作者:forever
原文链接:www.modb.pro/db/19247357...
一、概述
数据库的类型多种多样,关系型数据库、时序型数据库、非关系型数据库、内存数据库、分布式数据库、图数据库等等,每种类型都有其特定的使用场景和优势,KaiwuDB 是一款面向 AIoT 场景的分布式、多模融合、支持原生 AI 的数据库产品,支持同一实例同时建立时序库和关系库并融合处理多模数据,具备时序数据高效处理能力,kwdb支持关系数据库和时序数据库之间跨模检索相关的数据。
什么是时序数据库?
时序数据库(Time Series Database, TSDB)是专门针对时间序列数据(按时间顺序记录的数据点)进行存储和管理的数据库。这类数据通常包含时间戳(Timestamp)和对应的数值,例如传感器读数、服务器监控指标、金融交易记录等。时序数据库的核心特点是高效处理时间范围内的聚合查询、高频数据写入和时间窗口分析。
我们通过与关系型数据库的对比来详细了解时序数据库
关系数据库:采用表格形式存储数据,每个表格由行和列组成,行代表记录,列代表字段。数据之间的关系通过外键和表连接来维护,在复杂查询、多表关联查询和事务处理方面表现出色。然而,在处理大规模时间序列数据时,查询性能可能会下降。适用于需要复杂查询、事务处理和数据一致性的应用场景,如企业资源规划(ERP)、客户关系管理(CRM)等。
时序数据库:专为时间序列数据设计,数据通常按照时间戳排序存储。时序数据库支持高效的时间范围查询、聚合和插值等操作。针对时间序列数据的查询进行了优化,能够高效地处理时间范围查询、数据聚合和降采样等操作。适用于需要实时监控、数据分析和预测的应用场景,如物联网(IoT)、金融交易、能源管理等。
二、KWDB时序数据库特性使用
KWDB 时序数据库支持在创建数据库的时候设置数据库的生命周期和分区时间范围,我们创建数据库到创建表来完整体验时序特性
1、kwdb时序数据库特性使用
1)时序数据库创建
同一数据库实例可以创建一个或多个时序库,时序库只包含时序表,同理时序表也智能创建在时序库。
sql
CREATE TS DATABASE <db_name> [RETENTIONS <keep_duration>] [PARTITION INTERVAL <interval>];参数说明
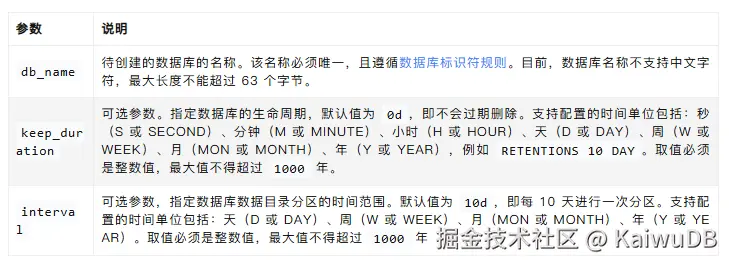
示例
创建一个普通的时序数据库
ini
CREATE TS DATABASE banjin_tsdb;
sql
root@192.168.150.135:26257/rdb> CREATE TS DATABASE banjin_tsdb;
CREATE TS DATABASE
Time: 3.406977ms创建一个带生命周期时序数据库
sql
CREATE TS DATABASE banjin_tsdb_life RETENTIONS 4w; -----生命周期4周
sql
root@192.168.150.135:26257/rdb> CREATE TS DATABASE banjin_tsdb_life RETENTIONS 4w;
CREATE TS DATABASE
Time: 4.492758ms创建一个一个带生命周期并且分区的时序数据库
sql
CREATE TS DATABASE banjin_tsdb_par RETENTIONS 4w PARTITION INTERVAL 1w;-----生命周期为4周与分区间隔为1周
sql
root@192.168.150.135:26257/rdb> CREATE TS DATABASE banjin_tsdb_par RETENTIONS 4w PARTITION INTERVAL 1w;
CREATE TS DATABASE
Time: 3.662981ms2)查询数据库
ini
#查看已创建的数据库
SHOW DATABASES;
#查看数据库的详细信息和创建
SHOW CREATE DATABASE <database_name>;
show create database banjin_tsdb_life;
#查看数据库中的表
SHOW TABLES FROM<database_name>;
##TIME SERIES 为时序库
##RELATIONAL 为关系库
sql
root@192.168.150.135:26257/rdb> SHOW DATABASES;
database_name | engine_type
-------------------+--------------
banjin_tsdb | TIME SERIES
banjin_tsdb_life | TIME SERIES
banjin_tsdb_par | TIME SERIES
defaultdb | RELATIONAL
postgres | RELATIONAL
rdb | RELATIONAL
system | RELATIONAL
tsdb | TIME SERIES
(8 rows)
Time: 2.407129ms
root@192.168.150.135:26257/rdb>
root@192.168.150.135:26257/rdb> show create database banjin_tsdb_life; ----带生命周期
database_name | create_statement
-------------------+--------------------------------------
banjin_tsdb_life | CREATE TS DATABASE banjin_tsdb_life
| retentions 2419200s
| partition interval 10d
(1 row)
Time: 1.211434ms
root@192.168.150.135:26257/rdb> show create database banjin_tsdb_par; ----带生命周期和分区
database_name | create_statement
------------------+-------------------------------------
banjin_tsdb_par | CREATE TS DATABASE banjin_tsdb_par
| retentions 2419200s
| partition interval 7d ---在此我们可以看到周其实也是转换为d(天)
(1 row)
Time: 1.195576ms在此我们刚好验证到了:创建数据库时,如果指定 retentions 和 partition interval 参数的取值,则显示指定的取值。如未指定,则显示该参数的默认值。默认情况下,retentions 参数的取值为 0s,partition interval 参数的取值为 10d。
3)数据库的修改
数据库修改支持修改数据库名称、修改数据生命周期或分区时间范围
sql
#修改名称
ALTER DATABASE <old_name> RENAME TO <new_name>;
#修改数据生命周期或分区时间范围
ALTER TS DATABASE <db_name> SET [RETENTIONS = <keep_duration> | PARTITION INTERVAL = <interval> ];参数介绍:

sql
ALTERroot@192.168.150.135:26257/rdb> ALTER DATABASE banjin_tsdb RENAME TO banjin_tsdb_re; ----修改名称
RENAME DATABASE
Time: 3.381247ms
root@192.168.150.135:26257/rdb>
root@192.168.150.135:26257/rdb> ALTER TS DATABASE banjin_tsdb_par SET RETENTIONS = 10 day; ---修改生命周期
ALTER TS DATABASE
Time: 2.554524ms
root@192.168.150.135:26257/rdb>
root@192.168.150.135:26257/rdb> ALTER TS DATABASE banjin_tsdb_par SET PARTITION INTERVAL = 2 day; ---修改分区时间范围
ALTER TS DATABASE
Time: 2.169787ms
root@192.168.150.135:26257/rdb> SHOW DATABASES;
database_name | engine_type
-------------------+--------------
banjin_tsdb_life | TIME SERIES
banjin_tsdb_par | TIME SERIES
banjin_tsdb_re | TIME SERIES
defaultdb | RELATIONAL
postgres | RELATIONAL
rdb | RELATIONAL
system | RELATIONAL
tsdb | TIME SERIES
(8 rows)
Time: 1.461412ms
root@192.168.150.135:26257/rdb> show create database banjin_tsdb_par;
database_name | create_statement
------------------+-------------------------------------
banjin_tsdb_par | CREATE TS DATABASE banjin_tsdb_par
| retentions 864000s
| partition interval 2d
(1 row)
Time: 1.216081ms DATABASE banjin_tsdb RENAME TO banjin_tsdb_re;4)删除数据库
ini
DROP DATABASE [IF EXISTS] <db_name> [CASCADE];#删除数据库
DROP DATABASE banjin_tsdb_re;
#在有数据库对象是可以级联删除
DROP DATABASE banjin_tsdb_re CASCADE;
root@192.168.150.135:26257/rdb> DROP DATABASE tsdb; ERROR: rejected: DROP DATABASE on non-empty database without explicit CASCADE (sql_safe_updates = true) SQLSTATE: 01000 root@192.168.150.135:26257/rdb> DROP DATABASE tsdb cascade; DROP DATABASE
Time: 49.574938ms
2、时序表的使用
了解完时序库,接着了解时序表,当然时序表就是同时序库是配套的
1)时序表创建
sql
#语法格式
CREATE TABLE <table_name> (<column_list>)
[TAGS|ATTRIBUTES] (<tag_list>)
PRIMARY [TAGS|ATTRIBUTES] (<primary_tag_list>)
[RETENTIONS <keep_duration>]
[ACTIVETIME <active_duration>]
[PARTITION INTERVAL <interval>]
[DICT ENCODING];
CREATE TABLE meter_data (
ts TIMESTAMPTZ(3) NOT NULL, -----第一列,数据类型必须是 TIMESTAMPTZ 或 TIMESTAMP 且非空,用于记录数据采集的时间。
voltage FLOAT8 NULL,
current FLOAT8 NULL,
power FLOAT8 NULL,
energy FLOAT8 NULL
) TAGS (
meter_id VARCHAR(50) NOT NULL )-----用于记录采集对象的静态数据。
PRIMARY TAGS(meter_id) -----主标签用于区分不同的实体。每张表需要指定至少一个主标签,主标签需要在建表时指定,且后续不允许修改或删除主表签。
retentions 30d -----可选参数,指定表的生命周期。超过设置的生命周期后,系统自动从数据库中清除目标表中数据。默认值为 0d,即不会过期删除。
activetime 20d -----可选参数,指定数据的活跃时间。超过设置的时间后,系统自动压缩表数据。
partition interval 10d -----可选参数,指定表数据目录分区的时间范围。默认值为 10d。
dict encoding;---可选参数,启用字符串的字典编码功能,提升字符串数据的压缩能力,且只能在建表时开启。开启后不支持禁用。参数详细介绍
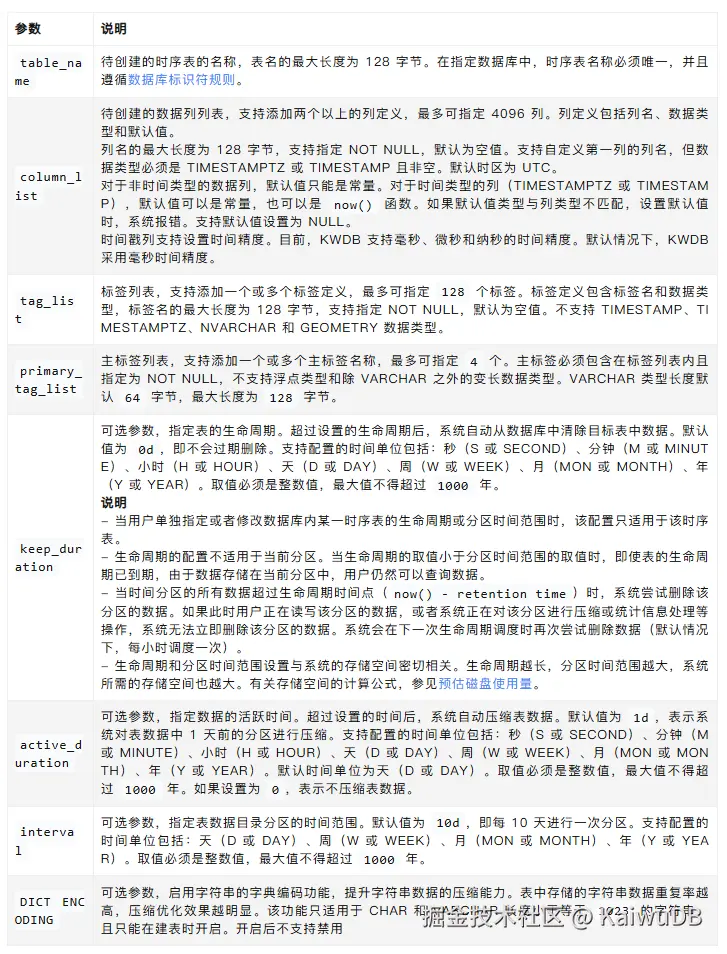
示例
sql
#创建一个时序表
CREATE TABLE meter_data1 (
ts TIMESTAMPTZ(3) NOT NULL,
voltage FLOAT8 NULL,
current FLOAT8 NULL,
power FLOAT8 NULL,
energy FLOAT8 NULL
) TAGS (
meter_id VARCHAR(50) NOT NULL )
PRIMARY TAGS(meter_id);
#创建一个生命周期30d和分区时间范围10的时序表
CREATE TABLE meter_data2 (
ts TIMESTAMPTZ(3) NOT NULL,
voltage FLOAT8 NULL,
current FLOAT8 NULL,
power FLOAT8 NULL,
energy FLOAT8 NULL
) TAGS (
meter_id VARCHAR(50) NOT NULL )
PRIMARY TAGS(meter_id)
retentions 30d
partition interval 10d;
#创建一个活跃时间为20的时序表
CREATE TABLE meter_data3 (
ts TIMESTAMPTZ(3) NOT NULL,
voltage FLOAT8 NULL,
current FLOAT8 NULL,
power FLOAT8 NULL,
energy FLOAT8 NULL
) TAGS (
meter_id VARCHAR(50) NOT NULL )
PRIMARY TAGS(meter_id)
activetime 20d
dict encoding;
sql
root@192.168.150.135:26257/banjin_tsdb_par> show create table meter_data1;
table_name | create_statement
--------------+-------------------------------------------------------------
meter_data1 | CREATE TABLE meter_data1 (
| ts TIMESTAMPTZ(3) NOT NULL,
| voltage FLOAT8 NULL,
| current FLOAT8 NULL,
| power FLOAT8 NULL,
| energy FLOAT8 NULL
| ) TAGS (
| meter_id VARCHAR(50) NOT NULL ) PRIMARY TAGS(meter_id)
| retentions 864000s
| activetime 1d
| partition interval 2d
(1 row)
Time: 145.235397ms
root@192.168.150.135:26257/banjin_tsdb_par> show create table meter_data2;
table_name | create_statement
--------------+-------------------------------------------------------------
meter_data2 | CREATE TABLE meter_data2 (
| ts TIMESTAMPTZ(3) NOT NULL,
| voltage FLOAT8 NULL,
| current FLOAT8 NULL,
| power FLOAT8 NULL,
| energy FLOAT8 NULL
| ) TAGS (
| meter_id VARCHAR(50) NOT NULL ) PRIMARY TAGS(meter_id)
| retentions 30d
| activetime 1d
| partition interval 10d
(1 row)
Time: 125.359513ms
root@192.168.150.135:26257/banjin_tsdb_par> show create table meter_data3;
table_name | create_statement
--------------+-------------------------------------------------------------
meter_data3 | CREATE TABLE meter_data3 (
| ts TIMESTAMPTZ(3) NOT NULL,
| voltage FLOAT8 NULL,
| current FLOAT8 NULL,
| power FLOAT8 NULL,
| energy FLOAT8 NULL
| ) TAGS (
| meter_id VARCHAR(50) NOT NULL ) PRIMARY TAGS(meter_id)
| retentions 864000s
| activetime 20d DICT ENCODING
| partition interval 2d
(1 row)
Time: 127.519057ms时序表必须创建在时序库里,当在关系库创建时序表时报错如下
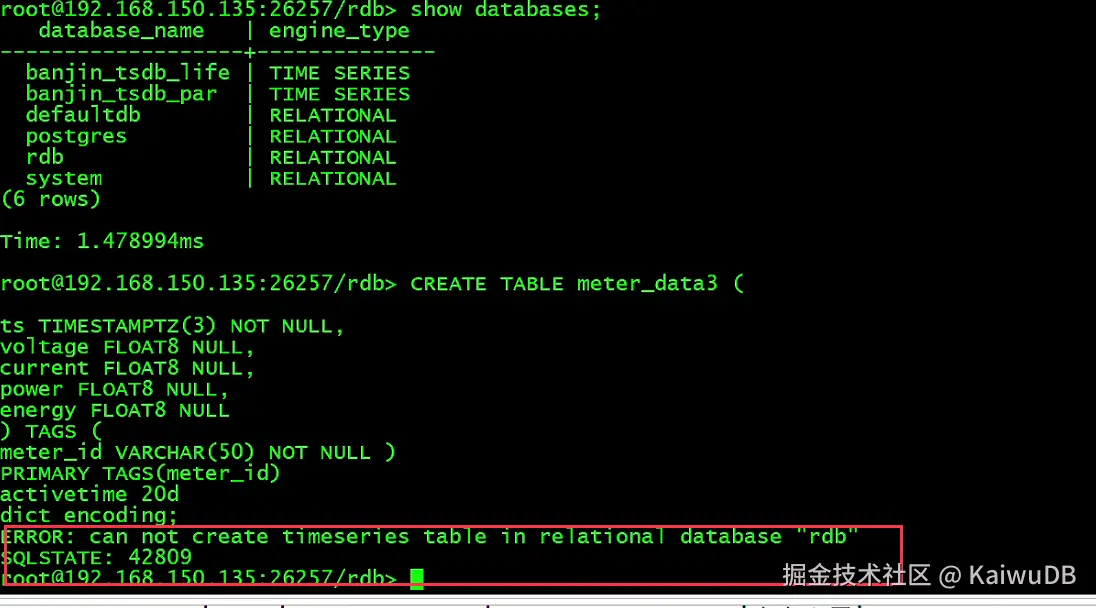
2)时序表修改
语法格式:
sql
ALTER TABLE <table_name>
[ADD [COLUMN] [IF NOT EXISTS] <colunm_name> <data_type> [DEFAULT <expr> | NULL ]
|ADD [TAG | ATTRIBUTE] <tag_name> <tag_type>
|ALTER [COLUMN] <colunm_name> [SET DATA] TYPE <new_type> [SET DEFAULT <default_expr> | DROP DEFAULT ]
|ALTER [TAG | ATTRIBUTE] <tag_name> [SET DATA] TYPE <new_type>
|DROP [COLUMN] [IF EXISTS] <colunm_name>
|DROP [TAG | ATTRIBUTE] <tag_name>
|RENAME TO <new_table_name>
|RENAME COLUMN <old_name> TO <new_name>
|RENAME [TAG | ATTRIBUTE] <old_name> TO <new_name>
|SET [RETENTIONS = <keep_duration> | ACTIVETIME = <active_duration> | PARITITION INTERVAL = <interval>]];一些时序表特有示例
更多修改用例可参考官网:www.kaiwudb.com/kaiwudb_doc...
sql
-- 修改表的生命周期。
ALTER TABLE ts_table SET RETENTIONS = 20d;
-- 修改表数据的活跃时间。
ALTER TABLE ts_table SET ACTIVETIME = 20d;
-- 修改表数据目录分区的时间范围。
ALTER TABLE ts_table SET PARTITION INTERVAL = 2d;
-- 新增标签。
ALTER TABLE ts_table ADD TAG color VARCHAR(30);
-- 删除标签。
ALTER TABLE ts_table DROP TAG color;
-- 修改标签名。
ALTER TABLE ts_table RENAME TAG site TO location;
-- 修改标签的宽度。
ALTER TABLE ts_table ALTER color TYPE VARCHAR(50);3)时序表查询
sql
#查看当前数据库下所有表
SHOW TABLES;
#查看特定数据库下的所有表
SHOW TABLES FROM tablename;
#查看表的详细介绍及创建语句
SHOW CREATE TABLE tablename;
SHOW CREATE TABLE database.tablename;
sql
root@192.168.150.135:26257/banjin_tsdb_par> show tables;
table_name | table_type
--------------+--------------------
meter_data1 | TIME SERIES TABLE
meter_data2 | TIME SERIES TABLE
meter_data3 | TIME SERIES TABLE
(3 rows)
Time: 2.194141ms
root@192.168.150.135:26257/banjin_tsdb_par> show create meter_data2;
table_name | create_statement
--------------+-------------------------------------------------------------
meter_data2 | CREATE TABLE meter_data2 (
| ts TIMESTAMPTZ(3) NOT NULL,
| voltage FLOAT8 NULL,
| current FLOAT8 NULL,
| power FLOAT8 NULL,
| energy FLOAT8 NULL
| ) TAGS (
| meter_id VARCHAR(50) NOT NULL ) PRIMARY TAGS(meter_id)
| retentions 30d
| activetime 1d
| partition interval 10d
(1 row)
Time: 128.253929ms三、KWDB的跨模查询
跨模查询是一种用于在不同类型数据库之间检索相关联数据的查询技术。它允许用户在例如关系数据库和时序数据库等不同类型的数据库系统间,查找和获取相关的数据。
可以使用SampleDB来直接体验跨模查询,SampleDB 是一个用于展示示例数据与场景的项目。其核心目标是助力用户快速掌握 KWDB 数据库的使用方法,为用户提供便捷的测试与学习环境,SampleDB数据库模型是一个智能电表项目,包含关系库rdb和时序库tsdb,提供了关系表和时序表的表结构及数据,还提供了很多用例
下载后上传服务器解压
bash
mkdir cd /var/lib/kaiwudb/extern
#上传rdb.tar.gz,tsdb.tar.gz到此目录
cd /var/lib/kaiwudb/extern
tar xvf rdb.tar.gz
tar xvf tsdb.tar.gz导入关系库 rdb 数据
arduino
import database csv data ("nodelocal://1/rdb");
sql
#登录
kwbase sql --certs-dir=/etc/kaiwudb/certs --host=192.168.150.135
#导入
import database csv data ("nodelocal://1/rdb");
root@192.168.150.135:26257/defaultdb> import database csv data ("nodelocal://1/rdb");
job_id | status | fraction_completed | rows | abandon_rows | reject_rows | note
----------------------+-----------+--------------------+------+--------------+-------------+-------
1073655494850838529 | succeeded | 1 | 305 | 0 | 0 | None
(1 row)
Time: 157.913643ms
#验证 --切换rdb数据库登录
root@192.168.150.135:26257/defaultdb> use rdb;
SET
Time: 403.717µs
root@192.168.150.135:26257/rdb> show tables;
table_name | table_type
--------------+-------------
alarm_rules | BASE TABLE
area_info | BASE TABLE
meter_info | BASE TABLE
user_info | BASE TABLE
(4 rows)导入时序库 tsdb 数据
arduino
import database csv data ("nodelocal://1/tsdb");
sql
#导入
root@192.168.150.135:26257/rdb> import database csv data ("nodelocal://1/tsdb");
job_id | status | fraction_completed | rows | abandon_rows | reject_rows | note
---------+-----------+--------------------+-------+--------------+-------------+-------
- | succeeded | 1 | 10100 | 0 | 0 | None
(1 row)
Time: 526.048817ms
root@192.168.150.135:26257/rdb> \q
#切换tsdb数据库
root@192.168.150.135:26257/defaultdb> use rdb;
SET
Time: 403.717µs
root@192.168.150.135:26257/tsdb> show tables;
table_name | table_type
-------------+--------------------
meter_data | TIME SERIES TABLE
(1 row)
Time: 1.576363ms场景实例
arduino
import database csv data ("nodelocal://1/tsdb");
sql
#导入
root@192.168.150.135:26257/rdb> import database csv data ("nodelocal://1/tsdb");
job_id | status | fraction_completed | rows | abandon_rows | reject_rows | note
---------+-----------+--------------------+-------+--------------+-------------+-------
- | succeeded | 1 | 10100 | 0 | 0 | None
(1 row)
Time: 526.048817ms
root@192.168.150.135:26257/rdb> \q
#切换tsdb数据库
root@192.168.150.135:26257/defaultdb> use rdb;
SET
Time: 403.717µs
root@192.168.150.135:26257/tsdb> show tables;
table_name | table_type
-------------+--------------------
meter_data | TIME SERIES TABLE
(1 row)
Time: 1.576363ms场景实例
告警检测查询
ini
SELECT
md.meter_id,
md.ts,
ar.rule_name,
md.voltage,
md.current,
md.power
FROM tsdb.meter_data md --时序表
JOIN rdb.alarm_rules ar ON 1=1 --关系表
WHERE (ar.metric = 'voltage'
AND ((ar.operator = '>' AND md.voltage < ar.threshold)
OR (ar.operator = '<' AND md.voltage > ar.threshold)))
OR (ar.metric = 'current' AND md.current > ar.threshold)
OR (ar.metric = 'power' AND md.power > ar.threshold)
ORDER BY md.ts DESC
LIMIT 100;
rust
root@192.168.150.135:26257/banjin_tsdb_par> SELECT
-> md.meter_id,
-> md.ts,
-> ar.rule_name,
-> md.voltage,
-> md.current,
-> md.power
-> FROM tsdb.meter_data md
-> JOIN rdb.alarm_rules ar ON 1=1
-> WHERE (ar.metric = 'voltage'
-> AND ((ar.operator = '>' AND md.voltage < ar.threshold)
-> OR (ar.operator = '<' AND md.voltage > ar.threshold)))
-> OR (ar.metric = 'current' AND md.current > ar.threshold)
-> OR (ar.metric = 'power' AND md.power > ar.threshold)
-> ORDER BY md.ts DESC
-> LIMIT 100;
meter_id | ts | rule_name | voltage | current | power
-----------+-------------------------------+-----------+---------+---------+--------
M2 | 2025-04-08 08:47:24.22+00:00 | 高压告警 | 221 | 5.1 | 1050
M2 | 2025-04-08 08:47:24.22+00:00 | 低压告警 | 221 | 5.1 | 1050
M2 | 2025-04-08 08:42:35.898+00:00 | 高压告警 | 221 | 5.1 | 1050
.........
M26 | 2025-04-08 04:47:24.22+00:00 | 低压告警 | 225 | 6 | 1250
M26 | 2025-04-08 04:47:24.22+00:00 | 高压告警 | 225 | 6 | 1250
M26 | 2025-04-08 04:42:35.898+00:00 | 低压告警 | 225 | 6 | 1250
M26 | 2025-04-08 04:42:35.898+00:00 | 高压告警 | 225 | 6 | 1250
(100 rows)
Time: 107.937794ms区域用电量top10
vbnet
SELECT
a.area_name,
SUM(md.energy) AS total_energy
FROM tsdb.meter_data md --时序表
JOIN rdb.meter_info mi ON md.meter_id = mi.meter_id --关系表
JOIN rdb.area_info a ON mi.area_id = a.area_id
GROUP BY a.area_name
ORDER BY total_energy DESC
LIMIT 10;
sql
root@192.168.150.135:26257/tsdb> SELECT
-> a.area_name,
-> SUM(md.energy) AS total_energy
-> FROM tsdb.meter_data md
-> JOIN rdb.meter_info mi ON md.meter_id = mi.meter_id
-> JOIN rdb.area_info a ON mi.area_id = a.area_id
-> GROUP BY a.area_name
-> ORDER BY total_energy DESC
-> LIMIT 10;
area_name | total_energy
------------+---------------
Area 2 | 5.556e+06
Area 1 | 5.55499e+06
Area 100 | 5.55398e+06
Area 99 | 5.55297e+06
Area 98 | 5.55196e+06
Area 97 | 5.55095e+06
Area 96 | 5.54994e+06
Area 95 | 5.54893e+06
Area 94 | 5.54792e+06
Area 93 | 5.54691e+06
(10 rows)
Time: 21.137013msKWDB 跨模查询支持的详细项:
KWDB 跨模查询支持以下关联查询:
-
内连接(INNER JOIN)
-
左连接(LEFT JOIN)
-
右连接(RIGHT JOIN)
-
全连接(FULL JOIN)
KWDB 跨模查询支持以下嵌套查询:
-
相关子查询(Correlated Subquery):内部查询依赖于外部查询的结果,每次外部查询的都触发内部查询的执行。
-
非相关子查询(Non-Correlated Subquery):内部查询独立于外部查询,只执行一次内部查询并返回固定的结果。
-
相关投影子查询(Correlated Scalar Subquery): 内部查询依赖于外部查询的结果,并且只返回一个单一的值作为外部查询的结果。
-
非相关投影子查询(Non-Correlated Scalar Subquery):内部查询独立于外部查询,并且只返回一个单一的值作为外部查询的结果。
-
FROM 子查询:将一个完整的 SQL 查询嵌套在另一个查询的 FROM 子句中,作为临时表格使用。
KWDB 跨模查询支持以下联合查询:
-
UNION:合并多个查询结果集,并去除重复行。
-
UNION ALL:合并多个查询结果集,但不去除重复行。
-
INTERSECT:返回两个查询结果集中都存在的所有行,去除重复行。
-
INTERSECT ALL:返回两个查询结果集中都存在的所有行,但不去除重复行。
-
EXCEPT:返回第一个查询结果集中不包含在第二个结果集中的行,去除重复行。
-
EXCEPT ALL:返回第一个查询结果集中不包含在第二个结果集中的行,不去除重复行。
四、时序特性的注意事项
1、当一个时序数据库指定了生命周期或分区时间范围时,单独指定或者修改数据库内某一时序表的生命周期或分区时间范围时,该配置只适用于该时序表。所以在如果表生命周期或分区时间范围在使用时如果不符合设定,要检查表的生命周期或分区时间范围是否单独设置了
2、生命周期的配置不适用于当前分区(指定表数据目录分区的时间范围的表分区)。当生命周期的取值小于分区时间范围的取值时,即使数据库的生命周期已到期,由于数据存储在当前分区中,用户仍然可以查询数据。当时间分区的所有数据超过生命周期时间点(now() - retention time)时,系统尝试删除该分区的数据。如果此时用户正在读写该分区的数据,或者系统正在对该分区进行压缩或统计信息处理等操作,系统无法立即删除该分区的数据。系统会在下一次生命周期调度时再次尝试删除数据(默认情况下,每小时调度一次)。
3、数据库生命周期和分区时间范围的设置与系统的存储空间密切相关。生命周期越长,分区时间范围越大,系统所需的存储空间也越大。