前言
高并发场景下的数据交互流程复杂多样,但关键诉求我认为只有三个:数据正确性/一致性、存储成本、调用延时。
方案分析
方案一
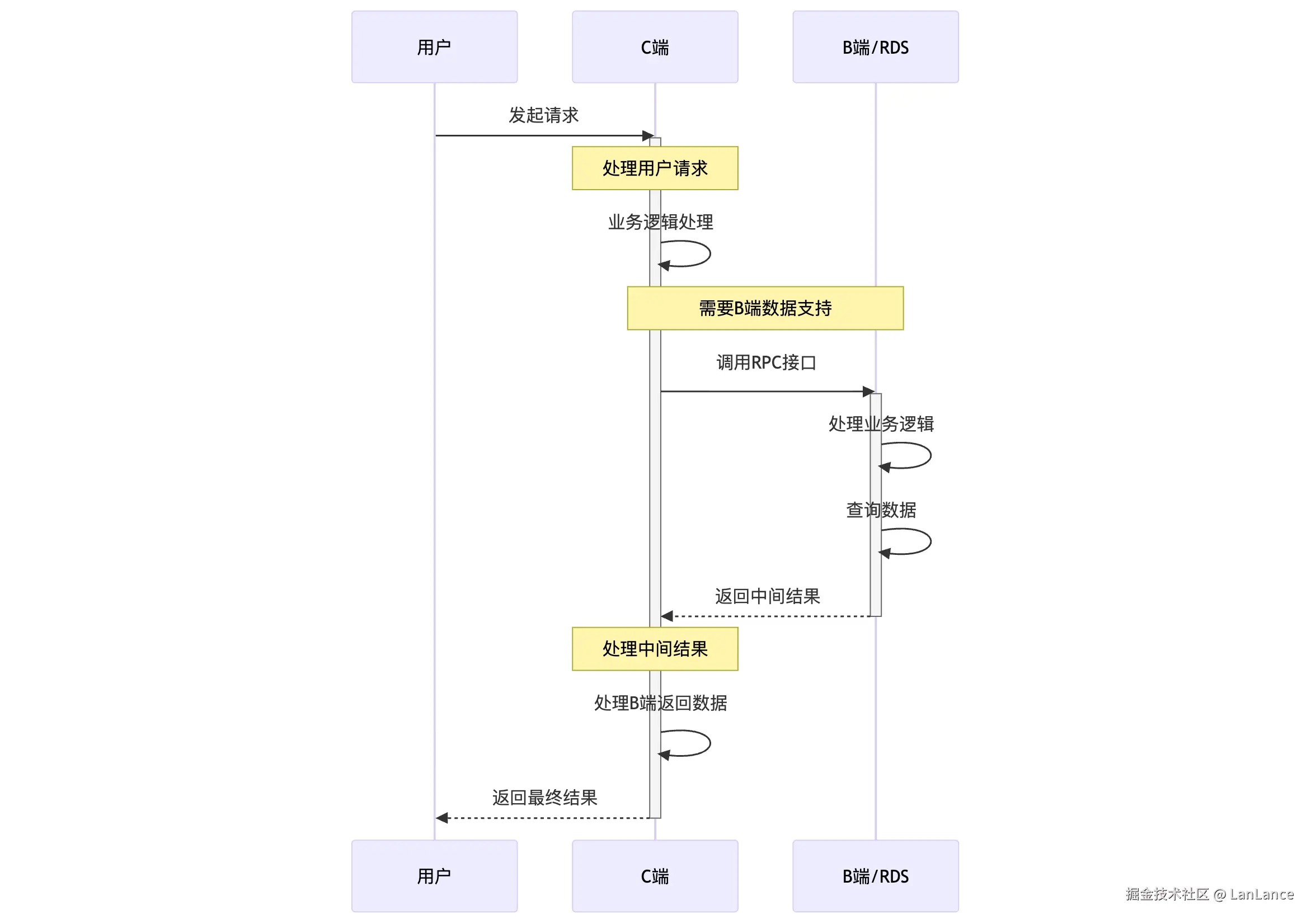
由 C 端服务直接打到 DB 中,B 端/DB 的 QPS 与 C 端请求 1:1。同时整个链路会因为多一次 RPC 调用以及序列化反序列化的操作,加大延时。若下游还是使用的 JDK8 甚至会有长尾问题,TP999 不可接受。但优点是完全没有一致性问题。
方案二
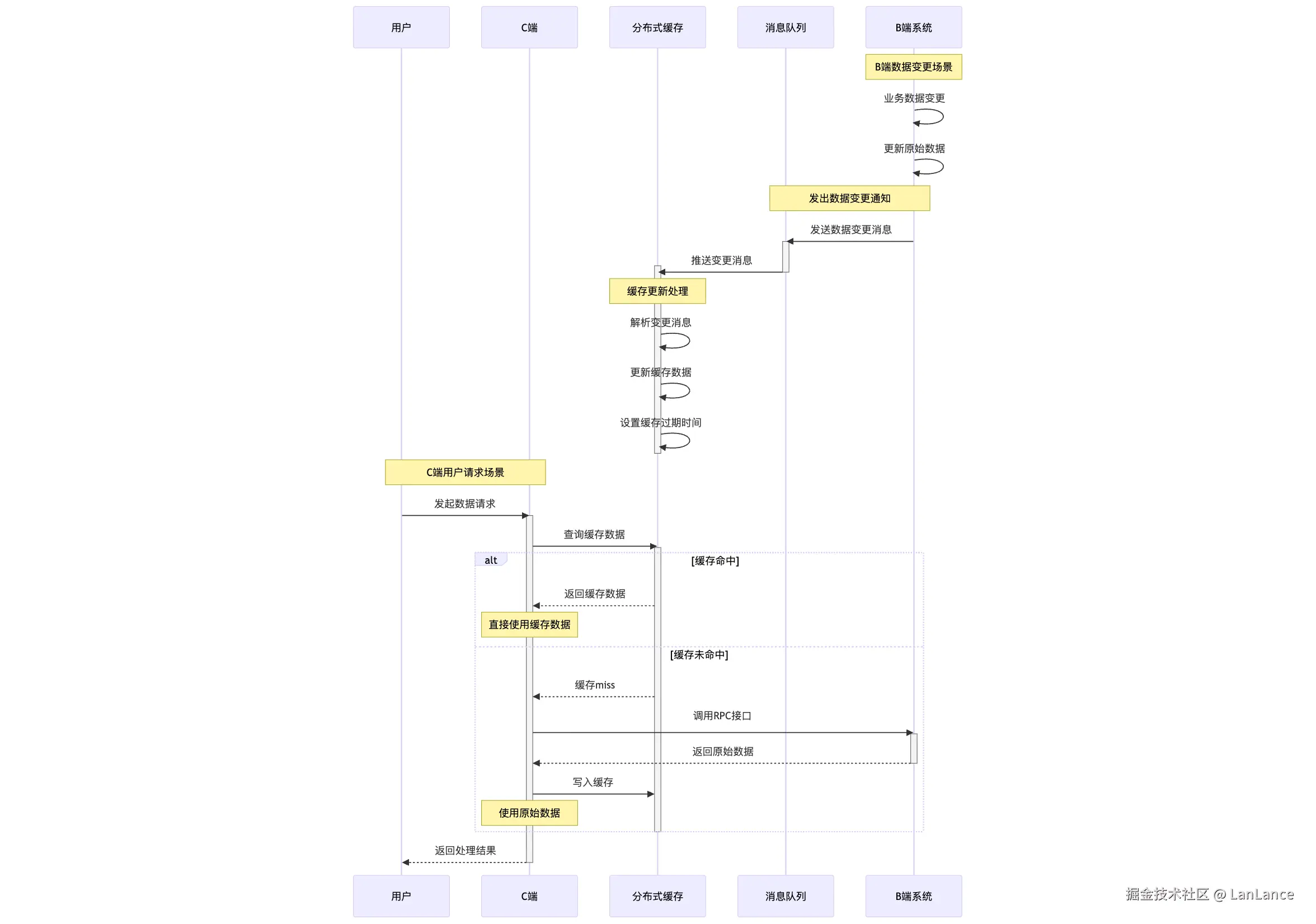
加入两个组件:分布式缓存和消息队列,当 DB 数据变更时先推到消息队列,再由消息队列消费写入缓存。C 端服务直接访问缓存,但访问缓存也有一定网络延时(同 Set 能保证 10ms 内,异地 Set 需要几十 ms)。同时缓存存储相较方案一成本更高,数据也会有一致性问题。
方案三
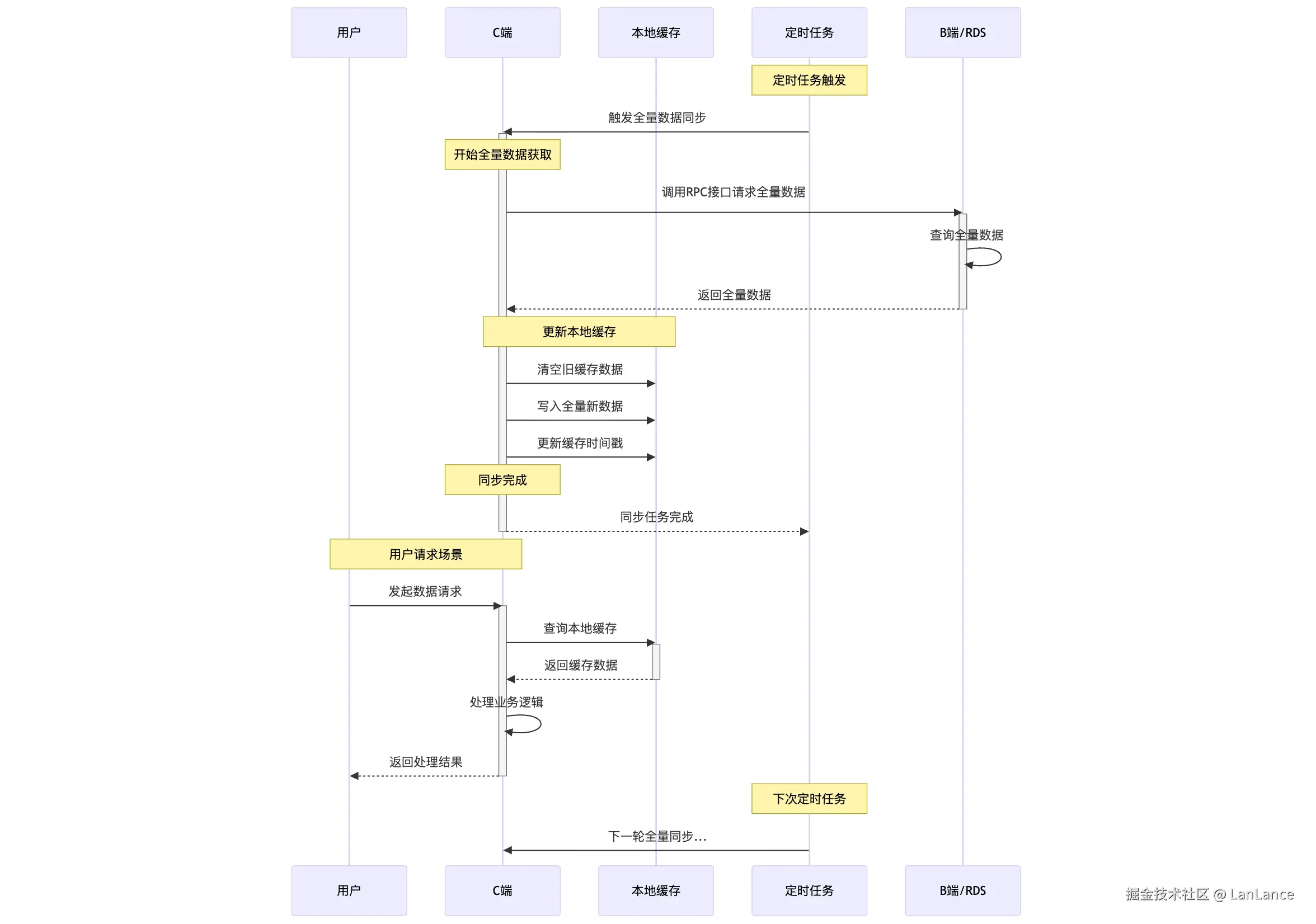
通过一个定时任务将 DB 数据同步到本地缓存中,缓存数据与 DB 数据一致,但需要接受一定延时(秒级)。系统访问本地缓存无需调用远端,几乎零耗时。但存储瓶颈由内存决定,成本较高。
思考
| 方案 | 延时 | 存储成本 | 数据一致性 |
|---|---|---|---|
| 1 | 100ms,需要一次 RPC 请求,同时还有一次访问 DB 的时延。 | 低,全部落库,硬盘存储。 | 强,没有其他数据存储介入。 |
| 2 | 10ms~50ms,瓶颈在分布式内存。 | 中,分布式缓存一般使用三级缓存架构,有硬盘介入。 | 弱,通常需要额外的校验任务。 |
| 3 | 0.1ms 以内,直接请求内存。 | 高,仅支持单台服务器内存可以承载的数据量级。 | 强,但有一定延时,能保证最终一致性。 |
写在最后
上述三个方案有各自的优势场景,需要根据具体的业务情况进行选型。但能得出一个简单的结论:在高并发的C端场景下,数据流交互不存在银弹。