1. Streamlit概述
Streamlit(/ˈstriːm.lɪt/,斯垂姆利特)是一个开源的Python库,专门为机器学习和数据科学团队设计,用于快速构建和共享美观、交互式的数据应用。自2019年发布以来,Streamlit因其简洁性、高效性和强大的功能集,迅速成为数据科学家和工程师创建数据驱动应用的首选工具之一。
1.1 核心设计理念
Streamlit的设计遵循几个关键原则:
- 纯Python开发:无需前端经验,仅用Python即可创建完整的Web应用
- 即时反馈:每次保存代码变更都会实时反映在应用中
- 极简API:提供直观的API,减少样板代码
- 无缝集成:与主流数据科学生态系统(Pandas, NumPy, Matplotlib等)完美兼容
1.2 技术架构
Streamlit采用独特的"脚本即应用"架构:
- 应用代码从上到下执行,每次交互都触发完整脚本重新运行
- 内置智能缓存机制优化性能
- 基于React的前端渲染,提供现代Web体验
- 使用WebSocket实现前后端实时通信
1.3 代码示例
本文中所有代码示例都是完整可运行的Streamlit应用,只需安装Streamlit库即可运行:
bash
pip install streamlit pandas numpy plotly scikit-learn运行示例
bash
streamlit run 示例文件名.py
完全可运行的示例
python
import streamlit as st
import pandas as pd
import numpy as np
# 最小化可运行示例
st.title("Streamlit 最小示例")
st.write("下面是一个简单的DataFrame展示:")
# 创建示例数据
data = pd.DataFrame({
'A': np.random.randn(50),
'B': np.random.randn(50)
})
st.dataframe(data) # 交互式表格
st.line_chart(data) # 折线图
2. 核心功能与高级特性
2.1 基础组件
python
import streamlit as st
import pandas as pd
import numpy as np
# 文本显示
st.title("完整基础组件演示")
st.header("这是一个头部")
st.subheader("子头部")
st.text("固定宽度文本")
st.markdown("**Markdown** 支持 *格式化*")
st.latex(r"\sqrt{x^2 + y^2}") # LaTeX公式
# 数据展示
df = pd.DataFrame({
'日期': pd.date_range(start='2023-01-01', periods=10),
'值': np.random.randn(10).cumsum()
})
st.dataframe(df.style.highlight_max(axis=0)) # 交互式DataFrame
st.table(df.head(3)) # 静态表格
# 指标显示
st.metric("温度", "25.6 °C", "1.2 °C") # 当前值,变化值
# 图表
st.line_chart(df.set_index('日期')) # 折线图
st.area_chart(df.set_index('日期')) # 面积图
st.bar_chart(df.set_index('日期')) # 柱状图
2.2 交互组件
python
import streamlit as st
import pandas as pd
st.title("交互组件演示")
# 用户输入
name = st.text_input("请输入您的姓名", "张三")
age = st.slider("选择年龄", 0, 100, 25)
options = st.multiselect(
"选择兴趣",
["运动", "音乐", "阅读", "旅行", "美食"],
["音乐", "阅读"]
)
# 日期输入
appointment = st.date_input("预约日期")
time = st.time_input("预约时间")
# 颜色选择器
color = st.color_picker("选择颜色", "#00f900")
# 按钮与操作
if st.button("提交信息"):
st.success(f"""
已提交信息:
姓名: {name}
年龄: {age}
兴趣: {', '.join(options)}
预约时间: {appointment} {time}
颜色: {color}
""")
# 文件上传示例
uploaded_file = st.file_uploader("上传CSV文件", type=["csv"])
if uploaded_file is not None:
df = pd.read_csv(uploaded_file)
st.write("上传数据预览:")
st.dataframe(df.head())
2.3 布局与样式
python
import streamlit as st
import pandas as pd
import numpy as np
st.title("布局与样式演示")
# 列布局
st.header("列布局示例")
col1, col2, col3 = st.columns(3)
with col1:
st.metric("温度", "25°C", "1.2°C")
with col2:
st.metric("湿度", "65%", "-3%")
with col3:
st.metric("风速", "12km/h", "0.5km/h")
# 标签页
st.header("标签页示例")
tab1, tab2, tab3 = st.tabs(["原始数据", "可视化", "分析"])
with tab1:
df = pd.DataFrame(np.random.randn(20, 3), columns=['a', 'b', 'c'])
st.dataframe(df)
with tab2:
st.line_chart(df)
with tab3:
st.write("描述统计:")
st.write(df.describe())
# 侧边栏
st.sidebar.header("配置选项")
n_samples = st.sidebar.number_input("样本数", 100, 10000, 1000)
show_raw = st.sidebar.checkbox("显示原始数据", True)
color = st.sidebar.selectbox(
"图表颜色",
["blue", "red", "green"]
)
# 扩展器
with st.expander("点击查看代码"):
st.code("""
import streamlit as st
st.title("Hello World")
""")
2.4 高级状态管理
2.4.1 复杂会话状态管理
python
import streamlit as st
import pandas as pd
import numpy as np
st.title("高级状态管理示例")
# 初始化复杂会话状态
if 'app_state' not in st.session_state:
st.session_state.app_state = {
'dataframe': pd.DataFrame(np.random.randn(5, 3), columns=['A', 'B', 'C']),
'settings': {
'color_theme': 'dark',
'font_size': 12,
'show_grid': True
},
'history': []
}
# 状态修改函数
def update_dataframe():
new_data = pd.DataFrame(np.random.randn(5, 3), columns=['A', 'B', 'C'])
st.session_state.app_state['history'].append(st.session_state.app_state['dataframe'].copy())
st.session_state.app_state['dataframe'] = new_data
def undo_last_action():
if st.session_state.app_state['history']:
st.session_state.app_state['dataframe'] = st.session_state.app_state['history'].pop()
# 界面布局
col1, col2 = st.columns(2)
with col1:
st.subheader("当前数据")
st.dataframe(st.session_state.app_state['dataframe'])
if st.button("生成新数据", on_click=update_dataframe):
st.success("数据已更新!")
if st.button("撤销操作", on_click=undo_last_action):
st.info("已撤销上一步操作")
with col2:
st.subheader("应用设置")
# 动态修改设置
theme = st.selectbox(
"颜色主题",
['dark', 'light', 'blue'],
index=['dark', 'light', 'blue'].index(st.session_state.app_state['settings']['color_theme'])
)
font_size = st.slider(
"字体大小",
8, 24,
st.session_state.app_state['settings']['font_size']
)
show_grid = st.checkbox(
"显示网格线",
st.session_state.app_state['settings']['show_grid']
)
if st.button("保存设置"):
st.session_state.app_state['settings'].update({
'color_theme': theme,
'font_size': font_size,
'show_grid': show_grid
})
st.success("设置已保存!")
st.subheader("当前设置")
st.json(st.session_state.app_state['settings'])
# 显示操作历史
st.subheader("操作历史记录")
history_df = pd.DataFrame({
'操作时间': pd.date_range(end=pd.Timestamp.now(), periods=len(st.session_state.app_state['history'])),
'数据形状': [f"{df.shape[0]}行×{df.shape[1]}列" for df in st.session_state.app_state['history']]
})
st.dataframe(history_df)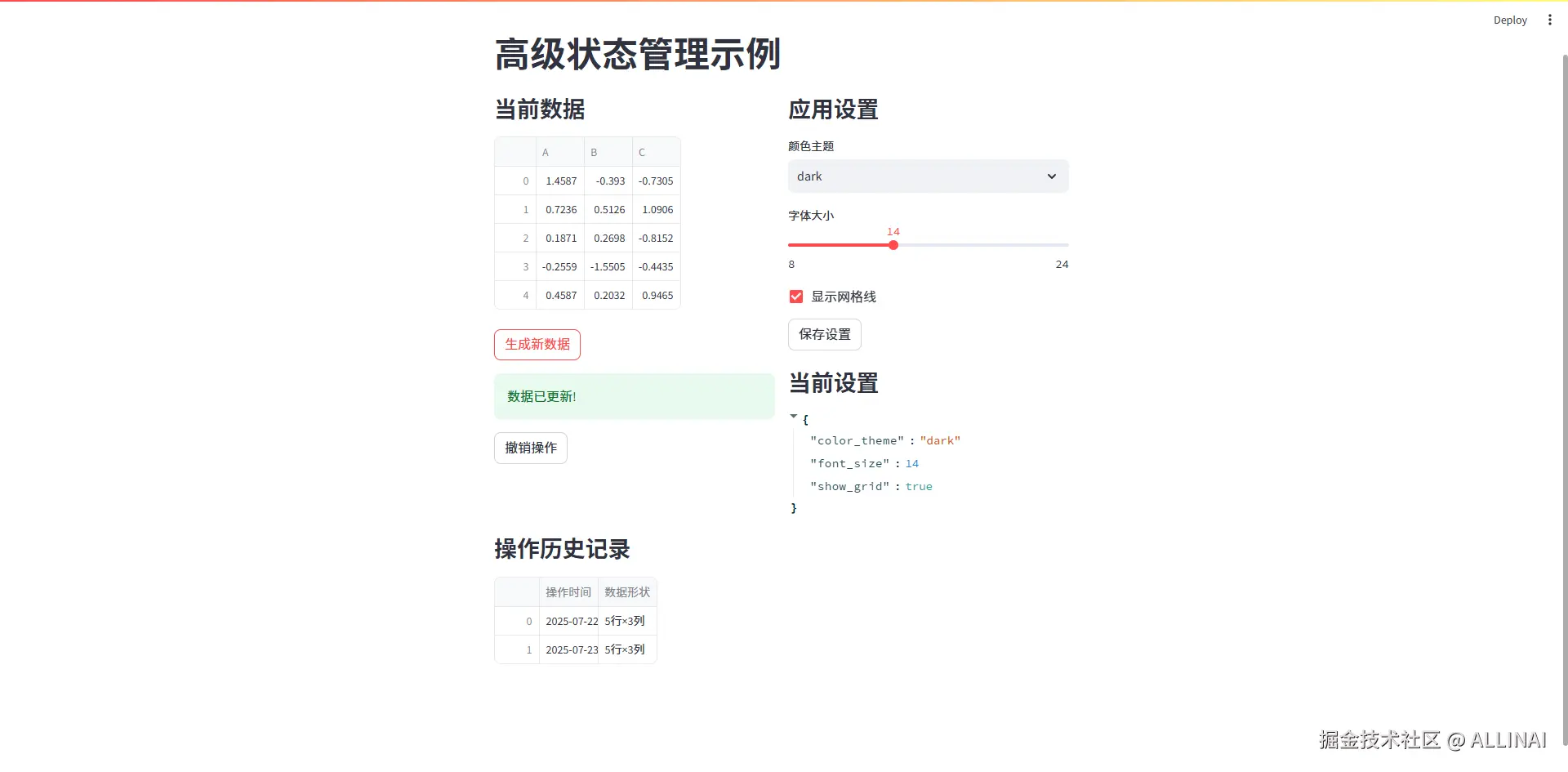
2.4.2 跨页面状态共享
创建两个文件演示跨页面状态:
- 1_page1.py
python
import streamlit as st
st.title("页面1 - 跨页面状态共享")
# 初始化共享状态
if 'shared_state' not in st.session_state:
st.session_state.shared_state = {
'counter': 0,
'messages': []
}
# 修改共享状态
def increment_counter():
st.session_state.shared_state['counter'] += 1
st.session_state.shared_state['messages'].append(
f"页面1增加计数器到{st.session_state.shared_state['counter']}"
)
st.write("当前计数器:", st.session_state.shared_state['counter'])
st.button("增加计数器", on_click=increment_counter)
# 添加消息
message = st.text_input("添加共享消息")
if st.button("提交消息"):
if message:
st.session_state.shared_state['messages'].append(f"页面1: {message}")
st.success("消息已添加!")
st.write("共享消息列表:")
st.write(st.session_state.shared_state['messages'])- 2_page2.py
python
import streamlit as st
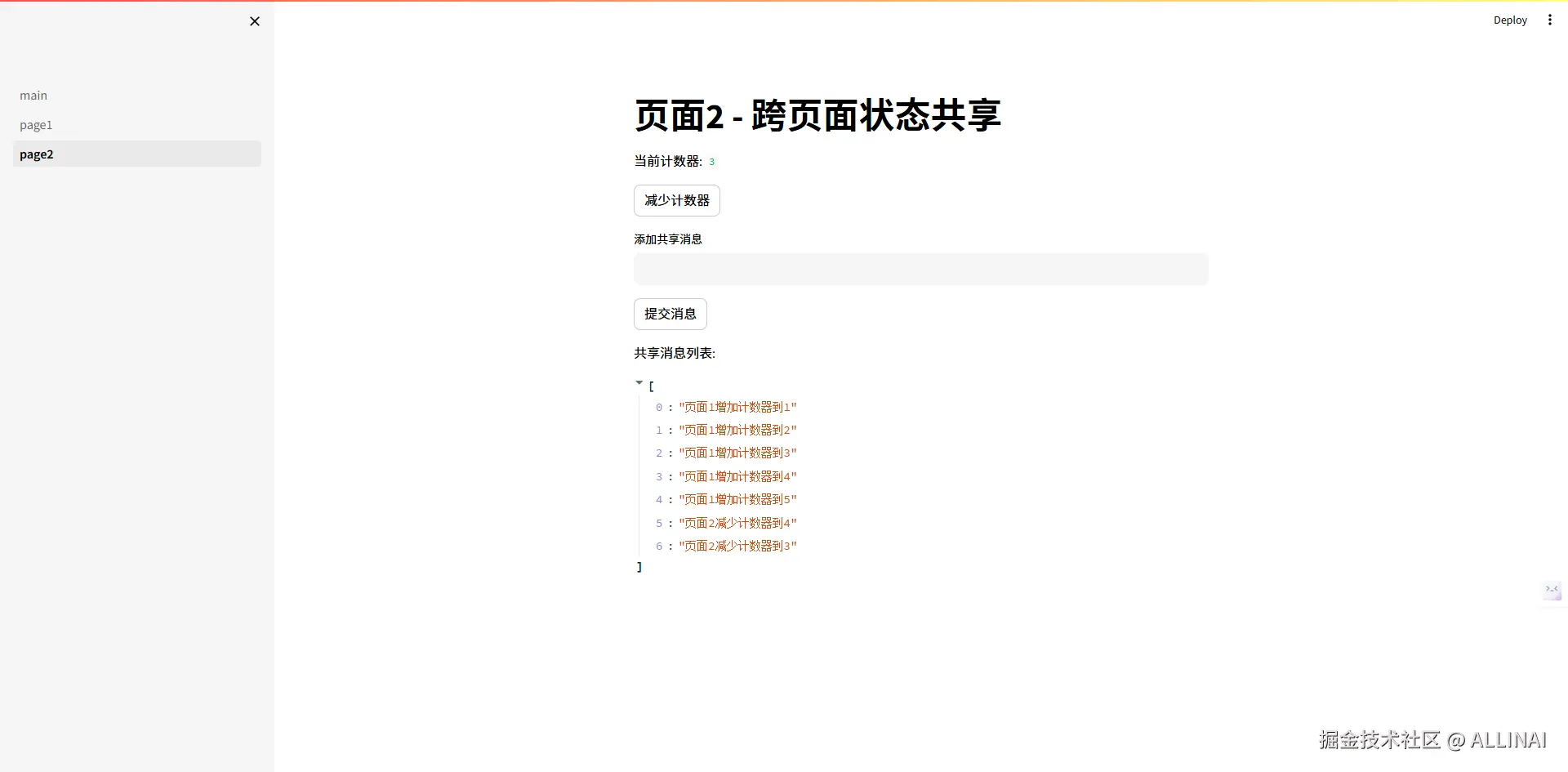
st.title("页面2 - 跨页面状态共享")
# 访问共享状态
if 'shared_state' not in st.session_state:
st.session_state.shared_state = {
'counter': 0,
'messages': []
}
# 修改共享状态
def decrement_counter():
st.session_state.shared_state['counter'] -= 1
st.session_state.shared_state['messages'].append(
f"页面2减少计数器到{st.session_state.shared_state['counter']}"
)
st.write("当前计数器:", st.session_state.shared_state['counter'])
st.button("减少计数器", on_click=decrement_counter)
# 添加消息
message = st.text_input("添加共享消息")
if st.button("提交消息"):
if message:
st.session_state.shared_state['messages'].append(f"页面2: {message}")
st.success("消息已添加!")
st.write("共享消息列表:")
st.write(st.session_state.shared_state['messages'])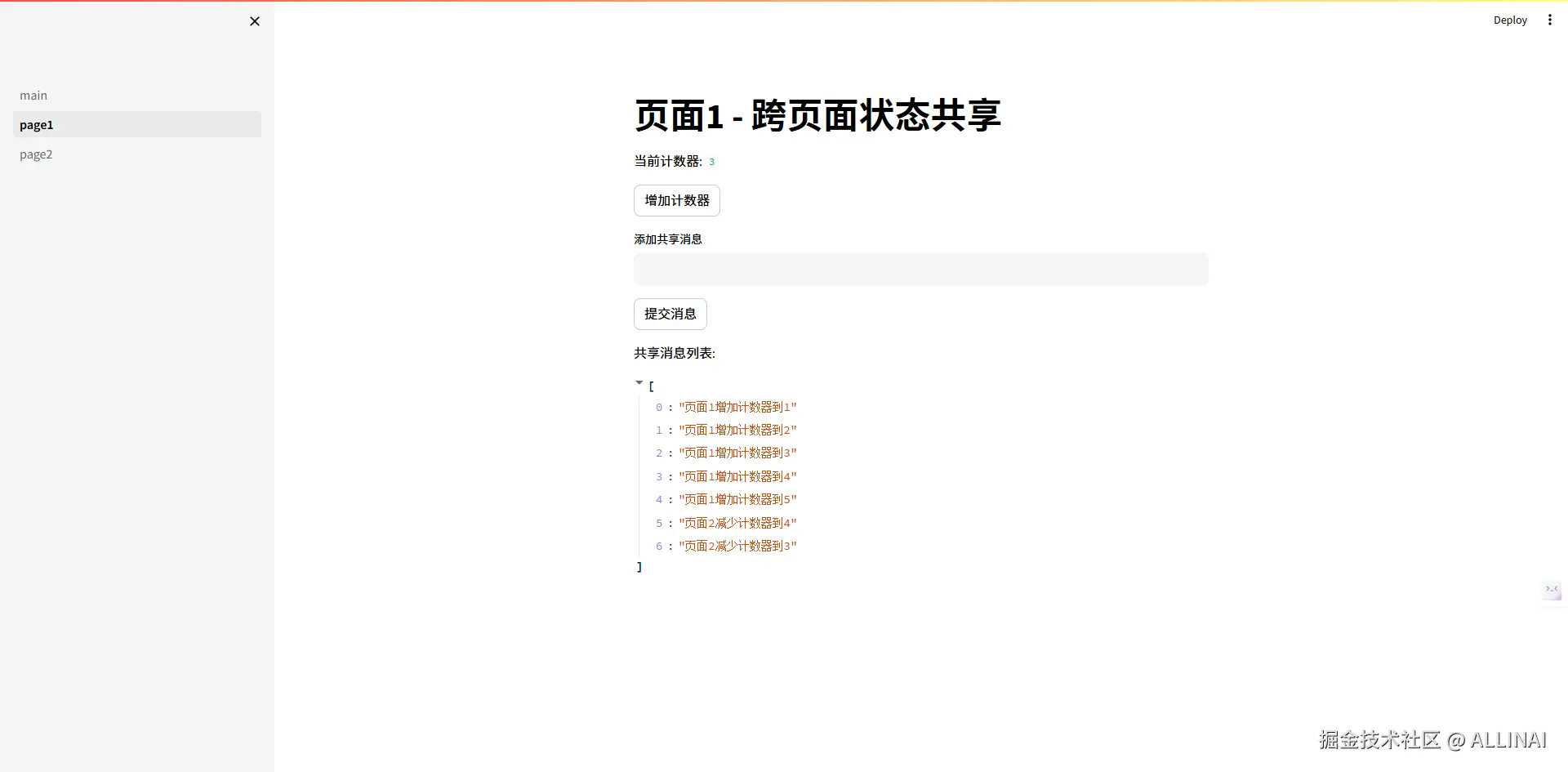
2.5 性能优化技术
2.5.1 智能缓存与计算优化
python
import streamlit as st
import pandas as pd
import numpy as np
import time
st.title("性能优化技术示例")
# 1. 数据缓存示例
@st.cache_data
def load_large_dataset(size):
"""模拟加载大型数据集"""
st.write("正在生成数据... (这只会运行一次)")
time.sleep(2) # 模拟耗时操作
data = pd.DataFrame({
'id': range(size),
'value': np.random.randn(size),
'category': np.random.choice(['A', 'B', 'C', 'D'], size)
})
return data
# 2. 资源缓存示例
@st.cache_resource
def train_complex_model(data_size):
"""模拟训练复杂模型"""
st.write("正在训练模型... (这只会运行一次)")
time.sleep(3) # 模拟耗时操作
return {
'model_type': 'RandomForest',
'data_size': data_size,
'accuracy': np.random.uniform(0.8, 0.95)
}
# 3. 计算缓存示例
@st.cache_data
def expensive_computation(data, param):
"""模拟耗时计算"""
st.write(f"执行计算... (参数: {param})")
time.sleep(1)
return {
'mean': data['value'].mean(),
'sum': data['value'].sum(),
'param': param
}
# 用户界面
st.header("1. 数据缓存演示")
dataset_size = st.slider("选择数据集大小", 1000, 100000, 10000, step=1000)
data = load_large_dataset(dataset_size)
st.write(f"已加载 {len(data)} 行数据")
st.dataframe(data.head())
st.header("2. 资源缓存演示")
if st.button("训练模型"):
model = train_complex_model(dataset_size)
st.success(f"模型训练完成! 准确率: {model['accuracy']:.2%}")
st.header("3. 计算缓存演示")
compute_param = st.slider("计算参数", 1, 10, 5)
result = expensive_computation(data, compute_param)
st.write("计算结果:", result)
# 4. 选择性渲染示例
st.header("4. 选择性渲染优化")
show_details = st.checkbox("显示详细分析")
if show_details:
with st.spinner("正在执行详细分析..."):
# 模拟耗时分析
time.sleep(2)
st.subheader("详细分析结果")
# 使用容器避免重复计算
with st.container():
st.write("值分布:")
st.bar_chart(data['value'].value_counts())
st.write("按类别分组统计:")
st.table(data.groupby('category').agg({
'value': ['mean', 'std', 'count']
}))
else:
st.info("勾选上方复选框显示详细分析")
# 5. 渐进式加载示例
st.header("5. 渐进式加载技术")
if st.button("加载大数据集(渐进式)"):
progress_bar = st.progress(0)
status_text = st.empty()
chunks = []
for i in range(5):
# 模拟分块加载
status_text.text(f"正在加载第 {i + 1}/5 部分...")
time.sleep(0.5)
chunk = pd.DataFrame({
'id': range(i * 2000, (i + 1) * 2000),
'value': np.random.randn(2000)
})
chunks.append(chunk)
progress_bar.progress((i + 1) / 5)
full_data = pd.concat(chunks)
st.session_state['big_data'] = full_data
status_text.text("加载完成!")
st.dataframe(full_data.head())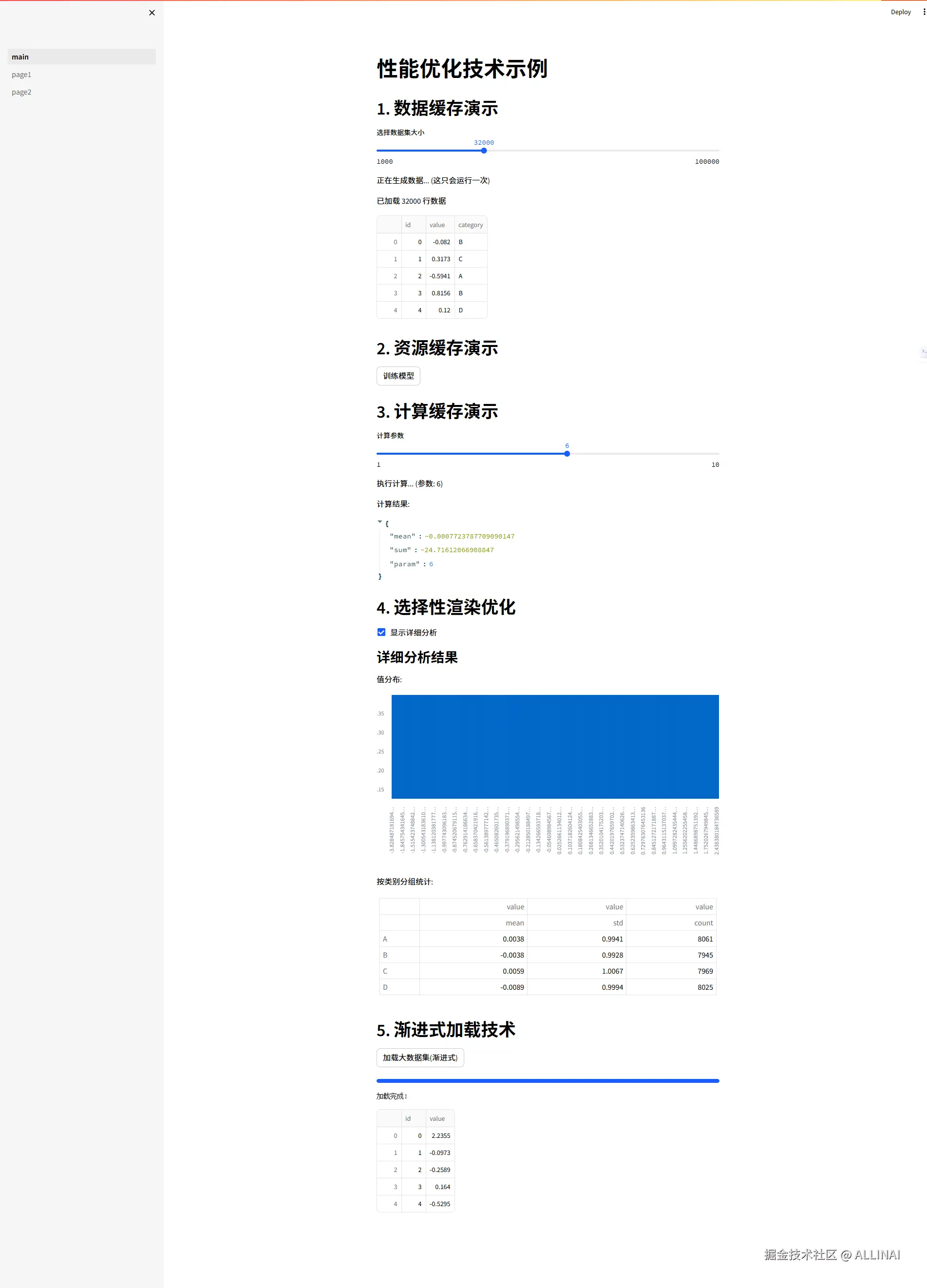
2.6 自定义组件与扩展
2.6.1 创建自定义可视化组件
python
import streamlit as st
import pandas as pd
import numpy as np
from streamlit.components.v1 import html
import json
import random
st.title("自定义组件开发示例")
# 1. 使用HTML/JS创建自定义组件
st.header("1. 自定义HTML/JS组件")
# 简单的D3.js条形图组件
def d3_bar_chart(data, width=600, height=400):
"""创建自定义D3.js条形图组件"""
chart_id = f"chart-{random.randint(0, 10000)}"
html_code = f"""
<div id="{chart_id}"></div>
<script src="https://d3js.org/d3.v7.min.js"></script>
<script>
// 数据
const data = {json.dumps(data)};
// 设置图表尺寸
const width = {width};
const height = {height};
const margin = {{top: 20, right: 30, bottom: 40, left: 40}};
// 创建SVG
const svg = d3.select("#{chart_id}")
.append("svg")
.attr("width", width)
.attr("height", height);
// 创建比例尺
const x = d3.scaleBand()
.domain(data.map(d => d.category))
.range([margin.left, width - margin.right])
.padding(0.1);
const y = d3.scaleLinear()
.domain([0, d3.max(data, d => d.value)]).nice()
.range([height - margin.bottom, margin.top]);
// 添加条形
svg.selectAll("rect")
.data(data)
.join("rect")
.attr("x", d => x(d.category))
.attr("y", d => y(d.value))
.attr("width", x.bandwidth())
.attr("height", d => y(0) - y(d.value))
.attr("fill", "steelblue");
// 添加X轴
svg.append("g")
.attr("transform", `translate(0,${{height - margin.bottom}})`)
.call(d3.axisBottom(x));
// 添加Y轴
svg.append("g")
.attr("transform", `translate(${{margin.left}},0)`)
.call(d3.axisLeft(y));
</script>
"""
return html(html_code, width=width, height=height + 50)
# 使用自定义组件
sample_data = [
{"category": "A", "value": 30},
{"category": "B", "value": 45},
{"category": "C", "value": 25},
{"category": "D", "value": 60}
]
st.write("自定义D3.js条形图:")
d3_bar_chart(sample_data)
# 2. 使用第三方组件库
st.header("2. 集成第三方组件")
# 使用streamlit-aggrid高级表格
try:
from st_aggrid import AgGrid, GridOptionsBuilder
st.write("使用streamlit-aggrid创建高级表格:")
df = pd.DataFrame(
np.random.randn(20, 5),
columns=['A', 'B', 'C', 'D', 'E']
)
gb = GridOptionsBuilder.from_dataframe(df)
gb.configure_pagination(enabled=True)
gb.configure_side_bar()
gb.configure_default_column(
editable=True,
groupable=True,
filterable=True
)
grid_options = gb.build()
AgGrid(df, gridOptions=grid_options, height=400)
except ImportError:
st.warning("请先安装st-aggrid: pip install streamlit-aggrid")
# 3. 自定义表单组件
st.header("3. 自定义表单组件")
def custom_slider(label, min_val, max_val, default_val):
"""创建自定义滑动条组件"""
slider_id = f"slider-{random.randint(0, 10000)}"
html_code = f"""
<div style="margin: 20px 0;">
<label for="{slider_id}" style="display: block; margin-bottom: 8px;">{label}</label>
<input type="range" id="{slider_id}"
min="{min_val}" max="{max_val}" value="{default_val}"
style="width: 100%; height: 10px;"
oninput="updateValue(this.value)">
<div id="{slider_id}-value" style="text-align: center; margin-top: 5px;">
{default_val}
</div>
</div>
<script>
function updateValue(val) {{
document.getElementById("{slider_id}-value").innerText = val;
// 将值发送回Streamlit
parent.postMessage({{
isStreamlitMessage: true,
type: "slider_change",
value: val,
id: "{slider_id}"
}}, "*");
}}
</script>
"""
# 处理前端消息
component_value = html(html_code, height=80)
# 从前端获取值
if st.session_state.get(f"{slider_id}_value"):
return st.session_state[f"{slider_id}_value"]
return default_val
# 使用自定义滑动条
st.write("自定义滑动条组件:")
custom_value = custom_slider("选择数值", 0, 100, 50)
st.write("当前值:", custom_value)
# 4. 嵌入外部应用
st.header("4. 嵌入外部应用")
# 嵌入Plotly编辑器
plotly_editor_html = """
<div>
<iframe
src="https://chart-studio.plotly.com/create/?fid=plotly_demo:1"
width="100%"
height="600"
frameborder="0">
</iframe>
</div>
"""
st.write("嵌入Plotly图表编辑器:")
html(plotly_editor_html, height=650)
2.6.2 创建可复用组件
- custom_components.py
python
from streamlit.components.v1 import html
class CustomComponents:
@staticmethod
def metric_card(title, value, delta=None, delta_color="normal"):
"""自定义指标卡片组件"""
color_map = {
"normal": "#1f77b4",
"positive": "#2ecc71",
"negative": "#e74c3c"
}
color = color_map.get(delta_color, "#1f77b4")
delta_html = f"""
<div style="color: {color}; font-size: 14px; margin-top: 4px;">
{delta}
</div>
""" if delta is not None else ""
html_str = f"""
<div style="
border: 1px solid #ddd;
border-radius: 8px;
padding: 20px;
margin: 10px 0;
background: white;
box-shadow: 0 2px 4px rgba(0,0,0,0.1);
">
<div style="color: #666; font-size: 14px;">{title}</div>
<div style="font-size: 28px; font-weight: bold; margin: 8px 0;">{value}</div>
{delta_html}
</div>
"""
return html(html_str)
@staticmethod
def progress_circle(percentage, size=100, color="#4CAF50"):
"""圆形进度条组件"""
html_str = f"""
<div style="position: relative; width: {size}px; height: {size}px; margin: 20px auto;">
<svg width="{size}" height="{size}">
<circle
cx="{size // 2}"
cy="{size // 2}"
r="{size // 2 - 5}"
stroke="#eee"
stroke-width="10"
fill="none"
/>
<circle
cx="{size // 2}"
cy="{size // 2}"
r="{size // 2 - 5}"
stroke="{color}"
stroke-width="10"
fill="none"
stroke-dasharray="{percentage / 100 * 2 * 3.1415 * (size // 2 - 5)} {2 * 3.1415 * (size // 2 - 5)}"
stroke-dashoffset="0"
transform="rotate(-90 {size // 2} {size // 2})"
/>
</svg>
<div style="
position: absolute;
top: 50%;
left: 50%;
transform: translate(-50%, -50%);
font-size: 20px;
font-weight: bold;
color: {color};
">{percentage}%</div>
</div>
"""
return html(html_str)- 使用自定义组件
python
import streamlit as st
from custom_components import CustomComponents
st.title("可复用自定义组件示例")
# 使用指标卡片组件
st.header("1. 指标卡片组件")
col1, col2, col3 = st.columns(3)
with col1:
CustomComponents.metric_card("用户数", "1,234", "+12%", "positive")
with col2:
CustomComponents.metric_card("留存率", "78%", "-3%", "negative")
with col3:
CustomComponents.metric_card("平均时长", "2.5h")
# 使用圆形进度条
st.header("2. 圆形进度条组件")
progress = st.slider("选择进度", 0, 100, 75)
CustomComponents.progress_circle(progress, size=150, color="#3498db")
# 动态更新示例
if st.button("随机更新"):
import random
progress = random.randint(0, 100)
st.experimental_rerun()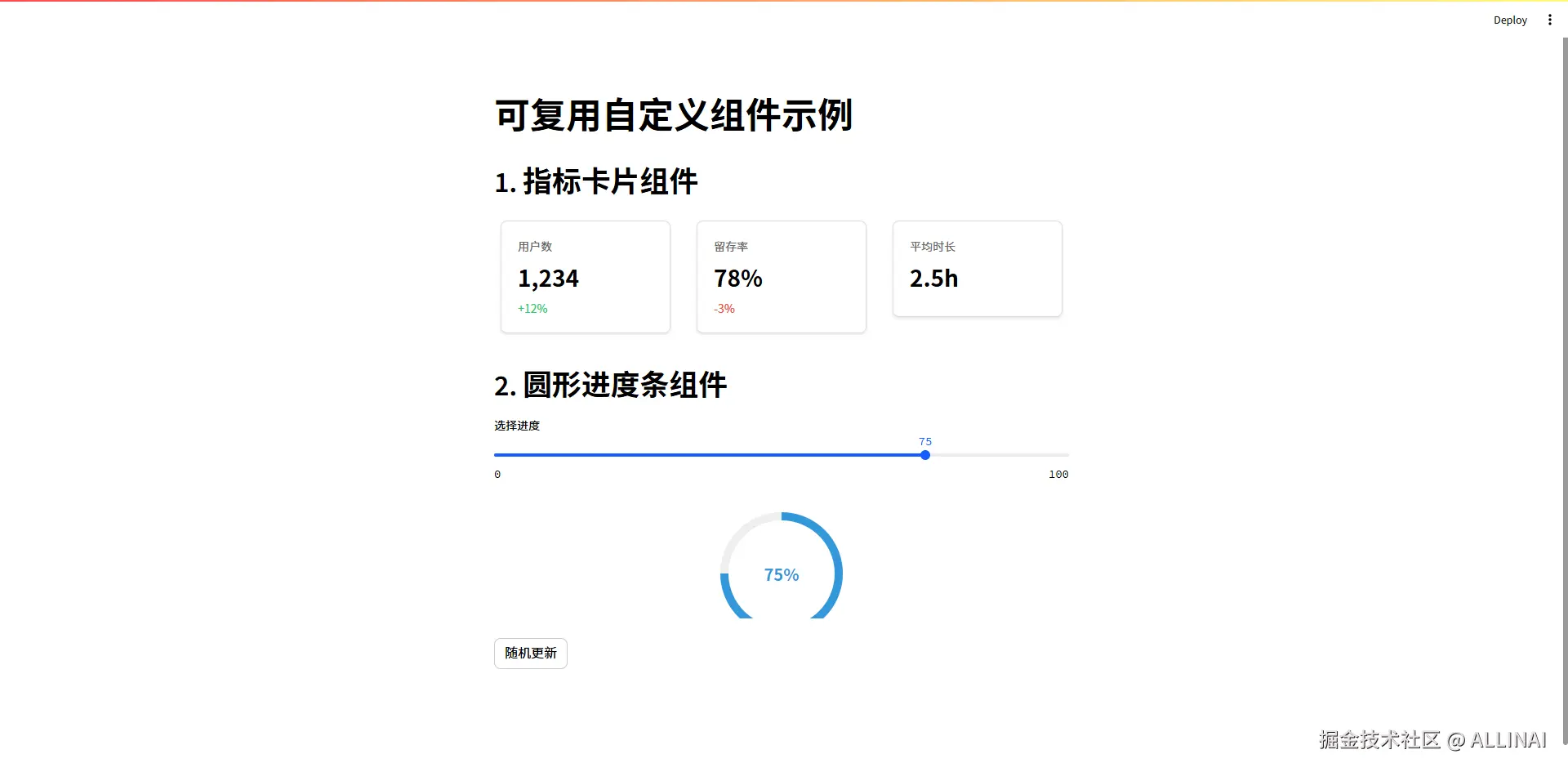
3. 专业应用场景
3.1 机器学习模型部署
python
import streamlit as st
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
# 模拟训练数据
np.random.seed(42)
X = np.random.rand(100, 1) * 10
y = 2 * X.squeeze() + np.random.randn(100) * 2
# 训练简单模型
model = LinearRegression()
model.fit(X, y)
# 创建预测界面
st.title("简单线性回归预测器")
st.write("""
### 房价预测模型
使用简单的线性回归模型预测房价
""")
# 用户输入
sqft = st.slider("房屋面积(平方英尺)", 500, 5000, 1500)
# 预测
prediction = model.predict([[sqft]])
st.metric("预测房价", f"${prediction[0]:,.2f}")
# 显示模型信息
st.subheader("模型信息")
st.write(f"斜率(每平方英尺价格): ${model.coef_[0]:.2f}")
st.write(f"截距: ${model.intercept_:.2f}")
# 显示训练数据
st.scatter_chart(pd.DataFrame({'面积': X.squeeze(), '价格': y}))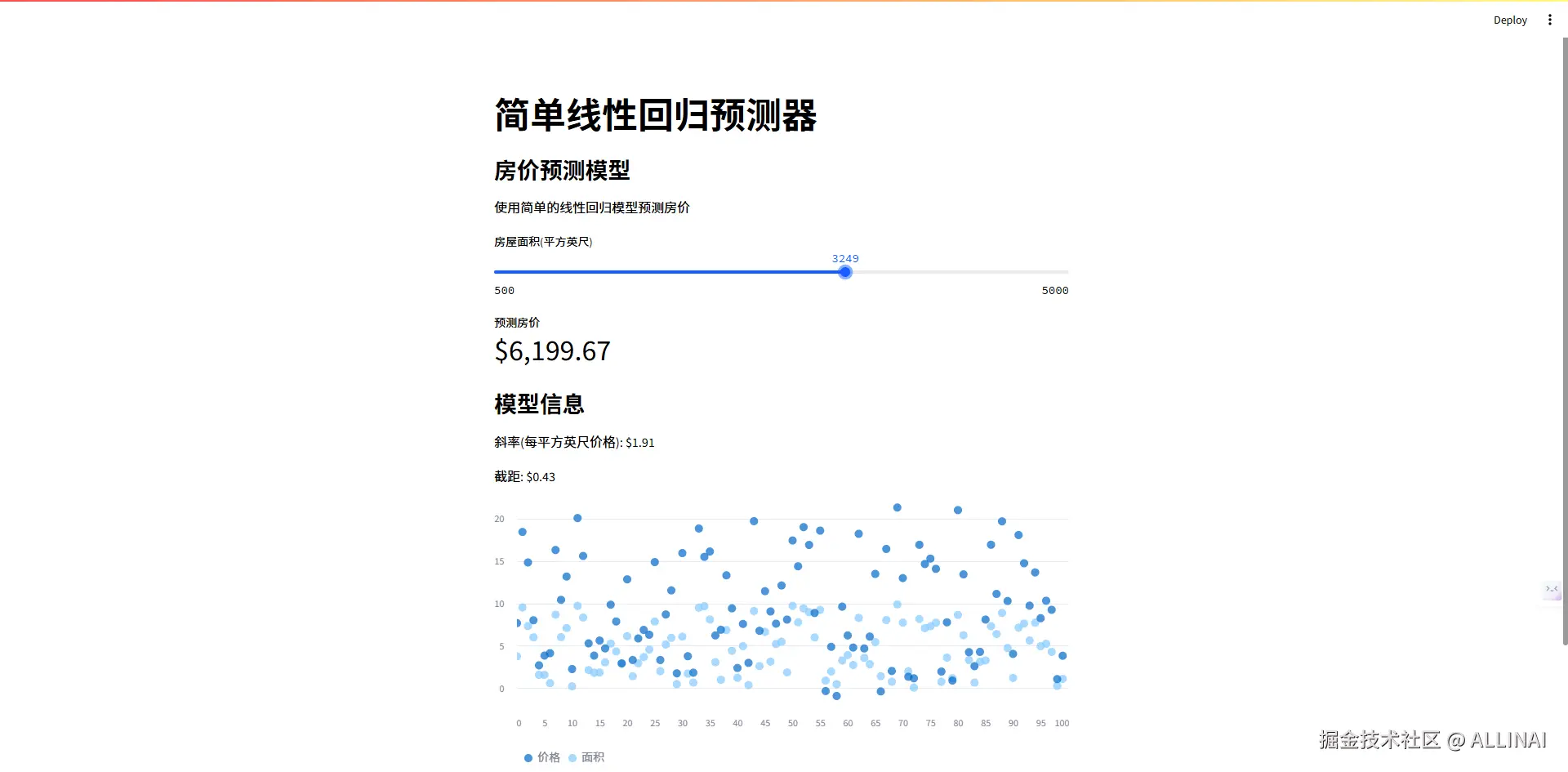
3.2 数据探索与分析
python
import streamlit as st
import pandas as pd
import numpy as np
import plotly.express as px
st.title("数据探索分析工具")
# 生成示例数据
@st.cache_data
def load_data():
np.random.seed(42)
data = pd.DataFrame({
'日期': pd.date_range('2023-01-01', periods=100),
'销售额': np.random.randn(100).cumsum() * 100 + 1000,
'客户数': np.random.poisson(50, 100),
'产品类别': np.random.choice(['A', 'B', 'C'], 100),
'地区': np.random.choice(['东区', '西区', '南区', '北区'], 100)
})
return data
df = load_data()
# 交互式控件
st.sidebar.header("分析选项")
show_raw = st.sidebar.checkbox("显示原始数据", False)
columns = st.sidebar.multiselect(
"选择分析列",
df.select_dtypes(include=['number']).columns.tolist(),
default=['销售额', '客户数']
)
group_by = st.sidebar.selectbox("分组依据", ['无', '产品类别', '地区'])
# 数据显示
if show_raw:
st.subheader("原始数据")
st.dataframe(df)
# 描述统计
st.subheader("描述统计")
st.write(df[columns].describe())
# 可视化
st.subheader("数据可视化")
if group_by != '无':
fig = px.line(df, x='日期', y=columns, color=group_by)
else:
fig = px.line(df, x='日期', y=columns)
st.plotly_chart(fig)
# 相关性分析
if len(columns) >= 2:
st.subheader("相关性分析")
st.write(df[columns].corr())
fig = px.scatter_matrix(df, dimensions=columns)
st.plotly_chart(fig)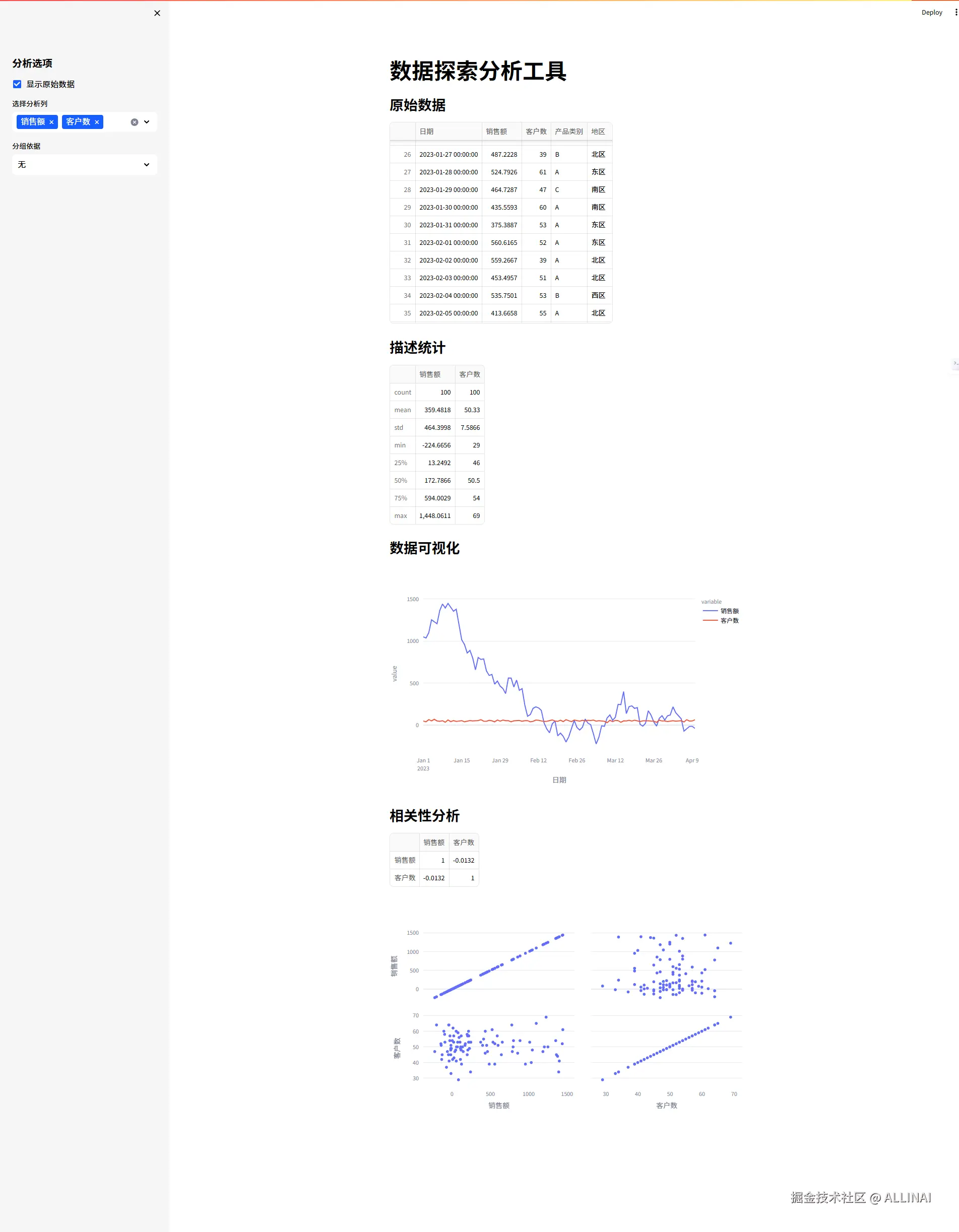
3.3 实验参数调优
python
import streamlit as st
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
st.title("模型参数调优实验")
# 生成模拟数据
@st.cache_data
def generate_data():
X, y = make_classification(
n_samples=1000,
n_features=20,
n_informative=3,
n_classes=2,
random_state=42
)
return train_test_split(X, y, test_size=0.2, random_state=42)
X_train, X_test, y_train, y_test = generate_data()
# 参数配置
st.sidebar.header("模型参数")
n_estimators = st.sidebar.slider("树的数量", 10, 200, 100)
max_depth = st.sidebar.slider("最大深度", 2, 20, 5)
min_samples_split = st.sidebar.slider("最小分裂样本数", 2, 20, 2)
bootstrap = st.sidebar.checkbox("Bootstrap采样", True)
# 训练按钮
if st.sidebar.button("训练模型"):
with st.spinner("模型训练中..."):
model = RandomForestClassifier(
n_estimators=n_estimators,
max_depth=max_depth,
min_samples_split=min_samples_split,
bootstrap=bootstrap,
random_state=42
)
model.fit(X_train, y_train)
train_acc = model.score(X_train, y_train)
test_acc = model.score(X_test, y_test)
st.success("训练完成!")
col1, col2 = st.columns(2)
col1.metric("训练准确率", f"{train_acc:.2%}")
col2.metric("测试准确率", f"{test_acc:.2%}",
f"{(test_acc - train_acc):.2%}")
# 特征重要性
if 'model' in locals():
st.subheader("特征重要性")
importance = pd.DataFrame({
'特征': [f"特征 {i}" for i in range(X_train.shape[1])],
'重要性': model.feature_importances_
}).sort_values('重要性', ascending=False)
st.bar_chart(importance.set_index('特征'))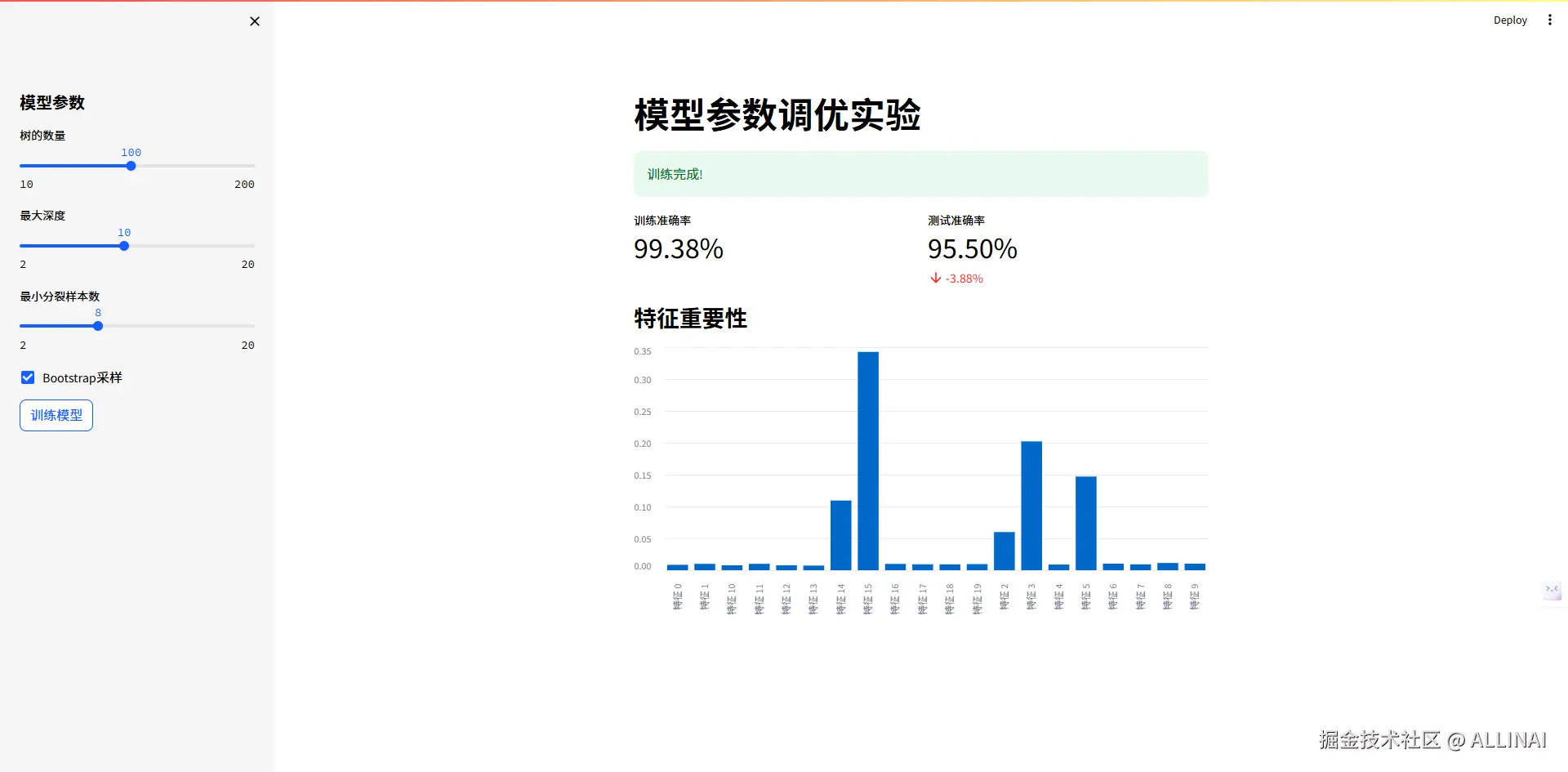
4. 完整可运行应用示例
python
import streamlit as st
import pandas as pd
import numpy as np
import plotly.express as px
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
# 应用配置
st.set_page_config(
page_title="完整数据科学应用",
page_icon="🧊",
layout="wide"
)
# 加载数据
@st.cache_data
def load_data():
iris = load_iris()
df = pd.DataFrame(
data=np.c_[iris.data, iris.target],
columns=iris.feature_names + ['target']
)
df['species'] = df['target'].map({
0: iris.target_names[0],
1: iris.target_names[1],
2: iris.target_names[2]
})
return df
df = load_data()
# 侧边栏
st.sidebar.header("配置选项")
analysis_type = st.sidebar.radio(
"选择分析类型",
["数据探索", "特征工程", "模型训练"]
)
# 主界面
st.title("鸢尾花数据分析应用")
if analysis_type == "数据探索":
st.header("数据探索")
# 数据显示选项
show_options = st.expander("数据显示选项")
with show_options:
rows = st.slider("显示行数", 5, 50, 10)
cols = st.multiselect(
"选择列",
df.columns.tolist(),
default=df.columns.tolist()[:4]
)
st.dataframe(df[cols].head(rows))
# 可视化
st.header("数据可视化")
chart_type = st.selectbox(
"选择图表类型",
["散点图", "箱线图", "直方图"]
)
x_axis = st.selectbox("X轴", df.columns.tolist()[:4])
y_axis = st.selectbox("Y轴", df.columns.tolist()[:4])
color_by = st.selectbox("颜色依据", ['species', None])
if chart_type == "散点图":
fig = px.scatter(df, x=x_axis, y=y_axis, color=color_by)
elif chart_type == "箱线图":
fig = px.box(df, x=color_by, y=y_axis)
else:
fig = px.histogram(df, x=x_axis, color=color_by)
st.plotly_chart(fig, use_container_width=True)
elif analysis_type == "特征工程":
st.header("特征工程")
st.write("特征相关性矩阵")
numeric_cols = df.select_dtypes(include=['float64']).columns
corr = df[numeric_cols].corr()
st.dataframe(corr.style.background_gradient(cmap='coolwarm'))
fig = px.imshow(corr, text_auto=True)
st.plotly_chart(fig, use_container_width=True)
elif analysis_type == "模型训练":
st.header("模型训练")
# 模型参数
st.sidebar.subheader("模型参数")
n_estimators = st.sidebar.slider("树的数量", 10, 200, 100)
max_depth = st.sidebar.selectbox("最大深度", [None, 5, 10, 20], index=1)
# 训练测试分割
X = df[df.columns[:4]]
y = df['target']
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.2, random_state=42
)
if st.button("训练模型"):
with st.spinner("训练中..."):
model = RandomForestClassifier(
n_estimators=n_estimators,
max_depth=max_depth,
random_state=42
)
model.fit(X_train, y_train)
train_acc = model.score(X_train, y_train)
test_acc = model.score(X_test, y_test)
st.success("训练完成!")
col1, col2 = st.columns(2)
col1.metric("训练准确率", f"{train_acc:.2%}")
col2.metric("测试准确率", f"{test_acc:.2%}")
# 特征重要性
st.subheader("特征重要性")
importance = pd.DataFrame({
'特征': X.columns,
'重要性': model.feature_importances_
}).sort_values('重要性', ascending=False)
st.bar_chart(importance.set_index('特征'))
# 预测示例
st.subheader("预测示例")
sample = X_test.iloc[:5].copy()
sample['预测类别'] = model.predict(X_test.iloc[:5])
sample['真实类别'] = y_test.iloc[:5].values
st.dataframe(sample)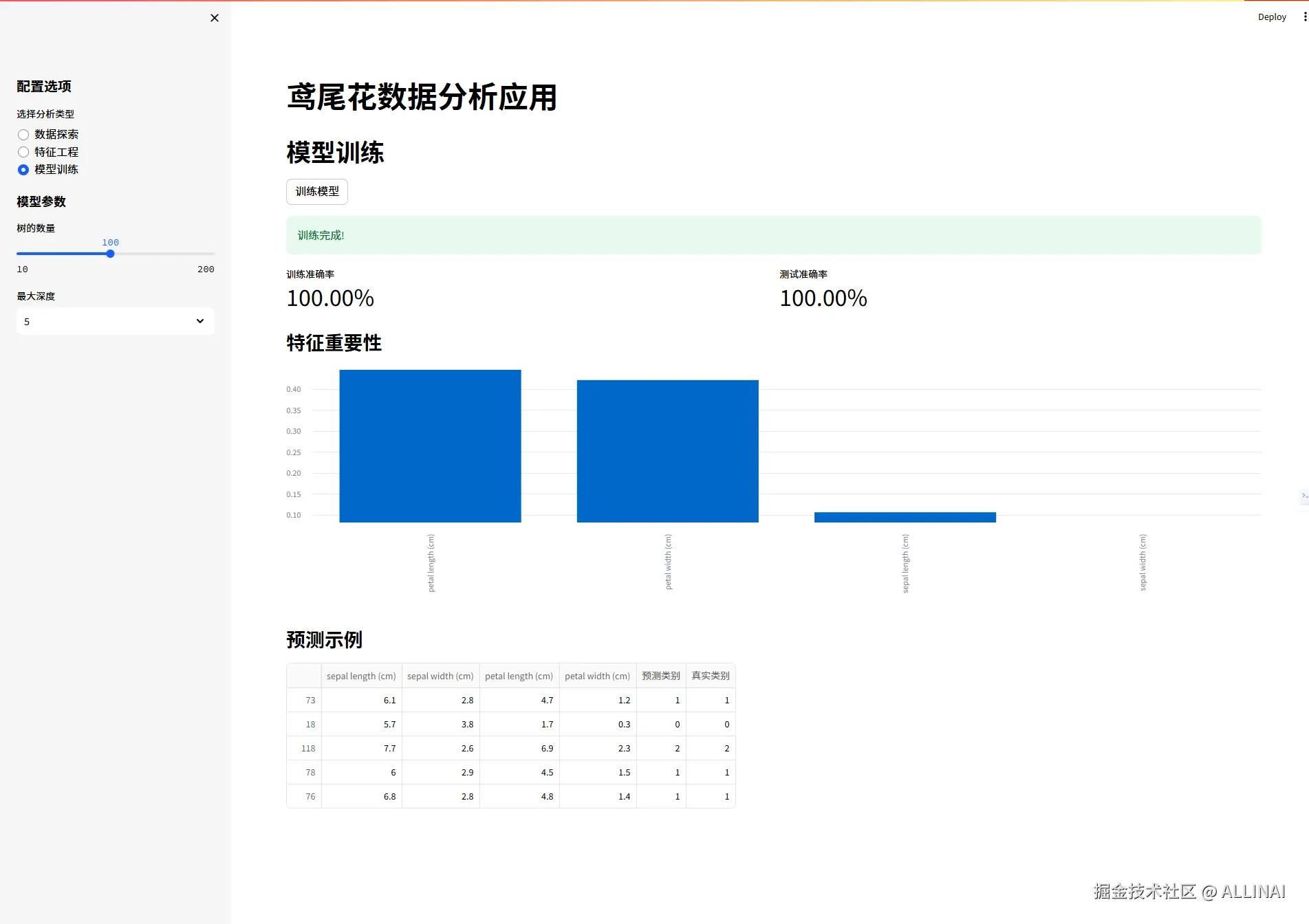
总结
Streamlit通过其独特的"脚本即应用"哲学,彻底改变了数据科学应用的开发范式。对于专业人士而言,掌握Streamlit意味着能够将分析结果、机器学习模型和数据处理流程快速转化为可交互、可共享的应用,极大提升了工作效率和成果影响力。虽然它在复杂应用场景下存在一定限制,但其简洁性、Python原生支持和活跃的社区使其成为数据科学工作流中不可或缺的工具。