7大设计原则
来,跟我背:单衣解开犁河堤
- 单一职责原则 (Single Responsibility Principle, SRP)
- 核心思想:一个类应该只有一个引起它变化的原因
- 关键点:每个类只承担一个职责,功能高度内聚
- 优势:提高代码可读性、可维护性,降低修改风险
通俗理解:把类尽可能划分开,比如对于表中的数据我们建立了一个实体类,但是当数据在系统中流转的时候又要在造一个dto(数据传输对象),这样即使后来表中新加了字段,我们只需要改变实体类就可以了,而dto则不受影响,因为你新加的字段对于这个dto可能是没用的,它还负责自己原来的工作。
- 开闭原则 (Open-Closed Principle, OCP)
- 核心思想:软件实体应对扩展开放,对修改关闭
- 关键点:通过抽象和接口实现扩展性
- 优势:系统更稳定,新增功能不影响现有代码
通俗理解:比如你现在有一个计算类,他有一个方法叫做shapeCompute(Shape shape)。那么圆形和三角形的计算方式肯定不一样吧?你是不是要在方法中写个if(shape.name == "圆形")else if(shape.name == "三角形")...之类的代码?现在问题来了,我每增加一个形状,是不是就要再更改一次代码?那么我们可以直接把计算类定义成一个接口,或者是抽象类,然后让其实现类或者子类自己去定义计算逻辑。比如采用接口的形式,直接把Shape拆解成Circle和Trangle,然后Circle implate 计算接口,重写shapeCompute。这样以后你每增加一个形状,就不需要改计算接口了,让新加的形状直接自己重写就好了。
- 里氏替换原则 (Liskov Substitution Principle, LSP)
- 核心思想:子类必须能够替换它们的基类而不改变程序的正确性
- 关键点:继承关系中保持行为一致性
- 优势:确保继承体系的正确性,避免运行时错误
通俗理解:你爱喝咖啡吗?美食还是卡布奇诺?假设现在有一个基础款的咖啡机(BasicCoffeeMachine),里面只有一个制作美式的方法makeAmericano()。现在要新建一个升级款的咖啡机(要新加上制作卡布奇诺的功能),你要怎么做?重写父类的makeAmericano方法吗?让该方法直接生产出卡布奇诺?当然不!这样你不就只能做卡布奇诺了吗?正确的做法应该是:
scala
class AdvancedCoffeeMachine extends BasicCoffeeMachine {
public void brewCappuccino() {
super.brewAmericano(); // 先做美式
this.foamMilk();
}
public void foamMilk(){
//加奶+打气泡
}
}这样AdvancedCoffeeMachine既可以通过调用父类的制作美式咖啡的方法单独制作美式咖啡,又可以结合两种方法来制作卡布奇诺。
- 接口隔离原则 (Interface Segregation Principle, ISP)
- 核心思想:客户端不应被迫依赖它们不使用的接口
- 关键点:接口要小而专,避免臃肿
- 优势:减少不必要的依赖,提高系统灵活性
通俗理解 :不要出现"瑞士军刀"接口(一个接口过于全能,里面写了太多方法)。接口臃肿导致实现类被迫承载无关方法,严重时对于程序的运行效率都会带来影响。
- 依赖倒置原则 (Dependency Inversion Principle, DIP)
- 核心思想:高层模块不应依赖低层模块,二者都应依赖抽象
- 关键点:依赖抽象而非具体实现
- 优势:降低耦合度,提高代码可测试性和可维护性
通俗理解:什么叫做高层依赖于底层呢?这个原则我们直接举一个很实际的例子。Spring中的controller,service和mapper。首先来说他们遵循了单一职责原则,分别负责接收请求、业务代码处理、数据库操作。如果按照高层依赖于底层的方式实现:Controller → Service → Mapper。
java
// Controller直接依赖具体Service实现
@Controller
public class UserController {
private final UserServiceImpl userService; // 直接依赖实现类
public UserController() {
this.userService = new UserServiceImpl(); // 硬编码依赖
}
}
// Service直接依赖具体Mapper实现
@Service
public class UserServiceImpl {
private final UserMapperImpl userMapper = new UserMapperImpl();
}会有什么问题?
- 可维护性差:如果,UserServiceImpl的一个方法名称改变了,或者UserServiceImpl改名了,改成了UserServiceImplv2。那么所有引用了它的Controller是不是全部都要修改?
- 耦合度强:过于紧密的结构肯定是不好的,比如你在测试的时候,没有办法将UserMapperImpl替换,也阻止不了它调用真是数据库。而在单元测试controller的时候,这些可能都用不到。
- 扩展性差:与1类似,如果UserServiceImpl中需要添加缓存服务,如果直接修改原来的方法,就会导致旧方法不可用。如果写一个子类继承父类,然后手动去替换也可以,但是,是否每一次添加都继承一次呢?会导致类爆炸,也就是过度继承,难以维护。
实际标准:Controller → Service接口 ← ServiceImpl → Mapper接口 ← MapperImpl。 Controller依赖的Service接口只是一个抽象,需要替换Impl时更为方便。mapper也是一个接口,当和数据库变更时,完全也不影响上层。也就是说,Service接口和Mapper接口就是原则中所说的抽象。它即被上层模块注入,又约束了下层的实现,所以说上层下层都依赖于抽象。
- 迪米特法则/最少知识原则 (Law of Demeter, LoD)
- 核心思想:一个对象应该对其他对象保持最少的了解
- 关键点:减少对象间的直接交互
- 优势:降低耦合度,提高模块独立性
通俗理解:不要和陌生人说话,只和直接的朋友(对象自身,成员变量,方法参数,内部创建的对象)进行通讯。假设我们现在的几个类结构是这样的:
css
Address->[city, street, zipCode]
Profile->[email, *address*]
User->[id,name, *profile*]
其中被*包围的代表引用数据类型那么User和Profile就是直接的朋友,Address和Profile也是直接的朋友,User和Address就是间接的朋友。 如果在外部代码中写user.getProfile().getAddress().getCity()就违反了迪米特法则,因为调用方需要完整的知道所有的关系。 正确的写法应该是在User中写一个getCity()方法,通过profile.getCity()来返回。这样就可以user.getCity()了。
- 组合/聚合复用原则 (Composite/Aggregate Reuse Principle, CARP)
- 核心思想:优先使用组合/聚合,而不是继承来达到复用的目的
- 关键点:对象间关系更灵活
- 优势:避免继承的缺点,系统更灵活易扩展
通俗理解: 这块我自己都快忘了,啥是组合啥是聚合了。 让AI帮我列了一下:
| 维度 | 聚合(Aggregation) | 组合(Composition) |
|---|---|---|
| 生命周期 | 部分可以独立于整体存在 | 部分与整体共存亡 |
| 关系强度 | 弱关联("has-a") | 强关联("contains-a") |
| UML表示 | 空心菱形箭头(指向整体) | 实心菱形箭头(指向整体) |
| 代码表现 | 通过setter或方法参数注入 | 在构造函数/声明时创建 |
| 可共享性 | 部分可被多个整体共享 | 部分专属某个整体 |
| 设计意图 | 表示松散的包含关系 | 表示紧密的组成关系 |
简单记忆:"你们这帮人聚在一起干什么"(分开每个人都是个个体,但是聚在一起就变成了一个集合)。"大家好,我们是,糖果超甜~"(如果少了某个糖糖,就不够甜了捏,组合就要面临解散捏)。
继承复用:
- 优点:简单方便,子类直接得到父类全部的方法。
- 缺点:破环封装,耦合度高
组合/聚合复用:
- 优点:降低耦合度,维护封装
- 缺点:产生的对象比较多。
举个例子:
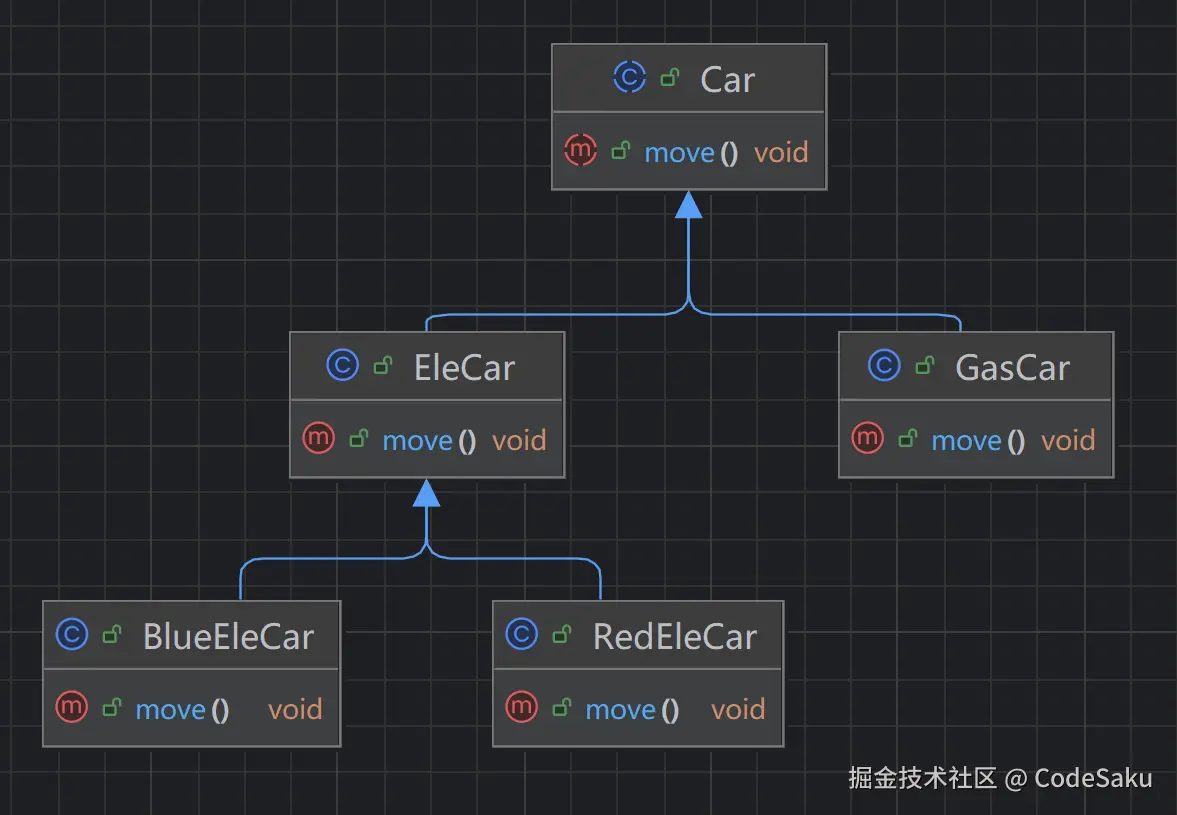
scala
public class RedEleCar extends EleCar{
@Override
public void move() {
System.out.println("红色电动车启动");
}
}
scala
public class BlueEleCar extends EleCar{
@Override
public void move() {
System.out.println("蓝色电动车启动");
}
}那么此时如果要再加上黄色汽油车,黑色汽油车呢?就是不断地继承,然后重写方法。 来看下组合方式怎么实现:
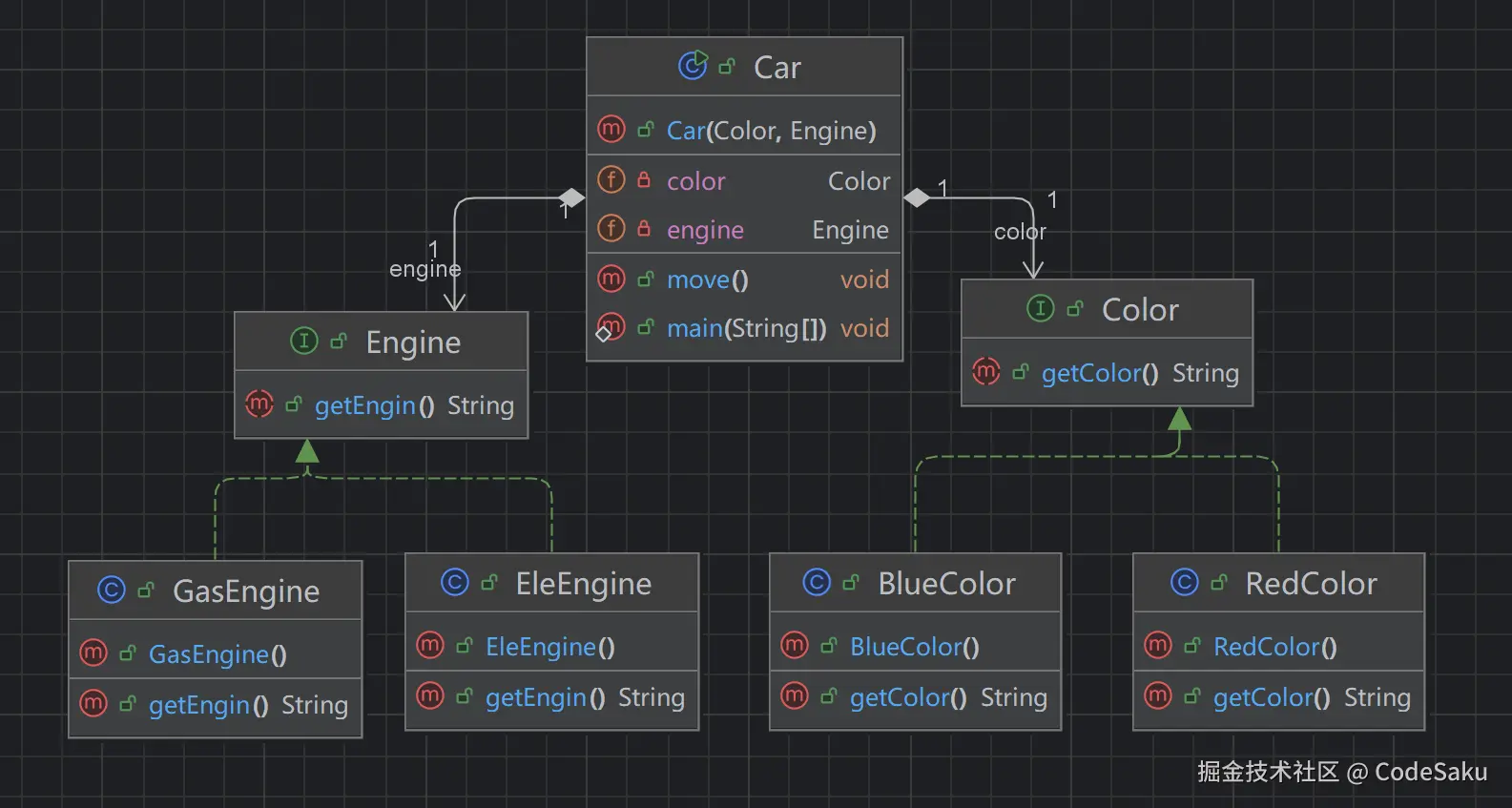
arduino
public class Car extends EleEngine {
private Color color;
private Engine engine;
public Car(Color color, Engine engine) {
this.color = color;
this.engine = engine;
}
public void move() {
System.out.println(color.getColor() + engine.getEngin() + "启动");
}
public static void main(String[] args) {
new Car(new RedColor(), new EleEngine()).move();
}
}
typescript
public class RedColor implements Color {
@Override
public String getColor() {
return "红色";
}
}
typescript
public class GasEngine implements Engine{
@Override
public String getEngin() {
return "汽油";
}
}在同样都只创建了一种类型的车的情况下,来看下我的文件数量:
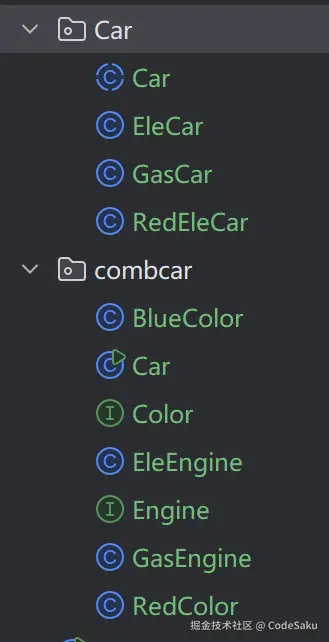
在继承复用的情况下,如果要再加一种车,只增加一个子类就好。但是组合复用则要再加两个,一个颜色的实现类,一个引擎的实现类。听上去貌似多了一点哈。但是设想一种情况,现在有九种颜色的车,和九种引擎。要创建每种颜色和引擎的对象各一个,你要写几个子类?81个!可是如果是组合的方式呢?是不是只要写九个Color实现类和九个Engine实现类,然后循环遍历一下就有了?体会一下吧嘿嘿。
首尾呼应:单衣解开犁河堤!!
感谢你能看到这里,下一篇再见!