🧑 博主简介:曾任某智慧城市类企业算法总监,CSDN / 稀土掘金 等平台人工智能领域优质创作者。
目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。
引言
在当今社会,烟酒成瘾问题日益严重,影响着无数人的健康和生活质量。通过对3000名烟酒成瘾者的详细数据进行分析,我们可以从多个维度深入了解成瘾者的特征和行为模式。本文将利用 Python 和 PyEcharts,以炫酷的暗黑风格可视化这些数据,揭示隐藏在数字背后的故事。

二、 技术栈
- Python 3.9+
- PyEcharts(支持暗黑主题、动态交互)
- Pandas(数据处理)
- Jupyter Notebook(演示)
三、数据集预览
| 字段名 | 含义 |
|---|---|
| age | 年龄 |
| gender | 性别 |
| country | 国家 |
| education_level | 教育水平 |
| employment_status | 就业状态 |
| annual_income_usd | 年收入(美元) |
| smokes_per_day | 每日吸烟支数 |
| drinks_per_week | 每周饮酒次数 |
| age_started_smoking | 开始吸烟年龄 |
| age_started_drinking | 开始饮酒年龄 |
| attempts_to_quit_smoking | 尝试戒烟次数 |
| attempts_to_quit_drinking | 尝试戒酒次数 |
| has_health_issues | 是否有健康问题 |
| mental_health_status | 心理健康状态 |
| exercise_frequency | 锻炼频率 |
| diet_quality | 饮食质量 |
| sleep_hours | 睡眠时间 |
| bmi | BMI指数 |
四、安装依赖
pip install pyecharts pandas numpy五、数据可视化完整代码(可直接运行)
加载需要的处理库和简单的数据清洗:
python
import pandas as pd
import numpy as np
from pyecharts.charts import *
from pyecharts.globals import ThemeType, SymbolType
import warnings, math, random
from pyecharts.commons.utils import JsCode
from pyecharts import options as opts
warnings.filterwarnings('ignore')
df = pd.read_csv('addiction_population_data.csv')
# 1. 关键字段清洗
df['has_health_issues'] = df['has_health_issues'].astype(int)
df['age_group'] = pd.cut(df['age'], bins=[0,25,35,45,55,100],
labels=['≤25','26-35','36-45','46-55','55+'])
df['income_group'] = pd.qcut(df['annual_income_usd'], q=4,
labels=['低收入','中低收入','中高收入','高收入'])5.1 年龄分布直方图(平滑密度图)
less
# 1. 年龄分布直方图(平滑密度图)
def age_distribution():
return (
Line(init_opts=opts.InitOpts(width="900px", height="500px", theme=theme))
.add_xaxis(df['age'].value_counts().sort_index().index.tolist())
.add_yaxis(
"年龄分布",
df['age'].value_counts().sort_index().values.tolist(),
is_smooth=True,
linestyle_opts=opts.LineStyleOpts(width=4, color="#00f5ff"),
itemstyle_opts=opts.ItemStyleOpts(color="#00f5ff")
)
.set_global_opts(
title_opts=opts.TitleOpts(title="1. 年龄分布(平滑密度图)", subtitle="总人数:3000人"),
xaxis_opts=opts.AxisOpts(name="年龄"),
yaxis_opts=opts.AxisOpts(name="人数"),
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="cross")
)
)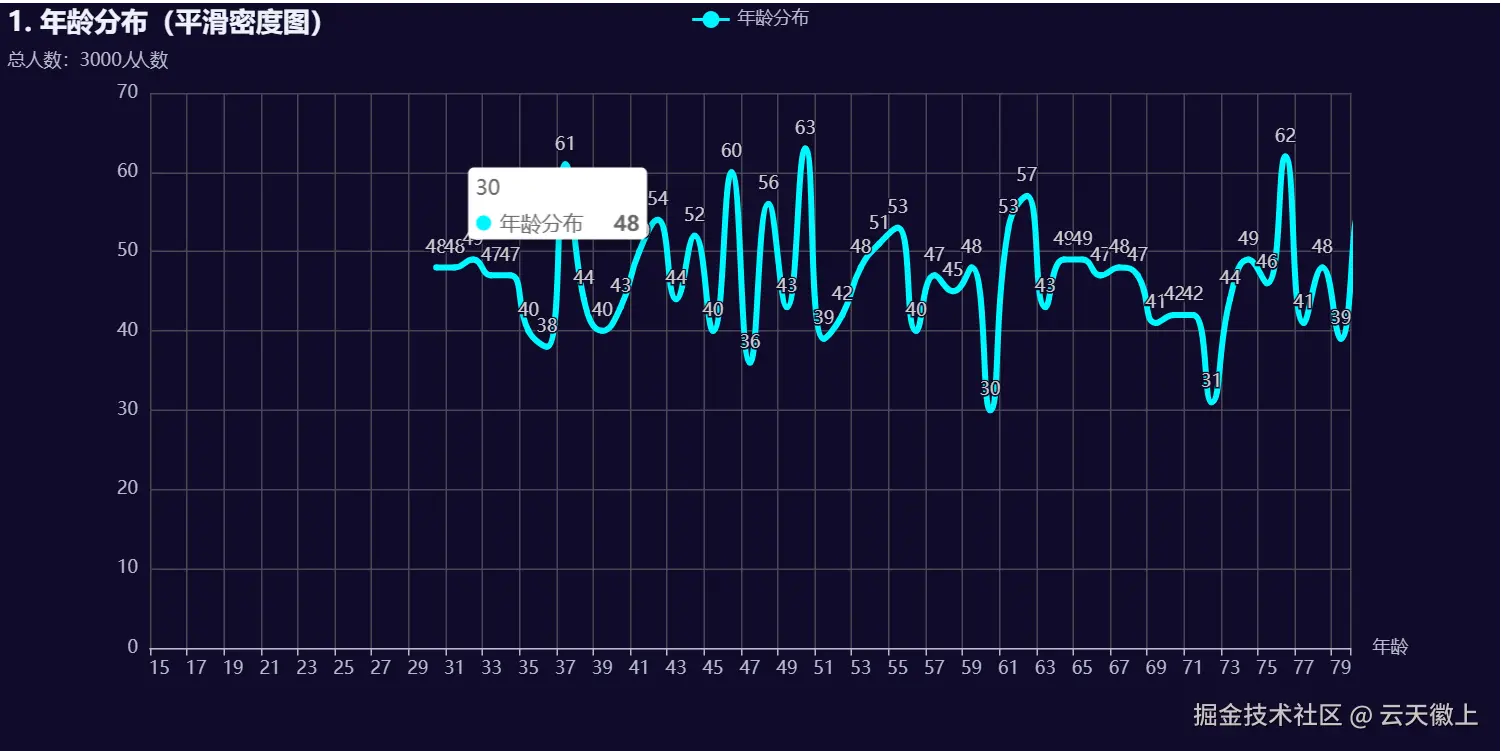 数据中统计的人员年纪在30-80岁之前,吸烟和饮酒成瘾与年纪分布看不出什么规律;
数据中统计的人员年纪在30-80岁之前,吸烟和饮酒成瘾与年纪分布看不出什么规律;
5.2 性别分布玫瑰图
ini
# 2. 性别分布玫瑰图
def gender_distribution():
gender_counts = df['gender'].value_counts()
return (
Pie(init_opts=opts.InitOpts(width="500px", height="400px", theme=theme))
.add(
"",
[list(z) for z in zip(gender_counts.index, gender_counts.values)],
radius=["20%", "75%"],
rosetype="radius",
label_opts=opts.LabelOpts(is_show=True, formatter="{b}: {c} ({d}%)")
)
.set_global_opts(
title_opts=opts.TitleOpts(title="2. 性别分布(玫瑰图)")
)
)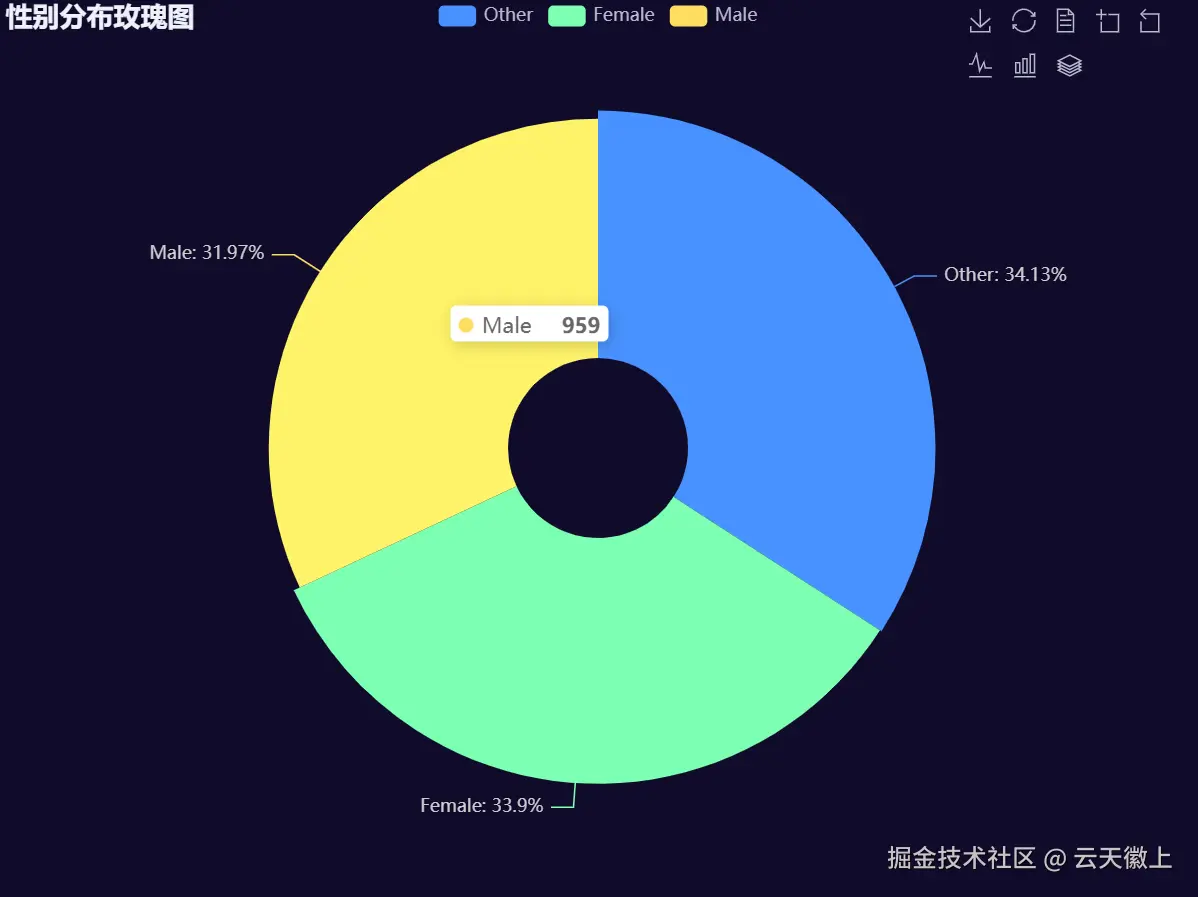 数据中成瘾的人员,男女比例相当,女性还略高于男性,可以看出吸烟和饮酒成瘾的并不是男的居多;
数据中成瘾的人员,男女比例相当,女性还略高于男性,可以看出吸烟和饮酒成瘾的并不是男的居多;
5.3 国家分布
ini
# 3. 国家分布
def country_map_distribution():
country_counts = df['country'].value_counts().reset_index()
country_counts.columns = ['country', 'count']
world_map = (
Map(init_opts=opts.InitOpts(theme=dark_theme, width="100%", height="700px"))
.add(
series_name="成瘾者数量",
data_pair=[list(z) for z in zip(country_counts['country'].tolist(), country_counts['count'].tolist())],
maptype="world",
is_map_symbol_show=False,
label_opts=opts.LabelOpts(is_show=False),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="全球成瘾者分布"),
visualmap_opts=opts.VisualMapOpts(
max_=max(country_counts['count']),
min_=1,
is_calculable=True,
range_color=['#313695', '#4575b4', '#74add1', '#abd9e9', '#e0f3f8', '#ffffbf', '#fee090', '#fdae61', '#f46d43', '#d73027', '#a50026'],
textstyle_opts=opts.TextStyleOpts(color="#fff")
),
tooltip_opts=opts.TooltipOpts(
formatter=JsCode(
"""function(params) {
return params.name + ': ' + params.value + '人';
}"""
)
)
)
)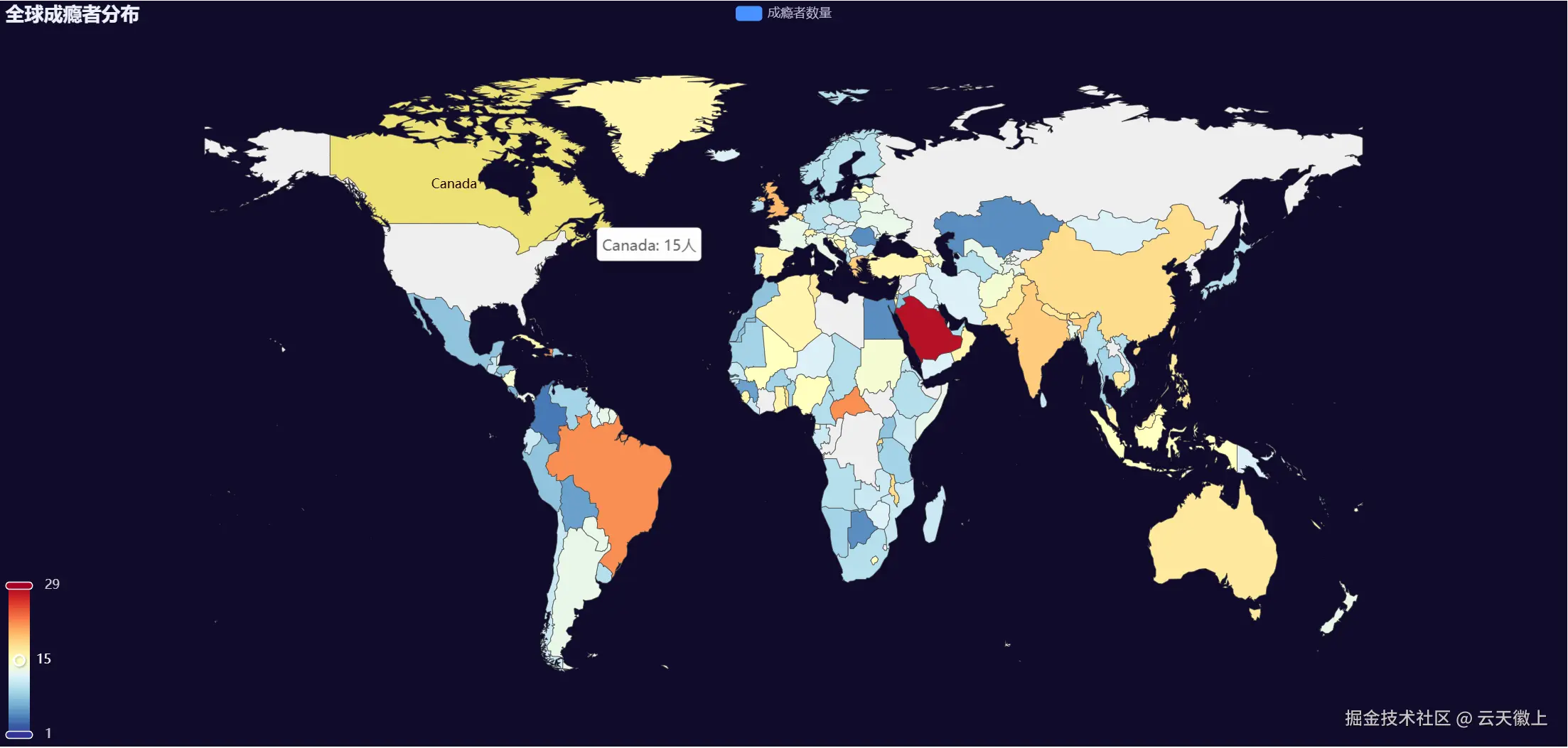 从图上可以看出,颜色越深的国家,吸烟饮酒成瘾的人数越多,其中Saudi Arabia占28人。
从图上可以看出,颜色越深的国家,吸烟饮酒成瘾的人数越多,其中Saudi Arabia占28人。
5.4 教育水平分布饼图
ini
# 4. 教育水平分布饼图
def education_distribution():
edu_counts = df['education_level'].value_counts()
return (
Pie(init_opts=opts.InitOpts(width="500px", height="400px", theme=theme))
.add(
"",
[list(z) for z in zip(edu_counts.index, edu_counts.values)],
radius=["30%", "70%"],
label_opts=opts.LabelOpts(is_show=True)
)
.set_global_opts(
title_opts=opts.TitleOpts(title="4. 教育水平分布")
)
)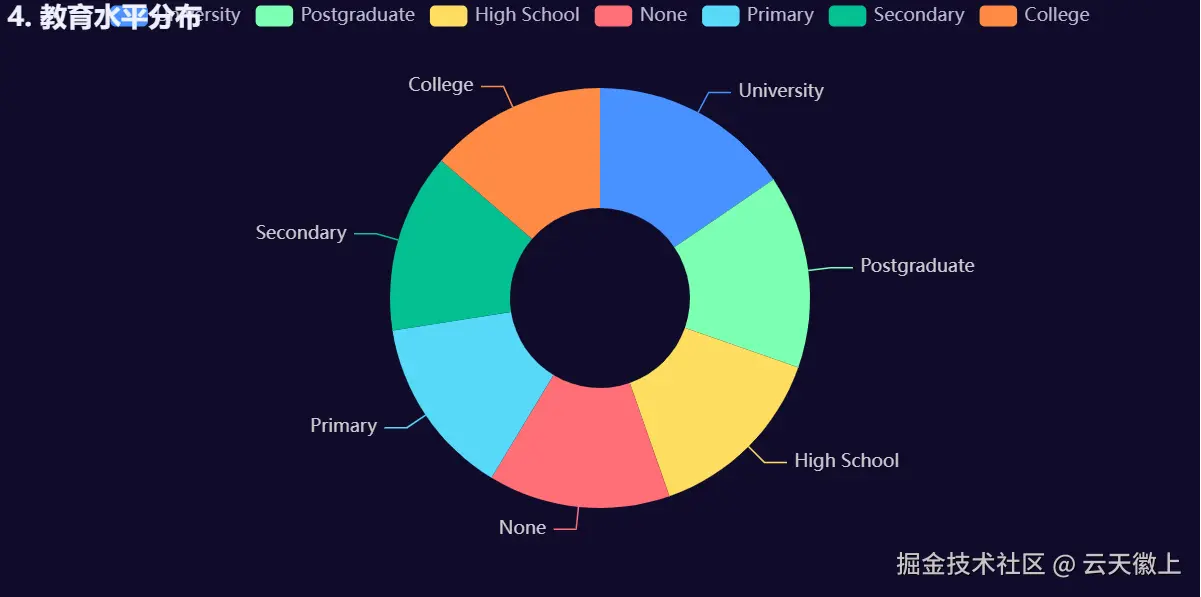 吸烟饮酒成瘾与学历几乎无关,可能不同学历的人有不同烦恼。
吸烟饮酒成瘾与学历几乎无关,可能不同学历的人有不同烦恼。
5.5 就业状况分布饼图
ini
# 5. 就业状况分布饼图
def employment_distribution():
emp_counts = df['employment_status'].value_counts()
return (
Pie(init_opts=opts.InitOpts(width="500px", height="400px", theme=theme))
.add(
"",
[list(z) for z in zip(emp_counts.index, emp_counts.values)],
radius=["30%", "70%"],
label_opts=opts.LabelOpts(is_show=True)
)
.set_global_opts(
title_opts=opts.TitleOpts(title="5. 就业状况分布")
)
)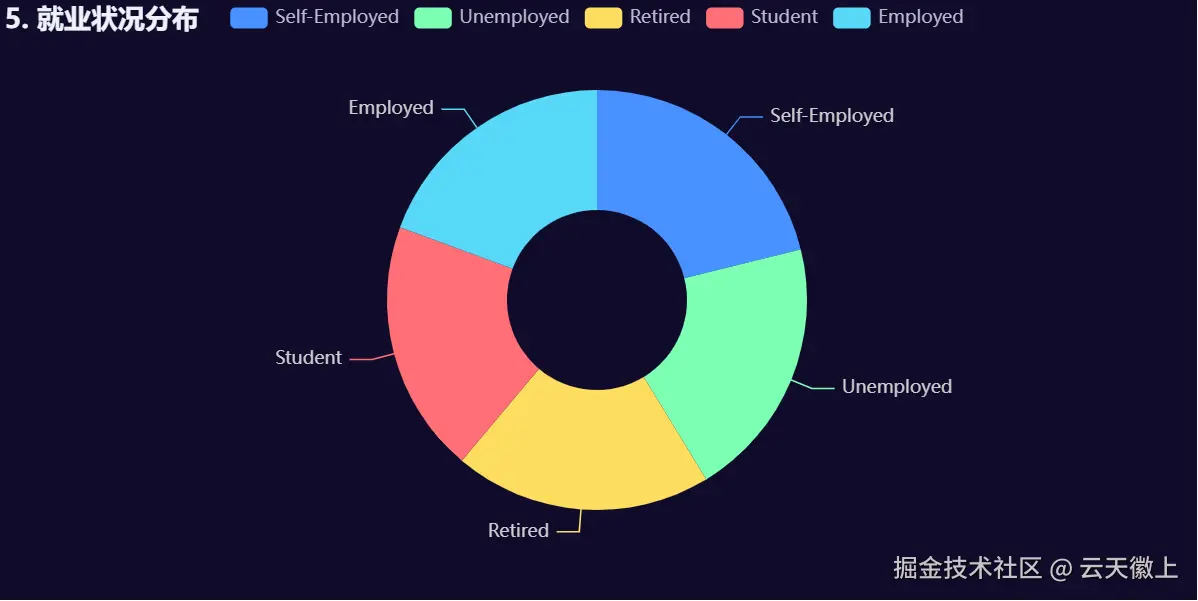 从图中可以看出就业状况与是否吸烟饮酒成瘾的关系也并不大。
从图中可以看出就业状况与是否吸烟饮酒成瘾的关系也并不大。
5.6 收入 vs 吸烟/饮酒散点图(按性别着色)
less
# 6. 收入 vs 吸烟/饮酒散点图(按性别着色)
def income_vs_addiction():
scatter = (
Scatter(init_opts=opts.InitOpts(width="900px", height="500px", theme=theme))
.add_xaxis(df['smokes_per_day'].tolist())
.add_yaxis(
"Male",
df[df['gender'] == 'Male'][['smokes_per_day', 'annual_income_usd']].values.tolist(),
symbol_size=8,
color="#00ffcc"
)
.add_yaxis(
"Female",
df[df['gender'] == 'Female'][['smokes_per_day', 'annual_income_usd']].values.tolist(),
symbol_size=8,
color="#ff00ff"
)
.set_global_opts(
title_opts=opts.TitleOpts(title="6. 吸烟量 vs 年收入(按性别着色)"),
xaxis_opts=opts.AxisOpts(name="每日吸烟支数"),
yaxis_opts=opts.AxisOpts(name="年收入(美元)")
)
)
return scatter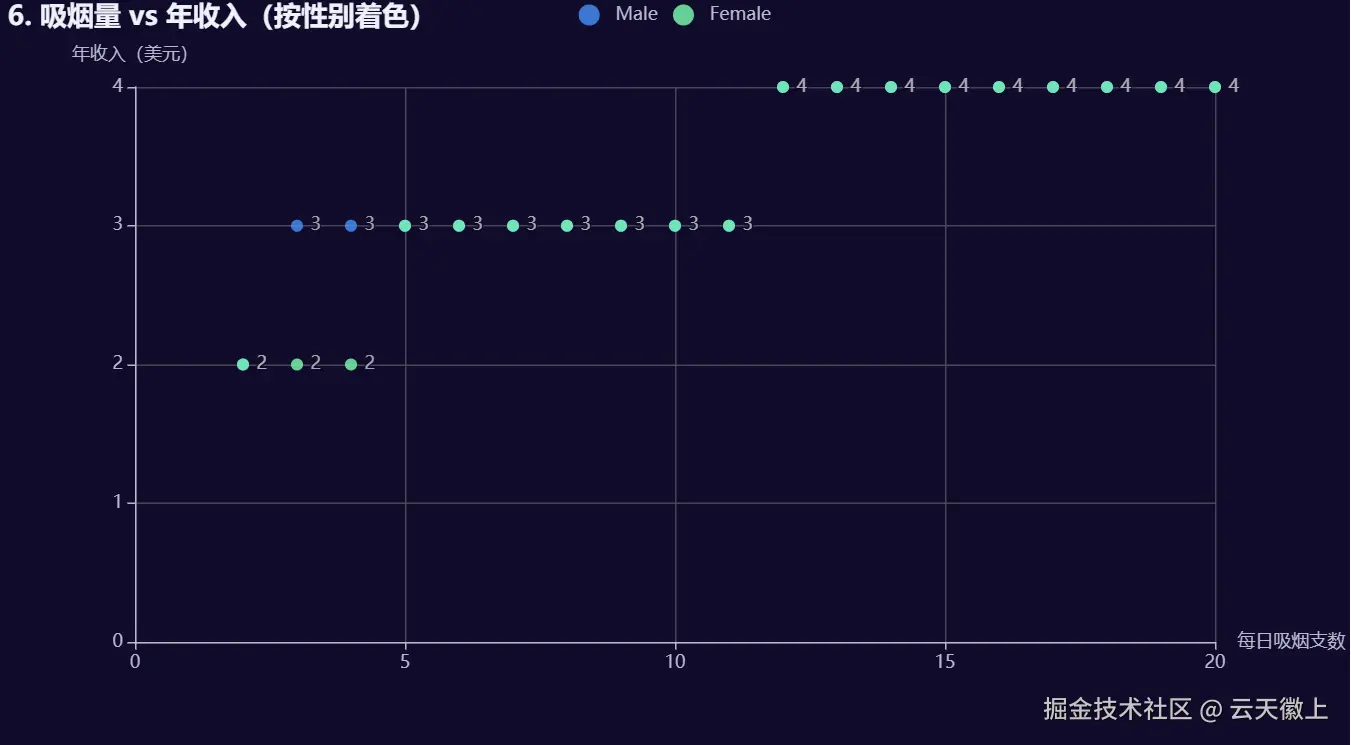
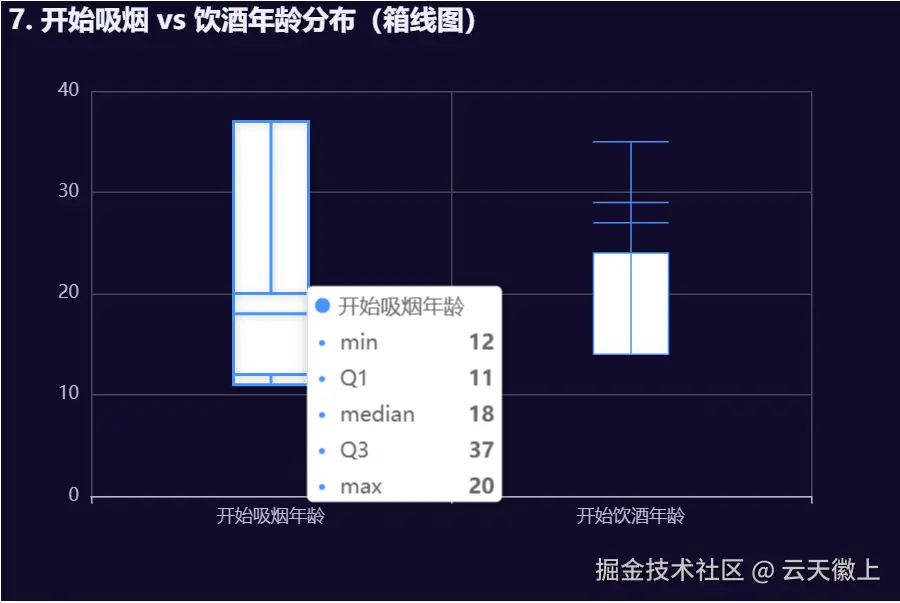
5.7 开始吸烟和饮酒年龄的箱线图
less
# 7. 开始吸烟和饮酒年龄的箱线图
def age_started_boxplot():
return (
Boxplot(init_opts=opts.InitOpts(width="600px", height="400px", theme=theme))
.add_xaxis(["开始吸烟年龄", "开始饮酒年龄"])
.add_yaxis("", [df['age_started_smoking'].dropna().tolist(), df['age_started_drinking'].dropna().tolist()])
.set_global_opts(
title_opts=opts.TitleOpts(title="7. 开始吸烟 vs 饮酒年龄分布(箱线图)")
)
)
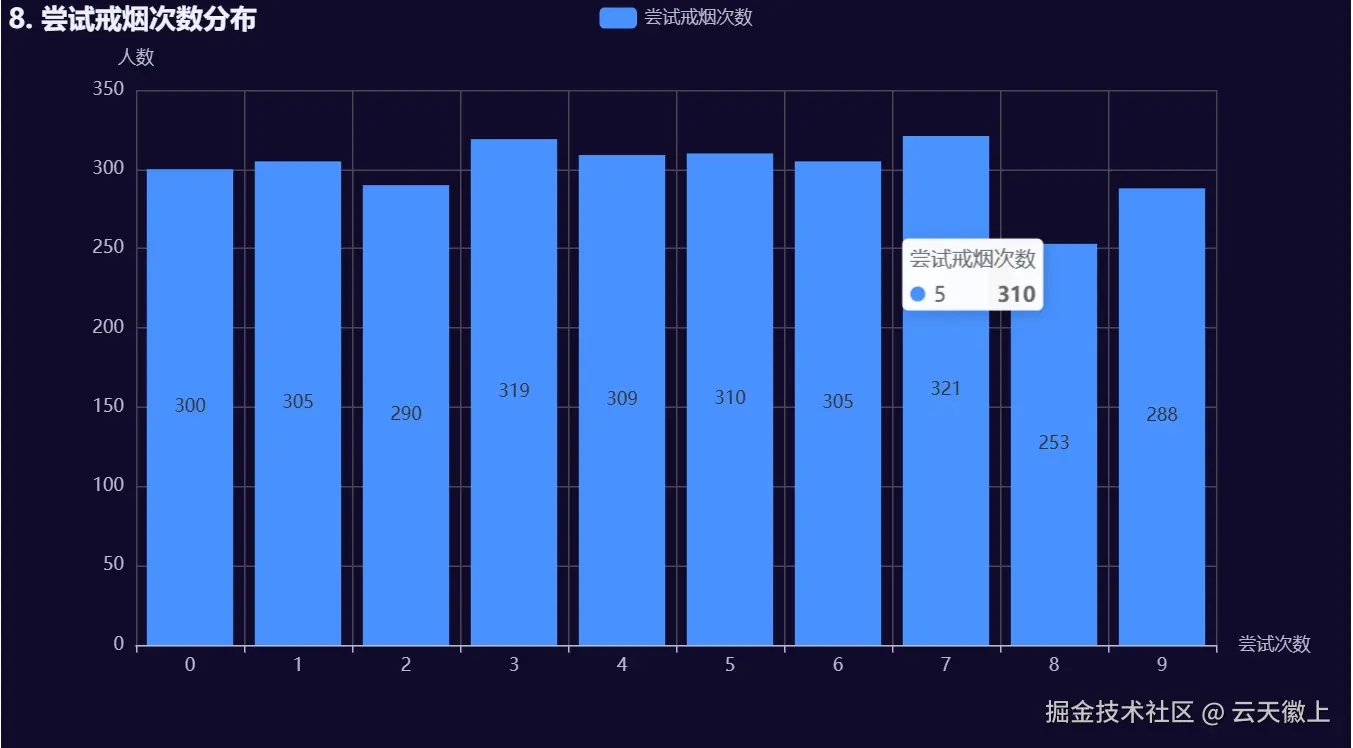
5.8 尝试戒烟/戒酒次数直方图
less
# 8. 尝试戒烟/戒酒次数直方图
def quit_attempts_histogram():
return (
Bar(init_opts=opts.InitOpts(width="900px", height="500px", theme=theme))
.add_xaxis(df['attempts_to_quit_smoking'].value_counts().sort_index().index.tolist())
.add_yaxis("尝试戒烟次数", df['attempts_to_quit_smoking'].value_counts().sort_index().values.tolist(), color="#ffcc00")
.set_global_opts(
title_opts=opts.TitleOpts(title="8. 尝试戒烟次数分布"),
xaxis_opts=opts.AxisOpts(name="尝试次数"),
yaxis_opts=opts.AxisOpts(name="人数")
)
)
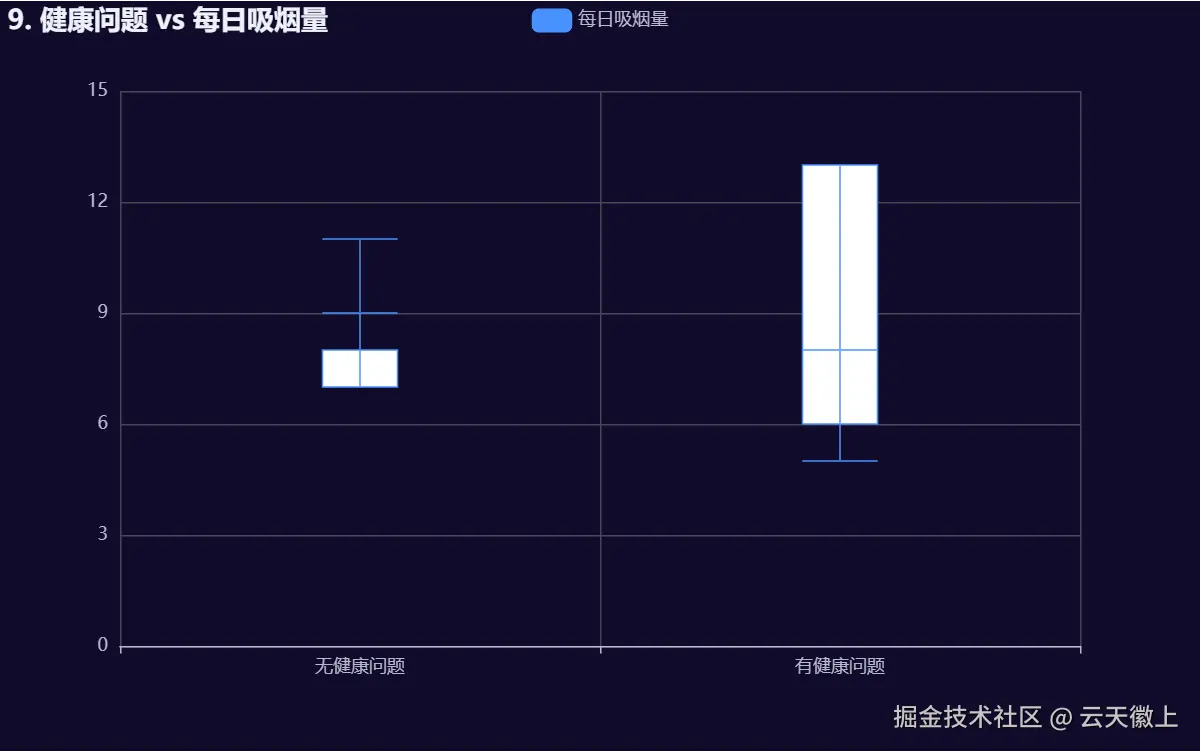
5.9 健康问题 vs 吸烟/饮酒量(分组箱线图)
less
# 9. 健康问题 vs 吸烟/饮酒量(分组箱线图)
def health_vs_addiction():
df['has_health_issues'] = df['has_health_issues'].astype(str)
return (
Boxplot(init_opts=opts.InitOpts(width="800px", height="500px", theme=theme))
.add_xaxis(["无健康问题", "有健康问题"])
.add_yaxis("每日吸烟量", [
df[df['has_health_issues'] == 'False']['smokes_per_day'].dropna().tolist(),
df[df['has_health_issues'] == 'True']['smokes_per_day'].dropna().tolist()
])
.set_global_opts(
title_opts=opts.TitleOpts(title="9. 健康问题 vs 每日吸烟量")
)
)
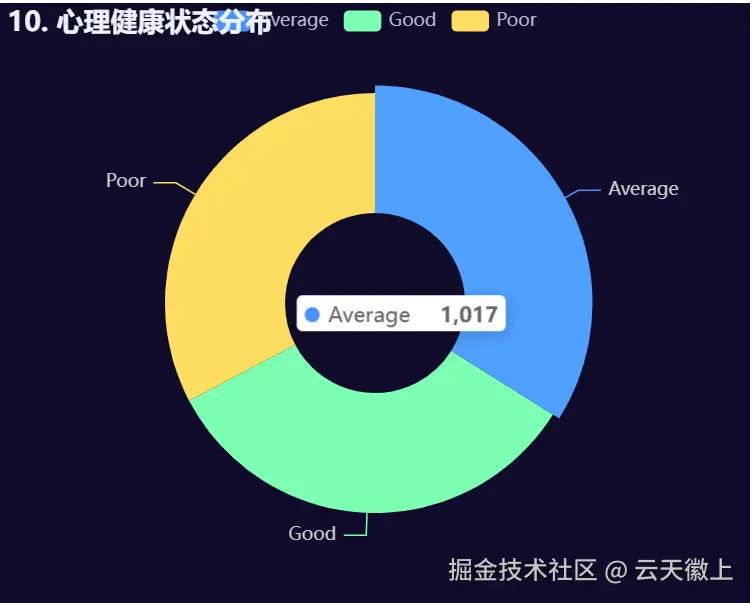
5.10 心理健康状态分布饼图
ini
# 10. 心理健康状态分布饼图
def mental_health_pie():
mh_counts = df['mental_health_status'].value_counts()
return (
Pie(init_opts=opts.InitOpts(width="500px", height="400px", theme=theme))
.add(
"",
[list(z) for z in zip(mh_counts.index, mh_counts.values)],
radius=["30%", "70%"],
label_opts=opts.LabelOpts(is_show=True)
)
.set_global_opts(
title_opts=opts.TitleOpts(title="10. 心理健康状态分布")
)
)
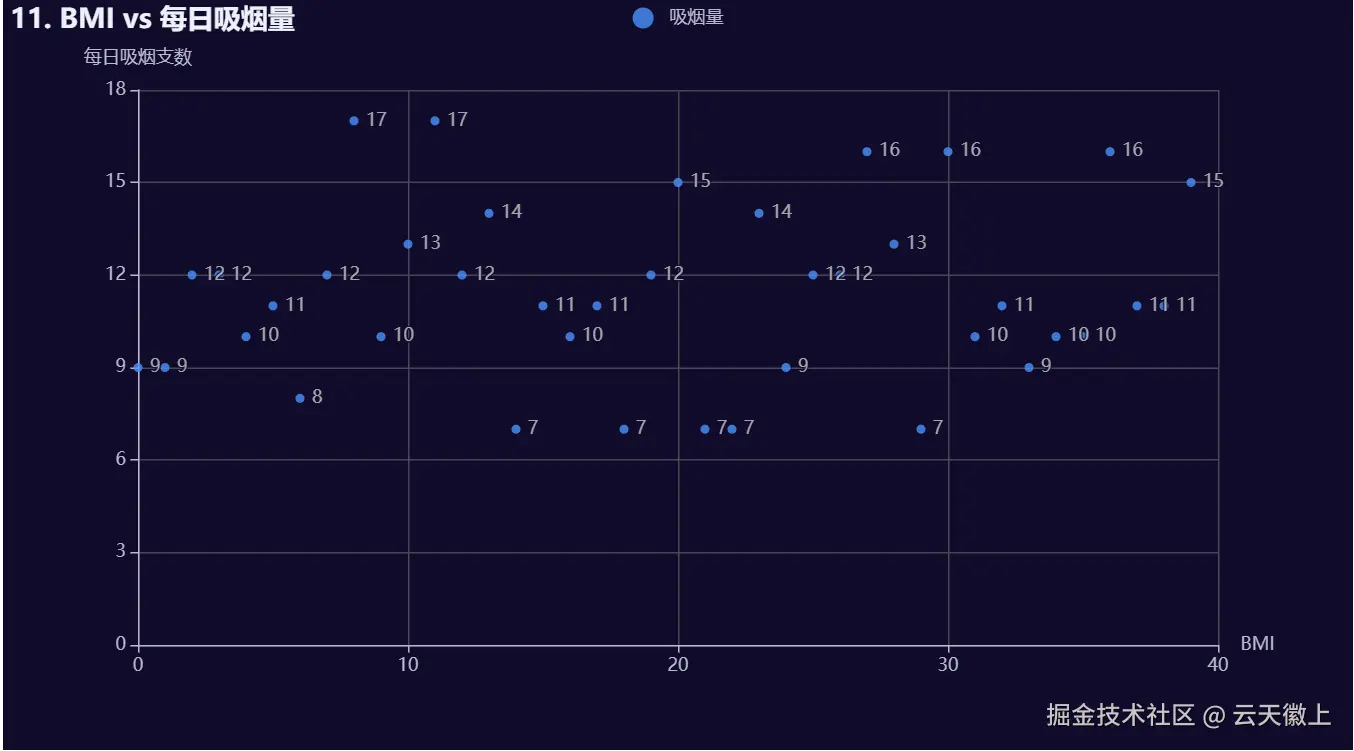
5.11 BMI 与吸烟量散点图
less
# 11. BMI 与吸烟量散点图
def bmi_vs_smoking():
return (
Scatter(init_opts=opts.InitOpts(width="900px", height="500px", theme=theme))
.add_xaxis(df['bmi'].tolist())
.add_yaxis("吸烟量", df['smokes_per_day'].tolist(), symbol_size=6, color="#ff6b6b")
.set_global_opts(
title_opts=opts.TitleOpts(title="11. BMI vs 每日吸烟量"),
xaxis_opts=opts.AxisOpts(name="BMI"),
yaxis_opts=opts.AxisOpts(name="每日吸烟支数")
)
)
5.12 吸烟与饮酒的双玫瑰图
ini
def dual_rose():
smoke_bins = pd.cut(df['smokes_per_day'], bins=[-1,5,10,20,999],
labels=['轻','中','重','极重'])
drink_bins = pd.cut(df['drinks_per_week'], bins=[-1,2,7,14,999],
labels=['轻','中','重','极重'])
cross = pd.crosstab(smoke_bins, drink_bins)
c = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.DARK,
width='1000px', height='600px'))
.add("吸烟等级", [list(z) for z in cross.sum(axis=1).items()],
radius=['25%', '45%'], center=['25%', '50%'], rosetype='radius')
.add("饮酒等级", [list(z) for z in cross.sum(axis=0).items()],
radius=['25%', '45%'], center=['75%', '50%'], rosetype='radius')
.set_series_opts(label_opts=opts.LabelOpts(color='#fff',
formatter="{b}: {d}%"))
.set_global_opts(title_opts=opts.TitleOpts(title="烟枪 vs 酒鬼",
subtitle="玫瑰双环"),
legend_opts=opts.LegendOpts(textstyle_opts=opts.TextStyleOpts(color='#fff')))
)
return c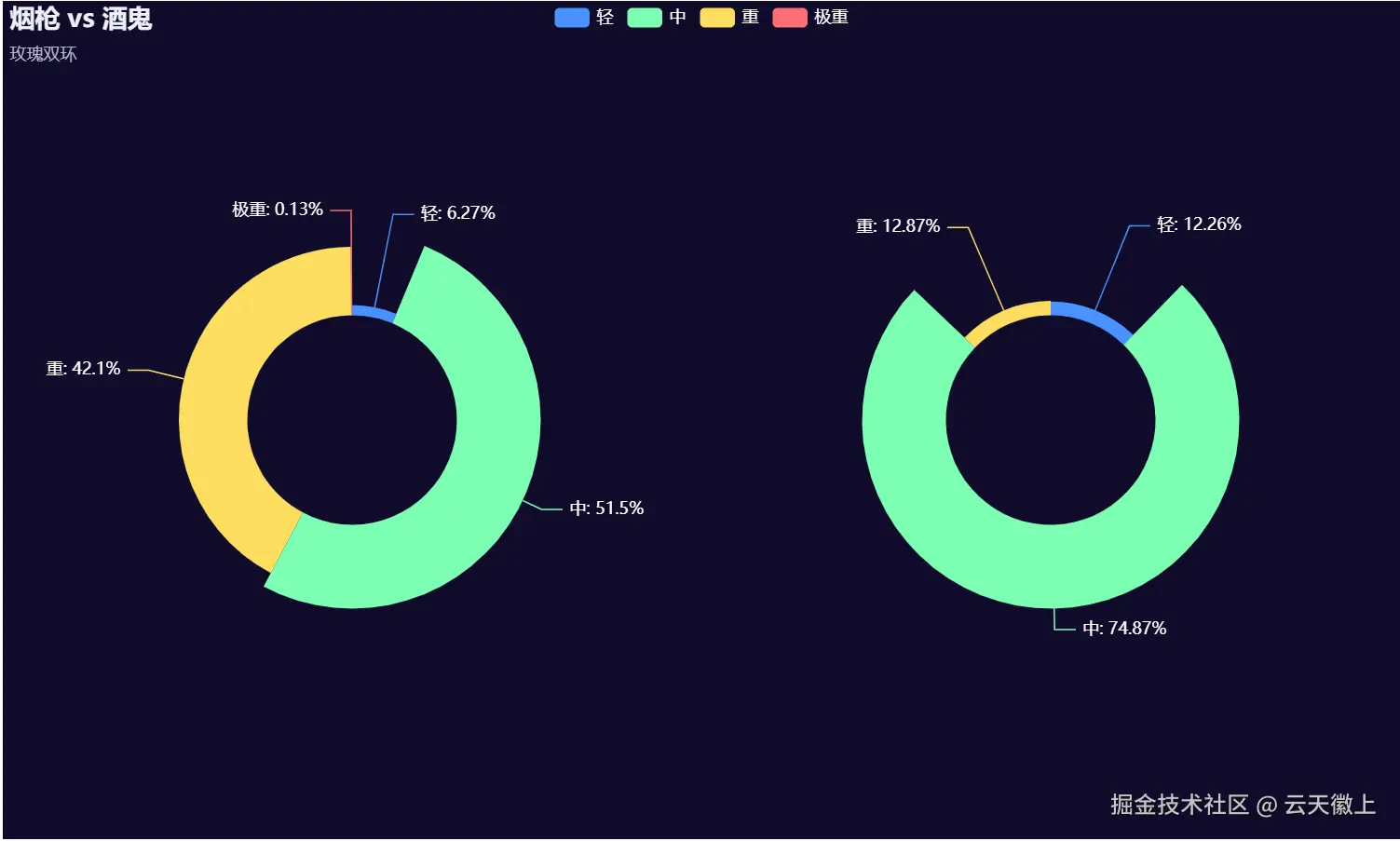
5.13 多维度雷达图
ini
def create_radar_chart(age_group):
group_data = df[df['age_group'] == age_group].mean()
data = [
group_data['smokes_per_day'],
group_data['drinks_per_week'],
group_data['bmi'],
group_data['sleep_hours'],
group_data['attempts_to_quit_smoking'],
group_data['children_count']
]
return data
## 3、 雷达图
def rader_distribution():
df['has_health_issues'] = df['has_health_issues'].map({True: 1, False: 0})
# 年龄分段
bins = [0, 18, 30, 45, 60, 100]
labels = ['<18', '18-30', '30-45', '45-60', '>60']
df['age_group'] = pd.cut(df['age'], bins=bins, labels=labels)
# 收入分段
income_bins = [0, 30000, 60000, 100000, 150000, 200000, 1000000]
income_labels = ['<30K', '30-60K', '60-100K', '100-150K', '150-200K', '>200K']
df['income_group'] = pd.cut(df['annual_income_usd'], bins=income_bins, labels=income_labels)
# 多维度雷达图 - 不同年龄组特征对比
age_groups = labels
radar_data = [create_radar_chart(group) for group in age_groups]
radar = (
Radar(init_opts=opts.InitOpts(theme=dark_theme, width="100%", height="700px"))
.add_schema(
schema=[
opts.RadarIndicatorItem(name="每日吸烟量", max_=13),
opts.RadarIndicatorItem(name="每周饮酒量", max_=6),
opts.RadarIndicatorItem(name="BMI指数", max_=30),
opts.RadarIndicatorItem(name="睡眠时间", max_=8),
opts.RadarIndicatorItem(name="戒烟尝试次数", max_=5),
opts.RadarIndicatorItem(name="子女数量", max_=3),
],
splitarea_opt=opts.SplitAreaOpts(
is_show=True, areastyle_opts=opts.AreaStyleOpts(opacity=0.1)
),
textstyle_opts=opts.TextStyleOpts(color="#fff"),
)
)
colors = ['#00FFFF', '#7FFF00', '#FFD700', '#FF4500', '#FF1493']
for i, group in enumerate(age_groups):
radar.add(
series_name=group,
data=[radar_data[i]],
linestyle_opts=opts.LineStyleOpts(width=2, color=colors[i]),
areastyle_opts=opts.AreaStyleOpts(opacity=0.4, color=colors[i]),
symbol="circle",
label_opts=opts.LabelOpts(is_show=False),
)
radar.set_global_opts(
title_opts=opts.TitleOpts(title="不同年龄组成瘾特征雷达图"),
legend_opts=opts.LegendOpts(
orient="vertical", pos_right="5%", pos_top="15%", textstyle_opts=opts.TextStyleOpts(color="#fff")
),
tooltip_opts=opts.TooltipOpts(trigger="item"),
)
return radar
六、数据可视化看板
scss
# 渲染所有图表
from pyecharts.charts import Page
page = Page()
page.add(
age_distribution(),
gender_distribution(),
top_countries(),
education_distribution(),
employment_distribution(),
income_vs_addiction(),
age_started_boxplot(),
quit_attempts_histogram(),
health_vs_addiction(),
mental_health_pie(),
bmi_vs_smoking()
)
page.render("addiction_analysis_dark.html")
七、总结
通过上述分析和可视化,我们可以从多个维度深入了解成瘾者的特征和行为模式。这些图表不仅具有视觉冲击力,还能为公共卫生研究和教育提供有力的数据支持。希望这些代码和图表能够帮助你更好地理解和分析数据。
如果您在人工智能领域遇到技术难题,或是需要专业支持,无论是技术咨询、项目开发还是个性化解决方案,我都可以为您提供专业服务,如有需要可站内私信或添加下方VX名片(ID:xf982831907)
期待与您一起交流,共同探索AI的更多可能!