python处理pdf文档
- PDF文件难管理,编辑受限,手动操作低效!
- [1.Python PDF处理库选择:PyPDF2与PyMuPDF对比](#1.Python PDF处理库选择:PyPDF2与PyMuPDF对比)
-
- [1.1 PyPDF2:轻量易用,处理PDF文本和基本操作](#1.1 PyPDF2:轻量易用,处理PDF文本和基本操作)
- 1.2PyMuPDF:功能强大,渲染与高级编辑
- [1.3 环境准备与选择建议](#1.3 环境准备与选择建议)
- 2.Python批量合并与分割PDF文件,轻松整理文档!
-
- [2.1 批量合并PDF文件:一键拼接,文档归一](#2.1 批量合并PDF文件:一键拼接,文档归一)
- [2.2 单个PDF文件按页分割:长篇文档秒变小册子!](#2.2 单个PDF文件按页分割:长篇文档秒变小册子!)
- 3.Python为PDF添加水印、页码与实现加密解密!
-
- [3.1 PDF水印:添加文字、图片Logo,保护文档版权!](#3.1 PDF水印:添加文字、图片Logo,保护文档版权!)
- [3.2 批量添加页码:让你的报告规范专业](#3.2 批量添加页码:让你的报告规范专业)
- [3.3 PDF密码加密与解密:为你的重要文档上锁](#3.3 PDF密码加密与解密:为你的重要文档上锁)
- [4. 阶段性总结pdf 全能管家](#4. 阶段性总结pdf 全能管家)
- 5.尾声:PDF自动化,解锁文档管理新高度!
PDF文件难管理,编辑受限,手动操作低效!
在职场中,PDF文件因其格式稳定、跨平台兼容性好而广泛应用。但你有没有被PDF的这些"痛点"折磨过?
文件零散: 多个相关的PDF文件(如项目周报、合同附件),散落在不同地方,难以整合为一个完整文档。
编辑受限: 想从PDF中提取文字,却发现无法复制;想修改某个数字,却无从下手。
合并/分割麻烦: 需要把几份PDF合并成一份,或者把一份长PDF拆分成多个小文件,手动操作效率低下。
缺乏保护: 重要PDF文件直接传输,没有密码保护,传输安全有隐患。
这些重复、低效的PDF文件管理任务,严重拖慢了你的办公自动化进程。
今天,我将带你进入Python处理PDF的奇妙世界!我们将手把手教你如何利用强大的Python库,轻松
实现:
PDF合并与分割: 批量操作,轻松整理文档。
PDF文本提取: 瞬间获取PDF中的文字信息。
PDF水印与页码: 批量添加,提升文档专业度。
PDF加密解密: 为你的重要文档加上"安全锁"。
最终,你将拥有一个强大的PDF全能管家。
1.Python PDF处理库选择:PyPDF2与PyMuPDF对比
要实现Python处理PDF,有两个非常流行的库可供选择:PyPDF2和PyMuPDF。了解它们的特点,能帮你选择最适合你需求的Python PDF库。
1.1 PyPDF2:轻量易用,处理PDF文本和基本操作
PyPDF2: 更轻量级,主要用于PDF的结构化操作(如合并、分割、提取文本/元数据)。
1.2PyMuPDF:功能强大,渲染与高级编辑
PyMuPDF (fitz): 功能更强大,除了结构化操作,还具备高性能的PDF渲染(转换为图片)、高级文本和图片提取、以及更精细的页面编辑能力。
python
pip install PyPDF2
pip install PyMuPDF1.3 环境准备与选择建议
表格:PyPDF2 与 PyMuPDF (fitz) 功能对比]
| 特性 | PyPDF2 | PyMuPDF (fitz) |
|---|---|---|
| 主要功能 | 合并、分割、旋转、加密、基础文本/页面提取 | 渲染、文本/图片/矢量图形提取、高级插入、格式转换 |
| 合并PDF | ✅ 支持 | ✅ 支持 |
| 分割PDF | ✅ 支持 | ✅ 支持 |
| 提取文本 | ✅ 支持(纯文本) | ✅ 支持(含坐标、格式) |
| 提取图片 | ❌ 不支持 | ✅ 支持 |
| PDF转图片 | ❌ 不支持 | ✅ 支持 (高性能渲染) |
| 添加水印 | ✅ 支持(简单文本/图片) | ✅ 支持(高级:文本/图片,字体、透明度可控) |
| 添加页码 | ❌ 不支持 | ✅ 支持 |
| 加密解密 | ✅ 支持(简单密码) | ✅ 支持(多种加密算法) |
| 内容替换 | ❌ 不支持 | ✅ 支持 |
| 复杂编辑 | ❌ 不支持 | ✅ 支持 |
| 安装/学习 | 简单 | 稍复杂/陡峭 |
| 适用场景 | 简单的PDF合并、分割、加密、提取 | PDF预览、高级文本/图片提取、文档渲染、PDF生成 |
选择建议:
如果你只是想简单合并、分割PDF,提取纯文本:PyPDF2已足够,因为它更简单,易于快速上手。
如果你需要进行PDF渲染(如将Excel内容"画"到PDF)、高级文本/图片提取、添加定制水印、或者更
精细的PDF内容操作:强烈推荐PyMuPDF。
本文接下来的例子将主要基于PyMuPDF进行演示,因为它功能更全面,能实现更多高级自动化。
2.Python批量合并与分割PDF文件,轻松整理文档!
PDF文档的合并与分割,是日常PDF自动化中最高频的需求。Python能帮你一键完成这些操作,让你的文档管理自动化效率翻倍!
作用: PyMuPDF将PDF视为一系列页面,可以方便地添加页面(合并)或提取页面(分割)。
2.1 批量合并PDF文件:一键拼接,文档归一
场景: 你有合同-附件1.pdf、合同-附件2.pdf和合同-正文.pdf,需要将它们按顺序合并成一份完整的完整合同.pdf。
方案: 编写一个Python脚本,指定多个源PDF文件,PyMuPDF将它们快速拼接成一个大的PDF文档,实现PDF合并的自动化。
代码:
python
import fitz # PyMuPDF库
import os
def merge_pdfs(pdf_list, output_pdf_path):
"""
批量合并多个PDF文件为一个PDF文件。
这是Python处理PDF和PDF合并分割的核心功能。
:param pdf_list: 要合并的PDF文件路径列表
:param output_pdf_path: 合并后PDF文件的输出路径
"""
if not pdf_list:
print("❌ 没有指定任何PDF文件进行合并。")
return False
os.makedirs(os.path.dirname(output_pdf_path), exist_ok=True)
print(f"🚀 正在合并 {len(pdf_list)} 个PDF文件到 '{os.path.basename(output_pdf_path)}'...")
# 创建一个新的PDF文档
new_pdf = fitz.open()
try:
for pdf_path in pdf_list:
if not os.path.exists(pdf_path):
print(f"⚠️ 文件不存在,跳过:{os.path.basename(pdf_path)}")
continue
# 打开每个PDF文件,并将其所有页面插入到新PDF中
with fitz.open(pdf_path) as doc:
new_pdf.insert_pdf(doc) # 插入PDF的所有页面
print(f" ✅ 已合并:{os.path.basename(pdf_path)}")
new_pdf.save(output_pdf_path) # 保存合并后的PDF
print(f"✨ PDF合并成功!结果保存到:'{output_pdf_path}'")
return True
except Exception as e:
print(f"❌ PDF合并失败:{e}")
return False
finally:
new_pdf.close() # 确保关闭PDF对象
if __name__ == "__main__":
# 准备测试PDF文件
pdf1_path = os.path.expanduser("~/Desktop/report_part1.pdf")
pdf2_path = os.path.expanduser("~/Desktop/report_part2.pdf")
output_merged_pdf = os.path.expanduser("~/Desktop/merged_annual_report.pdf")
# 简单创建模拟PDF文件 (实际请用你的真实PDF)
if not os.path.exists(pdf1_path):
doc1 = fitz.open(); doc1.new_page().insert_text(fitz.Point(50,50), "这是第一部分"); doc1.save(pdf1_path); doc1.close()
if not os.path.exists(pdf2_path):
doc2 = fitz.open(); doc2.new_page().insert_text(fitz.Point(50,50), "这是第二部分"); doc2.save(pdf2_path); doc2.close()
pdfs_to_merge = [pdf1_path, pdf2_path]
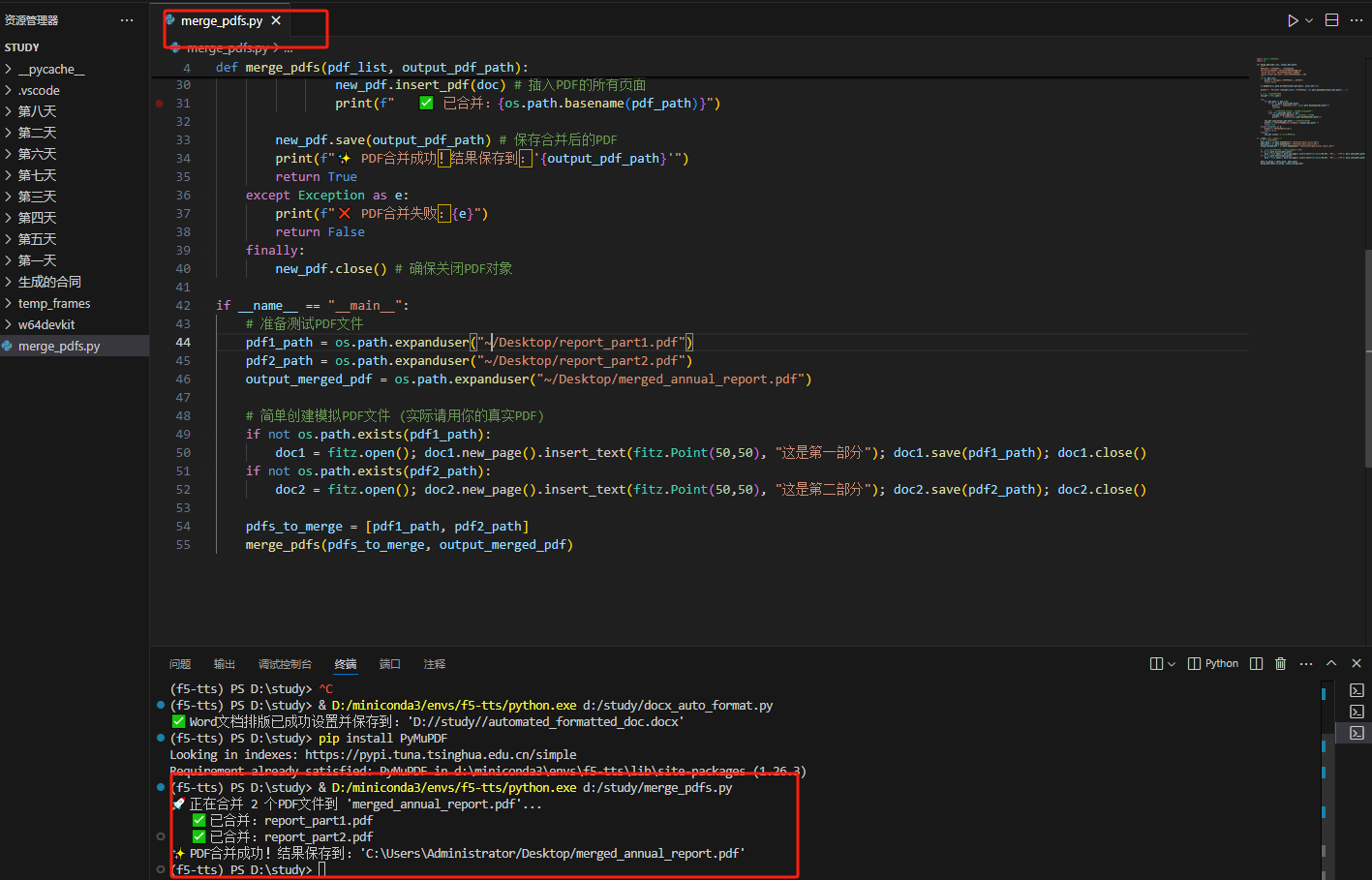
merge_pdfs(pdfs_to_merge, output_merged_pdf)步骤:
安装PyMuPDF: pip install PyMuPDF。
准备PDF文件: 在桌面创建report_part1.pdf和report_part2.pdf等测试PDF文件。
修改代码路径: 修改 pdfs_to_merge 列表中的路径和 output_merged_pdf。
运行: 运行 python merge_pdfs.py。
效果展示:
2.2 单个PDF文件按页分割:长篇文档秒变小册子!
场景: 你收到一份50页的PDF报告,但你只需要其中的第5页到第10页,或者想把每一页都拆分成单独的PDF文件。手动操作耗时且容易出错。
方案: PyMuPDF能让你精确地将一个多页PDF文件按页码范围分割成多个独立的PDF文件,或者将每一页都拆分成单独的文件。
代码:
python
import fitz # PyMuPDF
import os
def split_pdf_by_pages(input_pdf_path, output_folder, page_ranges=None):
"""
将单个PDF文件按页码范围分割为多个PDF文件。
这是Python处理PDF和PDF合并分割的高级功能。
:param input_pdf_path: 源PDF文件路径
:param output_folder: 分割后PDF文件的输出文件夹
:param page_ranges: 要分割的页码范围列表,例如 [[0, 2], [5, 5]] 表示分割第1-3页和第6页
页码从0开始计数。如果为None,则每页生成一个PDF。
"""
if not os.path.exists(input_pdf_path):
print(f"❌ PDF文件不存在:{input_pdf_path}")
return False
os.makedirs(output_folder, exist_ok=True)
print(f"🚀 正在分割PDF文件 '{os.path.basename(input_pdf_path)}'...")
try:
with fitz.open(input_pdf_path) as doc:
if page_ranges is None: # 如果没有指定范围,则每页分割一个PDF
page_ranges = [[i, i] for i in range(doc.page_count)]
for i, (start_page, end_page) in enumerate(page_ranges):
if start_page < 0 or end_page >= doc.page_count or start_page > end_page:
print(f"⚠️ 页码范围无效,跳过:[{start_page}, {end_page}]")
continue
# 创建新PDF来存储分割的页面
new_pdf = fitz.open()
new_pdf.insert_pdf(doc, from_page=start_page, to_page=end_page)
output_filename = f"{os.path.splitext(os.path.basename(input_pdf_path))[0]}_part_{i+1}_pages_{start_page+1}-{end_page+1}.pdf"
output_full_path = os.path.join(output_folder, output_filename)
new_pdf.save(output_full_path)
new_pdf.close()
print(f" ✅ 已分割:'{output_filename}' (页码: {start_page+1}-{end_page+1})")
print(f"✨ PDF分割完成!结果保存到:'{output_folder}'")
return True
except Exception as e:
print(f"❌ PDF分割失败:{e}")
return False
if __name__ == "__main__":
# 准备测试PDF文件 (多页)
long_report_path = os.path.expanduser("~/Desktop/long_report.pdf")
# 简单创建模拟PDF文件 (例如创建5页的PDF)
if not os.path.exists(long_report_path):
doc = fitz.open()
for i in range(5):
page = doc.new_page(width=595, height=842) # A4
page.insert_text(fitz.Point(50,50), f"这是第 {i+1} 页")
doc.save(long_report_path); doc.close()
output_split_folder = os.path.expanduser("~/Desktop/分割后PDF")
# 示例1:将每一页分割为单独的文件
print("\n--- 示例1:按页分割所有PDF ---")
split_pdf_by_pages(long_report_path, os.path.join(output_split_folder, "ByPage"))
# 示例2:按指定范围分割 (例如,只取第2页到第4页,对应索引1到3)
print("\n--- 示例2:按页码范围分割PDF (取第2到4页) ---")
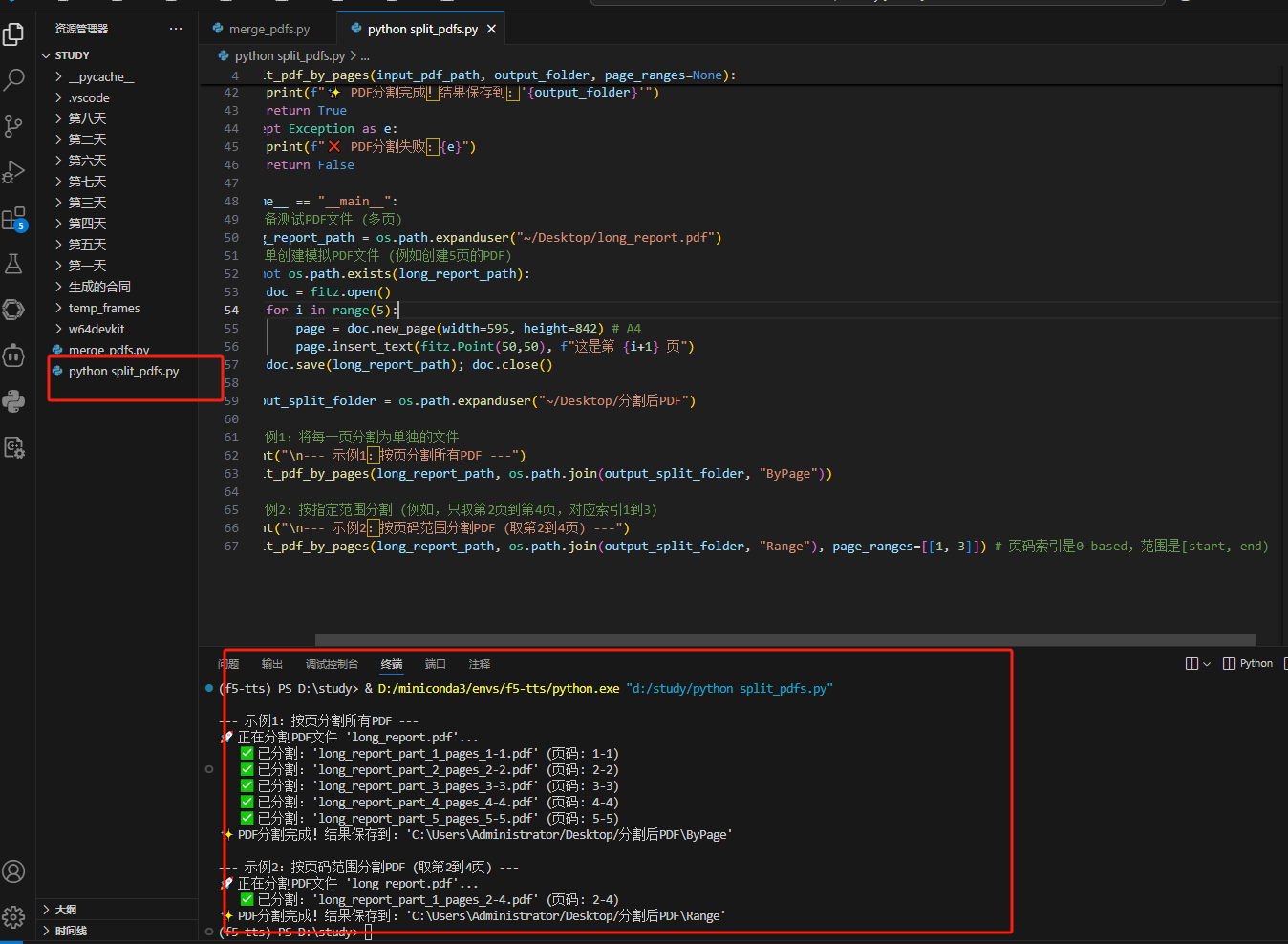
split_pdf_by_pages(long_report_path, os.path.join(output_split_folder, "Range"), page_ranges=[[1, 3]]) # 页码索引是0-based,范围是[start, end)操作步骤:
安装PyMuPDF: pip install PyMuPDF。
准备PDF文件: 在桌面创建long_report.pdf(包含多页内容,如5页)。
修改代码路径和页码范围: 修改 long_report_path 和 output_split_folder。
运行: 运行 python split_pdfs.py。
效果展示:
3.Python为PDF添加水印、页码与实现加密解密!
PDF的保护和专业化是文档管理的重要环节。
PyMuPDF能让你为PDF添加水印、自动生成页码,甚至进行PDF加密与解密,全方位提升你的PDF自动化能力!
3.1 PDF水印:添加文字、图片Logo,保护文档版权!
场景: 你需要为一份重要报告或内部资料添加"绝密"、"版权所有"等文字水印,或在每页添加你的公司名称。
方案: PyMuPDF可以精确地在PDF的每一页上添加文字水印或图片水印,并控制其位置、透明度等。
代码:
python
import fitz # PyMuPDF
from PIL import Image, ImageDraw, ImageFont # 用于文字渲染到图片 (如果需要),或处理Logo图片
import os
import io # 用于内存中的文件操作
# 定义一个中文字体路径,确保你的系统中有,否则中文可能显示为方块
CHINESE_FONT_PATH = "C:/Windows/Fonts/simhei.ttf" # Windows黑体示例
def add_pdf_watermark(pdf_path, output_path, watermark_type="text",
text_content="", font_size=30, text_color=(0.5, 0.5, 0.5), # RGB (0.0-1.0)
image_watermark_path=None, image_opacity=0.3, image_size_ratio=0.1,
position="bottom_right", rotate_degree=0): # 新增旋转参数
"""
为PDF文件添加文字水印或图片水印。
这是PDF自动化和PDF加水印的核心功能。
:param pdf_path: 源PDF文件路径
:param output_path: 输出PDF文件路径
:param watermark_type: "text" (文字水印) 或 "image" (图片水印)
:param text_content: 文字水印内容
:param font_size: 文字水印字体大小
:param text_color: 文字水印颜色 (RGB元组,范围0.0-1.0)
:param image_watermark_path: 图片水印文件路径
:param image_opacity: 图片水印透明度 (0.0-1.0)
:param image_size_ratio: 图片水印相对于页面宽度的比例
:param position: 水印位置 ("top_left", "top_right", "bottom_left", "bottom_right", "center")
:param rotate_degree: 文字水印旋转角度 (度)
"""
if not os.path.exists(pdf_path): return print(f"❌ PDF文件不存在:{pdf_path}")
os.makedirs(os.path.dirname(output_path), exist_ok=True)
doc = fitz.open(pdf_path) # 打开PDF文档
print(f"🚀 正在为 '{os.path.basename(pdf_path)}' 添加水印...")
# 尝试加载中文字体
font_name_in_pdf = "helv" # 默认内置字体
if pdf_font_path and os.path.exists(CHINESE_FONT_PATH):
try:
# register_font 返回字体对象的xref,可以直接用于insert_text
font_xref = doc.register_font(fontfile=CHINESE_FONT_PATH, fontname="MyCustomFont")
font_name_in_pdf = "MyCustomFont"
print(f" ℹ️ 已注册自定义字体 '{font_name_in_pdf}'。")
except Exception as e:
print(f"⚠️ 注册中文字体失败:{e}。中文水印可能无法正确显示。")
# 加载图片水印(针对图片水印)
watermark_img_obj = None
if watermark_type == "image":
if not os.path.exists(image_watermark_path):
print(f"❌ 水印图片文件不存在:{image_watermark_path}")
return False
try:
watermark_img_obj = Image.open(image_watermark_path).convert("RGBA")
print(f" ℹ️ 已加载水印图片:{os.path.basename(image_watermark_path)}")
except Exception as e:
print(f"❌ 无法加载水印图片:{e}")
return False
for page_num in range(doc.page_count):
page = doc.load_page(page_num)
rect = page.rect # 获取页面矩形
if watermark_type == "text":
# 插入文字水印
# 注意:fitz.insert_text直接处理透明度和颜色 (R,G,B浮点数0.0-1.0)
# 计算文字尺寸和位置 (需要实际渲染才能准确获取,这里估算)
# fitz.Font().text_bbox() 更精确,但需先实例化Font
text_len_estimate = fitz.Font(fontname=font_name_in_pdf).text_bbox(text_content, fontsize=font_size)[2]
text_height_estimate = font_size * 1.2 # 粗略估算高度
x, y = 0, 0
if position == "top_left": x, y = rect.x0 + 20, rect.y0 + 20
elif position == "top_right": x, y = rect.x1 - text_len_estimate - 20, rect.y0 + 20
elif position == "bottom_left": x, y = rect.x0 + 20, rect.y1 - text_height_estimate - 20
elif position == "bottom_right": x, y = rect.x1 - text_len_estimate - 20, rect.y1 - text_height_estimate - 20
elif position == "center": x, y = (rect.width - text_len_estimate) / 2, (rect.height - text_height_estimate) / 2
# 使用 insert_text
page.insert_text(
(x, y),
text_content,
fontname=font_name_in_pdf,
fontsize=font_size,
color=text_color, # 颜色为RGB浮点元组 (0.0, 0.0, 0.0) 到 (1.0, 1.0, 1.0)
# rotate=rotate_degree, # 旋转在insert_text中不直接支持,需要transform矩阵
overlay=True, # 确保水印在内容之上
)
# 对于旋转,需要更复杂的PyMuPDF变换矩阵,这里为简洁不展开
elif watermark_type == "image" and watermark_img_obj:
# 插入图片水印
page_width, page_height = rect.width, rect.height
# 调整水印图片大小 (相对于页面宽度比例)
wm_width = int(page_width * image_size_ratio)
wm_height = int(wm_width * watermark_img_obj.height / watermark_img_obj.width) # 保持比例
# 确保水印不超出页面且有最小尺寸
if wm_width == 0 or wm_height == 0:
print(f"⚠️ 水印尺寸计算为零,跳过页面 {page_num+1}。")
continue
resized_watermark_pil = watermark_img_obj.resize((wm_width, wm_height), Image.LANCZOS)
# 调整水印图片透明度
alpha = resized_watermark_pil.split()[-1]
alpha = Image.eval(alpha, lambda x: x * image_opacity)
resized_watermark_pil.putalpha(alpha)
# 将处理后的水印图片转为BytesIO,以便PyMuPDF插入
img_byte_arr = io.BytesIO()
resized_watermark_pil.save(img_byte_arr, format='PNG')
img_byte_arr_value = img_byte_arr.getvalue()
# 计算粘贴坐标
insert_x, insert_y = 0, 0
if position == "top_left": insert_x, insert_y = 10, 10
elif position == "top_right": insert_x, insert_y = page_width - wm_width - 10, 10
elif position == "bottom_left": insert_x, insert_y = 10, page_height - wm_height - 10
elif position == "bottom_right": insert_x, insert_y = page_width - wm_width - 10, page_height - wm_height - 10
elif position == "center": insert_x, insert_y = (page_width - wm_width) // 2, (page_height - wm_height) // 2
insert_rect = fitz.Rect(insert_x, insert_y, insert_x + wm_width, insert_y + wm_height)
page.insert_image(insert_rect, stream=img_byte_arr_value, overlay=True)
print(f" - 页面 {page_num+1} 已添加水印。")
doc.save(output_path)
print(f"✨ PDF水印添加完成!文件已保存到:'{output_path}'")
return True
finally:
if 'doc' in locals(): doc.close()
if 'watermark_img_obj' in locals(): watermark_img_obj.close() # 关闭水印图片
if __name__ == "__main__":
# 准备测试PDF文件 (多页)
source_pdf_path = os.path.expanduser("~/Desktop/sample_report.pdf")
# 简单创建模拟PDF文件
if not os.path.exists(source_pdf_path):
doc = fitz.open(); doc.new_page().insert_text(fitz.Point(50,50), "这是测试报告第一页\n请勿复制"); doc.new_page().insert_text(fitz.Point(50,50), "这是第二页"); doc.save(source_pdf_path); doc.close()
# 准备Logo图片 (如果测试图片水印)
logo_path = os.path.expanduser("~/Desktop/company_logo.png")
if not os.path.exists(logo_path):
Image.new('RGBA', (100, 50), color = (255, 0, 0, 128)).save(logo_path) # 模拟透明红色Logo
print(f"临时Logo文件 '{os.path.basename(logo_path)}' 已创建。")
output_text_wm_pdf = os.path.expanduser("~/Desktop/report_with_text_wm.pdf")
output_image_wm_pdf = os.path.expanduser("~/Desktop/report_with_logo_wm.pdf")
# 示例1:批量添加文字水印
print("\n--- 示例1:添加文字水印 ---")
add_pdf_watermark(
source_pdf_path,
output_text_wm_pdf,
watermark_type="text",
text_content="【机密文件 严禁外传】",
font_size=20, # 调整字体大小
text_color=(1, 0, 0), # 红色 (0.0-1.0)
position="center" # 居中
)
# 示例2:批量添加图片水印 (Logo)
print("\n--- 示例2:添加图片Logo水印 ---")
add_pdf_watermark(
source_pdf_path,
output_image_wm_pdf,
watermark_type="image",
image_watermark_path=logo_path,
image_opacity=0.3, # 更透明
image_size_ratio=0.2 # 尺寸更大
)操作:
安装库: pip install PyMuPDF Pillow。
准备PDF和Logo: 在桌面创建sample_report.pdf(多页),以及company_logo.png(一个Logo图)。
修改代码路径和水印参数: 修改 source_pdf_path、logo_path 等路径和水印参数。
运行: 运行 python add_pdf_watermark.py。
注意中文: 如果使用中文水印,需要确保 CHINESE_FONT_PATH 指向一个存在的中文字体文件,否则可能显示方块。
展示:

3.2 批量添加页码:让你的报告规范专业
场景: 制作长篇报告、书籍时,需要为每一页自动添加统一的页眉、页脚和页码,如"第X页 / 共Y页"。手动在PDF编辑器中添加,效率极低且容易出错。
方案: PyMuPDF能够让你自动化地为PDF文档添加页码,让你的文档瞬间变得专业和规范。
代码:
python
mport fitz # PyMuPDF
import os
# 确保中文字体路径正确,用于PDF中文页码渲染
CHINESE_FONT_PATH = "C:/Windows/Fonts/simhei.ttf" # Windows黑体示例
def add_page_numbers_to_pdf(input_pdf_path, output_pdf_path, position="bottom_center", font_size=9, color=(0,0,0)):
"""
为PDF文件的每一页批量添加页码。
这是Python处理PDF和PDF页码自动化的核心功能。
:param input_pdf_path: 源PDF文件路径
:param output_pdf_path: 添加页码后PDF文件的输出路径
:param position: 页码位置 ("top_left", "top_right", "bottom_left", "bottom_right", "center", "bottom_center", "top_center")
:param font_size: 字体大小
:param color: 颜色 (R, G, B),范围0.0-1.0
"""
if not os.path.exists(input_pdf_path): return print(f"❌ PDF文件不存在:{input_pdf_path}")
os.makedirs(os.path.dirname(output_pdf_path), exist_ok=True)
print(f"🚀 正在为 '{os.path.basename(input_pdf_path)}' 批量添加页码...")
try:
doc = fitz.open(input_pdf_path)
# 尝试加载中文字体 (用于中文页码,如"第X页")
font_name_in_pdf = "helv" # 默认内置字体 (英文数字)
if CHINESE_FONT_PATH and os.path.exists(CHINESE_FONT_PATH):
try:
doc.register_font(fontfile=CHINESE_FONT_PATH, fontname="MyCustomFont")
font_name_in_pdf = "MyCustomFont"
print(f" ℹ️ 已注册自定义字体 '{font_name_in_pdf}'。")
except Exception as e:
print(f"⚠️ 注册中文字体失败:{e}。中文页码可能无法正确显示。")
total_pages = doc.page_count
for page_num in range(total_pages):
page = doc.load_page(page_num)
# 页码文本:例如 "Page 1 / 10" 或 "第1页 / 共10页" (根据是否成功加载中文显示)
page_text = f"Page {page_num + 1} / {total_pages}"
if font_name_in_pdf == "MyCustomFont": # 如果成功加载了中文字体
page_text = f"第 {page_num + 1} 页 / 共 {total_pages} 页"
# 计算页码位置
rect = page.rect # 页面矩形
# fitz.Font().text_bbox() 更精确计算文本宽度,这里使用估算
# text_len_estimate = fitz.Font(fontname=font_name_in_pdf).text_bbox(page_text, fontsize=font_size)[2]
text_len_estimate = font_size * len(page_text) * 0.6 # 粗略估算宽度
text_height_estimate = font_size * 1.2 # 粗略估算高度
x, y = 0, 0
if position == "top_left": x, y = rect.x0 + 20, rect.y0 + 20
elif position == "top_right": x, y = rect.x1 - text_len_estimate - 20, rect.y0 + 20
elif position == "bottom_left": x, y = rect.x0 + 20, rect.y1 - text_height_estimate - 20
elif position == "bottom_right": x, y = rect.x1 - text_len_estimate - 20, rect.y1 - text_height_estimate - 20
elif position == "center": x, y = (rect.width - text_len_estimate) / 2, (rect.height - text_height_estimate) / 2
elif position == "bottom_center": x, y = (rect.width - text_len_estimate) / 2, rect.y1 - text_height_estimate - 20
elif position == "top_center": x, y = (rect.width - text_len_estimate) / 2, rect.y0 + 20
page.insert_text(
(x, y),
page_text,
fontname=font_name_in_pdf, # 使用注册的字体名或内置字体
fontsize=font_size,
color=color, # 颜色 (R, G, B) 范围0.0-1.0
overlay=True # 确保页码在内容之上
)
print(f" - 页面 {page_num+1} 已添加页码。")
doc.save(output_path)
print(f"✨ PDF页码添加完成!文件已保存到:'{output_path}'")
return True
finally:
if 'doc' in locals(): doc.close()
if __name__ == "__main__":
input_pdf = os.path.expanduser("~/Desktop/long_report_no_pages.pdf")
output_pdf = os.path.expanduser("~/Desktop/report_with_page_numbers.pdf")
# 简单创建模拟PDF文件 (多页)
if not os.path.exists(input_pdf):
doc = fitz.open()
for i in range(5):
page = doc.new_page()
page.insert_text(fitz.Point(50,50), f"这是第 {i+1} 页的内容。")
doc.save(input_pdf); doc.close()
# 示例1:添加右下角居中页码
print("\n--- 示例1:添加居中底部页码 ---")
add_page_numbers_to_pdf(
input_pdf,
output_pdf,
position="bottom_center",
font_size=10,
color=(0, 0, 0) # 黑色
)操作步骤:
安装PyMuPDF: pip install PyMuPDF。
准备PDF文件: 在桌面准备一个包含多页的PDF文件(如long_report_no_pages.pdf)。
修改代码路径和页码参数: 修改 input_pdf 和 output_pdf。
运行: 运行 python add_pdf_page_numbers.py。
效果展示:

3.3 PDF密码加密与解密:为你的重要文档上锁
场景: 你的PDF报告或合同包含敏感信息,需要进行PDF加密保护,只有拥有密码的人才能打开。手动设置密码繁琐且不安全。
方案: PyPDF2能够实现PDF文件的密码加密和解密,为你的敏感文档加上一把"安全锁",确保PDF加密和PDF解密的便捷。
代码:
python
from PyPDF2 import PdfReader, PdfWriter
import os
import shutil # 用于复制文件,如果未加密则直接复制
def encrypt_pdf_with_password(pdf_path, output_path, password):
"""
使用密码加密PDF文件。
这是PDF自动化和PDF加密的核心功能。
:param pdf_path: 源PDF文件路径
:param output_path: 加密后PDF文件的输出路径
:param password: 加密密码 (字符串)
"""
if not os.path.exists(pdf_path): return print(f"❌ PDF文件不存在:{pdf_path}")
os.makedirs(os.path.dirname(output_path), exist_ok=True)
reader = PdfReader(pdf_path)
writer = PdfWriter()
print(f"🚀 正在加密PDF文件 '{os.path.basename(pdf_path)}'...")
for page in reader.pages:
writer.add_page(page) # 将所有页面添加到writer
try:
writer.encrypt(password) # 设置加密密码
with open(output_path, "wb") as output_pdf_file:
writer.write(output_pdf_file)
print(f"✨ PDF文件加密成功!保存到:'{output_path}'")
return True
except Exception as e:
print(f"❌ PDF加密失败:{e}")
return False
def decrypt_pdf_with_password(encrypted_pdf_path, output_path, password):
"""
使用密码解密PDF文件。
这是PDF自动化和PDF解密的核心功能。
:param encrypted_pdf_path: 加密PDF文件路径
:param output_path: 解密后PDF文件的输出路径
:param password: 解密密码 (字符串)
"""
if not os.path.exists(encrypted_pdf_path): return print(f"❌ 加密PDF文件不存在:{encrypted_pdf_path}")
os.makedirs(os.path.dirname(output_path), exist_ok=True)
reader = PdfReader(encrypted_pdf_path)
if reader.is_encrypted:
if not reader.decrypt(password): # 尝试解密
print(f"❌ 解密失败:'{os.path.basename(encrypted_pdf_path)}' 密码不正确或文件已损坏。")
return False
else:
print(f"ℹ️ 文件 '{os.path.basename(encrypted_pdf_path)}' 未加密,直接复制到输出路径。")
shutil.copyfile(encrypted_pdf_path, output_path) # 未加密则直接复制
print(f"文件已直接复制到:'{output_path}'")
return True
writer = PdfWriter()
for page in reader.pages:
writer.add_page(page)
try:
with open(output_path, "wb") as output_pdf_file:
writer.write(output_pdf_file)
print(f"✨ PDF文件解密成功!保存到:'{output_path}'")
return True
except Exception as e:
print(f"❌ PDF解密失败:{e}")
return False
if __name__ == "__main__":
# 准备测试PDF文件
source_pdf = os.path.expanduser("~/Desktop/secret_document.pdf")
if not os.path.exists(source_pdf):
doc = fitz.open(); doc.new_page().insert_text(fitz.Point(50,50), "这是机密文档"); doc.save(source_pdf); doc.close()
encrypted_pdf = os.path.expanduser("~/Desktop/secret_document_encrypted.pdf")
decrypted_pdf = os.path.expanduser("~/Desktop/secret_document_decrypted.pdf")
password = "MySecurePassword123"
# 示例1:加密PDF
print("\n--- 示例1:加密PDF文件 ---")
encrypt_pdf_with_password(source_pdf, encrypted_pdf, password)
# 示例2:解密PDF
print("\n--- 示例2:解密PDF文件 ---")
decrypt_pdf_with_password(encrypted_pdf, decrypted_pdf, password)
# 示例3:尝试用错误密码解密
print("\n--- 示例3:尝试用错误密码解密 ---")
decrypt_pdf_with_password(encrypted_pdf, os.path.expanduser("~/Desktop/failed_decryption.pdf"), "WrongPassword")步骤:
安装库: pip install PyPDF2 PyMuPDF (PyMuPDF用于创建测试PDF)。
准备PDF: 在桌面创建secret_document.pdf。
修改代码路径和密码: 修改 source_pdf 等路径和 password。
运行: 运行 python pdf_encrypt_decrypt.py。
效果展示:

4. 阶段性总结pdf 全能管家
通过本篇文章,你已经掌握了PDF文档自动化的各项核心魔法,亲手打造了一个能够一键合并、分割、水印、提取与加密解密的 PDF全能管家!
我们深入学习了PyPDF2和PyMuPDF等库,它们堪称Python PDF库中的"瑞士军刀",实现了:
PDF合并分割: 轻松将多份PDF批量合并,或将长篇PDF按页分割,高效整理文档。
PDF水印: 自动化添加文字/图片Logo水印,保护文档版权,提升专业度。
PDF页码自动化: 告别手动排版,为报告批量加页码,瞬间规范。
PDF加密解密: 为你的敏感PDF文件加把"安全锁",确保文档管理中的数据安全。
现在,你不再需要为PDF文件难管理、编辑受限、手动操作低效而烦恼。
5.尾声:PDF自动化,解锁文档管理新高度!
通过本篇文章,你已经掌握了PDF文档自动化的强大能力,为你的办公自动化之旅又增添了一个重量级技能!你学会了如何利用Python的PDF处理库,高效地进行PDF文档的合并、分割、水印、页码和加密解密。

除了今天学到的PDF自动化功能,你还希望Python能帮你实现哪些更复杂的PDF处理需求?比如:自动填写PDF表单?将PDF内容智能转换为Excel或Word?在评论区分享你的需求和想法,你的建议可能会成为我们未来文章的灵感来源!
敬请期待! Word与PDF文档自动化系列圆满收官!在后续文章中,我们将继续深入Python办公自动化的宝库,探索如何利用Python实现邮件自动化,让你的邮件收发和管理工作效率翻倍!同时,本系列所有代码都将持续更新并汇总在我的GitHub仓库中,敬请关注!未来,这个**"Python职场效率专家实战包"还将包含更多开箱即用、功能强大**的自动化工具