作为分布式系统中异步通信的扛把子,RabbitMQ 凭借其高可靠、灵活路由的特性,几乎是每个后端开发者的"必备技能"。但很多新手刚接触时,常被各种组件名称绕晕------Broker、Exchange、Queue、vhost...这些"术语炸弹"到底啥关系?今天笔者带你了解RabbitMQ的核心组件!
一、先搞个大框架:RabbitMQ的"四梁八柱"
RabbitMQ本质是一个消息代理服务器 (Broker),但它不是单打独斗,而是靠一群"小弟"组件协作完成功能。先上一张核心组件关系图:
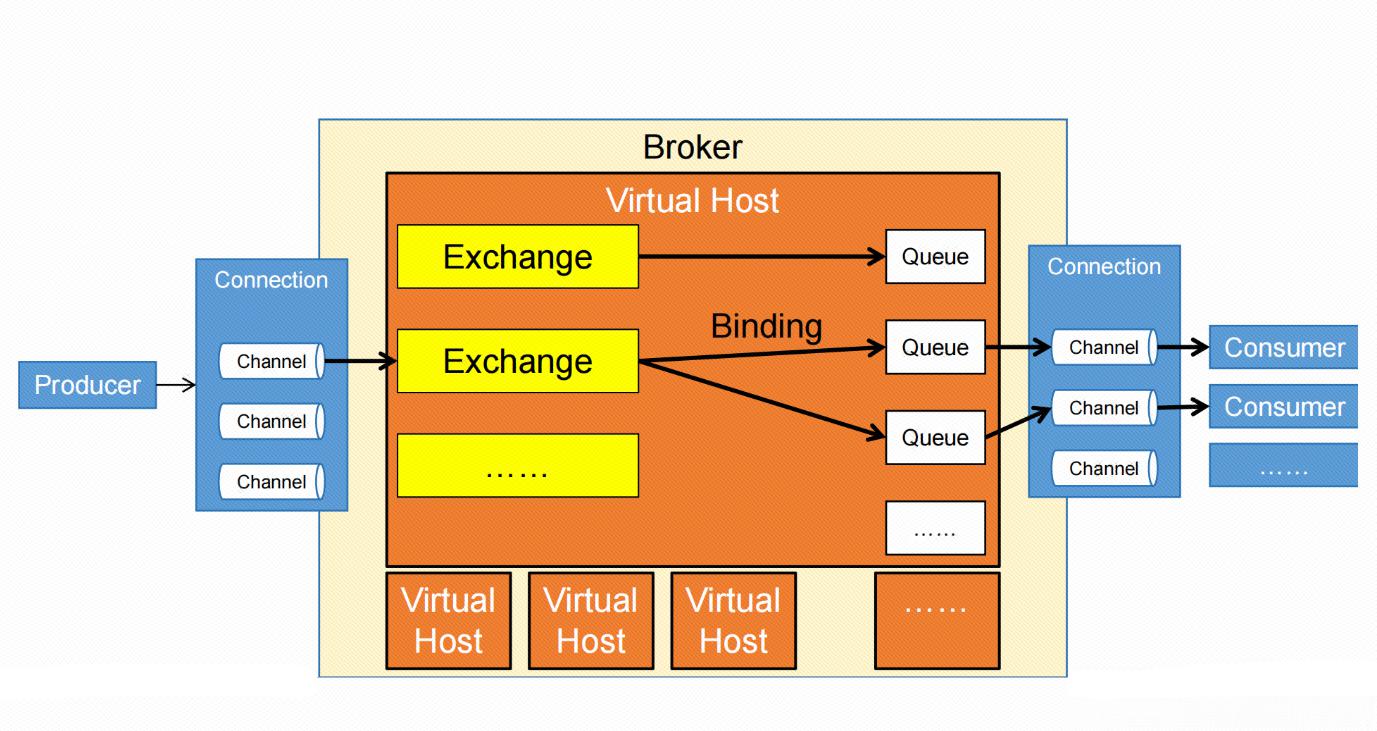
生产者 → 连接Broker → 通过Exchange(按路由规则)→ 投递到Queue → 消费者订阅Queue处理
这张图里藏着RabbitMQ的核心逻辑:消息从生产到消费,必须经过Exchange路由到Queue,而Broker是这一切的"大管家"。
二、逐个拆解:每个组件都是解决什么问题?
1. Broker:消息系统的"总控中心"
Broker是RabbitMQ服务器的核心进程,你可以理解为它是一个"超级快递站":
- 所有生产者发的消息先到这里"暂存";
- 根据交换器的规则,决定消息该送到哪个队列;
- 管理所有队列、交换器的"生死"(创建/删除);
- 处理消费者的订阅请求(比如某个队列被几个消费者盯着)。
划重点:Broker是RabbitMQ的"大脑",没有它,消息就彻底"迷路"了!
2. Virtual Host(vhost):消息系统的"独立租户"
想象一下:你所在的公司有两个团队(A团队做电商,B团队做金融),他们都需要用RabbitMQ发消息。如果共用同一个Broker,队列名很可能冲突(比如都叫order_queue),这还怎么玩?
这时候vhost(虚拟主机)就派上用场了!它相当于在Broker里划了一块"独立空间",每个vhost有自己独立的:
- 交换器(Exchange)
- 队列(Queue)
- 绑定关系(Binding)
举个栗子:
- 电商团队用vhost
/ecom,里面有个队列/ecom/order_queue; - 金融团队用vhost
/finance,里面有个队列/finance/loan_queue;
两边完全隔离,再也不会因为队列名重复吵架!
注意 :连接RabbitMQ时必须指定vhost(默认是/),权限控制也按vhost来做(比如限制某用户只能访问/ecom)。
3. Exchange:消息的"智能路由器"
Exchange是RabbitMQ的"灵魂组件",它的作用是根据规则把消息转发到正确的队列。打个比方,它就像快递站的"分拣员",手里有一张"路由表"(绑定关系),看到消息的"地址"(路由键)就能知道该往哪送。
Exchange的4种类型(最常用):
| 类型 | 路由规则 | 适用场景 |
|---|---|---|
direct |
消息的路由键和队列的绑定键完全匹配 (比如路由键pay.succ,绑定键也得是pay.succ) |
精确匹配场景(如订单支付成功通知) |
topic |
路由键和绑定键用通配符匹配(*匹配1个词,#匹配0或多个词) |
模糊匹配场景(如日志分类) |
fanout |
完全无视路由键,消息广播到所有绑定的队列 | 广播通知(如系统全局告警) |
headers |
不看路由键,看消息头的键值对匹配(比如user_id=123) |
复杂条件路由(少用,性能略差) |
实战场景 :
假设你有一个日志系统,需要区分error、info、warn级别的日志:
- 用
topic类型的Exchange,绑定键设为log.error、log.info; - 生产者发消息时路由键填
log.error,Exchange就会把消息转发到所有绑定键匹配log.error的队列; - 消费者可以订阅
log.error队列处理错误日志,订阅log.info队列处理普通信息。
4. Queue:消息的"临时仓库"
Queue是消息的存储容器 ,它的核心作用是:当消费者没来得及处理消息时,先把消息存起来,避免丢失。
Queue的关键特性:
- 持久化 :设置
durable=true后,消息会存盘(Broker重启不丢数据); - 独占性 :
exclusive=true时,队列仅限当前连接使用(连接断开自动删除); - 自动删除 :
auto-delete=true时,没有消费者订阅就自动销毁(适合临时任务); - FIFO顺序 :默认先发的消息先被消费(想插队?用
priority参数实现优先级队列)。
避坑指南 :
新手常犯的错误是不设置持久化,结果Broker重启后消息全没了!记住:重要消息一定要durable=true(但要注意性能损耗)。
5. Binding:Exchange和Queue的"婚书"
Binding是Exchange和Queue之间的绑定关系,相当于两者的"婚书"------告诉Exchange:"以后你的消息,按这个规则给我"。
比如:
- Exchange是
log_exchange(topic类型); - Queue是
error_log_queue; - Binding的绑定键是
log.error;
这表示:所有路由键为log.error的消息,都会被log_exchange转发到error_log_queue。
6. Producer & Consumer:消息的"发件人"和"收件人"
-
Producer(生产者) :负责把业务数据打包成消息,通过AMQP协议发给Exchange。
关键操作:连Broker→开信道(Channel)→发消息(指定Exchange和路由键)。 -
Consumer(消费者) :订阅Queue,接收并处理消息。
关键机制:- 消息确认(ACK):处理完消息后必须发ACK,Broker才会删消息(否则可能重复投递);
- 负载均衡 :一个Queue可以被多个Consumer订阅,消息按轮询或公平分发(
basic.qos)分配; - 死信队列:处理失败的消息可以转发到死信队列(避免无限重试)。
7. Channel:消息的"专用快递通道"
Channel是建立在TCP连接上的轻量级虚拟连接,相当于给每个操作开了条"专用通道"。
为什么需要Channel?
如果每次发消息都新建TCP连接,性能会差到怀疑人生!一个TCP连接可以创建多个Channel(比如1个连接开10个Channel),每个Channel独立处理自己的消息操作(发消息、声明队列等),既高效又隔离。
三、组件协作实战:一条消息的"奇幻之旅"
理解了各个组件,咱们看一条消息是怎么从生产到消费的:
-
生产者发消息 :
生产者连Broker→开Channel→指定Exchange(比如
order_exchange)和路由键(比如order.create)→发送消息(内容是订单ID)。 -
Exchange路由消息 :
order_exchange是direct类型,检查绑定关系发现:有一个队列order_queue绑定了路由键order.create→把消息转发到order_queue。 -
Queue存储消息 :
order_queue如果是持久化的,消息会被写入磁盘;如果是内存队列,就先存内存(Broker重启前会刷盘)。 -
消费者接收消息 :
消费者连Broker→开Channel→订阅
order_queue→Broker把消息推给消费者(或消费者主动拉取)。 -
消费者处理并确认 :
消费者处理完订单(比如更新库存)→发送ACK→Broker收到ACK后,把消息从
order_queue删除(或标记为已消费)。
四、总结:核心组件如何帮我们解决问题?
- 解耦:生产者和消费者不需要知道对方存在(通过Exchange和Queue间接通信);
- 异步:生产者不用等消费者处理完(消息存队列后直接返回);
- 削峰:突发流量时,消息先存在队列里,慢慢处理(避免系统崩溃);
- 可靠:持久化、ACK确认、死信队列等机制,保证消息不丢。
下次再遇到消息队列的问题,记住这句口诀:Broker管全局,vhost做隔离;Exchange分消息,Queue存数据;Binding定规则,Producer发,Consumer收!
动手练习建议 :
用RabbitMQ管理界面(默认http://localhost:15672)创建vhost、Exchange、Queue,然后用Python(pika库)或Java(Spring AMQP)写个简单的生产消费示例,亲身体验组件协作流程~
如果觉得本文对你有帮助,记得点赞收藏~ 😊