在当今数据爆炸的时代,企业对数据库的需求早已超越了"存储数据"的基础范畴------它们需要支撑每秒数十万次的并发请求,在全球分布式部署中保持毫秒级延迟,还要能随业务增长线性扩展,同时兼顾传统数据库的可靠性。而Aerospike,作为一款专注于"大规模、低延迟、高可靠"的分布式数据库,其架构设计正是为解决这些痛点而生。
什么是Aerospike?
Aerospike是一款专为web级分布式应用打造的数据库,其核心目标清晰而明确:
- 提供灵活可扩展的平台,支撑亿级用户规模的应用;
- 保留传统数据库的ACID可靠性,不牺牲数据一致性;
- 最小化人工干预,实现高效运维。
这些目标的实现,离不开其三层架构的精妙设计------客户端层、分布层、数据存储层,三层协同工作,既各司其职又紧密配合,共同构建了Aerospike的核心竞争力。
客户端层:让开发者专注业务,而非集群管理
作为开发者与数据库集群的"桥梁",Aerospike的客户端层堪称"减负大师"。它以开源库的形式提供,支持C、Java、Go、Python等几乎所有主流编程语言(完整列表可查看客户端下载页),让不同技术栈的团队都能轻松接入。
客户端层的核心能力:
- 直接对接集群,减少中间环节:客户端直接实现与集群的通信协议,无需通过代理节点转发请求,从源头降低延迟。
- 实时感知集群状态:它能动态跟踪集群节点的增减、配置变更,甚至能精准定位每一条数据的存储位置。当节点故障或扩容时,客户端会自动重新路由请求,开发者无需修改一行代码。
- 智能连接与重试机制:内置TCP/IP连接池提升效率,若某条命令因节点临时波动失败(未到节点宕机级别),会自动重试到数据副本所在节点,确保请求不丢失。
对开发者而言,这意味着无需手动编写数据分片、缓存策略或集群配置代码------应用无需重启,就能随集群扩缩容"自适应",极大降低了分布式系统的开发门槛。
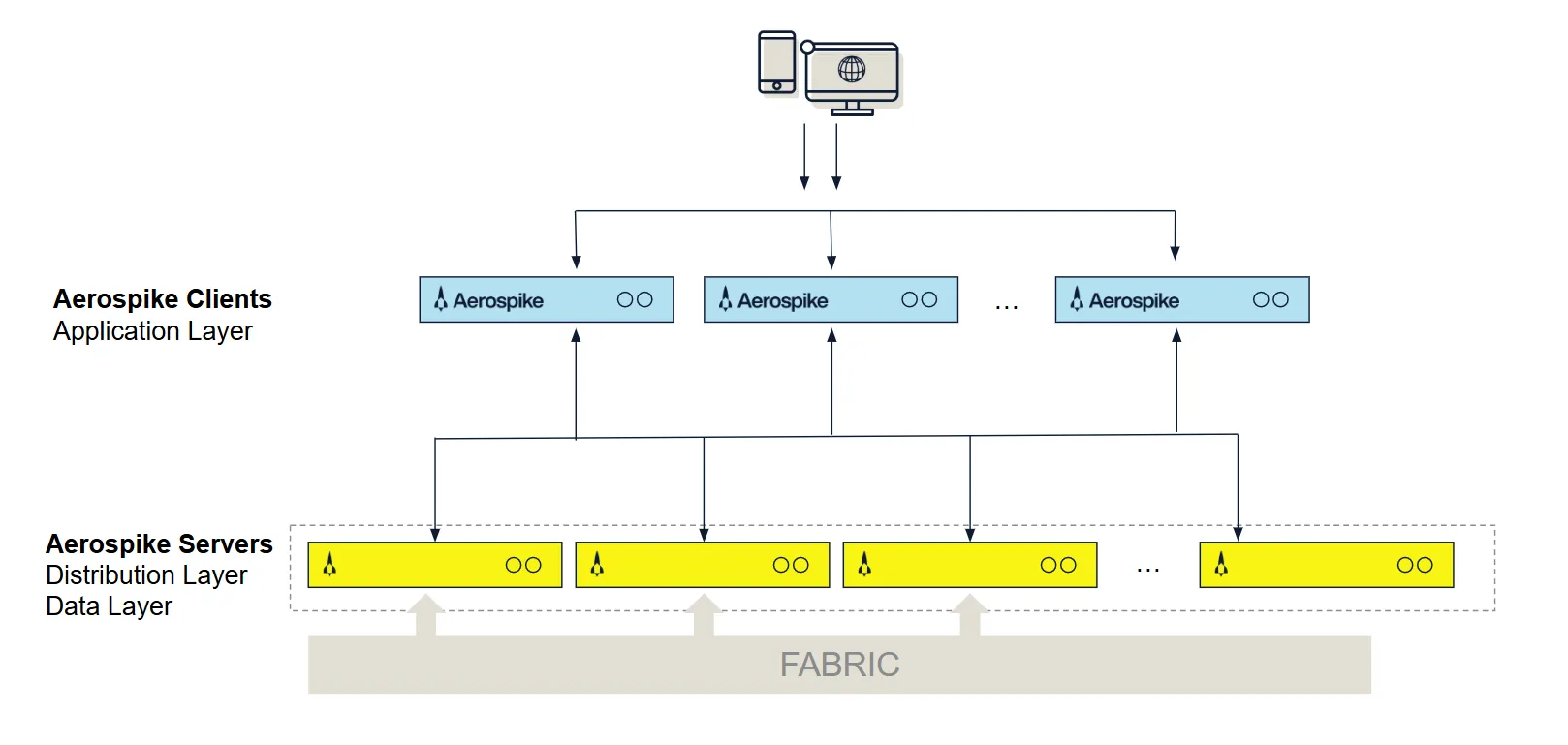
分布层:无共享架构,支撑PB级数据的线性扩展
如果说客户端层是"前端接口",那么分布层就是Aerospike的"中枢神经"。它采用"无共享(shared-nothing)"架构,每个节点独立处理数据,却能通过智能协作实现全局一致性,这也是其能从TB级轻松扩展到PB级的核心原因。
分布层的核心功能由三个模块协同实现:
1. 集群管理模块:用算法保障集群"自组织"
集群如何知道哪些节点是"自己人"?Aerospike采用了基于Paxos的gossip投票机制:节点间通过"主动+被动"心跳实时监测连接状态,再通过分布式投票确认集群成员。这种设计彻底摒弃了"主节点"依赖,即使部分节点故障,集群也能快速确认新成员,确保服务不中断。
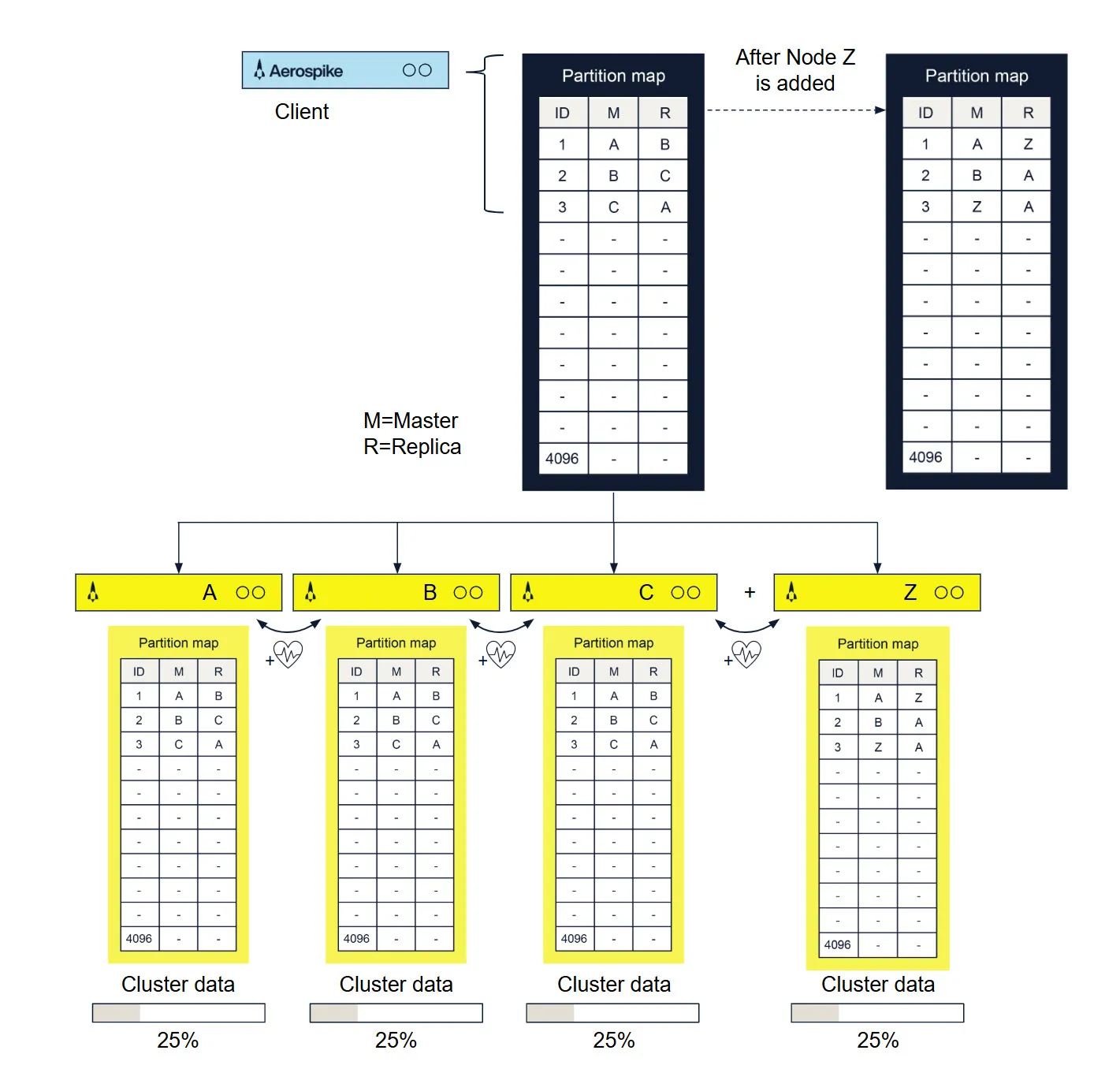
2. 数据迁移模块:数据"自动搬家",扩缩容零感知
当你给集群新增节点(或下线旧节点)时,数据如何自动"搬新家"?Aerospike的秘诀是分布式哈希算法:
- 整个数据索引空间被划分为4096个分区,每个分区通过哈希算法确定"主节点(Master)"和"副本节点(Replica)";
- 节点增减时,系统会重新计算分区归属,自动将数据迁移到新节点,确保每个节点负载均衡;
- 迁移过程中,数据会按配置的"复制因子"同步到多个节点(跨数据中心也支持),杜绝数据丢失。
更关键的是,这一过程完全自动化,无需人工配置分片规则------你只需加节点,剩下的交给数据库。
3. 事务处理模块:在分布式中坚守"可靠性"
分布式系统的一大难题是"如何在多节点间保证数据一致性",而事务处理模块正是为此而生:
- 同步/异步复制:若要求"写操作立即一致",它会先将数据同步到所有副本节点,再返回成功给客户端;
- 智能代理:集群变更时,若客户端暂时"信息滞后"发送了错误请求,模块会透明转发到正确节点,用户无感知;
- 数据冲突解决 :当集群从网络分区中恢复(如节点重启),若同一数据出现多个版本,会通过"版本号"或"最后更新时间"自动合并,避免数据混乱。
数据存储层:多模型+无模式,兼顾性能与成本
数据最终存在哪里?Aerospike的存储层用"灵活"和"高效"重新定义了分布式存储:
1. 多模型+无模式:适配复杂业务场景
Aerospike是典型的"多模型数据库",支持键值、文档、图等多种数据结构,且采用"无模式(schemaless)"设计:
- 命名空间(Namespace):类似传统数据库的"数据库",用于隔离不同业务数据;
- 集合(Set):类似"表",但无需预定义结构;
- 记录(Record):类似"行",每条记录有唯一索引键;
- Bin:类似"列",但无需提前声明------想新增一个字段?应用直接写入即可,无需修改 schema。
这种设计让数据库能轻松应对业务快速迭代(比如电商突然新增"优惠券"字段),尤其适合互联网场景。
2. 存储优化:速度与成本的完美平衡
Aerospike的存储层对硬件的利用堪称"极致":
- 索引优先存DRAM:主键索引和二级索引默认存在DRAM中,确保毫秒级查询;也可配置到持久内存(PMem)或NVMe闪存,平衡性能与成本;
- 数据存储灵活选:小数据可存在DRAM加速访问,大数据可存在SSD降低成本,且每个命名空间可独立配置(比如"用户会话"存DRAM,"历史订单"存SSD);
- 闪存友好设计:绕过传统文件系统(为机械硬盘优化),采用日志结构文件系统,大区块写入减少SSD磨损;内置碎片整理器自动回收低效存储块,确保闪存长期高效运行。
一个直观的数据:10亿条记录的索引,全集群仅需64GiB存储空间------这意味着用普通服务器就能支撑超大规模数据。
3. 数据安全双保险:碎片整理与逐出机制
为避免存储资源耗尽,Aerospike内置两大"管家":
- 碎片整理器:跟踪每个存储块的活跃记录占比,自动回收低利用率块,确保存储空间不浪费;
- 逐出器:当内存/磁盘使用率超过阈值时,自动删除过期记录(过期时间按命名空间配置),也支持应用指定"永不逐出"的核心数据。
为什么选择Aerospike?
从架构设计到实际落地,Aerospike的每一个细节都指向"web级应用"的核心需求:
- 低延迟:客户端直接访问数据节点、索引存DRAM、闪存优化,确保毫秒级响应;
- 高扩展:无共享架构+自动数据迁移,从3节点到100节点线性扩展,性能随节点数同比提升;
- 高可靠:多副本复制、跨数据中心同步(XDR)、自动故障转移,满足金融级可用性;
- 易运维:无需预定义schema、集群自动管理、动态配置更新,大幅降低DBA工作量。
无论是支撑电商平台的秒杀活动(高并发+低延迟),还是金融系统的全球分布式交易(一致性+灾备),亦或是物联网的海量设备数据存储(高扩展+低成本),Aerospike都凭借其独特的架构设计,成为web级分布式应用的理想数据库选择。
如果你正为数据规模增长快、延迟要求高、运维成本大 的问题困扰,Aerospike或许正是那个能让你既放心扩展,又省心运维的答案。