目录
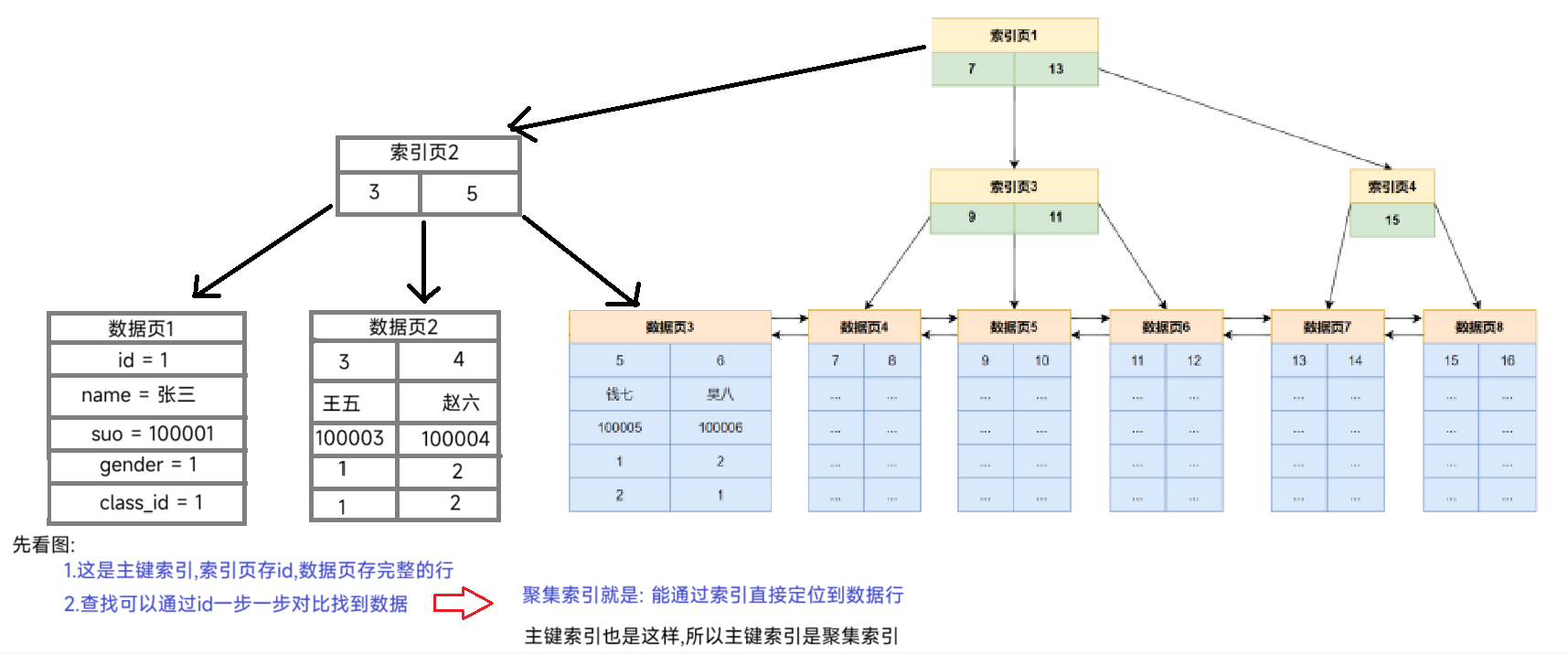
1.索引:⼀种特殊的数据结构,它可以帮助数据库⾼效地查询、更新数据表中的数据
[编辑 7.页的主体:](#编辑 7.页的主体:)
[<7>. 索引覆盖](#<7>. 索引覆盖)
[4. 索引使用或创建](#4. 索引使用或创建)
[<2>. 手动创建](#<2>. 手动创建)
在约束条件的外键约束 中,我们知道子表 与父表 建立联系时,父表对应列 必须要有索引(否则会大幅度减低查询速度,sql不允许这种情况),即:手动添加 或者被primary key , unique 修饰的列自动会创建索引
索引
1.索引:⼀种特殊的数据结构,它可以帮助数据库⾼效地查询、更新数据表中的数据
提到数据结构,不由得想起: 顺序表 链表 栈 队列 优先级队列 二叉树 二叉搜索树(红黑树 avl树) HASH表.其中那个可以作为索引的数据结构?
其中能提高查询速度的可谓是: 二叉搜索树 HASH
二叉搜索树:
---avl树:也称平衡树,要求左右子树的树高差<=1,虽然提高了访问速度,但插入要对树不断进行调整 ------>不用他
---红黑树: avl树的一种权衡,不要求严格意义上的平衡,二球查询速度稍微慢了一点(几乎感知不到),提高了插入删除速度------>树高随着数据的增多也越来越高,IO访问次数越多
HASH表:虽然删除查询快o(1),但只能针对等值查询,无法进行模糊查询,范围查询等
所以索引引入了B+树(也称B-树)这样的数据结构,他是B树的优化版
2.B树:是N叉数
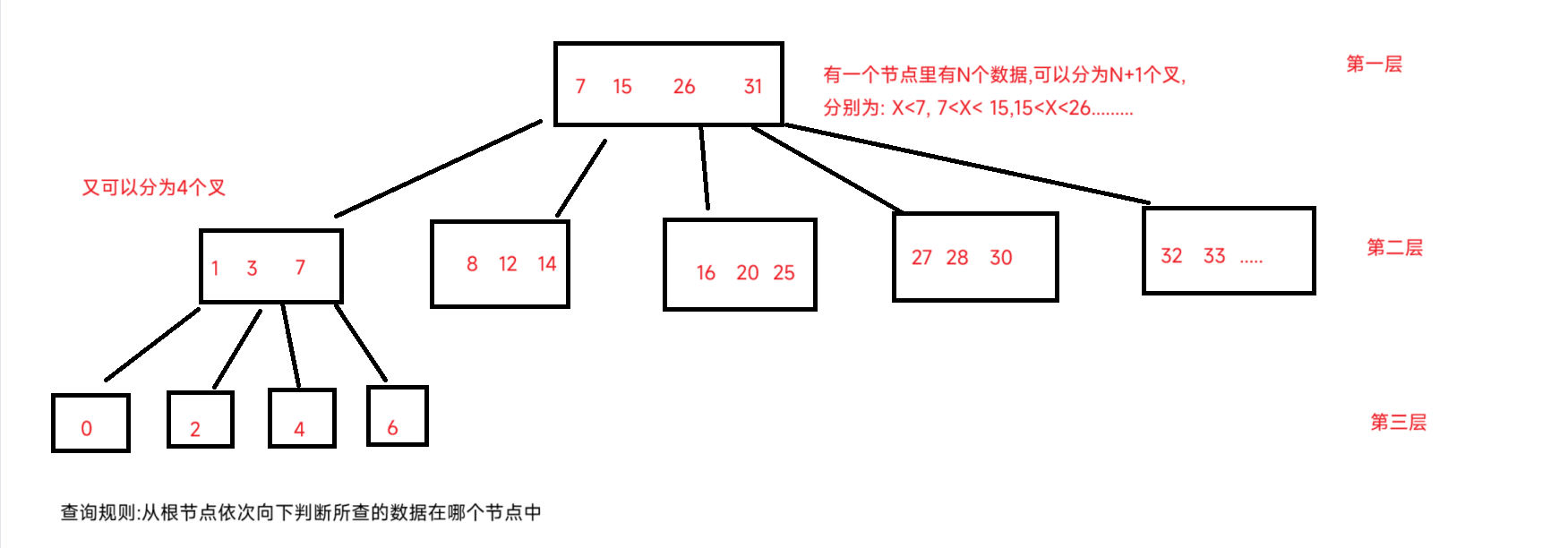
3.B+树(B-树):B数的升级版
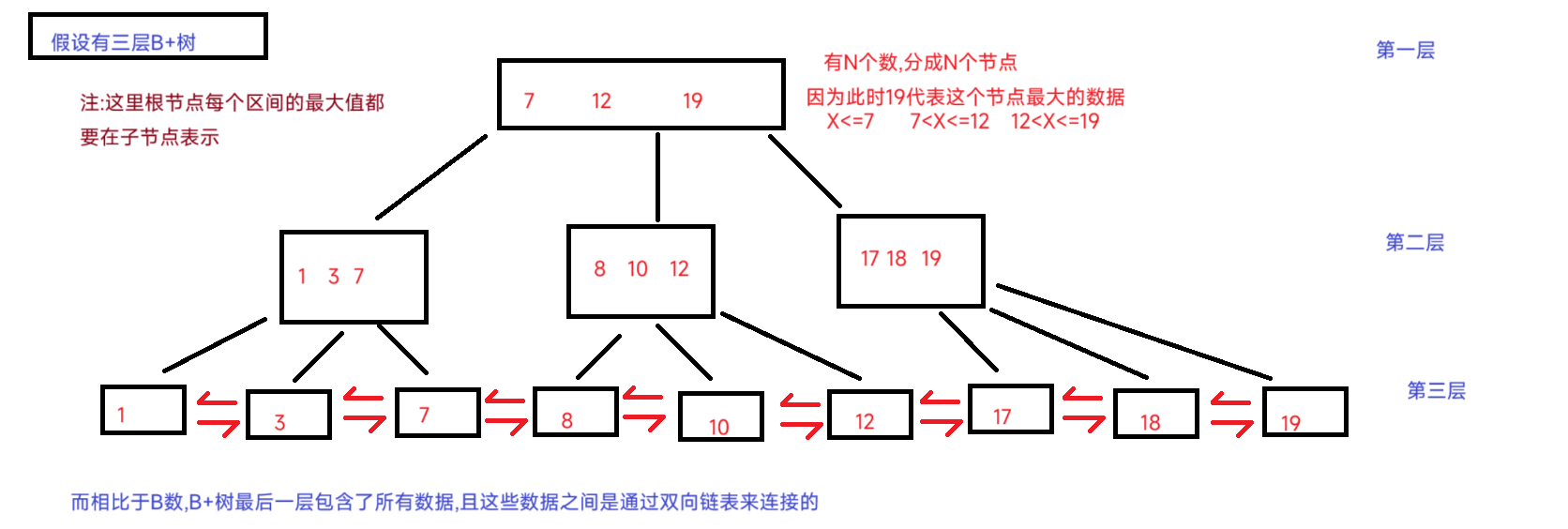
4.特点:
<1>.B+树也是一个N叉数
<2>.每个节点都有N个数据 ,可以分为N(不是N+1)个区间,每个区间的最后一个元素代表当前子树的最大值(也可以规定:第一个元素代表最小值)
<3>.每个子节点 ,也有N个值,且包含该父亲节点 所划分的区间的元素,且该区间最大元素(最小)要在子节点表示
<4>.叶子节点包括所有 的元素,且叶子结点之间用双向链表来表示
5.与B数比较的优势:
<1>.叶子节点是数据全集,包括了所有的数据,且用链表链接,方便进行范围查找
<2>.所有的数据都是存储在叶子节点,也只有叶子节点能存储完整的数据行,就意味着非叶子节点占空间非常小,那么非叶子节点存储的是索引key 或者 下一个节点的引用
<3>.每次查找 就是查到叶子节点才能完成查询 ,相比于B数更稳定,因为你也不知道查的元素在哪里
<4>.高度更低(与红黑树比较)
二.页
1.页:Mysql中的专业术语,就是B+树上的节点
分为两类:
数据页(叶子节点):存储数据行
索引页(非叶子节点):只需要要存储key 或 子节点的位置
2.局部性规则:
当程序使用了某个位置的数据,那么接下来可能会使用这个位置附近的数据
比如:有个学生表student(id int ,name varcahr(20))
当使用了id这列某个数据,那么接下来可能会用到name这列的某个数据
3.页的位置:
一个页有许多数据 ,而数据 是存在硬盘上的,每次数据库从硬盘读取数据都是以页为单位读取的
这个是可以看到的:
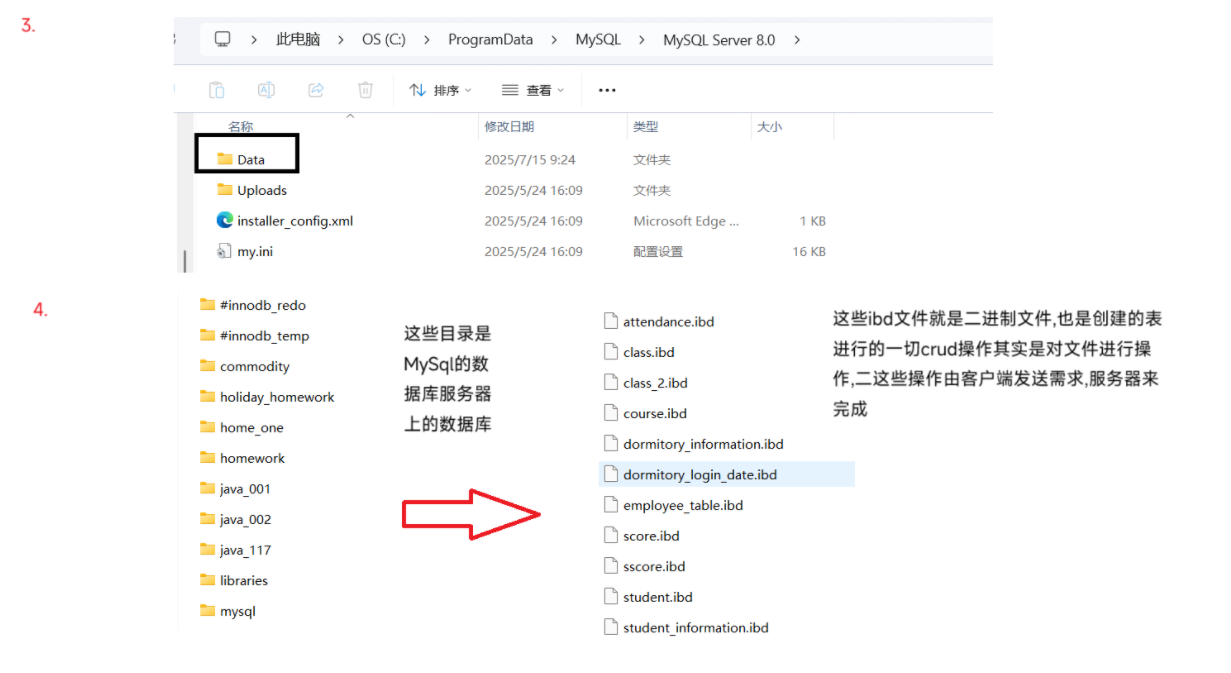
4.关于页更进一步认识:
在 .ibd ⽂件中最重要的结构体就是Page(⻚),⻚是内存与磁盘交互的最⼩单元,
默认⼤⼩为 16KB,每次内存与磁盘的交互⾄少读取⼀⻚
可以通过SQL语句来查看页的结构:
sql
show variables like 'innodb_page_size';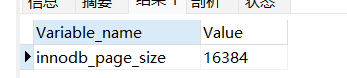
5.页的结构:
<1>页的结构
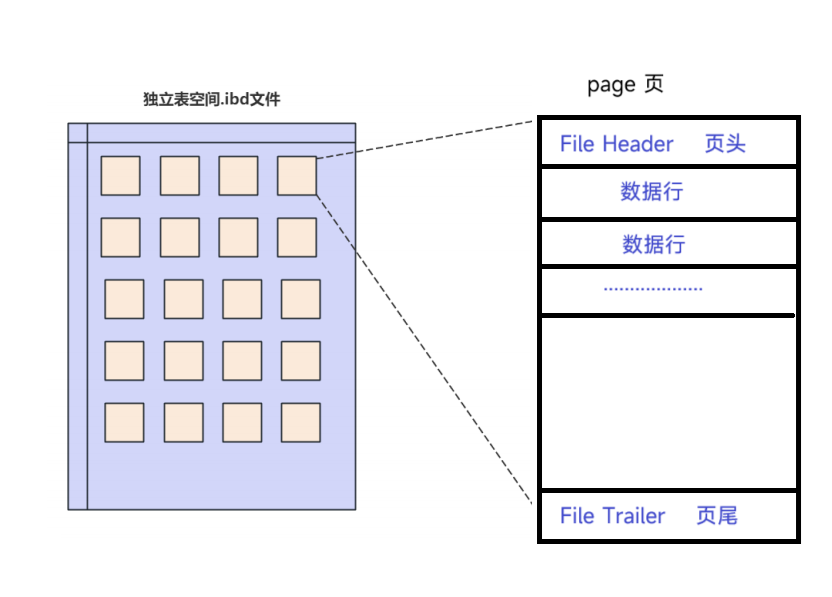
<2>.页头的结构
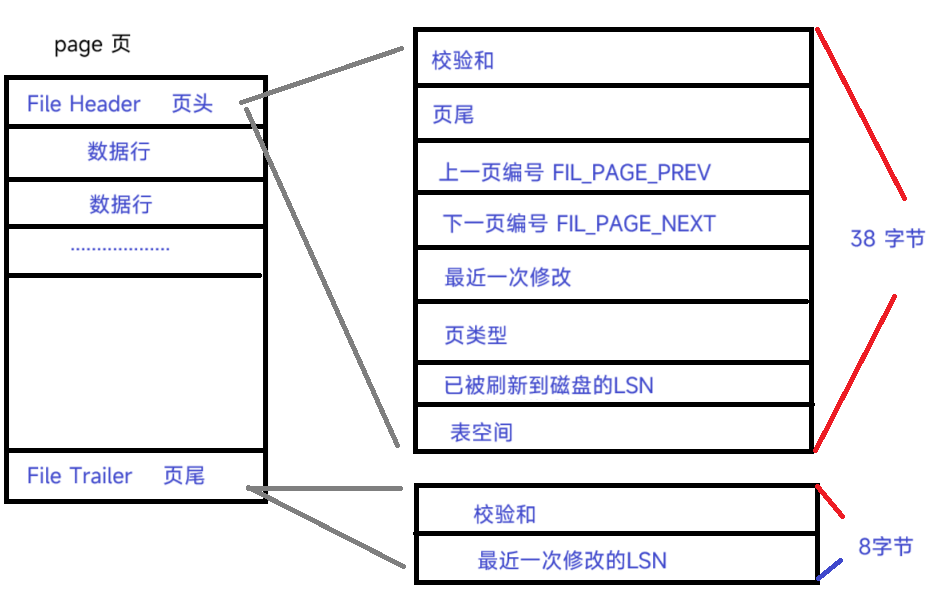
这里的上一页编号 下一页编号 类似于 双向链表中的 prev next, 通过这两个的就可以把页连接
6.页的数据行:
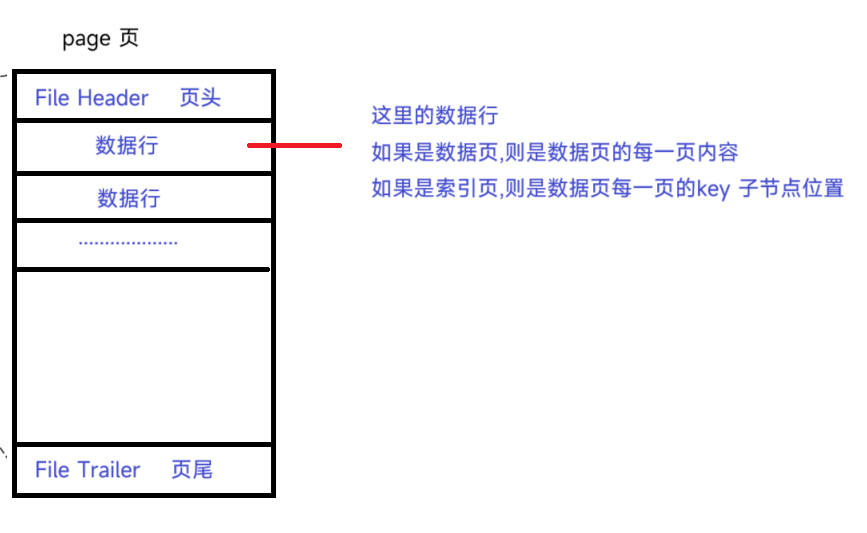 7.页的主体:
7.页的主体:
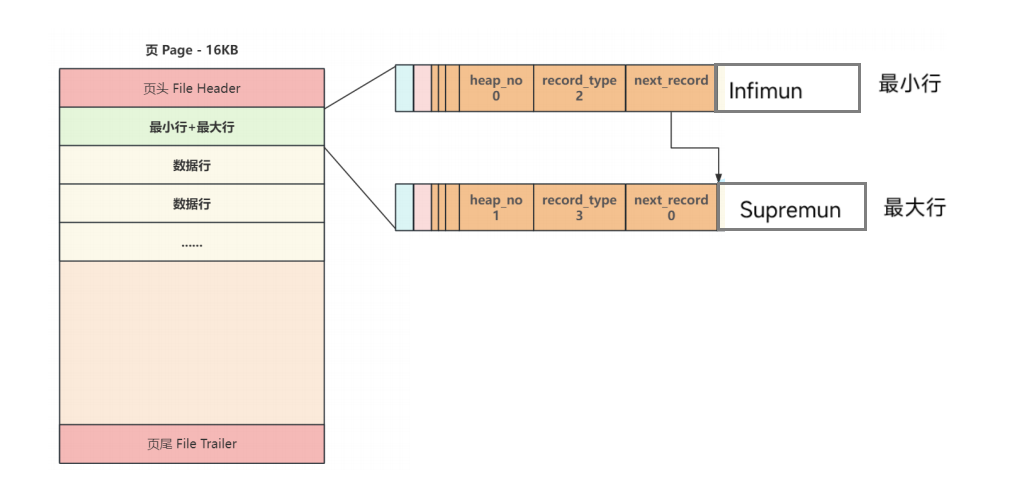
8.页的目录:
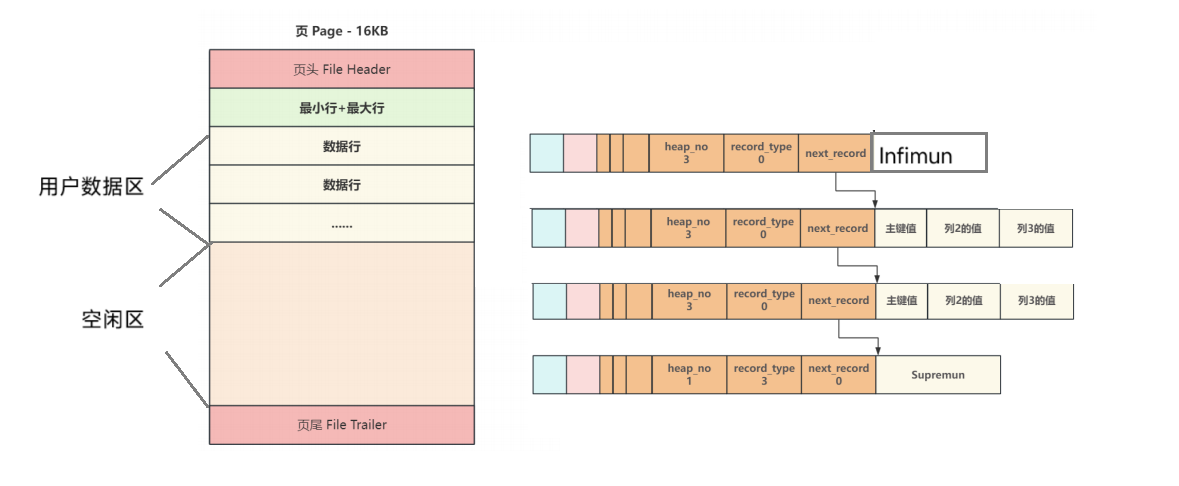
至于页目录和页主体在后续学习后会讲到,这里简单了解即可
9.一个面试题讲解:
3层树高的B+树有多少条记录?
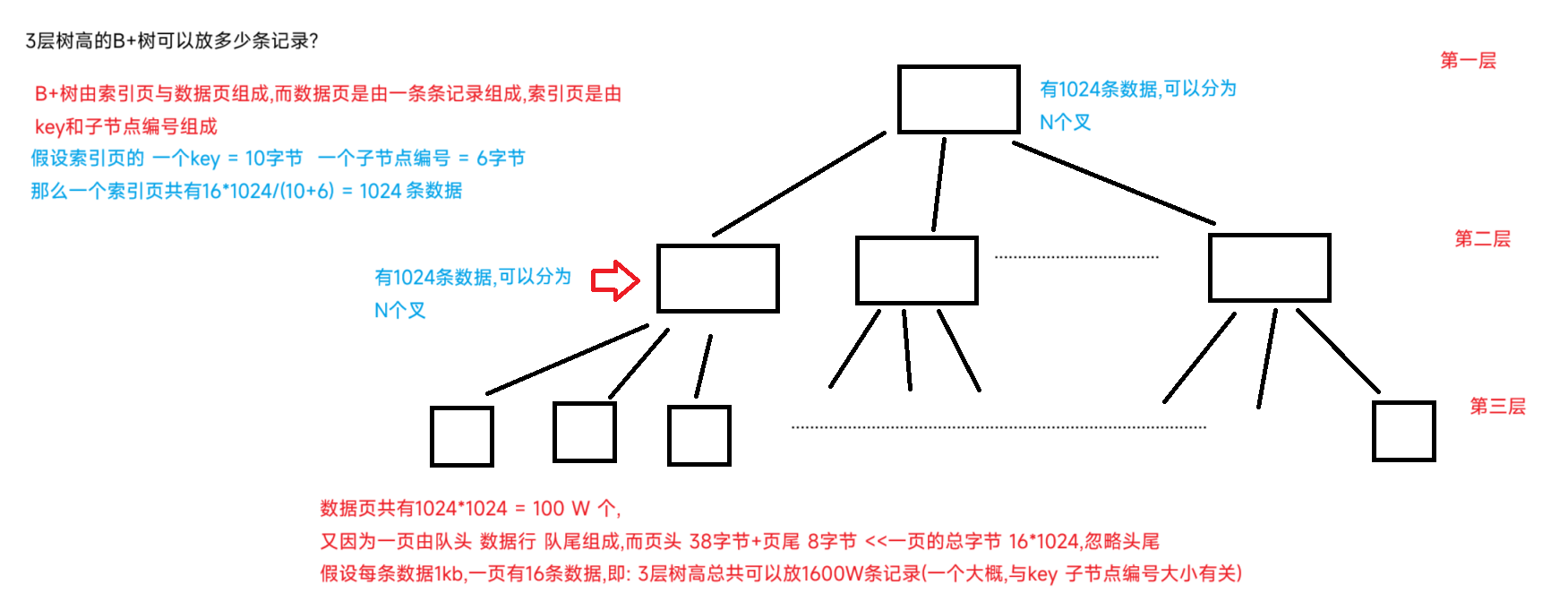
那么当一个表中的行数 超过1600w 时,在尝试插入数据,因为会增加 树高,所以查询开销 会明显增大,此时就要进行分表分库操作了,将大表分成一个个小表放入不同的数据库进行操作
三.索引使用
1.B+树在sql中应用
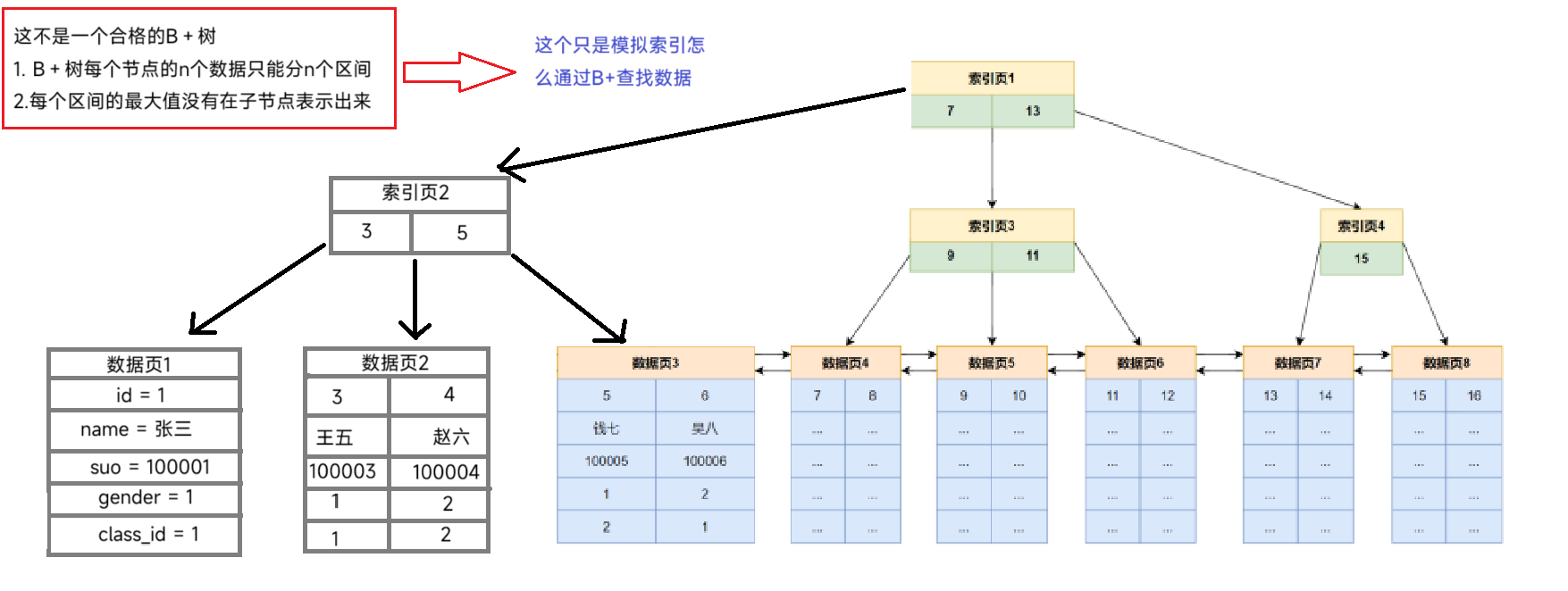
以查找id为5的记录,完整的检索过程如下:
- ⾸先判断B+树的根节点中的索引记录,此时 5 < 7 ,应访问左孩⼦节点,找到索引⻚2
- 在索引⻚2中判断id的⼤⼩,找到与5相等的记录,命中,加载对应的数据⻚
2.索引的分类
<1>.主键索引
(1).给一个表的某一列 定义主键primary key ,这个列的值 会作为索引key存储在索引页中
(2).若没有主键 ,则会自动创建一个"隐藏列"作为主键索引
(3).主键索引就是聚集索引(后面会介绍)
<2>.普通索引
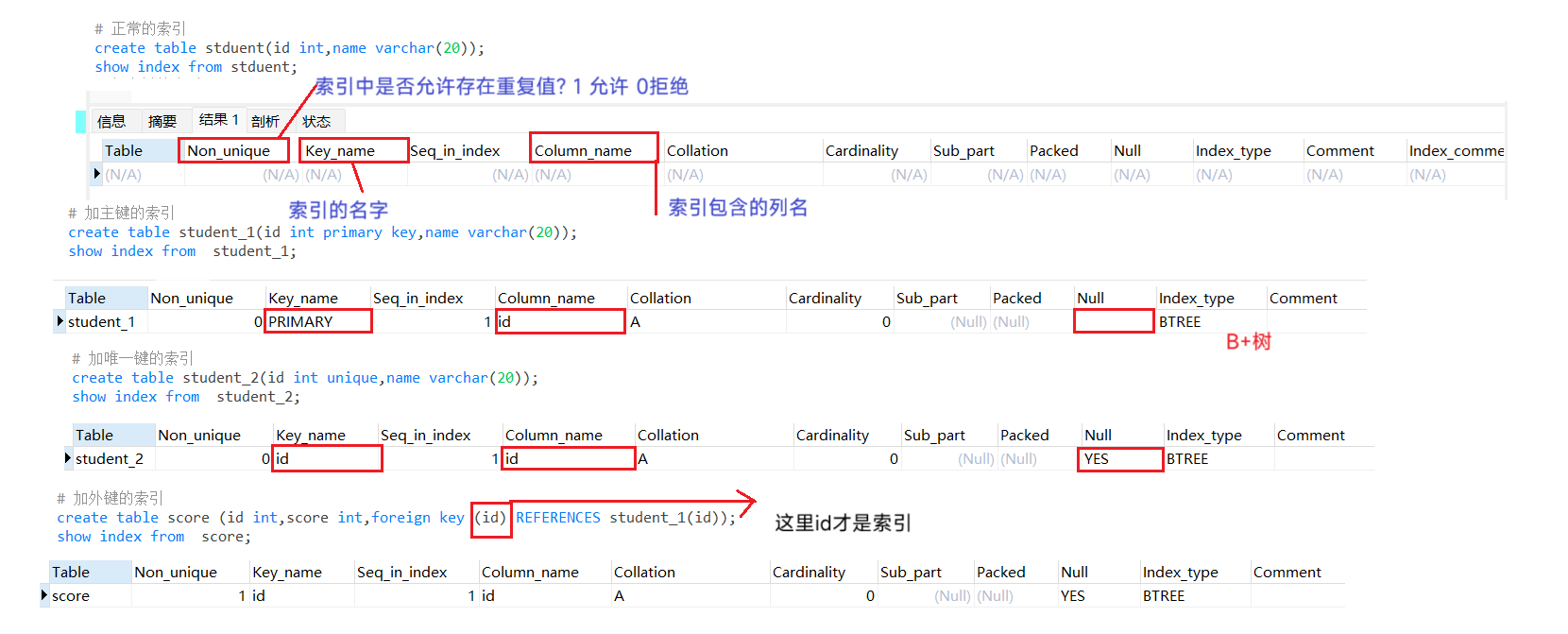
(1).针对普通的列手动创建 索引(允许有重复值)
(2).可能会将多列创建组合索引 ,称为复合索引 或组全索引
<3>.唯一索引
(1).当在⼀个表上定义⼀个唯⼀键 UNQUE 时,⾃动创建唯⼀索引。
(2).与普通索引类似,但区别在于唯⼀索引的列不允许有重复值。
<4>.全文索引
(1)基于⽂本列(CHAR、VARCHAR或TEXT列)上创建
(2).加快对这些列中包含的数据查询和DML操作
(3).⽤于全⽂搜索
<5>.聚集索引(又称聚簇索引)
这个我用图一次讲清楚
<6>.非聚集索引(非聚簇索引)
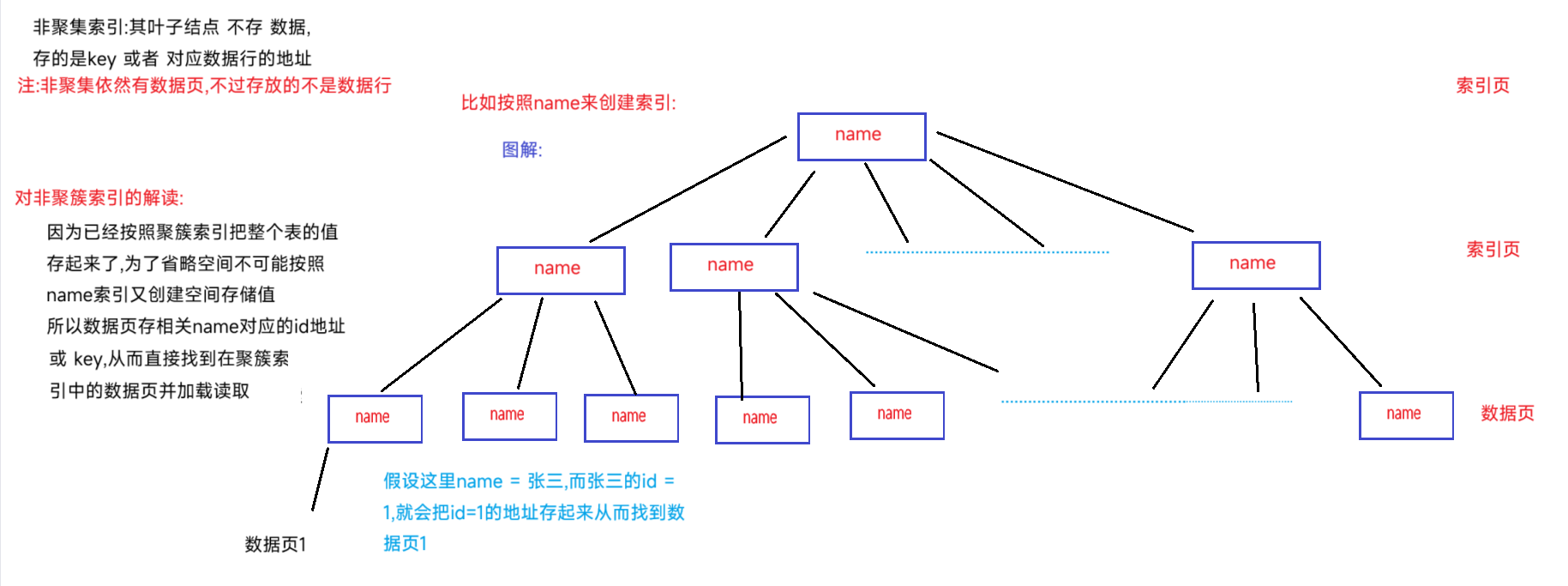
运行逻辑:
针对于name查询时,不是直接查找到数据页(聚簇的数据页,不是这里的数据页),而是先找到对应name的id地址, 再到聚簇索引的B+树图逛一圈找到id对应的数据页(回表操作),得到最中的数据行
<7>. 索引覆盖
当⼀个select语句使⽤了普通索引 且查询列表中的列刚好是创建普通索引时的所有或部分列,这时
就可以直接返回数据,⽽不⽤回表查询,这样的现象称为索引覆盖
<8>.注意事项
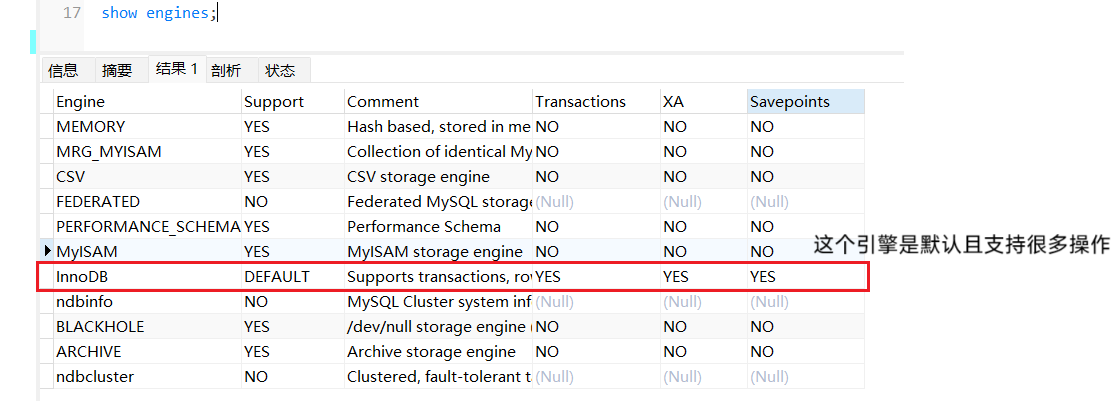
注 :以上所有的索引分类都有前提,必须使用Innodb引擎
可以使用 show engines;查看引擎
3.查看索引
sql
# 方式一(超级详细版)
show keys from 表名;
# 方式二(略微详细版)----->一般用这个
show index from 表名;
# 方式三(正常版本)
desc 表名;4. 索引使用或创建
<1>.自动创建
(1). 当我们为⼀张表加主键约束(Primary key),外键约束(Foreign Key),唯⼀约束(Unique)时,
MySQL会为对应的的列⾃动创建⼀个索引
(2).如果表不指定任何约束 时,MySQL会⾃动为每⼀列⽣成⼀个索引并⽤ ROW_ID 进⾏标识
注:自动为每一列生成的索引,在 innodb引擎中存在 并用ROW_ID标注,是看不到的
<2>. 手动创建
(1).创建主键索引
sql
# 方式⼀,创建表时创建主键
create table t_test_pk (
id bigint primary key auto_increment,
name varchar(20)
);
# 方式⼆,创建表时单独指定主键列
create table t_test_pk1 (
id bigint auto_increment,
name varchar(20),
primary key (id)
);
# 方式三,修改表中的列为主键索引
create table t_test_pk2 (
id bigint,
name varchar(20)
);
alter table t_test_pk2 add primary key (id) ;
alter table t_test_pk2 modify id bigint auto_increment;(2).创建唯一索引
sql
# 方式⼀,创建表时创建唯⼀键
create table t_test_uk (
id bigint primary key auto_increment,
name varchar(20) unique
);
# 方式⼆,创建表时单独指定唯⼀列
create table t_test_uk1 (
id bigint primary key auto_increment,
name varchar(20),
unique (name)
);
# 方式三,修改表中的列为唯⼀索引
create table t_test_uk2 (
id bigint primary key auto_increment,
name varchar(20)
);
alter table t_test_uk2 add unique (name);(3).创建普通索引
sql
# 方式⼀,创建表时指定索引列
create table t_test_index (
id bigint primary key auto_increment,
name varchar(20) unique
sno varchar(10),
index(sno)
);
# 方式⼆,修改表中的列为普通索引
create table t_test_index1 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10)
);
alter table t_test_index1 add index (sno) ;
# 方式三,单独创建索引并指定索引名
create table t_test_index2 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10)
);
create index 要创建的普通索引名字 on t_test_index2(sno);(4).创建复合索引
与正常创建相同,只不过多了逗号
sql
# ⽅式⼀,创建表时指定索引列
create table t_test_index4 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10),
class_id bigint,
index (sno, class_id)
);
# ⽅式⼆,修改表中的列为复合索引
create table t_test_index5 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10),
class_id bigint
);
alter table t_test_index5 add index (sno, class_id);
# ⽅式三,单独创建索引并指定索引名
create table t_test_index6 (
id bigint primary key auto_increment,
name varchar(20),
sno varchar(10),
class_id bigint
);
create index index_name on t_test_index6 (sno, class_id);注:这里只说了常见的索引创建方法,还有好多创建方法,需要的时候查一下
eg:主键的复合索引,即:联合主键的创造方式primary key(列名,列名........)
- 删除索引
<1>.删除主键
sql
# 语法
alter table 表名 drop primary key;
# 示例,删除t_test_index6表中的主键
alter table t_test_index6 drop primary key;
# 若主键设置自增属,先删除自增属性,在删除主键
mysql> alter table t_test_index6 modify id bigint;<2>.其他索引
sql
# 语法
alter table 表名 drop index 索引名
# 示例,删除t_test_index6表中名为index_name的索引
alter table t_test_index6 drop index index_name;在项目中,通常不会删除索引,因为当一个表很大的时候,添加或者删除很浪费时间,而且很占资源
那问题来了:项目都已经上线运行很长时间 了,我突然发现需要增加一个主键 怎么办?
首先可以采用停服更新公告 ,但一般不这样做 ,因为软件都是以盈利为目的,而停服更新的这段时间浪费的都是钱
可以重新建立一张新表 ,并给这张表建立应该加的主键,慢慢把旧表里的数据和服务器的请求倒过来,切记慢慢来,不然造成服务器卡顿
四.总结
1.索引应该创建在**⾼频查询的列上
2.索引需要占⽤额外的存储空间
3.对表进⾏插⼊、更新和删除操作时,同时也会修改**索引,可能会影响性能
4.创建过多或不合理的索引会导致性能下降,需要谨慎选择和规划索引
觉得写的不错的麻烦点个赞再走~~~~