大家好,这里是架构资源栈 !点击上方关注,添加"星标",一起学习大厂前沿架构!
关注、发送C1即可获取JetBrains全家桶激活工具和码!
Java 自带的 Arrays.hashCode(byte[]) 方法已经存在多年,是不少开发者生成哈希值的首选工具。但 Dynatrace 的研究人员最近发现,即使不使用任何原生代码,仅靠 Java 自身的手段,也能写出 性能更强的版本,甚至超过了 OpenJDK 24 的"底层优化"实现。

Java 原版 hashCode 的瓶颈在哪?
从 JDK 1.5 起,Arrays.hashCode(byte[]) 的逻辑其实非常朴素:
java
static int hashCode(byte[] b) {
if (b == null) return 0;
int h = 1;
for (byte q : b) {
h = 31 * h + q;
}
return h;
}这是经典的「乘 31 加元素」的哈希递推式。但问题在于:逐字节地串行处理,几乎没有编译器优化空间。
为此,研究者参考了 Daniel Lemire 提出的"更快的哈希技巧",通过手动展开循环和**并行处理(SWAR & SIMD)**两种方式,大幅加速了这一过程。
实测结果:比 OpenJDK 本身还快
他们在 AWS 的 c5.metal 实例上,基于 OpenJDK 24.0.1,对不同实现版本做了对比测试,包含:
- Java 默认实现
- OpenJDK 自带 Intrinsic 实现(SIMD 加速)
- 手动展开的 Java 循环
- 全新 SWAR 实现(寄存器并行)
- 全新 SIMD 实现(Java Vector API)
测试逻辑基于 JMH,每组包含 1 万个随机长度的 byte[] 数组。结果显示:
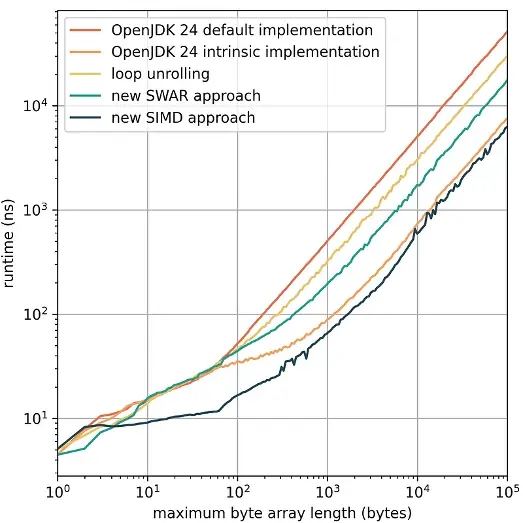
🔥 SWAR 实现比默认版本快 2.9 倍 🚀 SIMD 版本甚至超越了 OpenJDK 的底层 intrinsic 实现
优化一:SWAR(寄存器内并行)技术
SWAR(SIMD Within A Register)指的是在一个寄存器内部,完成多个小数据单元的并行操作。
核心思路:
- 每次读取 8 个字节,打包成一个
long(64 位) - 通过位运算和掩码,在这个
long上并行执行加、乘等运算 - 避免负数处理的溢出问题:给每个 byte +128,再统一做减法修正
示例代码:
java
long x = getLong(b, k) ^ 0x8080808080808080L;
x = 31 * (x & 0x00FF00FF00FF00FFL) + ((x >>> 8) & 0x00FF00FF00FF00FFL);
x = P2 * (x & 0x0000FFFF0000FFFFL) + ((x >>> 16) & 0x0000FFFF0000FFFFL);
h = P8 * h + P4 * (int) x + (int) (x >>> 32) + U;这段代码里用到了大量"无进位"运算技巧,将四组 byte 同时处理成中间结果,有效利用了 CPU 运算资源。
最终 SWAR 实现如下:
java
static int hashCodeSWAR(byte[] b) {
if (b == null) return 0;
if (b.length == 0) return 1;
if (b.length == 1) return 31 + b[0];
int h = 1;
int k = 0;
for (; k <= b.length - 8; k += 8) {
long x = getLong(b, k) ^ 0x8080808080808080L;
x = 31 * (x & 0x00FF00FF00FF00FFL) + ((x >>> 8) & 0x00FF00FF00FF00FFL);
x = P2 * (x & 0x0000FFFF0000FFFFL) + ((x >>> 16) & 0x0000FFFF0000FFFFL);
h = P8 * h + P4 * (int) x + (int) (x >>> 32) + U;
}
return finalize(h, b, k);
}优化二:Java SIMD(向量化 API)实现
Java 从 JDK 16 起提供了 Vector API,用来显式操作 SIMD 指令。
他们使用 Vector API,直接在 Java 层实现了一版 SIMD 版本的哈希计算,比 OpenJDK intrinsic 还快!
实现亮点:
- 使用 Vector API 加载 byte\[\]
- 先 reinterpret 为
short做无符号加法 - 再 reinterpret 为
int执行 31 的乘法链 - 最终通过向量归约计算出哈希结果
示例代码:
java
var s = ByteVector.fromArray(ByteVector.SPECIES_PREFERRED, b, k)
.lanewise(XOR, (byte) 0x80)
.reinterpretAsShorts();
var i = s.and((short) 0xFF)
.mul((short) 31)
.add(s.lanewise(LSHR, 8))
.reinterpretAsInts();
a = a.add(i.and(0xFFFF).mul(P2).add(i.lanewise(LSHR, 16)));最后的修正:
java
int h = (1 + a.mul(W).reduceLanes(ADD)) * F[remaining];其中 F[] 是为了解决补零后 hash 值偏差而预先计算的逆元数组。
总结:JDK 自带的 hashCode 实现并不够快!
这篇文章提供了两个高性能替代方案:
| 实现方式 | 优势 |
|---|---|
| SWAR | 无需依赖 SIMD,纯寄存器级并行操作 |
| SIMD + Vector API | 完全基于 Java Vector API,性能超越 Intrinsic 实现 |
👉 项目源码地址 : github.com/dynatrace-r...

如果你在做大量 byte[] 处理(如网络协议、缓存键、文件分片哈希等),不妨试试这些优化方式。你会惊喜地发现,Java 的性能天花板,其实还可以再抬高一点。
原文地址:mp.weixin.qq.com/s/CZWiGU_4F...
本文由博客一文多发平台 OpenWrite 发布!