为什么你总跑不过指数?
有没有这种感觉? 明明指数涨了 ,你账户却没赚钱 ,甚至还亏? 但是指数跌了一点点,你账户却被"血洗"了......

这不是错觉,也不是你"不会选股"那么简单,而是你可能低估了市场情绪的作用!
一、上证指数 ≠ 真实市场温度
我们每天都在看指数:上证、深成、创业板...... 但别忘了一个基本事实:
指数只是一个加权平均数,权重股在涨,指数就涨,哪怕90%的股票在跌!
尤其上证指数,权重股大象跳舞(比如银行、有色金属、钢铁、煤炭这4个搅屎棍子),指数看起来很稳,但中小盘个股已经一地鸡毛。
 所以,我们要找到一个比指数更真实反映市场情绪 的工具,来帮我们看懂当下的市场状态。
所以,我们要找到一个比指数更真实反映市场情绪 的工具,来帮我们看懂当下的市场状态。
我最近构建了一个小工具------
指数情绪指标,亲测比直接看指数要稳,原理不复杂通过统计全市场的乖离率(BIAS),直接量化市场情绪冷暖。
二、BIAS情绪指标:怎么看市场热不热、冷不冷?
先复习一下BIAS的定义:
python
BIAS = (当前价格 - 均线价格) / 均线价格 * 100%它描述的是"价格偏离均线的程度"。
我们通常在个股上看BIAS:
- 正BIAS高,短期涨太猛了,可能有回调风险
- 负BIAS高,短期超跌了,可能有反弹机会
但现在我们换个角度:
统计所有A股中,有多少股票的BIAS严重偏离了中位值?
我设定了一个简单的情绪指标模型,每天统计:
- 正BIAS超过5%的股票占比(bias_pos_ratio)
- 负BIAS低于-5%的股票占比(bias_neg_ratio)
- 大于0的BIAS股票占比(bias_up_ratio)
也就是说:
- bias_pos_ratio 高 → 市场过热,赚钱效应强,但容易见顶
- bias_neg_ratio 高 → 市场超跌,情绪恐慌,但可能接近底部
- bias_up_ratio → 反馈市场整体的情绪
三、一图胜千言:BIAS情绪 vs 上证指数
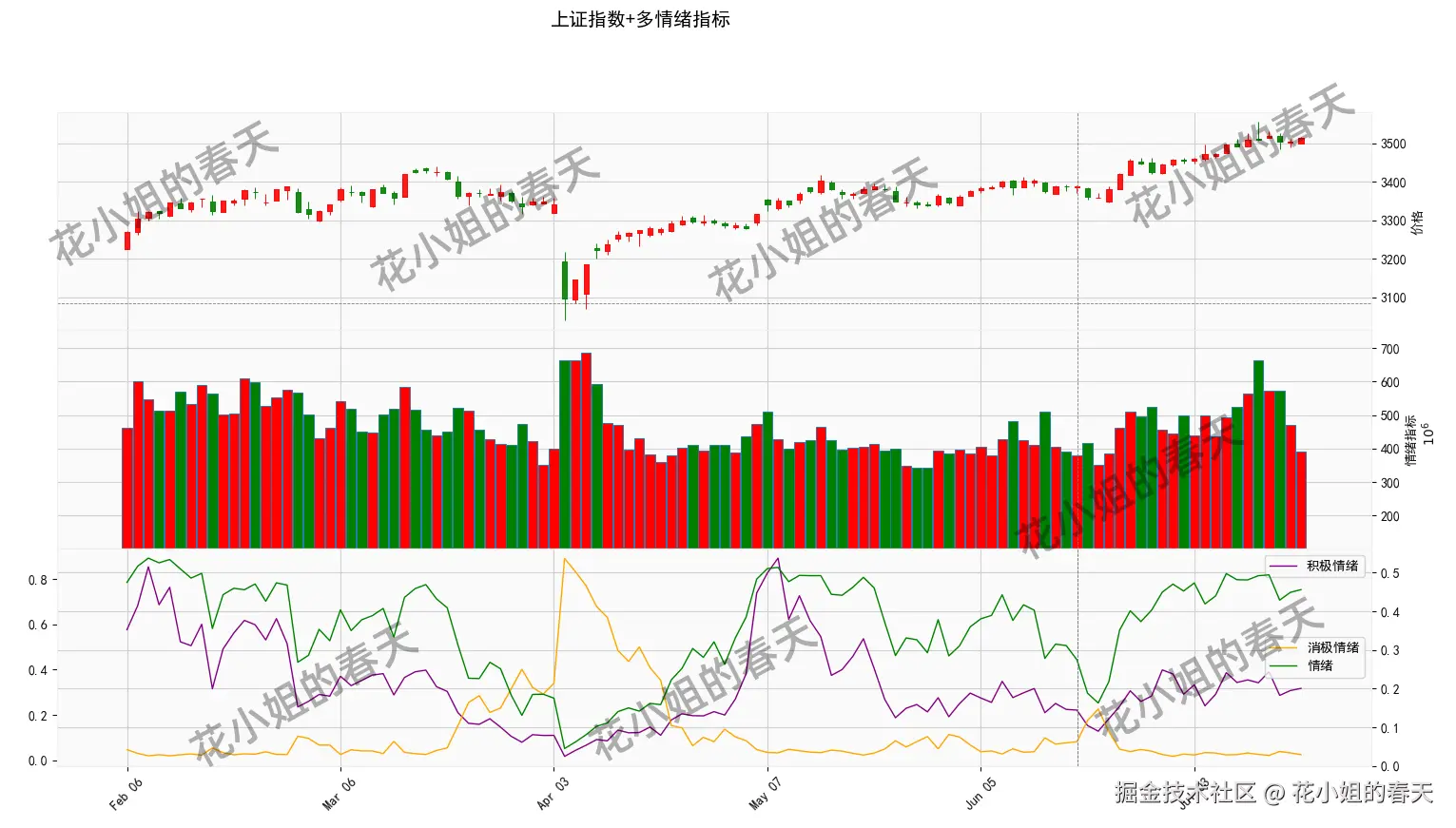
图表解读:
这张图我们绘制了三个情绪指标:
- 积极情绪(紫线) = bias > 5 的股票占比
- 消极情绪(橙线) = bias < -5 的股票占比
- 整体情绪(绿线) = bias > 0 的股票占比(即上涨股票占比)
我们从2025年初至7月中旬的K线与情绪三线图中,可以提炼出几个关键的市场信号和现象:
1. 情绪指标领先于指数拐点,具有预判能力
案例:3月底至4月初
- 指数在3月中下旬仍在阴跌震荡
- 消极情绪(橙线)飙升至高位,说明大量股票超跌,市场极度恐慌
- 此时积极情绪触底、整体情绪极低
- 紧接着4月初出现V型反弹,指数大涨,验证了情绪底信号
解读 :消极情绪过度释放往往是短线底部区域,可作为抄底博弈的参考信号。
2. 指数上涨期间,如果积极情绪不上升,说明赚钱效应不强
案例:2月中旬至3月初
- 指数缓慢上行,但积极情绪持续走低
- 说明虽然权重股稳住了指数,但大部分股票并没有上涨
- 散户普遍感知"涨得不明显",账户未涨,容易出现**"指数涨,我亏钱"**的错觉
解读 :积极情绪不配合指数上行,是结构性行情的典型表现,此时适合控仓、防追高。
3. 指数横盘时,情绪波动剧烈 → 暗藏分歧行情
案例:5月中旬到6月上旬
-
指数看似震荡无方向,但你会看到:
- 积极情绪高位震荡
- 整体情绪高 → 多数股票偏离正向
-
说明指数横盘时,大量个股在涨,市场赚钱效应不错,只是"指数看不出来"
解读:这种情绪指标与指数"背离"时,是超额收益的重要机会,尤其适合高频/轮动策略入场。
4. 趋势末期:指数新高但情绪不再扩张
案例:6月末至7月初
- 指数创新高,但整体情绪和积极情绪都出现背离下滑
- 市场进入"上涨乏力"阶段,赚钱效应开始下降
- 这种情绪-价格背离,常见于上涨后期,是趋势衰竭的前兆
解读:此时应逐步收缩风险敞口,逢高减仓而不是追涨。
结合这张图,可以建立一套"情绪辅助择时"逻辑
| 情绪状态组合 | 市场状态 | 操作建议 |
|---|---|---|
| 消极情绪高 + 指数未企稳 | 恐慌释放期 | 可试探性低吸,控制仓位 |
| 积极情绪持续攀升 + 整体情绪高 | 普涨期 | 把握短期赚钱窗口 |
| 积极情绪下降 + 指数继续冲高 | 情绪背离 | 注意顶部信号,谨慎追涨 |
| 情绪三线同时低位 | 冷静期 | 适合潜伏、观察等待信号 |
当然你也可以根据自己对市场的了解+这3个情绪指标来建立一套独属于自己的择时逻辑
四、如何用Python实现
1. 下载历史行情
首先不管是用AKShare、baoStock还是花姐爱用的xtquant+miniQMT,我们先把所有股票的行情数据下载下来: 这里花姐用的是xtquant+miniQMT实现的
python
def get_hq(code_list,start_date='19900101',period='1d',dividend_type='front',count=-1)->pd.DataFrame:
'''
基于xtquant下载股票的历史行情
'''
xtdata.enable_hello = False
xtdata.download_history_data2(stock_list=code_list, period=period, incrementally=True,start_time=start_date)
history_data = xtdata.get_market_data_ex(['open','high','low','close','volume','amount','preClose'],
code_list, period=period, count=count,
dividend_type=dividend_type,start_time=start_date,fill_data=False)
for code in code_list:
df = history_data[code]
df.index = pd.to_datetime(df.index.astype(str), format='%Y%m%d')
df['date'] = df.index
df.to_feather(os.path.join(target_dir,str(code)+".feather"))2. 计算偏离率
python
def gen_bias():
# 获取所有feather文件
file_list = [f for f in os.listdir(target_dir) if f.endswith('.feather')]
# 用于统计每一天的正/负BIAS个股数
bias_pos_count = {} # 日期 -> count 正乖离超过5%的股票比例
bias_neg_count = {} # 日期 -> count 负乖离超过5%的股票比例
bias_up_count = {} # 日期 -> count 正乖离超过0%的股票比例
total_stock_count = {} # 日期 -> 有数据的股票数量
for file in tqdm(file_list):
try:
df = pd.read_feather(os.path.join(target_dir, file))
df = df.sort_values('date')
# 自己算20日均线
df['ma20'] = df['close'].rolling(20).mean()
# 计算BIAS
df['bias'] = (df['close'] - df['ma20']) / df['ma20'] * 100
# 筛选出有效日期(ma20不为NaN)
df = df.dropna(subset=['bias'])
for i, row in df.iterrows():
date = row['date']
bias = row['bias']
if date not in total_stock_count:
total_stock_count[date] = 0
bias_pos_count[date] = 0
bias_neg_count[date] = 0
bias_up_count[date] = 0
total_stock_count[date] += 1
if bias > 5:
bias_pos_count[date] += 1
elif bias < -5:
bias_neg_count[date] += 1
if bias > 0:
bias_up_count[date] += 1
except Exception as e:
print(f"跳过出错文件 {file},错误信息:{e}")
return bias_pos_count, bias_neg_count, bias_up_count, total_stock_count3. 绘制图形
python
def draw_line(df_index,df_bias):
df_merged = pd.merge(df_bias, df_index, on='date', how='inner')
add_plots = [
mpf.make_addplot(df_merged['bias_pos_ratio'], panel=2, color='purple', width=1.0, label='积极情绪'),
mpf.make_addplot(df_merged['bias_neg_ratio'], panel=2, color='orange', width=1.0, label='消极情绪'),
mpf.make_addplot(df_merged['bias_up_count'], panel=2, color='green', width=1.0, label='情绪'),
]
df_merged['date'] = pd.to_datetime(df_merged['date'])
df_merged.set_index('date', inplace=True)
# 画图
mpf.plot(
df_merged,
type='candle',
style='yahoo',
volume=True,
addplot=add_plots,
panel_ratios=(1, 1), # 上面K线2份高度,下面情绪1份
figratio=(16, 9),
figscale=1.2,
title='上证指数+多情绪指标',
ylabel='价格',
ylabel_lower='情绪指标' # 设置副图y轴标签
)以上就是绘制大盘情绪指标的核心代码,关注花姐公众号领取完整代码