前言
截止目前,本博客内已经陆续解读了physical intelligence公司推出的一系列模型/算法,成了一个大系列,比如
- π0
涉及对其原理的解读、lerobot pi0代码的解析、openpi官方代码的解析,以及我司对其的微调 - FAST
- Hi Robot
- π0.5
- π0.5的KI改进版
这家公司确实因为牛人很多,加之很多又是斯坦福、UC伯克利等高校的副教授/研究员,带了一堆聪明的博士生(要知道,现在具身科研的主力一半都是TOP高校的博士生),所以,使得他们产出很快、很多
这不,在25年6.9日,他们又推出了本文要介绍的实时动作分块技术,使得VLA也可以做点燃火柴、插入网线的高精度任务

由此,证明了,VLA也是可以做高精度任务的,不一定只有RL或RL参与的算法才能做高精度任务
顺带小小感慨一下
- 本博客π0系列的文章 已经十多篇了,搞vla必读
- 而我和我司『七月在线』组织的π0交流群,成员来自各大top985,以及各大科研院所、公司,我们这帮人见证和推动了中国具身的飞跃
且我司也会在中国具身科技发展史上,留下浓墨一笔,期待与更多同行、同仁、工厂多多合作
第一部分
1.1 引言、相关工作、预备知识与动机
1.1.1 引言
如原论文所说,与聊天机器人和图像生成器不同,信息物理系统始终在实时环境下运行。当机器人在"思考"时,其周围的世界会按照物理规律不断变化。因此,输入与输出之间的延迟会对性能产生实际影响
对于语言模型来说,生成速度的快慢意味着用户的满意或不满;而对于机器人动作模型而言,这种差异可能意味着机器人要么把一杯热咖啡递到你手中,要么将其洒在你腿上
不幸的是,现代大规模机器学习的高效性不可避免地伴随着高延迟。LLMs、VLMs,以及VLAs都拥有数十亿个参数 8,29,5,4,57
-
这些模型不仅运行速度慢,而且需要高性能的硬件设备,这些设备很难集成到诸如移动机器人等边缘设备中,从而为远程推理带来了更多的开销。虽然边缘硬件将随着时间推移而提升性能,但随着机器人数据集规模的增长,最先进的VLA模型也会变得更加庞大 27
-
因此,要将大型模型有效应用于实时控制问题,必须采用某种形式的异步机制:也就是说,模型在执行先前动作的同时,需要思考其未来的动作
动作分块 (actionchunking)67,32,11,即模型在每次推理调用时输出并执行一系列多个动作,提供了部分解决方案。尽管动作分块在灵巧操作领域已取得许多最先进的成果5,4,57,但它仍然存在延迟问题
分块会牺牲系统对外部刺激的响应性,并且在分块之间的切换点引入不连续性,因为相邻分块可能会在所学习动作分布的不同模式(或"策略")之间跳变。这类异常对基于学习的系统尤其有害,因为它们会导致动力学分布转移,而模型往往无法应对简单的平滑策略,如将多个预测结果取平均67,并不能保证生成有效的动作,反而可能使问题更加严重(例如,见图2)
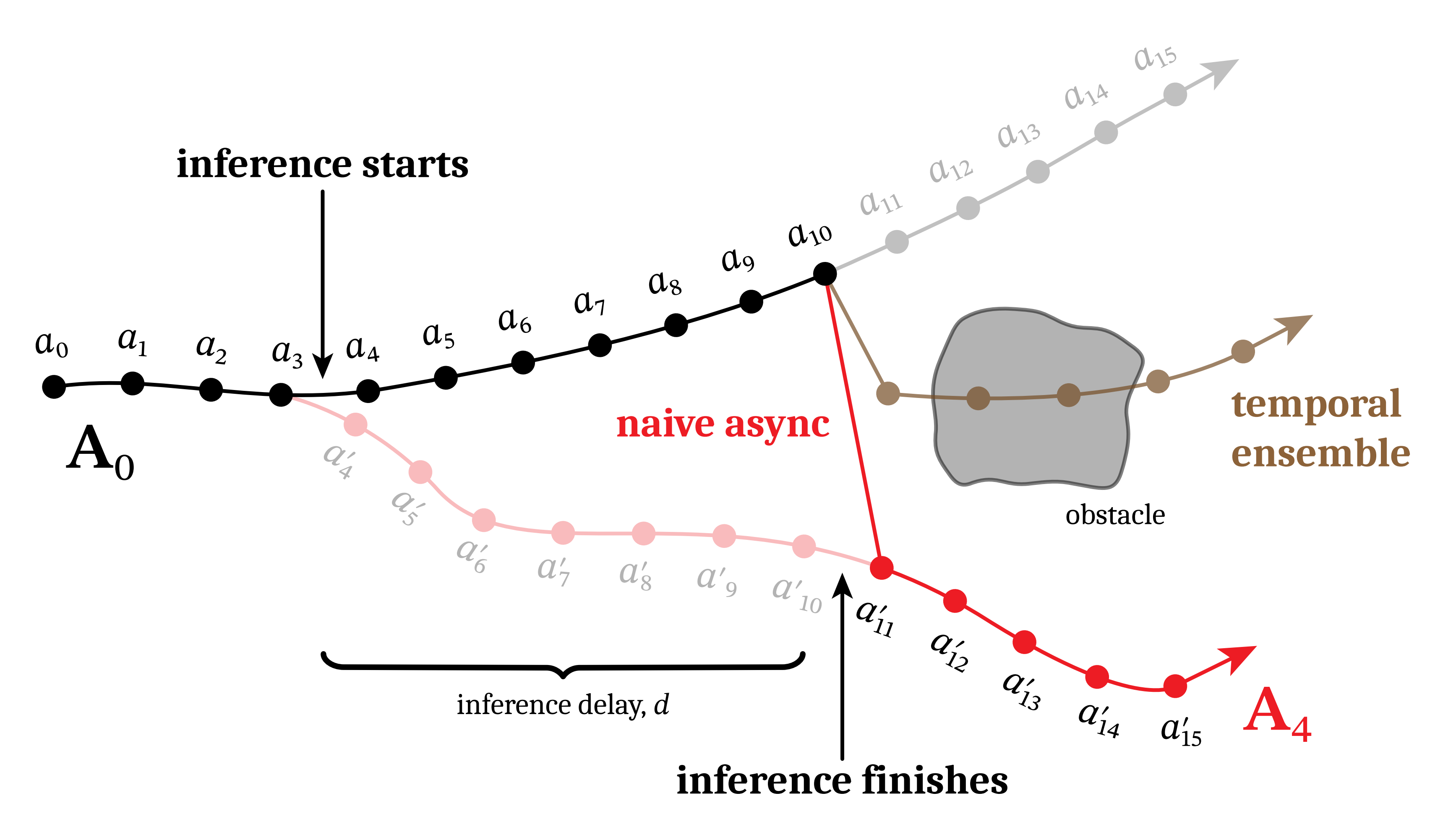
一个优秀的实时系统必须能够生成一致且连续的控制信号,融合最新的观测结果,同时不干扰环境的自然动态或模型产生正确动作的能力
在本研究中,作者提出了实时分块(RTC)方法

- 其对应的paper为:Real-Time Execution of Action Chunking Flow Policies
- 其将异步动作分块建模为一个修补(inpainting)问题
即算法在执行前一个动作块的同时生成下一个动作块,对由于推理延迟而必定被执行的动作进行冻结,并对其余部分进行"修补"
该方法适用于任何基于扩散21或基于流35的可变长度动作(VLA)模型,并且仅在推理阶段运行,无需对现有训练流程进行任何更改
1.1.2 相关工作
第一,对于动作分块与VLA
部分受到人类运动控制的启发32,动作分块近年来已成为视觉运动控制模仿学习领域的事实标准67,11
- 从人类数据中学习生成动作分块需要具有表现力的统计模型,如变分推断67,18、扩散模型11,12,68,67,45,58、流匹配5,6、向量量化方法 33,3,43,或字节对编码 46
- 最近,这些方法中的一些已扩展到数十亿参数,催生了VLA 7,13,29,5,70,10,9,69,23,46,36,即基于预训练视觉-语言模型骨干构建的大型模型类别
由于能够适配不断增长的机器人数据集 13,28,61,14,40,26,以及来自视觉-语言预训练的互联网知识,VLA 在通用机器人操作任务中取得了令人瞩目的成果
第二,对于降低推理延迟
- 提升模型实时性能的一个自然方法就是简单地加快其运行速度
例如,consistency policy 48 通过蒸馏扩散策略来省略昂贵的迭代去噪过程
Streamingdiffusion policy 22 提出了一种替代的训练方法,使每个控制器时间步仅需极少的去噪步骤
Kim 等人 30 通过并行解码增强了 OpenVLA 29,从而省略了昂贵的自回归解码 - 更广泛而言,关于推理速度优化的文献非常丰富,无论是针对扩散模型51,37,55,16 还是大型 Transformer 31,24,34
然而,这些方法都无法将推理成本降到一次前向传播以下。只要这一步前向传播所需时间超过控制器的采样周期,仍需采用其他方法以实现实时执行
第三,对于图像修复与引导
已有大量文献探讨了利用预训练扩散模型和流模型进行图像修复的方法 47,54,39,41
- 在本文介绍的工作中,作者将其中一种方法 47 融入了他们新颖的实时执行框架,并进行了必要的修改(即软掩码和引导权重裁剪),以适应他们的应用场景
- 在序列决策制定方面,Diffuser 25 首次提出了基于扩散的修复方法,用于在长期规划中遵循状态和动作约束,尽管其修复方法并非基于引导
此外,Diffuser 及其他相关工作 63,1 也通过价值函数对扩散模型进行引导,以解决强化学习(RL)问题
作者宣称,他们的工作具有独特性,因为这是首次将修复或引导方法应用于实时控制
第四,对于实时执行
早在VLA出现之前,实时控制就已被广泛研究
-
与动作分块类似,模型预测控制『MPC;50』在递进的时间范围内生成计划;与作者的方法一样,它将执行与计算并行化,并利用前一个分块为下一个规划提供热启动。尽管近期将学习方法与MPC结合的研究已在狭窄领域中展现出实时控制能力52,20,但它们对显式动态模型和代价函数的依赖,使其在非结构化环境下的应用变得困难,而VLA正是在这些领域获得了广泛应用
-
另一方面,在强化学习领域,已有多项研究提出了时延决策方法56,15,53,62,65,66。然而,这些方法并不总能适用于模仿学习,并且都未利用动作分块
巧的是,在25年7月10日前后,RL用到动作分块了,详见下一篇博客的解读 -
最近,分层VLA设计*57,4-GR00T N1*开始出现,将模型划分为System 2(高层规划)和System 1(低层动作生成)两个部分
用于高层规划的System 2组件包含VLA的大部分容量,并以较低频率运行,而用于低层动作生成的System 1组件则轻量且快速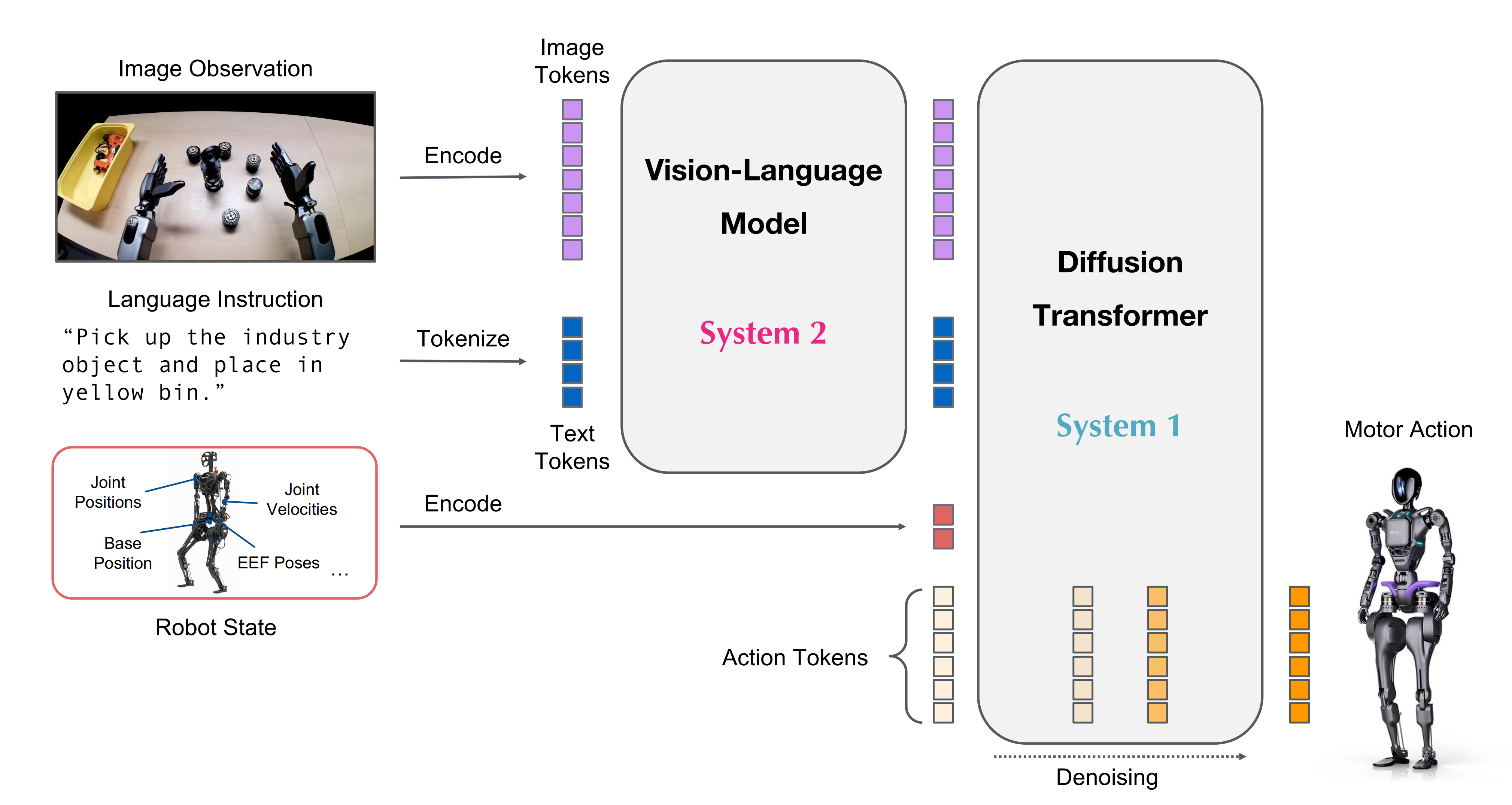
这种方法与本文介绍的方法相互独立,并具有自身的权衡(例如,限制System 1组件的规模并需要其专门的训练方法)
第五,对于双向解码
- 与本研究最为相关的前期工作是双向解码(BID;38),该方法通过拒绝采样,使预训练的动作分块策略能够实现完全闭环控制
尽管Liu等人38未考虑推理延迟,BID算法依然可以用于实现与本文基于引导的修复(inpainting)相同的效果 - 作者在模拟基准测试中将BID与RTC进行了对比,发现BID的性能不如RTC,同时计算资源消耗却显著更高
1.1.3 预备知识与动机
如原论文所述,作者介绍了本工作所涉及的预备知识与动机
-
比如从一个动作分块策略开始,记作
其中
是未来动作的一个分块,
-
当动作分块策略被执行时,每个分块的前
分块执行以牺牲反应性为代价确保了时间一致性。较长的执行视野会降低策略对新信息的响应能力,而较短的执行视野则增加了模式跳跃的可能性,即由于分块间的不连续性导致的动作突变行为
在本文中,作者考虑使用条件流匹配35 训练的策略,尽管他们的方法也可以通过在推理时将扩散策略转换为流策略来使用47, 17
-
为了从流策略中生成一个动作块,首先从标准高斯分布中采样随机噪声
其中现在,令
作者定义 -
如果
然而,使用现代VLA 几乎不可能实现这一点。例如,使用NVIDIA RTX 4090 GPU,参数量为30 亿的π0 VLA 仅在KV 缓存预填阶段就花费了46 ms,这还不包括任何去噪步骤5,而目标控制频率为50Hz (在移动操作的远程推理中,π0 在有线连接的理想条件下,网络延迟为13 ms。在更为现实的环境下,仅网络开销就可能轻松超过20ms
Kim 等人30 专门针对推理速度优化了7B OpenVLA 模型29,但即使在NVIDIA A100 GPU 上,延迟也未能优于321 ms -
当
朴素的同步推理(许多先前工作的默认设置5, 29, 8, 23, 30, 58 )在分块之间引入了明显的停顿,这不仅会减慢执行速度,还会改变机器人的动态特性,从而导致训练与评估之间出现分布偏移
实时系统的首要要求是异步执行,即推理需要提前启动,以保证每个时间步都能有可用的动作
-
令
如果当前正在执行
然而,由于策略在生成
类似于过短的执行时域,这种策略会导致动作不连贯的行为,并且在延迟较高时问题会显著加剧 -
具体参见下图图2,这是连续两个块之间典型分叉的一个示例。推理在第 3 步和第 4 步之间开始。正在执行的原始块 {
一个简单的异步算法可能会从
1.2 基于修补的实时分块
实时执行的关键挑战在于保持各分块之间的连续性
-
当新分块可用时,前一个分块往往已经部分执行,因此新分块必须与前一个分块"兼容"。与此同时,新分块还应当融合新的观测信息,以保证策略不会丧失反应和纠正的能力
作者的关键见解是将实时分块问题视为一次修复(inpainting)问题 -
为了使新分块"兼容",必须利用与前一分块剩余动作重叠的时间步------例如下图的
因此,将这些动作"冻结"为已知会被执行的值是合理的;作者的目标是在保证该冻结前缀一致性的前提下,补全新分块的其余部分( 如上图的a11-a15,如下图图3的a4-a10 ),这类似于修复一幅被移除部分的图像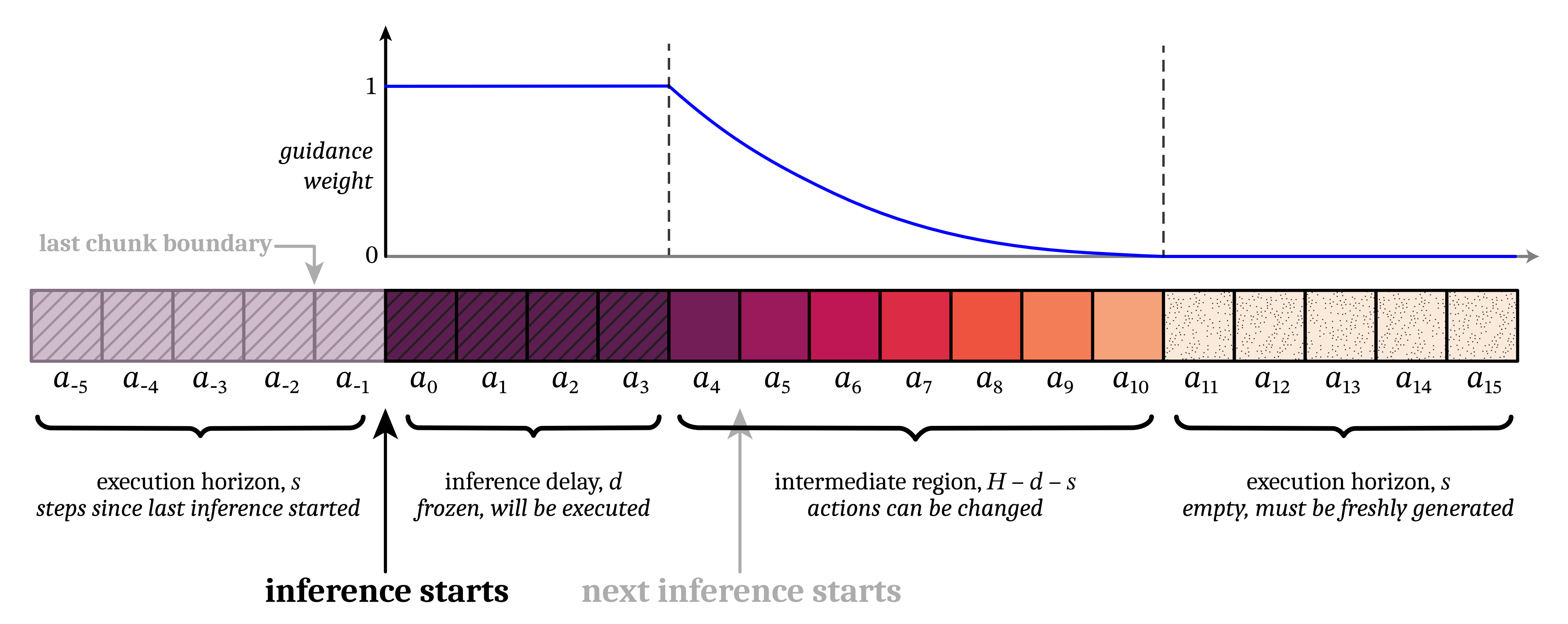
总之,上图图3展示了在实时分块过程中,动作生成如何关注前一个动作块,更多下文会详解
看到上面这,我觉得可能还是会有些朋友懵,为一目了然,我再补充说明下,简单一句话:RTC 让机器人"边做边想",不耽误干活
更具体地说,它用了一种"异步流水线"的小技巧:
- 先"锁"住已经做过的动作
机器人每走一步,后台就开始算下一步。但算得没那么快,比如慢了 4 拍。等新的动作算出来时,机器人已经把前 4 拍的动作做完了
RTC 就把这 4 拍"锁死",保证新算出来的动作必须从这里接着往下走,不会前后脱节- 再"续"出还没做的动作
锁完以后,剩下没做的部分就由模型继续往后编。它会参考刚才那 4 拍的动作风格,把后续动作补得又顺又自然,就像画画时把缺的那一角按原画风补全举个日常例子: 机器人正在划火柴。后台开始算下一步时,火柴已经划出去第一下(这 1 下就是已锁动作)。RTC 不会把这一下撤回,而是根据这一下的力度、方向,接着算出"点燃→移向蜡烛"的连贯动作,保证不会突然把火柴扔掉
1.2.1 推理阶段的流匹配补绘:确保新动作跟冻结部分吻合
修复是迭代去噪框架(如扩散和流匹配)已知的优势之一
-
作者基于Pokle 等人47 提出的免训练图像修复算法,该算法本身基于伪逆引导(IIGDM;54)
该算法通过在每一步去噪时向学习到的速度场
以促使最终生成结果匹配某个目标值 -
在图像修复的情况下,损坏算子是掩码操作,
针对作者设定的IIGDM 梯度修正为------分别定义为为公式2 3 4
其中,
*作者在这里滥用了记号,将
因此,引导项是一个向量-雅可比积,可以通过反向传播计算。引导权重裁剪
1.2.2 软掩码以提升跨片段连续性
在实际操作中,仅仅利用前一个动作片段的前几个时间步进行简单的修复,通常不足以确保新片段能够采用一致的策略,尤其当较小时(例如,参见图4)------说白了,有时新旧分块的策略差别太大,接起来还是不顺
ΠGDM校正并不完美,且较小的会导致指导信号较弱,这可能会导致新的分块仍然可能切换策略并导致不连续性『比如,当前分块计划让火柴划盒子顶部,新分块却想划底部,直接切换会让机器人动作猛地一跳』
作者的解决方案如图3 所示
是通过不仅仅考虑前d 个重叠动作,而是考虑所有H −s 个重叠动作(上面说过了,H是预测范围,s是执行范围),来赋予作者的策略更多跨分块的连续性
作者通过软掩码(Soft Masking)实现这一点,将W 设置为实值权重,而不是1 和0
- 前d 个动作的权重为1,相当于是必然会被执行的
如果推理在执行完 - 新分块的最后s 个动作则不与前一个区块重叠的部分,因此权重为0
最后的 - 中间的动作则赋予从1到0指数衰减的权重 ,以反映距离未来越远的动作应当被赋予更高的不确定性
在中间区域
由此得到的W的表达式为
直观来看,W调节了对前一块中每个相应动作所给予的"关注度"
简言之,软掩码就像在两段动作间加了个"缓冲带",让动作接得更自然,举个例子:假设预测范围H=8,执行范围s=4,延迟d=2
- RTC会给前2个动作(已执行)的权重1,完全冻结;
- 接下来的2个动作(可能执行)的权重从1逐渐降到0;
- 最后4个动作(全新生成)的权重是0
这样,新分块在点火柴时会更"尊重"前一段的划火柴动作,慢慢过渡到点燃蜡烛,而不是突然换个策略
还可以再想象你正在看一部连续剧,H=8 表示今天一共 8 集
- 你已经看完了 2 集(d=2),这 2 集的内容板上钉钉,不能改
- 接下来 2 集(s=4 里的前一半)是"预告片",可能拍也可能不拍,所以它们的"戏份"从 100% 慢慢降到 0%
- 最后 4 集还没写剧本,完全自由发挥
软掩码就像剪辑师在两段剧情之间加了"淡入淡出":老剧情音量先保持最大,再慢慢调低,新剧情音量从 0 逐渐拉高。于是观众不会觉得"咔"一下换台,而是感觉剧情顺滑地接下去了
1.2.3 实时分块的完整算法流程
作者在算法1 中展示了完整的实时分块系统(参见图3)

- 控制器通过GETACTION 与RTC的算法进行交互,该函数每隔
- INFERENCELOOP在后台线程中运行,以确保始终有可用的动作
它通过保留过去延迟的缓冲区来预测下一个延迟
执行范围s 可以在不同分块之间变化;用户提供一个期望的最小范围 - 最后,算法在GUIDEDINFERENCE 中描述了带有软掩码的修复过程,该过程明确地定义了去噪函数------即上文提到的公式3
并计算向量-雅可比积,这可以通过反向模式自动微分实现2
// 待更