本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院
在对大语言模型(LLM)进行微调时,有多种技术可选。今天我们分享一下最值得关注的 4 款工具 ------ 从单卡 到支持万亿参数的分布式集群,它们几乎覆盖了所有 LLM 微调场景,让我们看看该在什么时候用哪一个。让你一文掌握主流框架特性、性能对比与实战选型策略。
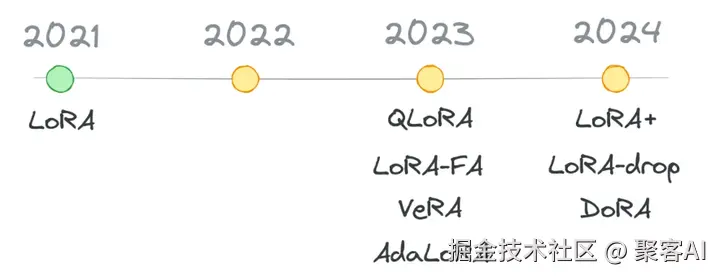
一、为什么微调工具如此关键?
大型语言模型(LLM)微调是模型适配业务场景的核心手段,但面临三大挑战:
- 计算资源瓶颈:全量微调千亿模型需数百张GPU
- 技术复杂度:分布式训练、显存优化、量化等技术耦合
- 迭代效率:实验周期长,参数调整成本高
>>> 解决方案分层: 根据资源规模与技术需求选择工具👇
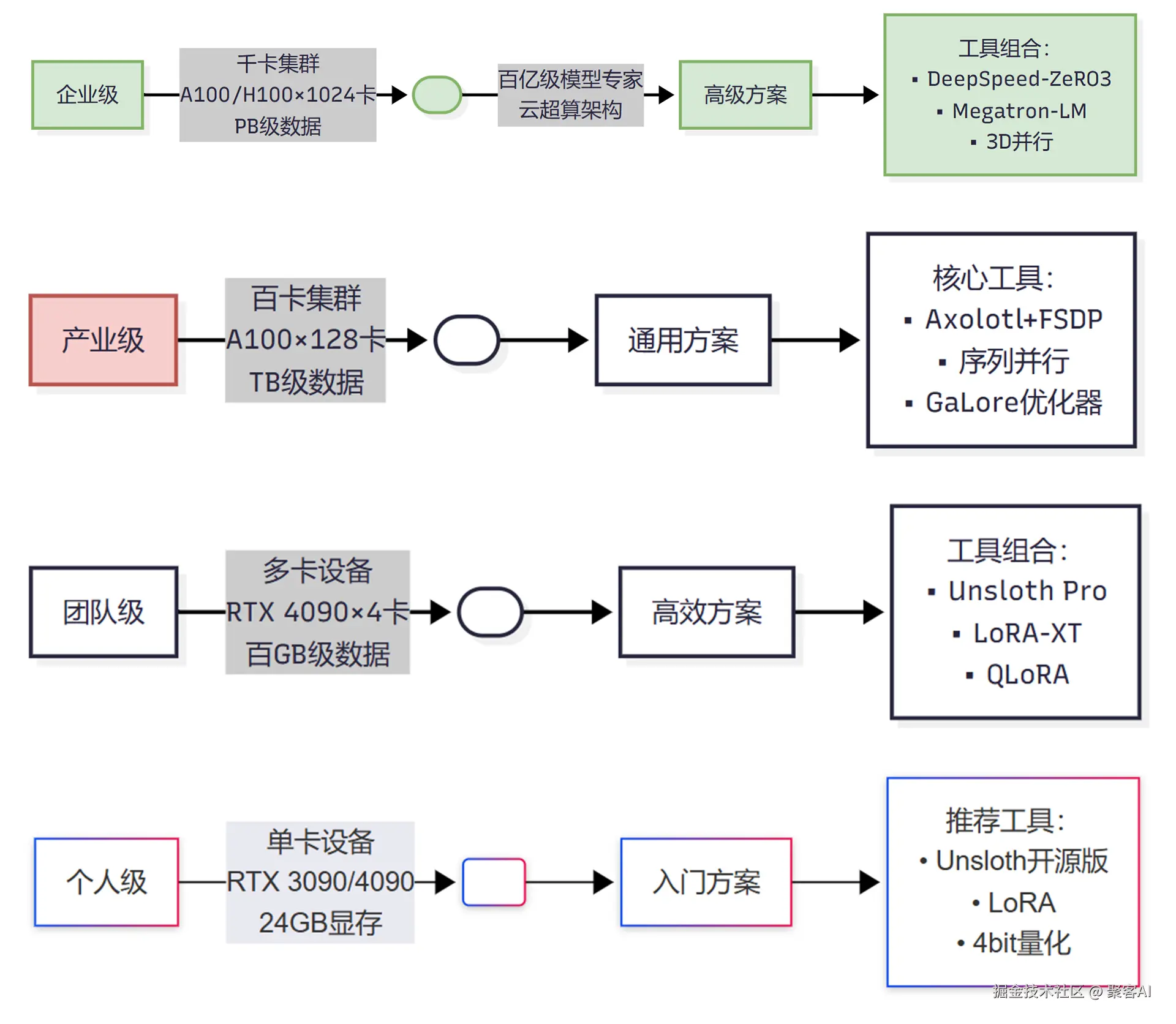
二、四大工具深度解析
1. Unsloth:个人开发者的极速实验利器
技术内核:
- 定制Triton内核:CUDA操作优化,相比HuggingFace提速2倍
- 动态显存管理:QLoRA训练时显存占用降低80%(实测RTX 3090可微调Llama2-13B)
- 多模态支持:扩展至Whisper语音模型、Stable Diffusion
典型工作流:
ini
from unsloth import FastLanguageModel
model, tokenizer = FastLanguageModel.from_pretrained("unsloth/llama-2-7b")
model = FastLanguageModel.get_peft_model(model, r=16, target_modules=["q_proj","k_proj","v_proj"])
# 自动启用梯度检查点+4bit量化
trainer = UnslothTrainer(model=model, train_dataset=dataset, max_seq_length=2048)
trainer.train()适用场景:
✔ 个人研究者单卡实验
✔ 教育领域快速原型验证
2. Axolotl:标准化生产的瑞士军刀
革命性设计:
yaml
# axolotl.yaml 配置示例
base_model: meta-llama/Llama-2-7b-hf
dataset:
- path: my_data.jsonl
type: completion
trainer:
batch_size: 8
optimizer: adamw_bnb_8bit
lora_r: 64
modules_to_save: [embed_tokens, lm_head] # 部分全参数更新核心优势:
-
全流程封装:数据预处理→训练→导出→部署
-
高级训练技术:
-
序列并行(Sequence Parallelism)突破长文本限制
-
GaLore优化器:降低95%的优化器状态显存
-
多数据打包(Data Packing)提升30%吞吐量
企业级部署:
支持Kubernetes集成,实现云原生训练
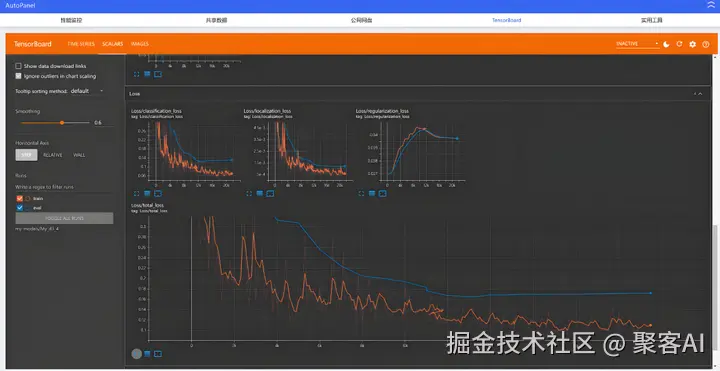 训练过程loss曲线
训练过程loss曲线
3. LlamaFactory:零代码可视化工厂
技术架构:
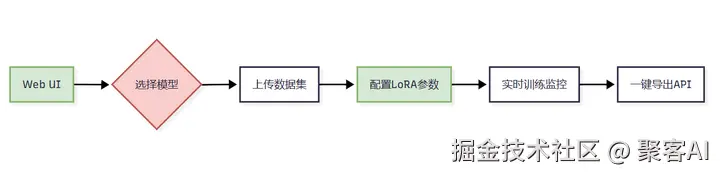
突破性功能:
- 动态LoRA(DoRA):权重分解技术,微调效果逼近全参训练
- 长文本优化:LongLoRA支持128K上下文微调
- 即插即用部署: docker run -p 8000:8000 llama-factory --api-style=openai
适用场景:
✔ 算法工程师快速验证
✔ 教育机构无代码教学
4. DeepSpeed:万亿模型的核武器
核心技术矩阵:
| 技术 | 作用 | 效果实例 |
|---|---|---|
| ZeRO-3 | 显存优化 | 170B模型训练显存降低8倍 |
| 3D并行 | 数据/模型/流水线并行 | 万亿参数千卡扩展效率92% |
| MoE训练 | 稀疏激活专家网络 | 推理速度提升5倍 |
| ZeroQuant FP8 | 低精度量化 | 精度损失<0.5% |
企业级实践:
css
# deepspeed 启动配置
deepspeed --num_gpus 128 train.py \
--deepspeed_config ds_config.json \
--tensor_parallel_size 16 \
--pipeline_parallel_size 8三、关键性能对比
| 工具 | 最小GPU要求 | 最大支持规模 | 训练速度 | 学习曲线 | 典型用户 |
|---|---|---|---|---|---|
| Unsloth | RTX 3060 | 70B QLoRA | ⚡⚡⚡⚡ | 简单 | 个人开发者 |
| Axolotl | A10G*2 | 700B FSDP | ⚡⚡⚡ | 中等 | 中型实验室 |
| LlamaFactory | V100 | 13B Full | ⚡⚡ | 极易 | 教育/产品经理 |
| DeepSpeed | A100 * 8 | 1T+ | ⚡⚡⚡⚡ | 陡峭 | 超算中心 |
四、选型决策树
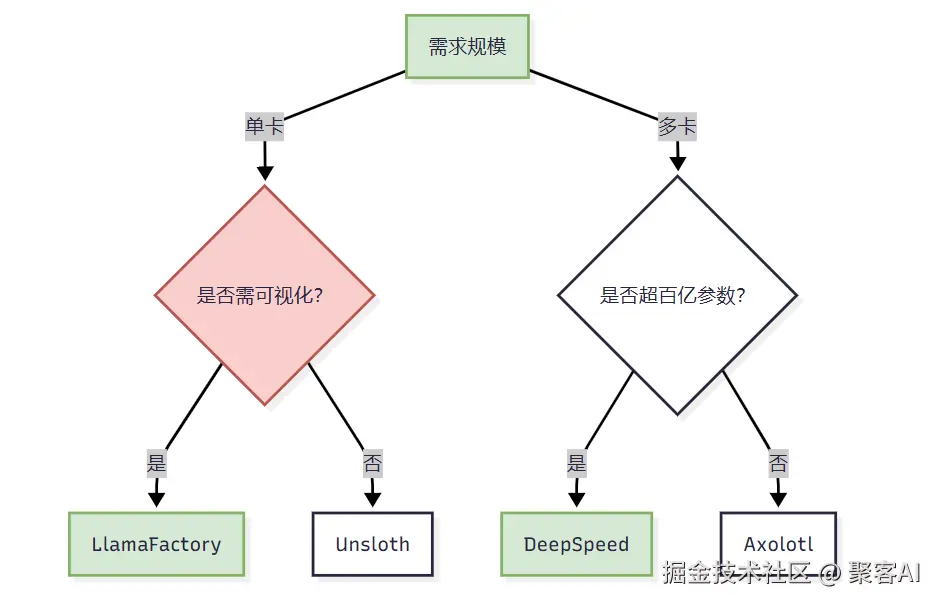
组合策略推荐:
- 快速原型:Unsloth + Google Colab Pro
- 中型项目:Axolotl + AWS p4d实例
- 生产部署:LlamaFactory API + vLLM推理优化
- 巨量模型:DeepSpeed + Megatron-LM混合并行
五、分享几个学习资源
- Unsloth (42k stars)(github.com/unslothai/u...)
Unsloth 让微调变得又快又简单,只需一个 Colab 或 Kaggle 笔记本,就能把中端 GPU 变成训练利器。
- Triton 内核:速度提升 2×,显存占用减少最高 80%
- 支持 LoRA / QLoRA / 全量微调(4/8/16 位)
- 文本、语音、扩散模型、BERT------几乎什么都能跑
- 兼容任何 CUDA-7.0+ NVIDIA GPU
适用人群:适合用 12--24 GB GPU 的个人或小团队,想快速做 LoRA 实验,又不想折腾 DeepSpeed 配置或集群。
- Axolotl (10k stars)(github.com/axolotl-ai-...)
Axolotl 把整个训练流程放进一个 YAML 文件里------写一次,数据准备到模型部署全能复用。
- 支持全量微调 / LoRA / QLoRA / GPTQ / RL / 偏好微调
- 内置 FlashAttn、XFormers、多数据打包、序列并行
- 支持从笔记本到集群的弹性扩展(FSDP、DeepSpeed、Ray)
- 提供现成的 Docker 镜像和 PyPI 包
适用人群:追求可重复性、喜欢用 YAML 开关切换高级配方的团队。
- LlamaFactory (54k stars)(github.com/hiyouga/LLa...)
LlamaFactory 提供易用的网页界面进行模型微调------像向导一样一步步操作,可实时查看训练,并一键部署。 完全 零代码。
- 支持 16 位、冻结微调、LoRA、低比特 QLoRA
- 集成 FlashAttn-2、LongLoRA、GaLore、DoRA
- 提供 LlamaBoard、W&B、MLflow 等可视化面板
- 一键生成 OpenAI 风格 API 或 vLLM 服务
适用人群:偏好 GUI、需要最新功能、并想要自带可视化面板的开发者。
- DeepSpeed (39k stars)(github.com/deepspeedai...)
DeepSpeed 是让集群变成"超算引擎"的核心工具,能极大加速 LLM 训练与推理。
- 支持 ZeRO、MoE、三维并行,适配万亿参数规模训练
- 定制推理内核,实现亚秒级延迟
- ZeroQuant 与 XTC 压缩,降低模型体积和成本
- 可与 Hugging Face、Lightning、MosaicML 无缝集成
适用人群:针对 100 亿以上参数模型训练,或需要高并发推理的企业与科研团队。
这里顺便再给大家分享一份大模型微调实战的思维导图,帮助大家更好的学习,粉丝朋友自行领取:《大模型微调实战项目思维导图》,好了,今天的分享就到这里,点个小红心,我们下期再见。