写在开篇
看过上一节的朋友是不是很期待这一小节?嘿嘿,那现在就开讲吧。
首先,我们来认识一下cheerio库。
cheerio 库是一个基于 Node.js 的轻量级 HTML/XML 解析工具,专门用于在服务端高效处理网页内容,其设计灵感来源于前端 JavaScript 的jQuery库,语法和操作方式高度相似,因此学习成本极低。
上面是豆包关于cheerio库的介绍,简单来说,cheerio库就是可以像jquery一样操作html中的dom节点的一个JS库,两者区别就是cheerio可以将html字符串转换成dom节点后再进行操作,jquery库是直接操作dom节点。
技术方案设计
知道了cheerio库的作用后,"chrome.scripting + cheerio"这个方案的流程理解起来就真的很容易了。
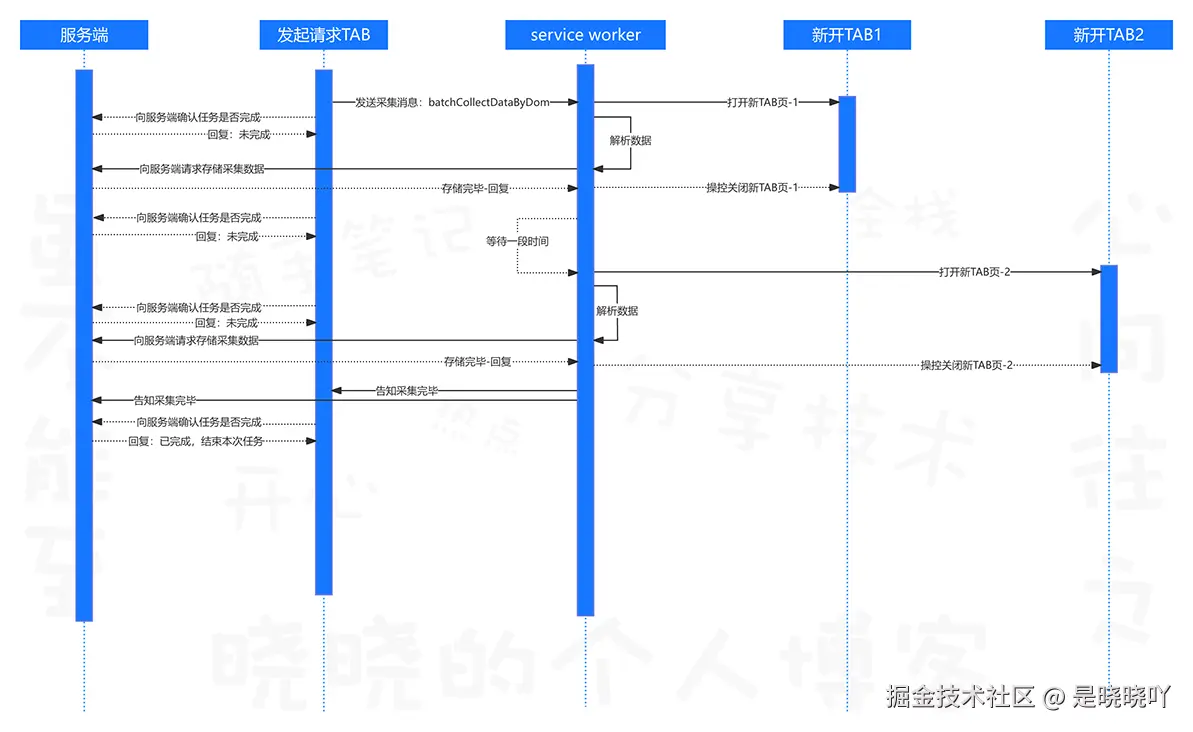
浏览器插件使用scripting函数解析DOM数据
结合上图,流程说明如下:
- service Worker打开TAB;
- 由Service Worker使用chrome.scripting函数获取新TAB页body下的所有dom节点的字符串;
- 利用cheerio进行dom节点的解析获取到数据;
- 将数据抛给第三方存储系统或向发起请求的TAB页抛出反馈信息。
-
- 数据的抛出可以单个单个向存储系统/请求侧抛出,也可以整体抛出,在这个方案中不会有多大影响(我们这里使用单个单个抛给服务端的方式,减少各个采集过程的相互影响);
特别需要提醒的是,在这个方案中,新打开的TAB页不过就是展示出数据等待Service Worker去取而已,并不会涉及到新开tab页中的浏览器API的调用。
另外,最重要的一点是,由以上流程图可以清晰的看出 单个链接的采集流程是同步执行的、两个链接采集之间也是同步执行的,所以,无论是流程理解上还是代码编写上,对于技术人员来说简直就是顺手拧开瓶般轻松;
方案落地与Demo
讲完理论的东西,我们当然要落到代码上啦~
首先,还是在发起的TAB页中插入可执行按钮。
js
// content.js
const _container = document.getElementById('ce-test-id');
const _btnDom = document.createElement('button');
_btnDom.innerHTML = '点击 BY SCRIPT';
_container.appendChild(_btnDom);
_btnDom.addEventListener('click', async function () {
contentToServiceWorkerByLongConnection({
command: 'batchCollectDataByScript',
payload: {
batchId: uuidV4(), // 一般这个批次ID由服务端生成,这里只是为了演示方便,所以直接由前端产生
urlList: ['https://www.baidu.com/', 'https://www.baidu.com/'], // 这里为了测试,所以放了两个一样的地址,只是为了有更直挂的感受
},
});
});接着就是Service Worker的事情了,很简单的同步代码。
js
// service.worker.js
import { v4 as uuidV4 } from 'uuid';
async function _batchCollectDataByScript(payload, port) {
const { batchId, urlList } = payload;
for (const _url of urlList) {
// 一般在这里做一些参数的校验、获取等操作
console.log('_batchCollectDataByScript===新TAB准备打开', _url);
const _tab = await chrome.tabs.create({ active: false, url: _url }); // 自动打开页面,active:false 代表的是静默打开tab页
console.log(`_batchCollectDataByScript===新TAB已打开,TAB ID - ${_tab.id}`);'
let _urlDetail;
let _checkLoopIndex = 0;
while (_checkLoopIndex < 20) {
await sleep(2000); // 每2秒检查一次,最多检查40秒还不出结果就直接判为失败,实际运用中需要根据源网站数据实际情况
console.log(`_batchCollectDataByScript===第${_checkLoopIndex + 1}次检验`);
++_checkLoopIndex;
const _itemId = uuidV4(); // 为本次请求生成一个唯一的ID
const _itemMessage = {
url: _url,
batchId: batchId, // 批次ID
itemId: _itemId, // 本次请求的唯一ID
tabId: _tab.id,
status: 'running',
startTime: new Date().getTime(),
loopIndex: _checkLoopIndex,
};
// 或为了交互、或为了保持content与service长链接通信通道,一般,我们会每次请求阶段给发出采集请求的content层回复一条消息;
// 这块逻辑和本章的内容没有非常直接的关系,是出于技术方案的完整性考虑
port.postMessage({
command: 'resolveBatchCollectDataByDom',
payload: _itemMessage,
});
const _result = await chrome.scripting.executeScript({
target: { tabId: _tab.id },
func: () => {
return document.body.innerHTML; // 这里之所以直接获取body数据,是因为除了数据节点,很有可能需要处理其他异常场景
},
});
if (!_result) {
continue;
}
console.log('_batchCollectDataByScript===_result', _result);
let _body;
for (const _item of _result) {
if (_item.result) {
_body = _item.result;
break;
}
}
if (!_body) {
continue;
}
const _bodyDom = load(_body);
_urlDetail = _bodyDom('#su').val(); // 我们这里只是举例获取一个数据,真实业务场景需要自行调研哦~
if (_urlDetail) {
break;
}
}
chrome.tabs.remove(_tab.id, () => {
console.log(`选项卡${_tab.id}已经关闭`);
});
console.log('_batchCollectDataByScript===_urlDetail', _urlDetail);
if (!_urlDetail) {
// 这里需要向服务端/用户侧直接发送采集结果;
continue;
}
// 接下去就需要根据获取到的_urlDetail判断是否是需要的数据;
// 比如是否需要让用户登陆、是否被风控了呀,一般都可以在dom节点中判断出来的(就是上一章中content层做的事情);
// 解析完数据之后,就可以向服务端/用户侧发送请求了;
// const _result = await fetch('xxxxx',{
// method: 'POST',
// body: JSON.stringify({
// batchId,
// url: url,
// status: collectStatus,
// result: collectResult
// }),
// headers: {
// 'Content-Type': 'application/json',
// },
// });
// 这个30秒的等待时间,一方面是为了不给源网站造成困扰,另一方面是一分钟以上的打开TAB页的时间间隔更加贴近用户操作路径;
// 如果可以做的更精细一些的话,可以产生一个随机数来做间隔时间,也可以根据不同的站点,缩短间隔时间
await sleep(10000);
}
// 因为整个过程是同步执行的,所以代码执行到这里就说明所有的链接都已经被采集过,不管成功与否,服务端/用户侧都已经接收到所有链接的结果;
// 当然,最好再向服务端/用户侧发送请求:告知服务端本次采集批次已经采集完毕;
// const _result = await fetch('xxxxx',{
// method: 'POST',
// body: JSON.stringify({
// batchId,
// status: 'finish',
// }),
// headers: {
// 'Content-Type': 'application/json',
// },
// });
// 2. 向Content层发送消息告知"本次采集完毕",请自行去服务端获取采集结果;
port.postMessage({
command: 'resolveBatchCollectDataByScript',
payload: {
batchId,
status: 'finish',
},
});
}
chrome.runtime.onConnect.addListener(function (port) {
port.onMessage.addListener(function (message) {
const { command, payload } = message;
if (command === 'batchCollectDataByScript') {
_batchCollectDataByScript(payload, port);
}
});
});以上代码实践后,就会有这样的效果: 【👉 由于这里不能上传视频,麻烦移步我的博客去查看测试流程交互视频吧】
与上一节方案对比
看到这里,你是不是也意识到:当数据存在于用户可视页面上时,本文阐述的方案更便捷呢?那接下来,我们就好好整理下两个方案到底有哪些区别吧!
-
首当其冲的当然是最大的优势:在足够满足技术方案完整性的情况下,涉及的技术端之间的交互更少;
这里说的是,虽然方案设计时我们加入了服务端的内容,但事实上,因为本次方案不像上一小节的方案具有并发问题,也就是插件端存储数据的能力就完全可用了,即,服务端的存储可要可不要;
另一方面就是,虽然本小节的方案依然涉及到了TAB页的操控,但新TAB页中不会涉及到消息通信、浏览器API的调用,相当于出现异常逻辑的可能性更少了;
-
第二个就是本文方案是同步执行,在开发方面对技术人员的比较友好(不仅流程理解性高,而且编码量具少);
-
兜底策略上,本方案只需注意dom节点的出现时机即可;
-
但从执行时间上来讲,其实两个方案的执行时间是差不多的,只不过本方案更方便去调试、缩短执行时间。
上一节的方案中有几个必要的停留时间:链接与链接之间的间隔时间、Service Worker等待Content层准备好的时间、Content层需要等待数据出现的时间、为避免消息丢失而需要等待的时间、最后判断是否全部链接采集完毕的等待时间;
本方案的必要停留时间就很少了:链接与链接之间的间隔时间、Content层需要等待数据出现的时间;
相比较之下,越少的等待场景,调试起来肯定越简单;
写在最后
到此,应对源网站风控的几个方案就讲完了,后续如果有其他方案的,会继续更新,望各位朋友持续关注哈~
今日与君共勉:作为前端工程师,在构思技术方案时,需以全局视野构建兼具完整性与前瞻性的体系,确保方案各环节逻辑自洽、无遗漏死角。同时,需将用户交互体验置于核心位置,从操作流畅度、视觉反馈到场景适配性等维度精细打磨,让技术方案不仅实现功能目标,更能为用户带来自然、愉悦且高效的使用感受。