1. RabbitMQ服务介绍
RabbitMQ是Advanced Message Queuing Protocol (AMQP,高级消息队列协议)开放标准的实现,它支持符合标准的客户端请求程序与符合标准的消息中间件代理进行通信。AMQP的模型架构如图1所示:
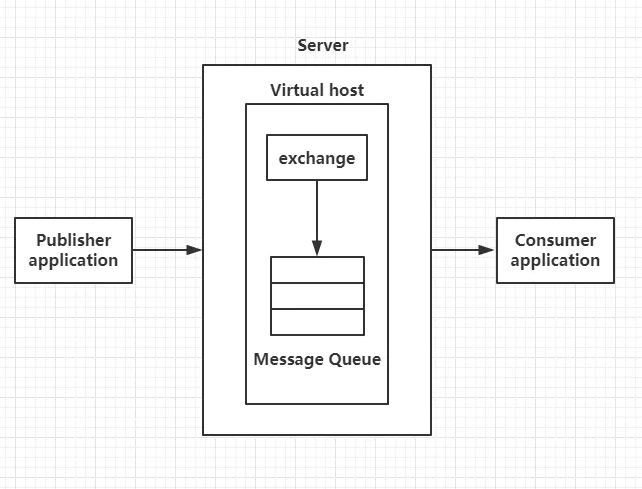
图1 AMQP模型
AMQP中的核心概念:
(1)Broker:消息中间件的服务节点,对于RabbitMQ来说,一个RabbitMQ Broker可以简单地看作一个RabbitMQ服务节点,或者RabbitMQ服务实例;
(2)Virtual Host:虚拟主机,表示一批交换器、消息队列和相关对象。虚拟主机是共享相同的身份认证和加密环境的独立服务器域。每个vhost本质上就是一个mini版的RabbitMQ服务器,拥有自己的队列、交换器、绑定和权限机制;
(3)Producer:生产者,消息投递方,生产者创建消息,然后发布到RabbitMQ中;
(4)Consumer:消费者,就是接收消息的一方,消费者连接到RabbitMQ服务器,并订阅到队列上;
(5)Queue:队列,RabbitMQ的内部对象,用于存储消息,RabbitMQ的生产者生产消息并最终投递到队列中,消费者可以从队列中获取消息并消费;
(6)Exchange:交换器,生产者将消息发送到Exchange,由交换器将消息路由到一个或者多个队列中;
(7)RoutingKey:路由键,生产者将消息发给交换器的时候,一般会指定一个RoutingKey,用来指定这个消息的路由规则,生产者可以在发送消息给交换器时,通过指定RoutingKey来决定消息流向哪里。
2. RabbitMQ在OpenStack中的运用
要了解RabbitMQ在OpenStack中的作用,首先以创建虚拟机为例分析一下消息流程,创建虚拟机的流程如图2所示:
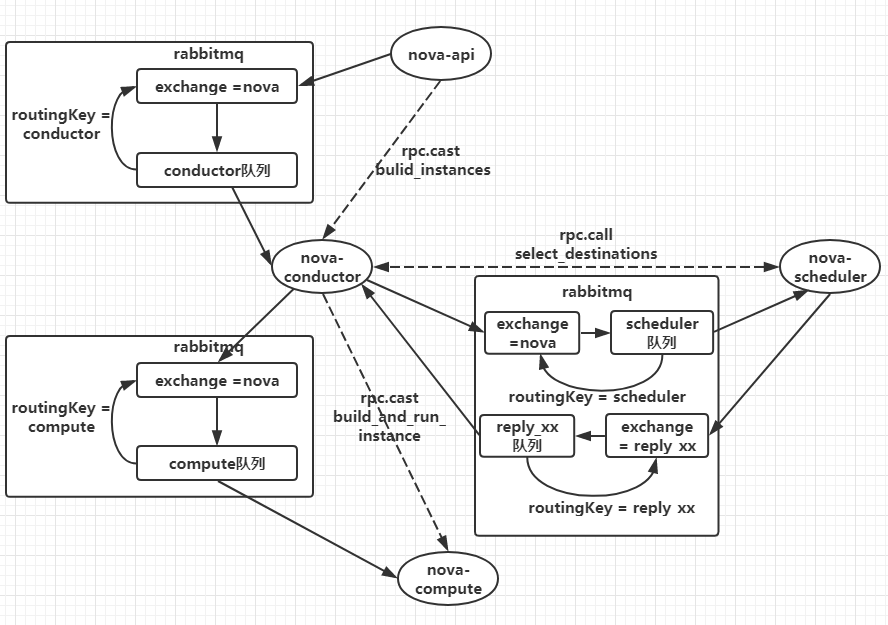
图2 创建虚拟机流程图
从上图能够看出,以nova-api和nova-conductor之间的通信为例,nova-conductor服务在启动时会注册一个RPC server等待处理请求,nova-api发送创建虚拟机的rpc请求时会先创建一个topic publisher用于topic发布,method为build_instance,然后publisher将消息发送给exchange,exchange再根据routingkey转发给绑定的queue中,最后由topic consumer接收并调用nova-conductor manager中的build_instance方法处理,对于nova-conductor和nova-scheduler之间的通信,多了一步把目标主机作为返回结果信息返回到reply_xx队列中,然后由nova-conductor接收以后向nova-compute发起rpc.cast的创建请求。
OpenStack各个组件内部的各个服务进程之间则是通过基于AMPQ的RPC方式进行通信,实现RPC通信需借助Rabbitmq消息队列,RPC方式又分为两种,rpc.cast和rpc.call,rpc.call为request/response方式,多用于同步场景;而使用rpc.cast方式发出请求后则无需一直等待响应,但之后需要定期查询执行结果,一般用于异步场景,OpenStack将其使用的通信方式都封装在公有库oslo_messaging中。
3. RabbitMQ的性能瓶颈
RabbitMQ每增加一个连接,erlang都会给这个连接分配三个erlang进程,每个进程都会分配一定大小内存空间,所以随着连接数的增长,内存和erlang进程数呈现有规律的增长,所以RabbitMQ连接数的无限增大会压垮mq服务,导致RabbitMQ服务崩溃。
客户端与RabbitMQ建立的是长连接,而不是建立短连接,因为如果频繁的建立、销毁connection,会增加额外的时间开销,当业务量比较大时,就会对系统性能产生比较大的影响。OpenStack组件与RabbitMQ的连接使用到了第三方库oslo_message中的connection pool的概念,在不超过pool size的前提上,当有并发业务的时候,如果发现pool中已有connection正被使用,那么就会在pool中继续创建新的connection,直到创建的connection数量达到pool的最大值,之后如果再有业务需要,会等待之前创建的connection被重新放入connection pool,然后等待被继续使用。这种情况下,就会出现connection一直增长的现象。
4. RabbitMQ的优化
在上面的文章中可以看到,RabbitMQ的连接数是压垮消息队列的一个重要的指标。所以在平时使用OpenStack平台的过程中,如果大量的用户同时创建虚拟机,会导致云平台创建报错,其实就是消息队列服务的崩溃。
在优化方面,我们首先想到,是将RabbitMQ服务默认的连接数量改大,修改方法如下:
(1)系统级别修改
使用CRT等远程工具连接到controller节点,然后修改配置文件,编辑/etc/sysctl.conf配置文件,命令如下:
[root@controller ~]# vi /etc/sysctl.conf
fs.file-max=10240
#在sysctl.conf文件的最下方添加一行fs.file-max=10240修改完毕后保存退出并生效配置,命令如下:
[root@controller ~]# sysctl -p
fs.file-max = 10240(2)用户级别修改
用户级别修改,编辑/etc/security/limits.conf配置文件,具体命令如下:
[root@controller ~]# vi /etc/security/limits.conf
openstack soft nofile 10240
openstack hard nofile 10240
#在配置文件的最后添加两行内容如上修改完之后,保存退出。
(3)修改RabbitMQ配置
修改RabbitMQ服务的service配置文件rabbitmq-server.service,具体命令如下:
[root@controller ~]# vi /usr/lib/systemd/system/rabbitmq-server.service
#在[Service]下添加一行参数如下:
LimitNOFILE=10240编辑完之后保存退出,重启RabbitMQ服务,命令如下:
[root@controller ~]# systemctl daemon-reload
[root@controller ~]# systemctl restart rabbitmq-server重启完毕后,查看RabbitMQ的最大连接数,命令如下:
[root@controller ~]# rabbitmqctl status
Status of node rabbit@openstack
...忽略输出...
{file_descriptors,
[{total_limit,10140},
{total_used,53},
{sockets_limit,9124},
{sockets_used,51}]},可以看到当前的RabbitMQ已被修改。