本人 Mac 环境,其它环境可参考
文章目录
- [0. 环境准备](#0. 环境准备)
-
- [0.1 安装 Homebrew(如果还没装)](#0.1 安装 Homebrew(如果还没装))
- [0.2 安装编译工具](#0.2 安装编译工具)
- [0.3 安装 Python(可选)](#0.3 安装 Python(可选))
- [1. llama.cpp的编译与运行](#1. llama.cpp的编译与运行)
-
- [1.1 克隆 llama.cpp](#1.1 克隆 llama.cpp)
- [1.2 构建 llama.cpp](#1.2 构建 llama.cpp)
- [1.3 运行 Demo](#1.3 运行 Demo)
- [1.4 下载另一个模型,开启对话](#1.4 下载另一个模型,开启对话)
0. 环境准备
0.1 安装 Homebrew(如果还没装)
在终端执行:
bash
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"验证:
bash
brew --version0.2 安装编译工具
bash
brew install cmake ninja git
brew install llvm # 最新 clangmacOS 默认 clang 也可以,但 Homebrew llvm 更现代,方便优化。
验证:
bash
clang --version
cmake --version
ninja --version0.3 安装 Python(可选)
Python 用于下载模型或做简单验证:
bash
brew install python
python3 --version1. llama.cpp的编译与运行
1.1 克隆 llama.cpp
在你喜欢的工作目录:
bash
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
1.2 构建 llama.cpp
使用 Ninja 构建:
bash
mkdir build
cd build
cmake .. -GNinja -DCMAKE_BUILD_TYPE=Release
ninja如果成功,你会在 build/bin 看到可执行文件:
bash
ls build/bin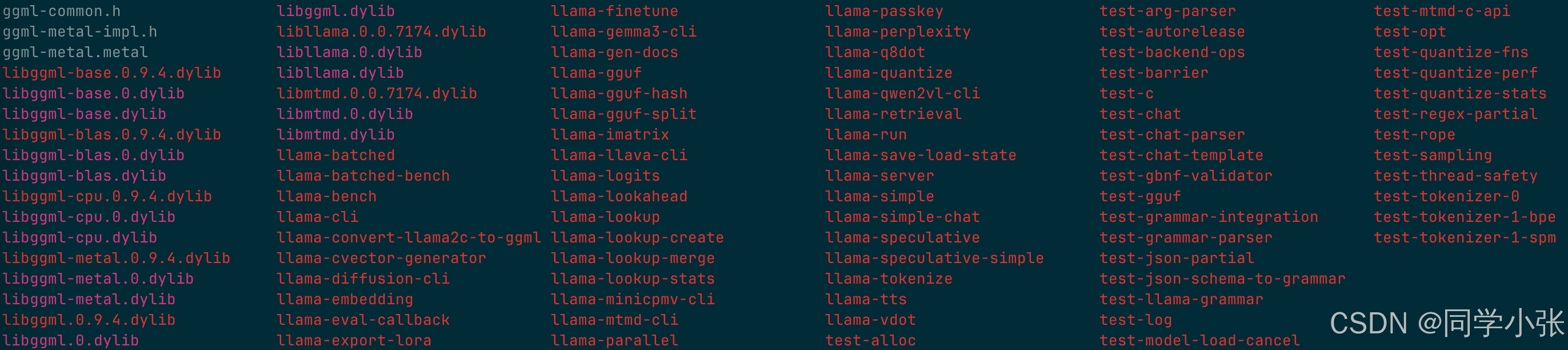
1.3 运行 Demo
回到 build/bin:
bash
cd ../build/bin
./llama-cli -hf ggml-org/gemma-3-1b-it-GGUF不出意外的话,你就可以像下图一样跟模型对话了。
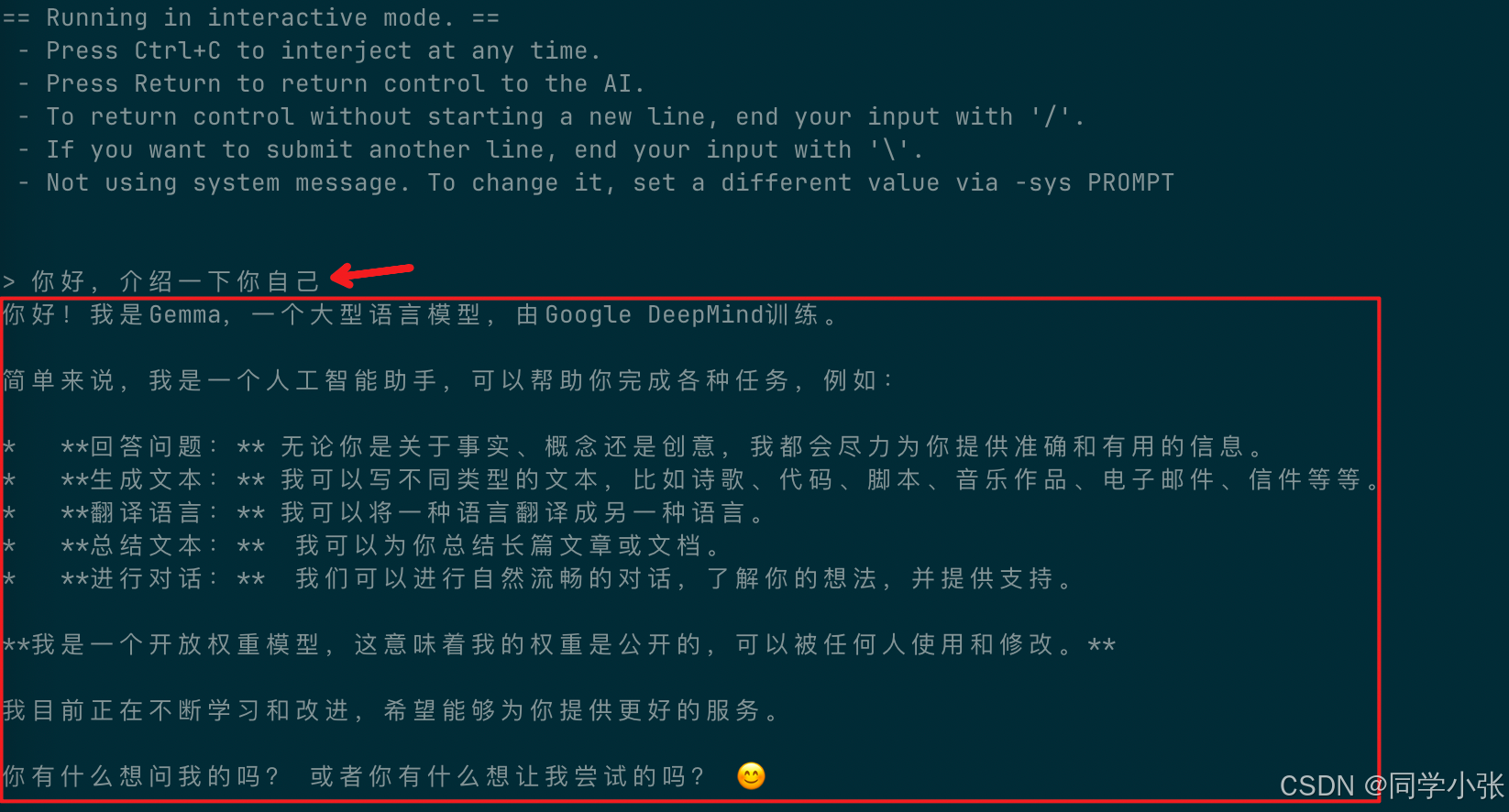
1.4 下载另一个模型,开启对话
(1)先安装 wget,用来下载模型:
bash
brew install wget(2)下载一个小模型:
bash
mkdir models
wget https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct-GGUF/resolve/main/qwen2.5-0.5b-instruct-q4_k_m.gguf\?download\=true -O qwen2.5-0.5b-instruct-q4_k_m.gguf
(3)本地运行
先回到 build/bin 目录:
bash
./llama-cli -m ../../models/qwen2.5-0.5b-instruct-q4_k_m.gguf -p "你好,做一下自我介绍" -n 64ok,运行成功!
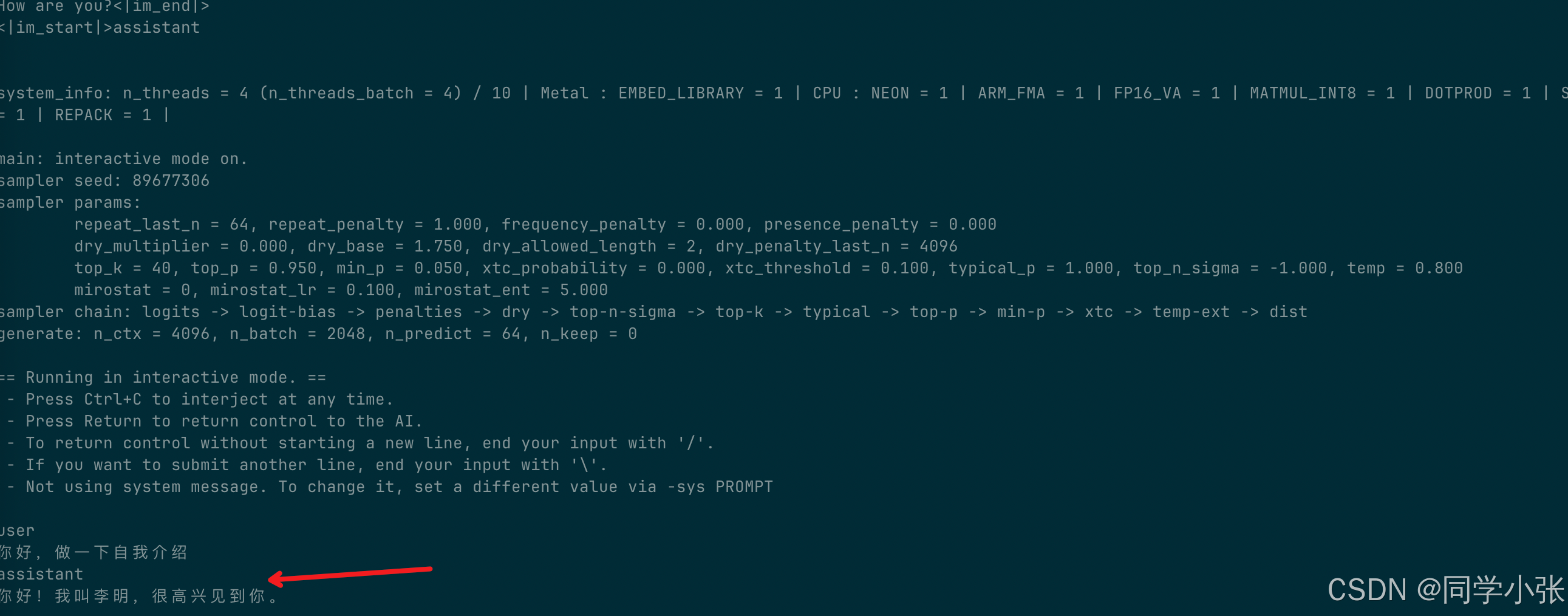
执行命令中的参数含义:
-m 模型路径,指向你下载的模型,一般是 gguf 文件(量化版本)
-p prompt
-n 生成 token 数量
至此,我们完成了 llama.cpp 的本地编译和运行,算是完成了一个 hello world 程序了。
下一篇文章,我们不用命令行运行了,自己写一个main.cpp文件,用代码调用 llama.cpp 来使用大模型!