在实时数仓的浪潮下,企业越来越重视如何以低延迟、高一致性的方式将数据写入数据湖,并结合下游分析引擎完成统一分析。Apache Paimon 作为新一代流批一体的数据湖存储引擎,因其高效写入、实时更新等能力,成为构建实时湖仓架构的理想选型。
本文将介绍如何基于 Paimon、CloudCanal、StarRocks 快速构建一套真正实时、灵活、高可维护的数据湖仓架构。
Apache Paimon 介绍
Apache Paimon 是一个开源的、面向流计算的湖仓存储格式,源于 Apache Flink 社区(原 Flink Table Store)。它的核心创新在于将 湖存储格式 与 日志结构合并树(LSM-tree) 技术融合,为数据湖带来了强大的实时流式更新能力,这使得高吞吐、低延迟的数据摄取、变更日志追踪和高效的即时分析成为可能。
核心能力:
- 流批一体处理:支持 Streaming Write / Snapshot Read
- 主键支持:高效 UPSERT / DELETE
- Schema 演进:新增、删除、修改列,无需重写旧数据
- ACID 事务保障:支持并发读写一致性
- 生态兼容:支持 StarRocks、Flink、Spark 等引擎
- 对象存储兼容 :支持 S3 、OSS 等文件系统
举个例子:数据湖中的实时订单状态变更
以大型电商平台的实时销售大屏为例,业务团队希望能够每秒更新订单状态,例如订单从"已支付"变为"已发货",并立即体现在可视化大屏中。
-
传统方案的挑战(Merge-on-Read)
在传统的数据湖架构中,变更数据通常会先追加写入日志区,再依赖定期的 Merge-on-Read 批处理任务将新旧数据合并成最新快照。
- 实时写入采用 追加方式,变更记录不会立即反映在查询结果中,需等待合并操作完成后才可见。
- 读旧、写新、重写文件的过程通常以分钟为单位,难以满足 秒级 延迟需求。
-
Paimon 的解决方式(LSM-tree)
Paimon 从架构层面对这一痛点进行了优化,引入类似数据库的主键更新能力。
- 订单在交易库(如 MySQL)中状态变更。
- 变更事件(如 UPDATE orders SET status = '已发货' WHERE order_id = '123')实时写入 Paimon。
- Paimon 基于 LSM-tree ,更新后读取,通常可在 秒级 内完成。
-
实际效果
下游如 StarRocks 等分析引擎可以秒级查询到更新后的状态,从而确保实时大屏始终反映业务的最新动态。
Paimon vs. Iceberg:关键特性对比
Apache Paimon 与 Apache Iceberg 是当前数据湖领域的两大主流方案,分别在实时处理和批量分析方向各有侧重,体现了两种不同的技术演进路径。
Paimon 设计之初就面向流式数据处理,底层采用 LSM-tree 架构,原生支持主键和高效变更,特别适合 高频更新 、CDC 等行级数据实时入湖 场景。
Iceberg 以快照机制为核心,强调 强一致性,同时也逐步增强对流式写入与变更处理的支持,具备实现近实时入湖的能力。
| 特性 | Apache Paimon | Apache Iceberg |
|---|---|---|
| 核心更新机制 | LSM-tree | Copy-on-Write / Merge-on-Read |
| 主键与更新模型 | 支持 Primary Key ,流式 UPSERT 写入更高效 | 通过 Merge-on-Read 机制支持 UPSERT |
| 流式写入 | 支持 | 支持 |
| 数据更新延迟 | 毫秒到秒级,更适合实时性要求极高的场景 | 通常为分钟级,更侧重于批处理和微批处理 |
| 生态成熟度 | 较新,在 Flink 社区中发展迅速 | 更成熟,拥有更广泛的引擎和工具支持 |
| 适用场景 | 实时数仓、CDC 数据实时入湖、流批一体分析 | 通用数据湖 、大规模批处理、数据仓库 |
总体来看,Paimon 在实时更新、变更频繁的场景中具备更直接的能力优势 ,而 Iceberg 则在批量处理、版本治理和生态成熟度方面表现更稳健。
构建湖仓一体架构
尽管 Paimon 可以通过 Flink CDC 写入数据,但管理作业状态、处理容错和检查点等工作,对多数团队而言仍有不小的技术门槛和运维成本。CloudCanal 提供了一种更轻量、更自动化的方式实现数据入湖。
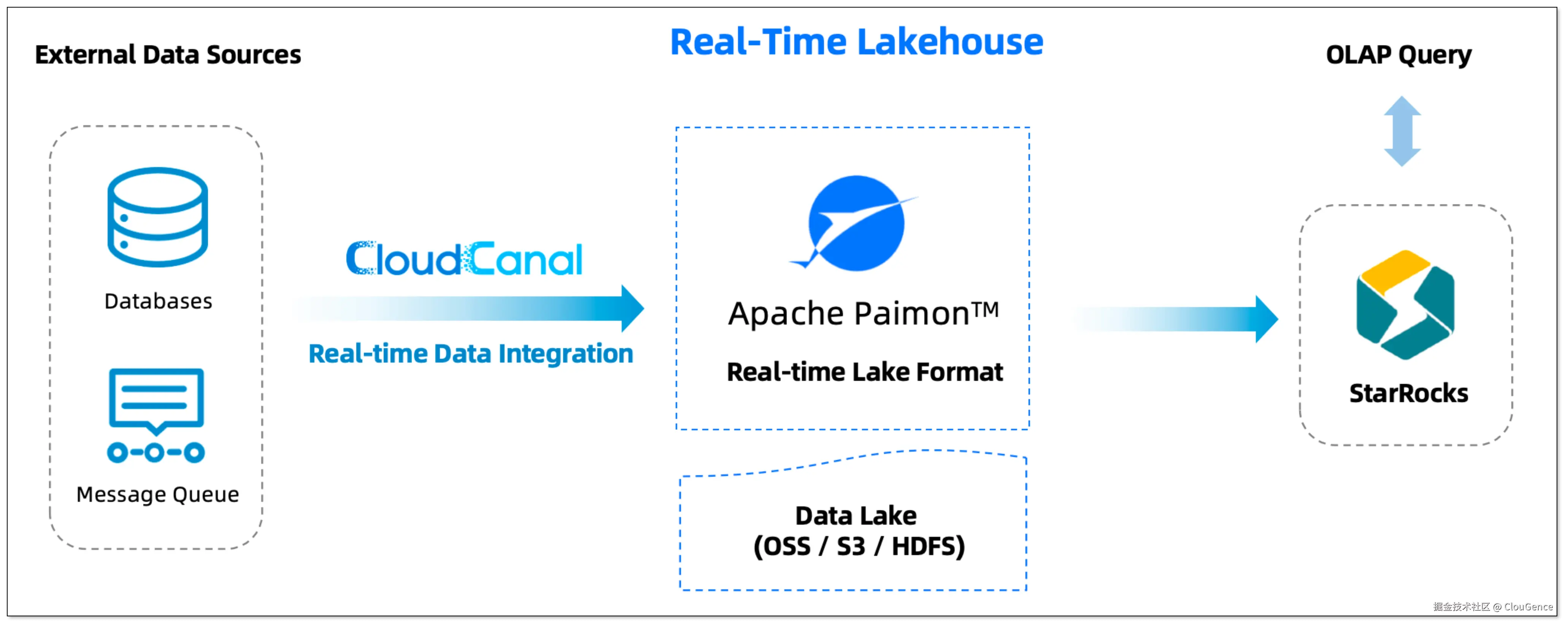
- 外部数据源:企业的核心交易库(如 MySQL, PostgreSQL)、日志数据(Kafka)等。
- CloudCanal :
- 基于日志实时捕获数据的变更,流式批量写入 ,实现秒级延迟。
- 支持 结构自动迁移 和 DDL 同步。
- 支持数据迁移同步、数据校验与订正、断点续传、任务监控、告警。
- Apache Paimon :
- 作为湖仓底座,承接 CloudCanal 写入的实时数据流。
- 采用 LSM-tree 架构自动去重合并,管理数据分区与后台 Compaction。
- 基于 S3、OSS 等其他对象存储,构建存算分离架构。
- StarRocks:直接进行实时查询分析,无需额外的数据导入或转换。
实操演示
接下来将以 MySQL -> Paimon 链路为例,展示如何快速将数据实时同步至 Paimon,并使用 StarRocks 外表实时查询入湖数据。
步骤 1: 安装 CloudCanal
请参考 全新安装(Docker Linux/MacOS),下载安装 CloudCanal 私有部署版本。
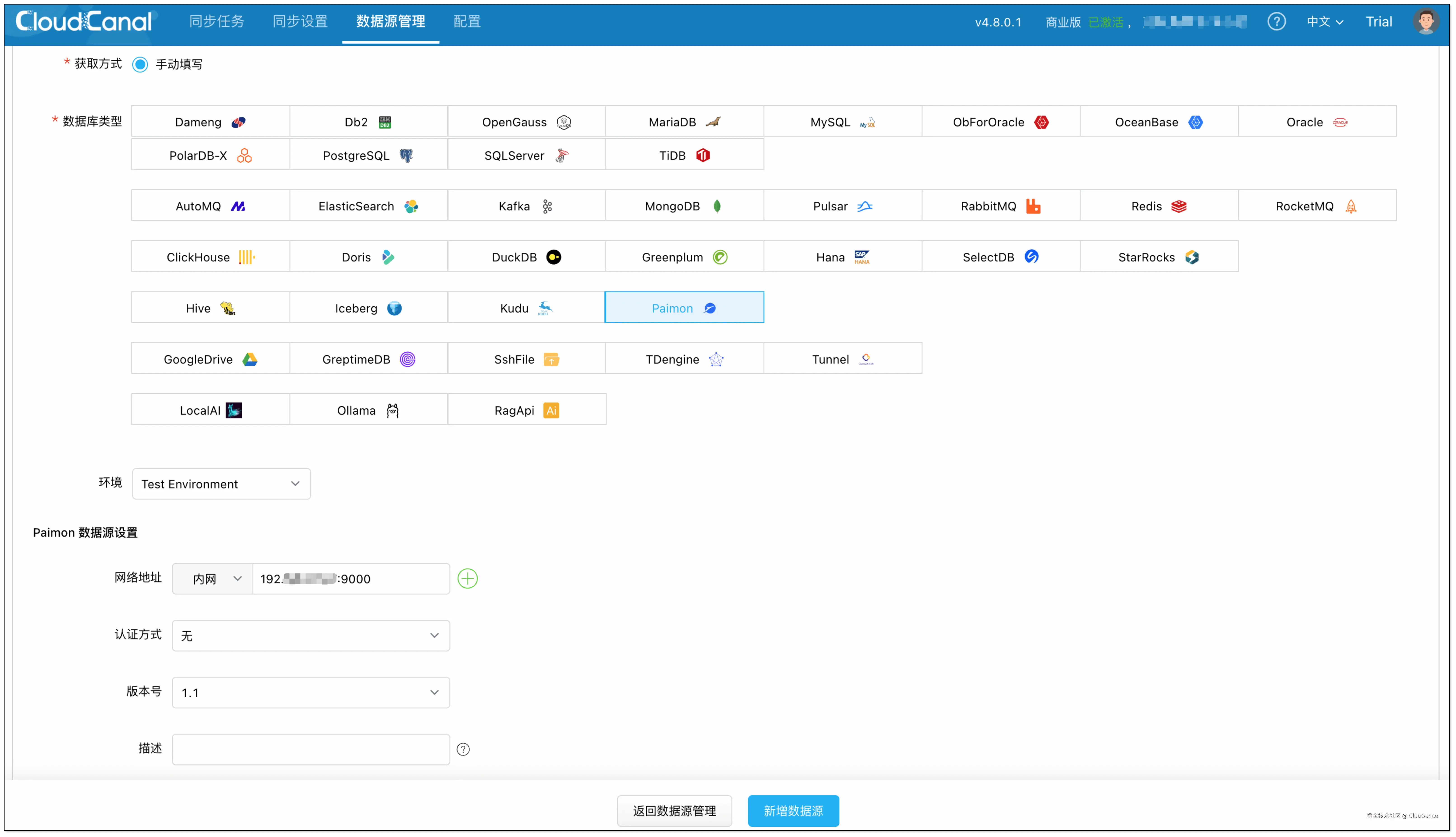
步骤 2: 添加数据源
-
登录 CloudCanal 平台 ,点击 数据源管理 > 添加数据源 ,分别添加 MySQL 和 Paimon 数据源。
-
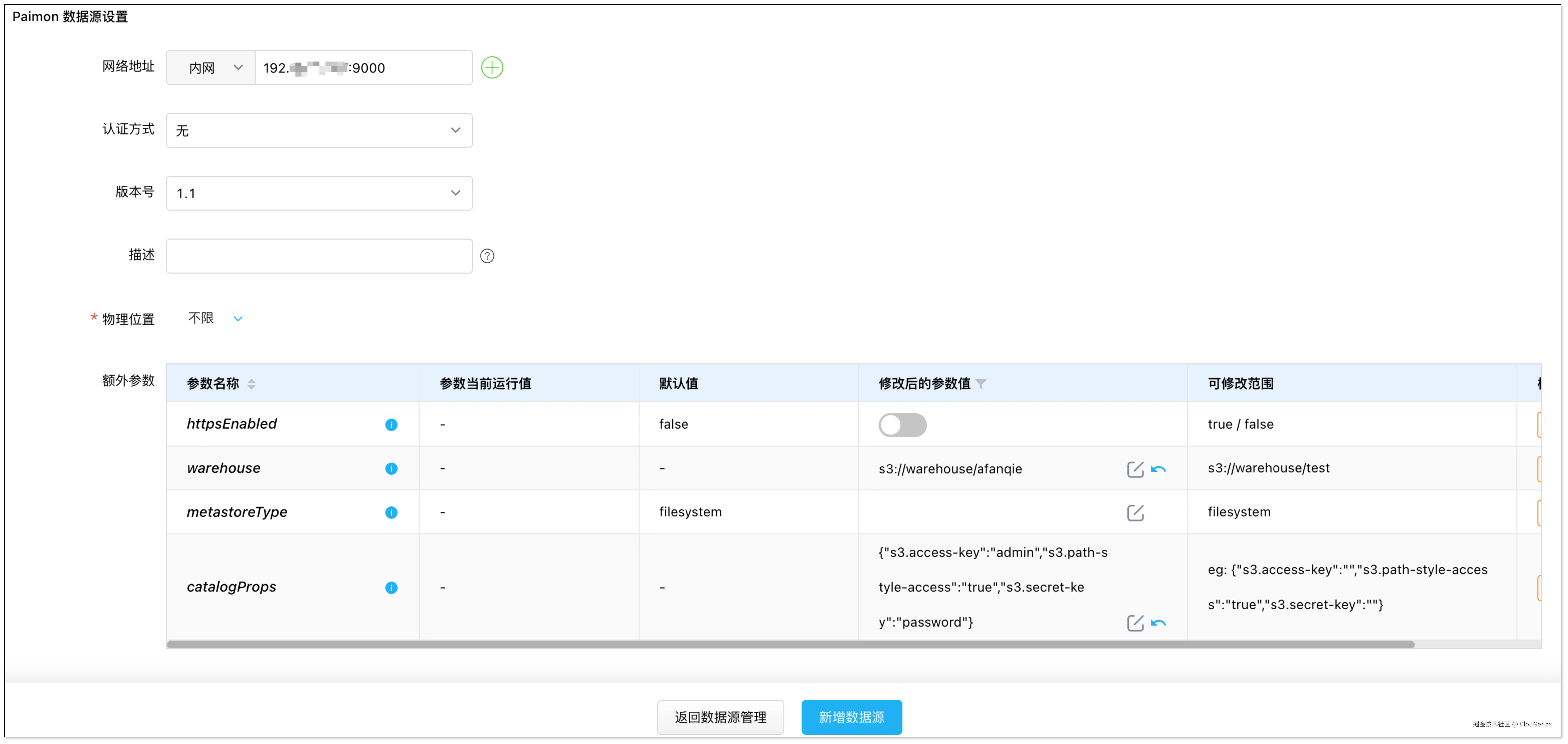
添加 Paimon 数据源时,需配置额外参数,具体可参考:Paimon 数据源配置
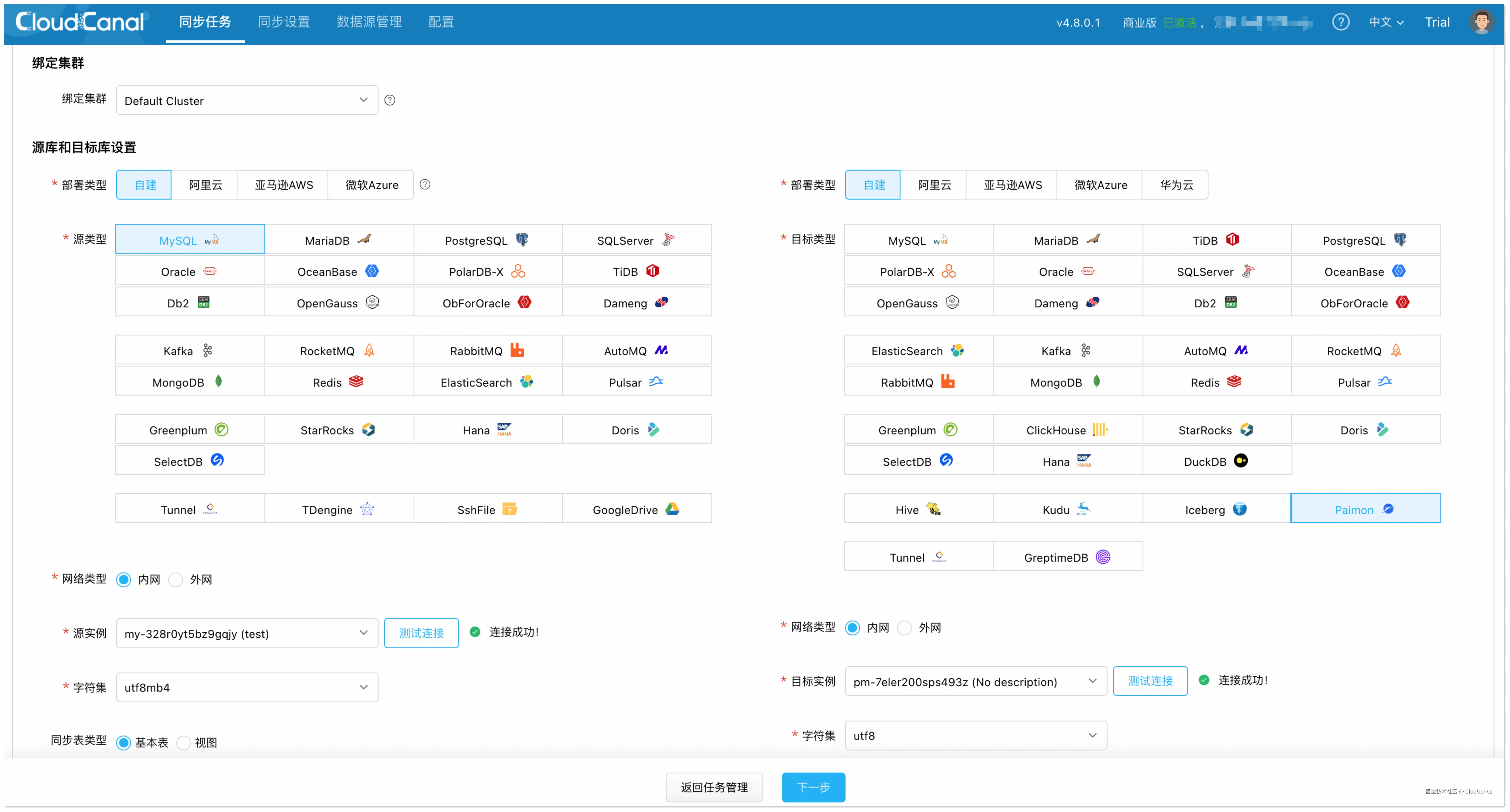
步骤 3: 创建任务
-
点击 同步任务 > 创建任务。
-
选择源和目标实例,并分别点击 测试连接 。
-
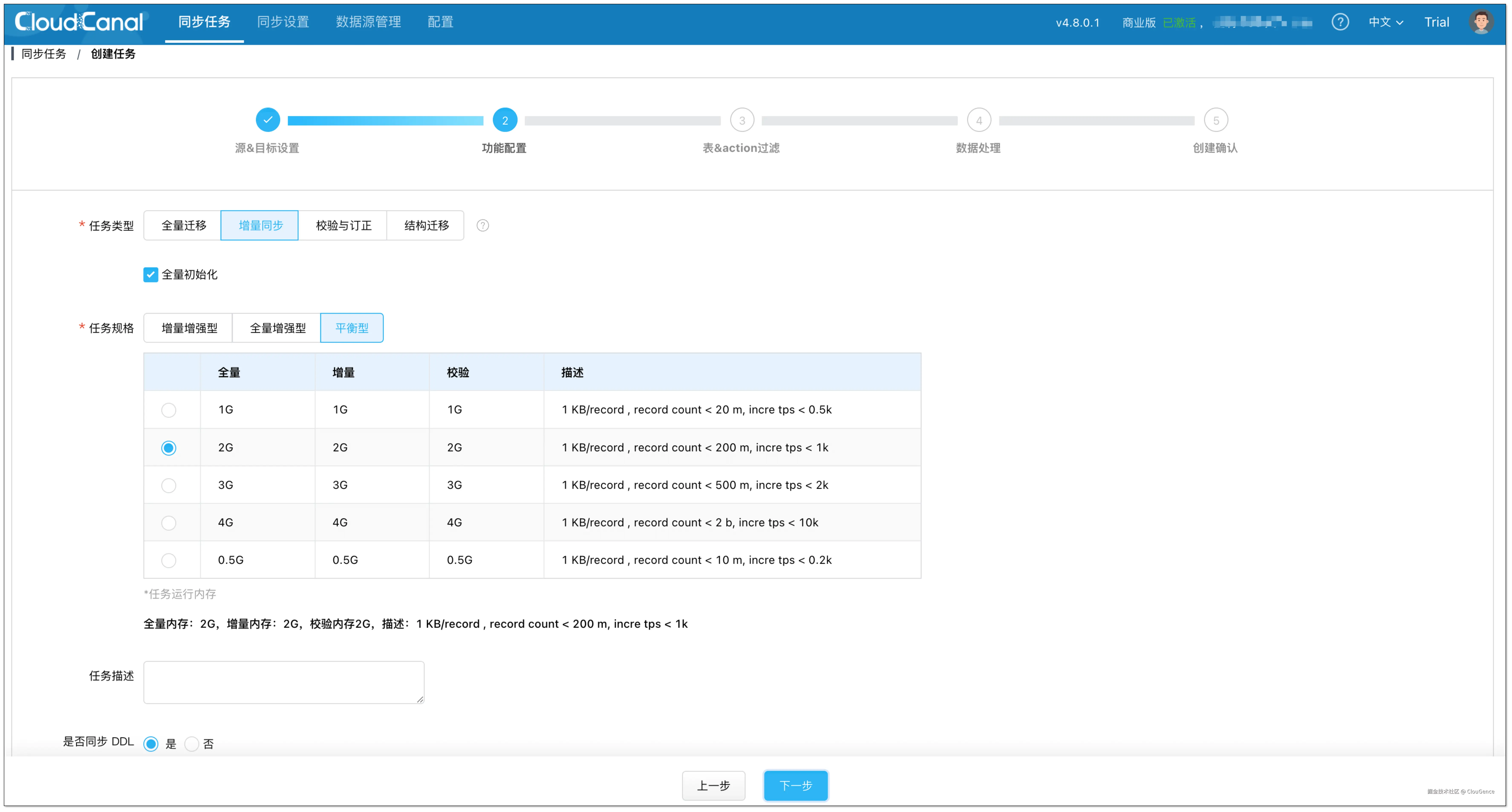
在 功能配置 页面,选择 增量同步 ,并勾选 全量初始化 。
-
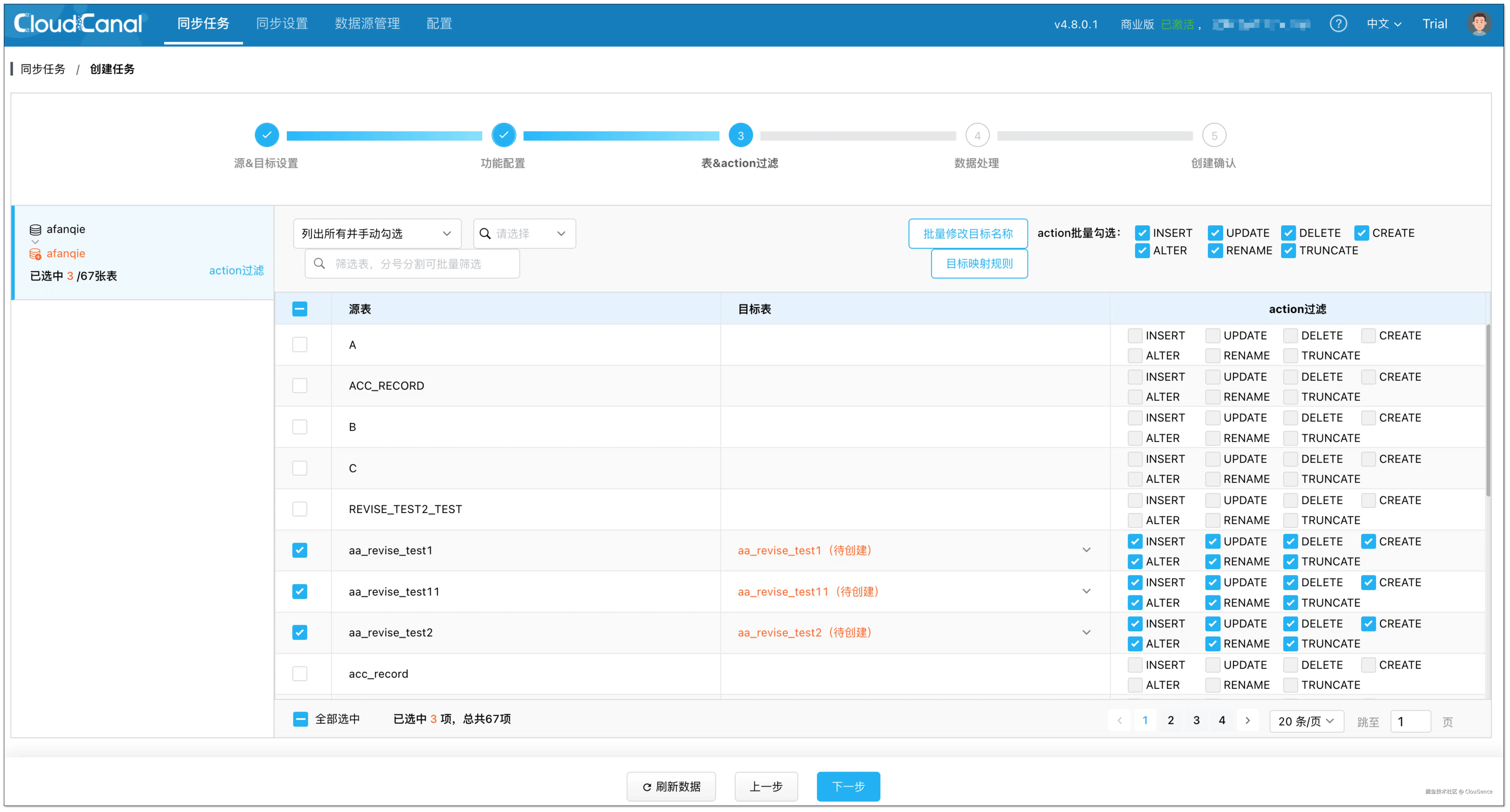
在 表和操作过滤 页面,选择需要迁移同步的表,可同时选择多张。
-
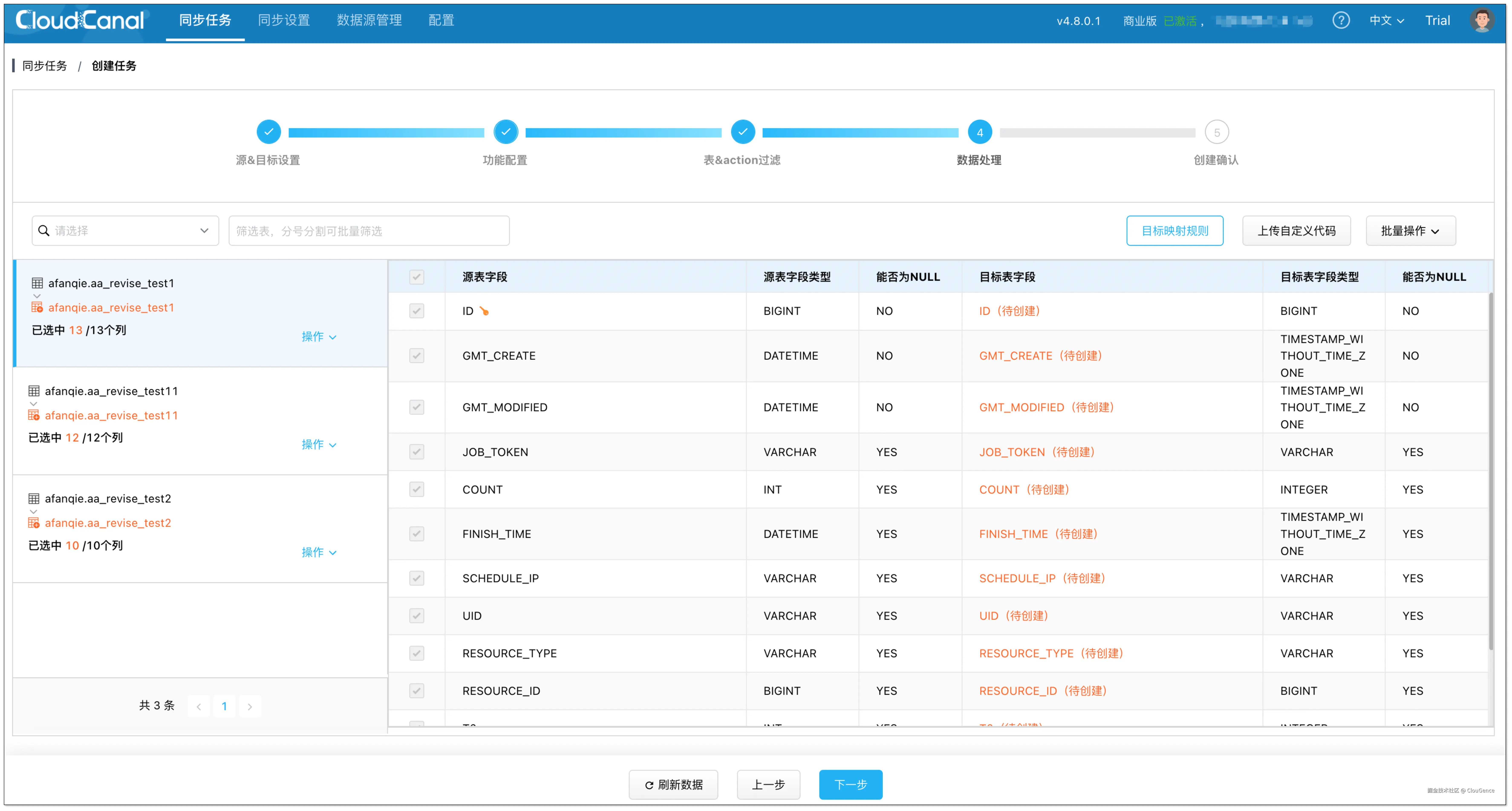
在 数据处理 页面,保持默认配置。
-
在 创建确认 页面,点击 创建任务 ,开始运行。

任务启动后,CloudCanal 会自动完成全量数据的初始化,并实时捕获增量变更写入 Paimon。
步骤 4: 使用 StarRocks 查询数据
Paimon 中的数据最终需要被下游分析引擎查询,StarRocks 原生支持 Paimon Catalog,可通过外部 Catalog 的方式直接查询 Paimon 中的实时数据,无需额外导入或数据转换。
- 在 StarRocks 中创建 Paimon Catalog
在 StarRocks 中执行 CREATE EXTERNAL CATALOG 语句,即可将整个 Paimon 仓库映射进 StarRocks:
shell
CREATE EXTERNAL CATALOG paimon_catalog
PROPERTIES
(
"type" = "paimon",
"paimon.catalog.type" = "filesystem",
"paimon.catalog.warehouse" = "<s3_paimon_warehouse_path>",
"aws.s3.use_instance_profile" = "true",
"aws.s3.endpoint" = "<s3_endpoint>"
);具体配置可参考:docs.starrocks.io/docs/data_s...
- 实时查询数据
Catalog 创建成功后,可以像 操作本地表 一样查询 Paimon 中的数据:
shell
-- 查看 Catalog 中有哪些数据库
SHOW DATABASES FROM paimon_catalog;
-- 切换 Catalog
SET CATALOG paimon_catalog;
-- 切换至指定数据库
USE your_database;
-- 查询表数据
SELECT COUNT(*) FROM your_table LIMIT 10;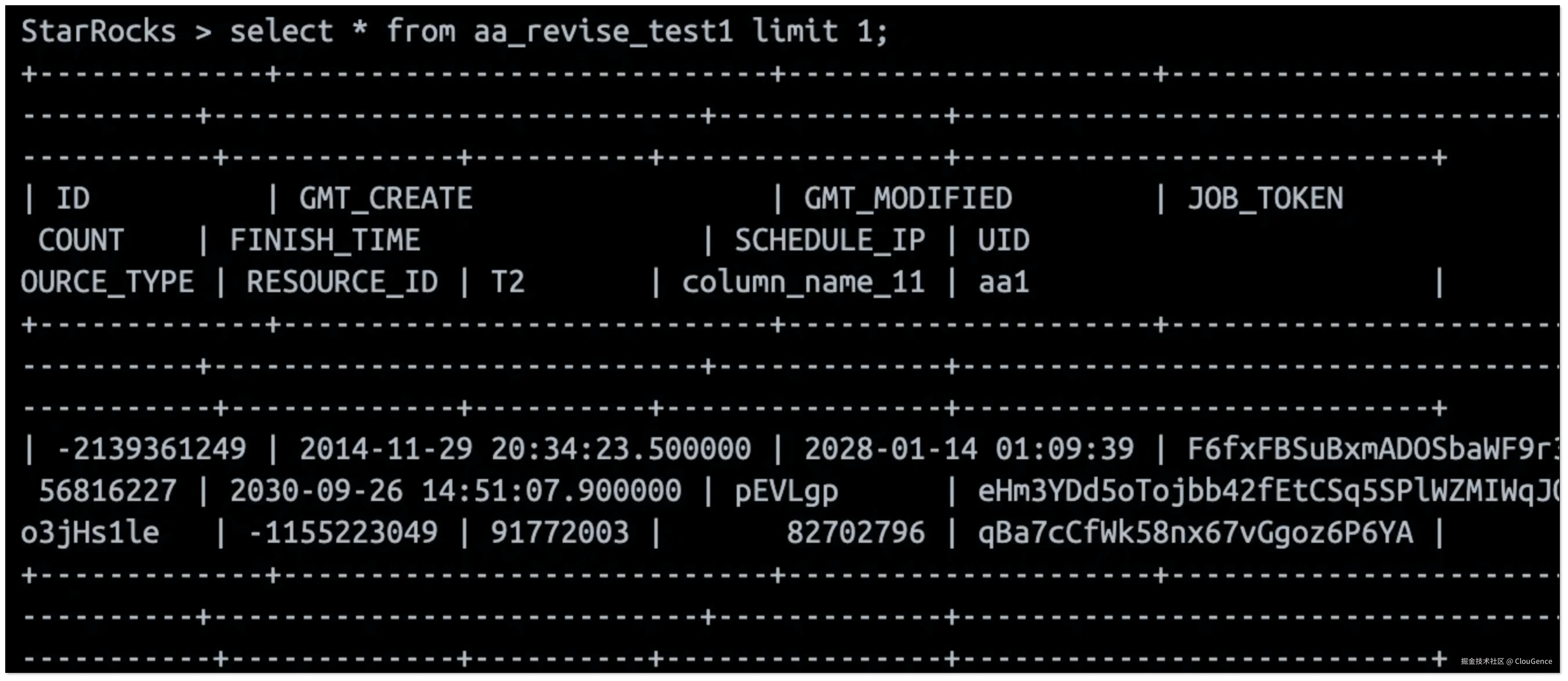
当 MySQL 中的数据发生变化后,CloudCanal 会将变更实时同步至 Paimon,StarRocks 查询到的数据也将同步更新,从而实现真正的端到端 秒级实时分析能力,无需构建复杂的 ETL 流程。
总结
Apache Paimon 以其创新的 实时更新 能力,为现代数据湖仓架构注入了新的活力,而 CloudCanal + Paimon 的组合,则通过零代码、自动化的方式,快速落地高性能的实时湖仓,最后与 StarRocks 等下游引擎配合,打通了从数据同步到实时查询的完整闭环。