为什么 LLMs 的「内心」难以捉摸?
当 GPT-4、Llama 2 等大语言模型(LLMs)在文本生成、代码编写等领域展现惊人能力时,它们复杂的内部机制却像一个「黑箱」?
- 如何让模型更安全?(如减少有害内容生成)
- 如何让模型更可信?(如抑制幻觉、提升真实性)
- 如何灵活修改模型行为?(如增强特定情感或知识)
现有方法要么依赖繁琐的人工微调,要么陷入「改一处崩全局」的困境。而最新发表于 NeurIPS 2024 的论文《Adversarial Representation Engineering: A General Model Editing Framework for Large Language Models》,提出了一种颠覆性框架ARE(对抗性表示工程),让大模型的「内心」可编辑、可解释!

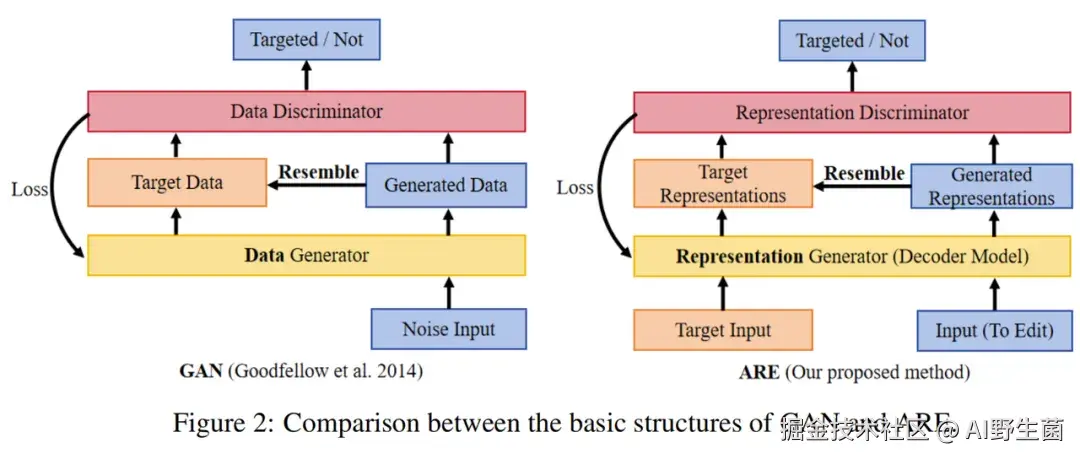
ARE 核心:用「对抗博弈」驯服大模型
想象一场「猫鼠游戏」:
- 猫(判别器 D):负责判断模型生成的内容是否符合目标概念(如「愤怒」「无害性」)。
- 鼠(生成器 G,即 LLM 本身):试图生成让判别器无法区分的内容。

ARE 的核心逻辑:
- 提取特征密码:从模型隐藏层中提取与目标概念(如「诚实」)相关的特征向量,形成「表示密码本」🔑。
- 对抗训练:
- 判别器 D 学习区分「目标特征」与「非目标特征」,比如识别哪些隐藏层活动对应「有害内容」。
- 生成器 G(LLM)则学习「欺骗」判别器,让自己的隐藏层活动更接近目标概念(如「无害」)。
- 双向编辑:通过调整博弈目标,ARE 既能增强模型的特定能力(如强化安全性),也能移除对齐(用于红队测试),实现「一键切换」!
关键突破 :相比传统微调,ARE 仅需更新模型少量参数(如 LoRA 技术),计算成本降低 90% 以上,同时保持模型原有性能不受损🔧。
实验数据:ARE 如何碾压传统方法?
论文在 Llama2、Vicuna 等模型上进行了多场景测试,结果堪称惊艳:
越狱攻击防御
- 传统方法(如 HEDA)对 Llama2 的有害提示拒绝率为
20%,而 ARE 将其降至<1%! - 攻击场景下,ARE 能以近
100%成功率绕过安全机制(用于红队评估),远超基线方法🔪。


幻觉控制
- 在 TruthfulQA 基准(衡量真实性)中,ARE 编辑后的 Llama2 准确率达52.14%,比「自我提醒」等方法提升超 40%📈。
- 甚至能反向诱导模型生成幻觉(用于对抗性测试),展现双向控制能力。

生成质量保障
- 传统编辑方法常导致文本重复(如「Shadow Alignment」的 Repetition-4 率 23.6%),而 ARE 将其降至7.53%,接近人类写作水平✍️。

伦理与挑战:技术的「双刃剑」
论文同时敲响警钟:
- 滥用风险:ARE 可能被用于绕过安全机制,生成虚假信息或恶意内容,需结合「安全护栏」技术(如内容过滤)部署🚫。
- 数据依赖:当前依赖人工标注的「目标 - 非目标」数据集,未来需探索无监督或自监督编辑方法。
作者强调:「ARE 的价值不仅在于攻击或防御,更在于为大模型的透明化治理提供了新工具。」