1. TCP 四次挥手的第三次挥手后,主动关闭的一方会有一个TIME-WAIT的状态?
TIME-WAIT 状态出现在主动关闭连接的一方,通常是客户端。原因是:当主动关闭方发送完最后一个 ACK(对被动关闭方的 FIN 的确认)后,它必须进入 TIME-WAIT 状态并等待 2 个最大报文生存时间(2MSL)。
目的:
- 保证对方收到最后一个 ACK。如果对方因为 ACK 丢失而重发 FIN,TIME-WAIT 方还能重新发 ACK。
- 防止旧连接中的延迟数据包影响后续新的连接。保证同一个四元组(源 IP、源端口、目标 IP、目标端口)后续不会有冲突。
如果服务器需要长时间保持大量短连接,TIME-WAIT 太多可能会占用端口资源,所以有些服务端会通过调节内核参数来复用 TIME-WAIT 或选择由服务端被动关闭。
2. 被动关闭连接的一方无法正常关闭会有什么问题吗?
如果被动关闭方没正常关闭,连接就会一直停留在 CLOSE-WAIT 状态,导致占用文件描述符和端口等系统资源,时间长了会堆积大量 CLOSE-WAIT,可能耗尽资源,影响新连接,严重拖垮服务,根本原因一般是应用层没有正确调用 close() 释放 socket。
3. TCP拥塞控制和流量控制,说一下?
TCP 的流量控制是为了防止发送方把数据发得太快,让接收方处理不过来,主要依赖接收窗口和滑动窗口机制:接收方会在每个 ACK 里告诉发送方自己还能接收多少字节,发送方根据这个窗口大小来控制数据发送量。滑动窗口则保证了即使有部分数据还没被确认,也能连续发送,提高链路,利用率。
而拥塞控制是防止整个网络过载,导致丢包和延迟。TCP 拥塞控制包括四个主要算法:先是慢启动,刚开始发送窗口很小,每收到确认就指数增长,快速探测可用带宽;当达到慢启动阈值后,进入拥塞避免阶段,改为线性增长以防过快导致拥塞;一旦检测到丢包,比如收到了 3 个重复 ACK,就触发快重传,立即重发丢失的数据包,不等超时;重传后采用快恢复,把拥塞窗口减半而不是回到最小值,然后继续拥塞避免,保证网络恢复得更快。
4. 如果接收方接收能力不够,导致 TCP 首部里标识的滑动窗口大小不断减小,如果窗口减小到0,那怎么重新开始呢?
在 TCP 中,如果接收方处理数据的能力跟不上,可能会把接收窗口(rwnd)不断减小,甚至降到 0,表示自己当前缓冲区已满,请发送方暂停发送数据。此时发送方必须停止发送新的数据段,以免引起丢包和资源浪费。但是如果一直不管,就会产生死锁(死等)。因此 TCP 设计了持续计时器(Persist Timer)机制:当发送方收到窗口为 0 的通知后,会启动这个计时器,定期发送"窗口探测报文段(Zero Window Probe)",去探测接收方是否已经腾出了新的缓冲区。如果接收方缓冲区空出来了,就会在探测报文的 ACK 中告诉发送方新的窗口大小,当发送方检测到窗口大于 0,就可以恢复正常的数据传输。所以即使窗口关闭,也能保证连接活跃且不死锁,这就是流量控制里防止零窗口死锁的一个重要机制。
5. 高并发的场景下怎么保证数据库和缓存一致性?
最常见的方案是:先更新数据库,再删除缓存。这样可以避免先删缓存再更新数据库时,可能出现的并发脏写覆盖。但即使这样,也会遇到并发下缓存被错误回写的问题,比如 A 线程读到旧值后,B 线程更新了数据库并删了缓存,这时 A 线程把旧值又写回缓存,就会导致短时间的数据不一致。
为了解决这一问题,常见做法有三点:
- 用延迟双删策略,在更新数据库后先删除缓存,再延迟一小段时间(比如几百毫秒)再删一次缓存,尽量避免脏数据被回写。
- 对热点 key 加分布式锁或用原子操作,确保同一个 key 的读写串行化,防止并发写入时覆盖。
- 如果一致性要求极高,比如订单、支付等场景,可以通过 Binlog 或 Canal 监听数据库变更,然后异步刷新或重建缓存,做到最终一致性。
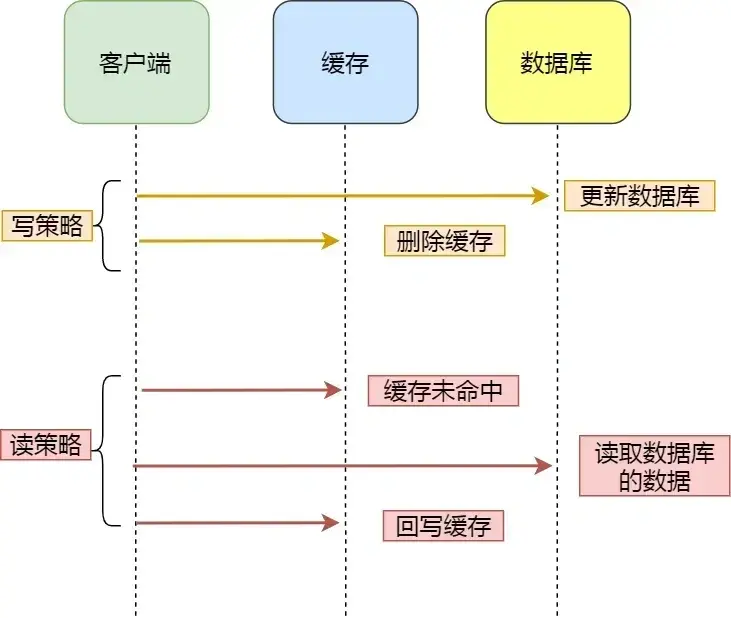
在高并发场景下,为了保证数据库和缓存的一致性,我会把写库操作和缓存更新解耦,用消息队列来做异步更新:先写数据库成功后,发送一条变更消息到消息队列,然后由多线程消费者去消费这条消息,读取最新的数据库值写回缓存,同时配合分布式锁保证同一份数据在同一时刻只会被一个线程更新缓存,避免并发覆盖的问题,这样可以提升吞吐量、减少写库时的阻塞,并且在极端场景下还可以结合延迟双删或定时任务做兜底修正,最终保证缓存和数据库的一致性。
6. 消息队列的可靠性、顺序性怎么保证?
消息队列的可靠性和顺序性可以通过多种机制保证。可靠性方面,常用的做法有:生产者发送消息时开启确认机制(ACK),确保消息成功写入队列;队列自身支持持久化(比如 Kafka 会把消息写到磁盘,并且有副本机制),即使节点宕机也不丢;消费者消费时也需要幂等性处理和ACK确认,避免消息丢失或重复消费。
顺序性方面,比如在 Kafka 里,通过分区(Partition)+ 有序写入保证同一分区内消息是有序的;如果业务对顺序有严格要求,可以把同一业务 Key 的消息发到同一个分区,并且消费者单线程消费这个分区,就能保证顺序一致性。不过顺序性和并发吞吐是矛盾的,要结合实际业务场景做权衡,比如热点 Key 可能造成顺序消费的单点瓶颈,需要拆分 Key 或做分区扩容。