CodeBuddy 背景介绍
最近收到了一份求职简历,自称是全球首个产设研一体 AI 全栈高级工程师,名字叫 CodeBuddy IDE,
已经正式入职了几个员工了,写代码都不太得劲,今天让我来面试下这个 CodeBuddy IDE,看看到底怎么回事,
见过太多只会背八股文了,这次我打算现场直接让 CodeBuddy IDE 上代码,毕竟 talk is cheap,show me code
一面 CodeBuddy 流程
第一次见面就被外表惊艳到了,虽然我不是颜值党,但是这满满的科技风,直接让我探索欲拉满,
刚好我最近有一个 idea,手下的员工都比较忙,于是我打算直接问 CodeBuddy IDE 给出解决方案,
这个 idea 是这样的,输入一个人物名,展示和这个人物有关的关系对,并且可视化,
这个 idea 我以前自己有类似的实现,只不过关系对都是现成的,分别来自各种关系数据集、NLP 文本的关系提取、手动整理,特别麻烦
这次我打算让腾讯混元大模型直接联网搜索相关知识库并且提取,并且让面试者 CodeBuddy 生成相关后端接口 API,
于是乎,我直截了当地问了 CodeBuddy:
阅读腾讯混元大模型 api,使用 python3 实现以下功能的后端接口,
传入一个著名人物名,使用大模型提取与该人物有关的主要人物关系对,尽可能全面且真实,
例如输入苏轼,输出格式如下:
苏轼,苏洵,父子
苏轼,苏辙,兄弟
苏轼,王安石,政敌
苏轼,秦观,师生
他二话没说,吭哧吭哧就开干了,

现场阅读了文档,写好了 Flask 后端接口代码,甚至还把 API 相关的密钥创建到了 .env 文件,生成了环境依赖 requirements.txt,这叫一个专业

尽管我现场竖起了大拇指,但是 CodeBuddy 一码无前,一鼓作气把说明文档 ReadMe.md 和后端测试脚本 test-api.py 也写完了,而且格式规范,内容翔实,这就是高级 AI 全栈工程师吗
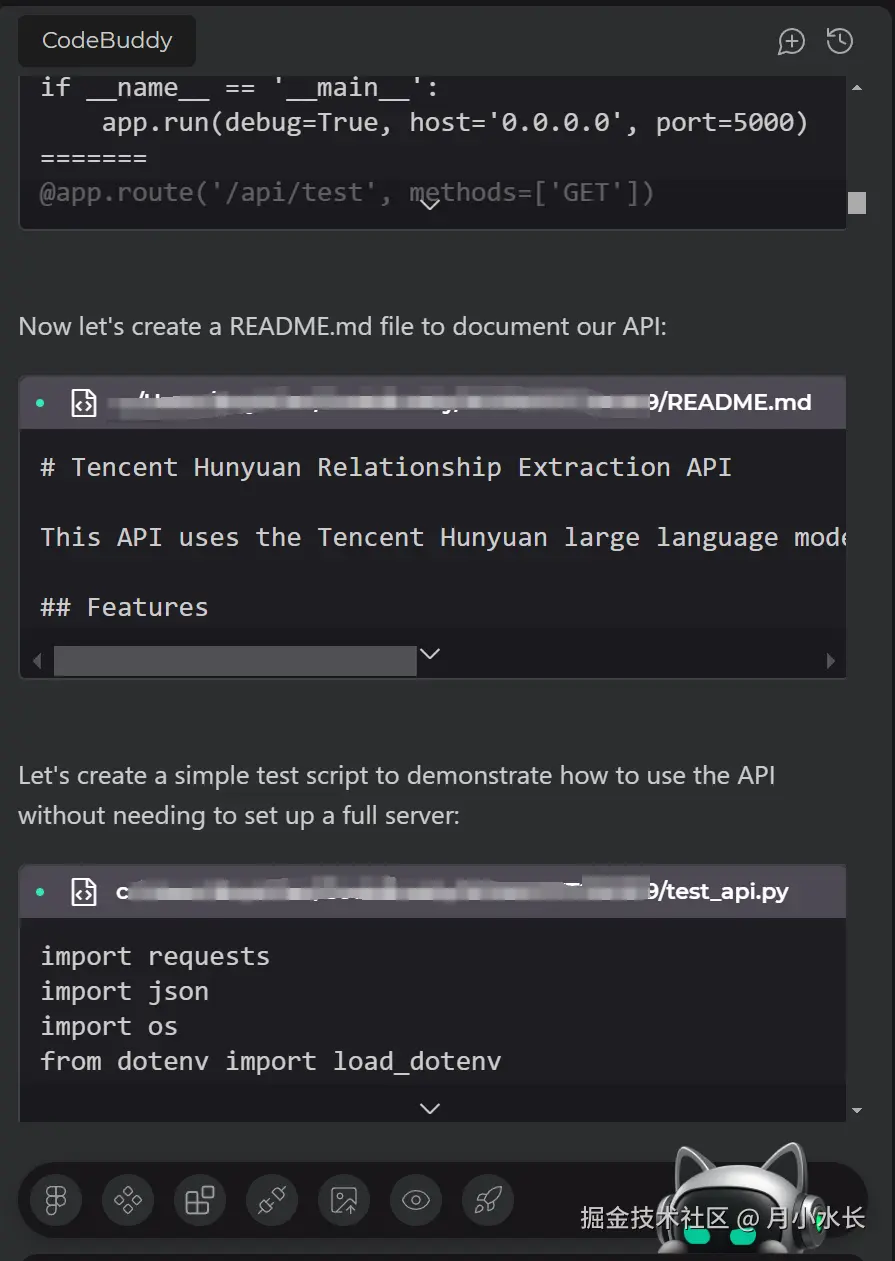
整个过程行云流水,看他信手拈来的样子,我有点不相信他是这个行业的新人,本来我先只让他写完后端的,还没等我浏览完 flask api 接口代码,他就把前端的代码就写完了,这要是招进来肯定是忠诚的员工,
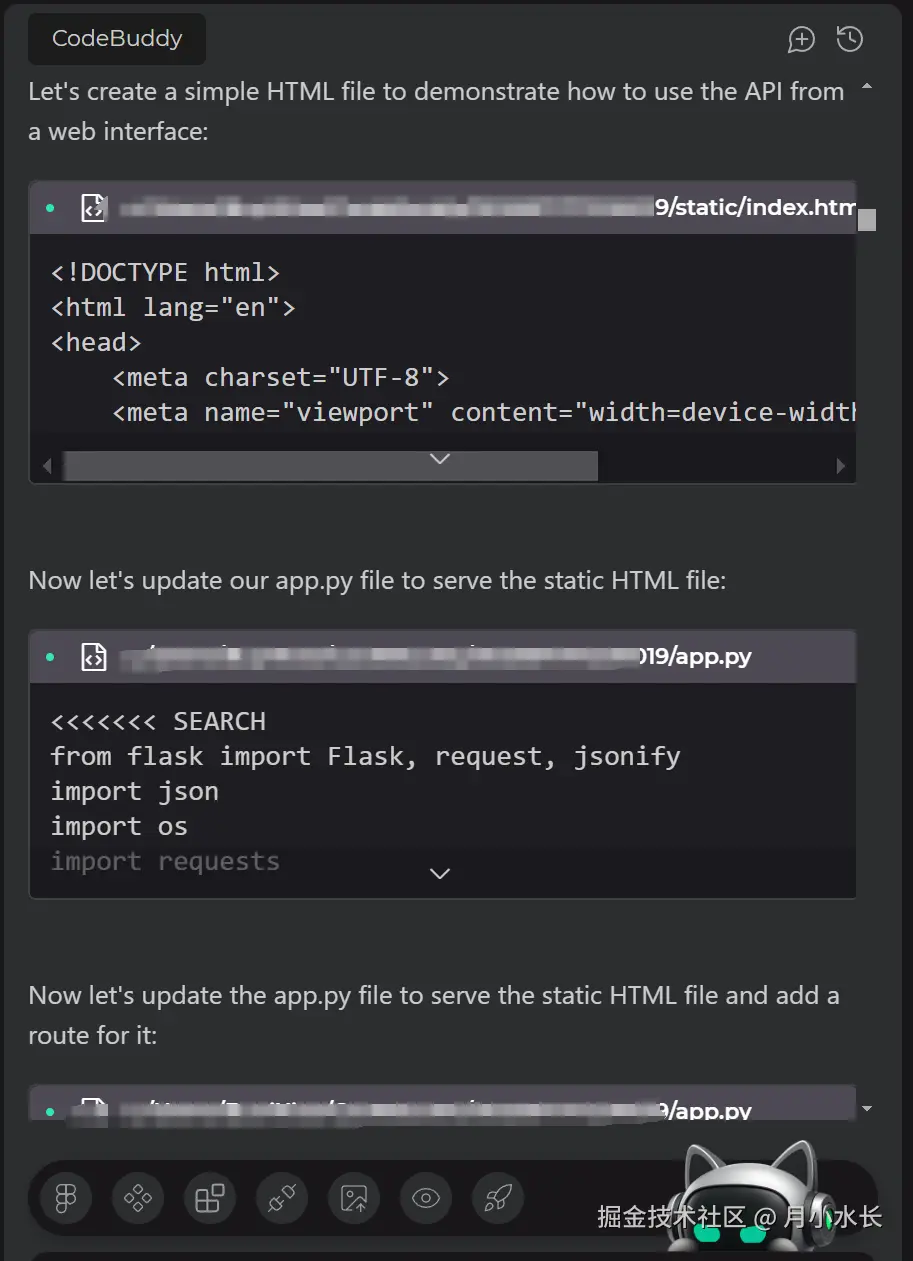
CodeBuddy 志在千里,继续写完了容器镜像 Dockerfile、多容器服务管理 docker-compose.yml,甚至写完了后端启动脚本文件 start_server.sh 和 bat,好家伙,这是把运维的活也全干了,
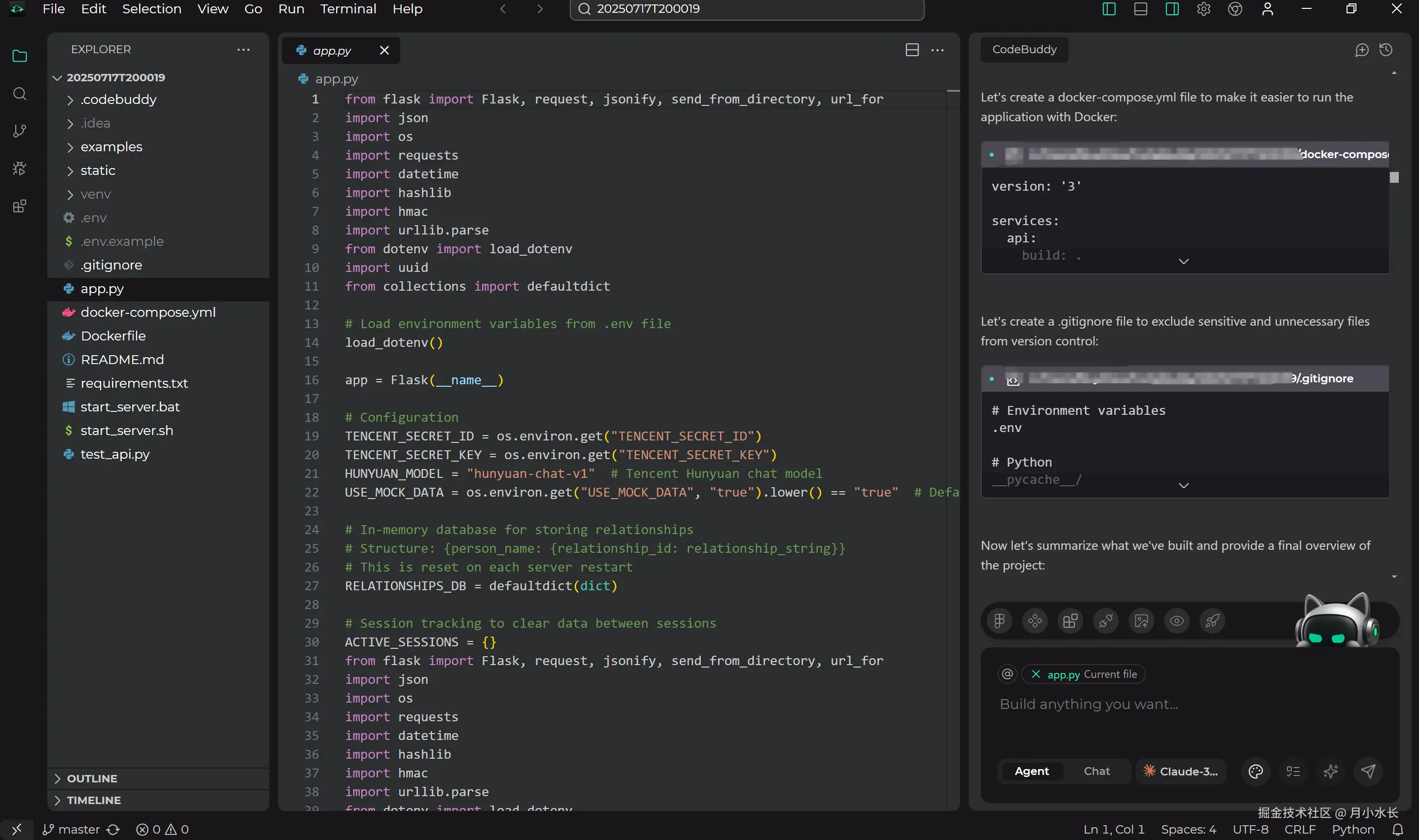
写完这些,CodeBuddy 就完整交出了我这个面试问题的答案,已经大大超出预期了,我当时心里暗想:如果等下测试前后端没问题能跑起来,就直接现场给他下 Offer 了,于是我开始了测试,
由于需要接入混元大模型,我先去下去混元的官网申请了 api key
由于他给出的代码是通过腾讯云 SDK 接入,而不是 OpenAI SDK 接入,为了考虑整个腾讯云账号的安全,我创建了子账号,只授予他访问混元 API 的权限,可在下面网站配置操作,
配置好之后,前后端确实是顺序运行起来了,但是提取关系对的报了错误,于是我继续准问这个错误
CodeBuddy 志不稍馁,埋头排查起了问题,并改进了错误,
改进之后,整个项目逻辑就完整跑了起来,网页打开 http://127.0.0.1:5000,可以很丝滑地生成关系对,
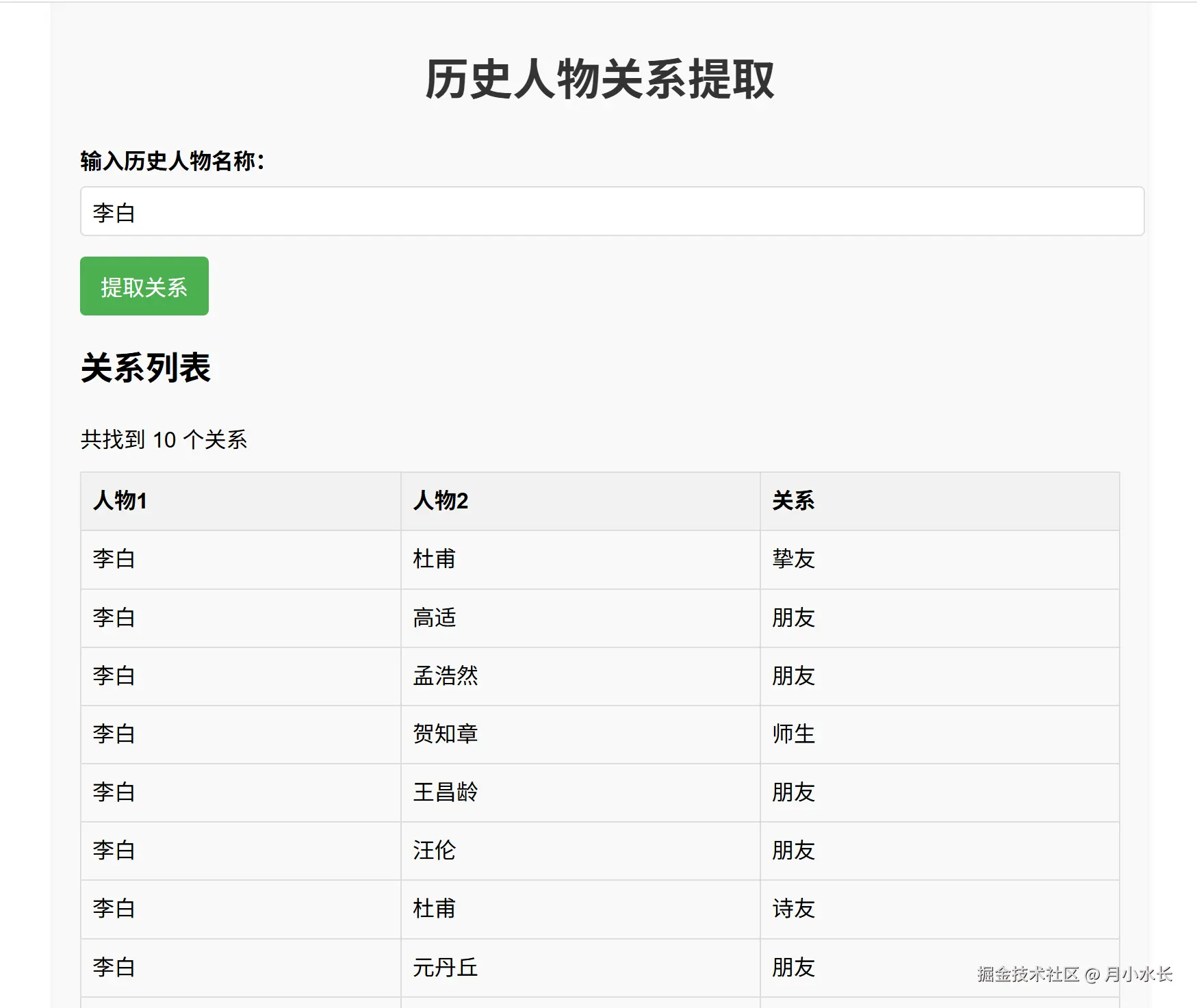
PS:虽然生成的关系对比较少,但是这些可以通过让他慢慢微调 Prompt,或者更换模型名或者参数,今天面试的主要是跑通流程。
二面 CodeBuddy 流程
本来都想直接下 Offer 了,但是看他写码意犹未尽的感觉,
我决定临时加面,二面试题如下:
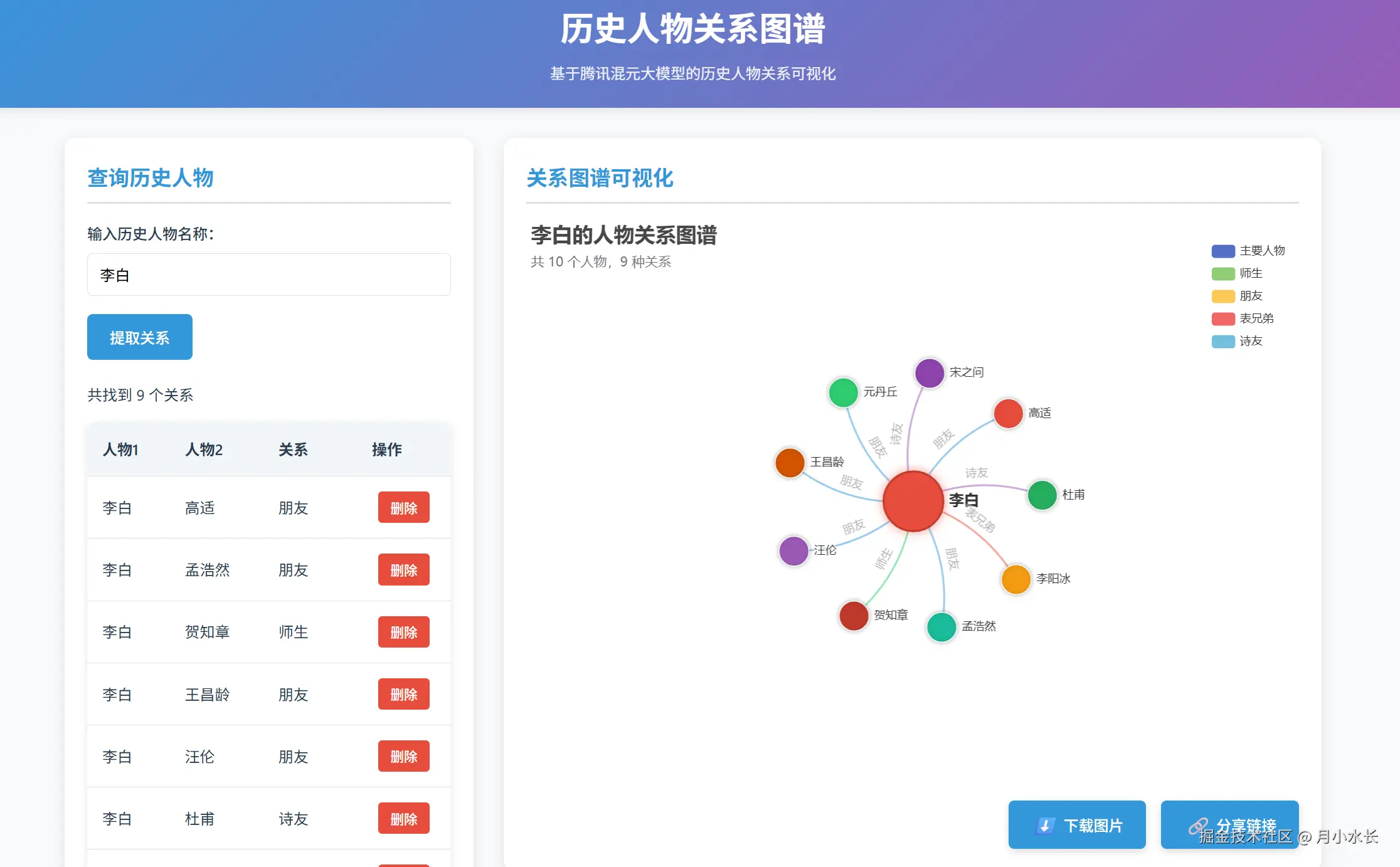
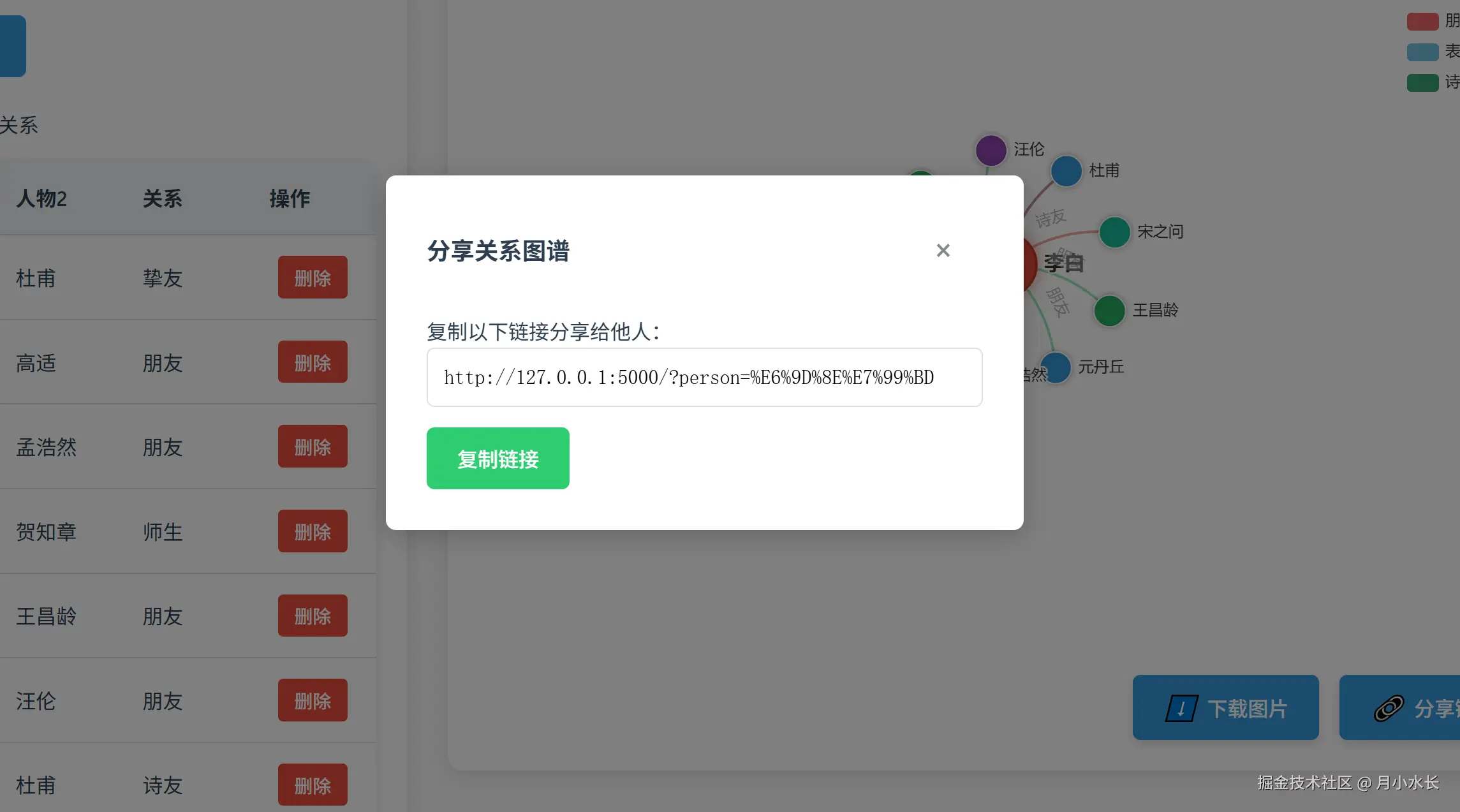
在现有代码基础上实现人物可视化,要求图表美观大气,生成的图表可以下载导出或者分享链接给他人。
做的好,在现有代码的基础上,提供在生成的关系列表上添加新增、删除功能,然后使用 echarts 生成 Graph 关系图,节点表示人物,边表示关系,
图表追求美观,参数设置合理,整体风格水准向设计师看齐,
生成的图表可以下载导出或者分享链接给他人。
CodeBuddy 也是一如既往拿到题目就是干,没有一点点犹豫,仿佛提前知道题目一样,
经过后端逻辑、前端样式多轮调试测试,最终跑起来效果如下:
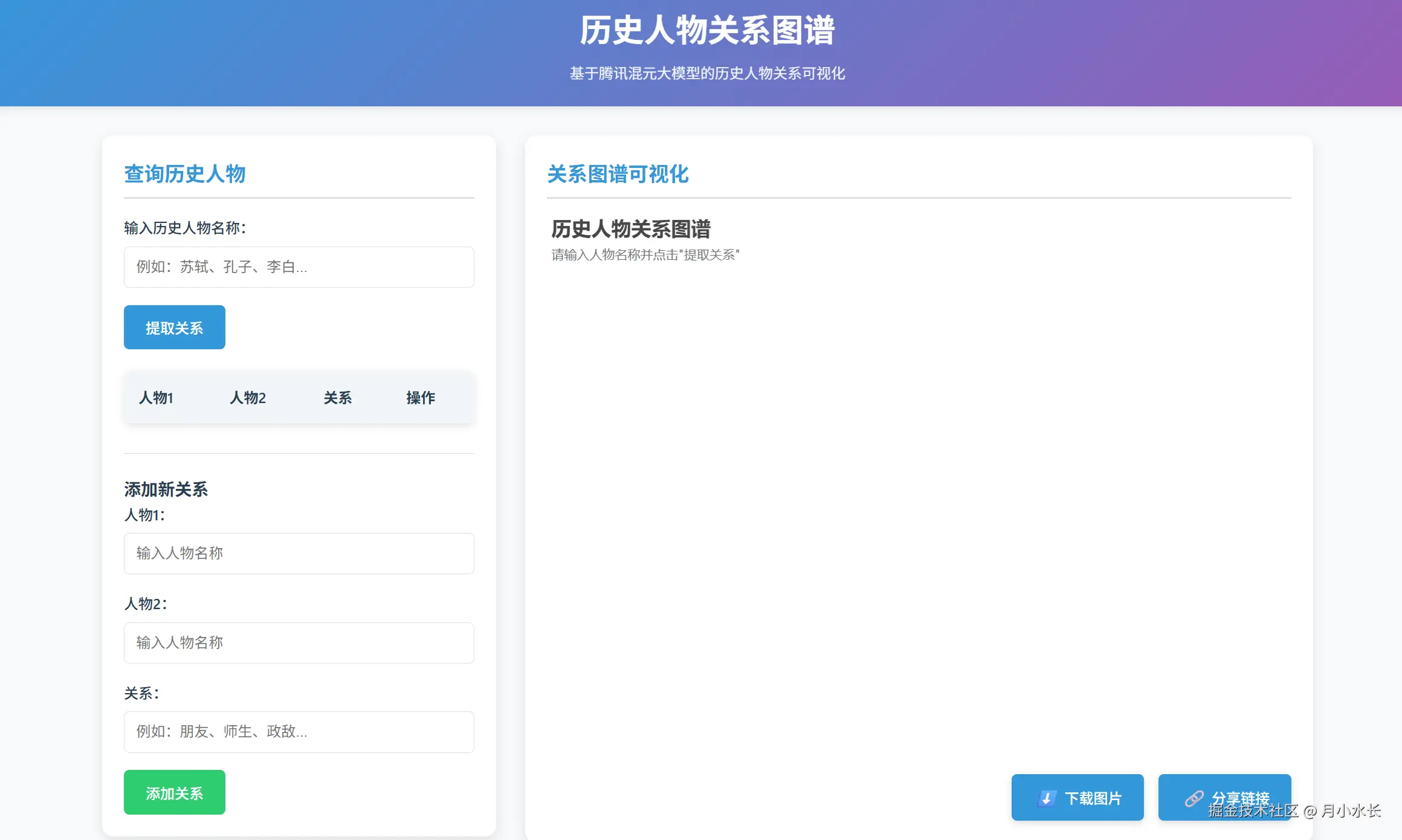
页面美观大气,两栏式布局居然还自己做了移动端适配,功能测试也基本没问题,
有一些 bug 比如点击了删除按钮图表不会刷新,每次网页刷新会保留老数据等等
但是每次我测试出 bug 后,详细给 CodeBuddy 介绍问题特征,他都能很快理解症状并且解决问题。
面试结果
候选人能力全面,可以独挡多面,聪明又质朴,而且皮实坑压能力高,可以给个人人生无限公司带来很高的 ROI,当场就下了 Offer。
面试心得总结
面试题要简明扼要
给大模型的指令一定要开门见山,去除废话,提高信息量,同时确保给足必需前提条件等信息,保证输出不会偏颇。
手动使用 Git 管理仓库
考虑到软件工程的复杂性,和大模型输出的不确定性,最好使用 git 管理仓库,每一次生成新的功能并且确认无误后,使用 git commit 固化存储此版本号,方便回退或者溯源。
理解 CodeBuddy 具体每一个在干什么
知己知彼,方能百战不殆,如果明白 CodeBuddy 每一步在干什么,就能很快调整下一轮对话的策略,如果偶然生成代码错误也能使用精确话术让 CodeBuddy 改正。
不要完全依赖大模型
有时候一个版本号不对引出的问题,大模型能弯弯绕绕给出多种方案,但测试起来都没解决问题,反而一去 stackoverflow 一搜,立马就有答案。
至此我忽有感悟,大模型会淘汰程序员甚嚣尘上,
我觉得,大模型肯定不会淘汰所有程序员,
但是,大模型会淘汰以下两类程序员,
第一,不会用 AI 辅助编程的程序员
以及
第二,只会用 AI 辅助编程的程序员