1.为什么会存在反压
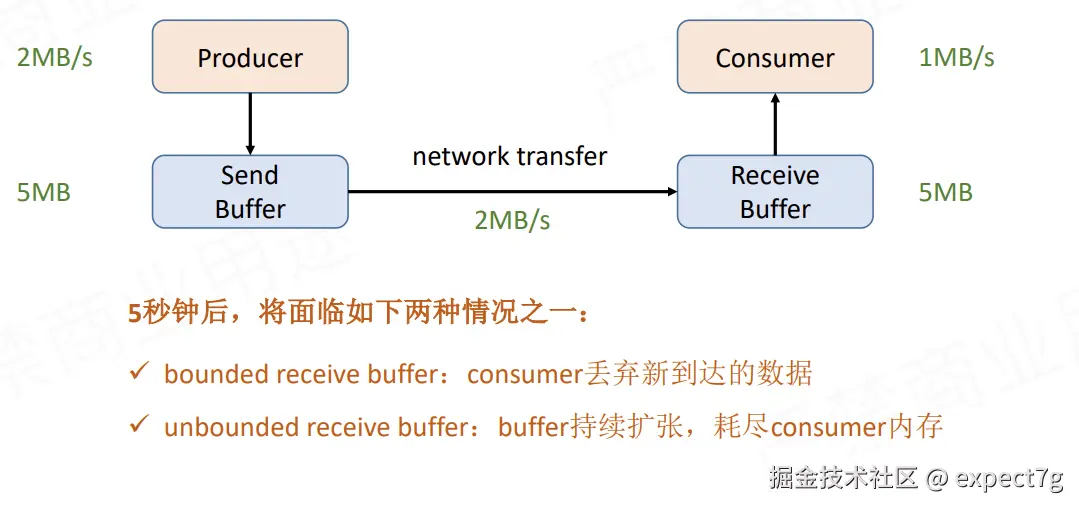
反压是很常见的情况,如下图
- 生产者:每s生产2MB数据
- 消费者:每s消费1MB数据
在生产者和消费者之间又存在一个缓冲区,为了缓解这个差值的,但是如果一致存在差值,迟早有一天,缓冲区会满,到时候会引发严重的溢出问题
 因此,我们为了解决这个问题,需要在中间加一个速度控制器,你可以理解为是变压器,把高压变为低压,Flink有2种解决方案
因此,我们为了解决这个问题,需要在中间加一个速度控制器,你可以理解为是变压器,把高压变为低压,Flink有2种解决方案
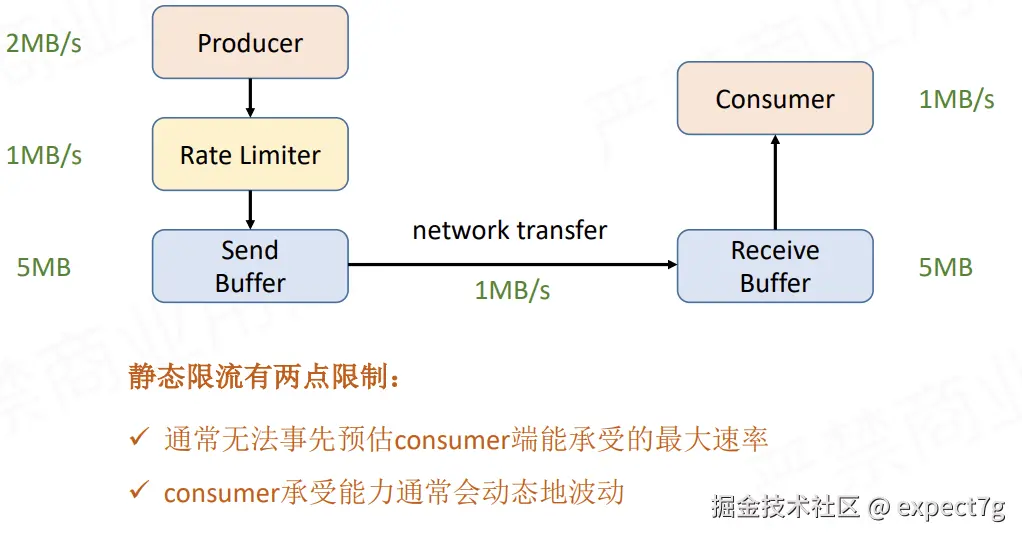
- 静态限速(1.5前)
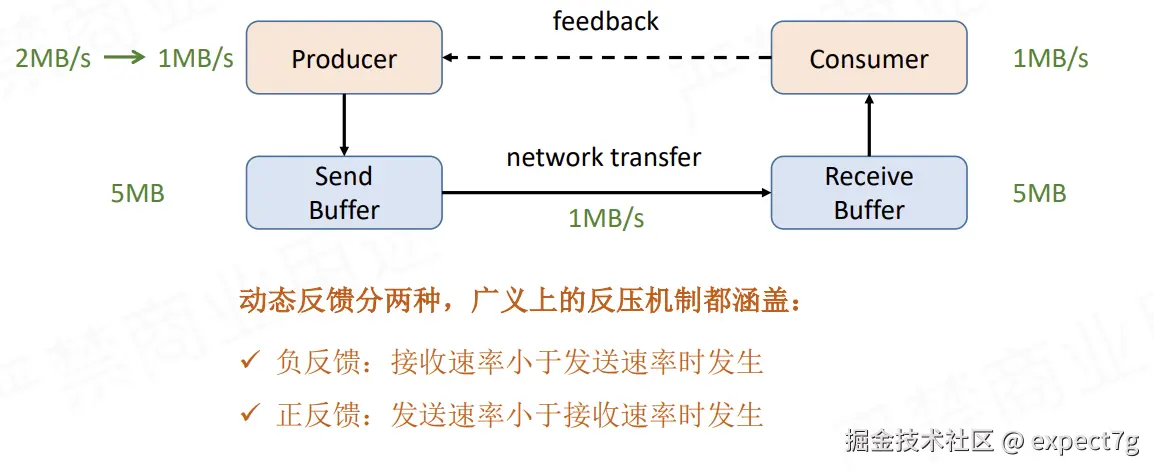
- 动态反馈(1.5后)
2.TCP-based反压--静态限速
这是早期Flink版本基于TCP去做的处理,我们都知道类似storm、spark、zookeeper都有一个机制就是feedback,而TCP天然具备feedback机制,因此Flink早期用它做反压 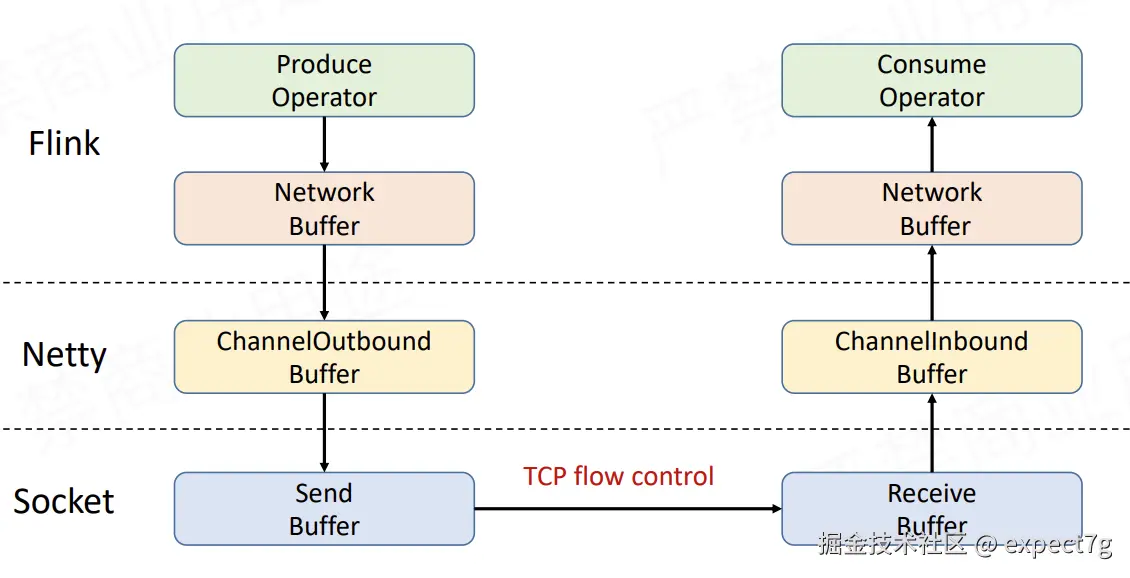 简单看一下他的原理(不重要)
简单看一下他的原理(不重要)
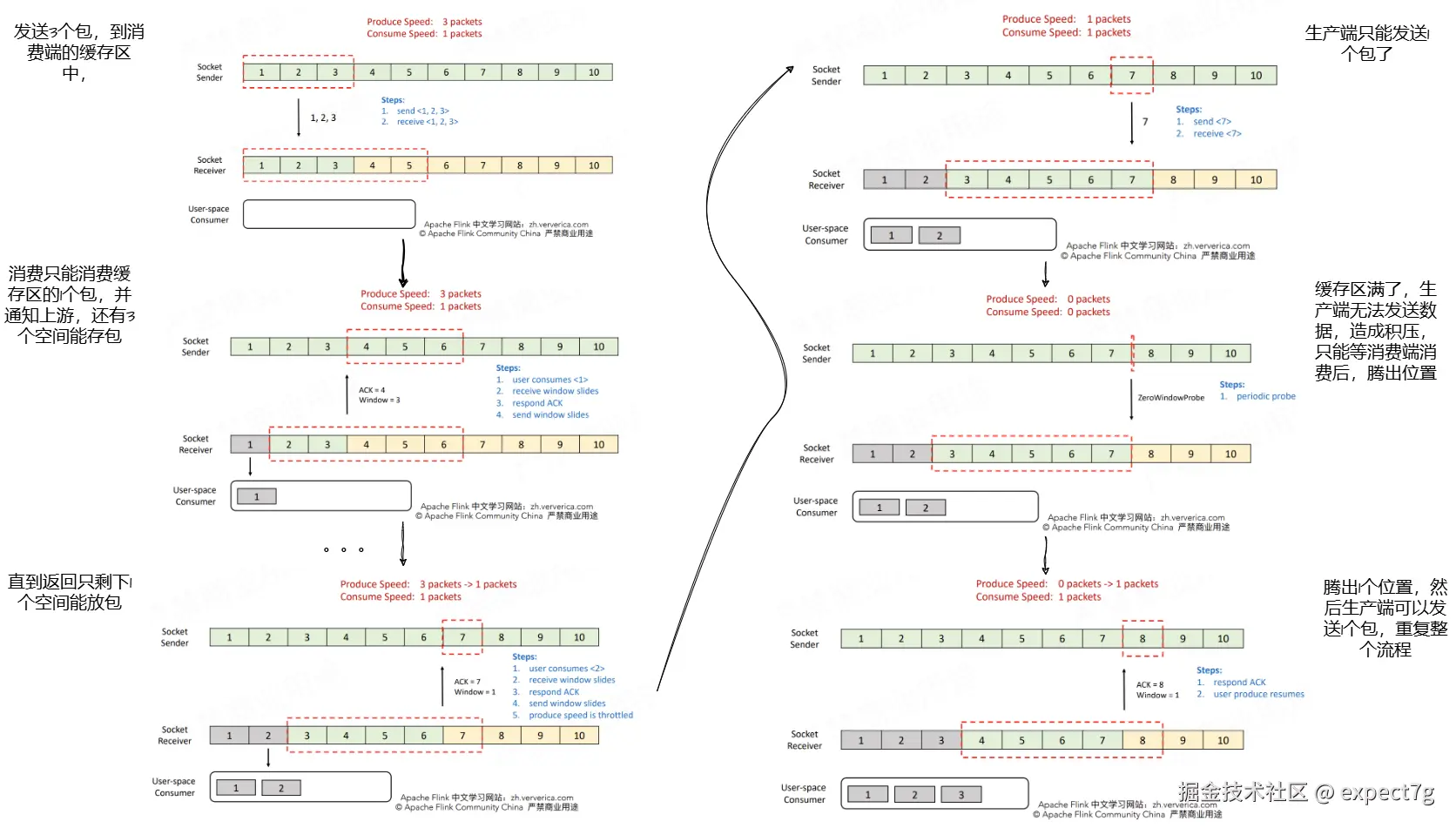 我们看得出来,整个静态窗口的机制还存在很大的不足,比如缓存区满了,就只能消费1个后,才能生产1个
我们看得出来,整个静态窗口的机制还存在很大的不足,比如缓存区满了,就只能消费1个后,才能生产1个
3.反压信息的传播
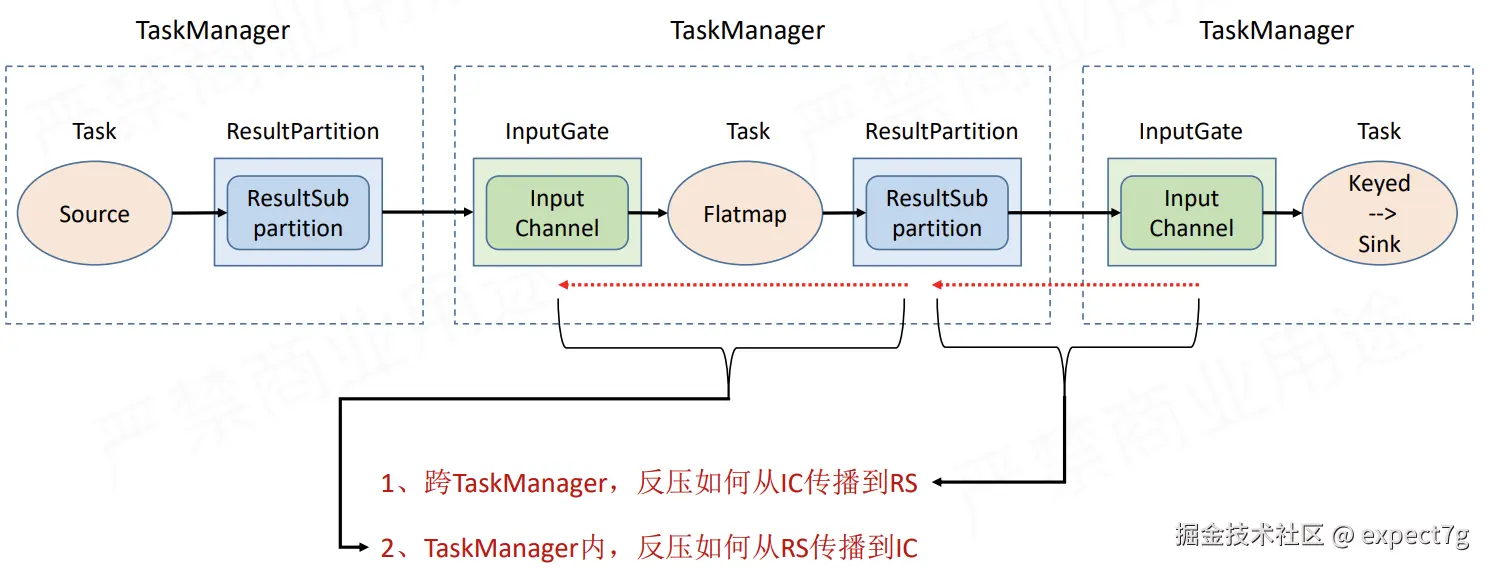
(1) 几个组件的概念
- ResultPartition:简称RSP ,生产者的数据输出 "分区",是数据发送的逻辑单元,其中ResultSubPartition 是细分,实际存储待发送数据的缓冲区,用于写
- InputGate:简称IC,消费者的数据输入 "门",用于读 ,聚合多个输入通道(InputChannel )的数据,其中InputChannel 是单个数据通道,对应上游一个
ResultSubpartition - LocalBufferPool:简称LBP ,为当前 TaskManager 内的任务提供 本地缓冲区,临时存放待发送的数据。
- NetworkBufferPool:简称NBP ,Flink 全局的 跨 TaskManager 网络缓冲区,用于在网络传输前暂存数据。
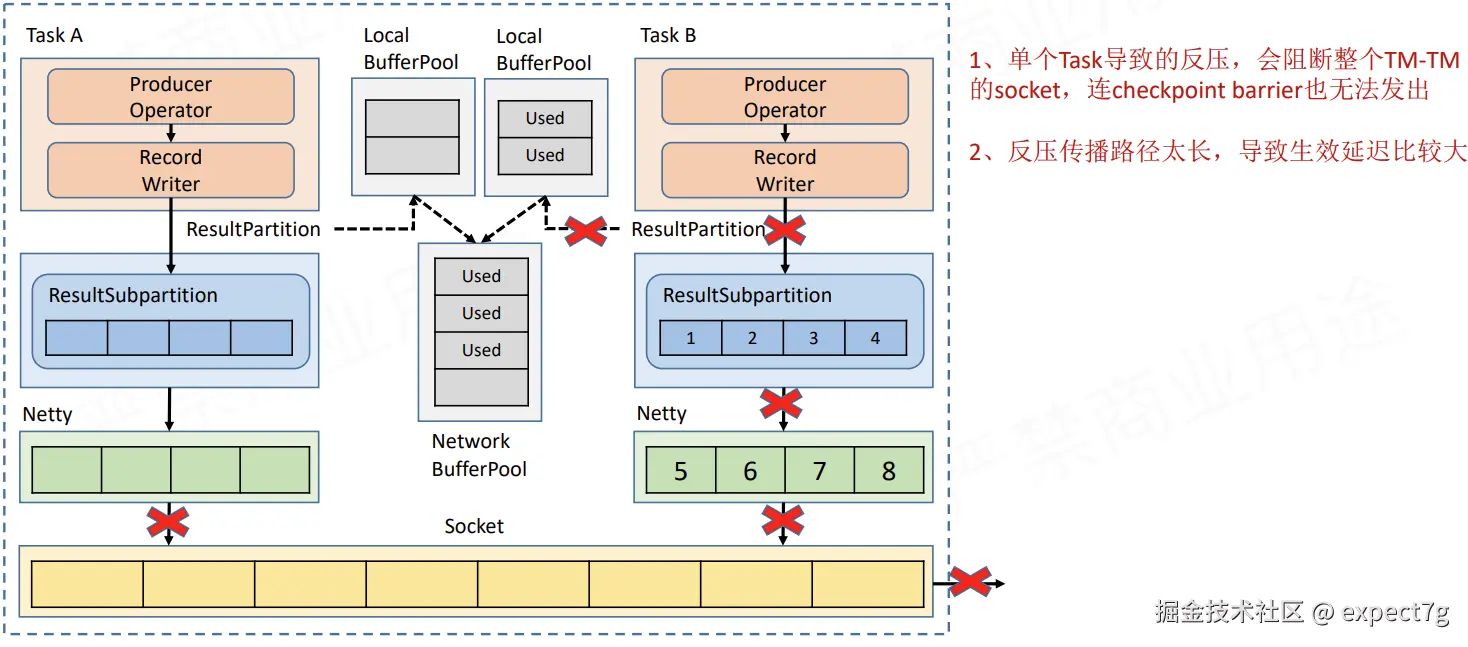
反压的前提:
- IC满了
- LBP满了
- NBP满了
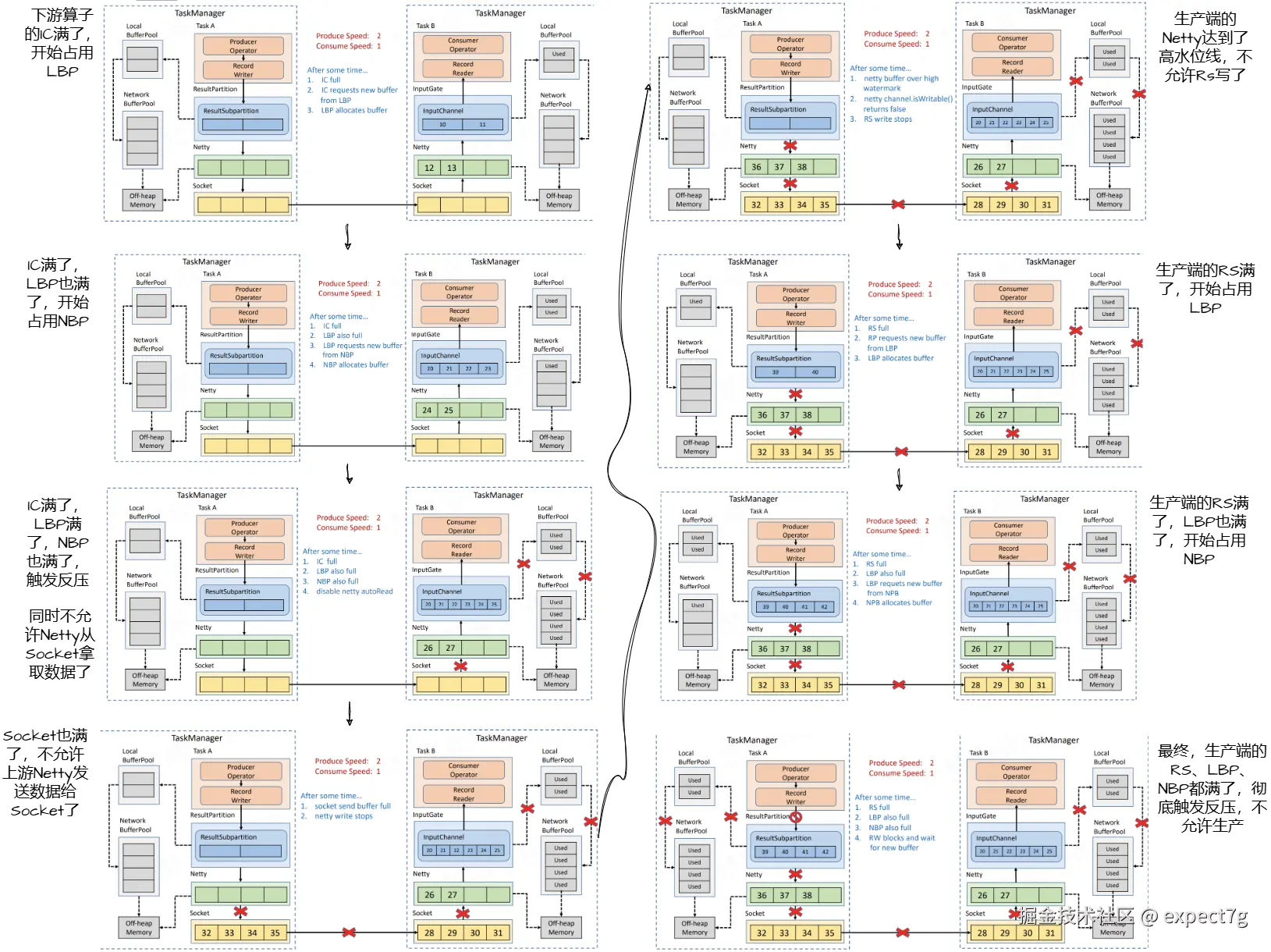
(2) 跨TM的反压
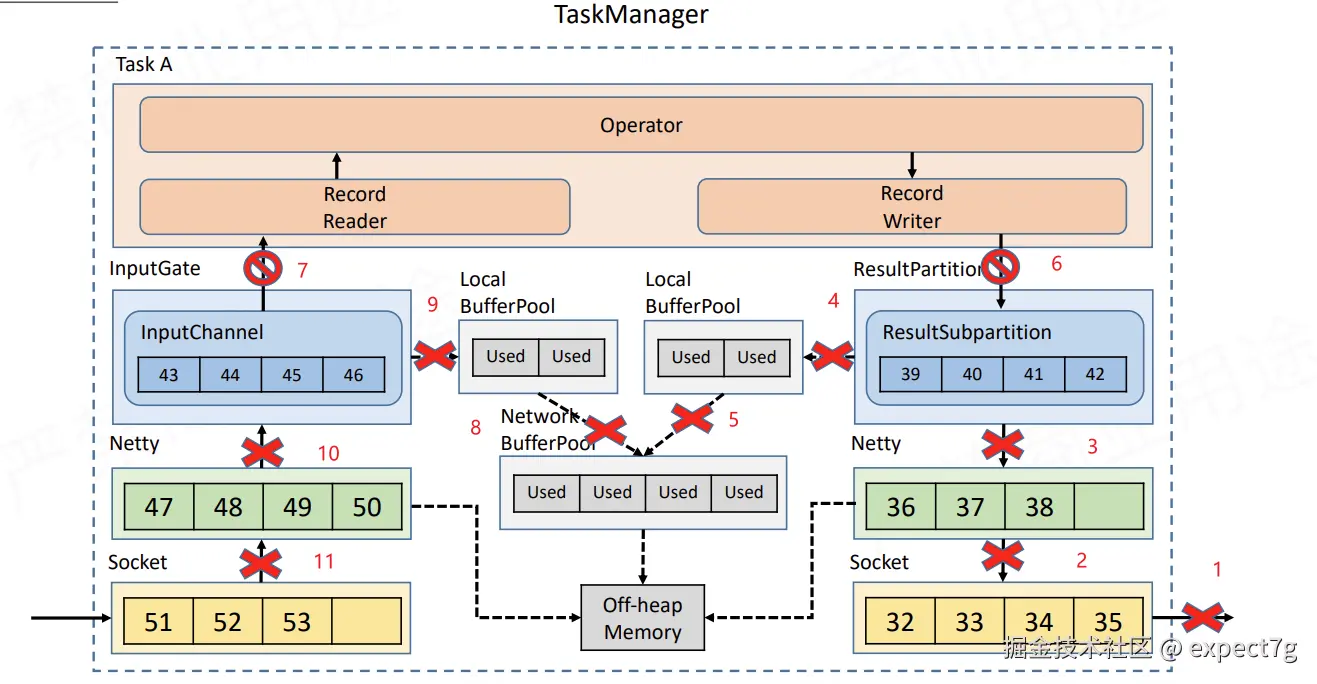
(3) TM内的反压
4.Credit-based反压---动态反馈
 在TCP反压版本优缺点的情况下,Flink选择自己实现一个feedback机制,credit可以类比TCP的窗口,原理如下图
在TCP反压版本优缺点的情况下,Flink选择自己实现一个feedback机制,credit可以类比TCP的窗口,原理如下图 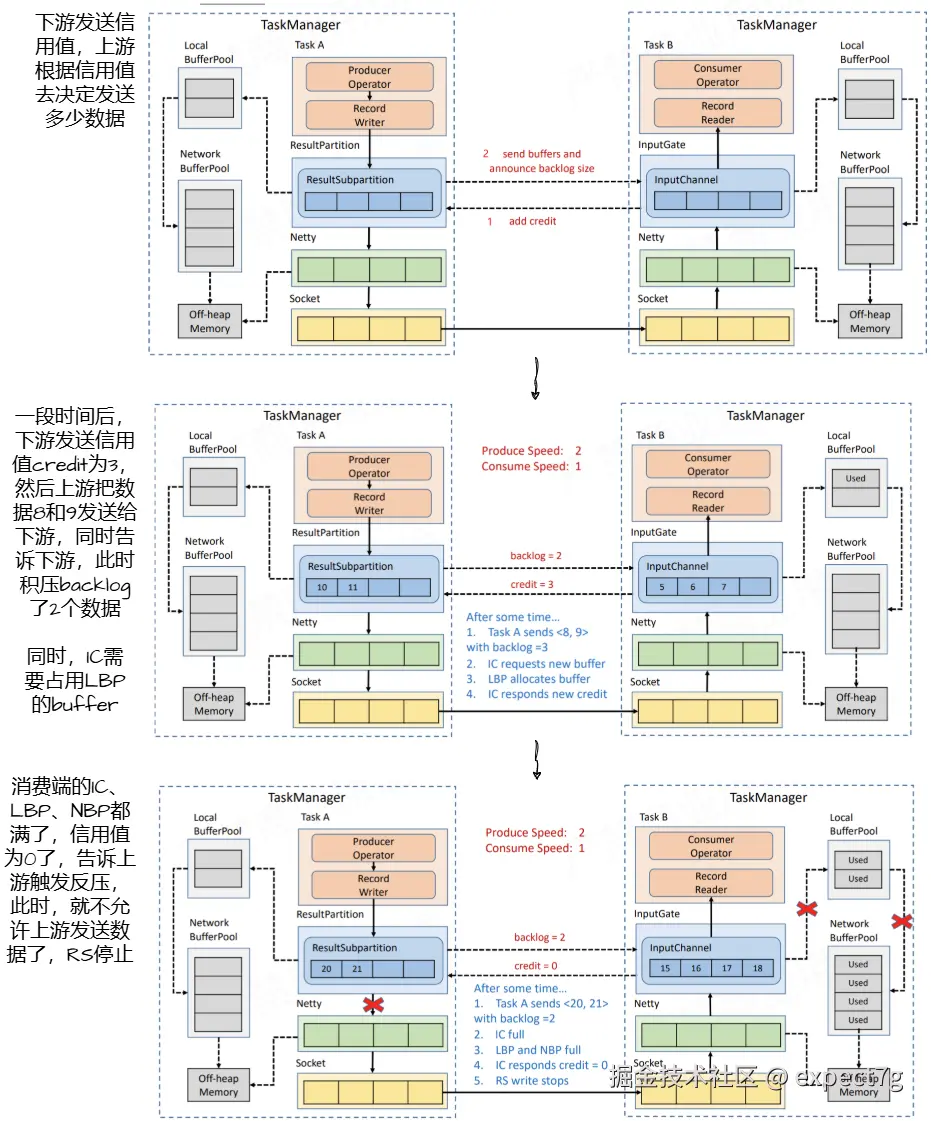 原理就是下面几点
原理就是下面几点
- 下游算子根据其可用缓冲区数量和处理能力计算信用值Credit(这是动态更新的),然后发送给上游算子
- 上游算子根据Credit去发送数据(只能<=Credit的值)
- 当下游可用缓冲区数量都满了,Credit降为0了,通知上游触发反压
- 上游开始反压,停止RS的写入