**摘要:**本文整理自抖音集团数据工程师陶王飞和羊艺超老师,在 Flink Forward Asia 2024 生产实践(一)专场中的分享。主要内容主要分为以下四个部分:
1、现状与痛点
2、链路通用优化
3、业务场景优化
4、未来规划
01、现状与痛点
1.1 业务现状

抖音的主要业务场景为视频和直播,实时数据在其中有着广泛应用,如实时大屏、实时预警、对内实时分析(如大盘生态监控)、实时榜单以及为推荐提供实时特征数据等。
视频场景流量巨大,晚高峰整体流量达亿级 RPS;直播场景则状态数据量大,因为业务上直播间开关播时间无限制,导致存在许多超长周期存储聚合需求。
1.2 问题挑战
(1)实时数仓架构图
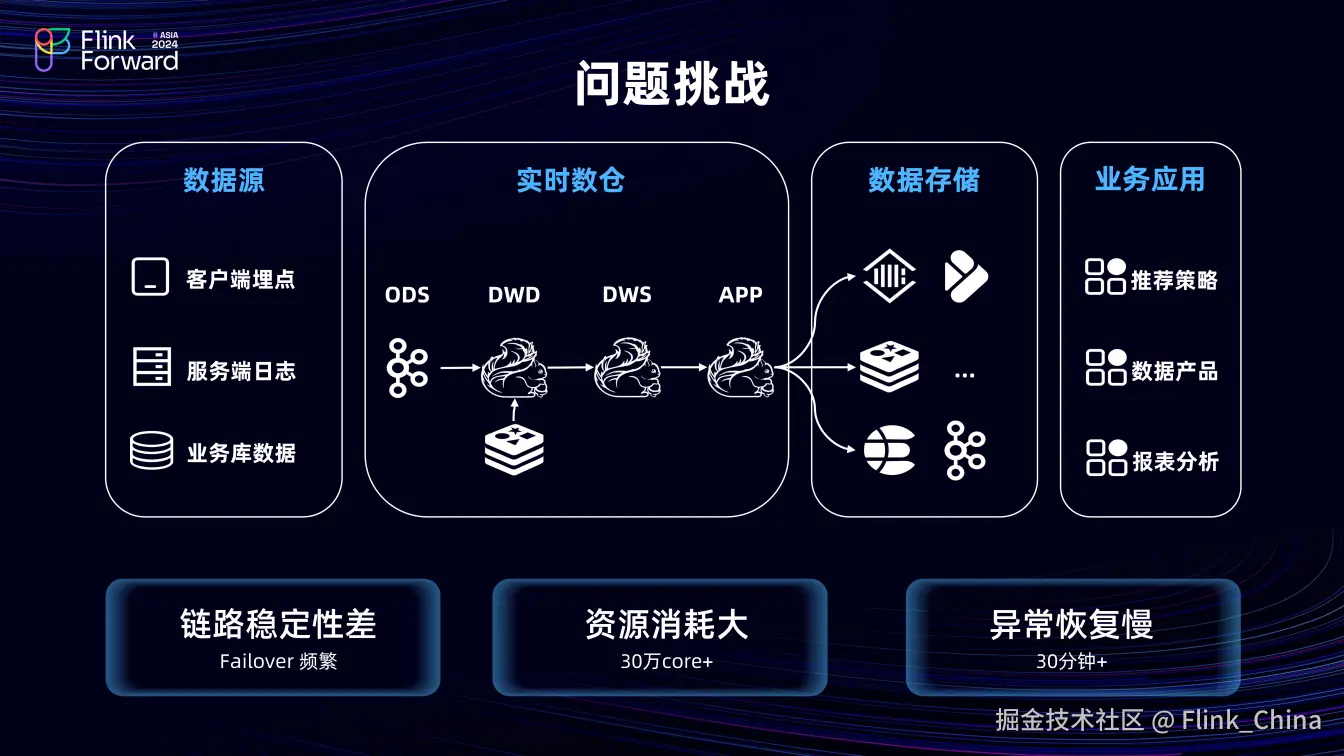
数据源层包括客户端埋点、服务端日志以及业务库数据。数仓的分层使用 Flink计算,依次为 ODS 层(数据源层)、DWD 层(进行维表关联与简单数据处理)、DWS 层(指标计算)和 APP 层(针对具体应用场景开发),最终将数据输出至下游存储。下游存储依据业务场景选择不同,ToC 场景多使用内部的 KV 存储引擎 Abase,分析型场景及对内产品、平台则使用 ClickHouse 或 Doris,以供下游业务使用。
(2)问题挑战
在开发过程中,主要面临着三个问题:
其一,由于数据量大且计算复杂,致使链路稳定性差,任务频繁失败;
其二,资源消耗巨大,整体计算资源已达 30 万 core;
其三,任务异常恢复缓慢,晚高峰时异常恢复时长30+分钟。
02、链路通用优化
2.1 通用优化方案
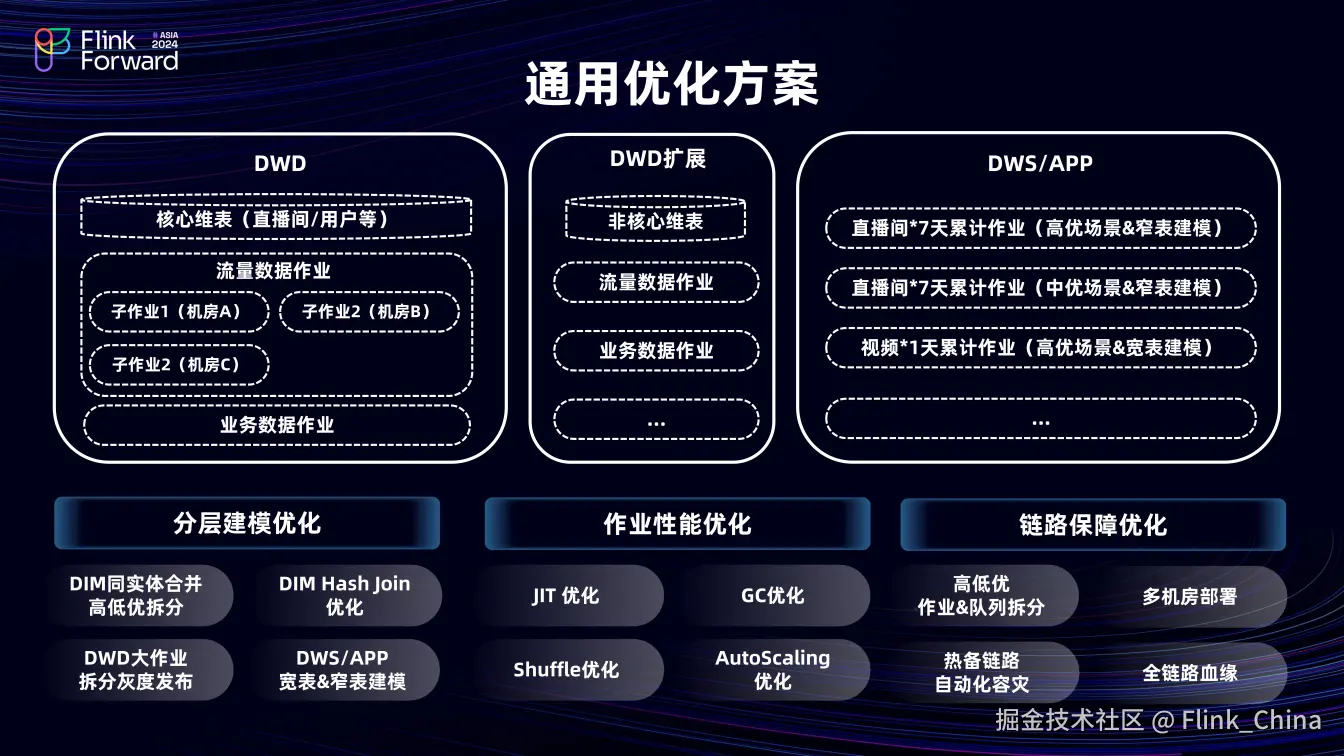
在 DWD 明细层,优化关联操作,核心维表在此层关联,而非核心维表及字段则在 DWD 扩展层关联。DWS 层和 APP 层计算直播及视频的天级累计指标。
(1)分层建模优化
在分层建模时,将相同实体、不同维度的数据合并为一张维表,以降低下游消费RPS。在维度关联时,使用 Keyby 提升本地缓存命中率。对于 DWD 大作业,将其拆分成多个小任务灰度上线。在视频大流量场景下,采用宽表模型输出指标,即将所有数据置于一行,存储在一个 Map 中输出;直播场景则使用窄表 Anchor 模型,一条数据对应一个指标一行数据。这两种模型在新增指标时均可实现状态兼容。
(2)作业性能优化
在任务层面进行性能优化以降低资源消耗,具体在后文中进行介绍。
(3)链路保障优化
对任务和队列进行分级,并构建全链路血缘来保障分级的准确性。对于高优任务,建立热备链路以及自动化容灾切换能力,提升链路大盘的容灾能力。
2.2 技术手段优化
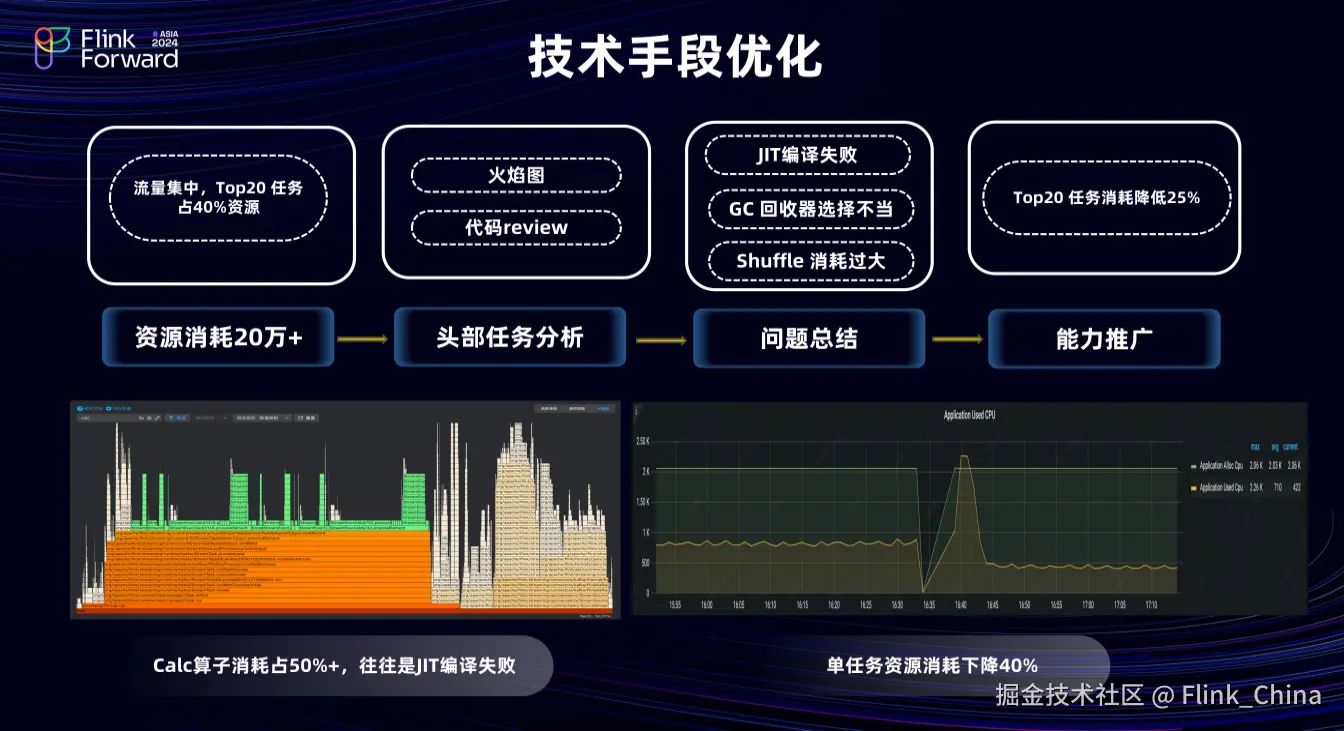
在抖音短视频业务中,流量呈现高度集中,top20个的任务占据40%以上的计算资源,这些任务不仅成本高,还会降低稳定性,加大运维难度。
从头部任务开发分析,部分简单的 Pipeline 任务消耗大量计算资源,可以结合火焰图查找问题的根源。如上图中左下角的火焰图,Calc 算子消耗占比达 56%,这对于非计算型的任务是明显异常情况。经分析是JIT及时编译优化失效所致。
再结合右侧重新开启优化后的图分析,大任务资源消耗下降约 40%。此外,火焰图中 Calc 占比较大的情况常出现在大并发 Hash 场景,上游并发×下游并发的数据输出队列会导致任务 Shuffle 利用率低,资源消耗较大。我们前后发现了十几项优化项,并推广至其他业务,最终 top 20 任务资源消耗下降约25%。
03、业务场景优化
3.1 视频场景痛点优化
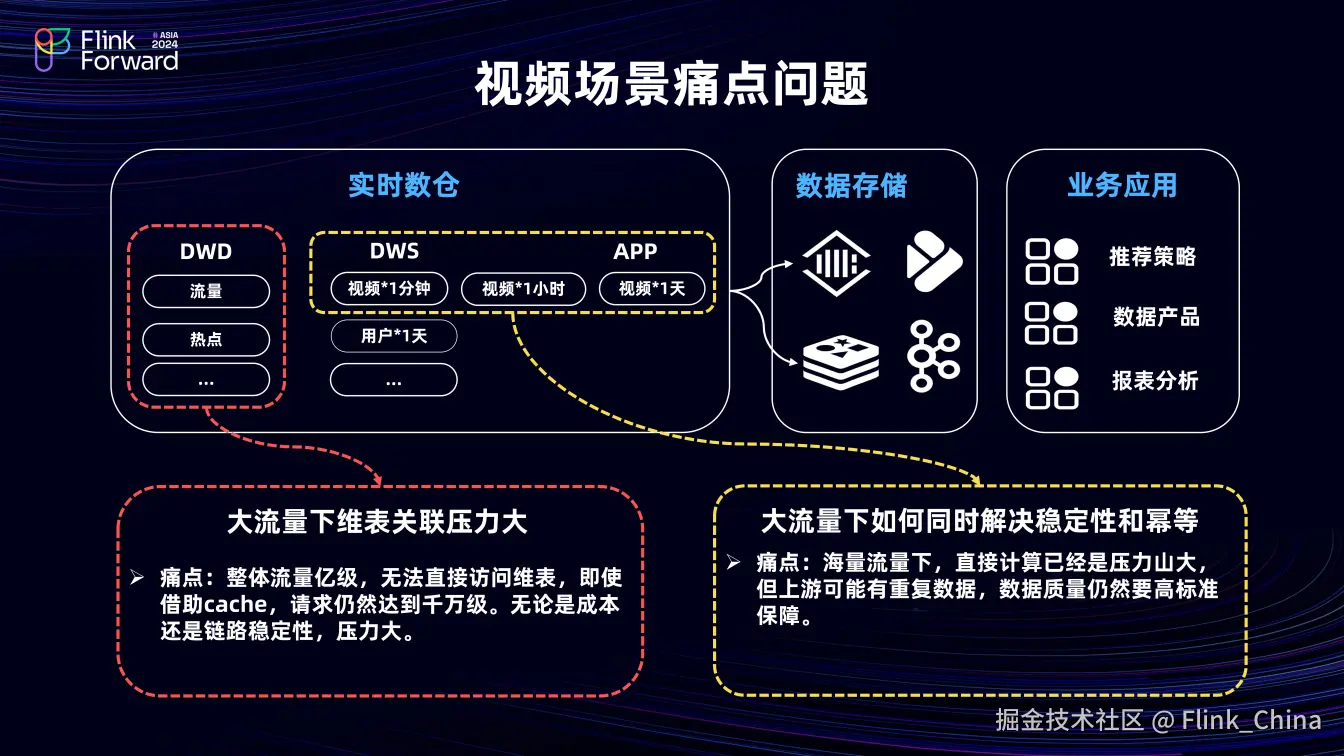
在 DWD 明细层,关联大量维表时面临巨大压力。大流量场景下整体流量达亿级规模,无法直接请求维表,即便开启维表 LRU cache 请求量也达千万级,这带来了成本和稳定性难题。在指标聚合计算时,大流量下解决重复数据问题挑战巨大。
(1)大流量维表关联优化
①场景分析
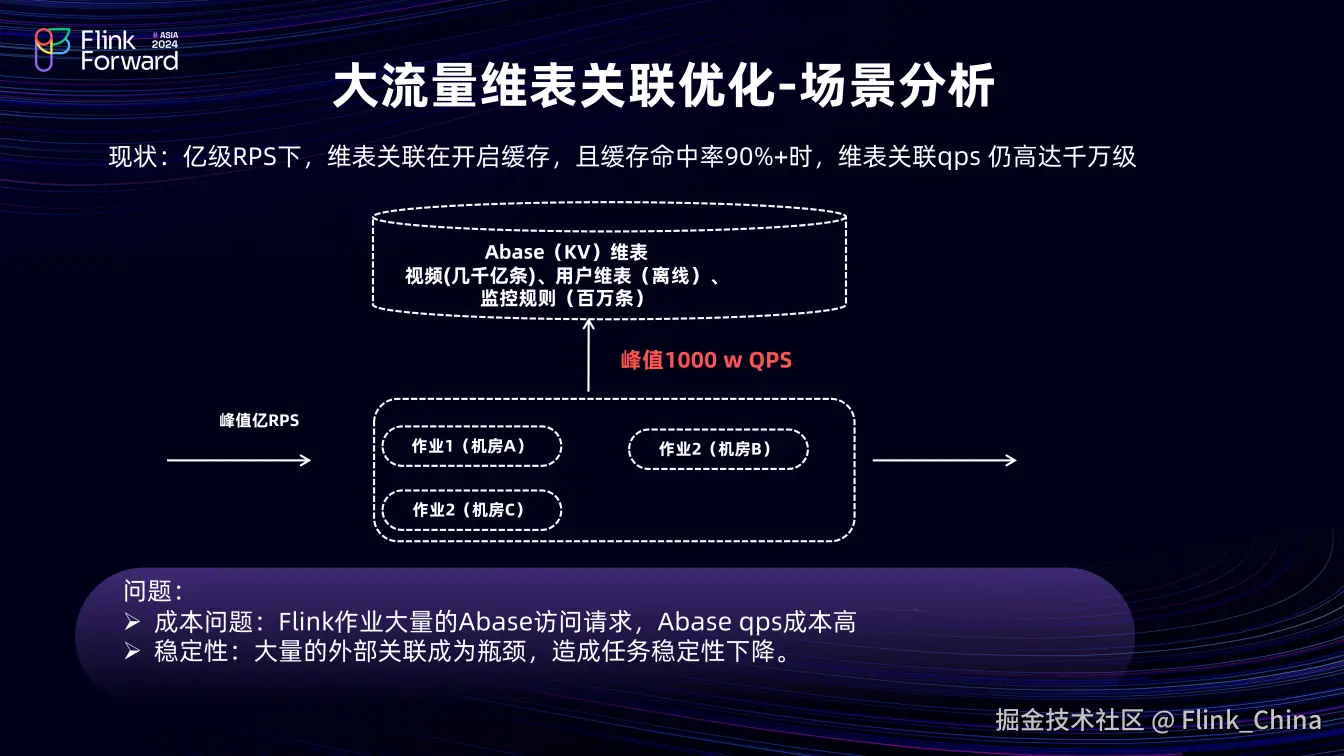
高 QPS 的维表访问导致 Abase 集群压力大,Flink 任务稳定性差,关联维表成为瓶颈。虽提升维表关联缓存命中率可降低外部请求 QPS,但目前缓存命中率已达 90% 以上,提升空间有限。且并非所有维表都超大且时效性要求高,如离线用户维表和百万级监控规则表都相对较小。数仓大量使用 Abase 这种 KV 存储支持大访问 QPS,但当超出其承受能力时,会带来不可控,因此需摆脱对 KV 引擎的依赖,引入新的维表存储方式。
②解决方案
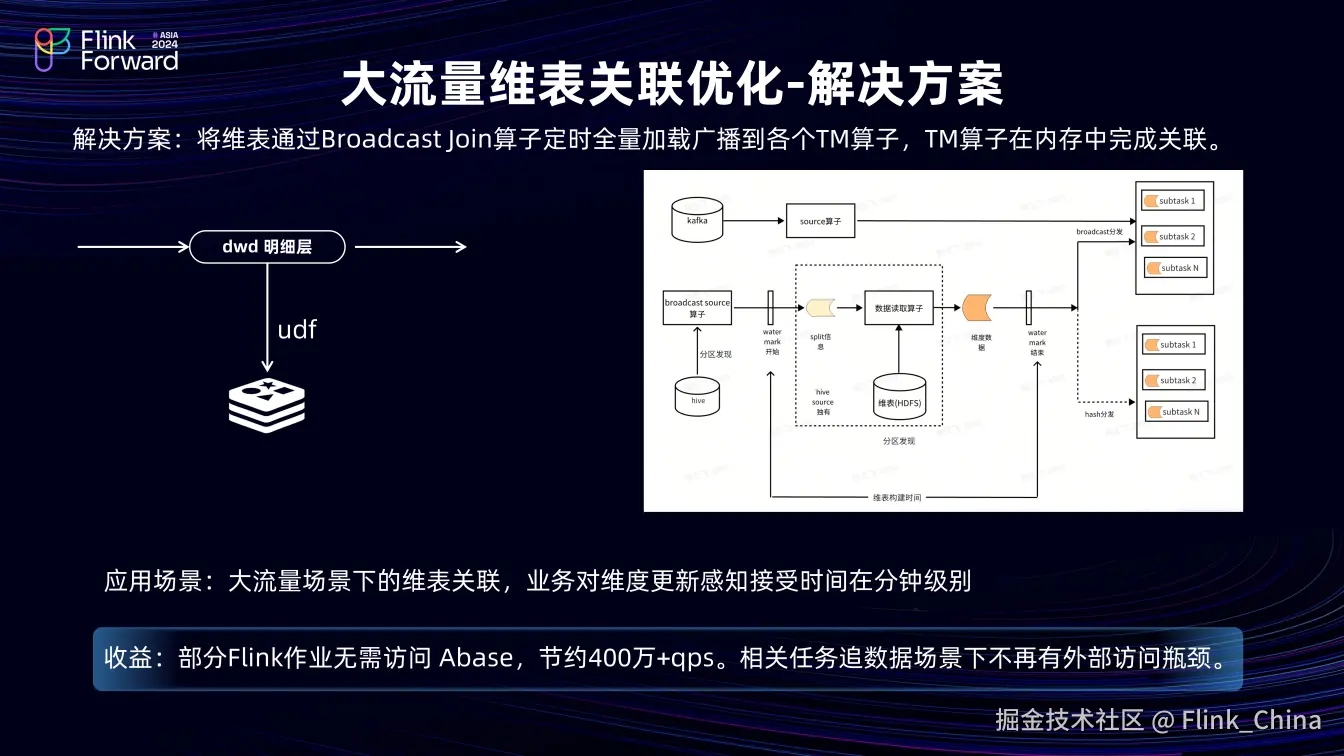
整体思路是将外部组件访问转化为本地访问,最直接的方式就是将数据加载到内存中完成计算。基于此,我们通过开发 UDF 将 Hive 和 MySQL 中的数据加载到内存中关联,但其并不通用,每次查询 Hive 和 MySQL 语句时需要单独指定,且只能加载少量数据,于是,我们将 UDF 升级为 Flink Broadcast join 功能。
该功能设计分为三个模块,以 Hive 为例。分区发现模块通过 Broadcast 算子监测 Hive 分区,发现新分区时,即向下游下发 Watermark 和表元数据信息;数据构建模块的数据读取算子,可配置大并发用于读取 Hive 维表数据;数据分发模块可以将读取的数据分发到各个 TM 中,根据数据量不同有两种分发方式, 即Broadcast 方式(将全量数据 copy 分发)或根据主键 Hash 分发(适用于数据量较大场景)。
在抖音内部场景,该功能支持了千亿级别的维表关联,主要适用于大流量场景下维表关联业务,对维表更新的感知在分钟级以上。功能上线后,它替代了部分 Abase 关联任务,减少约 400 万 QPS ,相关任务在追溯场景下无外部访问瓶颈。
(2)大流量幂等计算
①场景分析
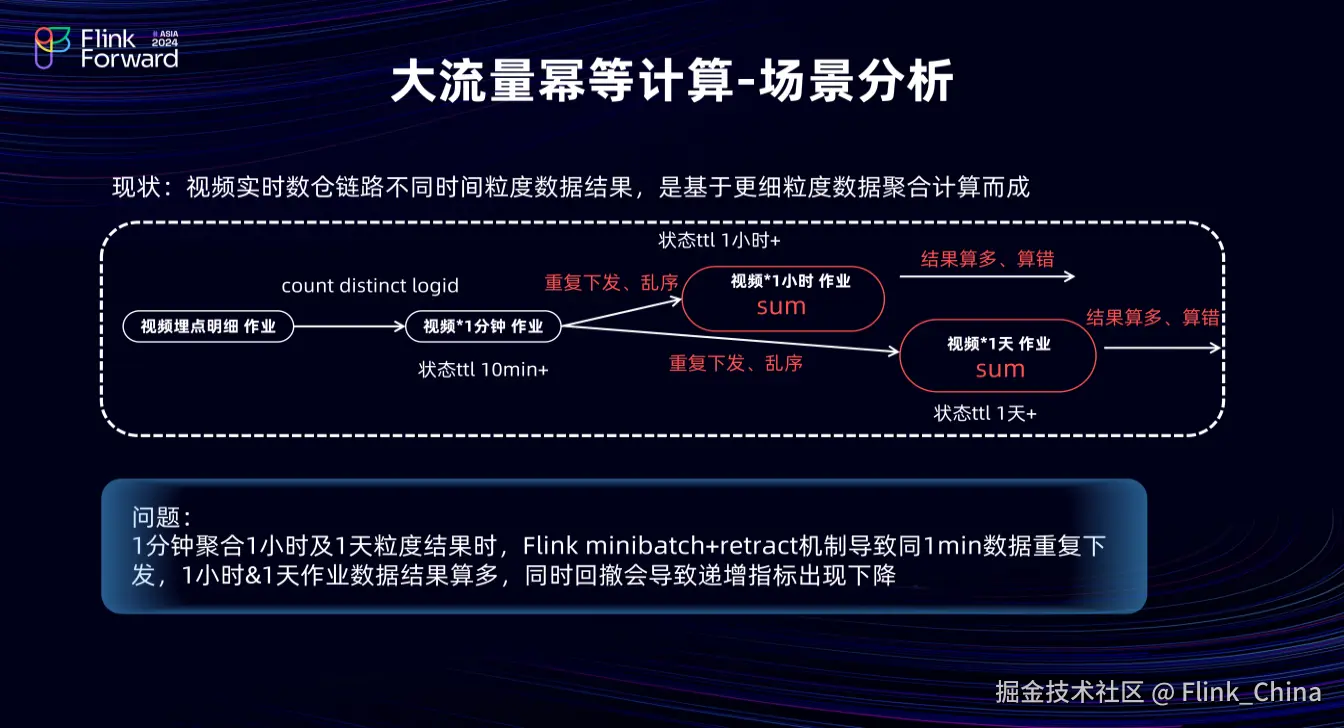
在大流量聚合计算优化方面,由于数据量大,短视频的小时和天级指标从分钟中间层聚合,这会导致分钟聚合输出有重复数据、乱序数据甚至回撤数据。如果直接通过先取 max 等方式聚合,其计算成本高且会引入回撤流问题,导致原本递增的埋点指标下降。以分钟向小时聚合为例,小时任务需要每一分钟的最后一条数据。
②解决方案
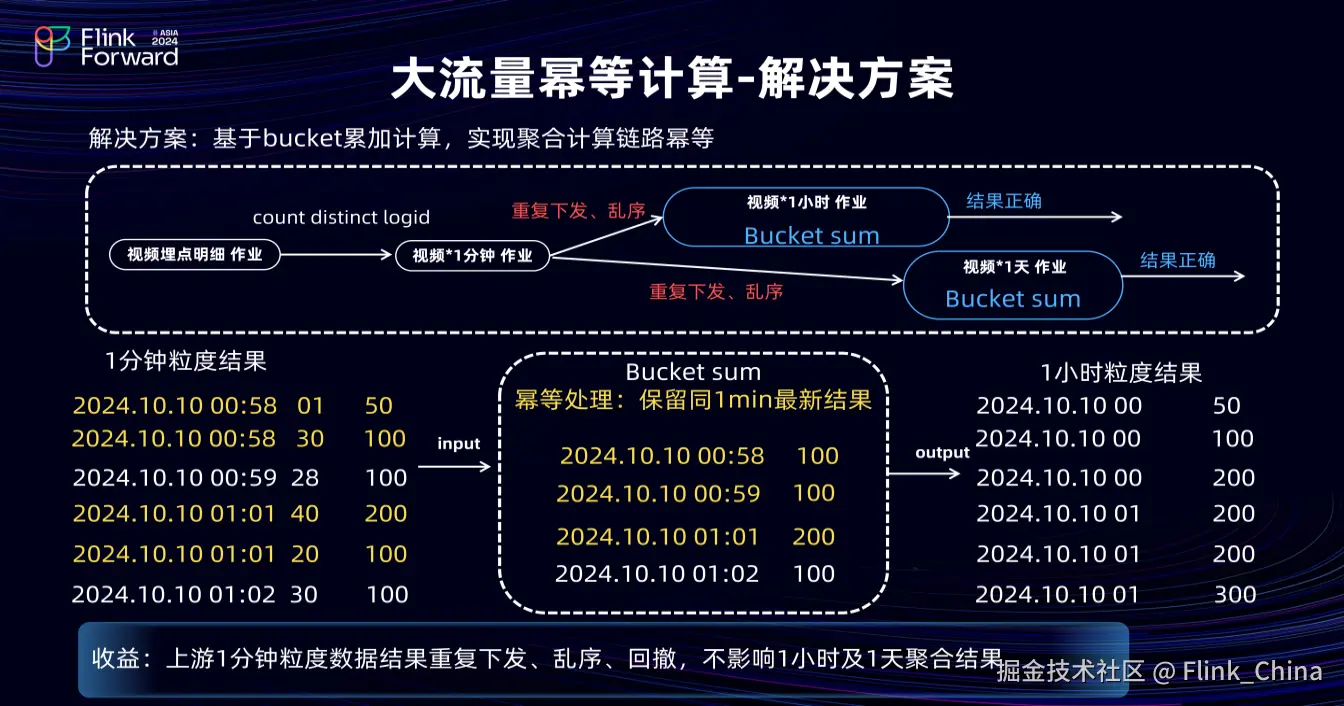
针对以上问题,我们引入了 Bucket 的思路,即每一分钟维护一个 Bucket,保留最后一条数据,新数据到来时,将其对应的 Bucket 与原本的数据相较,仅下发正序递增数据。这样,从分钟级向小时级聚合时,即使分钟级流量达百万 RPS,最终也只有 60 个 Bucket。
基于此简化模型,如上图左下角展示的分钟数据输出,第一列是分钟值,即 Bucket key;第二列是时间位移,用于 Bucket 的时间比较;第三列是指标值。第一、二条数据均为 58 分钟,因此,其属于同一个 Bucket,数据也是正序到来的,因此,Bucket记录为 30 秒;指标值为100的数据,第三条数据正常输出,第四条和第五条数据存在乱序,40 秒的数据先到,20秒的数据后到,因此,Bucket 只记录 40 秒的数据,在20 秒的数据进入后不再更新。这样,通过 Bucket 机制可有效处理重复下发、乱序和回撤数据,不影响小时及天指标聚合结果。
③性能优化
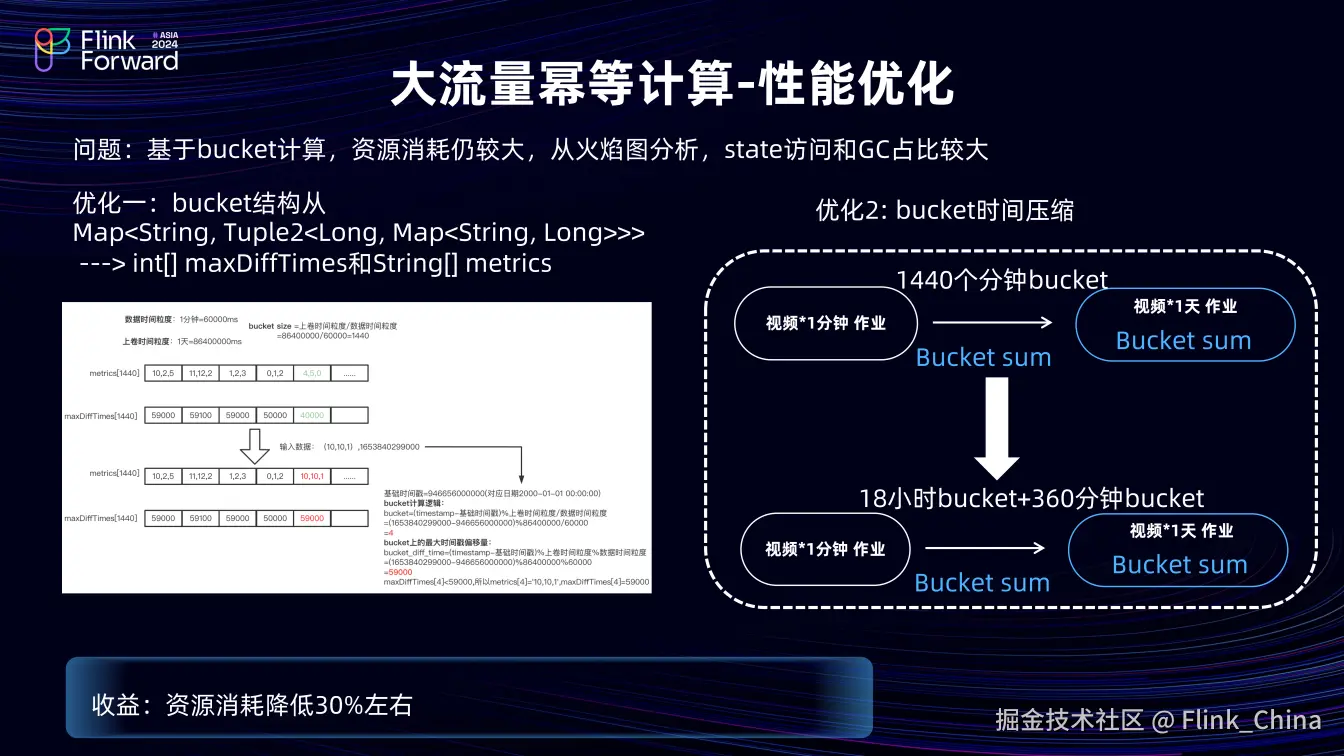
基于 Bucket 计算资源消耗仍较大,通过火焰图分析,发现 state 的序列化环节和 GC 环节占比较大,表明在状态和计算上仍有优化空间。我们从数据结构和业务两方面入手。
其一,优化 Bucket 结构,将多层嵌套结构改为两个数组,两个数组的长度等于 Bucket 的长度,无需要存储 Bucket key,按照数组的顺序取对应 Bucket。一个数组存储时间戳位移,将 long 格式的时间戳存储为 int 类型(减少存储占用),另一个数组通过字符串拼接指标值,将原本的 Map 中指标的 value 拼接成一行,节省 state 中的空间占用。
其二,进行 Bucket 时间压缩,从分钟向天级聚合最多 1440 个 Bucket,根据业务实际情况,将六个小时之前的 Bucket 压缩,Bucket 数量从1440 个降至378 个,降低约 70%。
完成这些优化后,整体资源消耗下降约 30%。
3.2 直播场景痛点问题
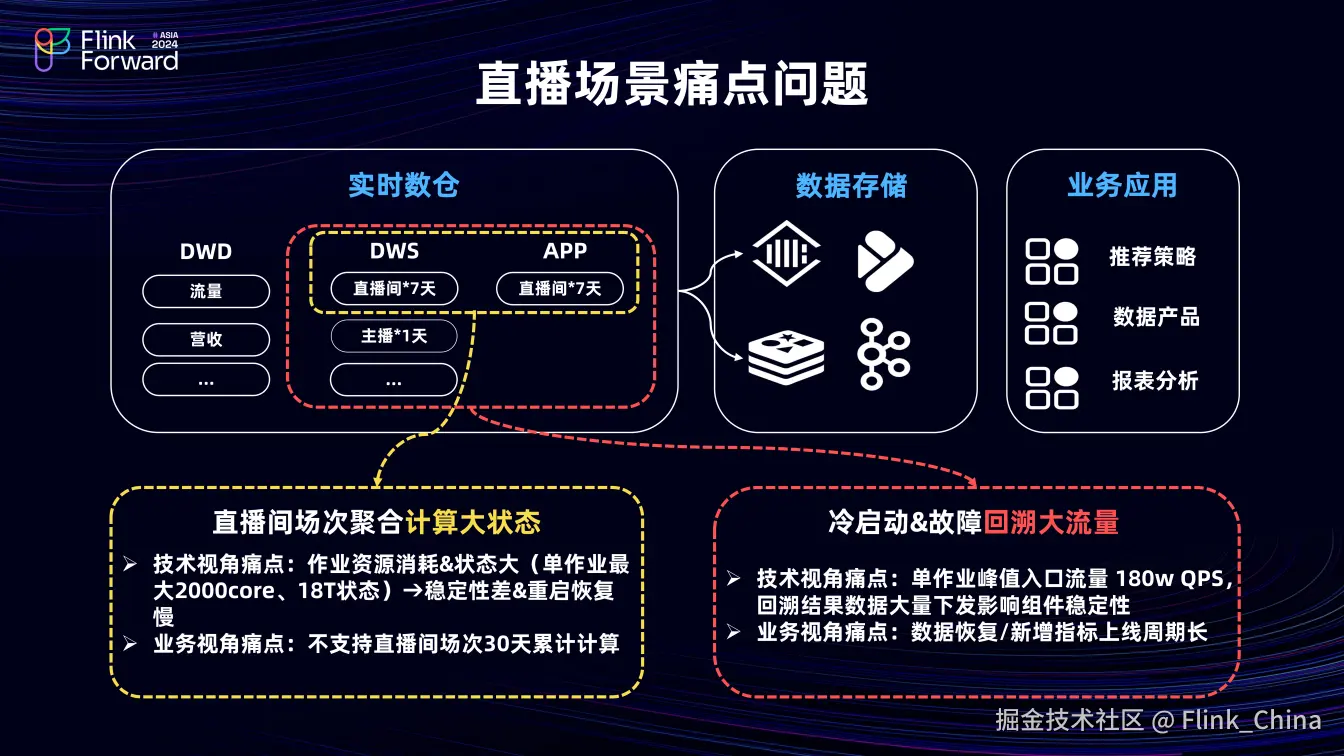
直播场景的痛点问题主要分为计算大状态和回溯大流量两类。
首先是直播间场次聚合计算大状态。抖音直播中,直播间最长可开播 30 天,但目前 Flink 作业的 DWS 和 APP 层只计算开播后七天状态的数据,即 state TTL 为七天。其原因是目前单作业资源消耗大,最高已达 2000 核,状态可达 18T,稳定性不佳,无法简单横向扩展资源解决问题。而业务有查看直播间 30 天累计指标的诉求。
其次是冷启动和故障回溯大流量。在此场景下,回溯数据从小时到天级不等,DWS 作业向下游下发数据时会重复且大量下发,影响下游 MQ 及 Redis 等 QA 存储组件稳定性。此外,Flink 作业运行虽有资源投入,但回溯数据仍较慢,从业务视角看,存在数据恢复慢和性能指标上线周期长的问题。
针对这些问题,我们提出了相应的解决方案。
(1)大状态优化
①场景分析

对于大状态优化场景,直播间开关播时间和时长不固定,最短不到分钟级,最长 30 天,平均在小时级别。分析 Flink 作业中不同开播时长的状态大小占比发现,state TTL 为七天时,开播时长一天的直播间状态大小占98%,这部分多存储六天;大于一天小于七天的占 1%,也存在多存情况;大于八天的仅占 0.5‰,存在少存情况。该问题的核心是状态固定的 TTL 与直播间动态的 TTL 矛盾,导致 99% 的状态多存,0.5‰状态少存。
解决思路是对齐两者 TTL,实现直播间关播后删除状态。
②方案设计
最初设计了两种方案。
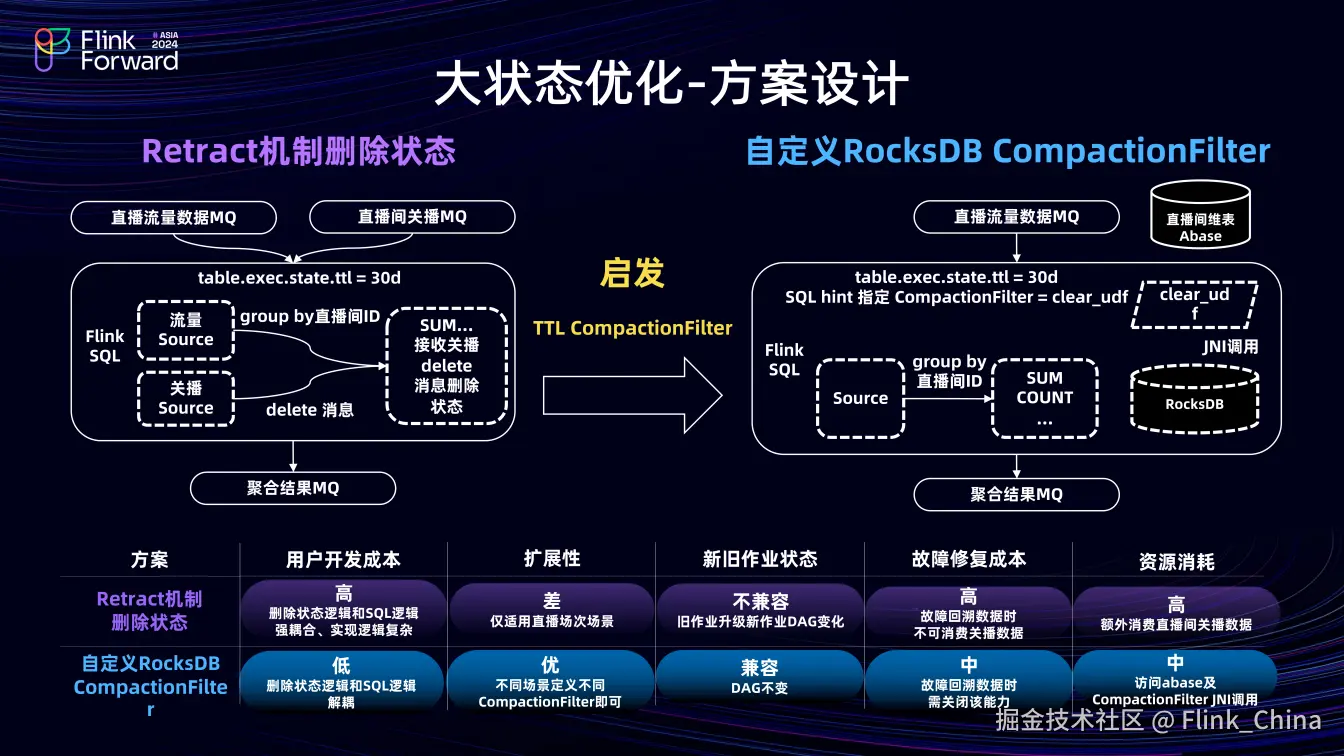
第一种基于 Retract 机制删除状态。在 Flink 作业中,同时消费直播间流量数据和关播数据,将两条数据进行聚合。按直播间 ID 分组聚合计算,关播 source 收到数据后向下游聚合算子发送 delete 消息,下游的聚合算子在接受到该消息后删除状态。
但该方案存在问题,用户开发成本高,删除状态逻辑与 SQL 逻辑强耦合,导致改造作业时开发成本大;扩展性差,仅适用于 group key 为直播间 ID的场景,而实际业务中 group key 可能包含更多内容,如用户画像或主播画像等,则不适用。
总结问题后,发现其核心是删除状态逻辑与 SQL 逻辑强耦合,进而设计了第二种方案作为TTL CompactionFilter 方案的扩展,即自定义 RocksDB CompactionFilter 方案。两者执行时机相同,自定义 RocksDB CompactionFilter 方案支持通过 Java UDF 为指定状态设定CompactionFilter 。两者的区别在于,TTL CompactionFilter 执行时解析状态中的时间戳判断状态是否删除,而自定义方案在 RocksDB 执行时,通过JNI将状态数据传给 Flink TM,解析直播间 ID 作为 CompactionFilter 入参,访问直播间 Abase 维表,判断是否关播,若关播,则 CompactionFilter 返回 true,删除状态。此方案实现了直播间关播后的状态删除,且与 SQL 逻辑完全解耦,解决了方案一中的问题。
③落地方案
与 Flink 架构组共建,实现了该方案的落地。

Flink 架构组在 RocksDB 层面支持 CompactionFilter 能力,在 SQL 层面支持用户为指定聚合算子指定 CompactionFilter。如代码示例所示,设置状态 TTL 为 30 天,通过ADD RESOURCES 语句引入CompactionFilter 的 jar 包,通过 SQL hint 指定聚合算子的 CompactionFilter,参数包括path(路径) 和 filed(直播间 ID)。
实现过程中对性能问题进行了优化,如 CompactionFilter 查询性能优化,将实时访问 Abase 优化为批量加载关播直播间数据到本地,判断是否关播,避免Compaction 执行过程中, CompactionFilter 访问外部组件查询阻塞,减少 CP 的时长;Cache选择优化,将本地存储关播直播间的 cache 从内存优化到磁盘,降低 GC 时长;CompactionFilter 调用频次优化,设定 state 存储时长超过两天才调用 CompactionFilter,减少未关播直播间频繁调用导致的 CPU 浪费,同时在 RocksDB C++侧缓存 直播间开关播的结果(CompactionFilter 结果),利用 RocksDB 存储机制,将直播间 ID 放在 group by 语句最前面,顺序存储相同 ID 的状态数据,复用 CompactionFilter 调用结果,避免 JNI 调用带来的性能损耗。
通过该方案,业务上支持了直播间 30 天累计指标,技术上直播间场次作业状态平均下降 60%,CPU资源使用下降 70%。
(2)大流量回溯优化
①场景分析
分析无 lag 场景和追lag 场景下作业期望目标。

无 lag 场景追求低延迟,数据实时产出,期望数据处理模式为流处理;追 lag 场景追求短时间内快速恢复,数据高吞吐,期望处理模式为批处理。
但当前 Flink 流处理作业仅能以流处理运行,设置 Minibatch 为 30 秒,在无 lag 场景可行,而在追 lag 场景则存在吞吐低、恢复慢的问题,与预期高吞吐目标不符。
为解决此问题,分析 Flink 流处理和批处理在引擎实现上的差异,在满足Flink 流处理低延迟特性的同时,实现 Flink 批处理的高吞吐。流处理通过 Minibatch 机制保证低延迟,但其 RocksDB 随机访问和 Retract 机制限制了吞吐;批处理虽有高延迟,但通过 sort 排序处理且无 Retract 机制,吞吐较高。因此,我们提出在流作业中动态监测消费积压情况,判断作业对高吞吐或低延迟的倾向性,在当前算子引入 sort 排序算子和动态调整 Minibatch 大小的能力,实现流批执行模式的动态切换。
②方案设计

该方案核心步骤包括积压检测、检测结果传递和动态启用 sorter 算子并调整 Minibatch 大小。Flink 作业运行时,Source 算子动态监测 lag size;当 lag size 超过指定值时,向下游算子发送数据时,标记 isBackLog 为 true,聚合算子接收数据后解析该字段,若为 true,则认为当前作业倾向于批处理,启用 sorter,将 Minibatch 的大小间隔调整为 CP 的间隔。
此方案实现了流作业执行过程中流处理和批处理模式的动态切换,且作业的 DAG 不变,状态完全兼容。
③落地方案
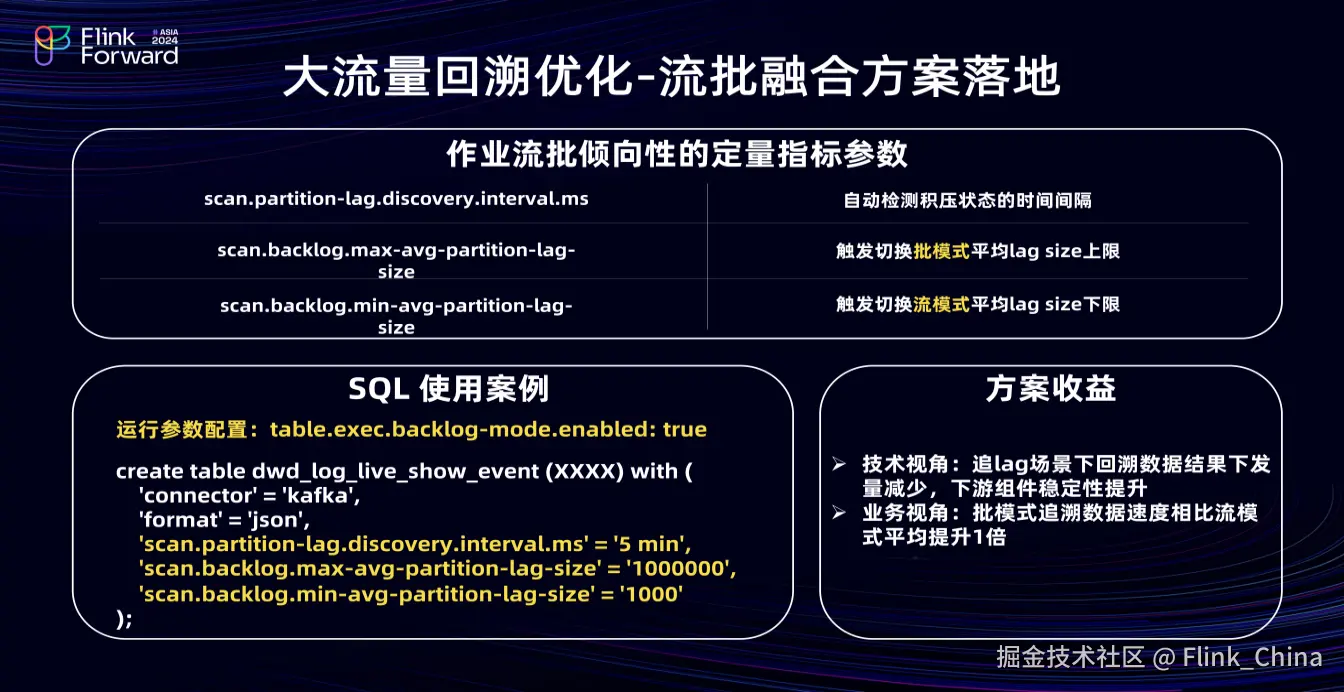
Flink流批倾向性指标有三个,即自动检测积压状态时间间隔、触发切换批模式处理的平均 lag size 上限、触发切换流处理平均 lag size 下限。SQL 使用案例如上图左下角所示:首先,在运行参数中设置 backlog mode开启,然后在 source 算子中指定以上三个参数,进而实现 Flink作业流批融合的处理。
通过该方案,技术上,追 lag 场景回溯数据结果下发量减少,下游组件稳定性提升;业务上,批模式追溯速度比流模式提升一倍。
04、未来规划
在抖音一级RPS场景下,未来优化分为通用优化和个性化场景优化。
4.1 通用优化
作业重启时内存 localcache 失效导致的缓存穿透优化;使用 Paimon 维表能力减少对 Redis 等 K-V 存储的请求,使用 PaimonWithMQ 能力减少 MQ dump 派作业,节约资源;丰富 AutoScaling 的资源优化规则,获取更多收益。
4.2 个性化场景优化
解决多任务比值类指标分子分母更新快慢不一致导致的波动明显问题;实现broadcast join 支持状态的增量加载,针对千亿级维表,拒绝全量加载,而是定时加载仅变化的增量数据,提升作业稳定性;进行内存优化。