本文将介绍 Zalando 如何利用高性能 API 取代事件驱动系统,该 API 能够支持每秒数百万个请求,P99 延迟时间达到毫秒级。原文:From Event-Driven Chaos to a Blazingly Fast Serving API
实时数据访问在电商系统中至关重要,确保准确的定价和可用性。在 Zalando,用于价格和库存更新的事件驱动架构成为了瓶颈,带来了延迟和扩展性的挑战。
本文将介绍 Zalando 如何重新设计并构建非常快速的 API,能够以毫秒级延迟处理每秒数百万个请求。通过本文,你将了解实现这种性能的缓存策略、低延迟优化和体系架构决策。
不支持读操作 API 的产品平台
2016年,Zalando 构建了一个微服务架构,其中独立的 CRUD API 安装在产品数据的不同部分上。一旦完成,每个产品都被具体化为一个事件,要求团队通过自己的 API 基于事件流来提供产品数据。
在实践中,这种方法将 API 服务的挑战分散到整个公司。但对于那些简单的请求("我正在构建一个新功能,需要访问产品数据,怎么才能访问这些数据?"),获得的回答却很不合理("订阅我们的事件流,从头开始重播事件,并建立自己的本地存储。")。
具有工程能力的团队消费事件,修改数据以满足自身需求,并公开他们自己的 API 或事件流。那些没有能力的人依赖现有的统一数据源,比如 Presentation API,继承其版本的产品数据。这导致了对真实数据源的竞争。
一个很好的类比是孩子们玩的"拷贝不走样"游戏,产品数据在每一步都可能被改变,到最后已经和原来的样子完全不同了。没有数据溯源,就没有办法追溯属性的预期含义。
报价构成问题
在 Zalando,报价(offer)代表商家以特定价格卖出特定数量的产品。为了服务于产品报价表示视图,一个多阶段事件驱动系统将产品、价格和点位事件合并到一个结构中。该结构经历了多个转换阶段,包括聚合和丰富,然后存储在 Presentation API 的数据存储中,该 API 由 Fashion Store 的 GraphQL 聚合器调用。
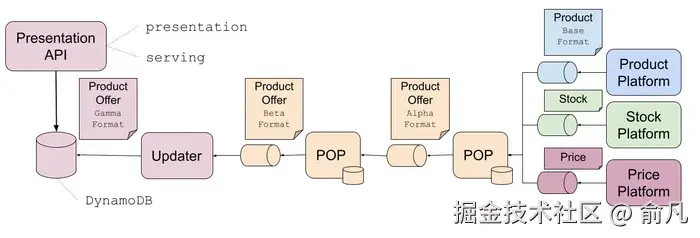
这种体系架构使得报价处理缓慢、昂贵且脆弱。频繁的量价更新与大多数静态产品数据一起处理,每个有效负载的 90% 以上都是不变的,浪费了网络、内存和处理资源。在黑五促销期间,库存和价格事件可能会延迟 30 分钟,导致糟糕的客户体验。
三种报价格式(上图中的Alpha, Beta, Gamma)明显偏离了基本格式。其他团队也可以从中间阶段访问事件,因此他们的开发也依赖于这些格式。
使命:解耦产品和报价数据
到 2022 年,很明显,如果不解决报价构成问题,将成为业务增长的障碍。为了解决这个问题,一个全球性项目 ------ 产品报价数据分割(PODS,Product Offer Data Split) ------ 应运而生。
目标是从事件流中移除大量的、未改变的产品数据,从而消除报价流水线的瓶颈。新的服务层将独立为产品和报价数据提供服务,或者作为组合格式为 Presentation 提供服务。
/products/{product-id}- 核心产品详细信息/products/{product-id}/offers- 商家为产品提供的报价/product-offers/{product-id}- Presentation API的组合产品报价
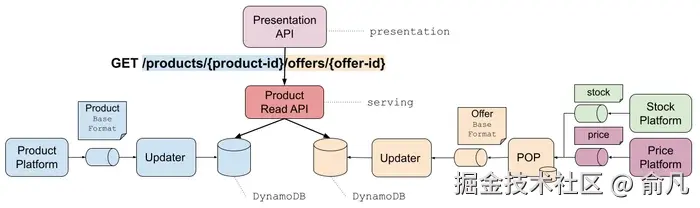
为了取得成功,我们的新服务层 ------ 产品读取 API(PRAPI,Product Read API)------ 需要匹配或超过它所取代的数据存储的性能。
随着团队对问题的深入研究,一个问题出现了:PRAPI 的性能能超过所有本地存储的产品数据副本吗?
如果是这样,那个简单的请求("我从哪里获得产品数据?")最终会有一个简单的答案:"调用产品读取API。"
PRAPI架构
PRAPI 有以下高级需求:
- 低延迟检索 ------ 单个项的 P99 请求延迟为50ms,批量检索为100ms
- 对个别产品的极端流量峰值的适应能力
- 国家层面的隔离 ------ 防止失败在欧盟市场上蔓延
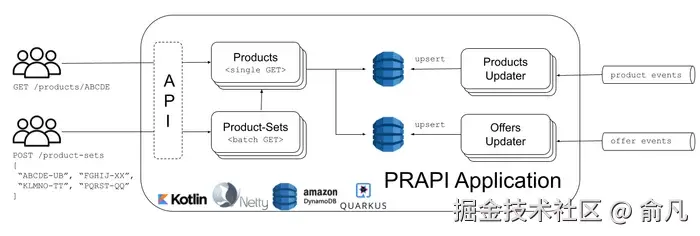
为了满足这些需求,PRAPI 被设计为四个主要组件,每个组件都是 Kubernetes 上的独立部署,具有定制的扩展规则。每个组件都集成了端到端非阻塞 I/O,利用 Netty 的 EventLoop 和 Linux 原生 Epoll 传输。DynamoDB 确保高速缓存丢失时的高可用性和快速查找。
国家级隔离/获取数据
为了实现国家级隔离,部署了多个 PRAPI 实例(称为市场组),每个实例服务于国家的一个子集。路由配置允许我们在市场组之间动态转移流量,允许我们将内部或金丝雀测试流量与高价值国家流量隔离开来。
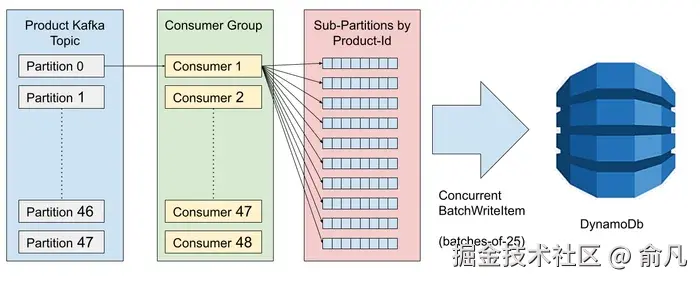
每个市场组的更新都根据延迟水平扩展,直到达到源流中的分区数量。为了确保快速处理上百万产品,每个 pod:
- 批量读取 250 个产品
- 按产品ID对事件进行子分区
- 向 DynamoDB 发送 10 个并发批处理写入 25 个项
扩展到数百个并发批处理写入时,DynamoDB 的写容量单元成为瓶颈,如果需要,我们可以在几分钟内增加容量来填充新的市场组。
DynamoDB 优化
PRAPI 被设计为 DynamoDB 之上的快速服务缓存层。在这里,我们非常依赖于高性能 Caffeine 缓存。利用其异步加载缓存,我们配置了 60s 缓存时间,最后 15s 作为过期窗口。在最后 15s 内,检索缓存条目会触发 DynamoDB 的后台刷新。
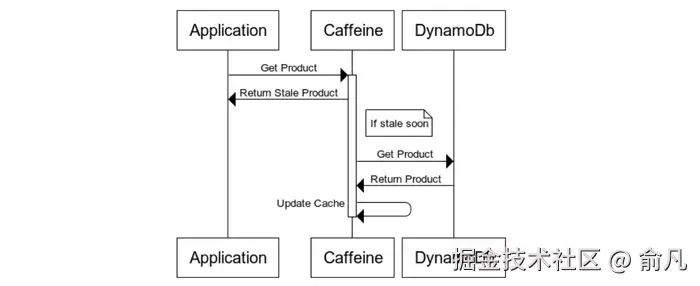
优化缓存命中
我们以客户为导向的流量将目录分为小热部分和大冷部分:
- 冷:小众商品,流量不高,但必须保持高可用性
- 热点:日常用品,如白袜子和t恤被频繁使用
- 极热:限量版产品,比如耐克运动鞋,会突然产生大量的流量高峰
但是,即使 1000 万个产品中只有 10% 是热的,每个 pod 缓存 100 万个大型(~1000 行 JSON)产品有效负载也是不可行的。
为了解决这个问题,我们的产品组件利用了一个强大的负载均衡算法,一致性哈希负载均衡(CHLB,Consistent Hash Load Balancing)。
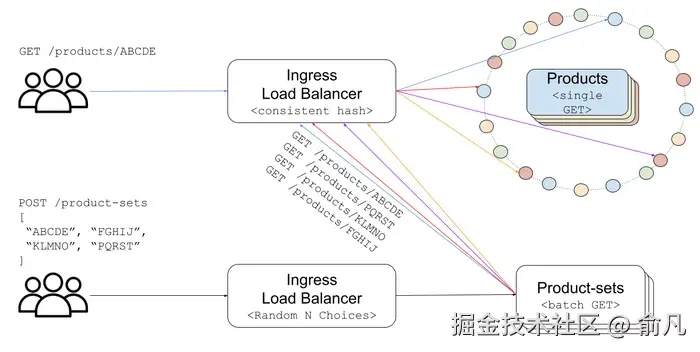
在 CHLB 中,每个后端 pod 被分配到哈希环上的多个随机位置。当请求进入时,将对 product-id 进行散列以定位其在环上的位置。最近的 pod 顺时针在环上,始终满足这一要求。在可用 pod 之间划分目录,允许小型本地缓存有效缓存热门产品。我们扩展的范围越广,目录中缓存的部分就越高。
批处理组件解包批处理请求,并发处理单项查找,并聚合响应。它基于双随机选择算法,将请求路由到两个随机选择的 pod 中负载较小的那个。
解决真实数据源竞争问题
通过 API 集中交付产品数据解决了报价组合问题,为未来的应用奠定了基础。但是否能成功取决于团队是否能迁移旧格式,标准化新格式,以及淘汰遗留应用。

大约有 350 个工程团队和数千个已部署的应用,其中许多直接或间接依赖于产品数据,因此迁移总是很复杂。如果没有明确的转换路径,遗留系统就会持续存在,就像上面的 XKCD 漫画一样,很容易以比以前更糟糕的状态结束。
为了确保采用,PRAPI 拥有产品和报价数据的所有遗留表示形式。工程师们仔细分析和复制了 PRAPI 中现有的转换,允许客户团队通过 Accept 标头请求所需格式的数据:
application/json- 适合所有团队的新标准格式application/x.alpha-format+json- 传统格式(以前事件流上的格式)application/x.beta-format+json- 传统格式(以前事件流上的格式application/x.gamma-format+json- 传统格式(以前 Presentation API 的格式)
此外,PRAPI 中的临时组件将 alpha 和 beta 格式发送回遗留事件流,从而使得遗留应用可以立即退役,而团队可以在固定时间内逐渐迁移遗留格式。
性能测试结果
为了从客户端角度准确度量 PRAPI 的性能,我们使用了来自入口负载均衡器 Skipper 的指标。
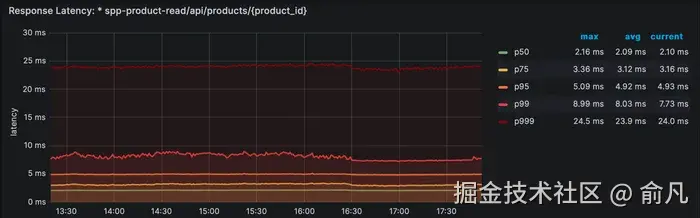
单个 GET 请求返回带有内容类型转换的大型(~1000 行 JSON)有效负载,但仍然实现低于 10ms 的 P99 延迟。
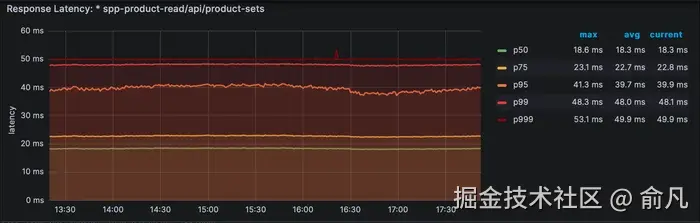
批处理 GET 请求(最多可处理 100 个条目)可随着响应时间的预期增加而可预测的扩展,与单个 GET 的 P999 非常接近。
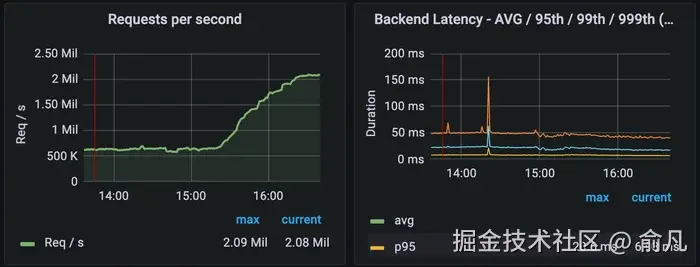
在高负载下,PRAPI 的性能会更好 ------ 随着流量增加,更多产品目录会被缓存,从而降低延迟。当我们对 PRAPI 进行负载测试时,可以在上面的集群范围延迟图中看到。
高级调优
本节介绍用于减少 PRAPI 尾部延迟的高级调优技术。
Java Flight Recorder(JFR)在对 JVM 进行微调方面非常有用。通过从性能不佳的 pod 中捕获遥测数据并在 JDK 任务控制中将其可视化,我们确定了垃圾收集(GC)暂停,并确保没有阻塞任务在 NIO 线程池上运行。
开源负载均衡器贡献
我们对 Kubernetes Ingress 负载均衡器 Skipper 中的 CHLB 算法做出了以下改进:
-
最小化扩容期间的缓存丢失 ------以前,扩缩容时的 pod 再平衡会导致大量缓存失效,从而将流量路由到冷缓存。我们通过将每个 pod 分配到环上的 100 个固定位置来解决这个问题,将缓存缺失减少到 1/N,其中 N 是先前的 pod 数量。
-
防止热门产品流量过载 ------ 我们添加了有界负载算法,将每个 pod 的流量限制在平均流量的 2 倍。一旦超过,请求就会顺时针溢出到下一个未超载的 pod,缓存并分发热门产品。
消除垃圾收集暂停
关键学习:消除 GC 暂停的最佳方法是完全避免对象分配。
- 产品 ------ 将产品数据缓存为单个
ByteArray而不是ObjectNode图,从而减少堆压力。 - 产品集 ------ 避免将单个压缩响应读入内存。相反,将它们存储在 Okio 缓冲区中,并直接连接到响应对象,从而消除不必要的 gunzip/re-gzip 操作。
LIFO vs FIFO
关键学习:在对延迟敏感的应用程序中,FIFO 队列可能会产生长尾延迟峰值。
- 负载均衡器 ------ 虽然目标是避免请求排队,但切换到 LIFO 减少了排队时的长尾延迟峰值。
- DynamoDB 客户端 ------ 为主 DynamoDB 客户端配置了 10ms 超时,为重试配置了 100ms 超时的备用客户端,防止在 DynamoDB 延迟高峰期间主客户端上的 FIFO 排队。
在架构的基础上扩展团队
PODS 项目的成功需要的不仅仅是技术上的改变,还需要团队重组来匹配新的体系架构。根据康威定律和 CQRS 原则,产品部门被重组为两个流程化团队:
- 合作伙伴和供应商 ------ 管理数据摄取(命令端)
- 产品数据服务 ------ 侧重于聚合和检索(查询端)
这种转变减少了依赖关系,提高了可伸缩性,并加速了产品更新。随着首席工程师推动架构简化,新架构确保了黑五促销周等高峰事件的弹性,并为未来的创新奠定了基础(包括统一产品数据模型和多租户解决方案)。
你好,我是俞凡,在Motorola做过研发,现在在Mavenir做技术工作,对通信、网络、后端架构、云原生、DevOps、CICD、区块链、AI等技术始终保持着浓厚的兴趣,平时喜欢阅读、思考,相信持续学习、终身成长,欢迎一起交流学习。为了方便大家以后能第一时间看到文章,请朋友们关注公众号"DeepNoMind",并设个星标吧,如果能一键三连(转发、点赞、在看),则能给我带来更多的支持和动力,激励我持续写下去,和大家共同成长进步!