一、Loki 简介
云原生可观测三大支柱
| 支柱 | 工具 | 用途 |
|---|---|---|
| Metrics | Prometheus | 性能趋势、系统负载 |
| Logs | Loki | 原始事件记录、错误诊断 |
| Traces | Tempo / Jaeger | 分布式链路追踪 |
一、Loki 简介
1.1 Loki 是什么
Loki 是由 Grafana Labs 开发的 日志聚合系统 ,与 Prometheus 架构一致,主打"标签驱动(label-based)日志管理 ",并与 Grafana 紧密集成。
1.2 Loki 的优势:
-
类似 Prometheus 的标签模型。
-
不做全文索引,成本低。
-
与 Promtail、Grafana 紧密协作。
-
支持结构化日志查询与聚合分析。
二、Loki 架构与组件
2.1 架构示例
+-------------+
| Grafana | <---> LogQL 查询
+------+------+
|
+-----v-----+ +-----------------+
| Loki |<--| Object Storage |
+-----+-----+ +-----------------+
^
+--------+--------+
| Promtail / Fluentbit |
+--------------------+2.2 Loki 模块角色
| 组件 | 说明 |
|---|---|
| Promtail | 日志收集 Agent,自动附加 Kubernetes 标签 |
| Loki | 存储、索引日志元数据,只索引 Labels |
| Grafana | 可视化查询,支持 Metrics + Logs 联动 |
| Ruler | 告警规则引擎(LogQL-based alert) |
三、日志采集与标签管理最佳实践
3.1 推荐采集方式
-
Kubernetes 场景推荐使用
PromtailDaemonSet,读取:/var/log/pods/<namespace>_<pod>/*.log
3.2 标签管理策略(重点 🔥)
建议标签选择的三原则:
-
低基数 :如
namespace,app,pod,container。 -
稳定性:避免标签频繁变动,如动态 IP。
-
唯一性避免 :不要将
trace_id作为标签!
配置示例(Promtail):
pipeline_stages:
- docker: {}
- labels:
job: my-app
environment: production四、LogQL 查询实践
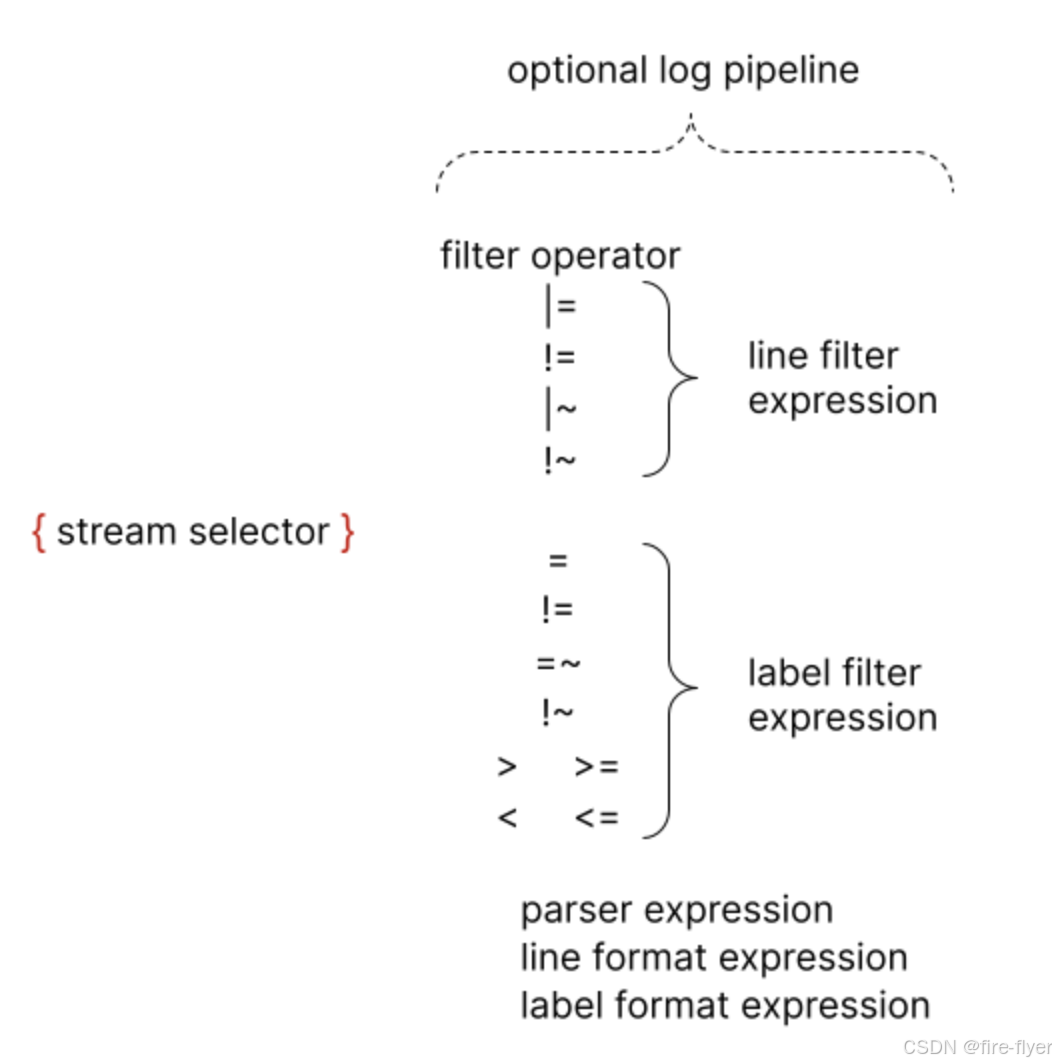
4.1 基础语法
{job="nginx"} |= "error"
-
{...}:标签过滤(必须) -
|= "xxx":精确包含 -
|~ "xxx":正则匹配 -
!=,!~:负向过滤
4.2 聚合语法
count_over_time({job="api"} |= "timeout" [5m])
聚合函数列表:
| 函数 | 说明 |
|---|---|
count_over_time |
日志数量统计 |
rate |
日志行的变化速率(类似 Prometheus) |
avg_over_time |
提取数字后的平均值(结合 line_format) |
sum by (...) |
标签维度聚合 |
4.3 结构化日志解析
{app="svc"} | json | level="ERROR" and request_id!="null"
或者使用正则提取:
{app="svc"} |~ "(?P<status>\\d{3}) (?P<path>/api/[^ ]+)"
五、告警策略与 LogQL
Loki 支持通过 Ruler + Alertmanager 进行日志级别的告警设置。
5.1 规则示例(YAML)
groups:
- name: error-alerts
rules:
- alert: HighErrorRate
expr: |
rate({app="nginx"} |= "error" [5m]) > 10
for: 1m
labels:
severity: critical
annotations:
summary: "High error rate detected"5.2 告警推荐实践
-
告警表达式尽量使用
rate,避免瞬时波动。 -
尽量避免基于高基数字段告警。
六、Grafana 可视化与联动
6.1 日志 → 指标 → Trace 的联动
-
在日志行中提取 trace_id,实现与 tracing系统 的点击跳转。
-
通过
Explore标签页可按 TraceID 聚合多维度观测。
6.2 日志仪表板设计建议
| 面板类型 | 示例内容 |
|---|---|
| 表格面板 | 最近 N 条错误日志 |
| 时间序列图 | error 频次 |
| 直方图 | 各服务日志量分布 |
| 链接跳转 | 指向 Trace 或外部监控平台 |
七、性能优化建议
7.1 采集优化
-
控制
scrape_interval,避免 Promtail 频繁读取。 -
开启
batchsize,batchwait进行日志缓冲。
7.2 存储优化
-
使用 MinIO / S3 存储 Chunk,减少本地磁盘压力。
-
配置
retention自动清理历史日志(如 7 天)。
7.3 查询优化
-
控制查询时间窗口,避免
[1h]级别的大窗口。 -
使用
label_values或metric name缩小搜索空间。
八、示例场景汇总(最佳实践)
| 场景 | 查询语句 |
|---|---|
| 统计每分钟内 error 次数 | rate({app="web"} |
| 查询最近 10 分钟内返回 500 的请求日志 | {status="500"} |
| 提取 json 字段中 level=ERROR | {app="svc"} |
| 按 pod 维度聚合异常日志速率 | sum by(pod) (rate({app="api"} |
| trace_id 跳转 | {job="frontend"} |
九、总结:Loki + LogQL 的可观测性价值
| 能力 | 实现 |
|---|---|
| 低成本日志存储 | 仅索引标签,不做全文索引 |
| 标签驱动的快速查询 | 类似 Prometheus 的语法体验 |
| 与指标/链路天然融合 | 与 Prometheus / skywarking等配合打造统一观测平台 |
| 结构化日志支持好 | 支持 JSON/正则解析字段 |
| 易于扩展与高可用部署 | Helm + Shipper + ObjectStore 架构可弹性部署 |
资料: