主要是很久之前safepoint的后续,整理笔记的时候才发现,这个东西一直没发,补个档。
首先基础就是一个jdk工具:javap,一般这么用:
shell
javap -v -p ${yourClass}关于javap的更深一些的了解,看oracle文档即可:docs.oracle.com/javase/6/do...
关于字节码
首先字节码的opcode本身是byte-sized的,也就是1byte大小,那就是8位,所以支持256种不同的字节码指令。
不过,opcode的参数可以是1byte/2byte大小的,所以一个完整的字节码指令,可以是1、2、3byte大小,比如:
- iload_0:1字节
- bipush 10:2字节
- goto 100:3字节
可以把jvm解释器看作是一个巨大的switch,用来解析所有class文件字节流,并根据opcode来分类解析后续的内容。
还有就是,bytecode的一个设计思想就是,运行的时候,可以假设是将bytecode序列取出来,然后把operand压入到一个模拟的stack中,然后将operand消耗掉,再把结果给压到stack里面。
这样的优势就在于,根据CPU寄存器的机制来进行抽象,而并不依赖任意一个CPU,比如说它并不依赖于某种特定的指令集,所以这也是bytecode可以run on every platform的原因。
简单的字节码
也就是local variables。在bytecode里面基本是以memory location的形式出现的。
像这样的一段代码:
java
void spin() {
int i;
for (int i = 0; i < 100; i++) {
; // do nothing
}
}对应的字节码就是:
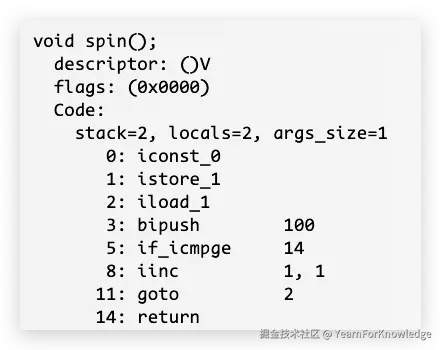
可以看到在opcode之前还有一些属性,这个也是挺关键的:
- stack:当前方法需要的最大栈深
- locals:当前方法本地变量个数
- args_size:当前方法的参数个数
那么直观看起来,locals和args_size的大小,似乎和方法的代码形式有点不一样。这是因为,在vm中,要计算上this这个引用。那么再详细一点解释就是:
- locals:包含this、i
- args_size:包含this
如果把这个方法改为static,再编译,就会看到locals=1和args_size=0的情况。
再提一嘴就是,这个locals,可以看作是一个数组一样的东西,每个元素可以称为slot,实际上它在内存中也是一块连续的区域。并且,对于实例方法,第0个位置永远都是this引用,再往后,首先会是方法的参数,从左到右排序,然后是方法中的本地变量,从上到下排序。
比较特殊的是,这个slot只能存放至多32位的内容,也就是说,long、double这样的数据,需要占用两个slot。
比较特殊的是对象引用,这个关联到经典的CompressedOops选项。但是,需要注意的是,当手动关闭这个CompressedOop选项的时候,对象指针仍然只占用一个slot:因为根据JVM规范,reference永远只占用一个slot,那么此时为了适应64位的reference,JVM会让特定的slot来变宽,以存放64位的reference。
那么结合一个例子来看locals:
java
public String method(int p1, int p2, Object p3) {
double d = 10.0d;
String res = p2.toString();
return result;
}那么这个方法的本地变量表大概是这么个样子:
| index | name | type | slots occupied |
|---|---|---|---|
| 0 | this | class | 1 |
| 1 | p1 | int | 1 |
| 2 | p2 | int | 1 |
| 3 | p3 | Object | 1 |
| 4 | d | double | 2 |
| 5 | - | - | - |
| 6 | res | String | 1 |
所以,这个方法的locals=7。这么看就很直观了。
至于这个stack,看一下代码就可以知道了:在for里面,对比i和100的时候,需要把100和当前的i都放到栈中,所以最大的栈深为2就可以了。
有一个网站总结了所有的bytecode opcode:javaalmanac.io/bytecode/
除此之外,这个网站还包含了java version feature comparing等,算是一个很不错的工具网站。
那么,在这些属性之后,来深入解读一下这个简单方法的字节码:
iconst_0:往栈里面放一个常数0istore_1:将栈顶的值放给第1个slot的局部变量,那么也就是给i赋值为0iload_1:将第1个slot的int值压到栈中,也就是ibipush 100:将100这个常数以byte的形式压入栈中if_icmpge:可以简单理解成compare if greater,这时候栈里有两值,从上到下为100、i,那么也就是对比i和100,如果i > 100那么跳转到对应的字节码,也就是return了iinc 1,1:简化成iinc a,b,给第a个slot的变量加上b,也就是i+1goto 2:指令跳转,也就是跳回第2行opcodereturn:显而易见,结束方法
可以将i改为long或者double的,来验证一下前面的说法。看到对应的字节码的话:
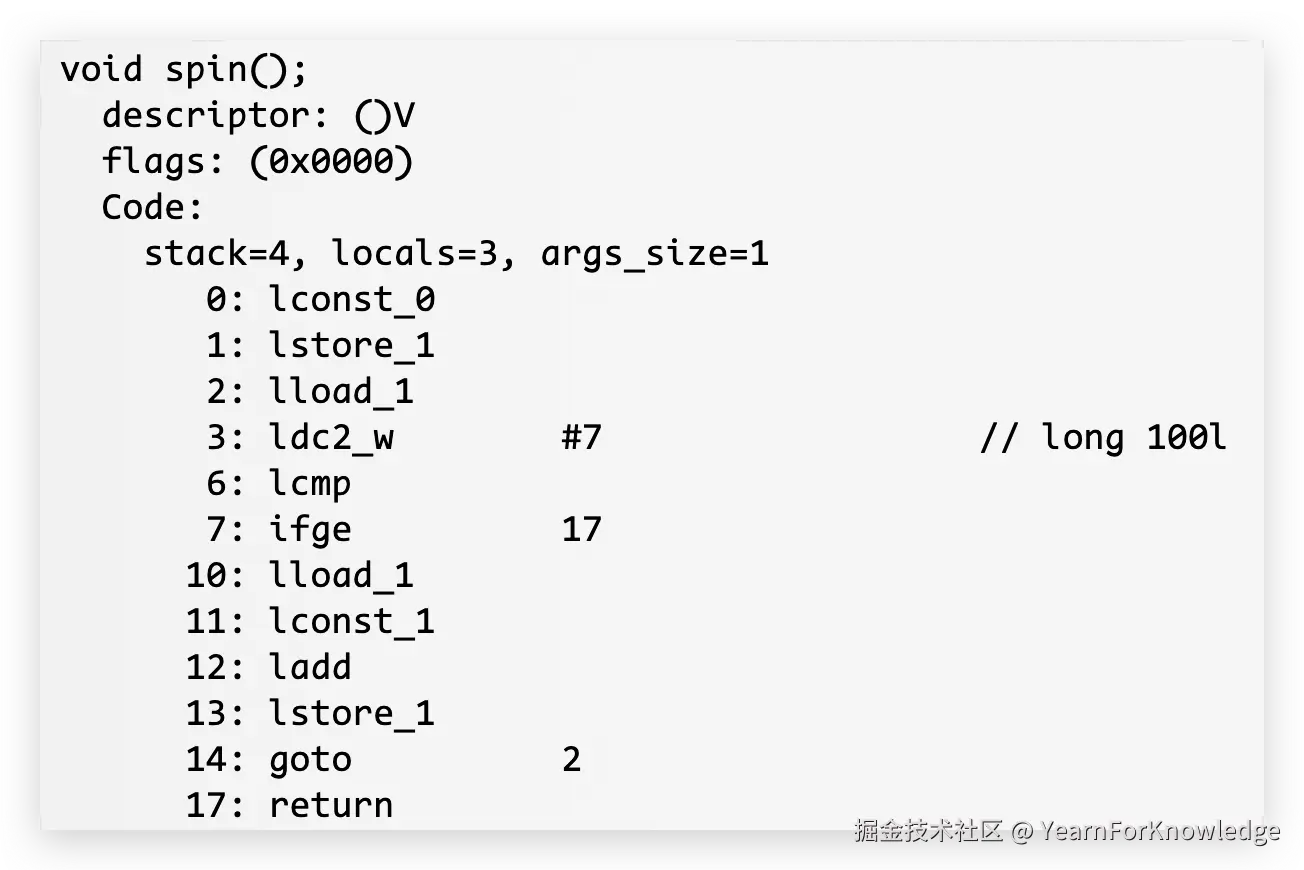 可以看到,不仅是stack、locals变大了,并且opcode的行数也变多了。
可以看到,不仅是stack、locals变大了,并且opcode的行数也变多了。
并且,很多指令都变成了l开头,而不是i,实际上opcode很多也就是以这些基本类型的首字母来区分的。
现在来看为什么多了几行,主要看一些和上面不同的opcode:
- lcmp:简单理解就是long comparision。那么在执行到这一行opcode的时候,栈里面从上到下分别是100,i,那么也就是long变量的大小比对不能简单的通过一个opcode就可以完成。实际上,double也是这样的。 这个指令只会返回1、-1、0这三种结果。
- ifge:这里就是lcmp的结果,此时栈上就剩下了lcmp的结果,如果这个值 > 0,那么跳转到17行,也就是return
可以看到,对于占用两个slot的变量,在字节码形式上,会比占用一个slot的要复杂一些,包括更多的load、const这种操作。并且,stack和local都会更大一些,也就是额外的内存占用。
所以,一个简单的int、long、double差别,在字节码上相差还是挺大的。
除此之外,实际还有一个区别就是,如果需要在栈中放置一个常数值,如果是浮点数,或者是非int值,使用的是ldc指令;而如果是整数,用的是bipush。
这是因为byte-based无法表示浮点数,只可以表示有限范围内的整数,所以浮点数需要ldc,在编译期间将复杂的constant存储到constant pool,也就是常量池。
这里的constant pool和堆中的constant pool不是一个东西,需要区分开来。
这一个constant pool只是类文件内容中的一块。一般来说,字符串和浮点数都会在编译期间被解析存储到constant pool中,需要使用的时候再ldc拿出来。
去翻了一下JVM规范,ldc这一类opcode,包含三种 (其他的相似作用的指令也会有好几种,不过这个我感觉可以单独说一下):
- ldc、ldc_w:从constant pool中获取一个32位的值
- ldc2_w:从constant pool中获取一个64位的值
实际上可以这么区分:
- ldc:使用一个字节的操作数作为索引
- ldc_w、ldc2_w:使用两个字节的操作数作为索引
因为ldc需要接收一个操作数,这个操作数是取出来的值在constant pool中的索引。所以,带w和不带w的区别就在这。
而实际上,不同类型的变量的字节码,还有一个细微的差别。
在bytecode层面上,大多数情况下,数值比对都是被视作int来统一进行,而long、double和float则不是。
同时,对于数值的增加/减小,JVM会将char、short、byte都视为int来统一操作,然后再通过i2c、i2s、i2b这样的指令转换为对应的类型的值。
所以,可以看的出来,原始的int值在字节码上非常受欢迎,为什么我要说是原始的呢?对于原始的int类型数值的加减,可以用类似iinc这样的opcode,直接去操作本地变量表进行加减,非常的高效。 但是,一旦改成了诸如char++、short++、byte++这样的操作,就需要经过先压栈,再相加,转换为原生类型,再保存回局部变量表这一系列操作。
Constant pool
前面提到了constant pool,稍微介绍一下,写个代码编译一下看看:
java
public class Demo {
// 注释代表对应的字节码,可以加深对上面内容的理解
void method() {
int a = 257; // sipush 257
float b = 3.14f; // ldc_w #7, fstore_2
double c = 3.14d; // ldc2_w #8, dstore_3
boolean d = true; // iconst_1, istore 5
byte f = 127; // bipush 127, istore 6
char g = 'A'; // bipush 65, istore 7
short h = 32767; // sipush 32767, istore 8
long l = 1234567890L; // ldc2_w #10, lstore 9
}
}编译结果,我们只看constant pool就可以了:
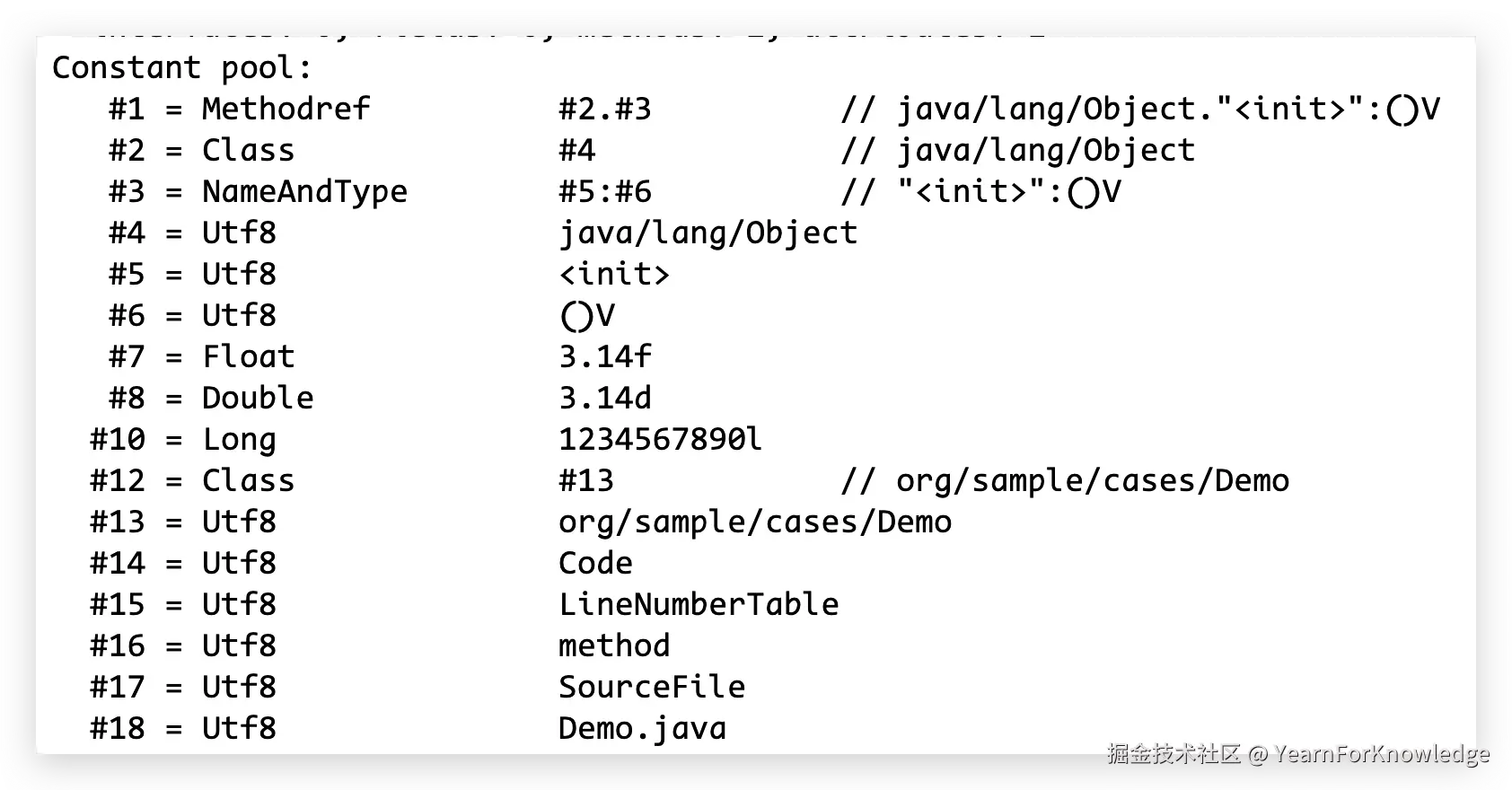 这里的constant pool是属于整个类的,包含了所有会出现的字符串和复杂的常量值,非常的直观,了解一下即可。 可以看到,这里的#8之后直接就到了#10,#10直接就到了#12,这里也是类似局部变量表的处理。
这里的constant pool是属于整个类的,包含了所有会出现的字符串和复杂的常量值,非常的直观,了解一下即可。 可以看到,这里的#8之后直接就到了#10,#10直接就到了#12,这里也是类似局部变量表的处理。
方法调用
前面已经提到了很多了,那么现在说一下方法的调用。后面会按照方法类型来介绍。
直接搞点简单的代码:
java
public void a() {
b();
}
public void b() {}编译结果为:
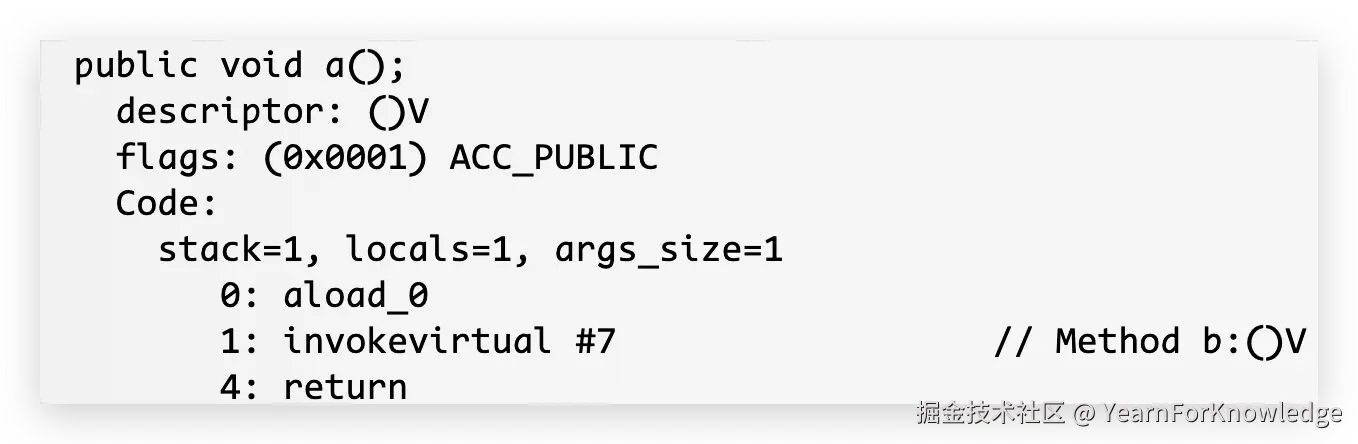 这就是最基本的实例方法的调用,非常的简单。
这就是最基本的实例方法的调用,非常的简单。aload_0就是把this给压入栈,如果忘了为什么有this,可以倒回去看看。 this压入栈后,通过invokevirtual指令,让vm通过this去执行方法,如果方法还需要多个参数的话,那么还需要把参数压入栈,此时,在this之后,会按照参数列表的顺序将参数逐个压入栈中,然后再调用invokevirtual。 看到这个#7,就是在常量池里的一个entry:
 也是很简洁明了的。
也是很简洁明了的。
如果将方法b改为static,那么字节码就更简单了: 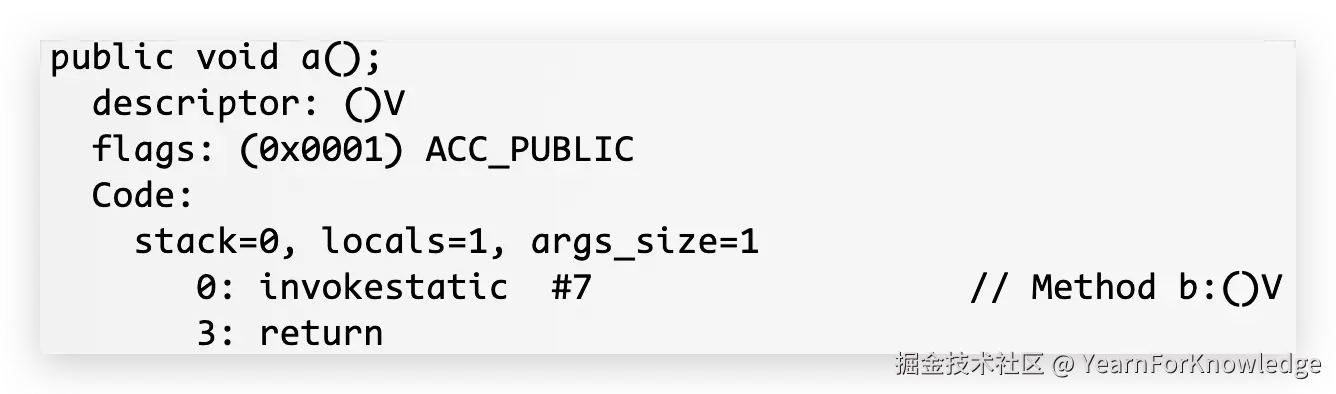 此时就直接通过invokestatic来调用静态方法即可。
此时就直接通过invokestatic来调用静态方法即可。
但是众所周知,invoke指令还有invokespecial和invokeinterface,以及一个invokedynamic。
本文不会介绍invokedynamic,因为这个比较复杂,足以再水一篇,避免篇幅过长,后面再补。
而invokespecial,这里需要提一嘴。很多文章提到,只要是private方法的调用,就会生成invokespecial,这一点是不完全对的。 这关联到一个jep,就是jep181,也可以参考apangin大佬的回答,简而言之就是,在jdk8以及之前的版本,private方法都是通过invokespecial调用的,然而在后续的版本,则改成了invokevirtual。
这是因为,在jdk11之前,如果一个内部类需要访问它的外部类的private方法,javac会为此生成一个bridge方法,也就是桥接方法。这是编译器通过桥接方法来间接的访问一个类的private方法的一个手段,而jep181提到了一个nest的概念,也就是把一个类和它的所有的内部类视作是同一个nest里的成员。那么,他们可以互相访问各自的private变量以及方法,而不再需要桥接方法。
如果大伙去搜一下jdk1.8和jdk24的JVM规范,就可以看到invokespecial的定义被修改了。在最新的jdk里,invokevirtual的定义也被扩宽了,说白了就是nest成员之间的互相调用可以直接使用invokevirtual。 在最新版本的jdk,invokespecial只负责构造方法以及父类方法的调用了。
而把这个指令给替换掉的原因可以简化为:
- 简化javac的工作
- 即使替换掉,也不会影响到性能。虽然invokespecial更容易被jit优化,但是invokevirtual最终也可以被jit给优化到很好
所以,具体的字节码我也不打算贴出来了,大家了解了之后自己去试一下不同版本的jdk里的javac去编译就可以看得到结果了。
至于说invokeinterface,简单定义一个接口再调用一下方法即可,大概的输出像这样:

那么,基于jdk24,稍微总结一下比较经典的几个invoke指令:
- invokevirtual和invokeinterface 这两个放在一起是因为,它们都需要到运行期间才能知道具体的方法载体是谁,也就是需要virtual lookup
- invokestatic和invokespecial 而这两个则是在编译期间就可以知道方法的载体,也就是可以static linking
那么这里也是总结了一下方法调用相关的字节码,还是比较简单比较好理解的。主要的就是在invokespecial的变化上,可能是比较少被提到的点,补充一下。以及invokedynamic这个强大的工具,后续我也打算补档一篇重点介绍一下。
构造方法
也是直接搞个简单的代码编译一下:
java
public class MyObject {
publci MyObject() {}
}编译结果为:
 稍微修改一下代码:
稍微修改一下代码:
java
public void create() {
Object o = new Object();
}编译出来就是:
 可以看到,在真正调用构造函数之前,还需要有new、dup这两个指令。从名字也可以很好理解它们的作用:
可以看到,在真正调用构造函数之前,还需要有new、dup这两个指令。从名字也可以很好理解它们的作用:
- new:可以看到它还带了个参数,就是类信息。这个指令就是告诉vm,根据这个类信息,申请一块空间来给新的对象使用。在申请成功之后,会将申请到的内存的起始地址作为返回值放在栈顶。
- dup:复制一个栈顶的值,再次压栈
这里的dup,其实就相当于是调用了一次aload_0,因为new返回的就是对象引用,这里dup是因为invokespecial需要消耗一个objectref,之后,就可以直接把原来new的结果给到本地变量表中的对象变量即可。
变量访问
也是直接一个代码示例即可,比较简单:
java
public class Demo {
int a;
private int b;
private static int c;
public void batchSet(int a1, int b1, int c1) {
a = a1;
b = b1;
c = c1;
}
public int getA() {return a;}
public int getB() {return b;}
public int getC() {return c;}
}编译结果为:
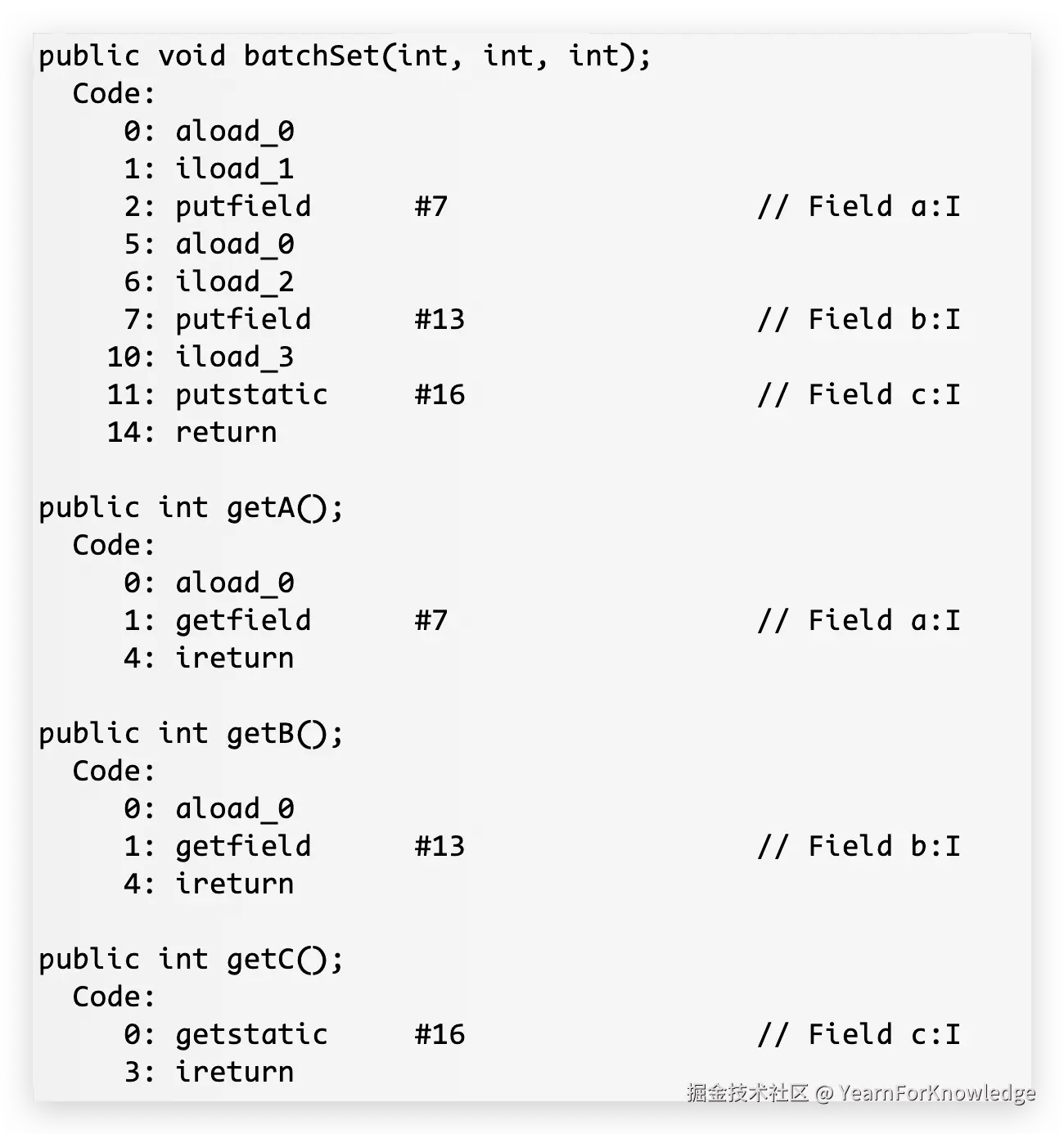 也很好理解,里面的各种getfield、setfiled、get/setstatic都非常的显而易见。
也很好理解,里面的各种getfield、setfiled、get/setstatic都非常的显而易见。
异常
实际还有一些和switch有关的,不过不是什么重点,就不提了。
还有一些想说的就是和异常相关的,直接看代码:
java
public void m() {
try {
tryItOut();
} catch (TestException e) {
handleException(e);
}
}
public void tryItOut() throws TestException {}
public void handleException(RuntimeException e) {}很标准的try-catch,那么看到编译结果:

也是非常好理解的,和上面那些方法的差别就在于这里多了个exception table。可以理解为,只要代码出现了try,那么字节码就会有一个exception table。 这个exception table的意思就是:如果from到to中间出现了type这个类型的异常,那么就跳转到target。
这里我还把locals也给打出来了,可以看到是2,第一个就是this,第二个就是catch里的exception变量。
看到上面的字节码,实际的方法调用,在第4行就结束了。后面的7-13都是catch的部分。
我们来详细看看为什么会有这些,首先,如果走到了7,可以看到它先store了栈里的值给到slot-1,也就是异常变量e,那么我们可以直接猜测到,如果出现了异常,那么会把栈清空,然后把发生的异常给放置到栈中,此时,栈里只有异常。 后面的几行就非常好理解,就是正常的调用handleException这个方法。
那么,如果我们加入finally的话,字节码会变成什么样呢:
java
public void m() {
try {
tryItOut();
} catch (TestException e) {
handleException(e);
} finally {
runWithNoDoubt();
}
}编译结果为:
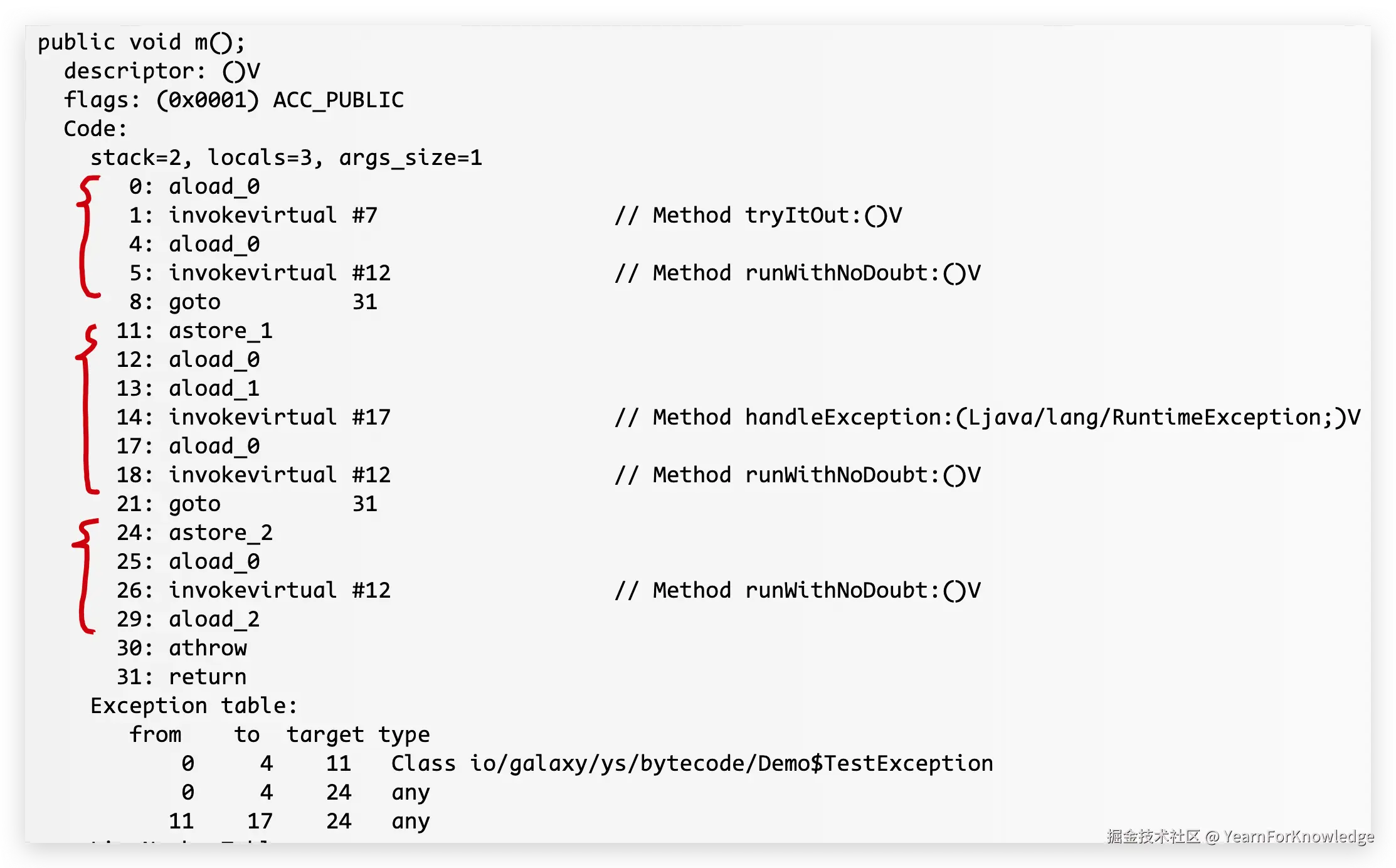
可以看到,exception table多了两个entry,并且,finally导致了==执行runWithNoDoubt==这一步被复制到了字节码中三个区域,也在图中标注了出来。 注意到这里的locals为3。除了this和exception变量,剩下一个slot是,用来保存任何在执行finally之前抛出的异常。 再结合到exception table里的内容,可以看到,type为any的时候,都会跳转到24行,那么前面说到,当出现异常的时候,JVM会清空整个栈,然后再把出现的异常放到栈中。 可以看到,24行的opcode,直接把这个异常给保存到了这个多出来的slot,然后执行finally方法,然后再把异常取出来放到栈上,再抛出去。
那么如果没有这个空位行不行呢?推理一下就知道了。假设此时抛出了个npe,那么:
- JVM清空当前方法的栈
- 将npe压入栈
- 根据这个npe去exception table找对应的handler,跳转
此时,栈里还有个npe,然后要立刻去执行finally的方法,注意到,invokevirtual的参数只需要一个。 所以,只要先aload_0,再invokevirtual就可以了。那么在方法结束之后,栈里还是保留了一个npe,然后再athrow、return,似乎也没什么问题。
但是,如果finally中会出现一些诸如pop之类的字节码,那么,是会有可能导致npe被异常弹出栈,导致异常丢失的。并且,从设计上来说,这个栈是用来保存opcode需要的元素的,但是此时的这个npe是需要得到保存,最后被抛出的,所以,需要有一个地方来暂存这个异常。
如果还是觉得迷糊的话,那么举个例子。如果没有这个额外的slot,在try抛出异常A的时候,清空栈,把A留在栈里,然后执行finally;此时finally再次抛异常,再次清空栈,把B留在栈里,然后athrow,返回。 可以看到,A没有得到正确的处理就被异常处理机制给清除掉了,也就是可能会被吞掉了一个异常。
而从设计哲学上来说,发生过的异常应该是需要得到处理的,不论它是被抛出去还是被指令消耗掉,都需要暂存,而字节码的设计哲学里,operand stack只用来存放操作数,而不作为一个暂存箱使用,所以需要额外找个地方来存放这个异常。
所以,这只是一个比较隐晦的点,不过还是值得提一下的。
那么到此,字节码基本上介绍的差不多了。下面打算结合一个例子来加深一下理解。
示例代码
代码如下:
java
public static int method(int i) {
try {
if (i == 0) {
throw new Exception();
}
return 1;
} catch (Exception e) {
throw e;
} finally {
return 2;
}
}同样,看一下编译的结果:
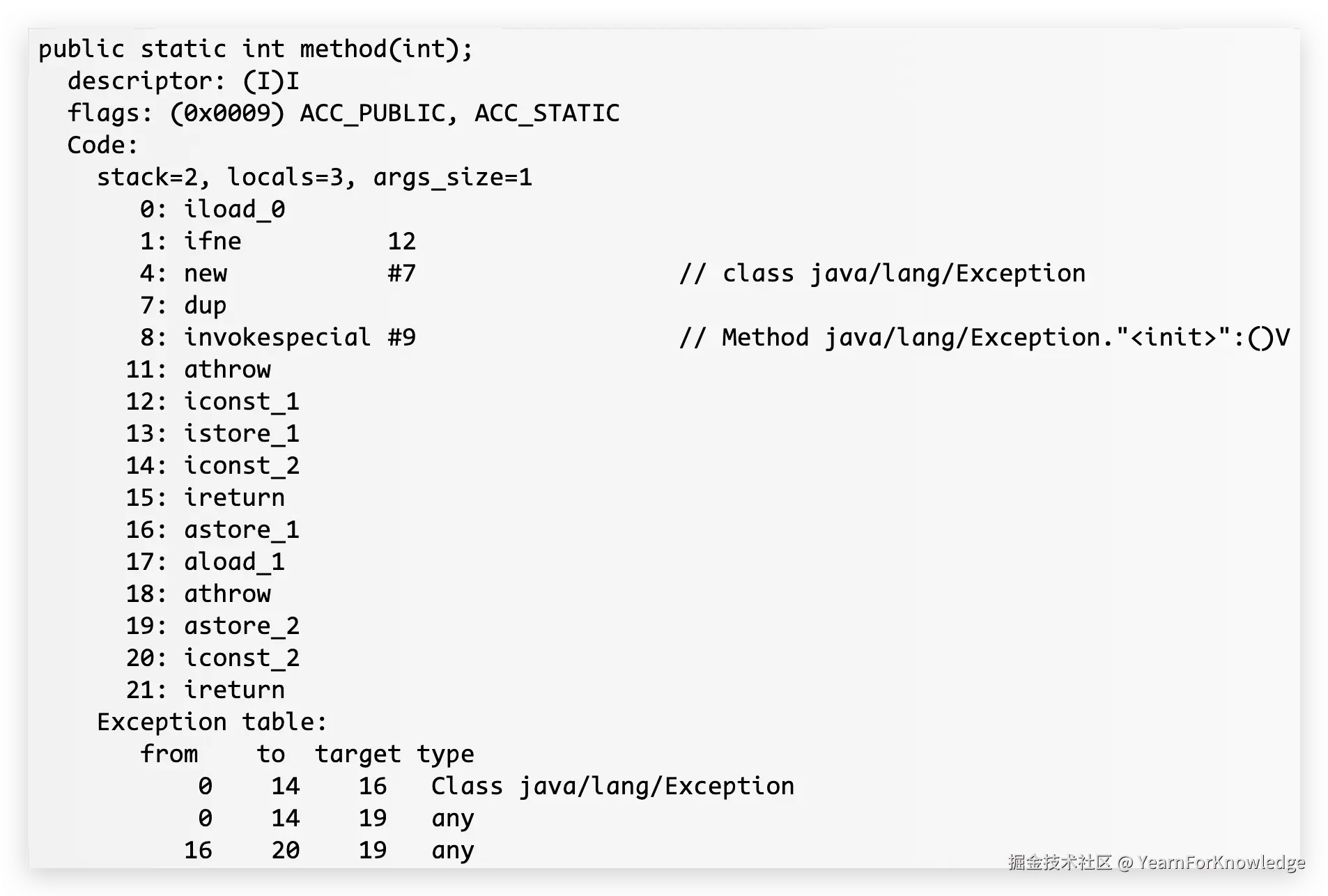 其实还是很简单的,最好在看下面的解释之前,自己尝试理解一下这里的运转流程:
其实还是很简单的,最好在看下面的解释之前,自己尝试理解一下这里的运转流程:
- 首先,0-8就是参加了一个Exception,11就是直接抛出去
- 那么根据exception table,满足第一个entry的条件,跳转到16
- 16这里熟悉的astore_1,也就是保存一下这个异常
- 17-18就是重新抛出去
- 那么,满足exception table最后一个entry的条件,再跳转回19
- 那么,还是一个astore,也就是保存这个被抛了两次的异常,此时slot-1、slot-2都是这个自己new出来的Exception,并且也顺便验证了,locals=3
- 最后压个常数2,直接返回
有没有发现,在try、catch里的异常并没有被抛出去,而是被finally里的return给正常返回了一个数值。所以,在finally里面出现return是一个需要注意的地方,它很可能会让程序出现异常被吞掉的情况。
关于异常的更多的东西
从前面说到的,异常处理多出来的slot中延展出来的一个内容,感觉是可以提一下。
主要是查资料的时候看到JLS的一部分,大致的意思就是在jdk1.7之前,会出现异常丢失的情况:
- 如果try因为原因r而突然完成,比如说异常a,那么finally会执行
- 如果finally也因为原因s而突然完成,比如说异常b,那么整个try就因为s突然完成,那么r就会被完全丢弃 也就是类似于前面提到的场景,但是这里是jdk主动选择抛弃掉这个a,那么导致异常a丢失。
而在jdk1.7之后,引入了一个suppressed exceptions,可以参考jsr334,主要是配合try-with-resource的:
- Throwable添加了两个api:
public final void addSuppressed(Throwable exception)public final Throwable[] getSuppressed()
这两个方法会在try-with-resource中被隐式的调用,就是为了解决上面的问题。但是,如果只是简单的在>jdk1.7的jdk中,通过编写简单的try-catch-finally,并不能得到这个suppressed exception的信息。 必须编写try-with-resource的语法,才能看到异常被suppressed。
至于说try-catch-finally看不到的原因,经过我查了一些资料发现,大概率是因为,不想破坏旧代码的语义,而选择了保持try-catch-finally的行为,给try-with-resource引入新行为。
所以,try-catch-finally仍然是有吞异常的可能的。所以,在finally中,不要做任何的return/throw,才是最安全的做法。
通过这样的代码可以看到suppressed exception:
java
public class Demo {
static class Resource implement AutoClosable {
public void use() { throw new Exception("exception from use"); }
@Override public void close() { throw new Exception("exception from close"); }
}
public static void main(String[] args) {
try {
try (Resource r = new Resource()) { r.use(); }
// 隐式 finally
} catch (Exception e) {
if (e.getSuppressed().length != 0) {
for (Throwable t : e.getSuppressed()) {
System.out.println(t);
}
}
}
}
}那么这样就可以看到,有一个被suppressed的异常了。
如果真正的跑一下这个demo,会发现,似乎主异常并不是finally里的那个,而是try里的那个。
那么原因是,jdk认为,try-with-resource里的异常优先级,try > finally,所以在try-with-resource里,try里的异常才是主异常,而finally的异常则会被suppressed,附加到try异常里。
所以,总结一下就是:
- 在try-catch-finally中,优先级为:finally return > finally throw > try throw
- 而在try-with-resource中,try里的异常是主异常,如果close方法(因为相当于隐式的在finally中调用close)抛出异常,那么它会被suppressed并附加到try异常中
相关链接:
总结
那么到此为止,相信大伙以后都可以很顺畅的看懂字节码了,这东西可以让大伙更精确的知道VM在执行代码的时候到底是怎么个样子的,而再往下,就涉及到了机器指令,比如说汇编这种,那这个就不是一两篇文章能搞定的事情了,大伙可以自行了解。
至于说invokedynamic,后续大概率是会写出来的,因为jdk后续很多feature都会使用到这个指令,自己也可以通过这个指令来实现一些奇妙的工具。