最近想要开发一些AI应用,不想要要使用线上的API调用,收费不说,有时候还不稳定。
就想着本地安装一个大模型运行试一试。
这篇文章手把手带你一起安装本地大模型,以及不同配置电脑应该如何选择大模型。
平台Ollama,模型qwen3:8b
当然本地运行大模型也有一定的局限性,对电脑性能,有一定要求。对于参数很大的模型,运行起来有些困难,不过好在都有少参数版本的模型,可以尝鲜。
一、什么是ollama?
ollama是一个本地运行大模型的工具,上面有基本所有市面上的开源大模型。让你快速下载,并可以本地运行。

下载
官网下载安装就可以了。ollama.com/download
安装好之后,第一次需要点击图标运行。
之后需要授权,授权之后,就启动了。
运行时,状态栏会有一个羊驼图标。(如果没有重启一下电脑)
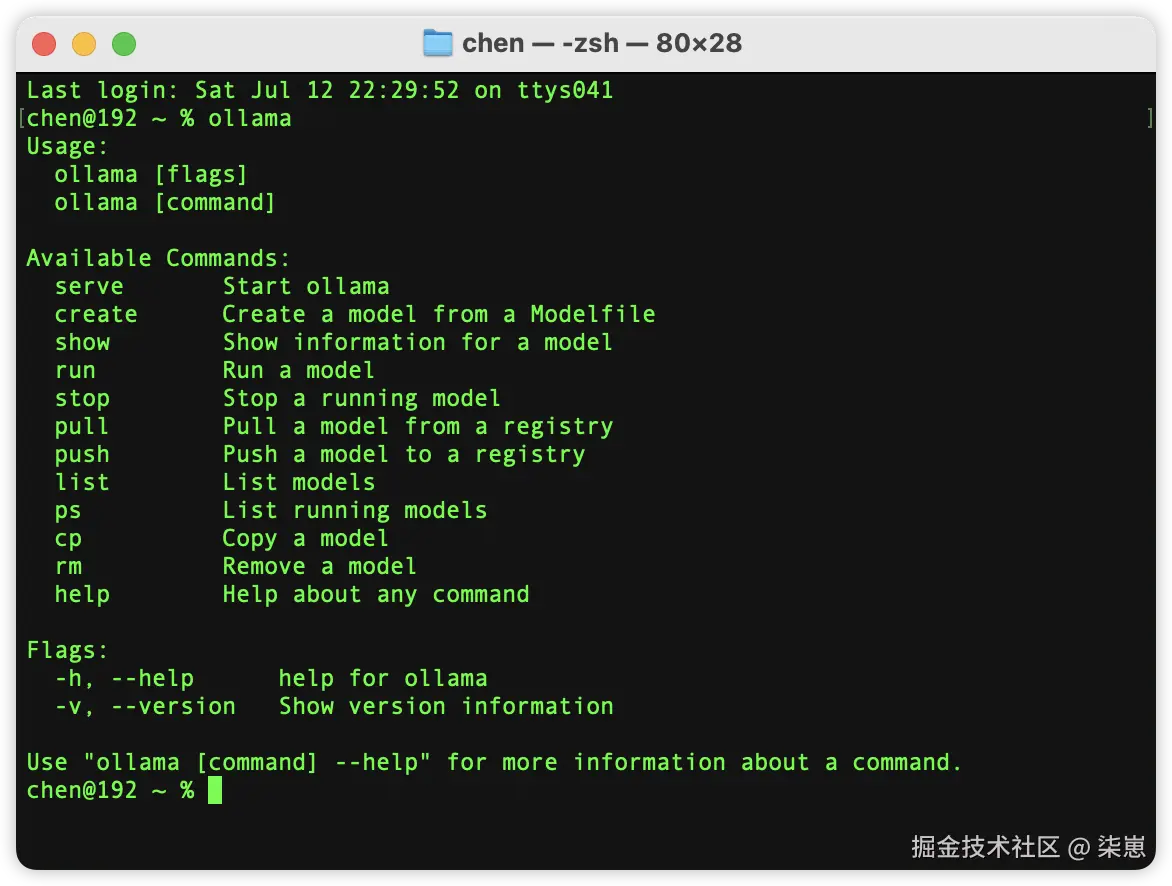
也可以命令行输入ollama。
如果有日志,就安装成功了。
二、模型怎么选择?
有两个点:
-
看模型是否支持你需要的功能,例如工具调用、深度思考、图像生成、向量化等。
-
看你的电脑配置能够运行什么级别的模型。
-
相同的模型,参数大小对性能的要求也不一样,参数越少,要求越低。
本地运行大模型,特别需要看电脑的配置,特别是内存(RAM)大小。
我的是 16GB 内存的 M4 MacBook Pro
选择模型的原则是:
-
8B (80亿) 参数左右 是性能和效果比较平衡的中间点。
-
14B (140亿) 参数 是 16GB 内存可以流畅运行的上限。
-
小于 8B 的模型会非常快,占用资源少。
-
大于 30B 的模型基本不适合在 16GB 内存的设备上本地运行。
你如你不会选,可以把你的电脑配置发给AI,问一下怎么选就可以了。
例如:
bash
我的电脑是mac bookpro M4芯片,14G内存。需要在本地运行ollama模型,需要支持工具调用、深度思考,有哪些模型可选。三、安装大模型
因为我要支持工具调用,选择的是qwen3:8B
如果你想拉取其他版本(例如 30B,对内存要求更高),可以指定为 ollama run qwen3:30b
模型大约有 4.1 GB 左右,运行之后,就会开始下载。
bash
ollama run qwen3:8b
所有可用模型在这:ollama.com/search

四、调用大模型
Ollama 有2种运行方式,命令行和 API 服务。
1. 命令行运行
执行ollama run qwen3:8b

2. 通过api接口调用
通过浏览器访问下面的网址,可以查看当前运行模型的信息:
http://localhost:11434/api/tags
下面是几个api调用的案例
bash
# --- 案例1 ---
# 这个例子会请求 qwen3:8b 模型,返回内容。
curl http://localhost:11434/api/generate -d '{
"model": "qwen3:8b",
"prompt": "你好呀",
"stream": false
}'
# --- 参数控制 ---
# 你可以控制生成文本的更多参数,例如温度 (temperature)、最大 token 数 (max_tokens)、
# top_p等。用于调整模型的生成行为。
curl http://localhost:11434/api/generate -d '{
"model": "qwen3:8b",
"prompt": "你好",
"stream": false,
"options": {
"temperature": 0.7,
"num_predict": 50,
"top_p": 0.9
}
}'3. 通过python代码调用
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
极简的Ollama调用Qwen3:8B模型演示
需要先安装ollama库: pip install ollama
需要先拉取模型: ollama pull qwen3:8b
"""
import ollama
def chat():
"""流式输出演示"""
try:
print("\n=== 流式输出演示 ===")
print("Qwen3:8B 流式回复:")
# 启用流式输出
stream = ollama.chat(
model='qwen3:8b',
messages=[
{
'role': 'user',
'content': '请写一首关于春天的短诗。'
}
],
stream=True
)
# 逐步打印回复
for chunk in stream:
print(chunk['message']['content'], end='', flush=True)
print() # 换行
except Exception as e:
print(f"流式输出错误: {e}")
if __name__ == "__main__":
print("=== Ollama Qwen3:8B 演示 ===")
# 基础对话演示
chat
print("\n演示结束!")五、ollama常用命令
-
ollama run <model_name>:运行一个模型并进入对话模式。如果模型不存在,会自动下载。 -
ollama pull <model_name>:下载指定模型到本地。 -
ollama list或ollama ls:列出本地已下载的所有模型。 -
ollama rm <model_name>:从本地删除指定模型。 -
ollama create <model_name> -f <Modelfile>:通过Modelfile创建或自定义模型。 -
ollama serve:在后台启动 Ollama API 服务(macOS 和 Windows 通常自动运行)。 -
ollama push <model_name> <registry_url>:将本地模型推送到 Ollama 注册表。 -
ollama cp <source_model> <destination_model>:复制一个模型为新的名称。 -
ollama show <model_name> <field>:显示模型的详细信息(如 Modelfile 内容、参数等)。 -
ollama help:查看所有命令及其用法帮助。
参考资料:
-
ollama应该使用哪种本地模型进行工具调用?(www.docker.com/blog/local-...)