开发者朋友们大家好:
这里是 「RTE 开发者日报」 ,每天和大家一起看新闻、聊八卦。我们的社区编辑团队会整理分享 RTE(Real-Time Engagement) 领域内「有话题的 技术 」、「有亮点的 产品 」、「有思考的 文章 」、「有态度的 观点 」、「有看点的 活动 」,但内容仅代表编辑的个人观点,欢迎大家留言、跟帖、讨论。
本期编辑:@赵怡岭、@鲍勃
01有话题的技术
1、阿里开源 FantasyPortrait 框架:支持多角色同步演绎,可无缝扩展为音频驱动框架
FantasyPortrait 是一个基于扩散变换器(DIT)的框架,由阿里巴巴高德地图团队与北京邮电大学联合发布。它能够为单角色和多角色场景生成高保真且情感丰富的动画。
FantasyPortrait 摒弃显式几何先验,系统通过隐式面部表示学习细粒度表情特征,显著提升对嘴部动作和情感表达的建模能力。驱动视频的面部动作特征被提取后,通过特征迁移融合技术生成最终动画。其独创的掩码式交叉注意机制实现多角色独立控制与协同生成,有效解决不同角色间的特征干扰问题。该设计支持使用多个单人视频或一个多人视频同时驱动多个角色。
-
多角色同步驱动: FantasyPortrait 支持使用单个或多个单人视频,或直接采用一段包含多人的视频,即可同步驱动多个角色,生成细腻自然、高度写实的人像动画;
-
多风格角色适配: FantasyPortrait 能够为不同艺术风格的角色生成动画,输出动态流畅、生动自然且风格统一的视频;
-
多风格角色适配: FantasyPortrait 能够为不同艺术风格的角色生成动画,输出动态流畅、生动自然且风格统一的视频;
-
多风格角色适配: FantasyPortrait 能够为不同艺术风格的角色生成动画,输出动态流畅、生动自然且风格统一的视频。
GitHub: github.com/Fantasy-AMA...
项目官网:fantasy-amap.github.io/fantasy-por... (@AIGitHub)
2、开源音频模型 Higgs Audio V2,基于 1000 万小时音频数据训练
Boson AI 正式开源其强大的音频基础模型 Higgs Audio V2。这款模型在超过 1000 万小时的音频数据和多样化文本数据上进行预训练,展现出深厚的语言与声学理解能力。除了一些常规语音任务外,模型支持生成多种语言的自然多说话人对话、叙述过程中自动调整韵律、使用克隆声音进行旋律哼唱以及语音与背景音乐同步生成。
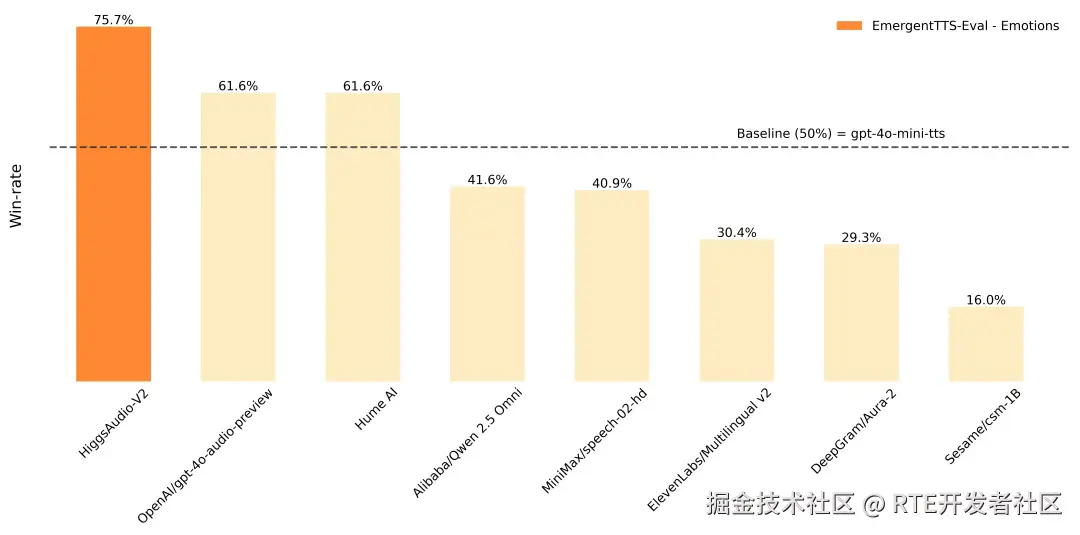
性能亮点:
-
超越 GPT-4o-mini-tts:在 EmergentTTS-Eval 中,Higgs Audio V2 在「情感」类别以 75.7% 的胜率、在「问题」类别以 55.7% 的胜率超越了 gpt-4o-mini-tts;
-
传统 TTS 基准测试领先:在 Seed-TTS Eval 和情感语音数据集(ESD)上均取得了最先进的性能。
功能亮点:
-
自动韵律适应:在叙述过程中能自动调整韵律;
-
多语言零样本生成:能够自然生成多说话人对话,无需额外训练即可支持多种语言;
-
旋律哼唱:支持使用克隆声音进行旋律哼唱;
-
语音与背景音乐同步生成:能够同时生成语音和背景音乐;
-
多说话人对话生成:轻松实现多说话人之间的对话生成;
-
长篇音频生成:凭借强大的条件控制和提示功能,Higgs Audio V2 能够实现良好的长篇音频效果;
-
高保真音频:V2 版本将音频管线从 16kHz 升级至 24kHz,提升了音频质量和声音的逼真度。
Higgs Audio V2 在超过 1000 万小时音频数据上的训练,确保了更佳的音频质量和更逼真的声音。其模型训练依赖于复杂的处理和标注流程,实现了训练数据的自动化生成。
相关链接:www.boson.ai/blog/higgs-...
模型代码:github.com/boson-ai/hi...
3、长时文生音频系统 FreeAudio:基于免训练方法精准控制生成时长
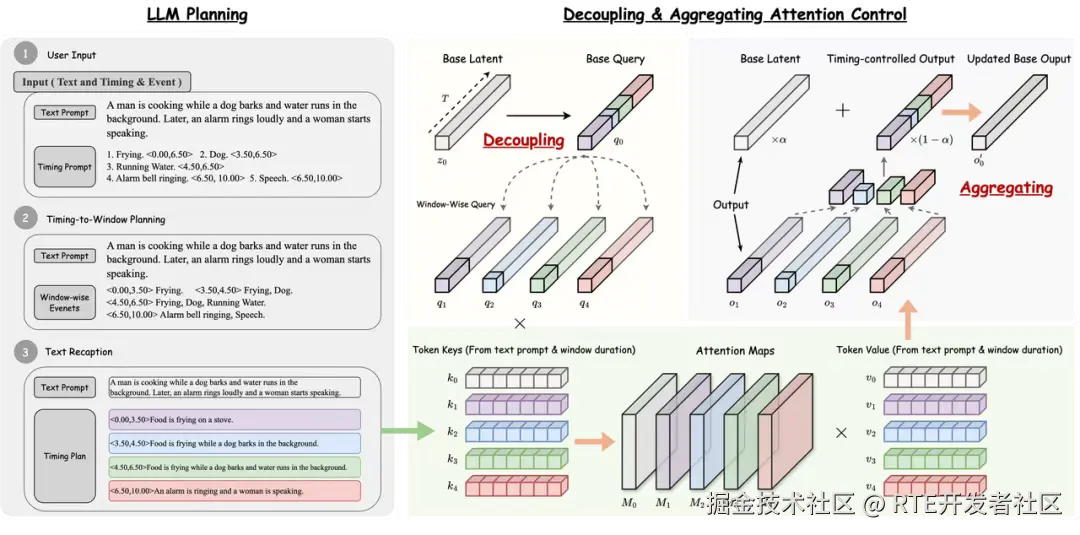
清华大学和生数科技最新科研成果提出了一种基于免训练方法的精准时间可控长时文生音频系统 FreeAudio,可基于自然语言文本与时间提示实现精确的时间控制与长时音频生成,例如 0-10 秒,森林风吹;0-4 秒,鸟儿鸣叫;4-6 秒,木头燃烧;6-16 秒,动物踩在干树叶上的脚步声;10-16 秒,蟋蟀鸣叫;16-19 秒,猫头鹰鸣叫;17-26 秒,溪水流淌
该方法利用 LLM 对时间结构进行规划,将文本与时间提示解析为一系列互不重叠的时间窗口,并为每个窗口生成适配的自然语言描述。随后,FreeAudio 依次生成各时间片段的音频内容,并通过上下文融合与参考引导机制实现最终的长时音频合成。
在时间可控音频生成方面,FreeAudio 首先借助 LLM 的 Chain-of-Thought(CoT)思维链推理规划能力,将文本提示和时间提示解析为一系列不重叠的时间窗口,再将每个时间窗口对应的一组事件重述为适合 T2A 模型生成的文本提示。
-
避免音效版权风险,解决音效匹配难题;
-
大幅降低音效制作成本;
-
支持多音轨秒级对齐(如环境声 + 动物鸣叫精准叠加)
FreeAudio 系统未来将在 Vidu 产品端上线。(@生数 ShengShu)
4、谷歌 Gemini 2.5 升级:对话指令驱动的智能图像分割
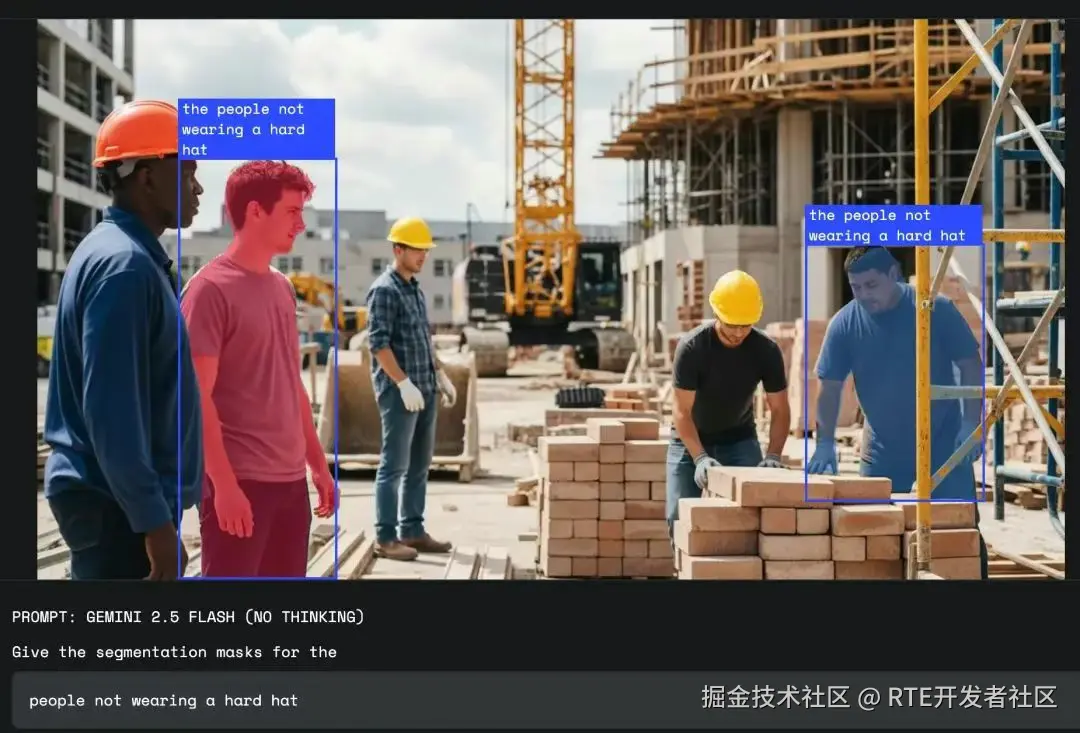
谷歌的 Gemini 2.5 现已支持对话式语义图像分割功能。它突破传统图像分割仅识别固定类别物体的局限,能理解复杂语义指令,像关系查询、基于逻辑的指令以及抽象概念等,并通过内置文本识别功能识别图像元素。
该功能支持多语言提示,可在图像编辑、工作场所安全、保险等多领域广泛应用,开发者能通过 Gemini API 便捷访问。
官方博客:developers.googleblog.com/en/conversa... (@三花 AI、@喜爱谱 CAIP)
02有亮点的产品
1、浏览器端音乐创作工具 MusicGPT:支持选择多种音乐氛围和自定义混音效果
MusicGPT 是一款创新的浏览器端音乐创作工具,致力于让用户轻松实现歌曲创作、混音与制作。这款产品完全基于下一代生成式 AI 驱动,确保用户创作的音乐 100% 原创且版权安全,无需担心盗用样本或付费插件的问题。
产品亮点:
-
完全原创与版权安全:MusicGPT 生成的所有音频都是独一无二的,且不含任何盗用样本,确保作品拥有完整版权;
-
超越竞品:MusicGPT 提供了比 Suno、Murf 和 Udio 更强大的工具和功能;
-
全能型浏览器体验:无论是节拍、人声还是混音,所有功能都可在浏览器中完成,无需额外设备或插件;
-
直观的创作流程:
- 氛围选择:支持选择多种音乐氛围,例如 Chillhop、Jazzhop 等;
- 歌词输入:输入歌词、剧本等;
- 混音设定:自定义混音效果;
- 即时生成与导出:MusicGPT 会将设定转化为一首完整的曲目,并支持即时导出。
体验链接: musicgpt.com(@Kawsar_Ai@X)
2、Checklist Genie:利用语音或图片自动生成可操作的清单
Checklist Genie 是一款利用 AI 技术,通过语音或照片快速生成并分享待办清单的工具,核心价值在于极简化用户创建和管理任务列表的流程。目标用户主要为需要高效管理日常任务和例行事务的个人及职场人士,尤其重视便捷性和智能化体验。 该产品解决了传统清单制作繁琐、耗时的问题,满足用户即时捕捉灵感和快速组织任务的需求,同时具备跟踪日常、每周、每月例行事务的功能,体现出较强的市场潜力,尤其在提高个人生产力及时间管理方面具备较大机会。
功能上,Checklist Genie 亮点包括利用语音或图片自动生成可操作的清单,智能追踪多周期的日程安排,以及简洁高效的分享机制。
相比传统清单工具,其差异化优势在于集成了 AI 自动识别和转换信息的能力,减少手动输入,提高使用效率。
网站链接:checklistgenie.app(@Z Potentials、@Product Hunt)
3、XREAL One Pro 智能 AR 眼镜上架
日前,XREAL 正式推出了最新款智能 AR 眼镜 XREAL One Pro,首发价格为 4299 元。
外观方面,对比上一代的 XREAL Air 2 系列,XREAL One Pro 搭载了全新设计的 X-Prism 光机,镜片和镜框都要更小更薄,也更贴脸,戴在头上也要更像一副普通的太阳镜。

延续了先前 XREAL One 上的自研「X1」空间芯片,XREAL One Pro 机身配备了一个小系统,视场角从 50° 提升至 57°,显示面积提升 38%。并且,由于自带空间计算能力,XREAL One Pro 眼镜本体提供了不同的空间屏模式:云台模式和悬停模式。
鼻托的部分支持摄像头组件的插拔,让眼镜拥有 1200 万像素的摄像头,能拍照片也能拍视频,还能进一步让眼镜支持 6DoF 的悬停,将现实的画面定在一个地方,用户可以走近画面仔细观察。
XREAL One Pro 还支持三档电致变色,可以调暗 AR 虚拟屏幕以外的环境,更有沉浸感。而开启自动通透模式后,将头朝向屏幕之外的地方,能够自动恢复镜片透明度。
听音方面,XREAL One Pro 配备了和 Bose 联合调教的音响系统,通过眼镜的镜柄实现环绕声,一站式解决视听体验,不用额外的耳机。(@APPSO)
03有态度的观点
1、OpenAI:ChatGPT 平均每天收到 25 亿条提示词
7 月 22 日,据 Axios 报道,OpenAI 透露表示,ChatGPT 平均每天要收到用户发送的 25 亿条提示词,而其中约有 3.3 亿条来自美国用户。
作为对比,Google 母公司 Alphabet 虽没有公开每日数据,但据 Axios 援引消息显示,Google 每年接收到 5 万亿次的查询,每天平均约有 140 亿次搜索,而 OpenAI 使用频率已经逼近 Google 搜索量的五分之一。 值得一提的是,去年 OpenAI CEO Sam Altman 曾表示,用户平均每天向 ChatGPT 发送超 10 亿条提示词,而如今该数据已翻倍。(@APPSO)
2、AI 教父:我们误解了模型推理的不够好
日前,被誉为「AI 教父」的图灵奖得主 Geoffrey Hinton 与 AI 创企 Cohere 联合创始人 Nick Frosst 进行了一次炉边对话,两人围绕 AI 与人类的关系进行了一次深入探讨。
交流中,Hinton 指出人们对模型推理的误解:模型推理错误时,自然会觉得它根本不理解。而 Hinton 认为,模型就如同有学习障碍的人一样------在基础推理上能够答对,复杂问题上可能做得不好。
同时 Hinton 也表示,模型推理在面对复杂问题时会出错,本质上是很多瓶颈限制而导致的的,并且这些瓶颈并非与 AI 本身直接相关:可能是隐私问题,也可能是部署问题,或它所接入的数据问题。
而在 Frosst 看来,AI 的运作机制与人类的思维方式也有很大区别。「尽管 AI 非常有用,但它们的工作原理和人类思维的机制仍有很大差距。」但 Frosst 将 AI 与人脑的工作机制比作飞机与鸟类的飞行方式------路径不同,但效果相似。
另外,Hinton 也在交流中详细分析了 AI 在未来的发展趋势。其指出,「我们每个人都会有非常聪明的 AI 助手,它们知道很多关于我们的事情,我们也不再需要传统的助理。」而这一方向也会引发人类的「生存性风险」。
对此,Hinton 也指出,这一「生存性风险」指的是 AI 接管整个世界,同时,短期的风险同样致命------包括 AI 被用来干预选举、监控人类、帮助研发自动化致命武器或生物武器,甚至发动新形式的网络攻击等。(@APPSO)

更多 Voice Agent 学习笔记:
GPT-4o 之后,Voice 从 Assistant 到 Agent,新机会藏在哪些场景里?|Voice Agent 学习笔记
对话 Wispr Flow 创始人 Tanay:语音输入,如何创造极致的 Voice AI 产品体验
Notion 创始人 Ivan Zhao:传统软件开发是造桥,AI 开发更像酿酒,提供环境让 AI 自行发展
ElevenLabs 语音智能体提示词指南 ------ 解锁 AI 语音交互的「灵魂秘籍」丨 Voice Agent 学习笔记
11Labs 增长负责人分享:企业级市场将从消费级或开发者切入丨Voice Agent 学习笔记
实时多模态如何重塑未来交互?我们邀请 Gemini 解锁了 39 个实时互动新可能丨Voice Agent 学习笔记
级联vs端到端、全双工、轮次检测、方言语种、商业模式...语音 AI 开发者都在关心什么?
视频丨Google 最新 AI 眼镜原型曝光:轻量 XR+情境感知 AI 打造下一代计算平台
a16z 最新报告:AI 数字人应用层即将爆发,或将孕育数十亿美金市场
a16z合伙人:语音交互将成为AI应用公司最强大的突破口之一,巨头们在B2C市场已落后太多丨Voice Agent 学习笔记
写在最后:
我们欢迎更多的小伙伴参与 「RTE 开发者日报」 内容的共创,感兴趣的朋友请通过开发者社区或公众号留言联系,记得报暗号「共创」。
对于任何反馈(包括但不限于内容上、形式上)我们不胜感激、并有小惊喜回馈,例如你希望从日报中看到哪些内容;自己推荐的信源、项目、话题、活动等;或者列举几个你喜欢看、平时常看的内容渠道;内容排版或呈现形式上有哪些可以改进的地方等。

素材来源官方媒体/网络新闻