分享一下我 5 月从事文旅 AI 助手的一些得与失,并探讨在对话场景下,怎样实现才更为合理。
首先补充一下项目背景:该项目涉及景区、美食、停车场、酒店、天气等信息。要求是:当用户提问时,系统能够基于数据库的内容进行润色后回答,且回答的模板可能是固定的,类似下面这种 
不过,很快就遇到了第一个问题:如何切分数据。
最初的实现思路是基于 Agent + RAG + Dify 的组合来搭建和管理,流程大致如下:
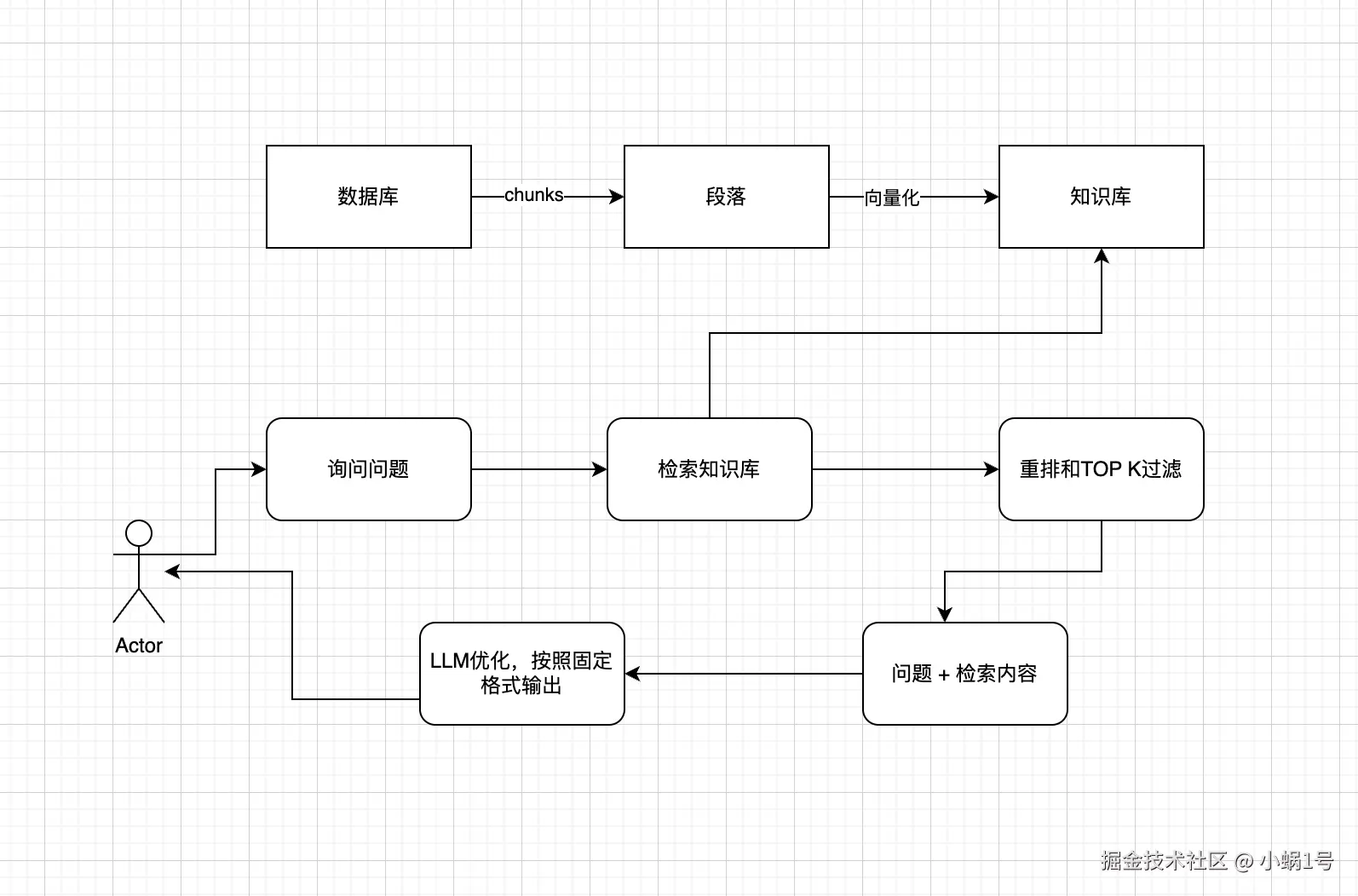
如何切分
数据库的字段大概是下面这种形式:
json
{
"name": "景点名称",
"type": "景点类型",
"address": "景点地址",
"description": "景点描述",
"price": "景点价格",
"time": "景点开放时间",
"ticket": "景点门票",
"phone": "景点联系电话",
"email": "景点联系邮箱",
"website": "景点官网",
"image": "景点图片"
}对于这种结构化数据,如果直接进行切分,效果会比较差。当时查阅了很多文章,也做了一些调研,后来实践发现,将其直接转化为 Markdown 格式是比较合适的方案,然后在段落之间手动添加特殊的分隔符(例如 ---)来标识切分点。
但这还没完,很快发现一个新问题:"景点描述"字段内容过长,超出了向量模型处理的最大长度限制,这带来了很大的麻烦。当时想了两个方案:
- 调高重叠段落(overlap)的字符数。
- 将单条数据拆分成多个文件上传。
但折腾了一番后,这两个方案都没能解决问题。究其原因,RAG 的本质是对段落信息进行检索。
- 由于原始文本太长,切分后的段落非常零散,导致关键信息无法被有效召回。
- 将数据库的每一行拆分成多个 MD 文件上传,但在实践中效果依然不佳,因为检索时系统会返回整个文件的内容,导致 Token 消耗量过大。
所以,这是我的第一个感悟:对于传统的结构化数据,将其转化为 MD 格式用于关键词检索通常已经足够。但如果某些字段(如描述)内容过长,就需要考虑其他实现方式。站在今天的视角来看,我认为最佳做法依然是 RAG,但核心思路有所调整:在向量索引中,不存储完整的"景点介绍"这类长文本,而是只存储其 ID。
这样,检索流程就变成了:先通过 RAG 检索到相关的 ID,再根据 ID 从数据库中查询详细的介绍信息,最后将信息拼接返回。
此外,随着后续 MCP Server(Model Control Plane,可以理解为模型工具调用服务)的推出,许多数据库也可以结合 LLM 直接实现信息检索。
需要注意配置 MCP 以及模型本身是否支持工具调用。
所以,概括一下,对于结构化数据场景,可以从以下两个方面来实现信息检索:
- 基于 RAG(优化为 ID 检索 + 数据库查询)
- 基于 MCP Server(工具调用)
天气
天气查询这部分也值得单独思考。初始版本是基于"固定城市 + 专用天气接口"的方式来实现的,但这是否为最优解呢?我认为不是。
后来到了 6 月,新版的 DeepSeek 推出了模型联网功能,这使得天气查询问题变得简单多了。模型可以直接从百度等网站上实时爬取信息,从而天然地支持了对任意城市的查询。
此外,随着 MCP 生态的完善,许多天气相关的 API 也支持通过 MCP 进行调用,通常只需配置一个 Token 即可轻松实现。
Prompt
Prompt 的编写也值得一提。市面上关于 Prompt 的文章和教程有很多,甚至还催生了"提示词工程师"这样的岗位。但对于一个流程清晰的项目而言,我认为遵循以下两个建议,就足以编写出可用的提示词:
- 利用模型生成初版:基于最新的模型(如 Gemini、ChatGPT),让它根据你的需求生成一份基础提示词。
- 提供范例(Few-shot Learning):LLM 可以通过少量样本来学习回答的格式和范例。如有需要,还可以加入负面样本(例如,不希望看到的回复)或明确的禁止项(例如,禁止回答某些话题)来进一步规范输出。
此外,在调试 Prompt 时我还发现一个问题:提示词写得好是一方面,模型的选择也同样至关重要。模型的输出效果固然依赖于提示词,但选择一个参数更大、版本更新的模型,往往能更大概率地改善最终效果。
最后
以上就是我的一些感悟,总结一下,在当前的 AI 项目实践中:
- 提示词需要精心设计:好的提示词需要不断打磨和完善。
- 模型选择至关重要:尽量选择参数量大、版本新的模型,这往往是提升效果最直接的方法。
- RAG 并非万能:RAG 方案不一定是最优解,可以多考察类似 MCP Server 这样的工具调用(Tool Calling)方案,善用现有生态。