基本概念
- 支持事务:4.2版本增加了分布式事务,增加对分片集群上多文档事务的支持
和传统数据库的对比
| 对比项 | mongo | 数据库 |
|---|---|---|
| table | collection | 表 |
| row | document | 行 |
| column | field | 字段 |
非规范化模型(嵌入式文档)
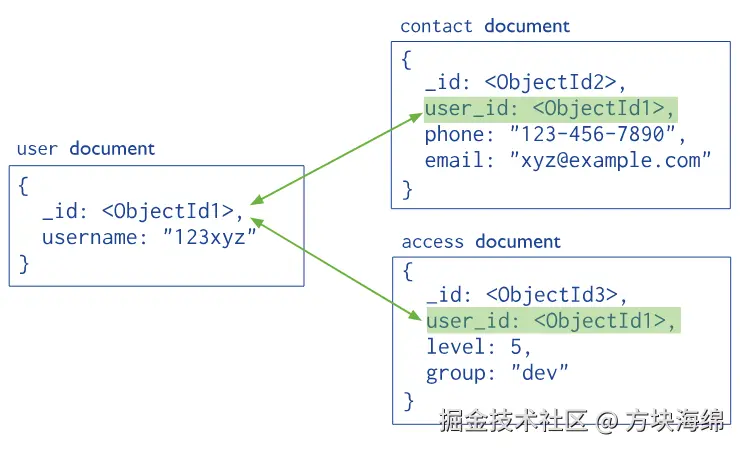

常见使用
capped collection(固定集合):
固定大小,先进先出
支持创建索引,但不支持在创建后更改索引。
capped collection的优点
1.支持高插入吞吐量
2.存储日志信息很有用,按顺序保存
capped collection的缺点
1.不支持分片
2.没有TTL索引
使用场景:
- 日志
- 实时数据缓存:限制存储的旧数据
- 时间序列数据:保存最近的样本
- 事件流
使用的操作实例
虽然遍历数据的查询是相对常见的,但是 MongoDB 认为查询单个数据记录远比遍历数据更加常见,由于 B 树的非叶结点也可以存储数据,所以查询一条数据所需要的平均随机 IO 次数会比 B+ 树少,使用 B 树的 MongoDB 在类似场景中的查询速度就会比 MySQL 快。这里并不是说 MongoDB 并不能对数据进行遍历,我们在 MongoDB 中也可以使用范围来查询一批满足对应条件的记录,只是需要的时间会比 MySQL 长一些。
sql
SELECT * FROM comments WHERE created_at > '2019-01-01'很多人看到遍历数据的查询想到的可能都是如上所示的范围查询,然而在关系型数据库中更常见的其实是如下所示的 SQL ------ 查询外键或者某字段等于某一个值的全部记录:
sql
SELECT * FROM comments WHERE post_id = 1上述查询其实并不是范围查询,它没有使用 >、< 等表达式,但是它却会在 comments 表中查询一系列的记录,如果 comments 表上有索引 post_id,那么这个查询可能就会在索引中遍历相应索引,找到满足条件的 comment,这种查询也会受益于 MySQL B+ 树相互连接的叶节点,因为它能减少磁盘的随机 IO 次数。
MongoDB 作为非关系型的数据库,它从集合的设计上就使用了完全不同的方法,如果我们仍然使用传统的关系型数据库的表设计思路来思考 MongoDB 中集合的设计,写出类似如上所示的查询会带来相对比较差的性能:
css
db.comments.find( { post_id: 1 } )因为 B 树的所有节点都能存储数据,各个连续的节点之间没有很好的办法通过指针相连,所以上述查询在 B 树中性能会比 B+ 树差很多,但是这并不是一个 MongoDB 中推荐的设计方法,更合适的做法其实是使用嵌入文档,将 post 和属于它的所有 comments 都存储到一起:
json
{
"_id": "...",
"title": "为什么 MongoDB 使用 B 树",
"author": "draven",
"comments": [
{
"_id": "...",
"content": "你这写的不行"
},
{
"_id": "...",
"content": "一楼说的对"
}
]
}使用上述方式对数据进行存储时就不会遇到 db.comments.find( { post_id: 1 } ) 这样的查询了,我们只需要将 post 取出来就会获得相关的全部评论,这种区别于传统关系型数据库的设计方式是需要所有使用 MongoDB 的开发者重新思考的,这也是很多人使用 MongoDB 后却发现性能不如 MySQL 的最大原因 ------ 使用的姿势不对。
相关 api
aggregate替代 mapreduce
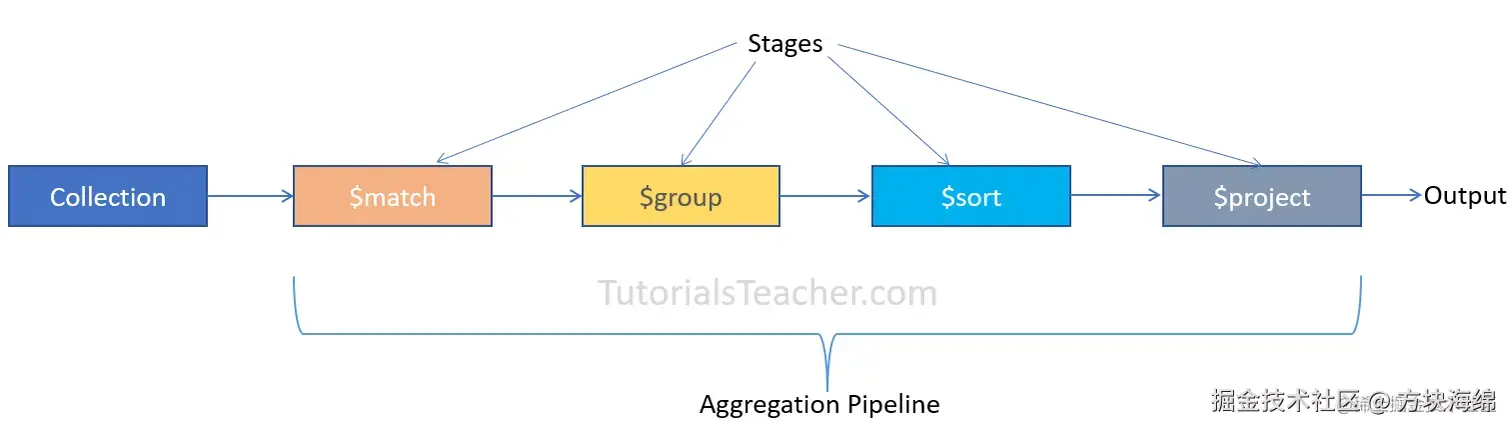
聚合示例:
less
db.collection.aggregate( [ { 阶段操作符:表述 }, { 阶段操作符:表述 }, ... ] )
php
db.orders.aggregate([
# 第一阶段:$match阶段按status字段过滤文档,并将status等于"A"的文档传递到下一阶段。
{ $match: { status: "A" } },
# 第二阶段:$group阶段按cust_id字段将文档分组,以计算每个cust_id唯一值的金额总和。
{ $group: { _id: "$cust_id", total: { $sum: "$amount" } } }
])高级
索引
底层结构
WiredTiger使用了 B 树
为什么使用 b树:
- mongo 对遍历数据的需求没有关系型数据库强,追求的是读写单个记录的性能。
- 大多数OLTP的数据库都是读多写少,B树和LSM树在该场景下更优
使用了 B 树,因为都是随机查询这样,大宽表
换了个引擎,引擎说是 b+树,就有了争论
background
因为是bson 结构,所以可以给字段的 json 也加索引
explain
stage:
- COLLSCAN:全表扫描
- IXSCAN:索引?
索引类型
- 单键索引:
db.userinfos.createIndex({age:1})
-
- 1表示升序索引
- -1表示降序索引
- 多键索引:当字段里面是 json 数组的时候,就是多键索引
- 哈希索引:直接 O(1)复杂度
- 局部索引:例如大于 100 小于 300 的 这样子的就加索引
- 唯一索引:只有一个 null 值
- 稀疏索引:不会将 null 值放在索引里面,所以每次查询出来的都没有 null 值 在联合索引中,如果有字段是 null,就不会把这个数据查出来
-
- 在需要全表扫描的时候,不会走这个索引,因为要把 null 值查询出来。除非强制指定 hint
- 和唯一索引一起使用,可以有多个 null 值
- TTL 索引:定时过期,需要有时间类型的字段配合使用
-
- 每60秒触发一次删除任务
数据分片与集群架构
复制集群(副本集群)
oplog(操作日志) 来同步数据的
客户端连接到整个 Mongodb 复制集群,主节点机负责整个复制集群的写,从节点可以进行读操作,但默认还是主节点负责整个复制集群的读。主节点发生故障时,自动从从节点中选举出一个新的主节点,确保集群的正常使用,这对于客户端来说是无感知的。
通常来说,一个复制集群包含 1 个主节点(Primary),多个从节点(Secondary)以及零个或 1 个仲裁节点(Arbiter)。
- 主节点 :整个集群的写操作入口,接收所有的写操作,并将集合所有的变化记录到操作日志中,即 oplog。主节点挂掉之后会自动选出新的主节点。
- 从节点 :从主节点同步数据,在主节点挂掉之后选举新节点。不过,从节点可以配置成 0 优先级,阻止它在选举中成为主节点。
- 仲裁节点 :这个是为了节约资源或者多机房容灾用,只负责主节点选举时投票不存数据,保证能有节点获得多数赞成票。
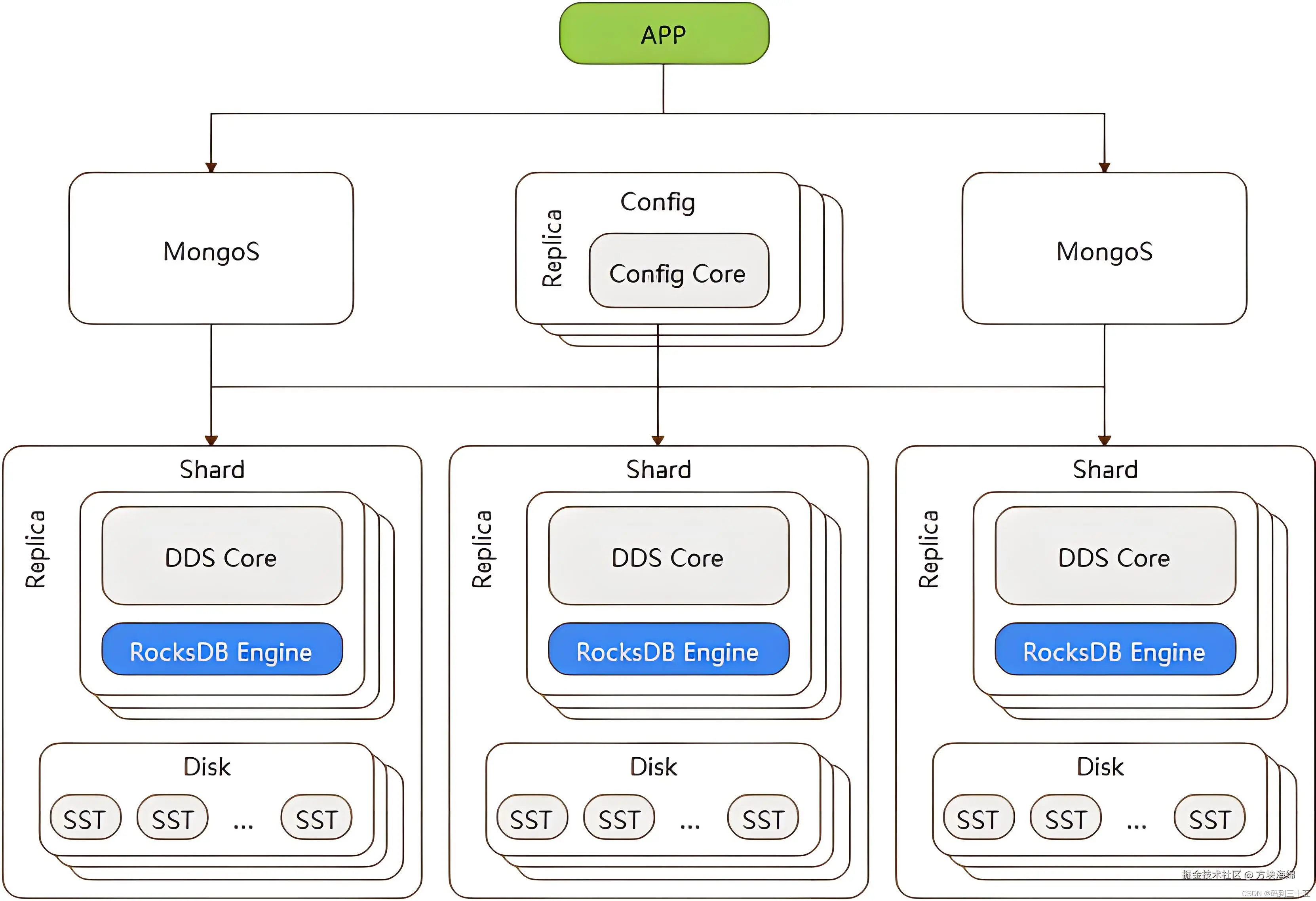
分片集群
-
支持 failover :提供自动故障恢复的功能,主节点发生故障时,自动从从节点中选举出一个新的主节点,确保集群的正常使用,这对于客户端来说是无感知的。
-
支持分片集群 :MongoDB 支持集群自动切分数据,让集群存储更多的数据,具备更强的性能。在数据插入和更新时,能够自动路由和存储。
-
支持存储大文件 :MongoDB 的单文档存储空间要求不超过 16MB。对于超过 16MB 的大文件,MongoDB 提供了 GridFS 来进行存储,通过 GridFS,可以将大型数据进行分块处理,然后将这些切分后的小文档保存在数据库中。
分片键(Shard Key) 是数据分区的前提, 从而实现数据分发到不同服务器上,减轻服务器的负担。也就是说,分片键决定了集合内的文档如何在集群的多个分片间的分布状况。
分片键就是文档里面的一个字段,但是这个字段不是普通的字段,有一定的要求:
- 它必须在所有文档中都出现。
- 它必须是集合的一个索引,可以是单索引或复合索引的前缀索引,不能是多索引、文本索引或地理空间位置索引。
- MongoDB 4.2 之前的版本,文档的分片键字段值不可变。MongoDB 4.2 版本开始,除非分片键字段是不可变的
_id字段,否则您可以更新文档的分片键值。MongoDB 5.0 版本开始,实现了实时重新分片(live resharding),可以实现分片键的完全重新选择。 - 它的大小不能超过 512 字节。
如何选择分片键:
- 取值基数 取值基数建议尽可能大,如果用小基数的片键,因为备选值有限,那么块的总数量就有限,随着数据增多,块的大小会越来越大,导致水平扩展时移动块会非常困难。 例如:选择年龄做一个基数,范围最多只有100个,随着数据量增多,同一个值分布过多时,导致 chunck 的增长超出 chuncksize 的范围,引起 jumbo chunk,从而无法迁移,导致数据分布不均匀,性能瓶颈。
- 取值分布 取值分布建议尽量均匀,分布不均匀的片键会造成某些块的数据量非常大,同样有上面数据分布不均匀,性能瓶颈的问题。
- 查询带分片 查询时建议带上分片,使用分片键进行条件查询时,mongos 可以直接定位到具体分片,否则 mongos 需要将查询分发到所有分片,再等待响应返回。
- 避免单调递增或递减 单调递增的 sharding key,数据文件挪动小,但写入会集中,导致最后一篇的数据量持续增大,不断发生迁移,递减同理。
分片策略
1、基于范围的分片 :
-
优点: Mongos 可以快速定位请求需要的数据,并将请求转发到相应的 Shard 节点中。
-
缺点: 可能导致数据在 Shard 节点上分布不均衡,容易造成读写热点,且不具备写分散性。
-
适用场景:分片键的值不是单调递增或单调递减、分片键的值基数大且重复的频率低、需要范围查询等业务场景。
2、基于 Hash 值的分片
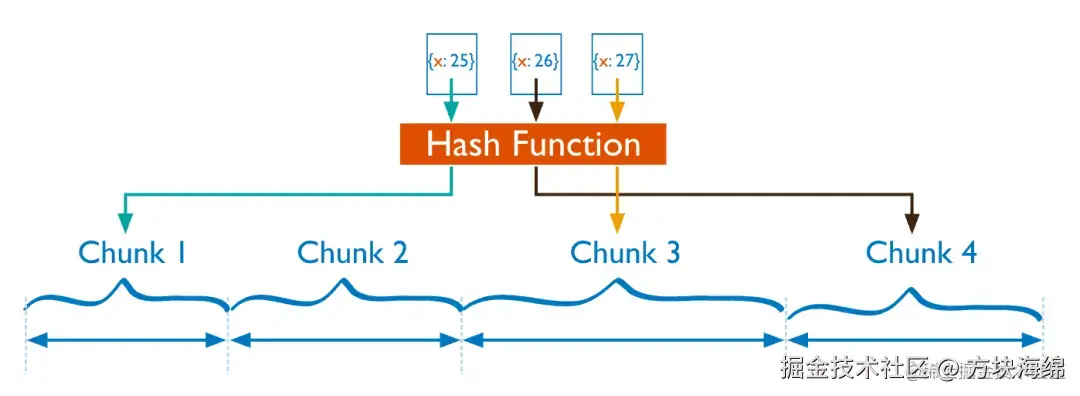
MongoDB 计算单个字段的哈希值作为索引值,并以哈希值的范围将数据拆分为不同的块(Chunk)。
- 优点:可以将数据更加均衡地分布在各 Shard 节点中,具备写分散性。
- 缺点:不适合进行范围查询,进行范围查询时,需要将读请求分发到所有的 Shard 节点。
- 适用场景:分片键的值存在单调递增或递减、片键的值基数大且重复的频率低、需要写入的数据随机分发、数据读取随机性较大等业务场景。
分布式锁
了解了 MongoDB 的分布式锁实现机制后,我们再来看看常见的分布式锁问题:
- 锁信息如何持久化?
客户端在写 MongoDB 时,使用 writeConcern majority,这样保证即使发生了主从切换,锁信息也不会丢失。
- 如何防止客户端 A 释放客户端 B 获得的锁?
每个进程加锁时会在锁资源中设置一个携带机器和 PID 信息的标志,在释放锁时会判断这个标志,防止错误释放。
- 如何避免客户端进程挂了,导致锁永远不会释放?
采用租约的方式,进程在获得锁之后,要启动一个后台线程定期续约。如果超过 15 分钟没有续约,则这个锁可以被其他进程抢占。
和其他大多数系统不同的是,MongoDB 没有使 用 TTL 来完成租约,而是记录最后一次续约的时间,将抢占操作交给客户端进程来实现。
- 如何避免机器时钟不同步带来的问题?
不同的客户端之间,以及客户端机器和 MongoDB 服务端的时钟可能并不同步。时钟不同步可能会对续租、发起抢占的操作造成影响。
比如 MongoDB 发生了主从切换,但是从节点的时间提前了几分钟,又或者主节点在 NTP 时钟对齐后时钟瞬间提前了几分钟等。这样可能会导致之前的正常续租失效,锁被异常抢占。为了避免时钟跳变带来的影响, MongoDB 内核代码中设置了 15 分钟没有续约才失效,如果 NTP 时钟对齐频繁一些,基本上是不会有啥问题。
- 如何避免进程停顿(如 GC)和网络延迟等带来的影响?
进程停顿:客户端进程 A 拿到锁之后,由于其他操作(或者 GC 等)停顿了几分钟,然后再去操作临界资源。但是再停顿期间,可能由于没有续约导致锁被客户端 B 抢占了。此时就存在竞争风险。
网络延迟:和进程停顿的场景类似,也有可能 2 个客户端同时"加锁成功"的情况。
MongoDB 官方文档中明确说明无法 100% 消除这种场景。业界通常的解决方法有:
a. 调大续约超时。MongoDB 推荐的设置为 15 分钟,已经是很长的时间了,现实中很少会有 GC 停顿或者网络请求长达 15 分钟。
b. 使用(严格递增的) fencing token. 进程 A 拿到锁时, 得到的 token 是 v1,然后 GC 导致续约卡住了。然后进程 B 抢占了锁,得到的 token 是 v2 并在要保护的系统上操作了数据。此时进程 A 再使用 v1 的锁再去操作数据时,会由于 token 版本太低被拒绝。这种机制需要第3方受保护的系统支持 token 的递增判断,因此会带来一定的系统复杂度。
有读者可能会认为这个解决方案有点重,实现起来比较繁琐,还不如 TTL 方案直观。我个人的建议是:对于可用性和一致性要求高的系统,尽量不要在关键链路上依赖 TTL,除非明确知道 TTL 方案带来的风险,并确保能承受该风险。