文章目录
- python自动化
-
- 第1章:Python介绍
- 第2章:Python基础
- 第3章:流程控制
-
- 3.1:条件语句
- 3.2:课堂练习
- 3.3:循环语句
-
- [3.3.1 while语句](#3.3.1 while语句)
- 3.3.2:for语句
- 3.3.3:循环嵌套
- 3.4:跳转语句
- 第4章:字符串
- 第5章:组合数据类型
- 第6章:函数
- 第7章:文件与数据格式化
- 第8章:面向对象
- 第9章:异常
-
- 9.1:异常概述
- 9.2:异常捕获语句
- 9.3:抛出异常
-
- [9.3.1:raise语句抛出异常 、](#9.3.1:raise语句抛出异常 、)
- 9.3.2:assert语句抛出异常
- 9.3.3:异常的传递
- 9.4:自定义异常
- 实验(终)
- 系统信息模块
- [系统批量运维管理器 paramiko](#系统批量运维管理器 paramiko)
-
- [1:paramiko 的安装](#1:paramiko 的安装)
- [2:paramiko 的核心组件](#2:paramiko 的核心组件)
-
- [SSHClient 类](#SSHClient 类)
- SFTPClient类
- 实战:堡垒机模式下的远程命令执行
- 实战:实现堡垒机模式下的远程文件上传
python自动化
第1章:Python介绍
1.1Python模块
1.1.1:安装模块
bash
pip install 模块名解决超时报错:
原因:国内镜像源未设置,需要配置pip.ini
bash
python -m pip install -i https://pypi.tuna.tsinghua.edu.cn/simple --upgrade pip
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple生成pip.ini文件后,再编辑添加镜像源(在华为镜像站搜索语言类pvpip里有相关内容)
bash
[global]
timeout=40
index-url=http://mirrors.aliyun.com/pypi/simple/
extra-index-url=
https://pypi.tuna.tsinghua.edu.cn/simple/
http://pypi.douban.com/simple/
http://pypi.mirrors.ustc.edu.cn/simple/检查安装是否成功
bash
pip list第2章:Python基础
2.1代码格式
可提升代码的可读性,与其他语言不同,Python代码的格式是Python语法的组成之一,不符合格式规范 的Python代码无法正常运行。
2.1.1:注释
1)单行注释 以"#"开头,用于说明当前行或之后代码的功能。单行注释既可以单独占一行,也可以位于标识的代码之 后,与标识的代码共占一行。
bash
# 单行注释,打印Hello,Python
print("Hello,Python")建议:为了确保注释的可读性,Python官方建议"#"后面先添加一个空格,再添加相应的说明文字;若 单行注释与代码共占一行,注释和代码之间至少应有两个空格。
2)多行注释
由三对双引号或单引号包裹的语句,主要用于说明函数或类的功能。因此多行注释也被称为说明文档。
bash
'''
注释内容
'''
###############用来换行输出################
print('''hello
world''')
hello
world
print('hello
world')
hello world或者用快捷键ctrl / 快速将像中的内容注释,已经注释的内容取消注释
2.1.2 :缩进
Python代码的缩进可以通过Tab键控制,也可使用空格控制。空格是Python3首选的缩进方法,一般使 用4个空格表示一级缩进;Python3不允许混合使用Tab和空格。
2.2:标识符和关键字
命名规则:
1)标示符由字母、下划线和数字组成,且数字不能开头。
2)Python中的标识符是区分大小写的。例如,tom和Tom是不同的标识符。
3)Python中的标识符不能使用关键字 。
为了规范命名标识符,关于标识符的命名提以下建议:
1)见名知意。(姓名:name;年龄:age)
2)常量名使用大写的单个单词或由下画线连接的多个单词(ORDER_LIST_LIMIT)。
3)模块名、函数名使用小写的单个单词或由下画线连接的多个单词(low_with_under)。
4)类名使用大写字母开头的单个或多个单词。(Cat,Dog,Person)
关键字是Python已经使用的、不允许开发人员重复定义的标识符。Python3中一共有35个关键字,每个 关键字都有不同的作用。
python
import keyword
print(keyword.kwlist)
['False', 'None', 'True', 'and', 'as', 'assert', 'async', 'await', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'finally', 'for', 'from', 'global', 'if', 'import', 'in', 'is', 'lambda', 'nonlocal', 'not', 'or', 'pass', 'raise', 'return', 'try', 'while', 'with', 'yield']
import keyword
print(len(keyword.kwlist))
352.3:变量和数据类型
2.3.1:变量
变量:用拉丁字母表示的,值不固定的数据。
程序在运行期间用到的数据会被保存在计算机的内存单元中,为了方便存取内存单元中的数据,Python 使用标识符来标识不同的内存单元,如此,标识符与数据建立了联系。
2.3.2:数据类型
根据数据存储形式的不同,数据类型分为基础的数字类型和比较复杂的组合类型,其中数字类型又分为 整型、浮点型、布尔类型和复数类型;组合类型分为字符串、列表、元组、字典等。

1)列表
python
#列表:有序,可改可查,数据类型任意
list_one = []
print(type(list_one))
<class 'list'>
list_one = [10,3.14,'hello',True,[100,200,300]]
print(list_one[2])
list_one = [10,3.14,'hello',True,[100,200,300]]
print(list_one[-3])
hello
list_one = [10,3.14,'hello',True,[100,200,300]]
list_one[3] = False
print(list_one[-2])
False
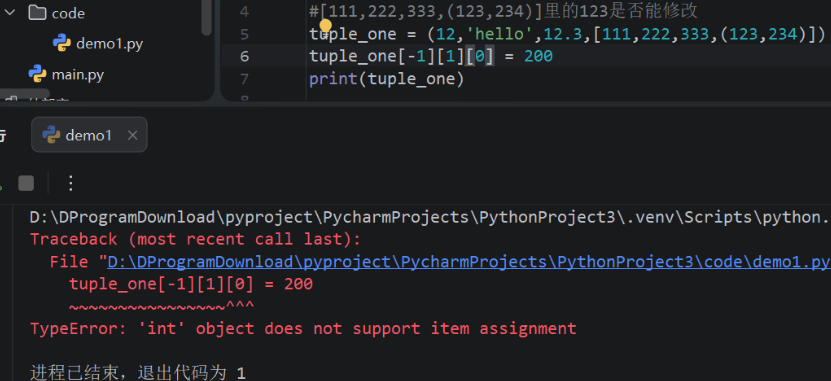
#要求将[100,200,300]中的300修改成333
list_one = [10,3.14,'hello',True,[100,200,300]]
list_one[-1][-1]= 333
print(list_one)
[10, 3.14, 'hello', True, [100, 200, 333]]2)元组
python
#元组:有序,可查不可改,数据类型任意,元组只能让一级数据无法修改,适用于数据安全场合tuple_one = (12,'hello',12.3,[111,222,333,(123,234)])
print(type(tuple_one))
print(tuple_one)
<class 'tuple'>
(12, 'hello', 12.3, [111, 222, 333, (123, 234)])
tuple_one = (12,'hello',12.3,[111,222,333,(123,234)])
print(tuple_one[-1])
[111, 222, 333, (123, 234)]
#[111,222,333,(123,234)]里的222是否能修改
tuple_one = (12,'hello',12.3,[111,222,333,(123,234)])
tuple_one[-1][1] = 200
print(tuple_one)
(12, 'hello', 12.3, [111, 200, 333, (123, 234)])
tuple_one = ()
print(type(tuple_one))
<class 'tuple'>
tuple_one = (10)
print(type(tuple_one))
<class 'int'>
tuple_one = (10,)
print(type(tuple_one))
<class 'tuple'>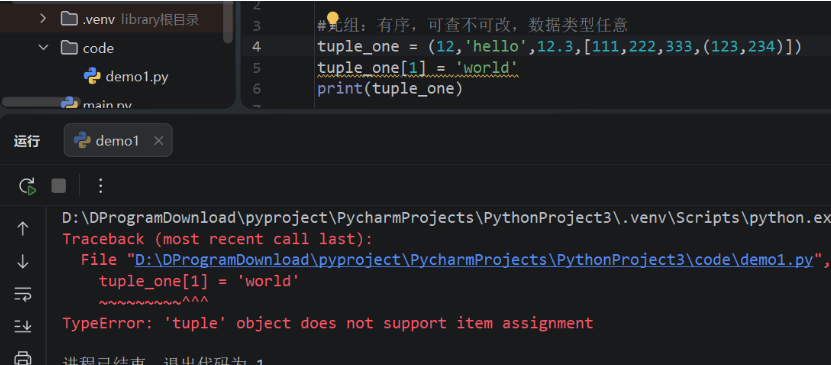
元组是无序的,所以不能使用下标定位
对于元组里的数据,如果是有序可改可查的则可以修改,但是可改可查的数据里包含的元组则不可以修改
3)集合
python
#集合:无序,可改可查,数据类型任意,不用许有重复值(去重) 场景:洗牌,数据清洗(去重)
set_one = {10,20,'hello',30,40,50}
print(type(set_one))
print(set_one)
<class 'set'>
{50, 'hello', 20, 40, 10, 30}
set_one = {10,20,'hello',30,40,50}
print(set_one[1])
#报错,集合无序,不能用索引表示
set_one = {10,20,'hello',30,40,50}
set_one.add(100)
print(set_one)
{50, 20, 100, 40, 10, 30, 'hello'}
set_one = {} #{}空的不能表示set集合类型
print(type(set_one))
<class 'dict'> #{}输出类型是字典
set_one = set() #想要生成一个空集合只能用set()
print(type(set_one))
<class 'set'>
#对于集合想要修改可以转化为字典修改,集合里的数据都是字典里的key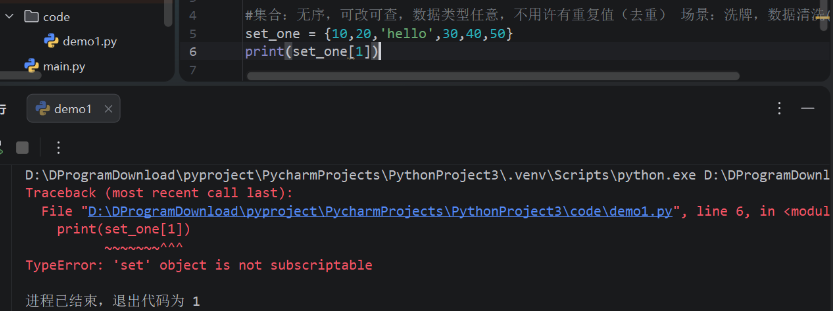
集合是无序的,所以不能使用下标定位
4)字典
python
dict_one = {'name':'jack','age':18,'score':100}
print(dict_one['name'])
jack
dict_one = {'name':'jack','age':18,'score':100}
for v in dict_one.values():
print(v)
jack
18
100
dict_one = {'name':'jack','age':18,'score':100}
for k in dict_one.keys():
print(k)
name
age
score
dict_one = {'name':'jack','age':18,'score':100}
for k,v in dict_one.items():
print(k)
print(v)
print('-'*30)
name
jack
------------------------------
age
18
------------------------------
score
100
------------------------------2.3.3:变量的输入和输出
程序要实现人机交互功能,需能从输入设备接收用户输入的数据,也需要向显示设备输出数据。
1)input函数
input()函数用于接收用户键盘输入的数据,返回一个字符串类型的数据,其语法格式如下所示:
python
input([prompt])prompt表示函数的参数,用于设置接收用户输入时的提示信息。
python
num = input('请输入:')
print(type(num))
请输入:2
<class 'str'>
#input 输入的值默认类型是str,字符串类型
#如果需要变化类型,需要强制转换
num = int(input('请输入:'))
print(type(num))
请输入:3
<class 'int'>2)print()函数
print()函数用于向控制台中输出数据,它可以输出任何类型的数据,其语法格式如下所示:
python
print(*objects, sep=' ', end='\n', file=sys.stdout)
objects:表示输出的对象。输出多个对象时,对象之间需要用分隔符分隔。
sep:用于设定分隔符,默认使用空格作为分隔。
end:用于设定输出以什么结尾,默认值为换行符\n。
file:表示数据输出的文件对象。#默认为sys.stdout标准输出到屏幕代码示例:
python
zh_name = 'zhang'
en_name = 'tom'
age = 18
print(zh_name,en_name,age,sep='\n')
zhang
tom
18
#####################################
zh_name = 'zhang'
en_name = 'tom'
age = 18
print(zh_name,en_name,age)
zhang tom 182.4:数据类型
2.4.1:整型
整数类型(int)简称整型,它用于表示整数。整型常用的计数方式有4种,分别是二制(以"0B"或"0b" 开头)、八进制(以数字"0o"或"0O"开头)、十进制和十六进制(以"0x"或"0X"开头)。
python
0b101 # 二进制
0o5 #八进制
5 #十进制
0x5 #十六进制
#对于进制之间的转换,必须要加前面的符号,不然python会识别为十进制为了方便使用各进制的数据,Python中内置了用于转换数据进制的函数:bin()、oct()、int()、hex(),关 于这些函数的功能说明如下。

代码示例:
python
num = 10
print(type(num))
<class 'int'>
##########################################
num = 10
print('将10转换成二进制:',bin(num))
print('将10转换成八进制:',oct(num))
print('将10转换成十六进制:',hex(num))
将10转换成二进制: 0b1010 #0b表示二进制
将10转换成八进制: 0o12 #0o表示八进制
将10转换成十六进制: 0xa #0x表示十六进制
print('将1101转换成十进制:',int(1101))
将1101转换成十进制: 1101
#python不知到1101是二进制必须标明清楚
print('将1101转换成十进制:',int(0b1101))
将1101转换成十进制: 132.4.2:浮点类型
浮点型(float)用于表示实数,由整数和小数部分(可以是0)组成例如,3.14、0.9等。较大或较小的 浮点数可以使用科学计算法表示。
Python程序中使用字母e或E代表底数10
bash
-3.14e2 # 即-314
3.14e-3 # 即0.00314
#####################################
num = 3.14
print(type(num))
<class 'float'>
num = 0.0
print(type(num))
<class 'float'>
num = 0
print(type(num))
<class 'int'>Python中的浮点型每个浮点型数据占8个字节(即64位),且遵守IEEE标准。Python中浮点型的取值范 围为-1.8e308~1.8e308,若超出这个范围,Python会将值视为无穷大(inf)或无穷小(-inf)。
2.4.3:复数类型
复数由实部和虚部构成,它的一般形式为:real+imagj,其中real为实部,imag为虚部,j为虚部单位。 示例如下:
python
num = complex(3,4)
print(num)
(3+4j)
num = complex(3,4)
print(num.real) #实数
print(num.imag) #虚数
3.0
4.02.4.4:布尔类型
布尔类型(bool)是一种特殊的整型,其值True对应整数1,False对应整数0。
python
None。
False。
任何数字类型的0,如0、0.0、0j。
任何空序列,如''''、()、[]。
空字典,如{}
######################################
num = True + 10
print(num)
#True等于1
11
num = False + 10
print(num)
#Fasle等于0
102.4.5:数字类型的转换
Python内置了一系列可实现强制类型转换的函数,使用这些函数可以将目标数据转换为指定的类型。数 字类型间进行转换的函数有int()、float()、complex()。需要注意的是浮点型数据转换为整型数据后只保 留整数部分。
python
num_one=2
num_two=2.2
print(int(num_two))
print(float(num_one))
print(complex(num_one))
2
2.0
(2+0j)2.5:运算符
Python运算符是一种特殊的符号,主要用于实现数值之间的运算。根据操作数数量的不同,运算符可分 为单目运算符、双目运算符;根据运算符的功能,运算符可分为算术运算符、赋值运算符、比较运算 符、逻辑运算符和成员运算符。
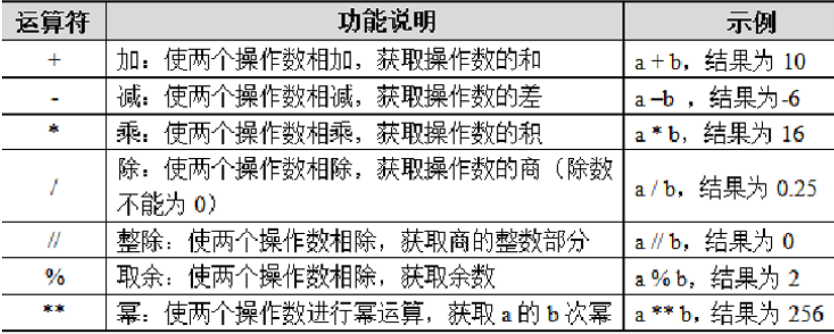
2.5.1:算术运算符
Python中的算术运算符包括+、-、*、/、//、%和**。以操作数a = 2,b = 8为例对算术运算符进行使用 说明。
Python中的算术运算符既支持对相同类型的数值进行运算,也支持对不同类型的数值进行混合运算。在 混合运算时,Python会强制将数值的类型进行临时类型转换,这些转换遵循如下原则:
bash
1:整型与浮点型进行混合运算时,将整型转化为浮点型。
2:其他类型与复数运算时,将其他类型转换为复数类型。
python
print(10/2.0)
print(10-(3+5j))
5.0
(7-5j)2.5.2:赋值运算符
赋值运算符的作用是将一个表达式或对象赋值给一个左值。左值是指一个能位于赋值运算符左边的表达 式,它通常是一个可修改的变量,不能是一个常量。
例如将整数3赋值给变量num
python
x = y = z = 1 # 变量x、y、z均赋值为1
a, b = 1, 2 # 变量a赋值为1,变量b赋值为2Python中的算术运算符可以与赋值运算符组成复合赋值运算符,赋值运算符同时具备运算和赋值两项功 能。以变量num为例, Python复合赋值运算符的功能说明及示例如下表所示:
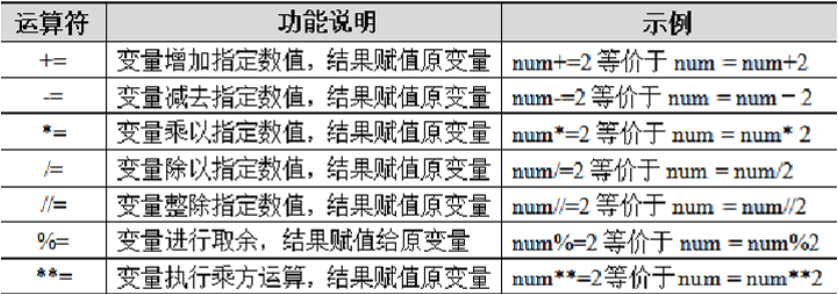
**注意:**在python中没有num++的情况,自加稚嫩那个num+=num
Python3.8中新增了一个赋值运算符------海象运算符":=",该运算符用于在表达式内部为变量赋值,因形 似海象的眼睛和长牙而得此命名。
python
num_one = 1
result = num_one + (num_two:=2)
print(result)
32.5.3:比较运算符
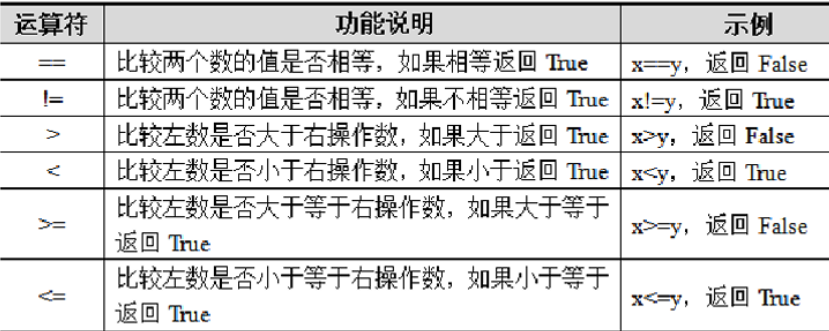
比较运算符也叫关系运算符,用于比较两个数值,判断它们之间的关系。Python中的比较运算符包括 ==、!=、>、<、>=、<=,它们通常用于布尔测试,测试的结果只能是True或False。以变量x=2,y=3为 例,具体如下:
2.5.4:逻辑运算符
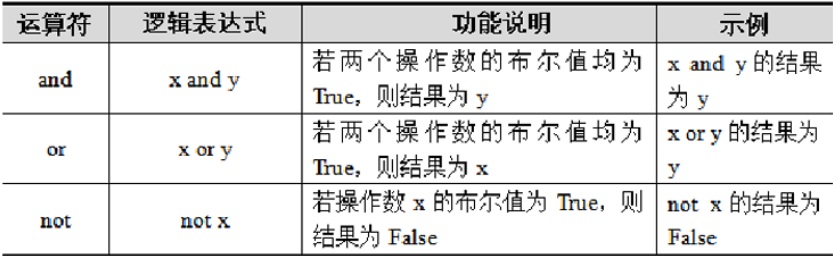
Python中分别使用"or","and","not"这三个关键字作为逻辑运算符,其中or与and为双目运算符,not 为单目运算符。以x=10,y=20为例,具体如下:
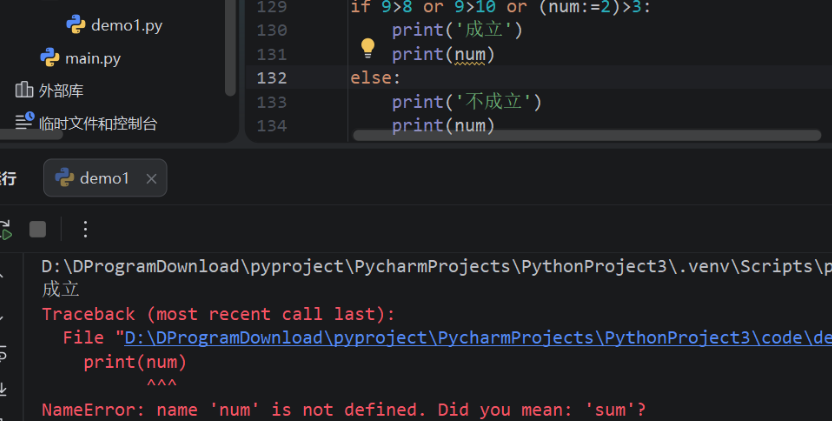
如图:执行结果显示num没有被定义,原因是对于or只需要得到一个结果是对的就不需要继续执行下面的表达式,则num:=2没有被执行就可以判断出表达式的结果了
**注意:**对于and只需要有一个表达式判断出是错误的就不需要运行,对于or只需要一个表达式判断出是正确的就不需要运行
python
score = input('请输入你的成绩:')
if score.isdigit() and 0<= int(score) <= 100:
#这里按照中文的语言应该是or,但是不能用or,对于or score.isdigit()正确就不会判断了,比如输入120,这样它不会进行下一步判断则结果错误
score = int(score)
if 90<= score <=100:
print('优秀')
elif score < 90 and score >= 80:
print('良好')
elif score < 80 and score >= 70:
print('中等')
elif score < 70 and score >= 60:
print('合格')
else:
print('不合格')
else:
print('你输入的成绩不合法,请重新输入')score.isdigit() 是判断score值是否是一个数字字符串
2.5.5:成员运算符
成员运算符in和not in用于测试给定数据是否存在于序列(如列表、字符串)中,关于它们的介绍如下:
python
in:如果指定元素在序列中返回True,否则返回False。
not in:如果指定元素不在序列中返回True,否则返回False。
python
x = "Python"
y = 't'
print(y in x)
print(y not in x)
True
False2.5.6:位运算符
位运算符用于按二进制位进行逻辑运算,操作数必须为整数。下面介绍位运算符的功能,并以a=2,b=3 为例进行演示,具体如下:
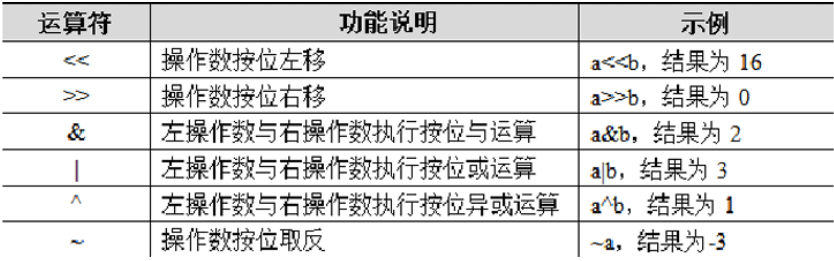
python
print(13>>2)
3
##################以下的1为真,0为假####################
& 与 必须同时为1 值才为1
| 或 必须同时为0 值才为1
^ 异或 相异才为1
~ 取反 值为符号取反再减1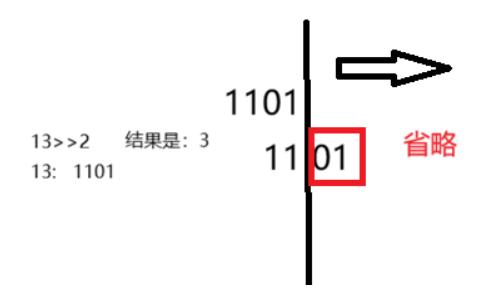
2.5.7:运算符优先级
Python支持使用多个不同的运算符连接简单表达式,实现相对复杂的功能,为了避免含有多个运算符的 表达式出现歧义,Python为每种运算符都设定了优先级。Python中运算符的优先级从高到低如下:
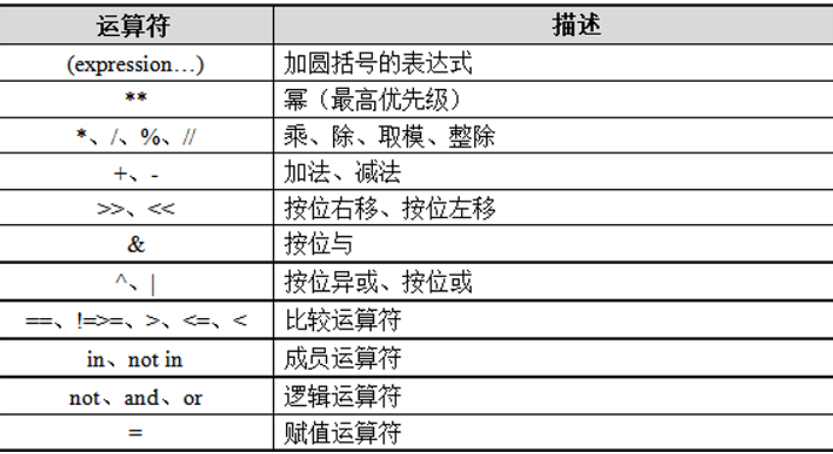
说明:如果表达式中的运算符优先级相同,按从左向右的顺序执行;如果表达式中包含
小括号,那么解 释器会先执行小括号中的子表达式
2.6:课堂练习
2.6.1:身体质量指数
BMI指数即身体健康指数,它与人的体重和身高相关,是目前国际常用的衡量人体胖瘦程度以及是否健 康的一个标准。已知BMI值的计算公式如下:
体质指数(BMI)= 体重(kg)÷身高^2(m)
本实例要求编写代码,实现根据用户输入的身高体重计算BMI指数的功能。
python
height = float(input('请输入你的身高(m):'))
weight = float(input('请输入你的体重(kg):'))
BMI = weight / (height ** 2)
if BMI < 18.5:
print(f'你的BMT为{BMI},偏瘦')
elif 18.5 <= BMI < 25:
print(f'你的BMI为{BMI},正常')
elif 25 <= BMI < 30:
print(f'你的BMI为{BMI},超重')
elif 30 <= BMI <35:
print(f'你的BMI为{BMI},肥胖')
else:
print(f'你的BMI为{BMI},过度肥胖')第3章:流程控制
程序中的语句默认自上而下顺序执行,但通过一些特定的语句可以更改语句的执行顺序,使之产生跳 跃,回溯等,进而实现流程控制。Python中用于实现流程控制的特定语句分为条件语句,循环语句和跳 转语句。
3.1:条件语句
现实生活中,大家在12306网站购票时需要先验证身份,验证通过后可进入购票页面,验证失败则需重 新验证。在代码编写工作中,大家可以使用条件语句为程序增设条件,使程序产生分支,进而有选择地 执行不同的语句。
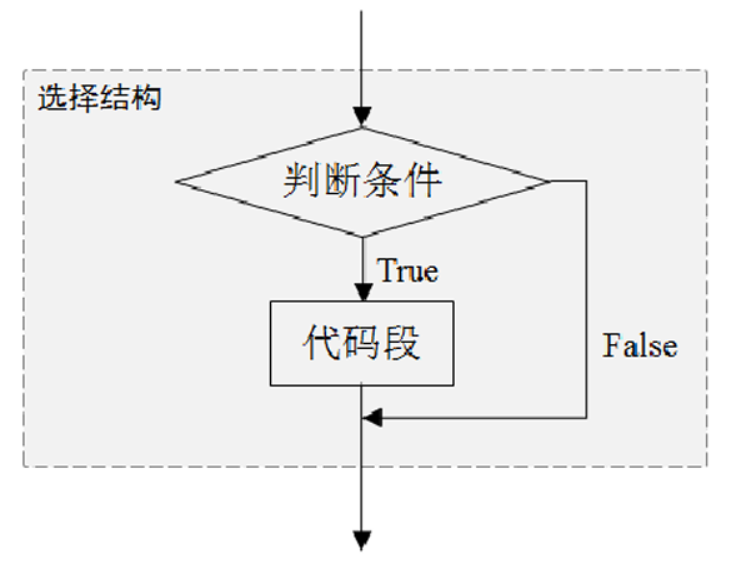
3.1.1:if语句
if语句由关键字if、判断条件和冒号组成,if语句和从属于该语句的代码段可组成选择结构。
bash
if 条件表达式:
代码块执行if语句时,若if语句的判断条件成立(判断条件的布尔值为True),执行之后的代码段;若if语句的 判断条件不成立(判断条件的布尔值为False),跳出选择结构,继续向下执行。
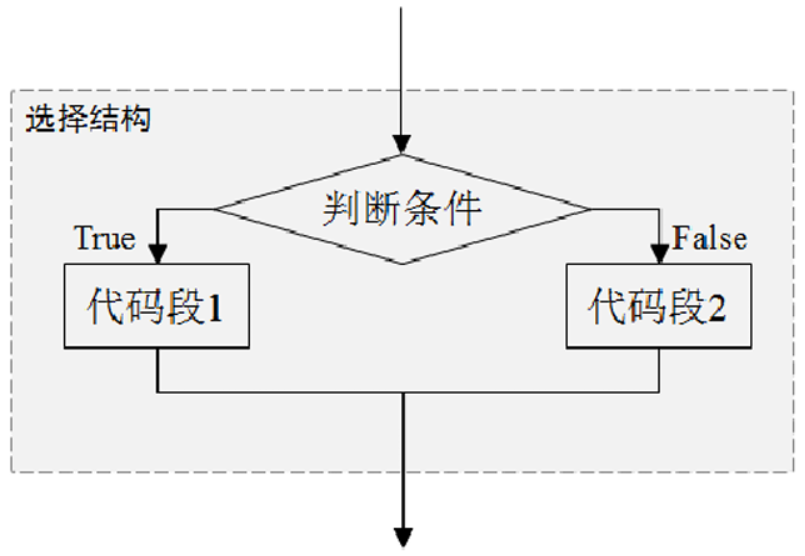
3.1.2:if-else语句
一些场景不仅需要处理满足条件的情况,也需要对不满足条件的情况做特殊处理。因此,Python提供了 可以同时处理满足和不满足条件的if-else语句。
bash
if 判断条件:
代码块1
else:
代码段2执行if-else语句时,若判断条件成立,执行if语句之后的代码段1;若判断条件不成立,执行else语句之 后的代码段2。
3.1.3:if-elif-else语句
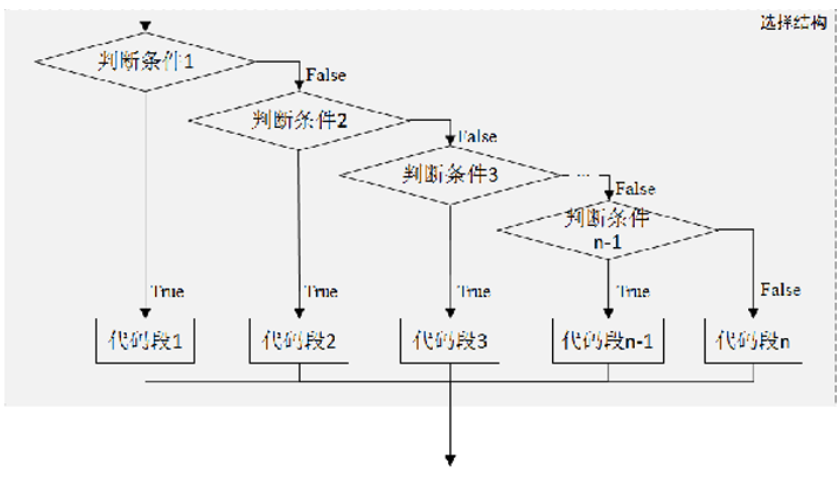
Python除了提供单分支和双分支条件语句外,还提供多分支条件语句if-elif-else。多分支条件语句用于 处理单分支和双分支无法处理的情况。
bash
if 判断条件1:
代码段1
elif 判断条件2:
代码段2
elif 判断条件3:
代码段3
...
else:
代码段n执行if-elif-else语句时,若if条件成立,执行if语句之后的代码段1;若if条件不成立,判断elif语句的判断 条件2:条件2成立则执行elif语句之后的代码段2,否则继续向下执行。以此类推,直至所有的判断条件 均不成立,执行else语句之后的代码段。
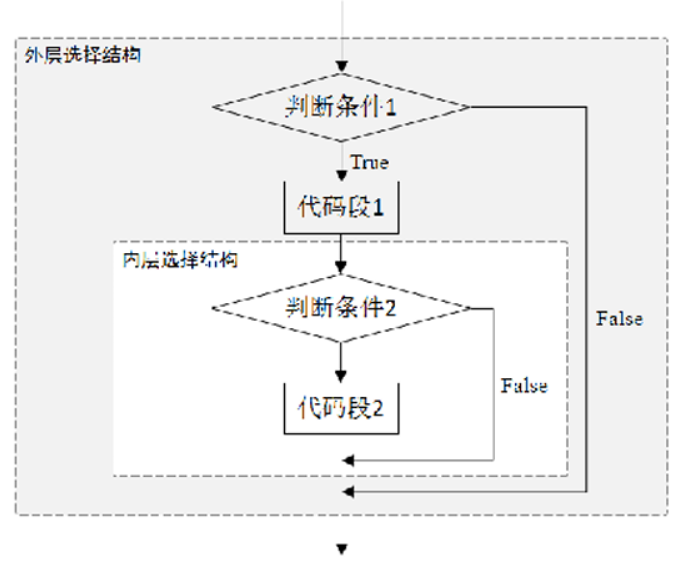
3.1.4:if嵌套
bash
if 判断条件1:
代码段1
if 判断条件2:
代码段2
...执行if嵌套时,若外层判断条件(判断条件1)的值为True,执行代码段1,并对内层判断条件(判断条 件2)进行判断:若判断条件2的值为True,则执行代码段2,否则跳出内层条件结构,顺序执行外层条 件结构中内层条件结构之后的代码;若外层判断条件的值为False,直接跳过条件语句,既不执行代码段 1,也不执行内层的条件结构。
案例:1年有12个月份,每个月的总天数具有一定的规律,1月,3月,5月,7月,8月,10月,12月有 31天,4月,6月,9月,11月有30天;2月的情况稍微复杂些,闰年的2月有29天,平年的2月有28天。 本示例要求根据年份和月份计算当月的天数。
python
year = int(input('请输入你所需要查询的年份:'))
mouth = int(input('请输入你所需要查询的月份:'))
if year % 4 == 0 and year % 100 != 0 or year % 400 == 0:
if mouth in [1,3,5,7,8,10,12]:
print('该月份的天数为:31')
elif mouth in [4,6,9,11]:
print('该月份的天数为:30')
else:
print('该月份的天数为:28')
else:
if mouth in [1,3,5,7,8,10,12]:
print('该月份的天数为:31')
elif mouth in [4,6,9,11]:
print('该月份的天数为:30')
else:
print('该月份的天数为:29')
###################################################
year = int(input('请输入你所需要查询的年份:'))
mouth = int(input('请输入你所需要查询的月份:'))
if mouth in [1,3,5,7,8,10,12]:
print('%d月有31天'%mouth)
elif mouth in [4,6,9,11]:
print('%d月有30天' %mouth)
else:
if year % 4 == 0 and year % 100 != 0 or year % 400 == 0:
print('2月有28天')
else:
print('2月有29天')
请输入你所需要查询的年份:2014
请输入你所需要查询的月份:2
2月有29天3.2:课堂练习
猜价格的游戏,随机生成一个价格,输入你的猜测,如果猜小了,提示猜小了,反之也是,猜对了,输出猜对了和猜的次数并退出。
bash
import random
price = random.randint(1,100) #可以取到1到100的任意整数
count = 0
while True: #死循环
guess = int(input('请输入你的猜测值:'))
count += 1
if guess < price:
print('猜小了')
elif guess > price:
print('猜大了')
else:
print('猜对了,一共猜了%d次' %count)
break #退出循环
#或者在循环外面写一共猜测的次数
print(f'一共猜测了{count}次')3.3:循环语句
现实生活中存在很多重复的事情,例如,地球一直围绕太阳不停地旋转;月球始终围绕地球旋转;每年 都会经历司机的更替;每天都是从白天到黑夜的过程,程序开发中同样可能出现代码的重复执行。 Python提供循环语句,使用该语句能以简洁的代码实现重复操作。
3.3.1 while语句
while语句一般用于实现条件循环,该语句由关键字while、循环条件和冒号组成,while语句和从属于该 语句的代码段组成循环结构。
bash
while 条件表达式:
代码块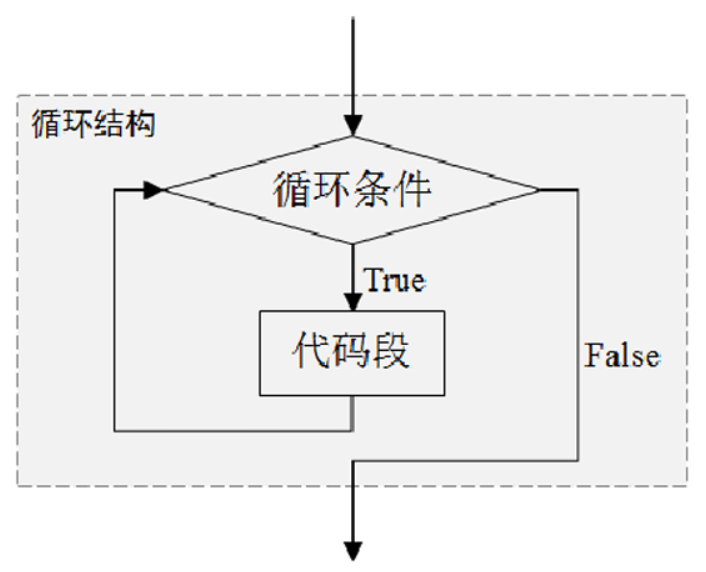
3.3.2:for语句
for语句一般用于实现遍历循环。遍历指逐一访问目标对象中的数据,例如逐个访问字符串中的字符;遍 历循环指在循环中完成对目标对象的遍历。
bash
for 临时变量 in 目标对象:
代码块
for i in range(起始值,终点值,步长) 起始值<=i<终点值 3.3.3:循环嵌套
逢7拍手游戏的规则是:从1开始顺序数数,数到有7或者包含7的倍数的时候拍手。本实例要求编写代 码,模拟实现逢七拍手游戏,实现输出100以内需要拍手的数字的程序。
python
for i in range(1,101):
if i != 100:
shi = i/10
ge = i%10
if i % 7 == 0 or shi == 7 or ge == 7:
print(i,end=' ')圣诞树模型
python
*
* *
* * *
* * * *
* * * * *
for j in range(1,6):
for i in range(j):
print('*',end=' ')
print()
* * * * *
* * * *
* * *
* *
*
for j in range(5,0,-1):
for i in range(j):
print('*',end=' ')
print()
*
* * *
* * * * *
* * * * * * *
* * * * * * * * *
for j in range(1,6):
for i in range(6-j):
print('#',end=' ') #防止空格看不清,所以用#代替
for k in range(2*j-1):
print('*',end=' ')
print()
*
* * *
* * * * *
* * * * * * *
* * * * * * * * *
*
* * *
* * * * *
* * * * * * *
* * * * * * * * *
for j in range(1,6):
for i in range(6-j):
print(' ',end=' ')
for k in range(2*j-1):
print('*',end=' ')
print()
for j in range(1,6):
for i in range(6-j):
print(' ',end=' ')
for k in range(2*j-1):
print('*',end=' ')
print()
*
* * *
* * * * *
* * * * * * *
* * * * * * * * * #将左侧的空格想象成倒着的三角形
* * * * * * *
* * * * *
* * *
*
for j in range(1,6):
for i in range(6-j):
print(' ',end=' ')
for k in range(2*j-1):
print('*',end=' ')
print()
for j in range(4,0,-1):
for i in range(6-j):
print(' ',end=' ')
for k in range(2*j-1):
print('*',end=' ')
print()逢7拍手游戏的规则是:从1开始顺序数数,数到有7或者包含7的倍数的时候拍手。本实例要求编写代 码,模拟实现逢七拍手游戏,实现输出100以内需要拍手的数字的程序。
python
for i in range(1,101):
if i != 100:
shi = i/10
ge = i%10
if i % 7 == 0 or shi == 7 or ge == 7:
print(i,end=' ')3.4:跳转语句
循环语句在条件满足的情况下会一直执行,但在某些情况下需要跳出循环,例如,实现音乐播放器循环 模式的切歌功能等。Python提供了控制循环的跳转语句:break和continue。
3.4.1:break语句
break语句用于结束循环,若循环中使用了break语句,程序执行到break语句时会结束循环;若循环嵌 套使用了break语句,程序执行到break语句时会结束本层循环。
案例:在使用for循环遍历字符串'Python'时,遍历到字符'o'就使用break语句结束循环。
python
for i in 'python':
if i == 'o':
break
print(i,end=' ')
p y t h 3.4.2:continue语句
continue语句用于在满足条件的情况下跳出本次循环,该语句通常也与if语句配合使用。
案例:在使用for循环遍历字符串'Python'时,遍历到字符'o'就使用continue语句跳出本次循环。
python
for i in 'python':
if i == 'o':
continue
print(i,end=' ')
p y t h n案例:进5家商店,每家商店都有鞋子,衣服,裤子,帽子
1衣服:200
2鞋子:180
3帽子:20
4裤子:150
是否进入这家商店(yes/no),是否进行购物(yes/no),购物商品序号,购物数量,要求最后输出总消费金额和分别购买的衣服鞋子裤子帽子的个数。
python
clothes,shoes,hat,pants = 200,180,20,150
sum=count_1=count_2=count_3=count_4=0
for i in range(5):
choice_1 = input('请选择是否进入该店(yes/no):')
if choice_1=='yes':
print(f'现在进入了第{i + 1}家店')
while True:
choice_2=input('请选择是否在该店继续购买(yes/no):')
if choice_2=='yes':
print('商品列表:\n1:衣服\n2:鞋子\n3:帽子\n4:裤子')
choice_3=int(input('请选择你所购买的商品序列号:'))
if choice_3==1:
sum += clothes
count_1+=1
elif choice_3==2:
sum += shoes
count_2+=1
elif choice_3==3:
sum += hat
count_3+=1
else:
sum += pants
count_4+=1
else:
break
else:
print(f'已经跳过了第{i + 1}家店')
continue
print(f'总消费金额为:{sum},衣服买了{count_1}件,鞋子买了{count_2}双,帽子买了{count_3}顶,裤子买了{count_4}条')
python
#九九乘法表
for j in range(1,10):
for i in range(1,j+1):
print(f'{j}x{i}={j*i}',end='\t') #\t相当于键盘的tab键
print()
#######################################################################
1x1=1
2x1=2 2x2=4
3x1=3 3x2=6 3x3=9
4x1=4 4x2=8 4x3=12 4x4=16
5x1=5 5x2=10 5x3=15 5x4=20 5x5=25
6x1=6 6x2=12 6x3=18 6x4=24 6x5=30 6x6=36
7x1=7 7x2=14 7x3=21 7x4=28 7x5=35 7x6=42 7x7=49
8x1=8 8x2=16 8x3=24 8x4=32 8x5=40 8x6=48 8x7=56 8x8=64
9x1=9 9x2=18 9x3=27 9x4=36 9x5=45 9x6=54 9x7=63 9x8=72 9x9=81 第4章:字符串
不可变可迭代对象
4.1:字符串介绍
字符串是由字母、符号或者数字组成的字符序列。
Python支持使用单引号、双引号和三引号定义字符串,其中单引号和双引号通常用于定义单行字符串, 三引号通常用于定义多行字符串。
扩展:一些普通字符与反斜杠组合后将失去原有意义,产生新的含义。类似这样的由"\"和而成的、具有 特殊意义的字符就是转义字符。转移字符通常用于表示一些无法显示的字符,例如空格、回车等。
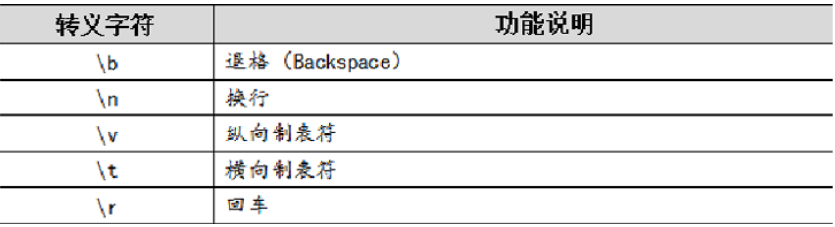
如果想要转义符只是单纯的输出没有其他的意思
bashprint('hello\nword') hello word print(r'hello\nword') hello\nword
4.2:格式化字符串
4.2.1:使用%格式化字符串
字符串具有一种特殊的内置操作,它可以使用%进行格式化。
bash
format % valuesformat:表示一个字符串,该字符串中包含单个或多个为真实数据占位的格式符;
values:表示单个或多个真实数据;
%:代表执行格式化操作,即将format中的格式符替换为values。
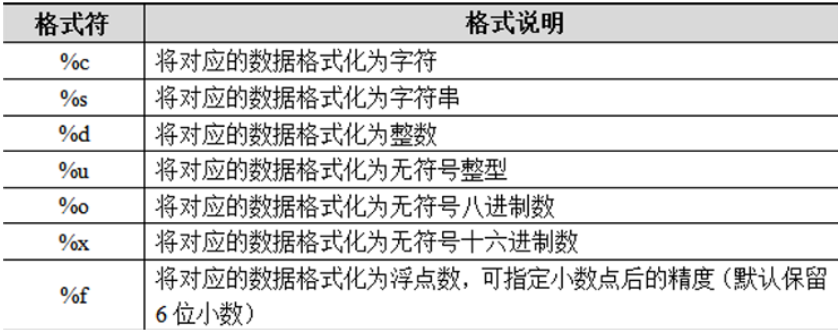
不同的格式符为不同类型的数据预留位置,常见的格式符如下所示。
bash
age = 20
print("我今年%d岁" %age)
我今年20岁
name = '小舞'
age = 20
print("我是%s今年%d岁" %(name,age))
我是小舞今年20岁、4.2.2:使用format()方法格式化字符串
bash
str.format(values)
bash
name = '小舞'
age = 20
print("我是{0}今年{1}岁".format(name, age))
name = '小舞'
age = 20
print("我是{}今年{}岁".format(name, age)) #默认从0开始按顺序
name = '小舞'
age = 20
print("我是{a}今年{b}岁".format(a=name, b=age))4.2.3:使用f-string格式化字符串
f-string提供了一种更为简洁的格式化字符串的方式,它在形式上以f或F引领字符串,在字符串中使用 "{变量名}"标明被替换的真实数据和其所在位置。
bash
f('{变量名}') 或者 F('{变量名}')
bash
name = '小舞'
age = 20
print(f"我是{name}今年{age}岁")4.3:字符串的常见操作
字符串的操作在实际应用中非常常见,Python内置了很多字符串方法,使用这些方法可以轻松实现字符 串的查找,替换,拼接,大小写转换等操作。但需要注意的是,字符串一但创建便不可修改;若对字符 串进行修改,就会生成新的字符串。
4.3.1:字符串的查找与替换
1)查找 :Python中提供了实现字符串查找操作的find()方法,该方法可查找字符串中是否包含子串,若 包含则返回子串首次出现的位置,否则返回-1。
bash
#字符串下标是从0开始的,空格和逗号都占位
strings = 'life is use, python'
print(len(strings))
print(strings[2])
print(strings.find('s'))
19
f
6
strings = 'life is use, python'
print(strings.find('use')) #查找单词显示的位置是单词首字母出现的位置
8
#查找字符串值查找的第一个字符的位置,如果没有匹配到就会输出-1
strings = 'life is use, python'
print(strings.find('use'))
print(strings.find('pythen'))
#单词的每个字母都会匹配,有一个字母没有相连找到都会返回-1
print(strings.find('a'))
8
-1
-12)替换:Python中提供了实现字符串替换操作的replace()方法,该方法可将当前字符串中的指定子串 替换成新的子串,并返回替换后的新字符串。
bash
#替换replace() str.replace(old, new, count)
word = """八百标兵奔北坡,北坡炮兵并排跑。炮兵怕把标兵碰,标兵怕碰炮兵炮。"""
new_string = word.replace("标兵", "战士")
print(new_string)
#不表明count数,默认是全文匹配替换
八百战士奔北坡,北坡炮兵并排跑。炮兵怕把战士碰,战士怕碰炮兵炮。
word = """八百标兵奔北坡,北坡炮兵并排跑。炮兵怕把标兵碰,标兵怕碰炮兵炮。"""
new_string = word.replace("标兵", "战士",2)
print(new_string)
八百战士奔北坡,北坡炮兵并排跑。炮兵怕把战士碰,标兵怕碰炮兵炮。4.3.2:字符串的分割与拼接
1)字符串分割
split()方法可以按照指定分隔符对字符串进行分割,该方法会返回由分割后的子串组成的列表。
bash
str.split(sep=None, maxsplit=-1)
`sep 分割的标志 maxsplit分割次数`
bash
#分割split() 默认是以空格为分隔符,输出为列表的形式,默认分割次数为-1即不限分割次数
word = """八百标兵奔北坡 北坡炮兵并排跑 炮兵怕把标兵碰 标兵怕碰炮兵炮。"""
print(word.split())
print(word.split('兵'))
print(word.split('兵',2))
['八百标兵奔北坡', '北坡炮兵并排跑', '炮兵怕把标兵碰', '标兵怕碰炮兵炮。']
['八百标', '奔北坡 北坡炮', '并排跑 炮', '怕把标', '碰 标', '怕碰炮', '炮。']
['八百标', '奔北坡 北坡炮', '并排跑 炮兵怕把标兵碰 标兵怕碰炮兵炮。']2)字符串拼接
join()方法使用指定的字符连接字符串并生成一个新的字符串。join()方法的语法格式如下。
bash
str.join(iterable)
bash
#字符串拼接方法 join() (拼接字符).join(需要拼接的字符串)
symbol = '-'
word = 'python'
print(symbol.join(word))
print('-'.join('java'))
p-y-t-h-o-n
j-a-v-a
##########################################
#如果分隔符和字符串的位置写反则会输出单个分割符
symbol = '-'
word = 'python'
print(word.join(symbol))
-Python中还可以使用运算符'+'和'*'连接字符串,代码示例
bash
start = 'pyt'
end = 'hon'
print(start + end)
print(start*3)
python
pytpytpyt4.3.3:删除字符串的指定字符
字符串中可能会包含一些无用的字符(如空格),在处理字符串之前往往需要先删除这些无用的字符。 Python中的strip()、lstrip()和rstrip()方法可以删除字符串中的指定字符。

bash
word = ' life is sort ,i use Python '
print(word)
print(word.strip()) #默认删除字符是空格
life is sort ,i use Python
life is sort ,i use Python
word = '*life is sort ,i use Python*'
print(word.strip('*')) #删除头尾字符只能是相同字符
print(word.lstrip('*'))
print(word.rstrip('*'))
life is sort ,i use Python
life is sort ,i use Python*
*life is sort ,i use Python4.3.4:字符串大小写转换
在特定情况下会对英文单词的大小写形式进行要求,表示特殊简称时全字母大写,如CBA;表示月份、 周日、节假日时每个单词首字母大写,如Monday。Python中支持字母大小写转换的方法有upper()、 lower()、capitalize()和title()。

bash
#大小写 upper()全部大写 lower()全部小写 capitalize()字符串的第一个单词首字母大写,其他字母全小写 title()每个单词首字母大写,其他字母全小写
string = 'life is short. I use Python'
print(string.upper())
print(string.lower())
print(string.capitalize()) #只有字符串的第一个单词首字母大写
print(string.title())
LIFE IS SHORT. I USE PYTHON
life is short. i use python
Life is short. i use python
Life Is Short. I Use Python4.3.5:字符串对齐
在使用Word处理文档时可能需要对文档的格式进行调整,如标题居中显示、左对齐、右对齐等。 Python提供了center()、ljust()、rjust()这3个方法来设置字符串的对齐方式。
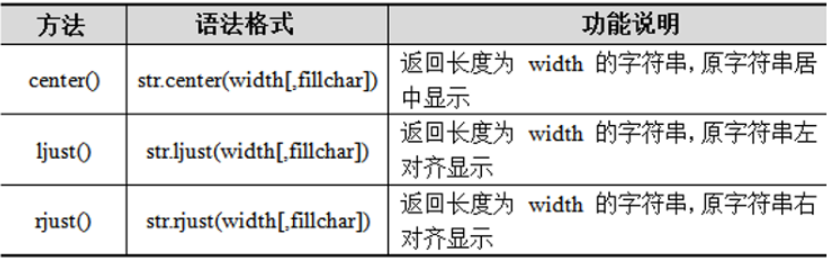
bash
#字符串对其,center(宽度,填充字符)居中对齐 ljust()左对齐 rjust()右对齐
string = 'hello world'
print(len(string))
print(string.center(15,'-'))
print(string.ljust(15,'-'))
print(string.rjust(15,'-'))
11
--hello world--
hello world----
----hello world第5章:组合数据类型
5.1:认识组合数据类型
组合数据类型可将多个相同类型或不同类型的数据组织为一个整体,根据数据组织方式的不同,Python 的组合数据类型可分成三类:序列类型、集合类型和映射类型。
1)序列类型
Python中常用的序列类型有字符串(str)、列表(list)和元组(tuple)。
字符串和元组都是不可变变量,但是有索引
2)集合类型
Python集合具备确定性、互异性和无序性三个特性。
Python要求放入集合中的元素必须是不可变类型,Python中的整型、浮点型、字符串类型和元组属于不 可变类型,列表、字典及集合本身都属于可变的数据类型。
- 确定性:给定一个集合,那么任何一个元素是否在集合中就确定了。
- 互异性:集合中的元素互不相同。
- 无序性:集合中的元素没有顺序,顺序不同但元素相同的集合可视为同一集合。
3)映射类型
映射类型以键值对的形式存储元素,键值对中的键与值之间存在映射关系。
字典(dict)是Python唯一的内置映射类型,字典的键必须遵守以下两个原则:
- 每个键只能对应一个值,不允许同一个键在字典中重复出现。
- 字典中的键是不可变类型。
5.2:列表
Python利用内存中的一段连续空间存储列表。列表是Python中最灵活的序列类型,它没有长度限制,可 以包含任意元素。开发人员可以自由的对列表中的元素进行各种操作包括访问、添加、排序、删除。
判断可迭代行
bash
#判断可迭代性
from collections.abc import Iterable
ls = [3,4,5]
print(isinstance(ls,Iterable))5.2.1:创建列表
bash
#创建方法:
list_one = []
list_two = list()
print(type(list_one))
print(type(list_two)5.2.2:访问列表元素
bash
list[起始索引,结束索引,步长]
bash
list_char = ['w','o','r','l','d']
#遍历,取r这个字符
print(list_char[2])
#[起始下标:结束下标:步长],结束下标取不到
#切片,取o到l
print(list_char[1:4])
#取r到d
print(list_char[2:5])
print(list_char[2:])
#取w到r
print(list_char[:3])
#取整体
print(list_char[:])
#取w,r,d
print(list_char[::2])
#取w,l
print(list_char[::3])
r
['o', 'r', 'l']
['r', 'l', 'd']
['r', 'l', 'd']
['w', 'o', 'r']
['w', 'o', 'r', 'l', 'd']
['w', 'r', 'd']
['w', 'l']5.2.3:添加列表元素
向列表中添加元素是非常常见的一种列表操作,Python提供了append()、extend()和insert()这几个方法 向列表末尾、指定位置添加元素。
1)append()方法
在列表末尾添加新的元素
bash
list_one = [10,20]
list_one.append(30)
print(list_one)
[10, 20, 30]2)extend()方法
在列表末尾一次性添加另一个列表中的所有元素,即使用新列表扩展原来的列表。
bash
list_one = [10,20]
list_two = [30,40,50]
list_one.extend(list_two)
print(list_one) #只改变list_one的内容
print(list_two)
[10, 20, 30, 40, 50]
[30, 40, 50]3)insert()方法
按照索引将新元素插入列表的指定位置。
bash
list_one = [10,20]
list_one.insert(1,15)
print(list_one)
[10, 15, 20]
#每插入一次索引的位置就变化一次
list_one = [10,20]
list_one.insert(1,15)
list_one.insert(2,25)
print(list_one)
[10, 15, 25, 20]5.2.4:元素排序
列表的排序是将元素按照某种规定进行排列。列表中常用的排序方法有sort()、reverse()、sorted()。
1)sort()方法
按特定顺序对列表元素排序,语法如下
bash
sort(key=None,reverse=False) #默认是正序
bash
#元素排序
#sort()
list_one = [10,20,30,12,34,9]
list_one.sort()
print(list_one)
[9, 10, 12, 20, 30, 34]
list_one = [10,20,30,12,34,9]
list_one.sort(reverse=True)
print(list_one)
[34, 30, 20, 12, 10, 9]
li_three = ['python','java','php']
li_three.sort(key=len) #按照字符串长度排序
print(li_three)
['php', 'java', 'python']
li_three = ['python','java','php']
li_three.sort()
print(li_three)
#字符串默认排序是按照英文字母的先后
['java', 'php', 'python']2)sorted()方法
按升序排列列表元素,该方法的返回值是升序排列后的新列表,排序操作不会对原列表产生影响。
bash
#不改变源列表,重新生成列表
list_one = [10,20,30,12,34,9]
list_two = sorted(list_one)
print(list_one) #生成新的列表,不改变原来的列表,相当于函数
print(list_two)
[10, 20, 30, 12, 34, 9]
[9, 10, 12, 20, 30, 34]3)reverse()方法
用于逆置列表,即把原列表中的元素从右至左依次排列存放。
bash
list_one = [10,20,30,12,34,9]
list_one.reverse()
print(list_one)
[9, 34, 12, 30, 20, 10]5.2.5:删除列表元素
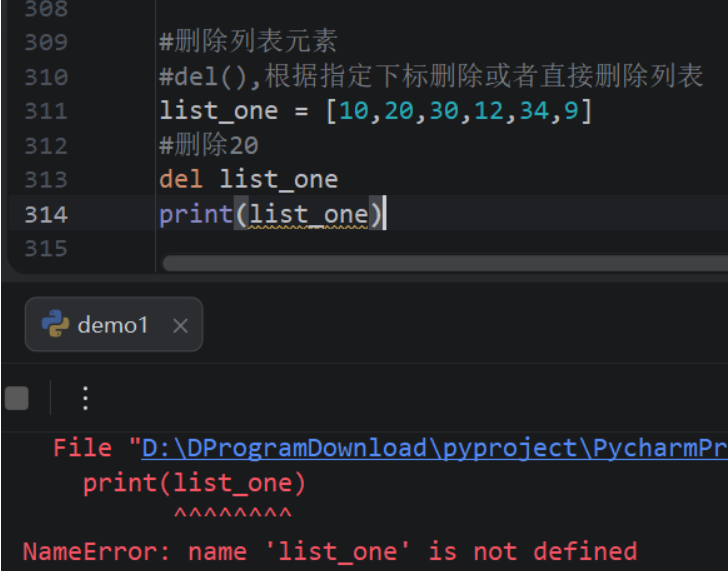
删除列表元素的常用方式有del语句、remove()方法、pop()方法和clear()方法。
1)del语句
用于删除列表中指定位置的元素。
bash
#删除列表元素
#del(),根据指定下标删除或者直接删除列表
list_one = [10,20,30,12,34,9]
#删除20
del list_one[1]
print(list_one)
[10, 30, 12, 34, 9]2)remove()方法
用于移除列表中的某个元素,若列表中有多个匹配的元素,remove()只移除匹配到的第1个元素。
bash
#remove(),直接指定删除值
list_one = [9,10,20,30,12,34,9]
list_one.remove(9)
print(list_one)
[10, 20, 30, 12, 34, 9]3)pop()方法
用于移除列表中的某个元素,若未指定具体元素,则移除列表中的最后1个元素。
bash
#pop() 删除指定的元素,如果空格里没有值,则会默认删除最后一项
list_one = [10,20,30,12,34,9]
print(list_one.pop()) #会返回带走的值
print(list_one.pop(1))
print(list_one)
9
20
[10, 30, 12, 34]4)clear()方法
用于清空列表。
bash
#clear()清空列表,不等于删除列表
list_one = [10,20,30,12,34,9]
list_one.clear()
print(list_one)
[]5.2.6:列表推导式
列表推导式是符合Python语法规则的复合表达式,它用于以简洁的方式根据已有的列表构建满足特定需 求的列表。
python
list_one = [1,2,3,4,5]
list_two = []
for i in list_one:
list_two.append(i**2)
print(list_two)
[1, 4, 9, 16, 25]
list_one = [1,2,3,4,5]
list_two = [i**2 for i in list_one]
print(list_two)
[1, 4, 9, 16, 25]**注意:**del是删除列表,删除后就不存在,clear()是清空列表的元素
5.3:元组
元组的表现形式为一组包含在圆括号"()"中、由逗号分隔的元素,元组中元素的个数、类型不受限制。 使用圆括号可以直接创建元组,还可以使用内置函数tuple()构建元组。
bash
tuple_one = ()
tuple_two = (10)
tuple_three = (10,)
print(type(tuple_one))
print(type(tuple_two))
print(type(tuple_three))
<class 'tuple'>
<class 'int'> #对于元组内只有一个元素,必须加上,否则只会显示该元素的数据类型
<class 'tuple'>元组是可查不可改,查询使用索引查询,想修改的话可以将它转化成列表类型
5.4:实训案例
**案例:**获取跳水运动员的10个评分,将评委的所有分数列出来,并去掉最大值和最小值求成绩的平均值
python
score = input('请输入10个教练的评分:')
score_list = score.split(',')
max = int(score_list[0])
min = int(score_list[0])
sum_score = 0
for i in range(1,len(score_list)):
score_list[i] = int(score_list[i])
if score_list[i] > max:
max = score_list[i]
for j in range(1,len(score_list)):
score_list[j] = int(score_list[j])
if score_list[j] < min:
min = score_list[j]
print('每个评委的打分分别是:')
for k in range(0,len(score_list)):
score_list[k] = int(score_list[k])
print(score_list[k],end=' ')
if score_list[k] != min and score_list[k] != max:
sum_score += score_list[k]
avg_score = sum_score/(len(score_list)-2)
print('\n去掉最大最小值的平均分为:',avg_score)
#######################优化后的#########################
score_list = []
sum = 0
for i in range(1,11):
score_list.append(int(input('请输入第'+str(i)+'评委的打出成绩:')))
for j in range(0,len(score_list)):
if score_list[j] != max(score_list) and score_list[j] != min(score_list):
sum += score_list[j]
print('平均值为:',sum/(len(score_list)-2))
########################或者#############################
score_list = []
sum = 0
for i in range(1,11):
score_list.append(int(input('请输入第'+str(i)+'评委的打出成绩:')))
for j in score_list:
if j == max(score_list) or j == min(score_list):
continue
else:
sum += j
print('平均值为:',sum/(len(score_list)-2))冒泡排序
python
list_one = []
num = int(input('请输入你需要排序的数的个数:'))
for k in range(1,num+1):
list_one.append(int(input('请输入第'+str(k)+'需要排序的值:')))
count = 0
for i in range(num-1):
for j in range(1,len(list_one)-i):
if list_one[j] < list_one[j-1]:
list_one[j], list_one[j-1] = list_one[j-1], list_one[j]
count += 1
print(list_one)
print(count)
请输入你需要排序的数的个数:5
请输入第1需要排序的值:13
请输入第2需要排序的值:12
请输入第3需要排序的值:14
请输入第4需要排序的值:11
请输入第5需要排序的值:15
[11, 12, 13, 14, 15]
4成绩录入查询系统
录入成绩(录入,姓名,三门课成绩:已存在的姓名无法录入)
查询成绩(查看全部成绩:查看个人成绩,加入不存在不提示)
修改成绩(能够单独修改每一门课的成绩)
删除成绩(按照姓名删除个人全部信息)
python
info = [['张飞',67,68,69],['刘备',78,79,70]]
subject = ['姓名','语文','数学','英语']
while True:
print('1:录入成绩\n2:查询成绩\n3:修改成绩\n4:删除成绩\n5:退出系统')
choice_1 =int(input('请输入选项:'))
if choice_1 ==5:
print('退出系统')
break
else:
if choice_1 == 1:
tmp = []
tmp.append(input('请输入你的姓名:'))
tmp.append(int(input('请输入你的语文成绩:')))
tmp.append(int(input('请输入你的数学成绩:')))
tmp.append(int(input('请输入你的英语成绩:')))
info.append(tmp)
print(info)
elif choice_1 == 2:
print('1:查看全部信息 2:查看个人信息')
choice_2 = int(input('请选择选项:'))
if choice_2 == 1:
for i in subject:
print(i,end=' ')
print()
for j in range(0,len(info)):
for k in info[j]:
print(k,end=' ')
print()
else:
name = input('请输入查询姓名:')
for a in range(0,len(info)):
if name in info[a][0]:
for b in subject:
print(b, end=' ')
print()
for c in info[a]:
print(c,end=' ')
print()
elif choice_1 == 3:
for i in subject:
print(i, end=' ')
print()
for j in range(0, len(info)):
for k in info[j]:
print(k, end=' ')
print()
name = input('请输入需要修改成绩的姓名:')
print('1:语文 2:数学 3:英语')
sub_type = int(input('请输入课程类型:'))
score = int(input('请输入要修改的成绩:'))
for a in range(0, len(info)):
if name in info[a][0]:
info[a][sub_type] = score
print('修改成功')
else:
for i in subject:
print(i, end=' ')
print()
for j in range(0, len(info)):
for k in info[j]:
print(k, end=' ')
print()
name = input('请输入姓名:')
for a in range(0, len(info)):
if name in info[a][0]:
del info[a]
print('删除成功')
##################################优化后的###################################
info = [['张飞',67,68,69],['刘备',78,79,70]]
subject = ['姓名','语文','数学','英语']
while True:
print('1:录入成绩\n2:查询成绩\n3:修改成绩\n4:删除成绩\n5:退出系统')
choice_1 =int(input('请输入选项:'))
if choice_1 ==5:
print('退出系统')
break
else:
if choice_1 == 1:
tmp = []
name = input('请输入你的姓名:')
found = False
for a in range(0, len(info)):
if name in info[a][0]:
found = True
print('改成绩已经存在')
if not found:
tmp.append(name)
tmp.append(int(input('请输入你的语文成绩:')))
tmp.append(int(input('请输入你的数学成绩:')))
tmp.append(int(input('请输入你的英语成绩:')))
info.append(tmp)
print(info)
elif choice_1 == 2:
print('1:查看全部信息 2:查看个人信息')
choice_2 = int(input('请选择选项:'))
if choice_2 == 1:
for i in subject:
print(i,end=' ')
print()
for j in range(0,len(info)):
for k in info[j]:
print(k,end=' ')
print()
else:
name = input('请输入查询姓名:')
found = False
for a in range(0,len(info)):
if name in info[a][0]:
found = True
for b in subject:
print(b, end=' ')
print()
for c in info[a]:
print(c,end=' ')
print()
if not found:
print('你查询的姓名不存在!')
elif choice_1 == 3:
for i in subject:
print(i, end=' ')
print()
for j in range(0, len(info)):
for k in info[j]:
print(k, end=' ')
print()
name = input('请输入需要修改成绩的姓名:')
print('1:语文 2:数学 3:英语')
sub_type = int(input('请输入课程类型:'))
score = int(input('请输入要修改的成绩:'))
for a in range(0, len(info)):
if name in info[a][0]:
info[a][sub_type] = score
print('修改成功')
else:
for i in subject:
print(i, end=' ')
print()
for j in range(0, len(info)):
for k in info[j]:
print(k, end=' ')
print()
name = input('请输入姓名:')
for a in range(0, len(info)):
if name in info[a][0]:
del info[a]
print('删除成功')
##################################再次优化###################################
menu = '''
1.录入成绩
2.查询成绩
3.修改成绩
4.删除成绩
5.退出系统
'''
info = [['张飞',56,67,78],['刘备',78,79,80]]
while True:
print(menu)
choice_1 = int(input('请输入你的选择:'))
if choice_1 == 1:
tmp = []
name = input('请您输入你的姓名:')
doing = True
for i in info:
if i[0] == name:
doing = False
print('该用户已存在,请重新输入')
if doing:
tmp.append(name)
tmp.append(int(input('请输入你的语文成绩:')))
tmp.append(int(input('请输入你的数学成绩:')))
tmp.append(int(input('请输入你的英语成绩:')))
info.append(tmp)
print(f'{name}已经录入成功')
elif choice_1 == 2:
print('1:查看全部信息 2:查看个人信息')
choice_2 = int(input('请输入你的选择:'))
print('姓名 语文 数学 英语')
if choice_2 == 1:
for i in info:
for j in i:
print(j, end=' ')
print()
elif choice_2 == 2:
name = input('请输入你所需查询的姓名:')
found = False
for i in info:
if name == i[0]:
found = True
print('姓名 语文 数学 英语')
for j in i:
print(j,end=' ')
print()
if not found:
print('该用户不存在,请重新输入')
elif choice_1 == 3:
print('姓名 语文 数学 英语')
for i in info:
for j in i:
print(j, end=' ')
print()
name = input('请输入修改的用户姓名:')
print('1:语文 2:数学 3:英语')
choice_3 = int(input('请输入遂改科目的序号:'))
score = int(input('请输入修改后的成绩:'))
for i in info:
if i[0] == name:
i[choice_3] = score
print('成绩修改成功')
elif choice_1 == 4:
print('姓名 语文 数学 英语')
for i in info:
for j in i:
print(j, end=' ')
print()
name = input('请输入删除的用户姓名:')
for k in info:
if k[0] == name:
info.remove(k)
print('删除成功!')
else:
print('退出系统')
break神奇魔方阵
魔方阵又称纵横图,是一种n行n列、由自然数1~n×n组成的方阵,该方阵中的数符合以下规律:
- 方阵中的每个元素都不相等。
- 每行、每列以及主、副对角线上的个元素之和都相等。 本实例要求编写程序,输出一个5行5列的魔方阵。
bash
magic = [[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0]]
row = 0
col = 2
for num in range(1,26):
magic[row][col] = num
next_row = (row -1)%5
next_col = (col +1)%5
if magic[next_row][next_col] != 0:
row = (row+1)%5
else:
row = next_row
col = next_col
for line in magic:
print(line)5.5:集合
Python的集合(set)本身是可变类型,但Python要求放入集合中的元素必须是不可变类型。 集合类型与列表和元组的区别是:集合中的元素无序但必须唯一。
1)创建集合
集合的表现形式为一组包含在大括号"{}"中、由逗号","分隔的元素。使用"{}"可以直接创建集合,使用内 置函数set()也可以创建集合。
bash
set_one = {}
set_two = set() #只有一种创造空集合的方式
print(type(set_one))
print(type(set_two))
<class 'dict'>
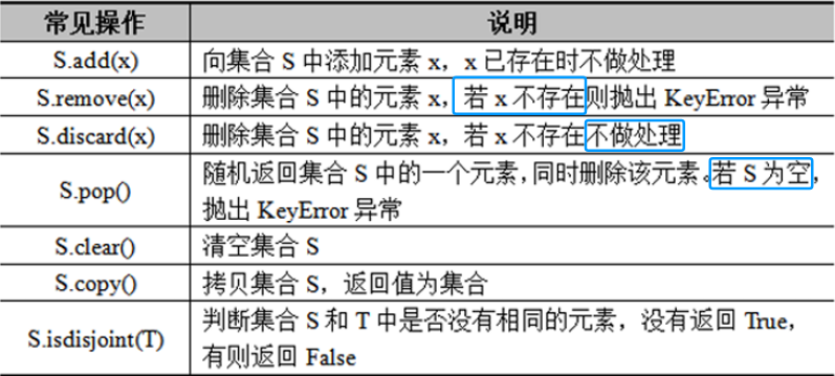
<class 'set'>2)集合的常见操作
集合是可变的,集合中的元素可以动态增加或删除。Python提供了一些内置方法来操作集合,常见内置 方法如下:
bash
#集合添加值
set_one = {10,20,30,40}
set_one.add(50)
print(set_one)
#集合删除值
#remove()
set_one = {10,20,30,40}
set_one.remove(40) #指定值
print(set_one)
#discard()
set_one = {10,20,30,40}
set_one.remove(40)
set_one.discard(40)
result = set_one.pop()
print(result)
print(set_one)
10
{20, 30}
#pop()
set_one = {10,20,30,40}
set_one.pop() #随机带走一个值,集合是无序的所以不能通过索引定位,只能随机带走值
print(set_one)
set_one.clear() #清空
#copy()拷贝返回值
set_one = {10,20,30,40}
set_one.pop()
set_two = set_one.copy()
print(set_two)
{10, 20, 30}
#判断两个集合是否没有相同元素
set_one = {10,12,13,14}
set_two = {10,20,30}
print(set_one.isdisjoint(set_two))
False
set_one = {10,12,13,14}
set_two = {11,20,30}
print(set_one.isdisjoint(set_two))
True5.6:字典
提到字典这个词相信大家都不会陌生,学生时期碰到不认识的字时,大家都会使用字典的部首表查找对 应的汉字。Python中的字典数据与学生使用的字典有类似的功能,它以"键值对"的形式组织数据,利用 "键"快速查找"值"。通过"键"查找"值"的过程称为映射,Python中的字典是典型的映射类型。
5.6.1:创建字典
bash
{键1:值1, 键2:值2,...,键N:值N}
dict_one = {}5.6.2:字典的访问
字典的值可通过"键"或内置方法get()访问。
bash
dict_one ={'name':'li','age':18,'score':[89,90,98]}
print(dict_one['name']) #键
print(dict_one.get('age')) #get()
li
18字典涉及的数据分为键、值和元素(键值对),除了直接利用键访问值外,python还提供了用于访问字 典中所有键、值的元素的内置方法keys()、values()和items()。
bash
dict_one ={'name':'li','age':18,'score':[89,90,98]}
for v in dict_one.values():
print(v)
li
18
[89, 90, 98]
dict_one ={'name':'li','age':18,'score':[89,90,98]}
for k in dict_one.keys(): `等同于 for k in dict_one:`
print(k)
name
age
score
dict_one ={'name':'li','age':18,'score':[89,90,98]}
for k,v in dict_one.items():
print(k,v)
name li
age 18
score [89, 90, 98]
dict_one ={'name':'li','age':18,'score':[89,90,98]}
for i in dict_one.items():
print(i)
#键值对是以元组的形式输出
('name', 'li')
('age', 18)
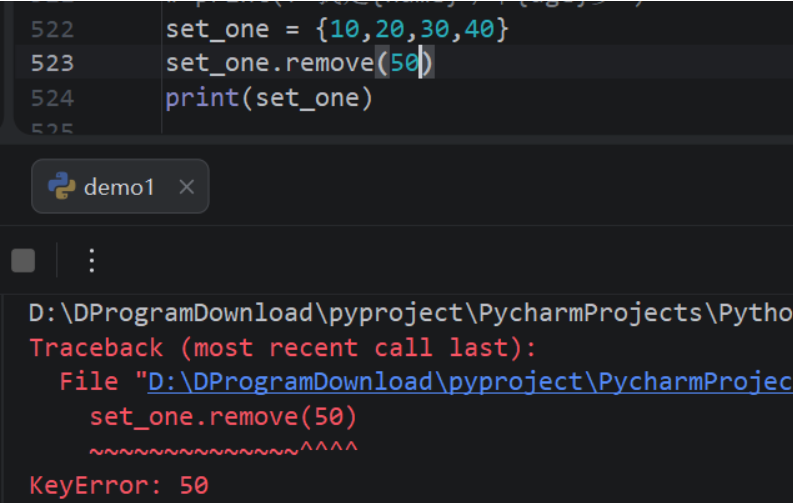
('score', [89, 90, 98])remove删除没有的元素会报错
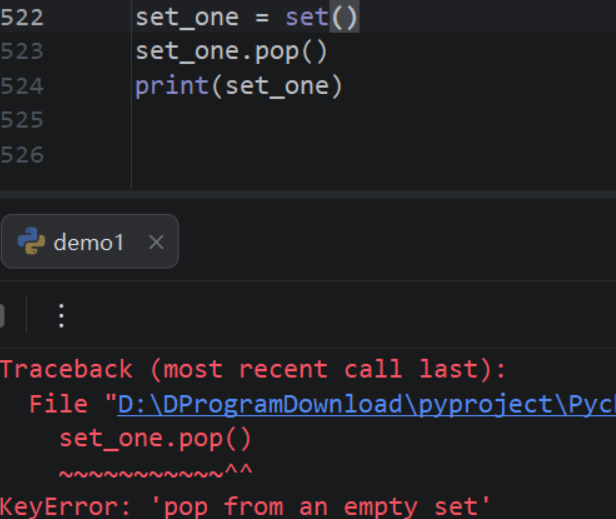
pop删除元素时,集合为空报错
5.6.3:字典元素的添加和修改
1)字典元素的添加
当字典中不存在某个键时,利用一下格式可在字典中新增一个元素。
bash
字典变量['键'] = 值
dic.update(键=值)
bash
dict_one ={'name':'li','age':18,'score':[89,90,98]}
dict_one['name'] = 'ding'
print(dict_one)
dict_one ={'name':'li','age':18,'score':[89,90,98]}
dict_one['sub'] = 'math'
print(dict_one)
dict_one ={'name':'li','age':18,'score':[89,90,98]}
dict_one.update(name='li')
print(dict_one)
dict_one ={'name':'li','age':18,'score':[89,90,98]}
dict_one.update(sub='math')
print(dict_one)原来有键就是修改值,原来每件就是添加
5.6.4:字典元素的删除
1)pop()方法
pop():根据指定键值删除字典中的指定元素,若删除成功,返回目标元素的值。
bash
#pop()
dict_one ={'name':'li','age':18,'score':[89,90,98]}
dict_one.pop('name')
print(dict_one)
{'age': 18, 'score': [89, 90, 98]}2)popitem()
方法 popitem():随机删除字典中的元素。实际上popitem()之所以能随机删除元素,是因为字典元素本身无 序,没有第1个和最后1个之分。若删除成功,popitem()方法返回被删除的元素。
bash
#popitem()
dict_one ={'name':'li','age':18,'score':[89,90,98]}
result=dict_one.popitem()
print(dict_one)
print(result)
{'name': 'li', 'age': 18}
('score', [89, 90, 98])3)clear()方法
clear():清空字典中的元素。
bash
#clear()
dict_one ={'name':'li','age':18,'score':[89,90,98]}
dict_one.clear()
print(dict_one)利用字典进行成绩录入查询
录入成绩(录入,姓名,三门课成绩:已存在的姓名无法录入)
查询成绩(查看全部成绩:查看个人成绩,加入不存在不提示)
修改成绩(能够单独修改每一门课的成绩)
删除成绩(按照姓名删除个人全部信息)
bash
menu = '''
1.录入成绩
2.查询成绩
3.修改成绩
4.删除成绩
5.退出系统
'''
info = {'张飞':[67,68,69],'刘备':[78,79,70]}
while True:
print(menu)
choice_1 = int(input('请输入你的选择:'))
if choice_1 == 1:
name = input('请输入姓名:')
tmp = []
found = True
for i in list(info.keys()):
if name == i:
found = False
print('该用户已经存在,请重新输入')
if found:
found = False
tmp.append(int(input('请输入语文成绩:')))
tmp.append(int(input('请输入数学成绩:')))
tmp.append(int(input('请输入英语成绩:')))
# info.update(name=tmp) 这样不行,会把name当成字符串
info[name]=tmp
print(f'{name}已经录入成功')
elif choice_1 == 2:
print('1:查看全部信息 2:查看个人信息')
choice_2 = int(input('请输入你的选择:'))
if choice_2 == 1:
print('姓名 语文 数学 英语')
for k, v in info.items():
print(k, end=' ')
for i in v:
print(i, end=' ')
print()
elif choice_2 == 2:
name = input('请输入查询的姓名:')
found = True
for i in info.keys():
if i == name:
found = False
print('姓名 语文 数学 英语')
for k, v in info.items():
if name == k:
print(k, end=' ')
for i in v:
print(i, end=' ')
print()
if found:
print('用户不存在,请重新输入!')
elif choice_1 == 3:
print('姓名 语文 数学 英语')
for k, v in info.items():
print(k, end=' ')
for i in v:
print(i, end=' ')
print()
name = input('请输入你需要修改的用户名:')
print('1:语文 2:数学 3:英语')
choice_3 = int(input('请输入选择的序号:'))
score = int(input('请输入修改后的成绩:'))
for k, v in info.items():
if k == name:
v[choice_3-1] = score
print(f'{name}修改成功')
elif choice_1 == 4:
print('姓名 语文 数学 英语')
for k, v in info.items():
print(k, end=' ')
for i in v:
print(i, end=' ')
print()
name = input('请输入你需要删除的用户名:')
for k in list(info.keys()):
if k == name:
info.pop(k)
print('成功删除成绩')
else:
print('退出系统')
break第6章:函数
6.1:函数概述
函数是组织好的、实现单一功能或相关联功能的代码段。我们可以将函数视为一段有名字的代码,这类 代码可以在需要的地方以"函数名()"的形式调用。
根据需求打印正方形,未使用函数前。
bash
#打印边长为2个星的正方形
for i in range(2):
for j in range(2):
print('*',end=' ')
print()
#打印边长为3个星的正方形
for i in range(3):
for j in range(3):
print('*',end=' ')
print()
#打印边长为4个星的正方形
for i in range(4):
for j in range(4):
print('*',end=' ')
print()使用函数后:
bash
#打印正方形的函数
def print_square(lenth):
for i in range(lenth):
for j in range(lenth):
print('*',end=' ')
print()
#使用函数打印
print_square(2)
print_square(3)
print_square(4)函数式编程具有以下优点:
1:将程序模块化,既减少了冗余代码,又让程序结构更为清晰。
2:提高开发人员的编程效率。
3:方便后期的维护与扩展。
6.2:函数的定义和调用
6.2.1:定义函数
函数类型:
1:有参数方式
bash
def func(a,b):
result = a + b
print(result)2:无参数方式
bash
def add():
result = 10 + 20
print(result)6.2.2:调用函数
函数在定义完成后不会立刻执行,直到被程序调用时才会执行。
注意:函数只有被调用才有意义
bash
def add():
result = 10 + 20
print(result)
def func(a,b):
add() #调用了上面的函数
result = a + b
print(result)
func(b=22,a=11)
30
33
def func(a,b):
result = a+b
def add(): #这里的函数没有被调用
r = 10 +20
print(r)
print(result)
func(11,22)
33 #所以只会输出一个值
def func(a,b):
result = a+b
def add():
r = 10 +20
print(r)
add() #调用了函数
print(result)
func(11,22)
30
336.3:函数参数传递
6.3.1:位置参数的传递
函数在被调用时会将实参按照相应的位置依次传递给形参,也就是说将第一个实参传递给第一个形参, 将第二个实参传递给第二个形参,以此类推。
bash
def add():
result = 10 + 20
print(result)
def func(a,b):
result = a + b
print(result)
#按照位置顺序进行实参的赋值
add()
func(11,b=22) #也可以是关键字参数的形式,没有
func(a=11,b=33)6.3.2:关键字参数的传递
关键字参数的传递是通过"形参=实参"的格式将实参与形参相关联,将实参按照相应的关键字传递给形 参。
bash
def add():
result = 10 + 20
print(result)
def func(a,b):
add()
result = a + b
print(result)
func(b=22,a=11) #传递关键字需要标明关键字,顺序可以忽略6.3.3:默认参数的传递
bash
#默认参数
def func(ip,port=3306):
print(f'地址是{ip},端口{port}')
func(ip='127.0.0.1',port=8080)
地址是127.0.0.1,端口8080
#对于默认参数设置后可以不进行传参,但是传参后显示的是传参值,如果没有传参就是默认值特殊字符:
在/前的为位置变量,*后的为关键字变量
bash
def func(a,/,b,*,c):
print(a+b+c)
func(10,20,c=30)
func(11,b=22,c=33)
#b在中间没有特别的规定可以是位置变量和关键字变量
#不可以写为:
func(a=10,20,c=30)
func(10,20,30)6.3.4:参数的打包与解包
1)打包
如果函数在定义时无法确定需要接收多少个数据,那么可以在定义函数时为形参添加"*"或"**":
bash
#元组类型
def func(*args):
print(type(args))
for i in args:
print(i)
func(10,20,30)
<class 'tuple'>
10
20
30
#字典类型
def func(**kwargs):
print(type(kwargs))
for i in kwargs:
print(i)
func(a=1,b=2,c=3,d=4)
#和字典相同kwargs=kwargs.keys()
<class 'dict'>
a b c d
def func(**kwargs):
print(type(kwargs))
for i in kwargs.items():
print(i)
func(a=1,b=2,c=3,d=4)
#键值对是以元组的形式输出
<class 'dict'>
('a', 1)
('b', 2)
('c', 3)
('d', 4)1:虽然函数中添加"*"和"**"的形参可以是符合命名规范的任意名称,但这里建议使用 * args和 * * kwargs。
2:若函数没有接收到任何数据,参数 * args 和 * * kwargs为空,即它们为空元组和空字典。
2)解包
注意:解包必须保证形参和键名一致,数量一致
实参是元组 → 可以使用 * 拆分成多个值 → 按位置参数传给形参
实参是字典 → 可以使用 * * 拆分成多个键值对 → 按关键字参数传给形参
bash
#解包
def func(A,B,C,D):
print(A,B,C,D)
tuple_one=(10,20,30,40)
dict_one={'A':11,'C':33,'B':22,'D':44}
#是通过键对应的值的,类似于关键字变量,所以顺序可以不同
func(*tuple_one)
func(**dict_one)
10 20 30 40
11 22 33 44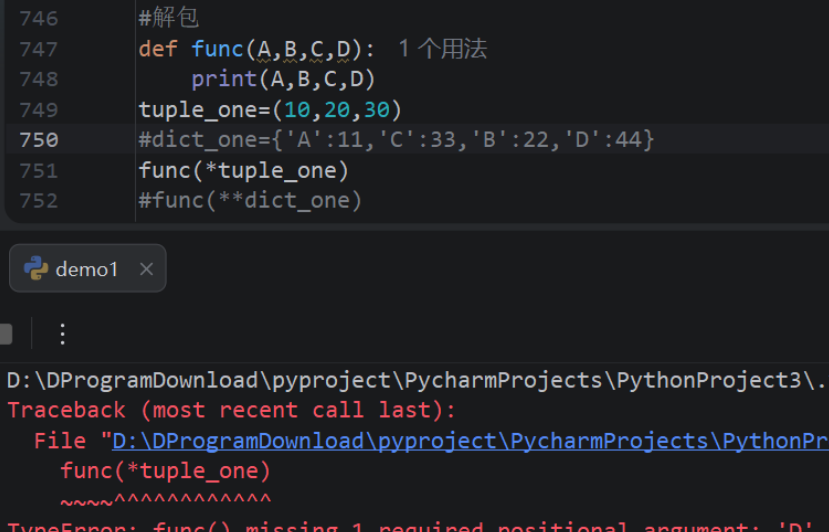
实际解包后的参数个数和形参不同时会报错
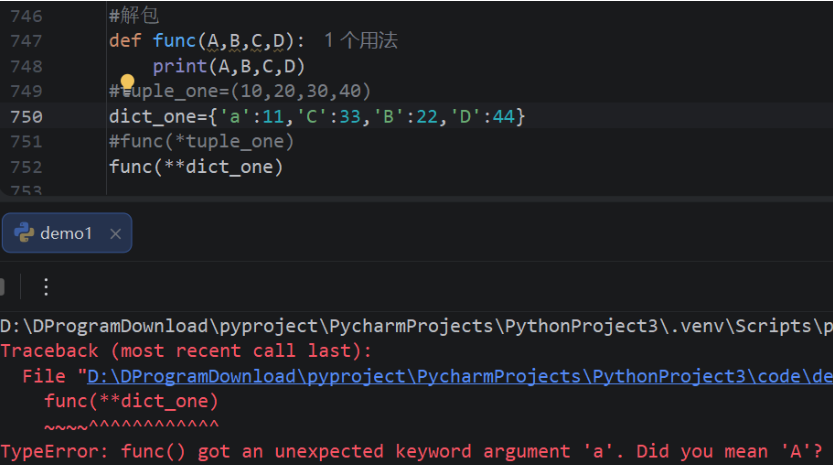
对应的关键字不同也会报错
6.3.5:混合传递
前面介绍的参数传递的方式在定义函数或调用函数时可以混合使用,但是需要遵循一定的规则,具体规 则如下:
- 优先按位置参数传递的方式。
- 然后按关键字参数传递的方式。
- 之后按默认参数传递的方式。
- 最后按打包传递的方式。
注意:解包的顺序也需要满足
在定义函数时:
- 带有默认值的参数必须位于普通参数之后。
- 带有 * 标识的参数必须位于带有默认值的参数之后。
- 带有 * * 标识的参数必须位于带有 * 标识的参数之后。
bash
def func(a,b,c=33,*args,**kwargs):
print(a,b,c,args,kwargs)
func(1,2)
func(1,2,3)
func(1,2,3,4)
func(1,2,3,4,e=5)
1 2 33 () {}
1 2 3 () {}
1 2 3 (4,) {}
1 2 3 (4,) {'e': 5}6.4:函数的返回值
函数中的return语句会在函数结束时将数据返回给程序,同时让程序回到函数被调用的位置继续执行。
return是返回函数的运行结果值,print()是将结果输出到屏幕上
bash
def test(word:str) -> str: #指定输出类型
if '翻墙' in word:
result = word.replace('翻墙','技术工具')
return result
print(test(input('请输入一段话:')))
def test(a:int,b:int): #定义输入数值类型
result1 = a + b
result2 = a * b
return result1, result2
tmp = test(10,20) #这里输入浮点型也行,但是不能影响后续函数里的运行
print(type(tmp))
print(tmp)
<class 'tuple'>
(30, 200)
def test(a:int,b:int):
result1 = a + b
result2 = a * b
return result1, result2
k,v = test(10,20) #如果以一个变量输出则是以元组的形式输出
print(k,v)
30 2006.5:变量作用域
变量并非在程序的任意位置都可以被访问,其访问权限取决于变量定义的位置,其所处的有效范围称为 变量的作用域。
6.5.1:局部变量和全局变量
1)局部变量
- 函数内部定义的变量,只能在函数内部被使用
- 函数执行结束之后局部变量会被释放,此时无法再进行访问。
2)全局变量
全局变量可以在整个程序的范围内起作用,可以在程序的任意位置被访问,它不会受到函数范围的影 响。
bash
#全局变量
sum = 100
def test(a):
a += 1
return a
print(test(sum))
print(sum)
101 #引用全局变量对全局变量本身没有影响
100
sum = 100
def test():
global sum #修改全局变量需要global加载全局变量
sum += 1
return sum
print(test())
print(sum)
101 #使用global后直接改变到全局变量本身
1014)嵌套变量
嵌套定义的函数中外层函数声明的变量生效的区域。
bash
#嵌套变量
def outer():
num = 100
def inner():
nonlocal num #使用nonlocal定义嵌套变量
num += 1
return num
inner()
print(outer()) #这里输出的值为None因为outer()没有返回值供print输出到屏幕
#解决方式:
def outer():
num = 100
def inner():
nonlocal num
num += 1
print(num)
inner()
outer()
########################
def outer():
num = 100
def inner():
nonlocal num
num += 1
return num
return inner()
print(outer())
#########################
def outer():
num = 100
def inner():
nonlocal num
num += 1
return num
result=inner()
return result
print(outer())6.5.2:global和nonlocal关键字
1)global关键字
使用global关键字可以将局部变量声明为全局变量
2)nonlocal关键字
使用nonlocal关键字可以在局部作用域中修改嵌套作用域中定义的变量
见上文
6.6:实训案例
角谷猜想
角谷猜想又称冰雹猜想,是由日本数学家角谷静夫发现的一种数学现象,具体内容:以一个正整数n为 例,如果n为偶数,就将它变为n/2,如果除后变为奇数,则将它乘3加1(即3n+1)。不断重复这样的 运算,经过有限步后,必然会得到1。
本实例要求编写代码,计算用户输入的数据按照以上规律经多少次运算后可变为1。
bash
def guess(num):
count = 0
while True:
if num != 1:
if num % 2 == 0:
count += 1
num = num // 2 #不用整除也行,因为偶数一定能被2整除
else:
count += 1
num = num*3 + 1
else:
break
print(count)
guess(6)
8
###############################优化后###################################
def guess(num:int) ->int:
count=0
while True:
if num == 1:
return count
elif num % 2 == 0:
count += 1
num = num // 2
else:
num = num*3 + 1
count += 1
num = int(input('请输入数字:'))
print(f'总共经历了{guess(num)}次,得到了1')6.7:特殊形式的函数
6.7.1:递归函数
函数在定义时可以直接或间接地调用其他函数。若函数内部调用了自身,则这个函数被称为递归函数。 递归函数在定义时需要满足两个基本条件:一个是递归公式,另一个是边界条件。其中:
- 递归公式是求解原问题或相似的子问题的结构。
- 边界条件是最小化的子问题,也是递归终止的条件。
递归函数的执行可以分为以下两个阶段:
- 递推:递归本次的执行都基于上一次的运算结果。
- 回溯:遇到终止条件时,则沿着递推往回一级一级地把值返回来。
递归函数的一般定义格式如下所示:
bash
def 函数名([参数列表]):
if 边界条件:
rerun 结果
else:
return 递归公式以阶乘为例:
bash
def test(num):
if num == 1:
return 1
else:
return num*test(num - 1)
num = int(input('请输入一个整数:'))
result = test(num)
print(f'{num}!={result}')
请输入一个整数:5
5!=1206.7.2:匿名函数
匿名函数是一类无需定义标识符的函数,它与普通函数一样可以在程序的任何位置使用。Python中使用 lambda关键字定义匿名函数,它的语法格式如下:
bash
lambda <形式参数列表> :<表达式>匿名函数与普通函数的主要区别如下:
- 普通函数在定义时有名称,而匿名函数没有名称;
- 普通函数的函数体中包含有多条语句,而匿名函数的函数体只能是一个表达式;
- 普通函数可以实现比较复杂的功能,而匿名函数可实现的功能比较简单;
- 普通函数能被其他程序使用,而匿名函数不能被其他程序使用。
bash
tmp = lambda x : pow(x,2)
print(tmp(2))
#变量名就是函数引用名
4成绩录入修改系统
python
def func_total():
print('姓名 语文 数学 英语')
for k in info.keys():
print(k,end=' ')
for v in info[k]:
print(v,end=' ')
print()
def func_personal(name):
print('姓名 语文 数学 英语')
for k in info.keys():
if name == k:
print(k,end=' ')
for v in info[k]:
print(v,end=' ')
print()
menu = '''
1.录入成绩
2.查询成绩
3.修改成绩
4.删除成绩
5.退出系统
'''
info = {'张飞':[67,68,69],'刘备':[78,79,70]}
while True:
print(menu)
choice_1 = int(input('请输入你的选项:'))
if choice_1 == 1:
name = input('请输入录入的姓名:')
tmp = []
doing = True
for i in info.keys():
if i == name:
doing = False
print('该用户已经存在,请重新输入')
if doing:
tmp.append(int(input('请输入语文成绩:')))
tmp.append(int(input('请输入数学成绩:')))
tmp.append(int(input('请输入英语成绩:')))
info[name]=tmp
print(f'{name}成绩录入成功')
elif choice_1 == 2:
print('1:查看全部信息 2:查看个人信息')
choice_2 = int(input('请输入你的选择:'))
if choice_2 == 1:
func_total()
elif choice_2 == 2:
name = input('请输入所需查询的姓名:')
doing = True
for i in info.keys():
if name == i:
doing = False
func_personal(name)
if doing:
print('用户不存在,请重新输入!')
elif choice_1 == 3:
func_total()
name = input('请输入需要修改的用户名:')
print('1:语文 2:数学 3:英语')
choice_3 = int(input('请输入修改的学科序号:'))
score = int(input('请输入修改后的分数:'))
for k in info.keys():
if name == k:
info[k][choice_3-1] = score
print('修改成功')
elif choice_1 == 4:
func_total()
name = input('请输入删除的用户名:')
for k in list(info.keys()):
if name == k:
info.pop(k)
print('删除成功')
else:
print('退出系统')
break第7章:文件与数据格式化
程序中使用变量保存运行时产生的临时数据,程序结束后,临时数据随之消失。但一些程序中的数据需 要持久保存,例如游戏程序中角色的属性数据,装备数据,物品数据等。那么使用什么方法能够持久保 存数据呢?计算机可以使用文件持久地保存数据。本章将从计算机中文件的定义、基本操作、管理方式 与数据维度等多个方面对计算机中与数据持久存储相关的知识进行介绍。
7.1:文件概述
类似于程序中使用的变量,计算机中的每个文件也有唯一确定的标识,以便识别和引用文件。
1)文件标识
- 文件标识的意义:找到计算机中唯一确定的文件。
- 文件标识的组成:文件路径、文件名主干、文件扩展名。

- 操作系统以文件为单位对数据进行管理。
2)文件类型
根据数据的逻辑存储结构,人们将计算机中的文件分为文本文件和二进制文件。
- 文本文件:专门存储文本字符数据(使用记事本)。
- 二进制文件:不能直接使用文字处理程序正常读写,必须先了解其结构和序列化规则,再设计正确 的反序列化规则,才能正确获取文件信息。
总结:二进制文件和文本文件这两种类型的划分基于数据逻辑存储结构而非物理存储结构,计算机中的 数据在物理层面都以二进制形式存储。
扩展:标准文件
Python的sys模块中定义了3个标准文件,分别为:
- stdin(标准输入文件)。标准输入文件对应输入设备,如键盘。
- stdout(标准输出文件)。
- stderr(标准错误文件)。标准输出文件和标准错误文件对应输出设备,如显示器。
在解释器中导入sys模块后,便可对标准文件进行操作。
bash
import sys
file = sys.stdout #将文件输出到屏幕上,类似于print()
file.write('hello world')
hello world 7.2:文件的基础操作
7.2.1:文件的打开与关闭
1)打开文件
内置函数open()用于打开文件,该方法的声明如下:
bash
open(file, mode='r', buffering=None)- file:文件的路径。
- mode:设置文件的打开模式,取值有r、w、a。
- r:以只读方式打开文件(mode参数的默认值)。
- w:以只写方式打开文件。
- :以追加方式打开文件。
- b:以二进制形式打开文件。
- +:以更新的方式打开文件(可读可写)
- buffering:设置访问文件的缓冲方式。取值为0或1。

返回值:若open()函数调用成功,返回一个文件对象。
bash
#使用r模式,文件不存在时报错
file1 = open('C:\\Users\\Lenovo\\Desktop\\data\\test1.txt',mode='r')
print(file1)
#使用模式含有w时,文件不存在时会自动创建
file2 = open('C:\\Users\\Lenovo\\Desktop\\data\\test2.txt','w')
file3 = open('C:\\Users\\Lenovo\\Desktop\\data\\test3.txt','w+')
file4 = open('C:\\Users\\Lenovo\\Desktop\\data\\test4.txt','wb+') #以二进制形式2)关闭文件
Python可通过close()方法关闭文件,也可以使用with语句实现文件的自动关闭。
1:close()方法,是文件对象的内置方法。
bash
file1 = open('C:\\Users\\Lenovo\\Desktop\\data\\test1.txt',mode='r')
print(file1.read())
file1.close()2:with语句,可预定义清理操作,以实现文件的自动关闭。
bash
with open('C:\\Users\\Lenovo\\Desktop\\data\\test1.txt',mode='r') as file1:
print(file1.read()) #相当于读完关闭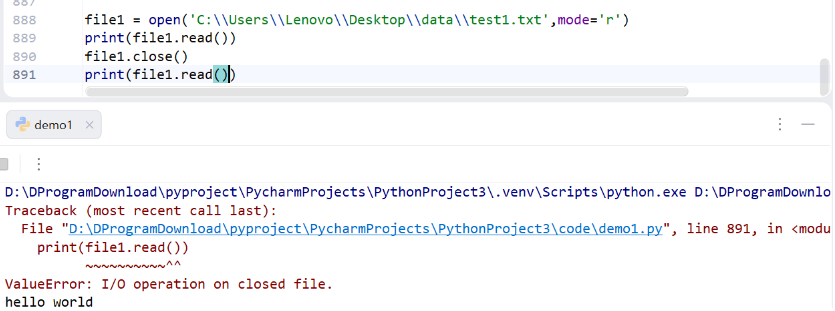
退出后则不能继续读写,会报错
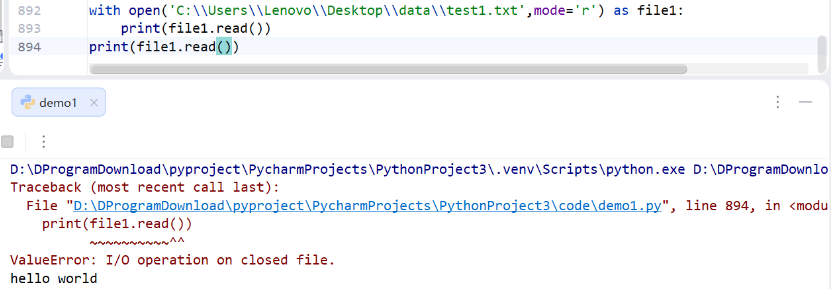
with 语句相当于包括了close()
7.2.2:文件的读写
Python提供了一系列读写文件的方法,包括读取文件的read()、readline()、readlines()方法和写文件的 write()、writelines()方法,下面结合这些方法分别介绍如何读写文件。
1)读取文件-read()方法
bash
read(size) #size字节数size:表示要从文件中读取的数据的长度,单位:字节,如果没有指定size,那么就表示读取文件的全 部数据。
bash
file = open('C:\\Users\\Lenovo\\Desktop\\data\\test1.txt',mode='r')
content = file.read(4)
print(content)
print('-'*30)
print(file.read())
file.close()
hell #前面读出的数据后面都不会输出
------------------------------
o world
with open('C:\\Users\\Lenovo\\Desktop\\data\\test1.txt',mode='r') as file1:
print(file1.read(4))
print('-'*30)
print(file1.read())
hell
------------------------------
o world2)读取文件-readline()方法
readline()方法可以从指定文件中读取一行数据,其语法格式如下:
bash
readline() #一行代码输出一行
python
#对于长的文件,不知道行数,将文件里的内容全部输出
#readline()输出的时字符串形式,如果没有行了输出空字符串
with open('C:\\Users\\Lenovo\\Desktop\\data\\test1.txt',mode='r') as f:
while True:
content = f.readline()
if content == '':
break
else:
print(content)
hello world
line1
line2扩展:假如出现如下报错如何解决
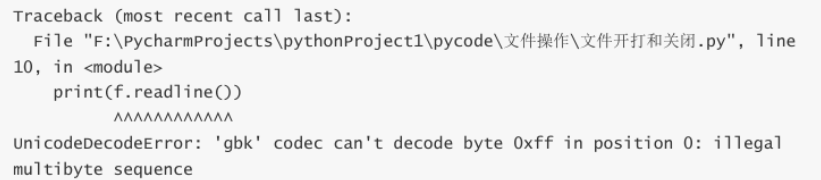
原因:表示在尝试使用GBK编码解码字节数据时,遇到了一个不合法的字节(0xff),解码器无法继续 解码。这通常发生在读取文件时指定了错误的编码,而文件实际上并非GBK编码。
解决方法如下:
当处理文本数据时,经常会遇到各种不同的字符编码。这可能导致乱码和其他问题,因此需要一种方法 来准确识别文本的编码。Python中的 chardet 库就是为了解决这个问题而设计的,它可以自动检测文本 数据的字符编码。
bash
pip install chardet
bash
import chardet
with open('C:\\Users\\Lenovo\\Desktop\\data\\test1.txt', 'rb') as f:
data = f.read()
encoding = chardet.detect(data)
print(encoding)
{'encoding': 'ascii', 'confidence': 1.0, 'language': ''} #以字典形式输出
import chardet
with open('C:\\Users\\Lenovo\\Desktop\\data\\test1.txt', 'rb') as f:
data = f.read()
encoding = chardet.detect(data)['encoding']
print(encoding)
ascii #输出形式是ascii形式
bash
#完整过程
import chardet
filepath = 'C:\\Users\\Lenovo\\Desktop\\data\\test1.txt'
def file_get_encoding(file:str)->str:
with open(file,'rb') as f:
data = f.read()
encoding = chardet.detect(data)['encoding']
return encoding
with open(filepath,mode='r',encoding=file_get_encoding(filepath)) as f:
while True:
line = f.readline()
if line == '':
break
print(line)3)readlines()方法
readlines()方法可以一次读取文件中的所有数据,若读取成功,该方法会返回一个列表,文件中的每一 行对应列表中的一个元素。
bash
with open('C:\\Users\\Lenovo\\Desktop\\data\\test\\test.txt') as f:
print(f.readlines())
['I am planning to write Python\n', 'hello world\n', 'line3'] #以列表的形式输出总结:
- read()(参数缺省时)和readlines()方法都可一次读取文件中的全部数据,但因为计算机的内存是 有限的,若文件较大,read()和readlines()的一次读取便会耗尽系统内存,所以这两种操作都不够 安全。
- 为了保证读取安全,通常多次调用read()方法,每次读取size字节的数据。
4)写文件-write()方法
write()方法可以将指定字符串写入文件,其语法格式如下:
bash
write(data)
bash
string = 'I am planning to write Python'
with open('C:\\Users\\Lenovo\\Desktop\\data\\test1.txt','w',encoding='utf-8') as f:
size = f.write(string) #write()里填写字符串
print(size)
#如果原来有内容就覆盖原来内容
29 #有输出size5)writelines()方法
writelines()方法用于将行列表写入文件,其语法格式如下:
bash
writelines(lines)- 以上格式中的参数lines表示要写入文件中的数据,该参数可以是一个字符串或者字符串列表。
- 若写入文件的数据在文件中需要换行,需要显式指定换行符。
bash
string = ['Life is short\n','I use python']
with open('C:\\Users\\Lenovo\\Desktop\\data\\test1.txt','w',encoding='utf-8') as f:
size = f.writelines(string) #写入列表形式
print(size)
None #无输出size- write :将字符串写入文件,适用于单行写入。要求传入的参数必须是字符串类型。如果传入其他 类型(如列表),会导致错误。
- writelines :将字符串按行写入文件,适用于多行写入。可以接受字符串序列(如列表),但序列 中的元素必须是字符串类型。如果传入其他类型(如数字),会导致错误。
**案例:**将文件内容拷贝到其他地方
bash
#将文件内容拷贝到其他地方
with open('C:\\Users\\Lenovo\\Desktop\\data\\test\\test.txt','r') as f:
contents = f.readlines()
print(contents)
with open('C:\\Users\\Lenovo\\Desktop\\data\\test\\test1.txt','w') as f:
f.writelines(contents)
print('写入完成')7.2.3:文件的定位读写
read()方法读取了文件luckycloud.txt,结合代码与程序运行结果进行分析,可以发现read()方法第1次读 取了2个字符,第2次从第3个字符开始读取了剩余字符。
- 在文件的一次打开与关闭之间进行的读写操作是连续的,程序总是从上次读写的位置继续向下进行 读写操作。
- 每个文件对象都有一个称为"文件读写位置"的属性,该属性会记录当前读写的位置。
- 文件读写位置默认为0,即在文件首部。
Python提供了一些获取与修改文件读写位置的方法,以实现文件的定位读写。
- tell():获取文件当前的读写位置。
- seek():控制文件的读写位置。
1)tell()方法
tell()方法用于获取文件当前的读写位置
bash
with open('C:\\Users\\Lenovo\\Desktop\\data\\test\\test.txt','r') as f :
print('获取文件初次的偏移量:',f.tell())
f.read(4)
print('读取后的偏移量:',f.tell())
获取文件初次的偏移量: 0
读取后的偏移量: 4 #偏移量是4但是位置为52)seek()方法
Python提供了seek()方法,使用该方法可控制文件的读写位置,实现文件的随机读写。seek()方法的语 法格式如下:
bash
seek(offset, from)- offset:表示偏移量,即读写位置需要移动的字节数。
- from:用于指定文件的读写位置,该参数的取值为0、1、2。
- 0:表示文件开头
- 1:表示使用当前读写位置
- 2:表示文件末尾
seek()方法调用成功后会返回当前读写位置。
bash
with open('C:\\Users\\Lenovo\\Desktop\\data\\test\\test.txt','r') as f :
print('获取文件初次的偏移量:', f.tell())
size = f.seek(3) #默认参数的取值0
print('偏移的字节数:',size)
print('现在的文件读写位置:',f.tell())
获取文件初次的偏移量: 0
偏移的字节数: 3
现在的文件读写位置: 3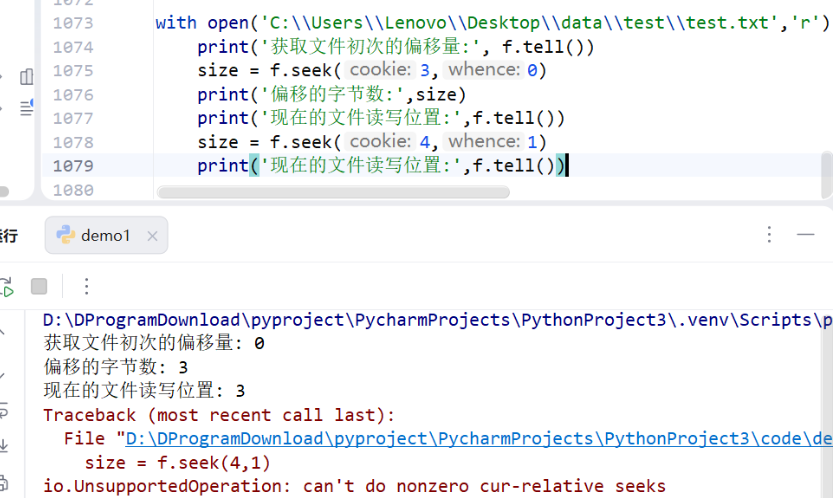
对于参数是1,是需要获取当前的自己位置,所以必须要使用二进制读
bash
with open('C:\\Users\\Lenovo\\Desktop\\data\\test\\test.txt','rb') as f :
print('获取文件初次的偏移量:', f.tell())
size = f.seek(3,0)
print('偏移的字节数:',size)
print('现在的文件读写位置:',f.tell())
size = f.seek(4,1)
print('现在的文件读写位置:',f.tell())
获取文件初次的偏移量: 0
偏移的字节数: 3
现在的文件读写位置: 3
现在的文件读写位置: 77.3:文件与目录管理
使用os模块调用系统中的目录进行操作
1)删除文件-remove()函数
bash
import os
#文件删除remove()
os.remove('C:\\Users\\Lenovo\\Desktop\\data\\test\\test2.txt')
print('删除成功')2)文件重命名-rename()函数
bash
import os
#文件重组rename()
os.rename('C:\\Users\\Lenovo\\Desktop\\data\\test\\test1.txt','C:\\Users\\Lenovo\\Desktop\\data\\test\\test.txt')
print('修改成功')3)获取当前目录-getcwd()函数
bash
import os
#获取当前目录getcwd()
print(os.getcwd())
D:\DProgramDownload\pyproject\PycharmProjects\PythonProject3\code #程序运行的位置4)创建/删除目录-mkdir()/rmdir()
bash
import os
#创建/删除目录mkdir()/rmdir()
os.mkdir('C:\\Users\\Lenovo\\Desktop\\data\\test1')
print('创建成功')5)更改默认目录-chdir()函数
python
import os
#更改默认目录chdir()
print(os.getcwd())
os.chdir('d:\\DProgramDownload')
print(os.getcwd())
D:\DProgramDownload\pyproject\PycharmProjects\PythonProject3\code
d:\DProgramDownload6)获取文件名列表-listdir()函数
bash
import os
#获取文件名列表listdir()
dirs = os.listdir('C:\\Users\\Lenovo\\Desktop\\data')
print(dirs)
['hi.txt', 'test', 'test1'] #以列表的形式输出**案例:**将目录里的文件拷贝到指定位置
bash
#将目录里的文件拷贝到指定位置
import os
source_dir = 'C:\\Users\\Lenovo\\Desktop\\data\\test'
target_dir = 'C:\\Users\\Lenovo\\Desktop\\data\\test1'
if not os.path.exists(target_dir):
os.mkdir(target_dir)
dirs = os.listdir(source_dir)
for i in dirs:
source_file = os.path.join(source_dir, i)
target_file = os.path.join(target_dir, i)
with open(source_file,'r') as file:
contents = file.readlines()
with open(target_file,'w') as file:
file.writelines(contents)
print('写入成功')7.4:数据维度与数据格式化
从广义上看,维度是与事物"有联系"的概念的数量。根据"有联系"的概念的数量,事物可分为不同维度, 例如与线有联系的概念为长度,因此线为一维事物;与长方形面积有联系的概念为长度和宽度,因此面 积为二维事物;与长方体体积有联系的概念为长度,宽度和高度,因此体积为三维事物。
7.4.1:基于维度的数据分类
1)一维数据
具有对等关系的一组线性数据
- 一维列表
- 一维元组
- 集合
2)二维数据
二维数据关联参数的数量为2
- 矩阵
- 二维数组
- 二维列表
- 二维元组
3)多维数据
利用键值对等简单的二元关系展示数据间的复杂结构
- 字典
7.4.2:一维数据和二维数据的存储与读写
1)数据存储
一维数据呈线性排列,一般用特殊字符分隔,一维数据的存储需要注意以下几点:
- 同一文件或同组文件一般使用同一分隔符分隔。
- 分隔数据的分隔符不应出现在数据中。
- 分隔符为英文半角符号,一般不使用中文符号作为分隔符。
二维数据可视为多条一维数据的集合,当二维数据只有一个元素时,这个二维数据就是一维数据。
CSV(Commae-Separeted Values,逗号分隔值)是国际上通用的一二维数据存储格式。
CSV格式规范:
- 以纯文本形式存储表格数据
- 文件的每一行对应表格中的一条数据记录
- 每条记录由一个或多个字段组成 字段之间使用逗号(英文、半角)分隔
CSV也称字符分隔值,具体示例如下:
bash
姓名,语文,数学,英语,理综
刘备,111,137,145,260
张飞,110,143,139,263 #必须使用英语标点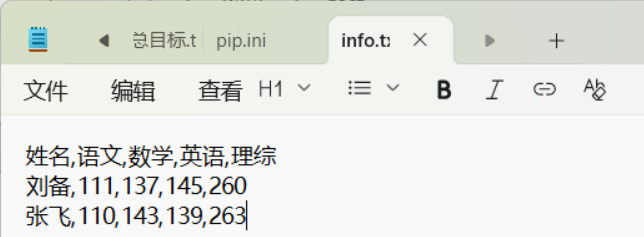
修改文件拓展名
2)数据读取
Windows平台中CSV文件的后缀名为.csv,可通过Office Excel或记事本打开。
Python在程序中读取.csv文件后会以二维列表形式存储其中内容。
bash
import chardet
filepath = 'C:\\Users\\Lenovo\\Desktop\\data\\test\\info.csv'
def get_encoding(filepath):
with open(filepath, 'rb') as f:
data = f.read()
encoding = chardet.detect(data)['encoding']
return encoding
with open(filepath, 'r',encoding=get_encoding(filepath)) as f:
#lines = list()
for line in f:
print(line) #查看文件里的数据输出结果
姓名,语文,数学,英语,理综 #字符串类型
刘备,124,137,145,260
张飞,116,143,139,263
关羽,120,130,148,255
周瑜,115,145,131,240
诸葛亮,123,108,121,235
黄月英,132,100,112,210
##以列表的形式输出
import chardet
filepath = 'C:\\Users\\Lenovo\\Desktop\\data\\test\\info.csv'
def get_encoding(filepath):
with open(filepath, 'rb') as f:
data = f.read()
encoding = chardet.detect(data)['encoding']
return encoding
with open(filepath, 'r',encoding=get_encoding(filepath)) as f:
lines = list()
for line in f:
line = line.replace('\n','') #原始的数据输出后面都有换行符
lines.append(line.split(',')) #将数据以,的形式分割
print(lines)
[['姓名', '语文', '数学', '英语', '理综'], ['刘备', '124', '137', '145', '260'], ['张飞', '116', '143', '139', '263'], ['关羽', '120', '130', '148', '255'], ['周瑜', '115', '145', '131', '240'], ['诸葛亮', '123', '108', '121', '235'], ['黄月英', '132', '100', '112', '210']]3)数据写入
将一、二维数据写入文件中,即按照数据的组织形式,在文件中添加新的数据。
在保存学生成绩的文件score.csv中写入每名学生的总分,代码示例如下
bash
import chardet
filepath = 'C:\\Users\\Lenovo\\Desktop\\data\\test\\info.csv'
def get_encoding(filename):
with open(filename, 'rb') as f:
data = f.read()
encoding = chardet.detect(data)['encoding']
return encoding
#字符集处理
with open(filepath, 'r',encoding=get_encoding(filepath)) as f:
#读取原来的文件内容
file_new = open('C:\\Users\\Lenovo\\Desktop\\data\\test\\count.csv','w+')
#写新的文件,为csv形式
lines = []
#将txt里的内容转化为列表形式
for line in f:
line = line.replace('\n','')
lines.append(line.split(','))
#列表第一行添加合计
lines[0].append('合计')
#计算每个人的分数总和
for i in range(1,len(lines)):
idx = i
sum_score = 0
for j in range(len(lines[idx])):
if lines[idx][j].isdigit():
#也可可以使用isnumeric()来判断字符串是否是数字类型
sum_score += int(lines[idx][j]) #int形式数值才能加减
lines[idx].append(str(sum_score))
#最后的总分还是要以字符串形式添加到列表才符合转化为csv的格式
#以文件txt格式输出写入成csv形式
for line in lines:
print(line)
file_new.write((','.join(line)+'\n'))
#join利用,将列表里的字符串连接7.4.3:多维数据的格式化
JSON格式的数据遵循以 下语法规则:
- 数据存储在键值对(key:value)中,例如"姓名": "张飞"。
- 数据的字段由逗号分隔,例如"姓名": "张飞", "语文": "116"。
- 一个花括号保存一个JSON对象,例如{"姓名": "张飞", "语文": "116"}。
- 一个方括号保存一个数组,例如{"姓名": "张飞", "语文": "116"}。
除JSON外,网络平台也会使用XML(可扩展标记语言)、HTML等格式组织多维数据,XML和HTML格 式通过标签组织数据。例如,将学生成绩以XML格式存储,示例如下
bash
<班级考试成绩>
<姓名>王小天</姓名><语文>124</语文><数学>127<数学/><英语>145<英语/><理综>259<理综/>
<姓名>张大同</姓名><语文>116</语文><数学>143<数学/><英语>119<英语/><理综>273<理综/>
......
</班级考试成绩>利用json模块的dumps()函数和loads()函数可以实现Python对象和JSON数据之间的转换,这两个函数的 具体功能如表所示。

Python对象与JSON数据转化时的类型对照表
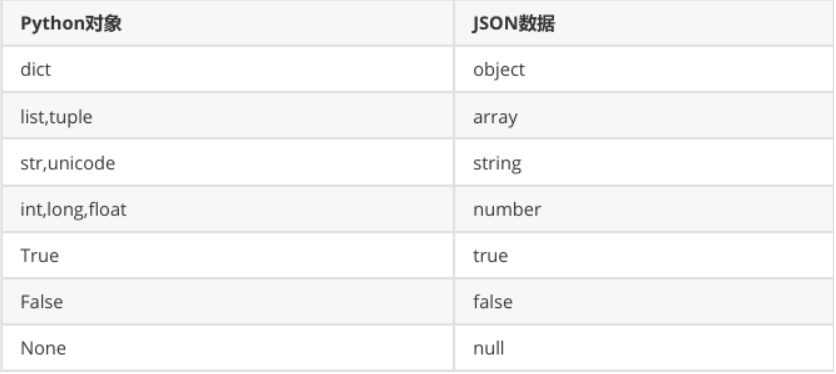
1)dumps()函数
使用dumps()函数对Python对象进行转码。
bash
import json
pyobj = [[1,2,3],10,3,14,'tom',{'java':98,'python':100},True,False,None]
jsonobj = json.dumps(pyobj)
print(jsonobj)
print(pyobj)
[[1, 2, 3], 10, 3, 14, "tom", {"java": 98, "python": 100}, true, false, null]
[[1, 2, 3], 10, 3, 14, 'tom', {'java': 98, 'python': 100}, True, False, None]2)loads()函数
使用loads()函数将JSON数据转换为符合Python语法要求的数据类型。
bash
import json
pyobj = [[1,2,3],10,3,14,'tom',{'java':98,'python':100},True,False,None]
jsonobj = json.dumps(pyobj)
print(jsonobj)
new_obj = json.loads(jsonobj)
print(new_obj)
10, 3, 14, "tom", {"java": 98, "python": 100}, true, false, null]
[[1, 2, 3], 10, 3, 14, 'tom', {'java': 98, 'python': 100}, True, False, None]第8章:面向对象
面向对象是程序开发领域的重要思想,这种思想模拟了人类认识客观世界的思维方式,将开发中遇到的 事物皆看作对象。
8.1:面向对象概述
面向过程:
- 分析解决问题的步骤
- 使用函数实现每个步骤的功能
- 按步骤依次调用函数
面向对象:
- 分析问题,从中提炼出多个对象
- 将不同对象各自的特征和行为进行封装
- 通过控制对象的行为来解决问题。
8.2:类的定义与使用
8.2.1:类的定义
类是由3部分组成的:
- 类的名称:大驼峰命名法,首字母一般大写,比如Person。
- 类的属性:用于描述事物的特征,比如姓名,性别,身高,体重等(静态描述)。
- 类的方法:用于描述事物的行为,比如吃饭,睡觉,健身,娱乐等(动态描述)。
python
class 类名:
属性名 = 属性值
def 方法名(self):
方法体8.2.2:对象的创建与使用
bash
对象名 = 类名() #实例
car = Car()8.3:类的成员
8.3.1:属性
1)类属性
- 声明在类内部、方法外部的属性。
- 可以通过类或对象进行访问,但只能通过类进行修改。
bash
#类属性
class Car:
color = '红'
def drive(self):
return '正在行驶'
car = Car()
car.color = '蓝'
print('类的方法:',Car.color)
print('对象属性:',car.color)
类的方法: 红
对象属性: 蓝
class Car:
color = '红'
def drive(self):
return '正在行驶'
car = Car()
Car.color = '蓝'
print('类的方法:',Car.color)
print('对象属性:',car.color)
类的方法: 蓝
对象属性: 蓝2)实例属性
- 实例属性是在方法内部声明的属性。
- Python支持动态添加实例属性。
(1)访问实例属性------只能通过对象访问
(2)修改实例属性------通过对象修改
(3)动态添加实例属性------类外部使用对象动态添加实例属性
bash
#实例属性
class Car:
color = '红'
def drive(self):
#实例属性,定义在方法内部,只能被对象调用
self.wheels = 4
return '正在行驶'
car = Car()
car.drive() #需要使用实例属性的方法
#类调用
#print(Car.wheels) #无法使用类访问
#对象调用
print(car.wheels) #只能被对象调用
class Car:
color = '红'
def drive(self):
self.wheels = 4
return '正在行驶'
car = Car()
car.drive()
car.wheels = 3
car.color = '红色'
print(car.wheels)
print(car.color)8.3.2:方法
Python中的方法按定义方式和用途可以分为三类:实例方法、类方法和静态方法。
1)实例方法
- 形似函数,但它定义在类内部。
- 以self为第一个形参,self参数代表对象本身。
- 只能通过对象调用。
bash
#实例方法
class Car:
def drive(self):
print('我是实例方法。')
car = Car()
car.drive()
#Car.drive() 不可以通过类调用实例方法2)类方法
- 类方法是定义在类内部
- 使用装饰器@classmethod修饰的方法
- 第一个参数为cls,代表类本身
- 可以通过类和对象调用
bash
#类方法
class Car():
@classmethod
def stop(cls):
print('我是类方法。')
car = Car()
car.stop()
Car.stop()#可以通过类调用类方法类方法中可以使用cls访问和修改类属性的值
python
class Car:
wheels = 3
@classmethod
def stop(cls):
print(cls.wheels)
cls.wheels = 4
print(cls.wheels)
car = Car()
Car.stop()
3
43)静态方法
- 静态方法是定义在类内部
- 使用装饰器@staticmethod修饰的方法
- 没有任何默认参数
静态方法可以通过类和对象调用,独立于类所存在
bash
#静态方法
class Car:
@staticmethod
def test():
print('我是静态方法。')
car = Car()
car.test()
Car.test()
#静态方法
class Car:
wheels = 3
@staticmethod
def test():
print('我是静态方法。')
print(f'类属性的值为{Car.wheels}') #使用类名访问类属性或调用类方法
car = Car()
car.test()总和:
bash
class Car:
color = '红'
#实例方法
def drive(self):
print('实例方法')
#类方法
@classmethod
def stop(cls):
print('类方法')
@staticmethod
def count():
print(f'车的颜色{Car.color}')
car = Car()
####实例方法的使用
car.drive()
####类方法
car.stop()
Car.stop()
####静态方法
car.count()
Car.count()8.3.3:私有成员
Python通过在类成员的名称前面添加双下画线(__)的方式来表示私有成员,语法格式如下:
- __属性名
- __方法名
bash
#私有成员
class Car:
__wheels = 4
def __drive(self):
print('开车')
car = Car()
print(car.wheels)
car.drive()
#无法调用私有成员在类的内部可以直接访问,在类的外部不能直接访问,但可以通过调用类的公有成员方法的方 式进行访问。
bash
class Car:
__wheels = 4
def __drive(self):
print('开车')
def test(self):
print(f'{self.__wheels}')
self.__drive()
car = Car()
car.test()
4
开车8.4:特殊方法
类中还包括两个特殊的方法:构造方法和析构方法,这两个方法都是系统内置方法
8.4.1:构造方法
构造方法指的是__init__()方法。 创建对象时系统自动调用 ,从而实现对象的初始化。 每个类默认都有一个__init__()方法,可以在类中显式定义__init__()方法。 __init__()方法可以分为无参构造方法和有参构造方法。
- 当使用无参构造方法创建对象时,所有对象的属性都有相同的初始值。
python
#__init__无参数
class Car:
name = 'BMW'
def __init__(self):
self.color = '白'
def drive(self):
print('车正在开')
car = Car()
print(f'今天买了一辆{car.name},颜色是{car.color}')
car.drive()
#__init__无参数
class Car:
name = 'BMW'
def __init__(self):
print('__init__在对象创建时就自动被调用') #验证自动调用
self.color = '白'
def drive(self):
self.wheels = 4
print('车正在开')
car = Car()
print(f'今天买了一辆{car.name},颜色是{car.color}')
car.drive()
print(car.wheels)
__init__在对象创建时就自动被调用
今天买了一辆BMW,颜色是白
车正在开
4
发现如果想输出实例参数需要先调用实例方法,但是
__init__也是实例方法为什么不用调用直接可以输出?因为
__int__是对象创建时就已经自动调用了
- 当使用有参构造方法创建对象时,对象的属性可以有不同的初始值。
python
#__init__有参数
class Car:
name = 'BMW'
def __init__(self,my_color):
print('__init__在对象创建时就自动被调用')
self.color = my_color
def drive(self):
self.wheels = 4
print('车正在开')
car = Car('樱花粉')
print(f'今天买了一辆{car.name},颜色是{car.color}')
car = Car('天空蓝')
print(f'今天买了一辆{car.name},颜色是{car.color}')
__init__在对象创建时就自动被调用
今天买了一辆BMW,颜色是樱花粉
__init__在对象创建时就自动被调用
今天买了一辆BMW,颜色是天空蓝8.4.2:析构方法
析构方法(即del()方法)是销毁对象时系统自动调用的方法。
每个类默认都有一个del()方法,可以显式定义析构方法。
python
class Car:
name = 'BMW'
def __init__(self,my_color):
self.color = my_color
print(f'{self.color}被创建')
def drive(self):
self.wheels = 4
print('车正在开')
def __del__(self):
print(f'{self.color}车被销毁')
car1 = Car('樱花粉')
print(f'今天买了一辆{car1.name},颜色是{car1.color}')
car2 = Car('天空蓝')
print(f'今天买了一辆{car2.name},颜色是{car2.color}')
樱花粉被创建
今天买了一辆BMW,颜色是樱花粉
天空蓝被创建
今天买了一辆BMW,颜色是天空蓝
樱花粉车被销毁 #发现结果并不是像我们想的创建完被销毁,而是集中销毁
天空蓝车被销毁 #这样会导致前面的对象一致在内存中积压
class Car:
name = 'BMW'
def __init__(self,my_color):
self.color = my_color
print(f'{self.color}被创建')
def drive(self):
self.wheels = 4
print('车正在开')
def __del__(self):
print(f'{self.color}车被销毁')
car1 = Car('樱花粉')
print(f'今天买了一辆{car1.name},颜色是{car1.color}')
del car1 #可以添加语句手动销毁变量
car2 = Car('天空蓝')
print(f'今天买了一辆{car2.name},颜色是{car2.color}')
樱花粉被创建
今天买了一辆BMW,颜色是樱花粉
樱花粉车被销毁
天空蓝被创建
今天买了一辆BMW,颜色是天空蓝
天空蓝车被销毁8.5:封装
封装是面向对象的重要特性之一,它的基本思想是对外隐藏类的细节,提供用于访问类成员的公开接 口。 如此,类的外部无需知道类的实现细节,只需要使用公开接口便可访问类的内容,这在一定程度上保证 了类内数据的安全。
为了契合封装思想,我们在定义类时需要满足以下两点要求。
1.将类属性声明为私有属性。
2.添加两类供外界调用的公有方法 ,分别用于设置 或获取私有属性的值。
bash
class Person:
def __init__(self,name):
self.name = name
#设置属性私有
self.__age = 1 #设置私有默认值
#共有方法设置
def set_age(self,age):
if 0 < age <= 120:
self.__age = age
#共有方法查看
def get_age(self):
return self.__age
zhangsan = Person('zhangsan')
zhangsan.set_age(-1) #如果age在这个范围内则使用age替换默认值
print(f'他的姓名是{zhangsan.name},年龄是{zhangsan.get_age()}')
他的姓名是zhangsan,年龄是18.6:继承
继承是面向对象的重要特性之一,它主要用于描述类与类之间的关系,在不改变原有类的基础上扩展原 有类的功能。
若类与类之间具有继承关系,被继承的类称为父类或基类,继承其他类的类称为子类或派生类,子类会 自动拥有父类的公有成员。
8.6.1:单继承
单继承即子类只继承一个父类。现实生活中,波斯猫、折耳猫、短毛猫都属于猫类,它们之间存在的继 承关系即为单继承,如图所示。
bash
class Cat:
def __init__(self,color):
self.color = color
def play(self):
print('喜欢玩毛线球')
class Scottishfold(Cat):
pass
fold = Scottishfold('白')
print(fold.color)
fold.play()
白
喜欢玩毛线球注意:子类不会拥有父类的私有成员,也不能访问父类的私有成员。
8.7.2:多继承
程序中的一个类也可以继承多个类,如此子类具有多个父类,也自动拥有所有父类的公有成员。
bash
class House:
def live(self):
print('居住')
class Car:
def drive(self):
print('行驶')
class Touringcar(Car,House):
pass #占位符
tc = Touringcar()
tc.live()
tc.drive()
居住
行驶
class House:
def live(self):
print('居住')
def test(self):
print('居住类的方法')
class Car:
def drive(self):
print('行驶')
def test(self):
print('车辆类的方法')
class Touringcar(`Car,House`): #对于继承的父类里有相同的方法,谁在前面执行谁
pass
tc = Touringcar()
tc.live()
tc.drive()
tc.test()
居住
行驶
车辆类的方法8.7.3:重写
子类会原封不动地继承父类的方法,但子类有时需要按照自己的需求对继承来的方法进行调整,也就是 在子类中重写从父类继承来的方法。
在子类中定义与父类方法同名的方法,在方法中按照子类需求重新编写功能代码即可。
bash
#父类
class Person:
def sayhi(self):
print('Hello')
#子类
class China(Person):
def sayhi(self):
print('你好')
china = China()
china.sayhi()
你好子类重写了父类的方法之后,无法直接访问父类的同名方法,但可以使用super()函数间接调用父类中被 重写的方法。
bash
class Person:
def sayhi(self):
print('Hello')
#子类
class China(Person):
def sayhi(self):
super().sayhi() #super()相当于car = Car()创建对象,创建父类的对象调用
print('你好')
china = China()
china.sayhi()
Hello
你好8.7:多态
多态是面向对象的重要特性之一,它的直接表现即让不同类的同一功能可以通过同一个接口调用,表现 出不同的行为。
bash
#多态
#类1
class Dog:
def shout(self):
print('汪~')
#类2
class Cat:
def shout(self):
print('喵~')
#接口
def call(obj):
obj.shout()
#创建对象
dog = Dog()
cat = Cat()
call(dog)
call(cat)
汪~
喵~示例:电脑通过USB接口和鼠标键盘连接
bash
#笔记本电脑类
class computer:
#USB接口1
def usb1(self,obj):
obj.doing()
#USB接口2
def usb2(self,obj):
obj.doing()
#鼠标类
class mouse:
def doing(self):
print('拖拽,点击')
#键盘类
class keyboard:
def doing(self):
print('打字')
computer = computer()
mouse = mouse()
keyboard = keyboard()
#鼠标插入USB1 #键盘和鼠标调换位置输出结果相同
computer.usb1(mouse)
#键盘插入USB2
computer.usb2(keyboard)
拖拽,点击
打字第9章:异常
程序开发或运行时可能出现异常,开发人员和运维人员需要辨别程序的异常,明确这些异常是源于程序 本身的设计问题,还是由外界环境的变化引起,以便有针对性地处理异常。
程序运行出现异常时,若程序中没有设置异常处理功能,解释器会采用系统的默认方式处理异常,即返 回异常信息、终止程序。
9.1:异常概述
异常信息中通常包含异常代码所在行号、异常的类型和异常的描述信息。
9.1.1:异常示例
bash
Traceback (most recent call last):
File "E:\pyproject\异常\异常概念.py", line 1, in <module>
print(5/0)
~^~
ZeroDivisionError: division by zero9.1.2:异常类型
Python程序运行出错时产生的每个异常类型都对应一个类,程序运行时出现的异常大多继承自 Exception类,Exception类又继承了异常类的基类BaseException。
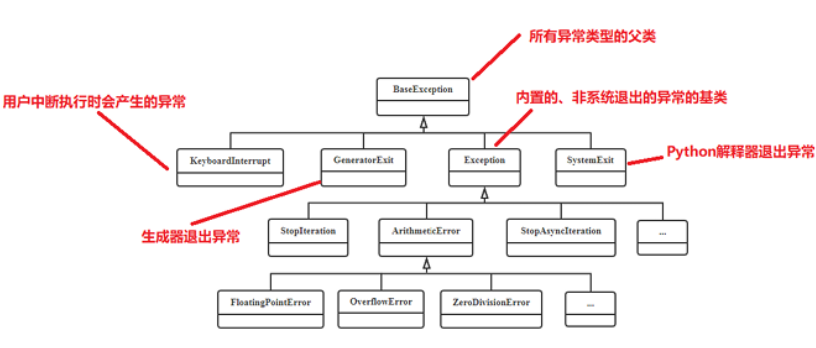
1)NameError
- NameError是程序中使用了未定义的变量时会引发的异常。
- 例如,访问一个未声明过的变量test,代码如下:
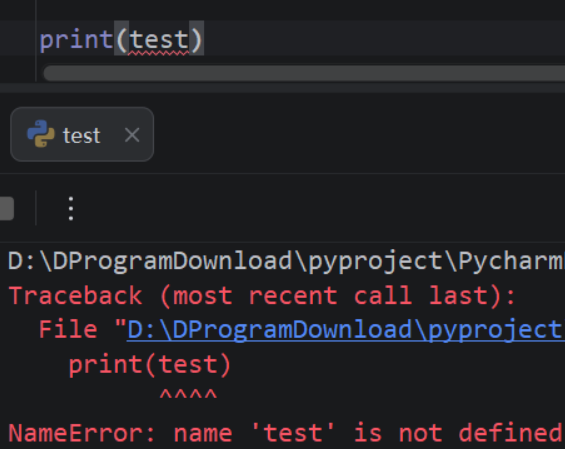
2)IndexError
- IndexError是程序越界访问时会引发的异常。
- 例如,使用索引0访问空列表num_list,代码如下:
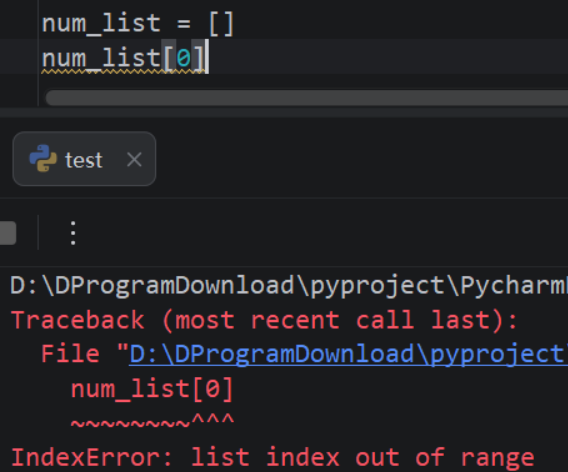
3) AttributeError
- AttributeError是使用对象访问不存在的属性时引发的异常。
- 例如,Car类中动态地添加了两个属性color和brand,使用Car类的对象依次访问color、brand属 性及不存在的name属性,代码如下:
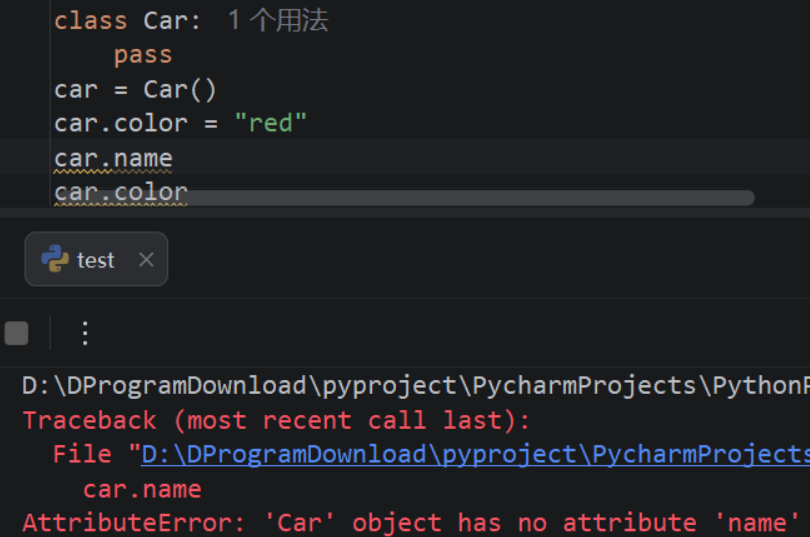
4)FileNotFoundError
- FileNotFoundError是未找到指定文件或目录时引发的异常。
9.2:异常捕获语句
Python既可以直接通过try-except语句实现简单的异常捕获与处理的功能,也可以将try-except语句与 else或finally子句组合实现更强大的异常捕获与处理的功能。
9.2.1:try-except语句捕获异常
bash
try:
可能出错的代码
except [异常类型 [as error]]: # 将捕获到的异常对象赋error
捕获异常后的处理代码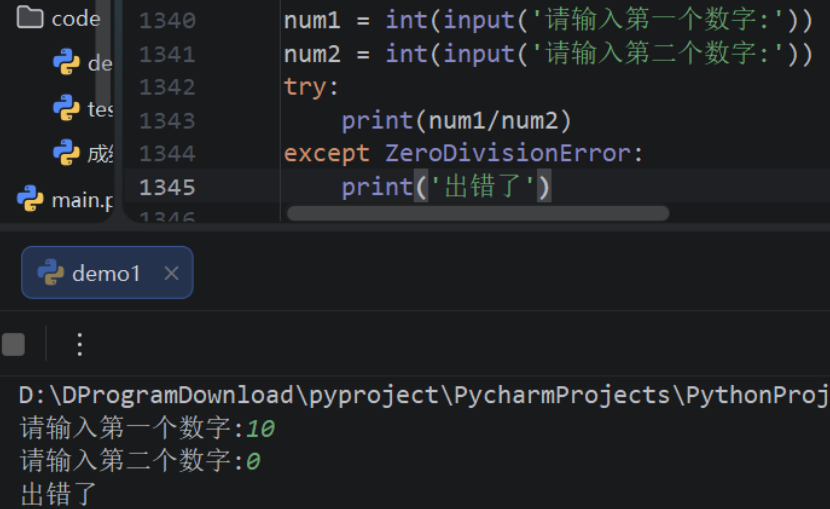
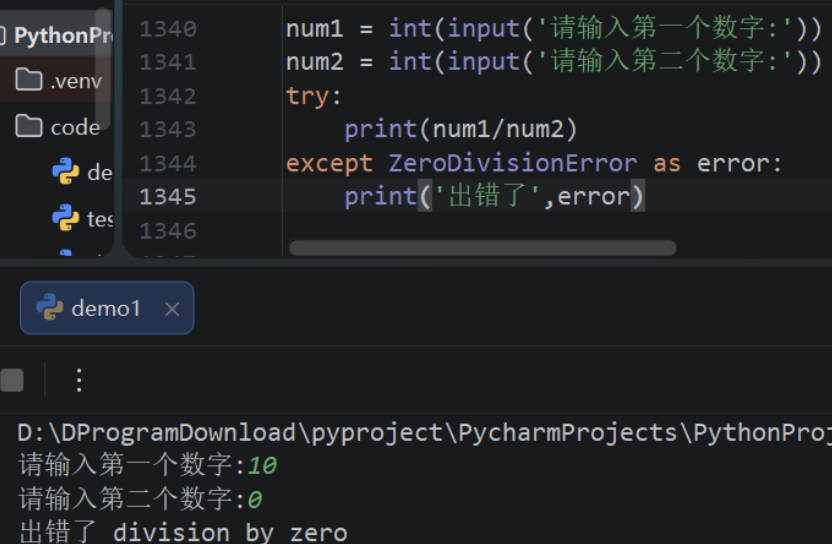
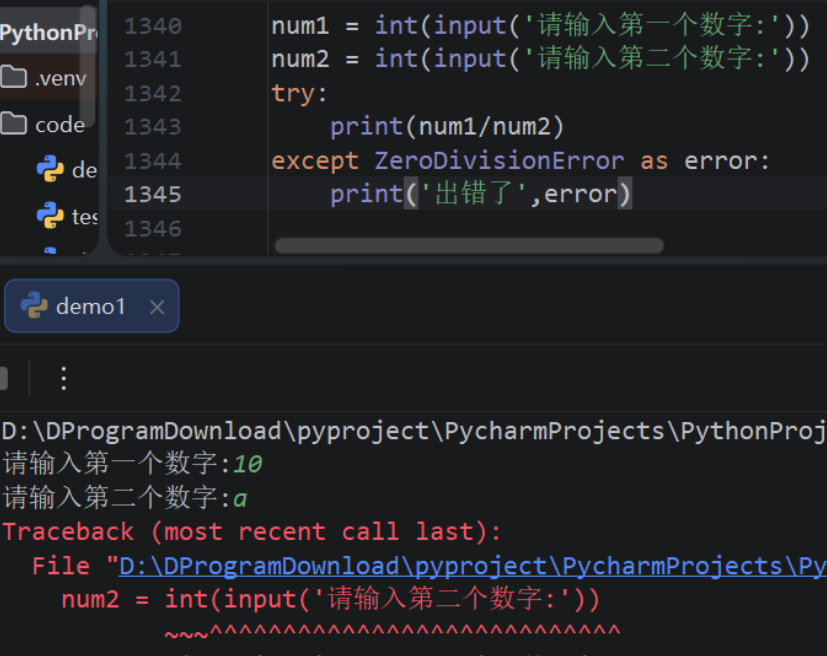
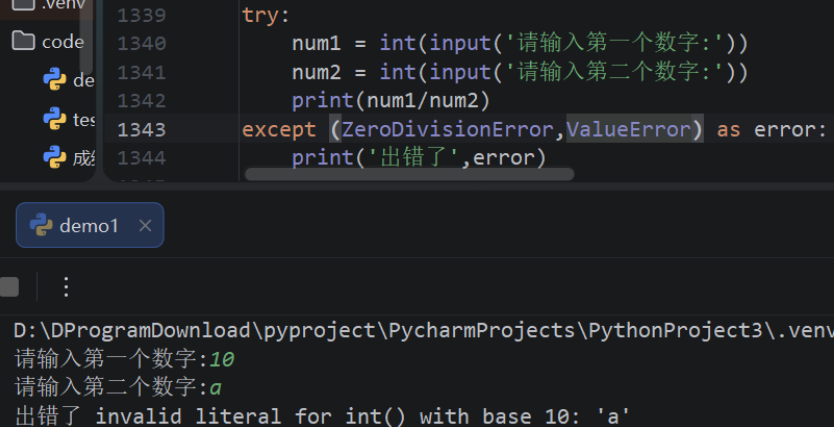
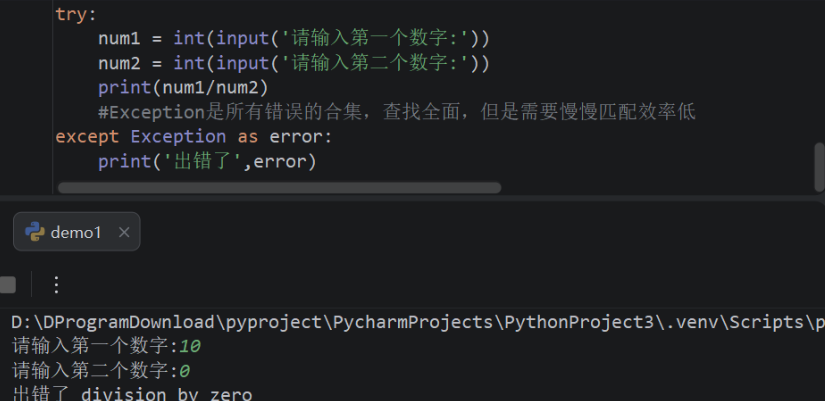
9.2.2:异常结构中的else子句
else子句可以与try-except语句组合成try-except-else结构,若try监控的代码没有异常,程序会执行else 子句后的代码。
bash
try:
可能出错的代码
except [异常类型 [as error]]: # 将捕获到的异常对象赋值error
捕获异常后的处理代码
else:
未捕获异常后的处理代码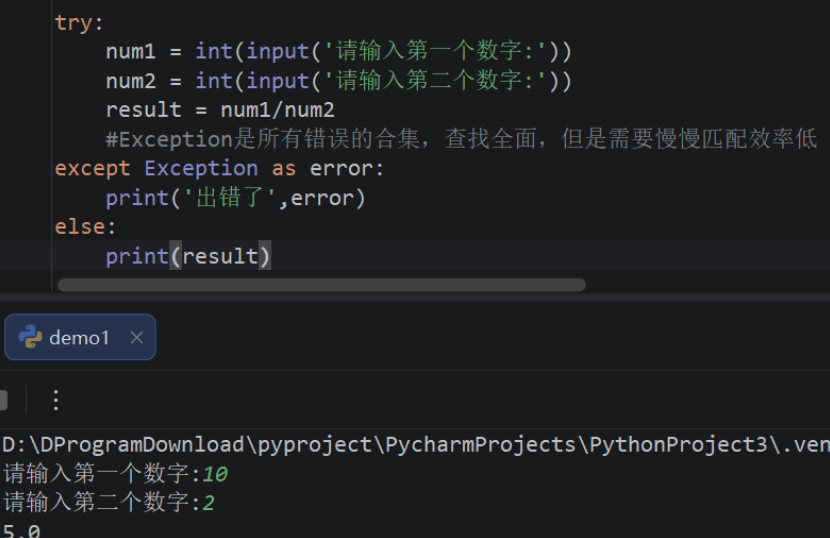
9.2.3:异常结构中的finally子句
finally子句可以和try-except一起使用,语法格式如下:
bash
try:
可能出错的代码
except [异常类型 [as error]]: # 将捕获到的异常对象赋值error
捕获异常后的处理代码
finally:
一定执行的代码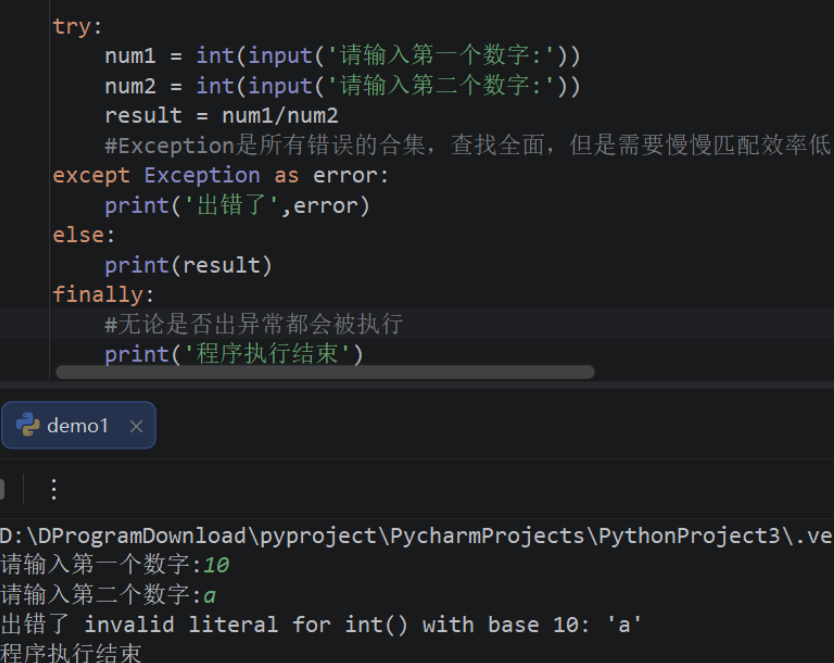
- 无论try子句监控的代码是否产生异常,finally子句都会被执行。
- finally子句多用于预设资源的清理操作,如关闭文件、关闭网络连接。
9.3:抛出异常
Python程序中的异常不仅可以自动触发异常,而且还可以由开发人员使用raise和assert语句主动抛出异常。
Python程序中的异常不仅可以自动触发异常,而且还可以由开发人员使用raise和assert语句主动抛出异常。
9.3.1:raise语句抛出异常 、
使用raise语句可以显式地抛出异常, raise语句的语法格式如下:
bash
raise 异常类 # 格式1:使用异常类名引发指定的异常
raise 异常类对象 # 格式2:使用异常类的对象引发指定的异常
raise # 格式3: 使用刚出现过的异常重新引发异常 1)异常类
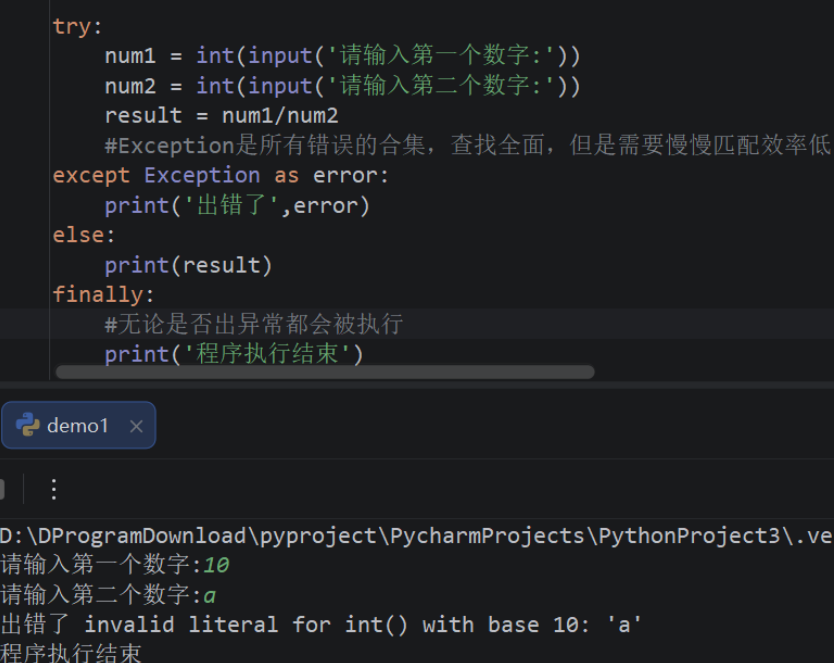
2)异常对象
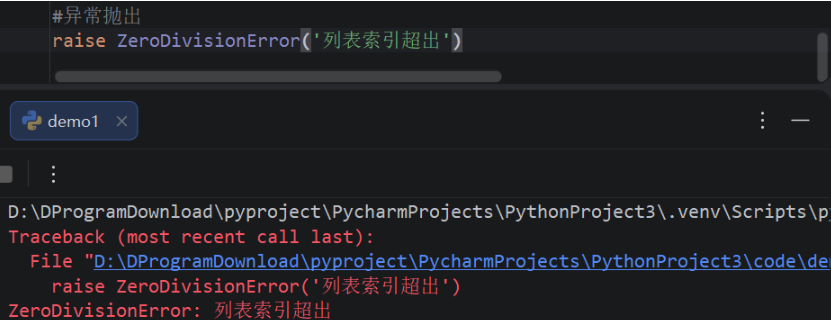
3)重新引发异常
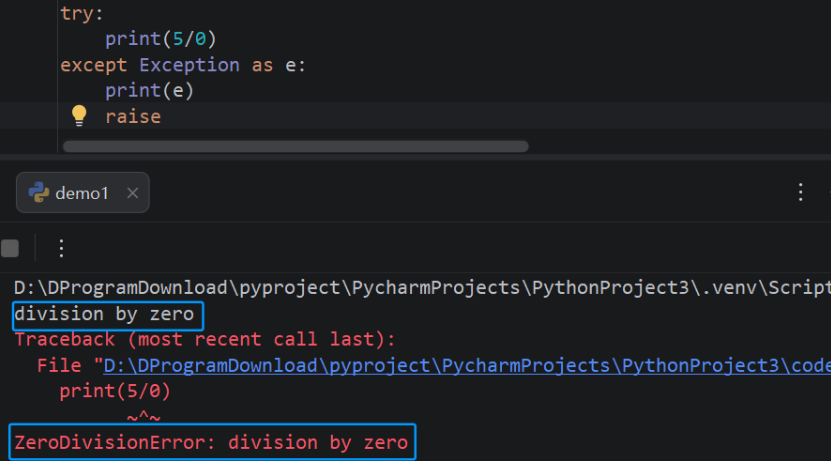
4)异常引发异常
如果需要在异常中抛出另外一个异常,可以使用raise-from语句实现。
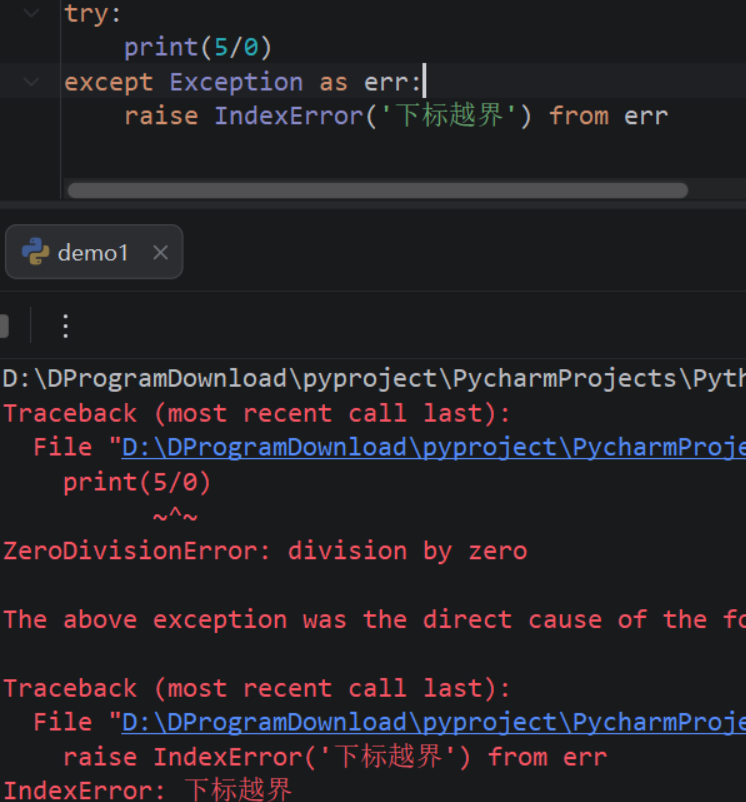
9.3.2:assert语句抛出异常
assert语句又称为断言语句,其语法格式如下所示:
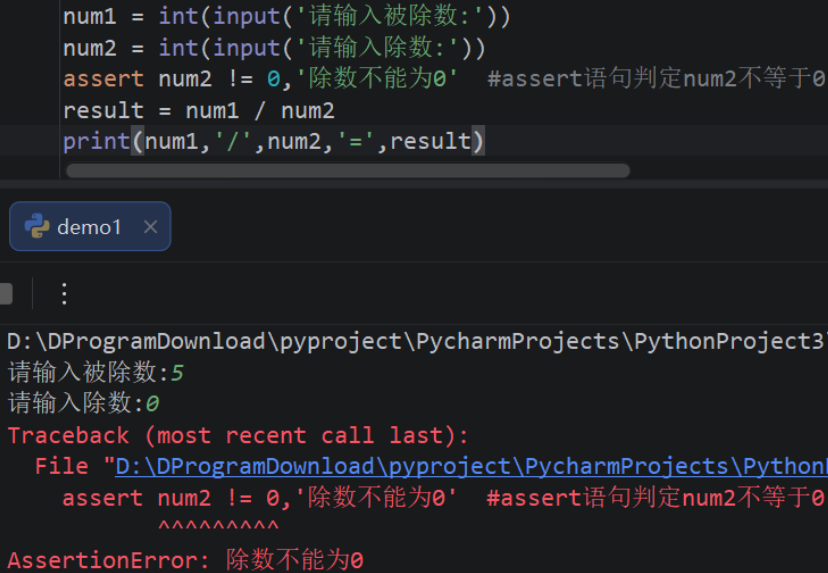
9.3.3:异常的传递
异常(exceptions)是通过栈(stack)传递的。当函数中发生异常,该异常会被抛出(raised),然后 由最内层的函数向外传递,直到被捕获(caught)或者导致程序终止。
bash
#异常的传递
def func_b():
print('Inside func_b')
raise ValueError('An error occurred')
def func_a():
print('Inside func_a')
func_b()
try:
func_a()
except ValueError as e:
print(f'An error occurred: {e}')
Inside func_a
Inside func_b
An error occurred: An error occurred9.4:自定义异常
有时我们需要自定义异常类,以满足当前程序的需求。自定义异常的方法比较简单,只需要创建一个继 承Exception类或Exception子类的类(类名一般以"Error"为结尾)即可。
bash
#自定义异常
class ShortPwd(Exception):
def __init__(self,length,atleast):
self.length = length
self.atleast = atleast
try:
text = input('请输入密码:')
if len(text) < 3 :
raise ShortPwd(len(text),3)
except ShortPwd as result:
print(f'ShortPwd:输入的密码长度为{result.length},长度至少应该是{result.atleast}')
请输入密码:12
ShortPwd:输入的密码长度为2,长度至少应该是3
###################
请输入密码:123实验(终)
python
#管理员账号名为root,密码为12345
#普通用户密码为123
#列出所有学生的成绩函数
def func_total():
print('姓名 语文 数学 英语')
for k in info.keys():
print(k,end=' ')
for v in info[k]:
print(v,end=' ')
print()
#列出指定学生的成绩函数
def func_personal(name):
print('姓名 语文 数学 英语')
for k in info.keys():
if name == k:
print(k,end=' ')
for v in info[k]:
print(v,end=' ')
print()
#判断输入分数是否满足一定范围函数
def score_range(score):
class Score:
def __init__(self, name):
self.name = name
self.score = -1
def set_score(self, score):
if 0 <=score <= 100:
self.score = score
def get_score(self):
return self.score
user = Score(name)
user.set_score(score)
score = user.get_score()
if score == -1 :
print('你输入的成绩有误,请重新输入!')
else:
return score
menu1 = '''
1.录入成绩
2.查询成绩
3.修改成绩
4.删除成绩
5.退出登录
'''
menu2 = '''
1.查询成绩
2.退出登录
'''
menu3 = '''
1.登录系统
2.退出系统
'''
password = {'root':'12345','user':'123'}
info = {'张飞':[67,68,69],'刘备':[78,79,70]}
while True:
print(menu3)
choice = int(input('请输入你的选择:'))
if choice == 1:
user_name = input('请输入你的用户名:')
#管理员的登录
if user_name == 'root':
passwd = input('请输入对应的密码:')
if passwd == password['root']:
while True:
print(menu1)
choice_1 = int(input('请输入你的选项:'))
if choice_1 == 1:
name = input('请输入录入的姓名:')
tmp = []
doing = True
for i in info.keys():
if i == name:
doing = False
print('该用户已经存在,请重新输入')
if doing:
score_1 = int(input('请输入语文成绩:'))
if str(score_range(score_1)).isdigit():
tmp.append(score_1)
else:
break
score_2 = int(input('请输入数学成绩:'))
if str(score_range(score_2)).isdigit():
tmp.append(score_2)
else:
break
score_3 = int(input('请输入英语成绩:'))
if str(score_range(score_3)).isdigit():
tmp.append(score_3)
else:
break
info[name] = tmp
print(f'{name}成绩录入成功')
elif choice_1 == 2:
print('1:查看全部信息 2:查看个人信息')
choice_2 = int(input('请输入你的选择:'))
if choice_2 == 1:
func_total()
elif choice_2 == 2:
name = input('请输入所需查询的姓名:')
doing = True
for i in info.keys():
if name == i:
doing = False
func_personal(name)
if doing:
print('用户不存在,请重新输入!')
elif choice_1 == 3:
func_total()
name = input('请输入需要修改的用户名:')
doing = True
for i in list(info.keys()):
if name == i:
doing = False
print('1:语文 2:数学 3:英语')
choice_3 = int(input('请输入修改的学科序号:'))
score = int(input('请输入修改后的分数:'))
if str(score_range(score)).isdigit():
for k in info.keys():
if name == k:
info[k][choice_3 - 1] = score
print('修改成功')
else:
break
if doing:
print('用户不存在,请重新输入!')
elif choice_1 == 4:
func_total()
name = input('请输入删除的用户名:')
doing = True
for k in list(info.keys()):
if name == k:
doing = False
info.pop(k)
print('删除成功')
if doing:
print('用户不存在,请重新输入!')
else:
print('退出登录')
break
else:
print('密码输入错误请重新登录!')
#普通用户的登录
else:
doing = True
for k in info.keys():
if user_name == k:
doing = False
passwd = input('请输入对应的密码:')
if passwd == password['user']:
while True:
print(menu2)
choice_1 = int(input('请输入你的选项:'))
if choice_1 == 1:
func_personal(user_name)
elif choice_1 == 2:
print('退出登录')
break
else:
print('密码输入错误请重新登录!')
if doing:
print('没有该用户请重新登录!')
else:
print('退出系统')
break系统信息模块
系统基础信息采集模块作为监控模块的重要组成部分,能够帮助运维人员了解当前系统的健康程度,同 时也是衡量业务的服务质量的依据,比如系统资源吃紧,会直接影响业务的服务质量及用户体验,另外 获取设备的流量信息,也可以让运维人员更好地评估带宽、设资源是否应该扩容。
本章通过运用Python第三方系统基础模块,可以轻松获取服务关键运营指标数据,包括Linux基本性 能、块设备、网卡接口、系统信息、网络地址库等信息。在采集到这些数据后,我们就可以全方位了解 系统服务的状态,再结合告警机制,可以在第一时间响应,将异常出现在苗头时就得以处理。
系统性能信息模块 psutil
psutl是一个跨平台库,能够轻松实现获取系统运行的进程和系统利用率(包括CPU、内存、磁盘、网络 等)信息。它主要应用于系统监控,分析和限制系统资源及进程的管理。
案例:获取当前物理内存总大小及已使用大小
shell脚本格式
bash
物理内存total值: free -m | grep Mem | awk '{print $2}'
物理内存used值: free -m | grep Mem | awk '{print $3}'psutil模块的Python源码
bash
import psutil
#获取内存对象
men_info = psutil.virtual_memory()
print('内存的总大小:',men_info.total)获取系统性能信息
采集系统的基本性能信息包括 CPU、内存、磁盘、网络等,可以完整描述当前系统的运行状态及质量。 psutil模块已经封装了这些方法,用户可以根据自身的应用场景,调用相应的方法来满足需求,非常简单 实用。
CPU 信息
Linux 操作系统的CPU 利用率有以下几个部分:
bash
User Time,执行用户进程的时间百分比;
System Time,执行内核进程和中断的时间百分比;
Wait IO,由于IO 等待而使CPU处于idle(空闲)状态的时间百分比;
Idle,CPU 处于 idle 状态的时间百分比。
bash
#CPU信息
#所有的cpu信息
cpu_info = psutil.cpu_times(percpu=True)
for i in cpu_info:
print(i)
print('usr进程CPU占用:',psutil.cpu_times().user)
#cpu核心数
import psutil as ps
print('逻辑核心数:',ps.cpu_count())
print('物理核心数:',ps.cpu_count(logical=False))
scputimes(user=1892.953125, system=3051.90625, idle=48971.46875, interrupt=579.828125, dpc=751.984375)
scputimes(user=1708.96875, system=1781.015625, idle=50426.28125, interrupt=105.84375, dpc=102.9375)
scputimes(user=2551.140625, system=2123.125, idle=49242.0, interrupt=125.359375, dpc=111.640625)
scputimes(user=1909.109375, system=1655.15625, idle=50352.0, interrupt=94.671875, dpc=84.390625)
scputimes(user=1598.71875, system=1207.28125, idle=51110.265625, interrupt=71.171875, dpc=76.875)
scputimes(user=1075.53125, system=752.2968749999927, idle=52088.4375, interrupt=41.0, dpc=51.609375)
scputimes(user=1029.53125, system=765.9218749999927, idle=52120.8125, interrupt=43.203125, dpc=51.546875)
scputimes(user=824.421875, system=552.4218749999927, idle=52539.421875, interrupt=31.5625, dpc=46.1875)
scputimes(user=1122.96875, system=891.125, idle=51902.171875, interrupt=62.984375, dpc=89.71875)
scputimes(user=566.828125, system=561.03125, idle=52788.40625, interrupt=37.578125, dpc=46.421875)
scputimes(user=1006.15625, system=812.1249999999927, idle=52097.984375, interrupt=46.890625, dpc=63.265625)
scputimes(user=461.984375, system=726.796875, idle=52727.484375, interrupt=39.90625, dpc=50.109375)
scputimes(user=631.6875, system=661.5, idle=52623.078125, interrupt=42.984375, dpc=57.71875)
scputimes(user=324.3125, system=366.7656250000073, idle=53225.17187499999, interrupt=17.953125, dpc=41.796875)
scputimes(user=574.109375, system=668.734375, idle=52673.421875, interrupt=42.578125, dpc=66.296875)
scputimes(user=397.453125, system=428.0156250000073, idle=53090.79687499999, interrupt=40.421875, dpc=56.5)
usr进程CPU占用: 17675.875
逻辑核心数: 16
物理核心数: 8内存信息
Linux 系统的内存利用率信息涉及total(内存总数)、used(已使用的内存数)、free(空闲内存数)、 bufers(缓冲使用数)、cache(缓存使用数)、swap(交换分区使用数)等,分别使用 psutil.virtual_memory()与psutil.swap_memory()方法获取这些信息。
bash
#内存信息
import psutil as ps
men = ps.virtual_memory()
print('内存总大小:',men.total)
print('内存适合用空间',men.used)
print('内存占用的空间',men.percent)
print('虚拟内存swap:',ps.swap_memory())
内存总大小: 17024741376
内存适合用空间 9422450688
内存占用的空间 55.3
虚拟内存swap: sswap(total=3489660928, used=107216896, free=3382444032, percent=3.1, sin=0, sout=0)磁盘信息
在系统的所有磁盘信息中,我们更加关注磁盘的利用率及IO信息,其中磁盘利用率使用 psutil.disk_usage方法获取。磁盘IO信息包括read_count(读IO数)、write_count(写IO数)、 read_bytes(IO 读字节数)、write_bytes(IO写字节数)、read time(磁盘读时间)write_time(磁盘写时间) 等。这些IO信息可以使用psutil.diskiocounters()获取。
bash
#磁盘信息
import psutil as ps
print('磁盘完整信息:',ps.disk_partitions())
print('分区参数使用情况:',ps.disk_usage("D:\\"))
#对于主机的磁盘使用的是磁盘标识符,对于虚拟机使用的是/根目录
print('磁盘总的IO个数,读写信息:',ps.disk_io_counters())
print('每块磁盘IO个数,读写信息:',ps.disk_io_counters(perdisk=True))
磁盘完整信息: [sdiskpart(device='C:\\', mountpoint='C:\\', fstype='NTFS', opts='rw,fixed'), sdiskpart(device='D:\\', mountpoint='D:\\', fstype='NTFS', opts='rw,fixed')]
分区参数使用情况: sdiskusage(total=294973861888, used=177293053952, free=117680807936, percent=60.1)
磁盘总的IO个数,读写信息: sdiskio(read_count=2412077, write_count=3329591, read_bytes=89492992512, write_bytes=103500286464, read_time=1099, write_time=615)
每块磁盘IO个数,读写信息: {'PhysicalDrive0': sdiskio(read_count=2412077, write_count=3329591, read_bytes=89492992512, write_bytes=103500286464, read_time=1099, write_time=615)} #字典形式呈现每块磁盘的信息网络信息
系统的网络信息与磁盘IO类似,涉及几个关键点,包括bytes_sent(发送字节数)、bytes_recv(接收字节 数)、packets_sent(发送数据包数)、packets_recv(接收数据包数)等。这些网络信息使用 psutil.net_io_counters()方法获取。
bash
#网络信息
import psutil as ps
print('网络总IO信息:',ps.net_io_counters())
print('每个网络接口的IO信息:')
for i in ps.net_io_counters(pernic=True).items():
print(i)
网络总IO信息: snetio(bytes_sent=86428511, bytes_recv=1183889925, packets_sent=756953, packets_recv=527053, errin=0, errout=0, dropin=0, dropout=0)
每个网络接口的IO信息:
('以太网', snetio(bytes_sent=86394915, bytes_recv=1183881027, packets_sent=723293, packets_recv=518155, errin=0, errout=0, dropin=0, dropout=0))
('VirtualBox Host-Only Network', snetio(bytes_sent=0, bytes_recv=0, packets_sent=0, packets_recv=0, errin=0, errout=0, dropin=0, dropout=0))
('VirtualBox Host-Only Network #2', snetio(bytes_sent=0, bytes_recv=0, packets_sent=0, packets_recv=0, errin=0, errout=0, dropin=0, dropout=0))
('VirtualBox Host-Only Network #3', snetio(bytes_sent=0, bytes_recv=0, packets_sent=0, packets_recv=0, errin=0, errout=0, dropin=0, dropout=0))
('VirtualBox Host-Only Network #4', snetio(bytes_sent=0, bytes_recv=0, packets_sent=0, packets_recv=0, errin=0, errout=0, dropin=0, dropout=0))
('本地连接* 9', snetio(bytes_sent=0, bytes_recv=0, packets_sent=0, packets_recv=0, errin=0, errout=0, dropin=0, dropout=0))
('本地连接* 10', snetio(bytes_sent=0, bytes_recv=0, packets_sent=0, packets_recv=0, errin=0, errout=0, dropin=0, dropout=0))
('VMware Network Adapter VMnet1', snetio(bytes_sent=1277, bytes_recv=0, packets_sent=1277, packets_recv=0, errin=0, errout=0, dropin=0, dropout=0))
('VMware Network Adapter VMnet8', snetio(bytes_sent=31092, bytes_recv=8898, packets_sent=31092, packets_recv=8898, errin=0, errout=0, dropin=0, dropout=0))
('VMware Network Adapter VMnet2', snetio(bytes_sent=1293, bytes_recv=0, packets_sent=1292, packets_recv=0, errin=0, errout=0, dropin=0, dropout=0))
('WLAN 2', snetio(bytes_sent=0, bytes_recv=0, packets_sent=0, packets_recv=0, errin=0, errout=0, dropin=0, dropout=0))
('Loopback Pseudo-Interface 1', snetio(bytes_sent=0, bytes_recv=0, packets_sent=0, packets_recv=0, errin=0, errout=0, dropin=0, dropout=0))其他系统信息
psutil模块还支持获取用户登录、开机时间等信息
bash
import psutil,datetime
print('当前系统登录用户信息:',psutil.users())
print('开机时间,以时间戳格式返回:',psutil.boot_time())
print('开机时间格式:',datetime.datetime.fromtimestamp(psutil.boot_time()).strftime('%Y-%m-%d%H:%M:%S'))
当前系统登录用户信息: [suser(name='Lenovo', terminal=None, host=None, started=1767170752.4612951, pid=None)]
开机时间,以时间戳格式返回: 1767153122.3770404
开机时间格式: 2025-12-3111:52:02
#提取起始时间戳
import psutil
print(psutil.users())
[suser(name='Lenovo', terminal=None, host=None, started=1767170752.4612951, pid=None)]
import psutil
print(psutil.users()[0])
print(type(psutil.users()[0]))
suser(name='Lenovo', terminal=None, host=None, started=1767170752.4612951, pid=None)
<class 'psutil._ntuples.suser'>
import psutil
print(psutil.users()[0].started)
1767170752.4612951
#转换成时间格式
import psutil,datetime
print('时间戳格式:',psutil.users()[0].started)
print('时间格式:',datetime.datetime.fromtimestamp(psutil.users()[0].started).strftime('%Y-%m-%d %H:%M:%S'))
时间戳格式: 1767170752.4612951
时间格式: 2025-12-31 16:45:52
###########同理############
import psutil as ps
print('提取发送的字节:',ps.net_io_counters()['以太网'].bytes_sent)
提取发送的字节: 106355393
import psutil as ps
print('C盘的权限:',ps.disk_partitions()[0].opts)
C盘的权限: rw,fixed系统进程管理
获得当前系统的进程信息,可以让运维人员得知应用程序的运行状态,包括进程的启动时间、查看或设 置 CPU亲和度、内存使用率、IO信息、socket连接、线程数等,这些信息可以呈现出指定进程是否存 活、资源利用情况,为开发人员的代码优化、问题定位提供很好的数据参考。
进程信息
psutil模块在获取进程信息方面也提供了很好的支持,包括使用 psutil.pids()方法获取所有进程 PID,使 用 psutil.Process()方法获取单个进程的名称、路径、状态、系统资源利用率等信息。
bash
#进程信息
import psutil,datetime
print('列出所有进程的PID',psutil.pids())
#实例化一个process对象,参数为PID
p = psutil.Process(1164)
print('进程名称:',p.name())
print('进程的运行(bin)路径:',p.exe())
# print('进程的工作目录绝对路径:',p.cwd()) #linux使用
print('进程的状态:',p.status())
print('进程的创建时间戳:',p.create_time())
print('进程的创建时间:',datetime.datetime.fromtimestamp(p.create_time()).strftime('%Y-%m-%d %H:%M:%S'))
# print('进程的UID信息:',p.uids()) #linux使用
# print('进程的GID信息:',p.gids()) #linux使用
print('进程的CPU时间:',p.cpu_times())
# print('CPU的亲和度:',p.cpu_affinity()) #linux使用
print('进程的内存使用率:',p.memory_percent())
print('进程rss,vms信息:',p.memory_info())
print('进程的IO信息:',p.io_counters())
print('进程开启的线程数:',p.num_threads())
列出所有进程的PID [0, 4, 272, 792, 1164, 1172, 1252, 1324, 1400, 1440, 1456, 1596, 1640, 1688, 1756, 1788, 1860, 1900, 1948, 2076, 2088, 2096, 2200, 2224, 2236, 2296, 2400, 2444, 2480, 2568, 2696, 2732, 2784, 2820, 2888, 2952, 3204, 3208, 3288, 3320, 3364, 3384, 3408, 3432, 3608, 3676, 3700, 3708, 3716, 3772, 3836, 3868, 3916, 3960, 3968, 4108, 4112, 4196, 4200, 4236, 4252, 4376, 4396, 4520, 4564, 4572, 4596, 4684, 4732, 4772, 4776, 4864, 4880, 4884, 4916, 4920, 4932, 5104, 5124, 5132, 5148, 5156, 5164, 5172, 5188, 5196, 5204, 5216, 5236, 5320, 5380, 5488, 5524, 5700, 5712, 6012, 6044, 6248, 6272, 6428, 6452, 6628, 6644, 6804, 6892, 6908, 6924, 7192, 7248, 7328, 7384, 7464, 7608, 7880, 7964, 8076, 8200, 8464, 8524, 8544, 8784, 8816, 8832, 9072, 9092, 9248, 9376, 9404, 10044, 10196, 10308, 10360, 10424, 10432, 10524, 10632, 10720, 10772, 11004, 11064, 11400, 11424, 11632, 11760, 11776, 11948, 12448, 12476, 12628, 12804, 12816, 12876, 12908, 13108, 13272, 13412, 13880, 14008, 14156, 14504, 14756, 15228, 15328, 15536, 15596, 15628, 15716, 15820, 15848, 15868, 15972, 16004, 16224, 16336, 16364, 17044, 17332, 17416, 17440, 17464, 18112, 18308, 18580, 18852, 19116, 19144, 19168, 19224, 19708, 19880, 19964, 20036, 20044, 20212, 20396, 20484, 20624, 20680, 20712, 20916, 21004, 21140, 21164, 21288, 21472, 21592, 21600, 21844, 21896, 21912, 21916, 22120, 22192, 22576, 22704, 22860, 23572, 23824, 24020, 24116, 24340, 24356, 24480, 24604, 24764, 24988, 25204, 25508]
进程名称: csrss.exe
进程的运行(bin)路径: C:\Windows\System32\csrss.exe
进程的状态: running
进程的创建时间戳: 1767153131.992572
进程的创建时间: 2025-12-31 11:52:11
进程的CPU时间: pcputimes(user=0.765625, system=7.5, children_user=0.0, children_system=0.0)
进程的内存使用率: 0.01636018978782518
进程rss,vms信息: pmem(rss=2785280, vms=2539520, num_page_faults=11309, peak_wset=8536064, wset=2785280, peak_paged_pool=348368, paged_pool=312208, peak_nonpaged_pool=31208, nonpaged_pool=27128, pagefile=2539520, peak_pagefile=2891776, private=2539520)
进程的IO信息: pio(read_count=298, write_count=0, read_bytes=232228, write_bytes=0, other_count=48602, other_bytes=1989742)
进程开启的线程数: 13
##########在linux上使用python##############
[root@centos7 python_code 16:15:36]# python3 test.py
列出所有进程的PID [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 30, 31, 32, 33, 41, 42, 43, 44, 45, 46, 47, 60, 95, 264, 275, 276, 277, 278, 279, 280, 282, 284, 290, 291, 302, 303, 304, 305, 306, 307, 308, 309, 310, 311, 312, 313, 314, 315, 316, 317, 318, 319, 320, 321, 322, 323, 324, 325, 326, 327, 328, 329, 330, 331, 332, 333, 334, 335, 336, 337, 338, 339, 340, 341, 342, 343, 344, 345, 346, 347, 348, 349, 350, 351, 352, 353, 354, 355, 356, 357, 358, 359, 360, 361, 362, 363, 364, 365, 366, 367, 368, 369, 370, 371, 372, 373, 374, 375, 376, 377, 378, 379, 380, 381, 382, 383, 384, 385, 386, 387, 388, 389, 453, 454, 463, 464, 477, 478, 479, 480, 481, 482, 483, 484, 485, 486, 487, 488, 566, 593, 596, 641, 646, 648, 654, 657, 659, 660, 661, 664, 665, 680, 682, 683, 685, 687, 689, 691, 693, 719, 745, 746, 747, 750, 751, 755, 764, 770, 773, 823, 1039, 1040, 1042, 1184, 1187, 1188, 1300, 1323, 1325, 1374]
进程名称: scsi_eh_2
进程的运行(bin)路径:
进程的工作目录绝对路径: /
进程的状态: sleeping
进程的创建时间戳: 1767514317.58
进程的创建时间: 2026-01-04 16:11:57
进程的UID信息: puids(real=0, effective=0, saved=0)
进程的GID信息: pgids(real=0, effective=0, saved=0)
进程的CPU时间: pcputimes(user=0.0, system=0.0, children_user=0.0, children_system=0.0, iowait=0.0)
CPU的亲和度: [0]
进程的内存使用率: 0.0
进程rss,vms信息: pmem(rss=0, vms=0, shared=0, text=0, lib=0, data=0, dirty=0)
进程的IO信息: pio(read_count=0, write_count=0, read_bytes=0, write_bytes=0, read_chars=0, write_chars=0)
进程开启的线程数: 1实用的IP地址处理模块IPy
IP地址的基础知识
回环地址适用于测试宿主机的TCP/IP协议,测试ip是否通直接ping 主机ip
ARP协议是将IP地址转换成MAC地址

注:对端连调使用30网段的地址,只有两个可用ip,可以避免其他局域网的攻击
IP 地址、网段的基本处理
bash
#查看地址类型
from IPy import IP
v1 = IP('192.168.1.1/32').version()
print(v1)
v2 = IP('::1').version()
print(v2)
4
6
#查看指定网段的所有IP清单,只能使用网络号
from IPy import IP
ip = IP('192.168.108.8/30')
print(ip.len())
for i in ip:
print(i)
4
192.168.108.8 #网络号
192.168.108.9 #可用地址只有两个
192.168.108.10
192.168.108.11 #主机号
from IPy import IP
ip = IP('192.168.1.20')
#反向解析地址格式
print(ip.reverseNames())
#地址类型
print(ip.iptype())
print(IP('8.8.8.8').iptype())
print(IP('255.255.255.255').iptype())
print('十进制',IP('8.8.8.8').int())
print('二进制',IP('8.8.8.8').strBin())
print('十六进制',IP('8.8.8.8').strHex())
#十六进制转换为IP格式
print(IP(0x8080808))
['20.1.168.192.in-addr.arpa.']
PRIVATE #私有地址
PUBLIC #公有地址
RESERVED #保留地址
十进制 134744072
二进制 00001000000010000000100000001000
十六进制 0x8080808
8.8.8.8
ip不是网络号,不能通过指定的网段输出该网段的IP个数及所有IP地址清单
IP方法也支持网络地址的转换,例如根据IP与掩码生产网段格式。
bash
from IPy import IP
#指定子网掩码
print(IP('192.168.1.0').make_net('255.255.255.0'))
print(IP('192.168.1.0/255.255.255.0',make_net=True))
#指定网段
print(IP('192.168.1.0-192.168.1.255',make_net=True))
192.168.1.0/24
192.168.1.0/24
192.168.1.0/24也可以通过 strNormal方法指定不同 wantprefxlen参数值以定制不同输出类型的网段,输出类型为字符 串。
bash
from IPy import IP
print('0格式:',IP('192.168.1.0/24').strNormal(0))
print('1格式:',IP('192.168.1.0/26').strNormal(1))
print('2格式:',IP('192.168.1.0/27').strNormal(2))
print('3格式:',IP('192.168.1.0/28').strNormal(3))
0格式: 192.168.1.0
1格式: 192.168.1.0/26
2格式: 192.168.1.0/255.255.255.224
3格式: 192.168.1.0-192.168.1.15含义:
wantprefxlen=0,无返回,如192.168.1.0;
wantprefxlen=1,prefx格式,如 192.168.1.0/24;
wantprefxlen=2,decimalnetmask格式,如192.168.1.0/255.255.255.0;
wantprefxlen=3,lastIP 格式,如192.168.1.0-192.168.1.255。
多网络计算方法详解
有时候我们想比较两个网段是否存在包含、重叠等关系,比如同网络但不同prefxlen 会认为是不相等的 网段,如10.0.0.0/16不等于10.0.0.0/24,另外即使具有相同的 prefxlen 但处于不同的网络地址,同样 也视为不相等,如10.0.0.0/16不等于192.0.0.0/16。IPy支持类似于数值型数据的比较。
IP对象进行比较。
判断 IP地址 和网段是否包含于另一个网段中。
bash
from IPy import IP
print(IP('10.1.0.0/24') < IP('12.0.0.0/24')) #网络号的判断
print('192.168.108.3' in IP('192.168.108.0/24'))
print(IP('192.168.1.0/24') in IP('192.168.0.0/16'))
True
True
True判断两个网段是否存在重叠,采用IPy提供的overlaps方法,1代表重叠,0代表不重叠。
bash
from IPy import IP
print(IP('192.168.0.0/23').overlaps('192.168.1.0/24'))
print(IP('192.168.1.0/24').overlaps('192.168.2.0/24'))
1
0根据输入的IP或子网返回网络、掩码、广播、反向解析、子网数、IP类型等信息。
bash
from IPy import IP
words = input('请输入IP或者网段:')
ip = IP(words)
if len(ip) > 1:
print('网络地址:',ip.net())
print('子网掩码:',ip.netmask())
print('广播地址:',ip.broadcast())
print('反向地址解析:',ip.reverseNames())
print('网络子网数:',len(ip))
else:
print('反向地址解析:',ip.reverseNames()[0])
print('十六进制:',ip.strHex())
print('十进制:',ip.int())
print('二进制:',ip.strBin())
print('地址类型:',ip.iptype())
#输入网段
请输入IP或者网段:192.168.1.0/24
网络地址: 192.168.1.0
子网掩码: 255.255.255.0
广播地址: 192.168.1.255
反向地址解析: ['1.168.192.in-addr.arpa.']
网络子网数: 256
#当len(ip)=1 时即只有一个IP地址,输入地址
请输入IP或者网段:192.168.1.2/32
反向地址解析: 2.1.168.192.in-addr.arpa.
十六进制: 0xc0a80102
十进制: 3232235778
二进制: 11000000101010000000000100000010
地址类型: PRIVATE系统批量运维管理器 paramiko
paramiko 是基于Python 实现的SSH2远程安全连接,支持认证及密钥方式。可以实现远程命令执行、 文件传输、中间 SSH代理等功能,相对于Pexpect,封装的层次更高,更贴近SSH协议的功能。
1:paramiko 的安装
虚拟机的python操作:
安装python3环境 --> pip的镜像源配置 --> 安装psutil模块
bash
[root@centos7 ~ 10:27:13]# yum install -y openssl-devel bzip2-devel expat-devel gdbm-devel readline-devel sqlite-devel libffi-devel gcc gcc-c++
[root@centos7 ~ 10:27:13]# tar zxvf Python-3.13.2.tgz
[root@centos7 ~ 10:27:13]# cd Python-3.13.2/
[root@centos7 Python-3.14.2 10:33:36]# ./configure --prefix=/usr/local/python3
[root@centos7 Python-3.14.2 10:33:36]# make && make install
[root@centos7 Python-3.14.2 10:33:36]# ln -s /usr/local/python3/bin/python3 /usr/bin/python3
[root@centos7 Python-3.14.2 10:35:12]# ln -s /usr/local/python3/bin/pip3 /usr/bin/pip
[root@centos7 Python-3.14.2 10:35:37]# python3 --version
Python 3.14.2
[root@centos7 Python-3.14.2 10:36:33]# pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple/
[root@centos7 Python-3.14.2 10:36:33]# vim /root/.config/pip/pip.conf
[root@centos7 Python-3.14.2 10:38:11]# cat /root/.config/pip/pip.conf
[root@centos7 ~ 11:17:27]# cat /root/.config/pip/pip.conf
[global]
timeout=40
index-url=http://mirrors.aliyun.com/pypi/simple/
extra-index-url=https://pypi.tuna.tsinghua.edu.cn/simple/ http://pypi.douban.com/simple/ http://pypi.mirrors.ustc.edu.cn/simple/
[install]
trusted-host=pypi.tuna.tsinghua.edu.cn mirrors.aliyun.com pypi.douban.com pypi.mirrors.ustc.edu.cn
[root@centos7 ~ 11:17:54]# /usr/local/python3/bin/python3.13 -m pip install --upgrade pip
[root@centos7 ~ 11:17:54]# mkdir python_code
[root@centos7 ~ 11:32:59]# cd python_code/
#用Xftp将主机的python文件和虚拟机连接
[root@centos7 python_code 11:33:01]# python3 test.py
Traceback (most recent call last):
File "/root/python_code/test.py", line 18, in <module>
import psutil as ps
ModuleNotFoundError: No module named 'psutil #没有安装模块
[root@centos7 python_code 11:40:10]# pip install psutil
[root@centos7 python_code 11:40:51]# pip list
Package Version
------- -------
pip 25.3
psutil 7.2.1
[root@centos7 python_code 11:41:04]# python3 test.py
内存总大小: 1019531264
内存适合用空间 342306816
内存占用的空间 33.6
虚拟内存swap: sswap(total=2147479552, used=270336, free=2147209216, percent=0.0, sin=114688, sout=184320)2:paramiko 的核心组件
paramiko模块包含两个核心组件,一个为SSHClient类,另一个为SFTPClient类。
SSHClient 类
SSHClient类是SSH服务会话的高级表示,该类封装了传输(transport)、通道(channel)及SFTPClient的校 验、建立的方法,通常用于执行远程命令。
1.connect 方法
connect方法实现了远程SSH连接并校验。
bash
connect(self,hostname,port=22,username=None,password=None,pkey=None,key_filename
=None,timeout=None,allow_agent=True,look_for_keys=True, compress=False)
bash
hostname(str类型),连接的目标主机地址; *
port(int类型),连接目标主机的端口,默认为22; *
username(str类型),校验的用户名(默认为当前的本地用户名); *
password(str类型),密码用于身份校验或解锁私钥; *
pkey(PKey类型),私钥方式用于身份验证;
key_filename(str or list(str)类型),一个文件名或文件名的列表,用于私钥的身份验证:
timeout(foat类型),一个可选的超时时间(以秒为单位)的TCP连接;
allow_agent(bool类型),设置为False 时用于禁用连接到 SSH 代理;
look_for_keys(bool类型),设置为 False 时用来禁用在~/.ssh 中搜索私钥文件;
compress(bool类型),设置为 True 时打开压缩。2:exec_command 方法
远程命令执行方法,该命令的输入与输出流为标准输人(stdin)、输出(stdout)、错误(stderr)的 Python 文件对象。
bash
exec_command(self, command, bufsize=-1)
bash
command(str类型),执行的命令串;
bufsize(int类型),文件缓冲区大小,默认为-1(不限制)。3: set_missing_host_key_policy方法
设置连接的远程主机没有本地主机密钥或HostKeys对象时的策略,目前支持三种,别是 AutoAddPolicy、RejectPolicy(默认)、WarningPolicy,仅限用于SSHClient类。
bash
ssh=paramiko.SSHClient()
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
bash
AutoAddPolicy,自动添加主机名及主机密钥到本地HostKeys对象,并将其保存;
RejectPolicy,自动拒绝未知的主机名和密钥;
WarningPolicy,用于记录一个未知的主机密钥的Python警告,并接受它,功能上与AutoAddPolicy相似,但未知主机会有告警案例:创建ssh客户端远程指令free -m 获取内存状态信息
python
#利用python远程获取一台主机的信息,远程执行指令返回在pycharm
#导入paramiko包
import paramiko as pk
#获取密码函数
def get_pwd(filename):
with open(filename) as f:
return f.read()
#四要素
host = '192.168.108.128'
port = 22
user = 'root'
passwd = get_pwd('passwd.txt')
#记录日志
pk.util.log_to_file('system.log')
#创建python客户端
ssh_client = pk.SSHClient()
#设置客户访问策略
ssh_client.set_missing_host_key_policy(pk.AutoAddPolicy())
#连接远程服务器
ssh_client.connect(hostname=host,port=port,username=user,password=passwd,allow_agent=False)
#执行命令
stdin,stdout,stderr = ssh_client.exec_command('free -m')
#解析返回结果
for line in stdout:
print(line)
#关闭资源
#关闭标准输入
stdin.close()
#关闭客户端
ssh_client.close()
total used free shared buff/cache available
Mem: 972 126 739 7 106 719
Swap: 2047 0 2047
####################将信息写入到文件中########################
#利用python远程获取一台主机的信息,远程执行指令返回在pycharm
#导入paramiko包
import paramiko as pk
#获取密码函数
def get_pwd(filename):
with open(filename) as f:
return f.read()
#四要素
host = '192.168.108.128'
port = 22
user = 'root'
passwd = get_pwd('passwd.txt')
#记录日志
pk.util.log_to_file('system.log')
#创建python客户端
ssh_client = pk.SSHClient()
#设置客户访问策略
ssh_client.set_missing_host_key_policy(pk.AutoAddPolicy())
#连接远程服务器
ssh_client.connect(hostname=host,port=port,username=user,password=passwd,allow_agent=False)
#执行命令
stdin,stdout,stderr = ssh_client.exec_command('free -m')
#解析返回结果
with open('content.txt','w') as f:
for line in stdout:
f.write(line)
print('写入完成')
#关闭资源
#关闭标准输入
stdin.close()
#关闭客户端
ssh_client.close()利用python远程获取一台主机的信息,远程执行指令返回在pycharm:
1.导入paramiko模块
2.四要素 :hostname,port,username,password
3.记录日志
4.创建python客户端
5.远程连接客户端策略
7.执行命令
8.解析返回结果
9.关闭资源
示例:巡检2台服务器,获取内存信息,把free状态的容量进行排序统计,并生成到sort.txt文件中
bash
import paramiko as pk
def get_pwd(filename):
with open(filename, 'r') as f:
return f.read()
hosts = ['192.168.108.128','192.168.108.144']
port = 22
user = 'root'
pwd = get_pwd('passwd.txt')
def get_info(host,port,user,pwd):
pk.util.log_to_file('system.log')
ssh_client = pk.SSHClient()
ssh_client.set_missing_host_key_policy(pk.AutoAddPolicy())
ssh_client.connect(hostname=host,port=port,username=user,password=pwd,allow_agent=False)
stdin,stdout,stderr = ssh_client.exec_command('free -m | grep Mem | awk \'{print $4}\'')
return stdout,stderr
infos = {}
for ip in hosts:
mem,err = get_info(ip,port,user,pwd)
for i in mem:
line = int(i.rstrip('\n'))
infos[f'{ip}'] = line
print(infos)
`sort_dict = dict(sorted(infos.items(),key=lambda x:x[1],reverse=True)) #Infos.items()输出结果是元组类型,x[1]对应的是数值`
print(sort_dict)
for k,v in sort_dict.items():
sort_dict[k] = str(v)
with open('sort.txt','w',encoding='utf-8') as f: #encoding='utf-8' 必须写,否则写入不了
for i in sort_dict.items():
line = i[0] + ' ' + i[1]+'\n' #字符串的拼接
f.write(line)
print('数据写入完成')
{'192.168.108.128': 737, '192.168.108.144': 6864}
{'192.168.108.144': 6864, '192.168.108.128': 737}
数据写入完成
#文件里的内容是
192.168.108.144 6864
192.168.108.128 737SFTPClient类
SFTPClient作为一个 SFTP 客户端对象,根据SSH传输协议的sftp 会话,实现远程文件操作,比如文件上 传、下载、权限、状态等操作。
1:from_transport 方法
创建一个已连通的SFTP 客户端通道。
bash
from_transport(cls,t)2:put方法
上传本地文件到远程SFTP服务端。
bash
put(self, localpath,remotepath, callback=None, confirm=True)
bash
localpath(str类型),需上传的本地文件(源); *
remotepath(str类型),远程路径(目标); *
callback(function(int,int)),获取已接收的字节数及总传输字节数,以便回调函数调用默认为 None
;
confirm(bool类型),文件上传完毕后是否调用stat()方法,以便确认文件的大小。3:get方法
从远程 SFTP 服务端下载文件到本地。
bash
get(self, remotepath, localpath, callback=None)
bash
remotepath(str 类型),需下载的远程文件(源); *
localpath(str 类型),本地路径(目标);*
callback(function(int,int)),获取已接收的字节数及总传输字节数,以便回调函数调用,默认为
None。4:其他方法
bash
mkdir,在SFTP 服务器端创建目录,如 sftp.mkdir("/home/userdir",0755)。
remove,删除SFTP服务器端指定目录,如sftp.remove("/home/userdir")。
rename,重命名SFTP服务器端文件或目录,如
sfp.rename("/home/test.sh","/home/testfile.sh")。
stat,获取远程 SFTP服务器端指定文件信息,如sfp.stat("/home/testflie.sh")。
listdir,获取远程 SFTP服务器端指定目录列表,以Python的列表(List)形式返回,如
sftp.listdir("/home")。**案例:**实现了文件上传、下载、创建与删除目录等,需要注意的是,put和 get方法需要指定文件名,不 能省略。
python
import paramiko as pk
#四要素
host = '192.168.108.128'
port = 22
user = 'root'
passwd = '123'
#创建传输对象
t = pk.Transport((host, port))
#连接传输对象
t.connect(username=user,password=passwd)
#创建SFTP客户端对象
sftp_client = pk.SFTPClient.from_transport(t)
#文件上传
sftp_client.put('..\\data.txt','/root/data.txt') #本地路径 远程路径
print('上传成功')
#文件下载
sftp_client.get('/root/test.txt','./test.txt')#路径一定要精确到文件名 远程路径 本地路径
print('下载成功')
t.close()
#################初次书写路径可能出现错误,结合错误排查使用####################
import paramiko as pk
#四要素
host = '192.168.108.128'
port = 22
user = 'root'
passwd = '123'
try:
#创建传输对象
t = pk.Transport((host, port))
#连接传输对象
t.connect(username=user,password=passwd)
#创建SFTP客户端对象
sftp_client = pk.SFTPClient.from_transport(t)
#文件上传
sftp_client.put('../data.txt','/root/data.txt')
print('上传成功')
#文件下载
sftp_client.get('/root/test.txt','.\\test.txt')
print('下载成功')
t.close()
except Exception as e:
print(e)注意:这里的路径,对于本主机的路径可以采用windows格式也可以是linux书写格式,不影响实验结果,但是对于SFTP文件传输路径一定要精确到文件名
实战:堡垒机模式下的远程命令执行
堡垒机环境在一定程度上提升了运营安全级别,但同时也提高了日常运营成本,作为管理的中转设备, 任何针对业务服务器的管理请求都会经过此节点,比如SSH协议,首先运维人员在办公电脑通过SSH协 议登录堡垒机,再通过堡垒机SSH跳转到所有的业务服务器进行维护操作。
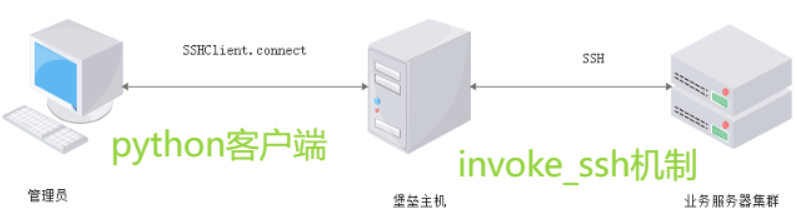
可以利用paramiko的invoke_shell机制来实现通过堡垒机实现服务器操作,原理是SSHClient.connect到 堡垒机后开启一个新的SSH会话(session),通过新的会话运行"ssh user@IP" 去实现远程执行命令的操作。
bash
#导入模块paramiko
import paramiko as pk
import sys
#四要素
#堡垒主机的信息
blip = '192.168.108.128'
bluser = 'root'
blpwd = '123'
#业务服务器的信息
host = '192.168.108.129'
user = 'root'
pwd = '123'
port =22
#设置password提示字符
passinfo = '\'s password: '
#记录日志
pk.util.log_to_file('test.txt')
#创建python客户端
ssh_client = pk.SSHClient()
#设置客户端访问策略
ssh_client.set_missing_host_key_policy(pk.AutoAddPolicy())
#远程连接客户端
ssh_client.connect(hostname=blip,username=bluser,password=blpwd,port=port)
#堡垒主机和业务服务主机之间的ssh连接
#创建会话,开启命令调用
channel = ssh_client.invoke_shell()
#设置会话超时时间,单位为秒
channel.settimeout(10)
#设置缓冲
buff = ''
#设置回答
resp = ''
#执行ssh登录业务服务器指令
channel.send('ssh '+user+'@'+host+'\n')
while not buff.endswith(passinfo):
try:
resp = channel.recv(9999).decode('utf-8')
except Exception as e:
print('Error info:'+str(e)+'connection time.')
channel.close()
ssh_client.close()
sys.exit()
buff += resp
if not buff.find('yes/no') == -1:
channel.send('yes\n')
buff = ''
channel.send(pwd+'\n')
buff = ''
while not buff.endswith('# '):
resp = channel.recv(9999).decode('utf-8')
if not resp.find(passinfo) == -1:
print('Error info:Authentication failed.')
channel.close()
ssh_client.close()
sys.exit()
buff += resp
channel.send('ip -br a\n')
buff = ''
try:
while buff.find('# ') == -1:
resp = channel.recv(9999).decode('utf-8')
buff += resp
except Exception as e:
print('error info:'+str(e))
print(buff)
channel.close()
ssh_client.close()
#####结果
ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
ens33 UP 192.168.108.129/24 fe80::7873:807b:13f6:add0/64
virbr0 DOWN 192.168.122.1/24
virbr0-nic DOWN 实战:实现堡垒机模式下的远程文件上传
实现堡垒机模式下的文件上传,原理是通过paramiko的SFTPCIient将文件从办公设备上传至堡垒机指定 的临时目录,如/tmp,再通过SSHClient的invoke_shell方法开启 ssh会话,执行scp命令,将/tmp下的 指定文件复制到目标业务服务器上。
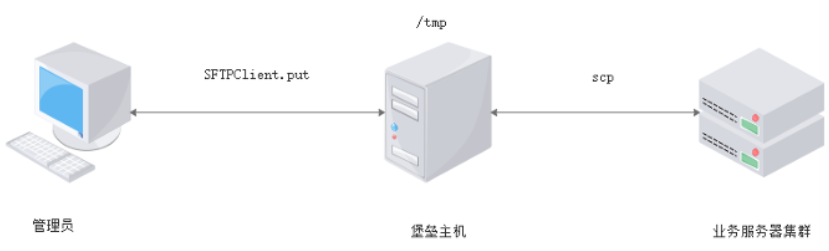
使用 sftp.put()方法上传文件至堡垒机临时目录,再通过send()方法执行scp命令,将堡垒机临时目录下 的文件复制到目标主机。
python
#导入paramiko模块
import paramiko
import sys
#四要素
#堡垒主机
blip = '192.168.108.128'
bluser = 'root'
blpwd = '123'
#业务服务主机
host = '192.168.108.129'
user = 'root'
pwd = '123'
port = 22
#堡垒主机临时目录
tmpdir = '/tmp'
#业务服务主机目标目录
remotedir = '/data'
#本地文件源地址
localpath = 'D:\\DProgramDownload\\pyproject\\PycharmProjects\\PythonProject3\\code\\passwd.txt'
#堡垒主机临时路径
tmppath = tmpdir+'/passwd.txt'
#业务主机目标路径
remotepath = remotedir+'/passwd.txt'
passinfo = '\'s password: '
#记录日志
paramiko.util.log_to_file('test.txt')
#创建传输客户端
t = paramiko.Transport((blip,port))
#连接客户端
t.connect(username=bluser,password=blpwd)
#创建python的SFTP客户端
sftp = paramiko.SFTPClient.from_transport(t)
#上传本地文件到堡垒主机
sftp.put(localpath,tmppath)
sftp.close()
#ssh登录堡垒主机
ssh_client = paramiko.SSHClient()
ssh_client.set_missing_host_key_policy(paramiko.AutoAddPolicy())
ssh_client.connect(hostname=blip,username=bluser,password=blpwd,port=port)
#创建会话,开启命令调用
channel = ssh_client.invoke_shell()
#创建超时时间
channel.settimeout(10)
buff = ''
resp = ''
#在堡垒主机使用SCP命令传输文件
channel.send('scp '+tmppath+' '+user+'@'+host+':'+remotepath+'\n')
while not buff.endswith(passinfo):
try:
resp = channel.recv(9999).decode('utf-8')
except Exception as e:
print('Error info:'+str(e)+'connection time.')
channel.close()
ssh_client.close()
sys.exit()
buff += resp
if not buff.find('yes/no') == -1:
channel.send('yes\n')
buff = ''
#发送业务主机密码
channel.send(pwd+'\n')
buff = ''
while not buff.endswith('# '):
resp = channel.recv(9999).decode('utf-8')
if not resp.find(passinfo) == -1:
print('Error info: Authentication failed.')
channel.close()
ssh_client.close()
sys.exit()
buff += resp
print(buff)
channel.close()
ssh_client.close()