发表"(从路由表简化来的"快捷指南"),确定这个分组该从哪个"出口"发出去。
2.2 交换结构:"传送带"
交换结构是路由器的"核心传送带",负责把输入端口收到的分组"搬运"到对应的输出端口。
比如输入端口确定"这个分组要去上海",交换结构就会把它送到通往上海的输出端口。
2.3 输出端口:"发货窗口"
输出端口是数据分组离开路由器的"出口",像快递站的发货窗口,主要做两件事:
- 暂存排队:如果一下子来了太多分组(超过输出线路的"承载能力"),会先放进"缓冲区"(类似快递站的暂存货架)排队。
- 打包发送:给分组重新套上"包装"(数据链路层的帧头帧尾),然后通过物理线路(比如网线、光纤)发送出去。
3. "转发"和"路由选择"不是一回事
很多人容易搞混这两个词,用快递举例就能分清:
- 路由选择:快递总部规划"从北京仓库到上海仓库该走空运还是陆运"(决策过程)。
- 转发:北京仓库的快递员把包裹放到去上海的运输车上(执行过程)。
简单说:路由选择是"算路",转发是"走路"。
4. 数据分组在路由器里的流程
- 进"门":分组从输入端口进入,输入端口拆掉外层包装,读取目标IP地址。
- 查"指南":输入端口查转发表,确定该从哪个输出端口发出去。
- 上"传送带":交换结构把分组从输入端口"搬"到对应的输出端口。
- 等"发车":如果输出端口的缓冲区没满,分组就排队等待;如果满了,可能会被"拒收"(这就是网络中"丢包"的常见原因)。
- 出"门":输出端口给分组套上新包装,通过线路发送到下一个路由器或目标设备。
5. 为什么会丢包?
有时候你上网会卡顿,可能是数据分组在路由器里被"丢了"。丢包的主要原因很简单:
路由器的缓冲区(暂存空间)就像快递站的货架,如果同时来的包裹太多,货架堆不下了,后面的包裹就只能被扔掉。
比如:输出端口的线路每秒能发100个分组,但一下子来了200个,缓冲区只能存80个,剩下的20个就会被丢弃。
6. 交换结构:路由器的传送带的三种设计
交换结构是"搬运"分组的核心,就像快递站的"传送带系统",有三种常见设计,各有优缺点:
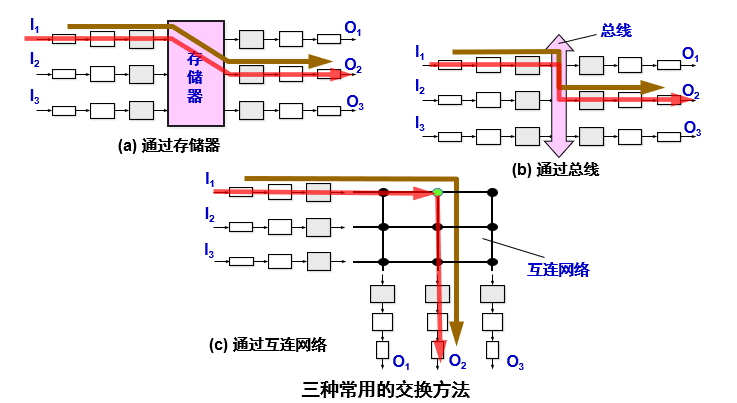
(1)通过存储器交换:"先存再取"
原理:输入端口先把分组放进路由器的"内存仓库",处理机再从仓库里取出来,送到输出端口。
- 就像:快递员先把包裹放进仓库,再从仓库拿出来放到发货区。
缺点:速度慢,因为"存"和"取"不能同时做,适合小流量场景。
(2) 通过总线交换:"共用一条传送带"
原理:输入端口和输出端口共用一条"总线"(可以理解为"公用传送带"),分组直接通过总线送到目标输出端口。
- 就像:所有快递都走同一条传送带,谁先到谁先走。
特点:结构简单,成本低,但如果同时有太多分组,会"堵车"(总线忙不过来)。现在很多家用路由器用这种方式。
(3) 纵横交换结构:"立交桥式交换"
原理:有很多条"纵横交错的通道"(类似立交桥的多个车道),输入端口和输出端口可以通过不同通道同时传输分组。
- 就像:多个方向的车可以通过立交桥同时行驶,互不干扰。
优点:速度快,能同时处理多个分组,适合大流量场景(比如电信机房的高端路由器)。
六、IPV6
1. 为什么需要IPv6?
想象一下,早期电话只有固定电话,号码是几位数字就够了。但现在每个人都有手机,还有智能手表、智能家居,原来的号码不够用了------互联网也遇到了同样的问题。
我们现在用的IPv4地址(比如192.168.1.1)是32位的,最多只能提供约43亿个地址。
- 但现在全球有几十亿台手机、电脑,还有无数智能设备(摄像头、冰箱、汽车),IPv4地址早就不够用了。
这时候,IPv6出现了。它就像把电话号码从"4位"升级到"128位",能提供的地址数量多到夸张------地球上每一粒沙子都能分到几十亿个IPv6地址,足够用几百年。
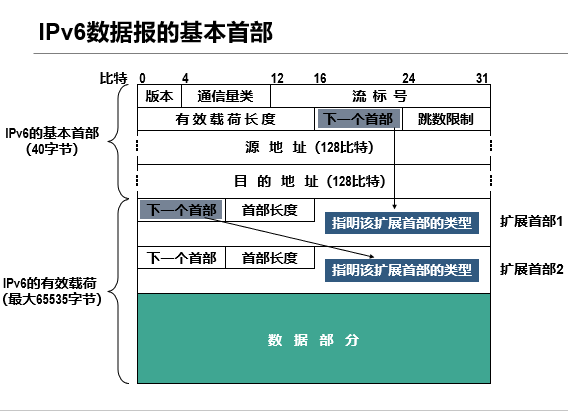
2. IPv6的基本首部:
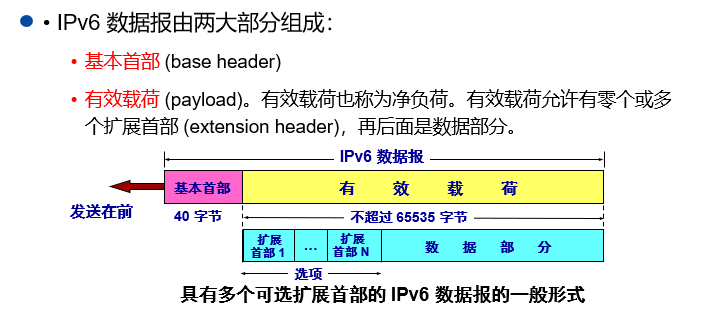
IPv4的首部有很多字段,就像一张复杂的快递单,填写麻烦还占空间。IPv6简化了首部,让"快递单"更轻便,处理更快。
IPv6基本首部的特点:
- 固定长度:40字节(IPv4首部长度可变,最小20字节),路由器处理时不用花时间计算长度,效率更高。
- 字段精简:去掉了IPv4里很少用的字段(比如校验和),保留核心信息(源地址、目的地址、版本号等)。
- 可扩展:如果需要额外信息,可以在基本首部后面加"扩展首部"(类似快递单的附加备注),但基本首部始终保持简洁。
3. IPv6的地址
(1) IPv6地址长什么样?
IPv4地址是点分十进制(比如192.168.1.1),IPv6地址是冒分十六进制 ,比如:2001:0db8:85a3:0000:0000:8a2e:0370:7334。
- 由8组数字组成,每组4个十六进制数(0-9,a-f),组之间用冒号隔开。
- 为了简化写法,有两个规则:
- 连续的0可以用
::代替(但只能用一次)。比如2001:0db8::8a2e:0370:7334(中间的4个0组简化成::)。 - 每组前面的0可以省略。比如
0db8可以写成db8。
- 连续的0可以用
(2) IPv6地址的类型:三种"通信方式"
IPv6定义了三种地址类型。
- 单播地址:一对一通信(最常用)。比如你给朋友发消息,数据只送到朋友的设备,就像寄快递给特定人。
- 多播地址:一对多通信。比如直播平台发消息给所有在线用户,就像群发邮件。
- 任播地址:一对最近的一个。比如你想访问"百度服务器",数据会送到离你最近的百度服务器(可能在北京、上海或广州的服务器),就像外卖会分配给最近的骑手。
(3) 特别的"本地地址"
IPv6里有专门的本地地址,比如:
fe80::开头的地址:仅在本地局域网内使用,不会被路由到互联网(类似IPv4的192.168.x.x)。
4. 从IPv4向IPv6过渡
IPv4已经用了几十年,全球的设备和网络都基于它运行,不可能一下子全换成IPv6,就像不能一天之内把全国的旧电话系统全换成新的。
过渡需要"渐进式",主要有三种方法:
1. 双栈技术
让设备(比如电脑、路由器)同时支持IPv4和IPv6协议,就像手机同时支持4G和5G。
- 当设备和IPv4网络通信时,用IPv4地址;和IPv6网络通信时,用IPv6地址。
- 这是最基础的过渡方法,现在很多操作系统(比如Windows、手机系统)都默认支持双栈。
2. 隧道技术
如果两个IPv6网络之间被IPv4网络隔开(比如早期的互联网主要是IPv4),可以用"隧道"传输:
- 把IPv6的数据包放进IPv4的"包裹"里,通过IPv4网络传输,到达目的地后再拆开。
- 就像你要寄一个不符合旧快递标准的新包裹,先放进旧快递的盒子里,到了目的地再拿出来。
3. NAT64
当IPv6设备需要访问IPv4设备(比如老服务器还在用IPv4),可以通过NAT64服务器做"翻译":
- IPv6设备把数据发给NAT64服务器,服务器把IPv6地址转换成IPv4地址,再发给目标设备。
- 反之,IPv4设备的回复也通过服务器翻译成IPv6地址,发给原设备。
- 就像两个人语言不通,通过翻译官沟通。
5. ICMPv6:IPv6的"助手协议"
每个网络协议都需要"助手"处理错误和控制信息,IPv4有ICMPv4(比如ping命令就用它),IPv6对应的是ICMPv6,功能更强大:
- 错误处理:比如数据无法送达时,返回错误信息("目标地址不可达")。
- 邻居发现:IPv6设备可以自动发现局域网内的其他设备(比如你的手机自动找到家里的路由器),不用手动配置。
- 自动配置地址:很多IPv6设备能自动生成地址(类似手机插卡后自动获取号码),比IPv4需要手动或DHCP配置更方便。
七、IP 多播
1. 什么是IP多播?
我们平时上网,数据传输主要有三种方式,用生活场景类比会很容易理解:
- 单播:一对一通信。就像你给朋友打电话,只有你们两人能听到,数据只发给一个目标(比如微信私聊)。
- 广播:一对所有通信。就像小区广播通知,所有设备(不管是否需要)都会收到数据(比如路由器发"ARP请求"找设备)。
- 多播:一对多通信。就像直播,主播发一次数据,只有订阅了直播间的观众能收到,没订阅的收不到(比如视频会议、在线课堂)。
IP多播的核心优势:只给需要的设备发数据,既不像广播那样浪费带宽(所有人都收到),也不像单播那样重复发送(给1000人发消息要发1000次)。比如一场10万人的直播,多播只发1次数据,10万观众同时接收,效率极高。
2.在局域网上进行硬件多播
局域网(比如家里的WiFi、公司内网)里的设备靠"MAC地址"识别彼此,多播在局域网内的实现,依赖"多播MAC地址"这个特殊标记。
1. 多播MAC地址:给多播数据贴"专属标签"
- 普通单播的MAC地址是唯一的(比如你的手机有一个独一无二的MAC地址),而多播MAC地址是"共享标签"------所有加入同一多播组的设备,都会"监听"这个标签的数据包。
- 格式小知识:多播MAC地址以
01-00-5E开头(十六进制),后面的部分和IP多播地址对应(简单说就是"多播组的专属编码")。
比如:一个多播组的IP地址是224.0.0.1,对应的MAC地址是01-00-5E-00-00-01,所有加入这个组的设备,都会接收带有这个MAC地址的数据包。
2. 交换机如何处理多播数据?
局域网的交换机收到多播数据时,不会像广播那样"无脑转发给所有设备",而是:
- 先查"多播组列表":记录哪些端口(连接着设备)加入了这个多播组。
- 只把数据发给列表中的端口,其他端口不转发。
就像小区的快递柜:"生鲜快递"(多播数据)只通知订阅了生鲜服务的住户(多播组成员)来取,没订阅的住户不会收到通知,避免打扰。
4. 网际组管理协议IGMP
当设备想加入或退出多播组(比如进入直播间、退出直播间),需要一种协议告诉局域网的路由器------这就是IGMP(网际组管理协议) 的作用。
简单说,IGMP是"主机和路由器之间的群聊管理工具",主要做三件事:
(1) 加入多播组:"我要进群"
当你的电脑想接收某个多播数据(比如打开直播软件),会通过IGMP向局域网的路由器发送"加入请求":
- 消息内容:"我要加入
224.1.2.3这个多播组,请把这个组的数据包发给我"。 - 路由器收到后,会在自己的"多播组列表"里记下:"连接这台电脑的端口,属于
224.1.2.3组"。
(2)维持成员关系"
路由器不会一直无条件发数据,它会定期"点名"(默认每60秒一次),通过IGMP发送"查询消息":
- 消息内容:"
224.1.2.3组的成员还在吗?在的请回复"。 - 多播组里的设备收到后,会回复"我还在"(但为了减少消息量,通常只有一个设备代表全组回复,避免大家同时说话)。
(3) 退出多播组
当设备不想接收多播数据了(比如关闭直播软件),会通过IGMP发送"退出请求":
- 消息内容:"我退出
224.1.2.3组,不用再发数据包给我了"。 - 路由器收到后,会从"多播组列表"中删掉该设备的端口;如果组里没人了,就不再转发这个组的数据包。
5. 多播路由选择协议
IGMP解决了局域网内的多播管理,但多播数据往往需要跨网络传输(比如北京的主播,数据要传到上海、广州的观众)。
- 这时候,路由器之间需要"多播路由选择协议"来确定数据传输的路径。
核心目标:构建"多播分发树"
多播数据从源设备(比如主播的服务器)到所有成员(比如各地观众),最优路径是一棵"分发树"------就像树干(源)分支出多个树枝(中间路由器),最后到树叶(成员设备)。
这样做的好处是:
- 数据在分支点只复制一次,避免重复传输(比如从北京到上海、广州,数据先到武汉分拨中心,再分别发往两地,而不是北京直接发两次)。
- 避免环路(比如数据不会在路由器之间来回转圈)。
常见的多播路由协议
不同场景用不同的协议,简单了解三个:
- DVMRP:基于距离矢量的协议(类似RIP的多播版),适合小型网络。
- MOSPF:基于链路状态的协议(类似OSPF的多播版),利用全网拓扑构建最优分发树,适合中大型网络。
- PIM :最常用的协议,分两种模式:
- 密集模式:适合多播组成员多、分布密集的场景(比如校园网内的多播)。
- 稀疏模式:适合成员少、分布分散的场景(比如互联网上的直播)。
以上就是本篇博客的全部内容,下一篇将进入网络层的学习,探索IP协议与路由技术。
我的个人主页,欢迎来阅读我的其他文章
https://blog.csdn.net/2402_83322742?spm=1011.2415.3001.5343我的计算机网络专栏,欢迎来阅读
https://blog.csdn.net/2402_83322742/category_12909527.html
|------------------------------------|
| 如果您觉得内容对您有帮助,欢迎点赞收藏,您的支持是我创作的最大动力! |
