【前瞻创想】Kurator分布式云原生平台:从架构解析到企业级多云集群管理实战指南
- 【前瞻创想】Kurator分布式云原生平台:从架构解析到企业级多云集群管理实战指南
-
- 摘要
- [1. Kurator平台架构概览](#1. Kurator平台架构概览)
-
- [1.1 多云原生技术栈整合](#1.1 多云原生技术栈整合)
- [1.2 统一管理平面设计思想](#1.2 统一管理平面设计思想)
- [1.3 分布式云原生的核心价值](#1.3 分布式云原生的核心价值)
- [2. 环境搭建与基础配置](#2. 环境搭建与基础配置)
-
- [2.1 从源码构建Kurator平台](#2.1 从源码构建Kurator平台)
- [2.2 多集群环境初始化](#2.2 多集群环境初始化)
- [2.3 核心组件部署与验证](#2.3 核心组件部署与验证)
- [3. Fleet:集群舰队的统一治理](#3. Fleet:集群舰队的统一治理)
-
- [3.1 Fleet资源模型与架构](#3.1 Fleet资源模型与架构)
- [3.2 跨集群资源同步机制](#3.2 跨集群资源同步机制)
- [3.3 命名空间与身份的相同性保障](#3.3 命名空间与身份的相同性保障)
- [4. Karmada集成:跨集群弹性扩展实战](#4. Karmada集成:跨集群弹性扩展实战)
-
- [4.1 Karmada在Kurator中的定位](#4.1 Karmada在Kurator中的定位)
- [4.2 多集群应用分发策略](#4.2 多集群应用分发策略)
- [4.3 跨集群弹性伸缩实现](#4.3 跨集群弹性伸缩实现)
- [5. KubeEdge:边缘计算与云边协同](#5. KubeEdge:边缘计算与云边协同)
-
- [5.1 KubeEdge核心架构解析](#5.1 KubeEdge核心架构解析)
- [5.2 云边协同的通信隧道](#5.2 云边协同的通信隧道)
- [5.3 边缘应用部署最佳实践](#5.3 边缘应用部署最佳实践)
- [6. Volcano:AI/批处理工作负载调度](#6. Volcano:AI/批处理工作负载调度)
-
- [6.1 Volcano调度架构优势](#6.1 Volcano调度架构优势)
- [6.2 Queue与PodGroup资源管理](#6.2 Queue与PodGroup资源管理)
- [6.3 深度学习任务调度实战](#6.3 深度学习任务调度实战)
- [7. Kurator未来发展方向](#7. Kurator未来发展方向)
-
- [7.1 分布式云原生技术趋势](#7.1 分布式云原生技术趋势)
- [7.2 Kurator技术路线图](#7.2 Kurator技术路线图)
- [7.3 企业数字转型建议](#7.3 企业数字转型建议)
- 结语
【前瞻创想】Kurator分布式云原生平台:从架构解析到企业级多云集群管理实战指南

摘要
在数字化转型浪潮中,企业面临着多云、混合云、边缘计算等复杂环境下的基础设施管理挑战。Kurator作为新一代开源分布式云原生平台,通过整合Kubernetes、Karmada、KubeEdge、Volcano等优秀开源项目,为企业提供统一的资源管理、调度、监控和应用交付能力。本文从实战角度深入剖析Kurator架构设计,详细演示Fleet集群舰队管理、Karmada跨集群调度、KubeEdge边缘协同、Volcano批处理调度等核心功能的配置与实践,并结合GitOps理念探讨企业级CI/CD流水线构建,最终展望分布式云原生技术的未来发展方向,为架构师和运维工程师提供全面的技术参考和实践指导。
Kurator开源项目 参考图:
1. Kurator平台架构概览
kurator架构参考图:
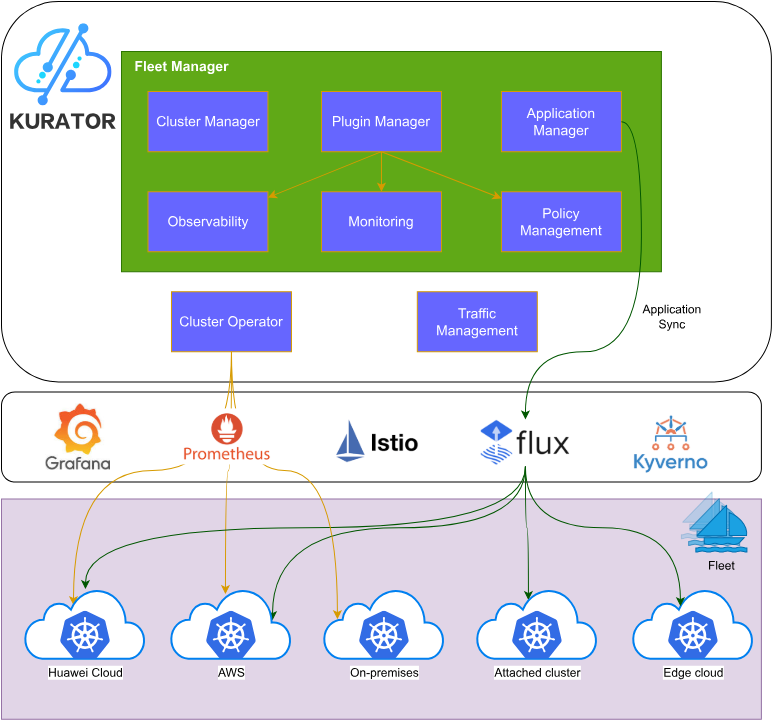
1.1 多云原生技术栈整合
Kurator不是另一个从零开始的云原生平台,而是站在巨人肩膀上的集大成者。它巧妙整合了Kubernetes生态中的多个明星项目:Karmada负责多集群管理,KubeEdge打通云边协同,Volcano优化批处理工作负载调度,Istio提供服务网格能力,Prometheus实现统一监控,FluxCD支撑GitOps实践,Kyverno确保策略合规。这种"乐高式"的架构设计让Kurator能够快速吸收社区最佳实践,避免重复造轮子。
从架构视角看,Kurator采用分层设计:基础设施层支持公有云、私有云、边缘节点的异构资源整合;控制平面层通过统一API提供集群生命周期管理;应用层则聚焦于工作负载的跨环境部署与调度;运维层整合可观测性、安全策略和自动化能力。这种层次分明的架构既保证了扩展性,又简化了运维复杂度。
1.2 统一管理平面设计思想
Kurator 统一策略管理参考图:
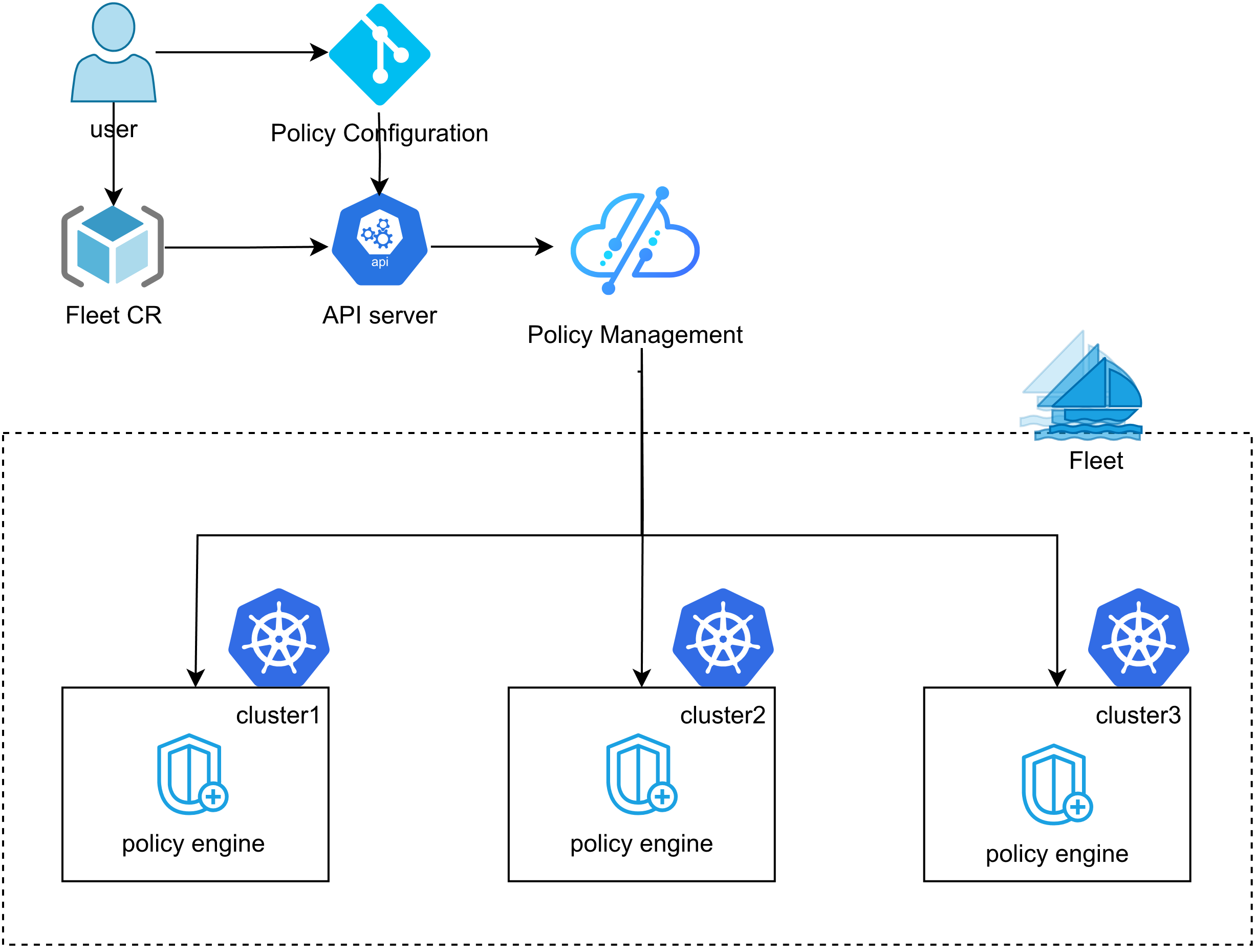
Kurator的核心创新在于其"统一管理平面"设计哲学。在传统架构中,多云管理通常意味着多个独立的控制台、不一致的API接口和割裂的运维体验。Kurator通过抽象层将这些差异隐藏起来,向用户提供一致的接口和体验。例如,Fleet资源对象是Kurator的核心抽象,一个Fleet可以包含来自不同云厂商、不同地域甚至边缘环境的多个集群,用户只需关注业务需求,而无需关心底层基础设施的具体细节。
yaml
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
meta
name: production-fleet
spec:
clusters:
- name: aws-us-west-cluster
kubeconfigRef: aws-us-west-kubeconfig
- name: azure-east-cluster
kubeconfigRef: azure-east-kubeconfig
- name: edge-beijing-cluster
kubeconfigRef: edge-beijing-kubeconfig
placement:
strategy: spread
replicas: 31.3 分布式云原生的核心价值
核心价值参考图:
分布式云原生不仅是技术升级,更是业务模式创新的催化剂。Kurator通过统一资源编排、统一调度、统一流量管理和统一遥测四大核心能力,解决了企业在多云环境下面临的关键痛点。统一资源编排确保应用可以在不同环境中无缝迁移;统一调度优化资源利用率,降低总体拥有成本;统一流量管理提供跨集群服务发现和负载均衡;统一遥测打破数据孤岛,提供全局视图。
这种价值在实际业务场景中尤为明显:零售企业可以将核心交易系统部署在公有云,将用户行为分析放在边缘节点,通过Kurator实现数据的就近处理和低延迟响应;制造企业可以将AI质检模型部署在工厂边缘,同时将训练任务调度到云端高性能计算集群,形成闭环的智能生产系统。
2. 环境搭建与基础配置
2.1 从源码构建Kurator平台
环境搭建是实战的第一步。Kurator提供灵活的部署选项,从源码构建可以获取最新特性和定制能力。以下命令将获取Kurator的完整代码库:
bash
git clone https://github.com/kurator-dev/kurator.git
cd kurator下载下来是这样的,如图所示

对于网络受限环境,比如如下这样

也可以使用wget下载zip包:
bash
wget https://github.com/kurator-dev/kurator/archive/refs/heads/main.zip
unzip main.zip
cd kurator-mainwget下载下来是这个界面,可以清楚的看到源码已经下载下来了
源码构建需要满足以下前置条件:
- Kubernetes集群 (v1.20+)
- Helm (v3.8+)
- Kustomize (v4.5+)
- Go (v1.18+)
构建过程分为两个主要阶段:首先是编译Kurator CLI工具,其次是部署Kurator控制平面组件。CLI工具提供了简化的安装和管理接口,是日常运维的主要入口。
bash
# 构建CLI工具
make build
# 验证构建结果
./bin/kurator version2.2 多集群环境初始化
Kurator的真正价值在多集群环境中才能充分展现。典型的生产环境至少需要三个集群:一个中央控制集群(运行Kurator控制平面),一个或多个成员集群(运行实际工作负载),以及可选的边缘集群。可以使用Kind、Minikube或云厂商托管服务快速创建测试集群。
bash
# 使用Kind创建三个测试集群
kind create cluster --name kurator-control-plane
kind create cluster --name member-cluster-1
kind create cluster --name member-cluster-2
# 获取集群kubeconfig
kind get kubeconfig --name kurator-control-plane > control-plane.kubeconfig
kind get kubeconfig --name member-cluster-1 > member1.kubeconfig
kind get kubeconfig --name member-cluster-2 > member2.kubeconfig集群准备就绪后,需要配置集群间网络连通性。在云环境中,这通常涉及VPC对等连接、安全组规则和网络ACL配置;在混合云场景中,可能需要建立VPN隧道或专线连接。Kurator提供网络连通性检查工具,帮助验证集群间通信能力:
bash
./bin/kurator check connectivity --kubeconfig control-plane.kubeconfig \
--member-kubeconfigs member1.kubeconfig,member2.kubeconfig2.3 核心组件部署与验证
Kurator控制平面部署采用Helm Chart方式,确保部署过程的可重复性和可审计性。安装过程分为两个阶段:首先是基础依赖(如cert-manager、metrics-server),然后是Kurator核心组件。
bash
# 安装基础依赖
helm install cert-manager jetstack/cert-manager \
--namespace cert-manager \
--create-namespace \
--version v1.8.0 \
--set installCRDs=true
# 部署Kurator控制平面
./bin/kurator install --kubeconfig control-plane.kubeconfig安装完成后,通过kubectl验证组件状态:
bash
kubectl get pods -n kurator-system
# 应该看到所有Pod状态为Running
# kurator-controller-manager-xxx 2/2 Running 0 2m
# kurator-webhook-xxx 1/1 Running 0 2m
# karmada-controller-manager-xxx 1/1 Running 0 2m关键验证点包括:
- 所有控制器Pod正常运行
- Webhook服务可用
- API扩展正确注册
- 多集群通信通道建立
3. Fleet:集群舰队的统一治理
3.1 Fleet资源模型与架构
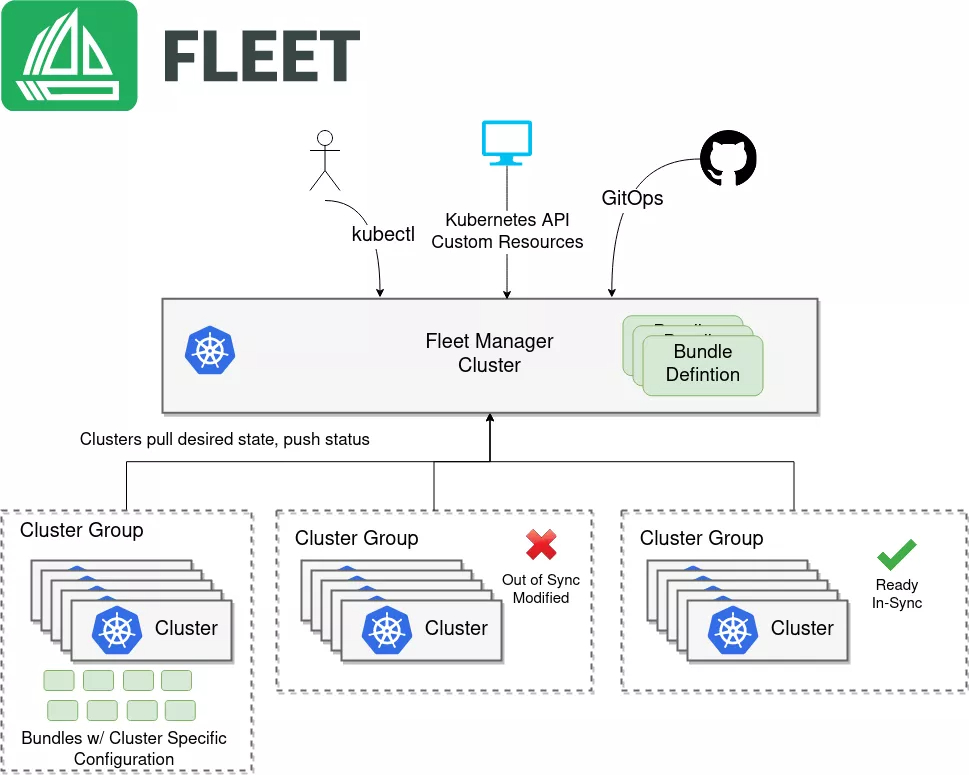
Fleet是Kurator中最具创新性的抽象概念,它将多个物理上分散的Kubernetes集群在逻辑上组织为一个统一的资源池。Fleet不仅仅是集群集合,它定义了集群间的协作规则、资源分配策略和一致性保障机制。从API设计角度看,Fleet资源包含三个核心部分:集群成员定义、工作负载放置策略和跨集群服务治理规则。
yaml
apiVersion: fleet.kurator.dev/v1alpha1
kind: Fleet
metadata:
name: global-services
spec:
clusters:
- name: us-east-cluster
labels:
region: us-east
environment: production
- name: eu-central-cluster
labels:
region: eu-central
environment: production
- name: ap-southeast-cluster
labels:
region: ap-southeast
environment: production
placementPolicy:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: region
whenUnsatisfiable: DoNotSchedule
serviceTopology:
enabled: true
topologyKeys: ["region", "zone"]Fleet架构的核心是"控制器模式":Fleet控制器监视Fleet资源变化,协调底层Karmada和KubeEdge组件实现声明式配置。这种设计既保持了Kubernetes的声明式API哲学,又提供了足够的灵活性来适应复杂的业务场景。
3.2 跨集群资源同步机制
Fleet 的集群注册参考图:

在多集群环境中,保持资源配置的一致性是巨大挑战。Kurator通过两种主要机制解决这个问题:基于GitOps的声明式同步和基于事件的主动同步。GitOps模式使用FluxCD监控Git仓库中的配置变化,自动应用到所有相关集群;事件驱动模式则通过Kubernetes事件机制,在一个集群发生变化时触发其他集群的同步操作。
对于敏感资源如同步ServiceAccount和Secret,Kurator采用"加密传输+权限最小化"策略。所有跨集群传输的数据都通过TLS加密,目标集群只获得完成特定任务所需的最小权限。以下示例展示了如何配置跨集群ConfigMap同步:
yaml
apiVersion: fleet.kurator.dev/v1alpha1
kind: ClusterResourceSync
meta
name: global-config-sync
spec:
fleetRef:
name: global-services
resources:
- group: ""
version: v1
kind: ConfigMap
name: global-settings
namespace: kube-system
syncPolicy:
interval: 5m
retryLimit: 3
failureThreshold: 13.3 命名空间与身份的相同性保障
多集群环境中的身份管理是安全合规的关键。Kurator提供"身份相同性"(Identity Sameness)机制,确保用户和服务账户在不同集群中具有相同的身份标识和权限。这通过两种方式实现:集中式身份提供者(如Keycloak、Dex)集成和分布式身份同步。
Fleet 舰队中的命名空间相同性参考图:
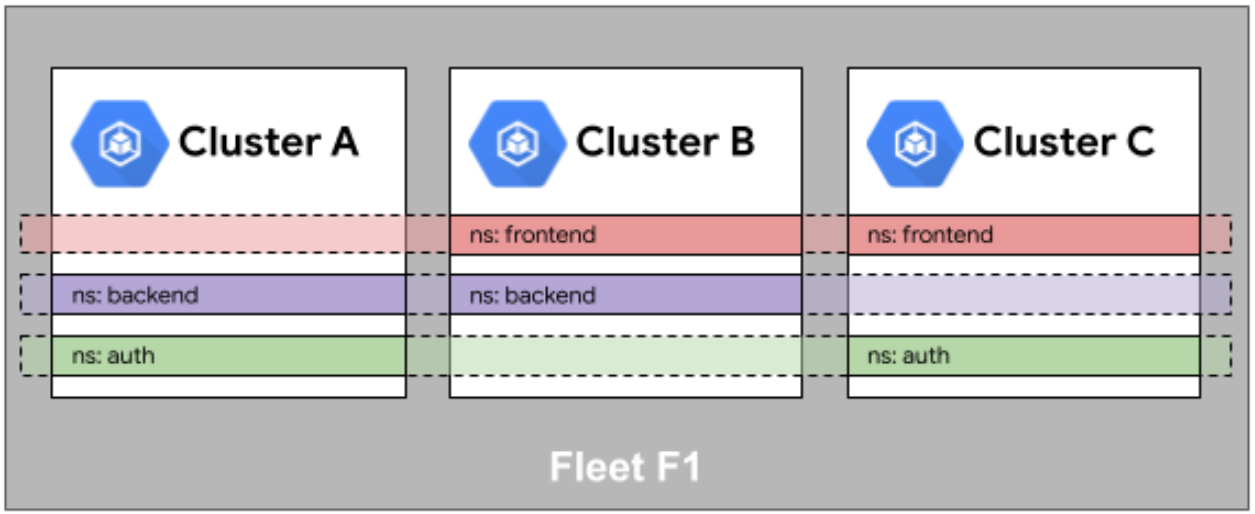
命名空间相同性(Namespace Sameness)则确保相同名称的命名空间在所有集群中具有相同的配置和策略。这对于多环境部署
(dev/staging/prod)和多租户隔离至关重要。以下Kurator策略示例强制所有集群中的"production"命名空间具有相同的资源配额和网络策略:
yaml
apiVersion: policy.kurator.dev/v1alpha1
kind: NamespacePolicy
meta
name: production-namespace-policy
spec:
namespaceSelector:
matchNames: ["production"]
resourceQuota:
hard:
requests.cpu: "16"
requests.memory: 64Gi
limits.cpu: "32"
limits.memory: 128Gi
networkPolicies:
- name: default-deny
spec:
podSelector: {}
policyTypes: ["Ingress", "Egress"]4. Karmada集成:跨集群弹性扩展实战

4.1 Karmada在Kurator中的定位
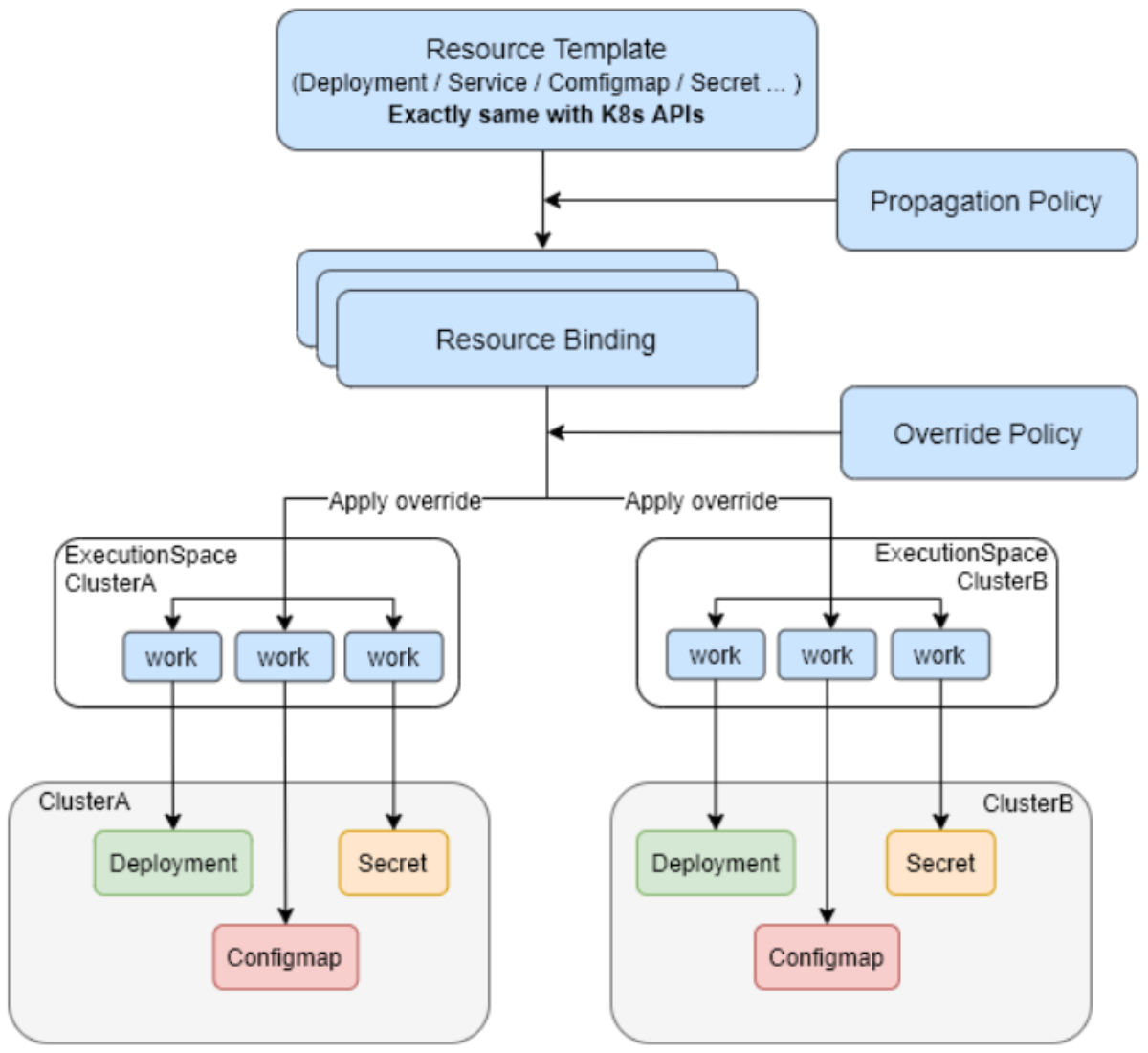
Karmada作为CNCF孵化项目,是多集群调度的事实标准。在Kurator架构中,Karmada不是可选组件,而是核心调度引擎。Kurator对Karmada进行了深度集成和扩展,主要体现在三个方面:简化的API抽象、增强的策略引擎和扩展的调度算法。用户无需直接操作复杂的Karmada API,而是通过Kurator提供的高级抽象完成跨集群部署。
Karmada的核心价值在于其"调度-执行"分离架构:调度器决定工作负载应该部署在哪些集群,传播控制器负责将资源实际分发到目标集群,执行引擎在各集群中运行工作负载。Kurator强化了这一架构,增加了集群健康度感知、成本优化和合规性检查等企业级特性。
4.2 多集群应用分发策略
Kurator 统一应用分发参考图:

在Kurator中,应用分发策略通过PropagationPolicy资源定义。这些策略支持复杂的约束条件,包括集群选择器、副本分布规则和故障转移配置。以下示例展示了如何将关键业务服务部署到三个高可用区域的集群,同时确保每个区域至少有一个副本:
yaml
apiVersion: policy.karmada.io/v1alpha1
kind: PropagationPolicy
meta
name: critical-service-policy
spec:
resourceSelectors:
- apiVersion: apps/v1
kind: Deployment
name: payment-service
placement:
clusterAffinity:
clusterNames: ["us-east-1", "eu-west-1", "ap-southeast-1"]
replicaScheduling:
replicaDivisionPreference: Weighted
replicaSchedulingType: Divided
weightList:
- targetCluster:
clusterNames: ["us-east-1"]
weight: 50
- targetCluster:
clusterNames: ["eu-west-1"]
weight: 30
- targetCluster:
clusterNames: ["ap-southeast-1"]
weight: 20
spreadConstraints:
- maxGroups: 3
minGroups: 3
topologyKey: region这种策略设计不仅考虑了地理分布,还考虑了流量模式和成本因素。例如,为美国用户分配更多副本,同时保持足够的冗余以防区域故障。
4.3 跨集群弹性伸缩实现
Karmada调度引擎参考图,详细见下图:
Kurator结合Karmada的弹性伸缩能力,实现了真正的跨集群自动扩缩容。与单集群HPA不同,Kurator的FederatedHPA可以根据全局指标(如总请求量、平均延迟)和局部指标(如单个集群CPU利用率)做出扩缩容决策。这种全局视角的扩缩容策略能够避免"震荡"问题,提高资源利用效率。
yaml
apiVersion: autoscaling.kurator.dev/v1alpha1
kind: FederatedHPA
meta
name: global-web-hpa
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: web-frontend
metrics:
- type: Object
object:
metric:
name: requests-per-second
describedObject:
apiVersion: networking.k8s.io/v1
kind: Ingress
name: web-ingress
target:
type: AverageValue
averageValue: 1000
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70
behavior:
scaleUp:
stabilizationWindowSeconds: 60
policies:
- type: Percent
value: 100
periodSeconds: 15
scaleDown:
stabilizationWindowSeconds: 300
policies:
- type: Percent
value: 10
periodSeconds: 60在实际生产环境中,我们建议采用渐进式扩缩容策略:首先在流量高峰前预扩容,然后根据实时指标微调,最后在低谷期逐步缩减。这种策略结合了预测性和反应性,既能应对突发流量,又能避免资源浪费。
5. KubeEdge:边缘计算与云边协同

5.1 KubeEdge核心架构解析
KubeEdge核心架构参考图:
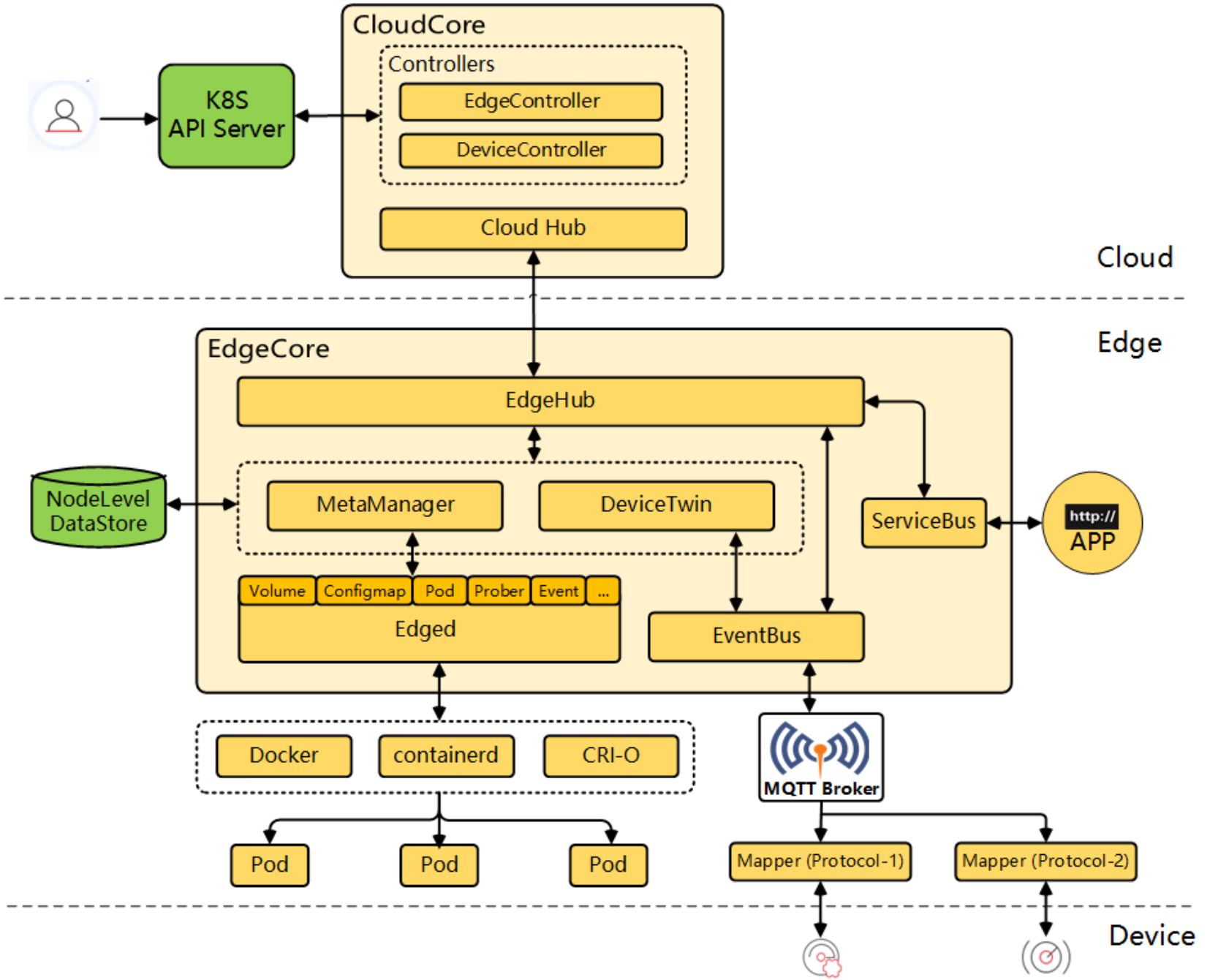
KubeEdge是Kurator边缘计算能力的基石,它将Kubernetes原生能力扩展到边缘节点。KubeEdge架构分为三个主要部分:云上组件(CloudCore)、边缘组件(EdgeCore)和通信层(WebSocket/MQTT)。在Kurator中,KubeEdge不是独立运行,而是与Karmada深度集成,形成"云-边-端"三级架构。
KubeEdge的核心创新在于其"离线自治"能力。当边缘节点与云端断开连接时,EdgeCore可以继续运行已有工作负载,并根据预定义策略做出本地决策。这种能力对工业物联网、车联网等网络不稳定场景至关重要。Kurator进一步增强了这一能力,通过预取模型和智能缓存,让边缘节点在断网期间仍能获得最新的配置更新。
yaml
apiVersion: edge.kurator.dev/v1alpha1
kind: EdgeNode
meta
name: factory-edge-node-01
spec:
nodeSelector:
kurator.dev/edge-node: "true"
connectivity:
tunnelType: websocket
heartbeatInterval: 15
maxConnectionRetries: 5
autonomy:
offlineTTL: 24h
localPolicyStorage: true5.2 云边协同的通信隧道
隧道机制参考图:
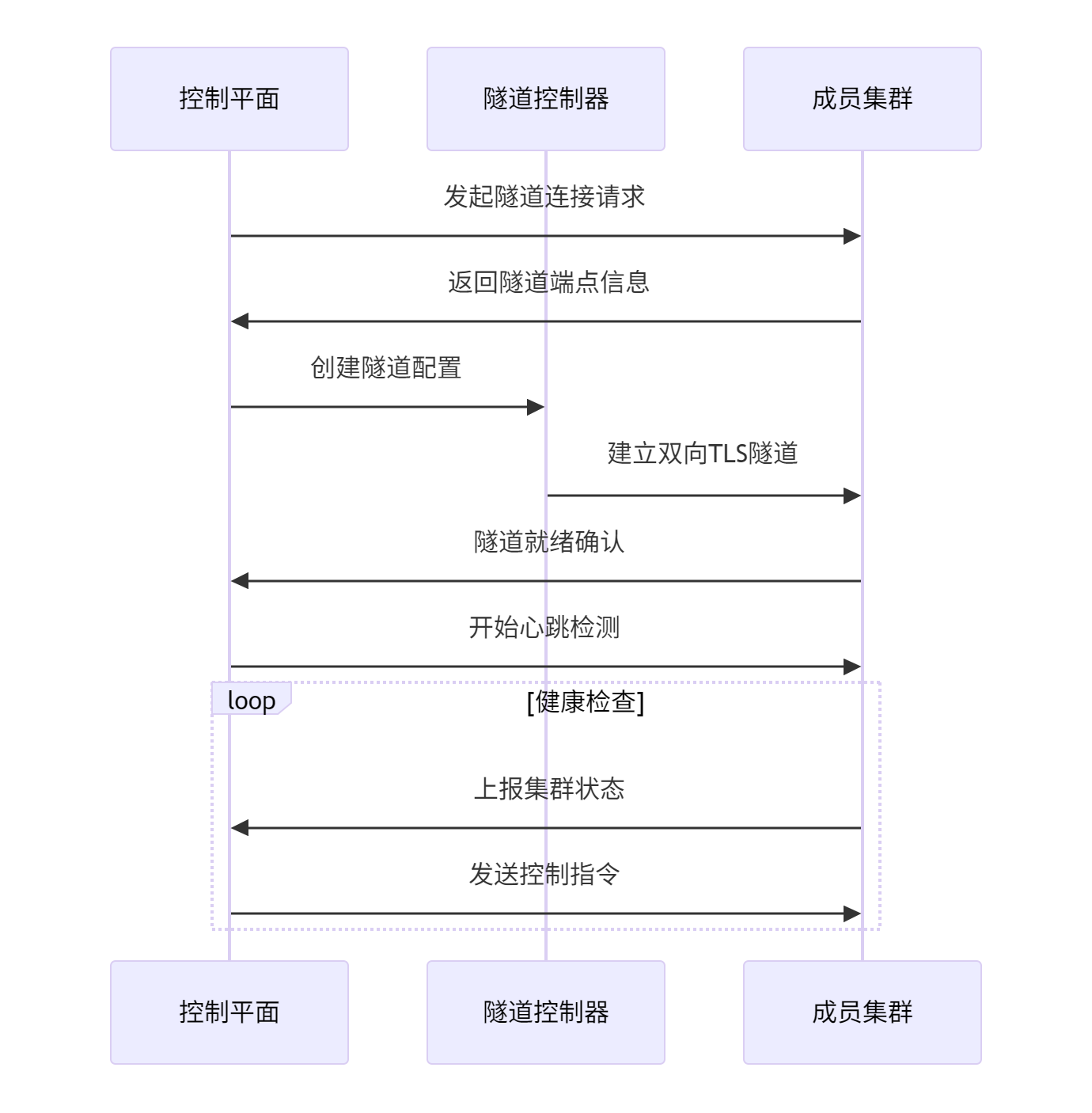
边缘环境通常存在复杂的网络限制:NAT、防火墙、带宽限制等。Kurator通过多种通信隧道技术解决这些问题,包括WebSocket隧道(适用于大多数Web代理环境)、MQTT(适用于低带宽不稳定网络)和QUIC(适用于高延迟网络)。这些隧道都支持自动故障转移,当主隧道失效时,系统会自动切换到备用隧道。
在安全方面,所有云边通信都经过双向TLS认证和端到端加密。Kurator还支持基于证书的设备认证和动态证书轮换,防止长期凭证泄露风险。以下配置示例展示了如何为高延迟网络优化隧道参数:
yaml
apiVersion: edge.kurator.dev/v1alpha1
kind: EdgeTunnel
metadata:
name: remote-site-tunnel
spec:
edgeNodeSelector:
site: remote-factory
protocol:
primary: quic
fallback: websocket
security:
certRotationInterval: 720h
trustedCA: edge-ca-cert
performance:
compression: true
heartbeatTimeout: 300s
maxPayloadSize: 10Mi5.3 边缘应用部署最佳实践
云边协同应用部署参考图:
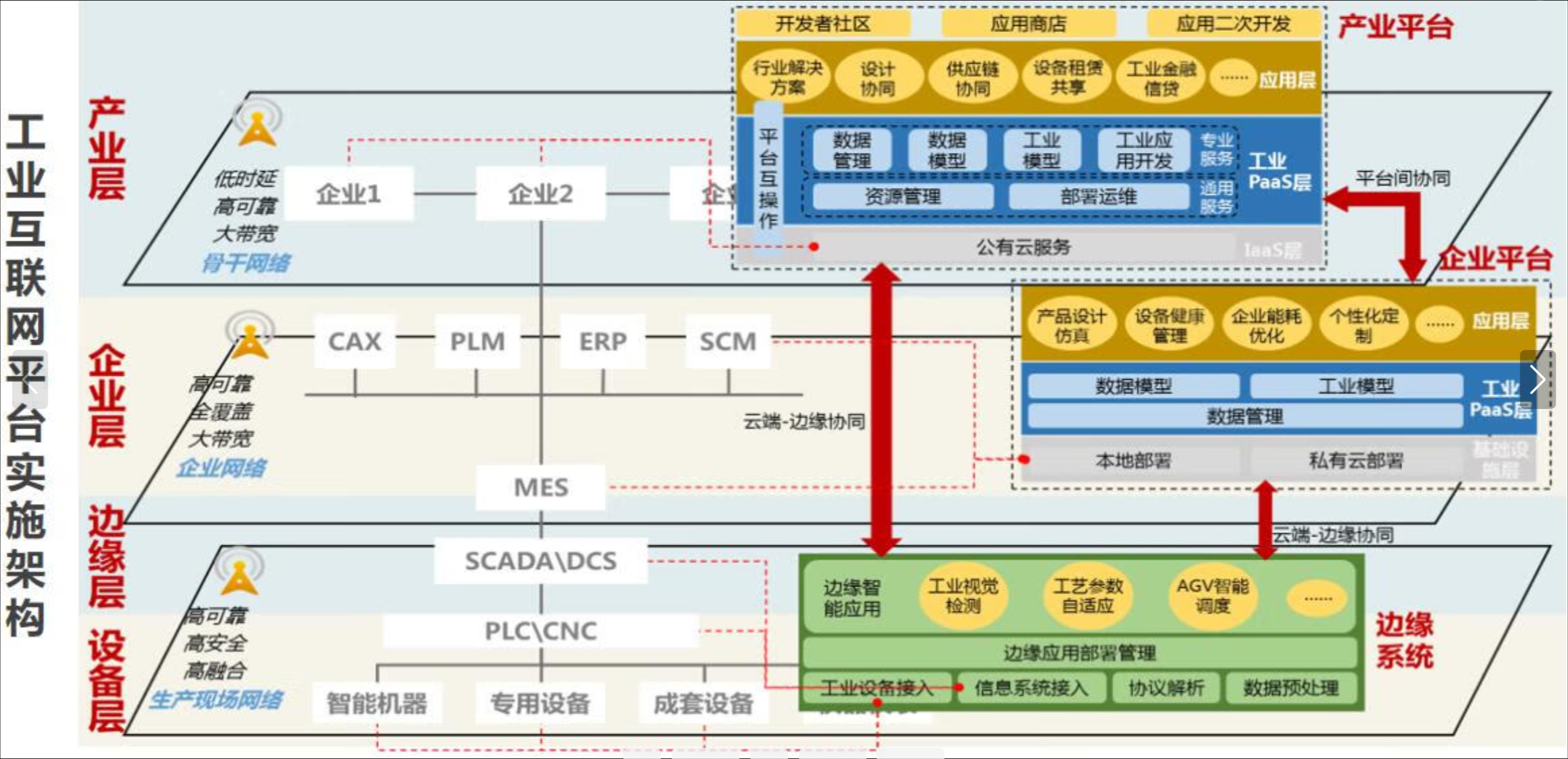
在边缘环境部署应用需要考虑资源限制、网络波动和物理安全等因素。Kurator提供边缘专用的工作负载抽象,优化边缘场景下的应用生命周期管理。对于AI推理等计算密集型任务,建议采用"云训边推"模式:模型在云端训练,推理在边缘执行。
yaml
apiVersion: apps.kurator.dev/v1alpha1
kind: EdgeDeployment
meta
name: quality-inspection
spec:
selector:
edgeNodeSelector:
site: manufacturing-floor
template:
meta
annotations:
edge.kurator.dev/offline-capable: "true"
edge.kurator.dev/model-cache: "inspection-model-v3"
spec:
containers:
- name: inspection-service
image: edge-registry/quality-inspection:1.2
resources:
limits:
cpu: "2"
memory: 4Gi
nvidia.com/gpu: 1
volumeMounts:
- name: model-cache
mountPath: /models
volumes:
- name: model-cache
edgeCache:
source: cloud-registry/inspection-model:v3
updatePolicy: OnDemand边缘部署的关键是平衡自治性和集中控制。建议采用"分级策略":安全策略和合规要求集中管理,业务逻辑和数据处理在边缘自治。这种模式既满足了监管要求,又保持了边缘响应的敏捷性。
6. Volcano:AI/批处理工作负载调度
6.1 Volcano调度架构优势
Volcano调度架构参考图:
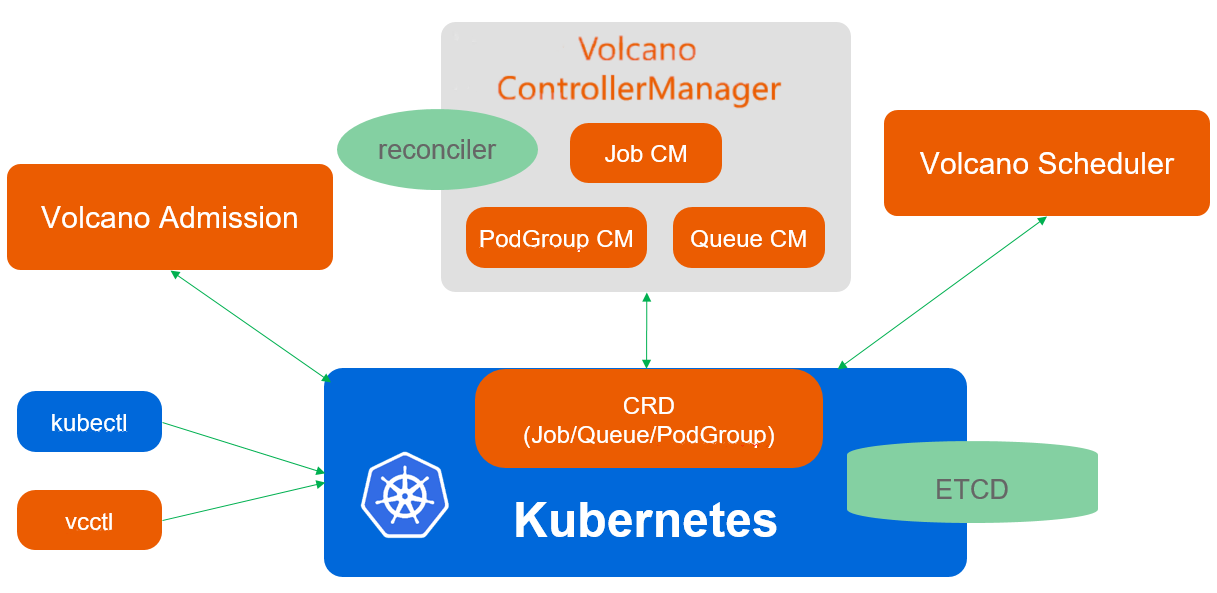
在AI训练、大数据分析和科学计算领域,标准Kubernetes调度器往往力不从心。Volcano作为CNCF沙箱项目,专为批处理工作负载优化,提供任务依赖、资源抢占、公平共享等高级调度能力。Kurator将Volcano深度集成到统一调度框架中,使AI/ML工作负载能够与常规服务共享基础设施,同时获得所需的调度保障。
Volcano的核心创新在于其"两级调度"架构:全局调度器负责集群间资源分配,本地调度器负责集群内任务调度。这种设计特别适合分布式训练场景,其中参数服务器需要全局视野,而数据并行任务可以在本地优化。Kurator进一步扩展了这一架构,增加了跨集群资源预留和弹性训练能力。
6.2 Queue与PodGroup资源管理
Volcano的Queue和PodGroup是其最强大的抽象。Queue定义了资源池和配额策略,PodGroup则描述任务组的调度要求和依赖关系。在Kurator中,这些资源被提升为一级公民,与Fleet资源无缝集成,实现跨集群的批处理工作负载管理。
yaml
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
meta
name: ml-training-queue
spec:
weight: 50
capability:
cpu: "100"
memory: 500Gi
nvidia.com/gpu: "20"
reclaimable: true
---
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
meta
name: distributed-training
spec:
minMember: 8
minTaskMember:
ps: 2
worker: 6
schedulerName: volcano
queue: ml-training-queue
priorityClassName: high-priority这种配置定义了一个机器学习训练队列,预留100核CPU、500GB内存和20块GPU,要求分布式训练任务至少包含2个参数服务器和6个工作节点。Kurator会自动将这些任务调度到具有足够GPU资源的集群,如果单个集群资源不足,会触发跨集群任务拆分。
6.3 深度学习任务调度实战
在实际AI训练场景中,资源效率和训练速度是关键指标。Kurator结合Volcano和Karmada,实现了智能的分布式训练任务调度。以下示例展示了如何配置PyTorch分布式训练作业,利用多个集群的GPU资源:
yaml
apiVersion: batch.volcano.sh/v1alpha1
kind: Job
meta
name: image-classification-training
spec:
minAvailable: 16
schedulerName: volcano
plugins:
ssh: ""
env: []
svc: []
queue: ml-training-queue
tasks:
- replicas: 2
name: ps
template:
spec:
containers:
- image: pytorch-training:1.10-cuda11.3
name: pytorch
command: ["/bin/sh", "-c"]
args:
- |
python -m torch.distributed.run \
--nnodes=$WORLD_SIZE \
--node_rank=$RANK \
--nproc_per_node=8 \
--master_addr=$MASTER_ADDR \
--master_port=$MASTER_PORT \
train.py --model=resnet50 --data-dir=/data
resources:
limits:
cpu: "8"
memory: 64Gi
- replicas: 14
name: worker
policies:
- event: TaskCompleted
action: CompleteJob
template:
spec:
containers:
- image: pytorch-training:1.10-cuda11.3
name: pytorch
command: ["/bin/sh", "-c"]
args:
- |
python -m torch.distributed.run \
--nnodes=$WORLD_SIZE \
--node_rank=$RANK \
--nproc_per_node=8 \
--master_addr=$MASTER_ADDR \
--master_port=$MASTER_PORT \
train.py --model=resnet50 --data-dir=/data
resources:
limits:
cpu: "8"
memory: 64Gi
nvidia.com/gpu: 8
nodeSelector:
kurator.dev/accelerator: nvidia-tesla-v100Kurator会自动处理跨集群网络配置、数据同步和故障恢复。如果某个集群的训练任务失败,系统会尝试在其他集群重新调度,同时保持整体训练进度。这种弹性设计大幅提高了大规模训练任务的成功率和资源利用率。
7. Kurator未来发展方向
7.1 分布式云原生技术趋势
随着企业数字化转型深入,分布式云原生技术将向三个方向演进:边缘智能化、跨云自治和可持续计算。边缘设备将具备更强的本地决策能力,减少对中心云的依赖;多云管理将从"集中控制"转向"分布式自治",各环境在保持策略一致的同时具有更大的自主权;计算资源优化将从成本导向转向碳足迹导向,支持绿色计算。
Kurator作为开源平台,需要在这些趋势中发挥引领作用。建议加强边缘AI推理框架集成,如TensorFlow Lite和ONNX Runtime;发展去中心化策略引擎,支持基于区块链的策略验证;增加碳感知调度能力,根据区域电网碳强度动态调整工作负载分布。
7.2 Kurator技术路线图
Kurator的未来发展应聚焦于三个核心维度:增强核心能力、扩展生态系统和提升用户体验。在核心能力方面,需要加强多集群状态一致性保障、混合工作负载调度优化和零信任安全架构;在生态系统方面,应深化与CNCF项目集成,特别是Service Mesh Interface (SMI)、OpenTelemetry和Crossplane;在用户体验方面,需要提供更直观的可视化界面、更智能的故障诊断工具和更丰富的参考架构。
具体技术路线建议包括:
- 实现跨集群服务网格统一管理,打通Istio多集群部署
- 增强GitOps能力,支持多环境渐进式交付和自动回滚
- 开发AI驱动的资源预测和自动扩缩容
- 构建统一的可观测性平台,整合指标、日志和追踪
- 支持更多边缘硬件平台,包括ARM64、RISC-V和专用AI加速器
7.3 企业数字转型建议
企业在采用Kurator等分布式云原生平台时,应遵循"平台先行、应用跟随"的策略。首先建立统一的基础设施平台,定义清晰的治理策略和安全标准,然后逐步迁移应用。建议采用"双模IT"架构:核心系统保持稳定,创新业务快速迭代。
组织能力建设同样重要。企业需要培养"全栈云原生工程师",他们既懂应用开发,又了解基础设施;既掌握云技术,又理解业务需求。建议设立专门的平台工程团队,负责Kurator平台的运维和优化,让业务团队专注于价值创造。
最后,分布式云原生不仅是技术变革,更是文化变革。企业需要建立"平台即产品"思维,将内部平台视为产品,关注内部用户的体验和反馈。通过度量平台的采用率、用户满意度和业务价值,持续改进平台能力,真正实现技术驱动业务创新的目标。
结语
Kurator代表了分布式云原生技术的最新发展方向,它通过整合最佳开源项目,为企业提供统一、灵活、可扩展的多云管理平台。从本文的架构解析到实战案例,我们可以看到Kurator如何解决企业在多云、混合云和边缘计算环境中的实际挑战。随着技术演进和生态成熟,Kurator将从基础设施管理平台发展为企业数字创新的核心引擎,推动云原生技术从"技术红利"走向"业务价值"。作为云原生从业者,我们应拥抱这种变革,不断探索技术创新与业务价值的结合点,共同构建更加智能、高效、可持续的数字未来。