目录
[import 与 from...import使用](#import 与 from...import使用)
[Numpy 对象](#Numpy 对象)
Python 是一种解释型、面向对象、动态数据类型的高级程序设计语言。
易于学习 :Python有相对较少的关键字,结构简单,和一个明确定义的语法,学习起来更加简单。
易于维护 :Python的成功在于它的源代码是相当容易维护的。
一个广泛的标准库 :Python的最大的优势之一是丰富的库,跨平台的: Windows 、 Linux 和 Mac OS X 。
可扩展 :如果你需要一段运行很快的关键代码,或者是想要编写一些不愿开放的算法,你可以使用C或C++完成那
部分程序,然后从你的Python程序中调用。
...
教程:
Python 官网: https://www.python.org/
文档 : https://www.python.org/doc/
Python3: https://www.runoob.com/python3/python3-install.html
Python2: https://www.runoob.com/python/python-tutorial.html
Python2与Python3区别: https://www.zhihu.com/question/19698598
Python IDE(集成开发环境):一种改进代码创建、测试和 debug 流程的工具
基础语法
版本查看: python --v 或者 python ---version
注释: Python中单行注释以 #开头,多行可以用#也可以用''' 和 """
行与缩进: python最具特色的就是使用缩进来表示代码块,不需要使用大括号 {}
多行语句 :一行语句换行使用\,在 \[\], {}, 或 () 中的多行语句,不需要使用反斜杠 \
数字类型: python中数字有四种类型:整数、布尔型、浮点数和复数
字符串: python中单引号和双引号使用完全相同
输出: print 默认输出是换行的,如果要实现不换行需要在变量末尾加上 end="":
import 与 from...import使用
• 在 python 用 import 或者 from...import 来导入相应的模块。
• 将整个模块(somemodule)导入,格式为: import somemodule
• 从某个模块中导入某个函数,格式为: from somemodule import somefunction
• 从某个模块中导入多个函数,格式为: from somemodule import firstfunc, secondfunc, thirdfunc
• 将某个模块中的全部函数导入,格式为: from somemodule import *
Python3 中有六个标准的数据类型:
Number(数字)
String(字符串)
List(列表):
• Python 中使用最频繁的数据类型
Tuple(元组)
Set(集合)
Dictionary(字典):
• Python中另一个非常有用的内置数据类型
• 创建空字典使用 { }
• 字典是一种映射类型,字典用 { } 标识,它是一个无序的 键(key) : 值(value) 的集合
• 在同一个字典中,键(key)必须是唯一的
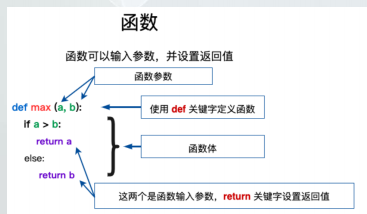
函数
• 函数代码块以 def 关键词开头,后接函数标识符名称和圆
括号 ()。
• 任何传入参数和自变量必须放在圆括号中间,圆括号之间
可以用于定义参数。
• 函数的第一行语句可以选择性地使用文档字符串---用于存
放函数说明。
• 函数内容以冒号 : 起始,并且缩进。
• return 表达式 结束函数,选择性地返回一个值给调用
方,不带表达式的 return 相当于返回 None
File
open() 方法用于打开一个文件,并返回文件
对象
open() 函数常用形式是接收两个参数:文件
名(file)和模式(mode)
例:open(file, mode='r')
面向对象-类与对象
类:是一组相关属性和方法的集合。可以看成是一类事物的模板,使用事物
的属性特征和方法特征来描述该类事物
属性:就是该事物的状态信息。
方法:就是该事物能够做什么。
对象:是一类事物的具体体现。对象是类的一个实例(对象并不是找个女朋
友),必然具备该类事物的属性和方法
类是对一类事物的描述,是抽象的。
对象是一类事物的实例,是具体的。
类是对象的模板,对象是类的实体
面向对象-封装与继承
什么是封装?
装:将一大堆名字装到一个容器中
封:隐藏起来 对内公开对外隐藏
什么是继承
继承是一种新建类的方式,继承的类称之为子类或派生类
被继承的类称之为父类或基类或超类
子类继承父类,也就意味着子类继承了父类所有的属性和方法
可以直接调用
为什么要有继承
减少代码冗余
Numpy
功能十分强大的 python 扩展库,数学库,主要用于数组计算。
Numpy****对象
N 维数组对象 ndarray ,它是一系列同类型数据的集合,以 0 下标为开始进行集合中元素的索引
ndarray 中的每个元素在内存中都有相同存储大小的区域
ndarray 内部由以下内容组成:
一个指向数据(内存或内存映射文件中的一块数据)的指针
数据类型或 dtype ,描述在数组中的固定大小值的格子
一个表示数组形状( shape )的元组,表示各维度大小的元组
一个跨度元组( stride ),其中的整数指的是为了前进到当前维度下一个元素需要 " 跨过 " 的字
节数
Numpy****创建
numpy.array 构造器来创建
# order:创建数组的样式,C为行方向,F为列方向,A为任意方向
numpy.array(object, dtype = None, copy = True, order = None, subok = False,
ndmin = 0)
#例:
a = np.array([1,2,3])
a = np.array([[1, 2], [3, 4]]) #两个维度2x2
a = np.array([1, 2, 3], dtype = complex) #复数
#order - "C"和"F"两个选项,分别代表,行优先和列优先,在计算机内存中的存储元素的顺序。
numpy.empty(shape, dtype = float, order = 'C')
#例:
x = np.empty([3,2], dtype = int)
numpy.zeros(shape, dtype = float, order = 'C')
#例:
y = np.zeros((5,), dtype = np.int)
numpy.ones(shape, dtype = None, order = 'C')
#例:
x = np.ones([2,2], dtype = int)
#根据 start 与 stop 指定的范围以及 step 设定的步长,dtype数据类型生成ndarray
numpy.arange(start, stop, step, dtype)
#例:
x = np.arange(10,20,2)
x = np.arange(5)Numpy****索引
通过冒号分隔切片参数 start:stop:step 来进行切片操作。
切片还可以包括省略号 ... ,来使选择元组的长度与数组的维度相同。 如果在行位置使用省略号,它
将返回包含行中元素的 ndarray 。
a = np.array(\[1,2,3,3,4,5,4,5,6])
print(a)
从某个索引处开始切割
print('从数组索引 a1: 处开始切割')
print(a1:)
print (a...,1) # 第2列元素
print (a1,...) # 第2行元素
print (a...,1:) # 第2列及剩下的所有元素
Numpy 常用操作
numpy.reshape 函数可以在不改变数据的条件下修改形状
numpy.reshape(arr, newshape, order='C')
#例:
a = np.arange(8)
print ('原始数组:')
print (a)
print ('\n')
b = a.reshape(4,2)
print ('修改后的数组:')
print (b)
numpy.transpose(arr, axes)
#例:
import numpy as np
a = np.arange(12).reshape(3,4)
print ('原数组:')
print (a )
print ('\n')
print ('对换数组:')
print (np.transpose(a))
numpy.squeeze(arr, axis)
#例:
x = np.arange(9).reshape(1,3,3)
print ('数组 x:')
print (x)
print ('\n')
y = np.squeeze(x)
print ('数组 y:')
print (y)
print ('\n')
print ('数组 x 和 y 的形状:')
print (x.shape, y.shape)
numpy.concatenate((a1, a2, ...), axis)
#例:
a = np.array([[1,2],[3,4]])
b = np.array([[5,6],[7,8]])
print (np.concatenate((a,b),axis = 1))Tensor****介绍
张量是一种特殊的数据结构,与数组和矩阵非常相似。在 PyTorch 中,我们使用张量来编码模型的
输入和输出,以及模型的参数。
张量可以在 GPU 或其他硬件加速器上运行。
张量和 NumPy 数组通常可以共享相同的底层内存,从而消除了复制数据的需要
张量也对自动微分进行了优化
Tensor****构建
张量可以直接从数据中创建。数据类型是自动推断的
张量可以从 NumPy 数组中创建
从另一个 tensor 创建
随机量或者常量初始化
Tensor****常用操作
张量属性描述它们的形状、数据类型和存储它们的设备
import torch
import numpy as np
data = \[1, 2,3, 4]
x_data = torch.tensor(data)
np_array = np.array(data)
x_np = torch.from_numpy(np_array)
#新张量保留参数张量的属性(形状,数据类型)
x_ones = torch.ones_like(x_data) # 保留x_data的属性
print(f"Ones Tensor: \n {x_ones} \n")
x_rand = torch.rand_like(x_data, dtype=torch.float) # 重写x_data的数据类型
print(f"Random Tensor: \n {x_rand} \n")
shape = (2,3,)#决定了输出张量的维数
rand_tensor = torch.rand(shape)
ones_tensor = torch.ones(shape)
zeros_tensor = torch.zeros(shape)
print(f"Random Tensor: \n {rand_tensor} \n")
print(f"Ones Tensor: \n {ones_tensor} \n")
print(f"Zeros Tensor: \n {zeros_tensor}")
Tensor 常用操作
张量属性描述它们的形状、数据类型和存储它们的设备
tensor = torch.rand(3,4)
print(f"Shape of tensor: {tensor.shape}")
print(f"Datatype of tensor: {tensor.dtype}")
print(f"Device tensor is stored on: {tensor.device}")
# We move our tensor to the GPU if available
if torch.cuda.is_available():
tensor = tensor.to('cuda')
tensor = torch.ones(4, 4)
print('First row: ',tensor[0])
print('First column: ', tensor[:, 0])
print('Last column:', tensor[..., -1])
tensor[:,1] = 0
print(tensor)
t1 = torch.cat([tensor, tensor], dim=1)
print(t1)
t = torch.ones(5)
print(f"t: {t}")
n = t.numpy()
print(f"n: {n}")
tt = torch.from_numpy(n)
print(f"t:{tt}")
# 计算两个张量之间的矩阵乘法。Y1 y2 y3的值是一样的
y1 = tensor @ tensor.T
y2 = tensor.matmul(tensor.T)
y3 = torch.rand_like(tensor)
torch.matmul(tensor, tensor.T, out=y3)
print(f"y1: {y1}")
print(f"y2: {y2}")
print(f"y3: {y3}")
# 它计算元素的乘积。z1 z2 z3的值是一样的
z1 = tensor * tensor
z2 = tensor.mul(tensor)
z3 = torch.rand_like(tensor)
torch.mul(tensor, tensor, out=z3)
print(f"z1: {z1}")
print(f"z2: {z2}")
print(f"z3: {z3}")