1.InnoDB逻辑存储结构
表空间->段->区->页->行->数据
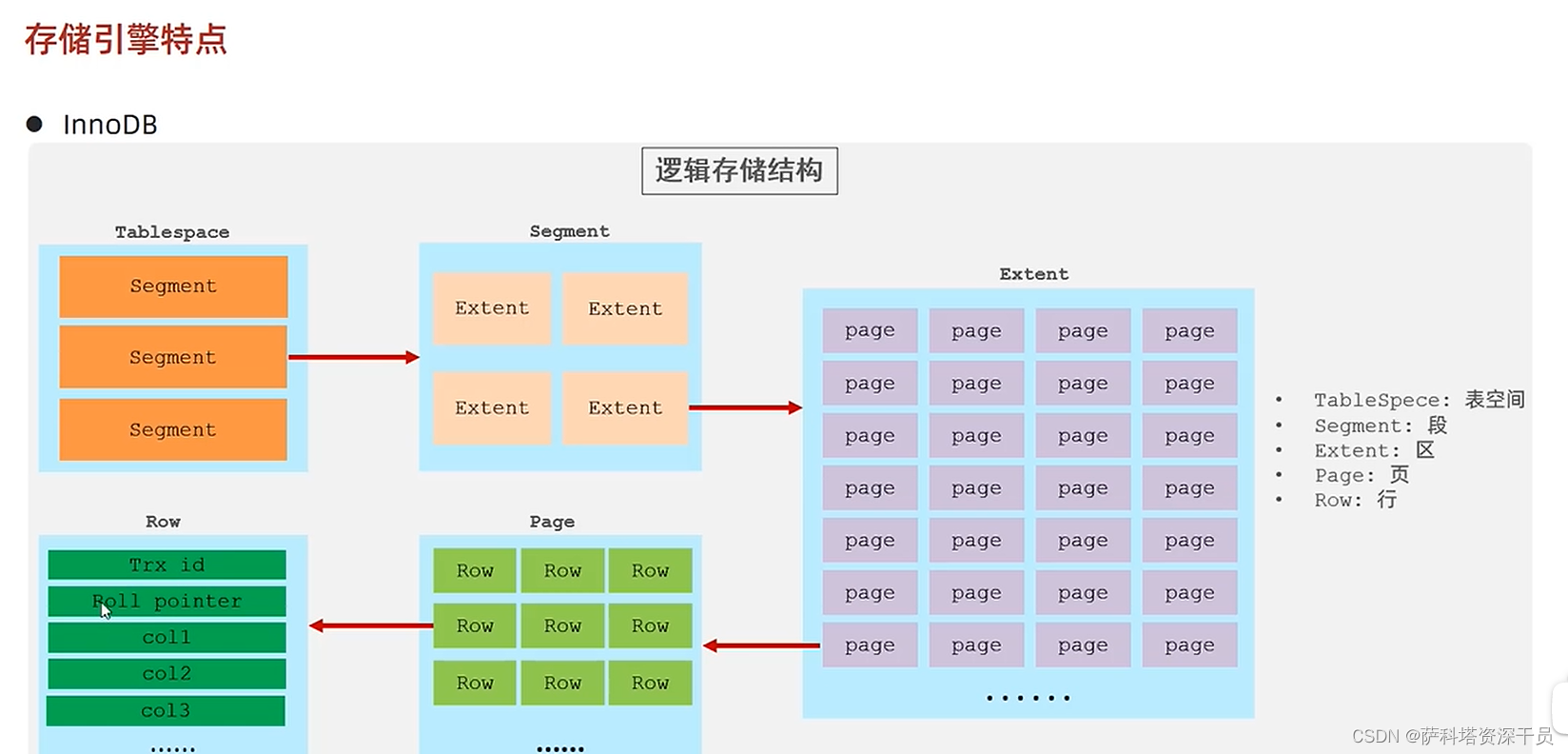
表空间:覆盖了所有的数据和索引,系统表在系统表空间,还有默认表空间等
段:多个段组成表空间
区:多个区组成段,一般每个区的大小通常是1M
页:默认64个连续的页组成一个区,每个页的大小默认是16KB
行:多行数据在都在页里。
MySQL每次去磁盘读取数据到内存时,都至少将一个页的数据加载到内存里。
在数据库中,不论读取一行还是多行都需要将一个页或者多个页的数据加载到内存中。页是MySQL读取数据的最小单位。
2.MySQL的物理存储结构
2.1. 5.7版本
InnoDB
表&索引数据:ibd文件
表结构:frm文件
redo log文件:用于崩溃恢复的日志文件之一
系统元数据:存储元数据和存储引擎无关
MyISAM
表结构:frm
数据:MYD
索引:MYI
没有redo log文件
2.2. 8.0版本
InnoDB
表数据&索引:ibd文件
表结构:被剔除了,表结构被放到系统元数据里了,information_schema
redo log文件:用于崩溃恢复的日志文件之一
MyISAM
表结构:被剔除了,表结构被放到系统元数据里了,information_schema
数据:MYD
索引:MYI
MySQL8.0推出了DDL原子性操作,针对原子操作可以通过information_schema
来实现定义表信息的一致性和可靠性。
3.MySQL常见存储引擎的区别
| 功能 | InnoDB | MyISAM |
|---|---|---|
| 聚簇索引 | 支持 | 不支持 |
| 表锁 | 支持 | 支持 |
| 行锁 | 支持 | 不支持 |
| 数据缓存 | 支持(buffer pool) | 不支持 |
| 外键 | 支持 | 不支持 |
| MVCC | 支持 | 不支持 |
| 事务 | 支持 | 不支持 |
4.AHI
自适应hash索引,innodb特有。
当AHI发现某些索引值使用的非常频繁,则会建立hash索引来提升查询效率。
AHI的操作不需要做任何操作,默认即可。在AHI生成自适应hash索引后,查询效率可以从B+Tree的O(logn)提升到O(1)。
5.Buffer Pool
Buffer Pool是MySQL主存中的一个区域。使用InnoDB存储引擎时,会将数据从磁盘中拉取到Buffer Pool中。而这些数据是以页的形式存在。官方文档建议80%的物理内存都配置给Buffer Pool中。
当Buffer Pool 的数据发生修改和数据库不一致时,MySQL通过Page Cleaner线程池(默认1个线程,可配置)负责脏页刷盘,避免阻塞前台查询,将Buffer Pool中的数据同步到idb文件中。
并且在Buffer Pool发生修改之前,会先将数据变化的日志写入到redo log(通过log buffer实现)中。
5.1.存储结构和内存淘汰机制
存储结构是将整个Buffer Pool分成了两个区域
New Sublist 5/8 最经常被访问的数据
Old Sublist 3/8
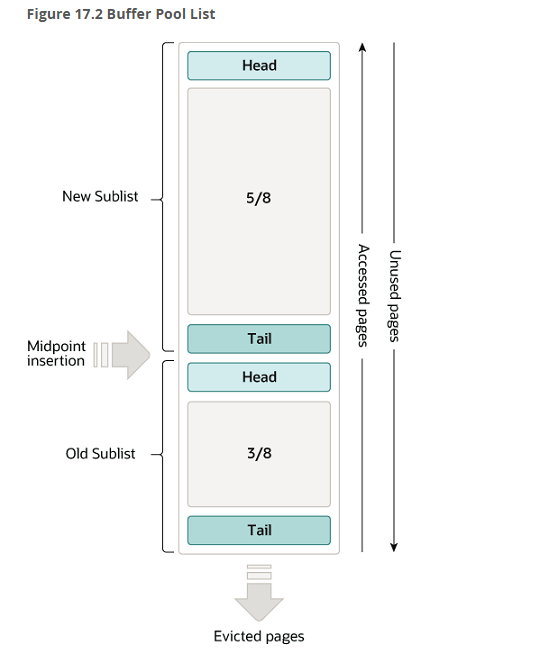
内部数据都是页,页是基于链表链接的。
内存淘汰机制是LRU(最近最少使用Least Recently Used)
当需要将磁盘中获取的页存储到Buffer Pool时,会先将这个页的数据存放到Old Sublist的head位置。如果某个页没操作,慢慢的会被放到Old Sublist的tail位置。当又有数据需要存放到Buffer Pool时,如果内存不足,则会淘汰Old Sublist的tail位置的数据。
当某个页的数据被操作了(需要满足一定规则,被高频操作),就会放到New Sublist的head位置。
内存淘汰时有限淘汰old的tail部。当old区域没有内存可以淘汰时,才回去淘汰new区域的内存。
5.2.多线程问题
buffer pool是一个共享区域,多个线程同时操作时会产生指针问题。所以操作需要用到锁。
buffer pool是支持多实例的,可以通过innodb_buffer_pool_instances去设置实例个数,最大设置64个,默认1个。多个实例时,每个实例至少分配1个G内存才会生效。
注意:多个buffer pool之间的数据是不一样的!知识根据hash将数据分布到了不同的buffer pool中。
6.Change Buffer
Change Buffer是在mysql中使用二级索引(非聚集索引)去写数据时优化的一个策略。实在进行DML(CRUD)操作的一个优化。
如果写的操作是非聚簇索引,并且对应的数据页不在Buffer Pool中,此时不会立即将磁盘中的数据库页加载到Buffer Pool中。而是先将写操作扔到Change Buffer中,做一个缓冲。当要修改的这个数据页被读取时,再将Change Buffer中的记录合并到Buffer Pool中。减少磁盘IO次数,提高性能。
注:Change Buffer占用的是Buffer Pool的内存。
如果业务场景写多读少,则可以调大Change Buffer的占用空间。
整体流程:
当更新一条记录时,该记录在BP中,直接修改对应的页,进行一次内存操作。
当更新一条记录时,该记录不在BP中,在不影响一致性的前提下,会将更新操作缓存在CB中,不去做磁盘IO操作。
当查到该记录时,会将这个记录扔到BP中,并将CB中与这条数据的相关的操作合并到BF中。
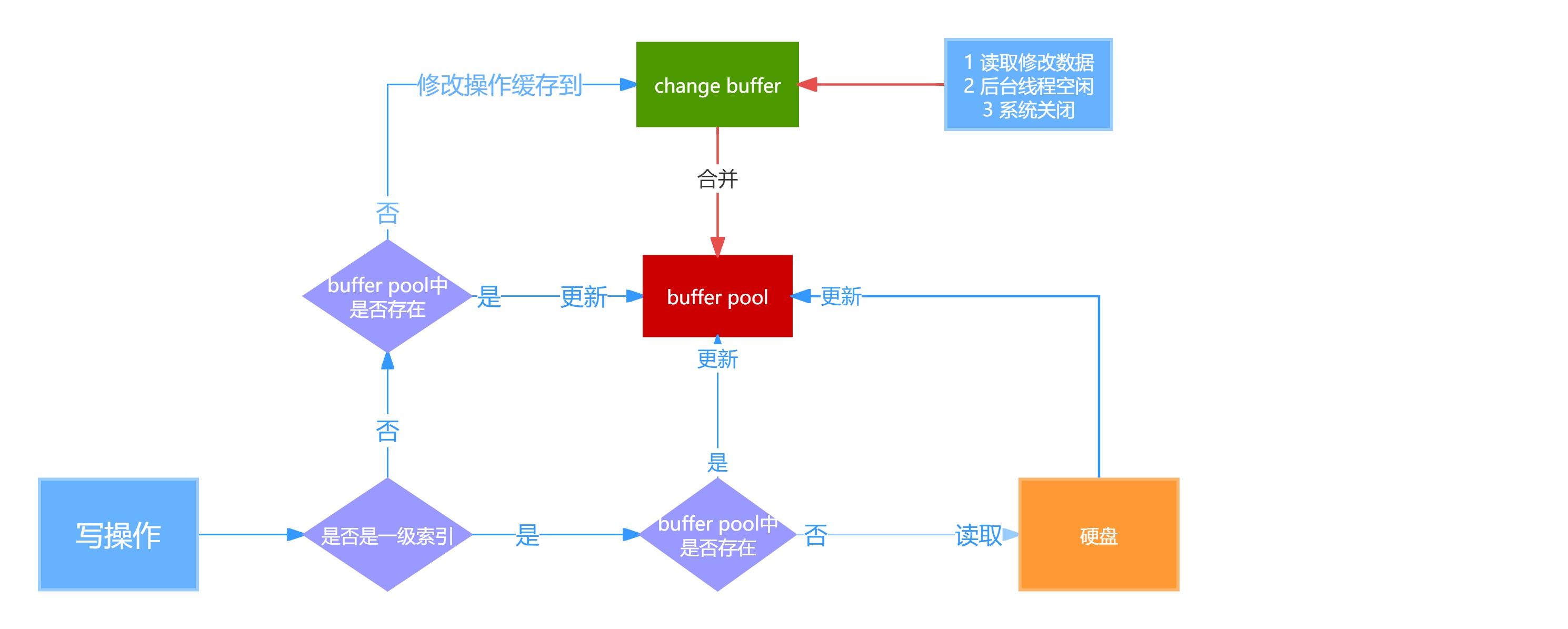
6.1.如果Change bufferr同步之前,mysql宕机了怎么办?
通过redo log可以实现事务提交之后,数据不会丢失。
7.Log Buffer
innodb特有的,是存储要写入磁盘的日志文件的一片内存区域。主要是redo log。默认占用内存16M。
减少写操作时,日志写入的IO损耗。
8.Redo Log
innodb独有,让mysql有了崩溃恢复能力(一般配合bin log)。
redo log的结构:存储表空间号+数据页号+偏移量+具体修改的数据...
在修改buffer pool和change buffer之前,会先记录redo log(将日志写到log buffer中)。
将log Buffer中的数据刷新到磁盘有的触发时机根据配置项进行配置:
innodb_flush_log_at_trx_commit: 0 1 2
0:每次事务提交,不刷盘,后台线程去刷盘,每秒一次,如果log buffer超过设置空间的一半,也会刷盘。
1:每次事务提交后,立即刷盘(默认值),此时后台线程仍然运行。
2:每次事务提交后,将log buffer的数据刷新到系统内存中
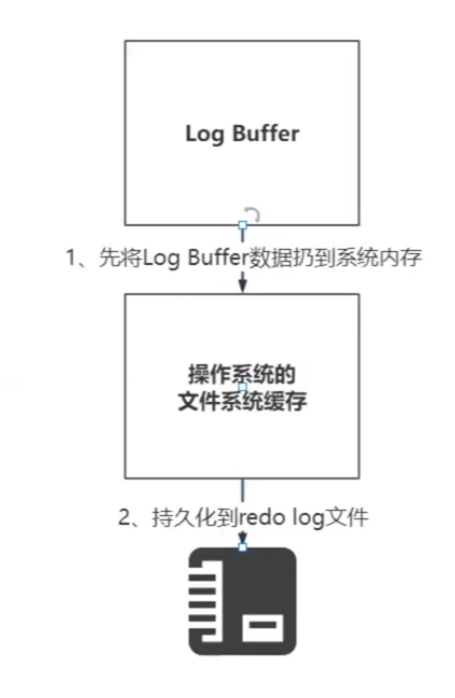
思考:如果设置为1的话,那么如果事务还没有提交的时候,后台线程将log buffer中的数据刷新到了系统内存中,那么事务回退是否会造成数据不一致的问题?
8.1.redo log的存储形式
redo log是顺序读写的。并且redo log是以文件组的形式存在的。5.7中默认是2个文件,可以配置为多个文件,每个文件的大小一致。
在写redo log时会用到两个指针:
write ops:记录当前要写的位置,一边写,一边往后移。
check point:记录当前要擦除的位置,一边删,一边后移。当文件写满了,需要删除之前的数据,才能继续写。
8.2.为什么数据不直接写到具体的表,而是先写到redo log中?
redo log是顺序写入,速度快。如果写到表里,表中的数据,地址是随机的,会影响事务提交对的效率。如果要回滚事务,还得随机寻址。
9.bin log
bin log文件不依赖于存储引擎而存在,记录数据的写操作。
主要用于MySQL的主从复制,数据备份和数据的一致性。
9.1.bin log存储格式
分为三种
statement:存储每个造成数据修改的sql,如在sql中使用了不确定函数比如now(),那么恢复数据时,可能导致数据不一致。
row:(默认)不但具备sql,还具备当前行的数据,避免了函数导致的问题。但是会占用更多的数据。
max:混合,会判断当前数据是否会造成不一致问题,如果会则使用row,不会则使用statement。
9.2.bin log存储数据的时机
提交时机和事务挂钩。当事务提交后,会将事务中的内容提交到bin log cache中。
与log buffer不同的是,mysql 会给每一个线程都分配一个bin log cache。因为一个事务中的bin log不能拆分,无论多大的事务,都要保证一次性写入。如果多个线程共用一个bin log cache,则会发生不同事物的bin log事件交错存储。
bin log cache的大小可以自定义,默认32KB。但是如果事务太大,超过了binlog_cache_size怎么办?mysql会自动扩容内存,不能超过max_binlog_cache_size。但是这个值特别大,基本不用考虑长事务导致cache超出的问题。但是开发中仍然要避免长事务。
binlog cache何时同步到磁盘根据配置项来配置。
sync_binlog 取值0 1 N
0:每次提交时,都会将cache中的数据同步到系统的内存中。至于系统内存同步到硬盘,由操作系统控制。
1:默认值,每次提交事务都会执行fsync操作,确保binlog cache中的数据一定能落到本地磁盘中。数据是完整的。
N:大于1的值,每次提交事务的执行write操作,当积累了N个事务才会主动的去执行fsync。虽然能提高IO瓶颈,但是可能造成数据丢失。
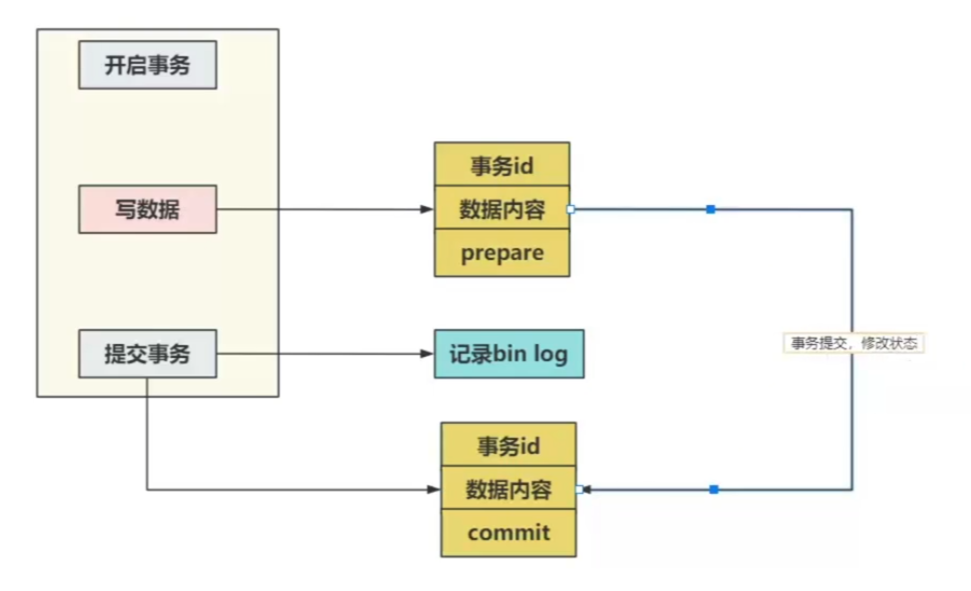
10.二阶段提交
redo log让mysql有了崩溃恢复的能力,在事务的执行过程中会不断地写入。
bin log 让mysql有了集群架构的一致性,仅在事务提交的时候会写入。
当redo log和bin log文件产生不一致时,如
原先age = 18
执行SQL:update table set age = 38 where id = 1;
假设redo log 在事务还没有提交的时候,将age = 38持久化到了redo log文件中。
但是事务没有正常提交,此时bin log中age还是18,此时两个日志文件发生了不一致。
此时MySQL崩溃重启。主库就会出现age = 18,而从库age = 38。因为主从是根据bin log同步的。而崩溃时根据redo log恢复的。
二阶段就是用来解决上述问题。
redo log 的写入分为了两个阶段:prepare 和commit。
事务还没有提交的时候,redo log中的数据是prepare阶段,而当真正提交了数据之后才是commit阶段。
MySQL在恢复时,会判断如果redo log中的数据处于prepare阶段,并且bin log中没有对应的数据,则不会恢复该数据。
如果redo log中的数据处于prepare阶段,并且bin log中有对应的数据,则会恢复该数据。
所以在恢复数据时以bin log为主。
11.undo log
innodb引擎的一个日志文件。
存储数据的历史版本,一方面是为了做事务回滚时,可以找到需要回滚的数据内容,另一方面是MVCC的多版本并发控制操作时,需要读取快照信息,就要在undo log里面去读。
12.事务的常见问题
12.1.事务的特性
原子性:事务是一个不可分割的工作单元,事务中的所有操作要么全部执行成功,要么全部不执行
隔离性:多个事务并发执行时,一个事务的操作不应影响其他事务,即事务之间相互隔离。
持久性:事务一旦提交,其对数据库的修改就是永久性的,即使系统崩溃或重启,数据也不会丢失。
一致性:事务执行前后,数据库必须从一个一致的状态转移到另一个一致的状态。事务提交后预期的结果和最终的结果是一致的。
12.2.事务的并发问题
脏读:读取到其他事务未提交的数据,若该事务回滚,则读取到的数据无效。
不可重复读:同一事务中多次读取同一数据,结果可能不同(其他事务已修改并提交)。
幻读:同一事务中多次查询同一范围的数据,结果集可能不同(其他事务插入了新数据)。
12.3.事务的隔离级别
隔离级别 脏读 不可重复读 幻读 并发性能
读未提交ru 可能 可能 可能 最高
读已提交rc 不可能 可能 可能 高
可重复读rr 不可能 不可能 可能 中
串行化 不可能 不可能 不可能 最低
13.bin log 和 undo log的存储位置
bin log的存放路径,根据log_bin配置,默认存放到数据目录下
8.0版本默认将undo log存放到数据目录下。