在图像编辑领域,近期涌现了多款用于评估"大型多模态模型"的图生图(以图生图)能力 的数据集。这类数据集通常包含输入图像 和文本指令 (如修改要求、风格变换或增强提示等),模型需据此生成新的输出图像 ,并配套自动评估指标来衡量生成图像对文本要求的满足程度和图像质量。
1 MagicBrush 数据集
✅任务 :首个大规模人工标注 的指令引导图像编辑数据集,涵盖多种场景的单轮和多轮编辑。数据集中包含约 10,000 组三元组样本,每组包括原始图像 、编辑指令 和目标编辑后图像。指令内容多样,包括添加/删除物体、改变颜色材质、修改文字或图案,以及多轮连续编辑等。
✅公开获取:可通过 Hugging Face 平台获取。
✅自动评估指标 :MagicBrush 提供了参考输出图像,因此可使用多维指标对生成结果评估,包括:生成图与目标图像 的相似度(利用 CLIP 图像编码相似度CLIP-I及DINO特征相似度等)、编辑区域的像素级误差(L1/L2距离)以及生成图与文本指令的匹配度(利用CLIP计算图文对齐得分CLIP-T)。也可以人工或大模型评价,以衡量模型在用户角度的编辑有效性。
✅引用情况:作为通用图像编辑评测基准,已用于评估多种图像编辑模型的性能;Meta的Emu Edit基准也直接利用了MagicBrush的多样真实图像作为基础评测素材之一。

📊 MagicBrush 提供了多轮和单轮的图像编辑示例。左侧展示多轮编辑:从原始图像开始,模型按序执行指令(如"背景换成县集市"、"戴牛仔帽"、"衬衫改成格子"),逐步得到最终图像;右侧为单轮编辑示例,每条指令直接生成对应输出。体现了复杂连续编辑和单步精细编辑场景下对模型的评估能力。
2 Emu Edit 测试集(Meta 2023)
✅任务 :Meta推出的精确图像编辑模型评测数据集,专注于指令驱动的图像局部编辑 。测试集中定义了七大类常见编辑操作,包括背景替换、整体场景改变、风格转换、对象移除、对象添加、局部属性修改以及颜色/纹理改变等。每个样本包含一个输入图像 和一条编辑指令 ,模型需生成满足指令要求的输出图像。为了便于评估,每个样本还附带了输入图像描述 和期望输出图像描述,用于对比模型输出与期望目标之间的匹配程度。
✅公开获取:可通过 Hugging Face 平台获取。
✅自动评估指标 :Emu Edit提供了人工验证过的输入输出描述 ,方便使用自动指标评估模型生成质量。例如,论文中采用了与MagicBrush类似的CLIP向量方向匹配分 评估编辑效果是否符合文本意图,及CLIP图像相似度和DINO特征相似度评估输出图像对原图/目标的保真度;还计算了局部像素差异 (如L1误差)来衡量模型是否只修改了指令相关区域。通过对比这些指标,Emu Edit注重严格按指令修改指定内容且不损坏无关区域的能力。
✅引用情况 :Emu Edit测试集由Meta提出,作为其基础模型Emu在图像编辑方面能力的评估基准。正成为业界衡量精细指令图像编辑能力的新标准之一。
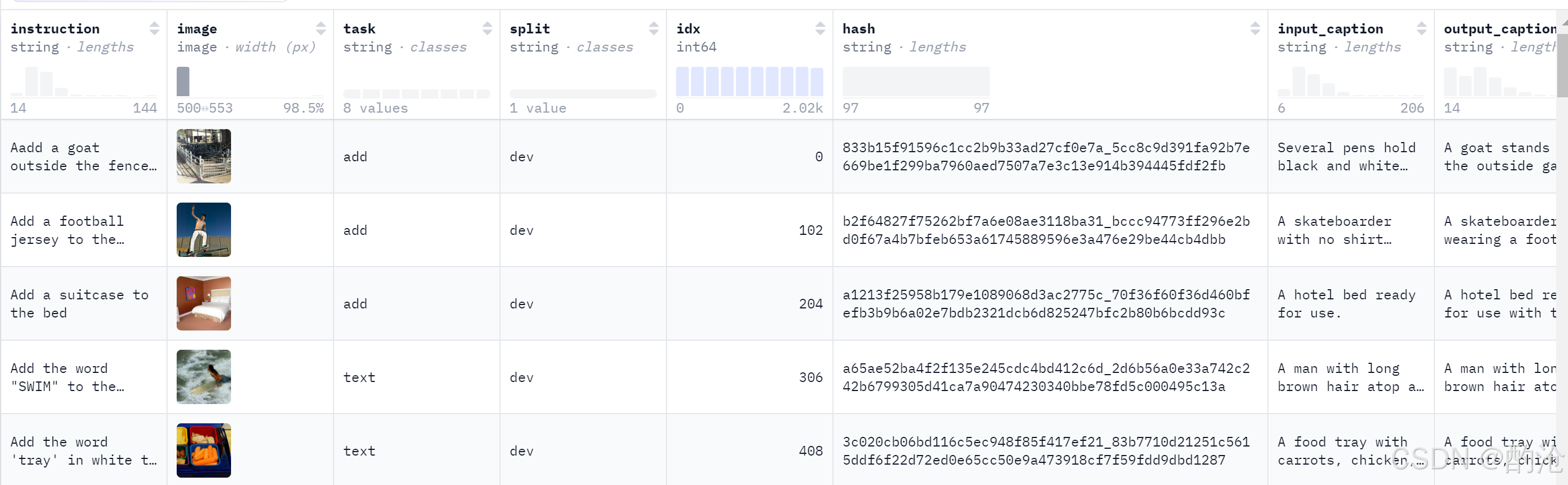
📊 Emu Edit从 MagicBrush 图像中精选样本,并为每张图像创建了七种典型编辑任务的指令,如背景更改、风格迁移、添加/移除对象等。测试集中无人工"正确答案"图像,而是用于比较模型输出质量,通常采用CLIP Score、DINO 特征距离等自动指标评估编辑是否准确,以及非目标区域是否完好。
3 TEdBench 数据集
✅任务 :TEdBench由谷歌团队在"Imagic"方法中引入,用于评测文本引导的真实图像编辑 性能。该基准非常精简,包含 100 对图像及对应编辑描述。每个样本包括:一张原始输入图像 、一段目标编辑文本描述 ,以及由Imagic模型生成的示例编辑结果 图像。这些文本描述通常涉及复杂的非刚性编辑(如"让一只山羊跳过一只猫"这类富有挑战性的合成场景)。
✅公开获取:通过 Hugging Face 等平台公开。
✅评估方法 :由于TEdBench没有"标准答案"图像,评估主要依赖模型间对比 和人类评价 。研究中常用CLIP等预训练模型计算生成图与文本描述的相似度 作为参考指标,并通过人工偏好测试判断哪种方法更好地满足了编辑指令。
✅应用情况 :TEdBench作为一个小型但具有挑战性的评测集,被用于验证扩散模型在复杂文本编辑下的能力边界。
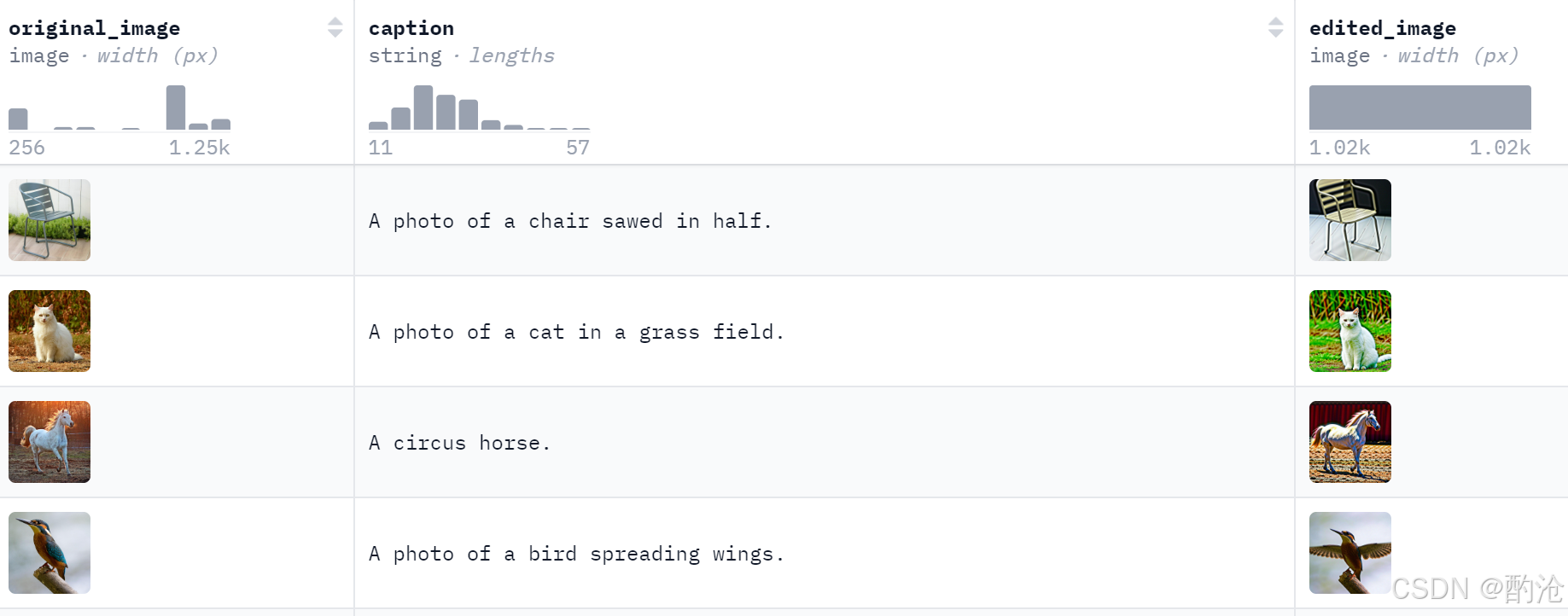
📊 TEdBench 提供了少量高难度的真实图像编辑样本,每个样本都需要模型根据文本执行复杂修改。数据集中文本指令涉及姿态变化、多物体处理等真实场景需求,超出了简单风格迁移或物体替换。
4 EditBench 数据集
✅任务 : EditBench是谷歌提出的文本引导图像填充 评测数据集。它专注于场景中局部区域的文本指导修改 ,提供了 240 张高质量图像及相应编辑任务。其中120张为生成的合成图像(来自Parti等模型),120张为真实世界照片。每个样本包含:(1) 一张带有遮罩区域 的输入图;(2) 一条针对该遮罩区域的文本修改指令 ;(3) 一张由人或高质量模型生成的期望输出图像,作为评估参考。这些指令精心设计,涵盖细粒度的属性(颜色、形状、数量等)、物体类别(常见或稀有物体、文字等)以及场景类型(室内、室外、写实或绘画风格)等三大类编辑情形,以全面测试模型性能。
✅评估指标 : 强调多维度细粒度 评价模型的编辑能力。具体而言,研究者针对每一类别的编辑设计了分层的语义指标 :例如评估模型是否准确修改了指定属性、有没有引入额外变化、场景一致性是否保持等。同时,EditBench非常重视文本指令的忠实程度 ,即输出图像与输入文本在局部修改上的精准对齐,同时确保整体图像质量不下降。论文中引入了一系列自动度量(如基于分割检测的修改正确性、图文对齐得分等)来细化评价,并通过人眼验证这些度量的有效性。
✅公开获取: 随Imagen Editor论文发布。谷歌提供了数据获取途径和评价代码(例如通过其研究官网或CVPR提供的项目页面)。
✅引用情况 : 作为谷歌Imagen Editor 方法的评测基准,为局部区域的文字引导编辑建立了严格的评测标准。

📊 EditBench 数据集侧重遮罩区域的精确编辑。如图所示,模型依次对左图中狗应用了多轮遮罩编辑:首先根据提示在狗身上添加红色太空服(左二图),接着在右侧地面添加纸板火箭(右二图),最后在狗头上加入蓝色耳机(右一图)。每一步都仅修改选定区域,其余内容完好无损。
5 I2EBench基准
✅任务 :I2EBench专门用于自动评估 各类指令驱动图像编辑模型 。该基准收集了 2000+ 张代表性图像和对应 4000+ 条多样化编辑指令(平均每张图像2条不同表述的指令)。指令涵盖从简单修改到复杂描述的广泛范围,确保对模型理解和编辑能力的全面考察。与数据集一起,I2EBench还汇总了多个现有编辑模型在这些指令下生成的编辑结果图像 ,并提供了人工标注的评价信息。
✅评估指标 :定义了多达 16 项 评价维度,涵盖高层语义 和低层次视觉质量两个方面,对每个模型的编辑结果进行全面诊断。高层次维度包括如"指令遵循程度"、"编辑正确性"、"内容一致性"等,低层维度则考虑"图像清晰度"、"无失真和无碍观感程度"等。例如,它既评价编辑后图像与指令描述在语义上的契合度,也评估图像是否出现模糊/伪影等低级质量问题。
✅公开获取:开源项目托管在GitHub上。
✅引用情况 :提供了衡量模型在理解指令、编辑质量和细节保留等方面的统一标准,有助于指导这些模型的开发和调优。
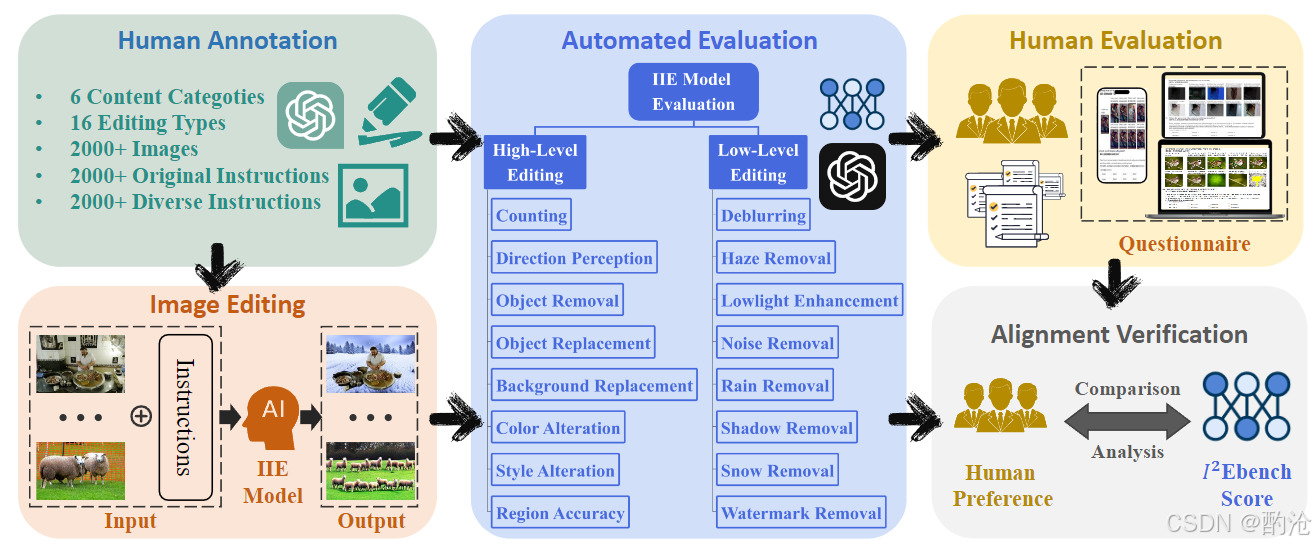
📊 I²EBench 的流程涵盖数据收集、模型生成、自动评估和人类校准四个环节。如图所示:左上为人工标注阶段,从公共数据集中筛选图像并撰写原始指令,再经ChatGPT生成多样化改写,保证指令丰富度;左下为图像编辑阶段,不同模型根据指令对输入图像进行编辑;右上为自动评估阶段,对每个模型输出从高低层维度打分;右下为人工评价阶段,收集用户偏好并验证自动评分与人类判断的一致性。最终比较分析模型优劣,生成 I²EBench 综合评分。
6 ImgEdit数据集与Bench
✅任务 :ImgEdit 是由腾讯AI Lab等提出的新框架,包含大规模图像编辑数据集 和相应的评测套件 。构建了一个超过 120万 对高质量图像编辑样本的数据集(涵盖10种典型编辑操作,每条样本含原始图、指令和编辑后图像),以及约 11万 组多轮交互编辑样本(最多5轮对同一图像的连续指令编辑)。
✅评估指标 :提出了三级难度 的评测套件:(1) 基础单轮编辑集,考查模型对指令的执行、编辑质量和细节保留等基本能力;(2) 升级单轮编辑集,引入更复杂的场景(如需要空间推理、多目标同时编辑等)来挑战模型理解与定位能力;(3) 多轮编辑集,用于评测模型的跨轮记忆 、上下文理解 以及版本回溯 能力。评测使用多个维度指标,重点关注指令遵循度 、编辑效果质量 以及原有内容保留 三方面。例如,在指令遵循度上观察模型是否确切完成用户要求;在编辑质量上通过CLIPScore等衡量图文匹配和Inception Score/FID衡量图像真实感;在细节保留上利用图像对比度量未指示区域的保持情况等。引入了人工偏好对齐的评分模型"ImgEdit-Judge",该模型经GPT-4大量评判数据微调,能够自动给出与人类评价高度一致的评分。
✅公开获取:将随论文正式发表而开源。
✅引用情况 :ImgEdit框架在提出时,就拿GPT-4V和谷歌Gemini等闭源模型作为对比标杆。
7 EditVal 基准
✅任务 :EditVal是专为扩散模型驱动的文本图像编辑 设计的标准化评测基准。它包含一个精心整理的图像集,每张图像关联若干可编辑属性(分属 13 类常见编辑类型,例如颜色变化、风格替换、增加或移除对象、空间位置调整等)。针对每张图像的每种属性,提供一条对应的文本编辑指令 ,模型需据此生成修改后的图像。EditVal还定义了一套自动评估流程 :利用预训练的视觉-语言模型(如CLIP等)对模型输出进行分析,根据不同编辑类型计算生成图的保真度 和匹配度分数。例如,对于"改变物体颜色"这类编辑,评估管线会检测输出图中的颜色是否符合指令要求;对于"移除物体"则评估背景是否合理填充且不存在原物体痕迹,等等。
✅评估指标 :EditVal的自动评估主要依赖预训练模型的嵌入匹配 和属性分类 。它针对每种编辑定义了专项指标,以确保评价有针对性 且公平。
✅公开获取:EGitHub网站已经上线评测工具,并计划开放数据集供同行使用。
✅引用情况 :为图生图模型的评测提供了高信度的自动方案。

📊 EditVal示例,原始图像中包含红苹果与橙子,指令要求将苹果修改为橙子。模型理想输出:所有原本为苹果的部分都成功变为橙色橘子,同时背景和其他元素完好无损。
8 Reason-Edit 数据集
✅任务 :Reason-Edit是专门用于评估复杂指令场景 的微型数据集,由腾讯ARC Lab构建。它包含仅 219 组"图像-指令"对,每条指令都涉及复杂理解或推理 。例如,有的指令需要模型识别并修改多个目标中的一个特定对象及其属性,或需要利用常识推理找到要编辑的对象(如"将能报时的物件改成...",需要先识别钟表)。这些场景超出了简单编辑范畴,旨在测试模型在复杂理解 (多对象、多属性指令)和复杂推理(需要外部知识判断)的能力。
✅评估指标 :由于此数据集重点在考察模型对复杂指令的正确执行 ,评估主要通过人工评价指标进行。
✅引用情况:主要被SmartEdit用于展示自身改进效果。未来的评测可以针对模型薄弱环节(复杂逻辑、跨对象等)建立类似"小而难"的测试集。

📊 Reason-Edit 示例展示了多个复杂指令的前后对比。每组左图为原图,右图为目标编辑结果,红色文字标注指令中的关键推理要素。例如顶排指令要求移除刀具("用于切水果")并改变水果种类(苹果→橙子);中排指令涉及替换动物(牛→猫,"躺在草地上");底排指令隐含添加饲喂用具(在狗前放置食盆)等。体现了隐含语义理解、多对象操作方面的评测,传统方法在此往往失败。
右图为目标编辑结果,红色文字标注指令中的关键推理要素。例如顶排指令要求移除刀具("用于切水果")并改变水果种类(苹果→橙子);中排指令涉及替换动物(牛→猫,"躺在草地上");底排指令隐含添加饲喂用具(在狗前放置食盆)等。体现了隐含语义理解、多对象操作方面的评测,传统方法在此往往失败。