上篇文章:
目录
[1 HAProxy安装](#1 HAProxy安装)
[1.1 安装HAProxy](#1.1 安装HAProxy)
[1.2 配置haproxy.cfg(配置负载均衡器监听的服务器和管理界面)](#1.2 配置haproxy.cfg(配置负载均衡器监听的服务器和管理界面))
[1.3 启动HAProxy](#1.3 启动HAProxy)
[2 HAProxy使用](#2 HAProxy使用)
前面讲到消息分发时可以对消费者进行负载均衡,当然面对多节点的RabbitMQ集群,也需要负载均衡。原因如下:
1.写代码时,我们访问集群中任何一个节点都可以,但是如果我们访问的节点宕机,虽然集群还可以正常工作,但是我们的生产者或消费者服务很可能因为无法访问该节点就崩溃。因此,直接访问某个节点不太好,需要访问一个统一的入口,该入口来帮助负载均衡到不同的RabbitMQ节点。
2.如果都只访问集群的某一个节点,容易导致该节点负载过大从而容易崩溃,而其它集群节点很可能比较空闲,因此需要把消息负载均衡到不同的RabbitMQ节点。
这里介绍使用其它软件作为负载均衡器:
1 HAProxy安装
HAProxy是一个开源的负载均衡器和TCP/HTTP应用程序的代理服务器,主要用来提供集群的高可用性、负载均衡和代理功能。HAProxy会把接受的请求分发到多个服务器,以提高网络的可靠性和性能。
1.1 安装HAProxy
命令:yum -y install haproxy

1.2 配置haproxy.cfg(配置负载均衡器监听的服务器和管理界面)
命令:vim /etc/haproxy/haproxy.cfg
配置内容如下:
bash
#haproxy监听集群配置
listen rabbitmq_local_cluster 0.0.0.0:5670 #集群前端IP,供producter和consumer来进行选择,选择一个没有被占用的即可
mode tcp #负载均衡选项
balance roundrobin #轮询算法将负载发给后台服务器
server rabbit1 127.0.0.1:5672 check inter 5000 rise 2 fall 3 #负载均衡器监听的集群节点配置,rabbitmq节点名称只在负载均衡器中使用(不一定和rabbitmq服务器名称一样),每5000秒一次健康检查,连续3次检查失败就停用该服务器,连续2次检查成功就恢复该服务器。
server rabbit2 127.0.0.1:5673 check inter 5000 rise 2 fall 3
server rabbit3 127.0.0.1:5674 check inter 5000 rise 2 fall 3
#haproxy前端监控页面配置
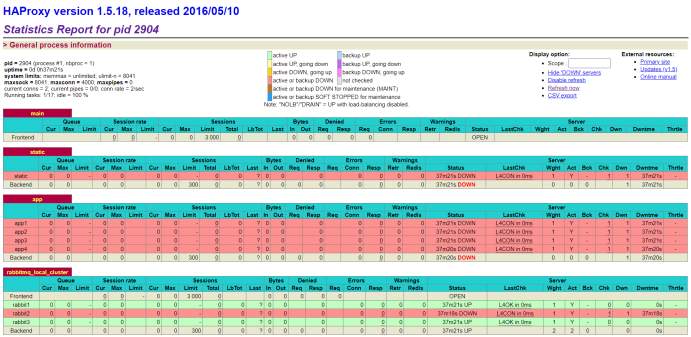
listen private_monitoring :8100
mode http
option httplog
stats enable
stats uri /stats #haproxy 前端页面
stats refresh 60s # 60s刷新一次页面
stats auth admin:admin #用户名和密码1.3 启动HAProxy
命令:systemctl start haproxy

2 HAProxy使用
开启HAProxy后,生产者需要把与RabbitMQ连接的ip和端口号改为HAProxy所在的ip和其开发的端口号:
java
spring:
rabbitmq:
addresses: amqp://admin:admin@192.168.159.150:5670/testVirtual其它使用就和普通队列的消息发送无异了:
java
@Bean("haproxyQueue")
public Queue haproxyQueue(){
return QueueBuilder.durable("haproxy.queue").quorum().build();
}
@RequestMapping("haproxy")
public String haproxy() {
rabbitTemplate.convertAndSend("", "haproxy.queue", "Hello SpringBoot RabbitMQ");
return "发送成功";
}运行结果如下:

如果让其中一个节点宕机,生产者也不会出现连接异常,仍然可以发送消息:


恢复宕机的节点,由于仲裁队列的同步能力,消息也同步到宕机节点上:


注意:由于增加了负载均衡器,如果Haproxy所在节点也发生宕机,对于客户端来讲就无法与RabbitMQ交互,因此通常会用Keepalived等高可用解决方案对haproxy做主备,在HAProxy主节点故障时自动将流量转移到备用节点。这也体现了分布式环境解决高可用的特点,就是增加机器用备用节点备份。