温馨提示:
本篇文章已同步至"AI专题精讲 " InstructBLIP:通过指令微调迈向通用视觉-语言模型
摘要
大规模预训练和指令微调在构建通用语言模型方面取得了显著成功。然而,构建通用视觉-语言模型仍然面临挑战,这主要源于由于视觉输入所带来的丰富输入分布和任务多样性。尽管视觉-语言预训练已经被广泛研究,视觉-语言指令微调仍然是一个未被充分探索的方向。本文基于预训练的 BLIP-2 模型,对视觉-语言指令微调进行了系统且全面的研究。我们收集了 26 个公开数据集,涵盖了广泛的任务和能力,并将它们转换为指令微调格式。此外,我们引入了一种感知指令的 Query Transformer,该模块可根据给定的指令提取更具信息性的特征。在 13 个训练数据集上训练后,InstructBLIP 在所有 13 个未见数据集上实现了最先进的零样本性能,显著优于 BLIP-2 以及更大规模的 Flamingo 模型。我们的模型在单个下游任务上微调后也达到了 SOTA 性能(例如在包含图像上下文的 ScienceQA 问题上达到 90.7% 的准确率)。此外,我们通过定性分析展示了 InstructBLIP 相较于当前多模态模型的优势。所有 InstructBLIP 模型均已开源。
1 引言
人工智能研究的长期目标之一是构建一个能够解决任意用户指定任务的通用模型。在自然语言处理(NLP)领域,指令微调46, 7 已被证明是实现该目标的一种有前景的方法。通过在由自然语言指令描述的多种任务上微调大型语言模型(LLM),指令微调使模型能够遵循任意指令。最近,指令微调后的 LLM 也开始被应用于视觉-语言任务。例如,BLIP-2 20 能够有效地适配冻结的指令微调 LLM 来理解视觉输入,并在图像到文本生成任务中展现出初步的指令遵循能力。
与 NLP 任务相比,视觉-语言任务由于包含来自不同领域的视觉输入而更加多样化。这对统一模型的泛化能力提出了更高要求,尤其是在面对训练过程中未见的多样化视觉-语言任务时。以往的相关工作大致可以分为两类:第一类是多任务学习方法 6, 27,它将各种视觉-语言任务统一转化为相同的输入-输出格式。但我们实证发现,缺乏指令的多任务学习方法(见表4)在泛化到未见数据集和任务时表现不佳。第二类方法 20, 4 则是在预训练 LLM 的基础上引入额外视觉模块,并使用图像描述数据对视觉模块进行训练。然而,这类数据过于有限,难以支持对需要超出视觉描述能力的视觉-语言任务的广泛泛化。

为了解决上述挑战,本文提出了 InstructBLIP,一个视觉-语言指令微调框架,使通用模型能够通过统一的自然语言接口解决各种视觉-语言任务。InstructBLIP 利用多样化的指令数据对多模态 LLM 进行训练。具体而言,我们以预训练的 BLIP-2 模型作为起点,该模型由图像编码器、LLM 和一个连接两者的 Query Transformer(Q-Former)组成。在指令微调过程中,我们仅对 Q-Former 进行微调,图像编码器和 LLM 保持冻结状态。
本文的主要贡献如下:
- 我们对视觉-语言指令微调进行了全面系统的研究。我们将 26 个数据集转化为指令微调格式,并划分为 11 个任务类别。使用其中 13 个数据集进行训练,其余 13 个数据集用于零样本评估。此外,我们还保留了 4 个完整任务类别用于任务级别的零样本评估。详尽的定量与定性实验结果展示了 InstructBLIP 在视觉-语言零样本泛化方面的有效性。
- 我们提出了感知指令的视觉特征提取机制,这是一种新的机制,能够根据给定指令灵活地提取信息性特征。具体来说,自然语言指令不仅被输入给冻结的 LLM,也输入给 Q-Former,从而使其能够从冻结的图像编码器中提取与指令相关的视觉特征。同时,我们提出了一种平衡采样策略,用于同步不同数据集间的学习进度。
- 我们在两类 LLM 基础上评估并开源了一系列 InstructBLIP 模型:1)FlanT5 7,一种在 T5 34 基础上微调的编码-解码型 LLM;2)Vicuna 2,一种在 LLaMA 41 基础上微调的解码器-only 型 LLM。InstructBLIP 模型在广泛的视觉-语言任务上实现了最先进的零样本性能。此外,当作为单个下游任务的初始化模型使用时,InstructBLIP 也能获得最先进的微调表现。
2 视觉-语言指令调优
InstructBLIP 旨在解决 vision-language instruction tuning 中的独特挑战,并系统性地研究模型对未见数据和任务的泛化能力提升。在本节中,我们首先介绍 instruction tuning 数据的构建方式,随后说明训练与评估协议。接下来,我们从模型和数据的角度分别阐述两种提升 instruction tuning 表现的技术。最后,我们给出实现细节。
2.1 任务与数据集
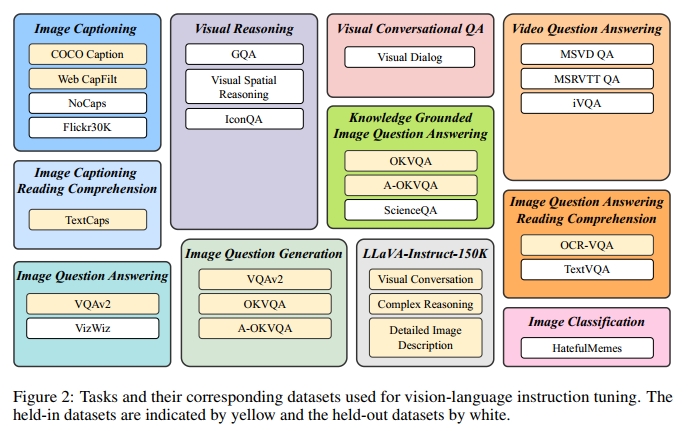
为了确保 instruction tuning 数据的多样性,同时考虑其可获取性,我们收集了一套全面的公开 vision-language 数据集,并将它们转换为 instruction tuning 格式。如图 2 所示,最终数据集合涵盖 11 类任务与 26 个数据集,包括图像描述(image captioning)23, 3, 51、带阅读理解的图像描述 38、视觉推理(visual reasoning)16, 24, 29、图像问答(image question answering)11, 12、基于知识的图像问答(knowledge-grounded image question answering)30, 36, 28、带阅读理解的图像问答 31, 39、图像问句生成(从 QA 数据集改造而来)、视频问答(video question answering)47, 49、多轮视觉问答(visual conversational question answering)8、图像分类 18 和 LLaVA-Instruct-150K 25。我们在附录 C 中提供了每个数据集的详细描述和统计信息。
针对每项任务,我们精心设计了 10 到 15 个不同的自然语言 instruction 模板。这些模板构成了 instruction tuning 数据的基础,用于明确描述任务及其目标。对于那些本身倾向于输出简短回复的公开数据集,我们在部分指令模板中加入了"简要""简短"等词汇,以降低模型始终生成短文本的过拟合风险。至于 LLaVA-Instruct-150K 数据集,由于其本身已经采用 instruction 格式,因此我们未额外添加 instruction 模板。完整的 instruction 模板列表见附录 D。
2.2 训练与评估协议
为了确保 instruction tuning 与 zero-shot 评估中有充足的数据与任务,我们将 26 个数据集划分为 13 个 held-in 数据集和 13 个 held-out 数据集,分别在图 2 中以黄色和白色标示。我们使用 held-in 数据集的训练集进行 instruction tuning,并使用其验证集或测试集进行 held-in 评估。
对于 held-out 评估,我们的目标是理解 instruction tuning 如何提升模型在未见数据上的 zero-shot 表现。我们定义两类 held-out 数据:1)模型在训练过程中未接触的某些数据集,但其任务类型已出现在 held-in 集合中;2)训练过程中完全未见的数据集及其相关任务。第一类 held-out 评估面临的主要挑战是 held-in 与 held-out 数据集之间的数据分布差异。对于第二类,我们完全舍弃若干任务,包括视觉推理(visual reasoning)、视频问答(video question answering)、多轮视觉问答(visual conversational QA)和图像分类(image classification)。
为了避免数据污染,我们在选择数据集时非常谨慎,确保不同数据集中用于评估的样本不会出现在 held-in 训练集合中。在 instruction tuning 过程中,我们混合所有 held-in 训练集,并对每个数据集均匀采样指令模板。模型使用标准的语言建模损失函数进行训练,直接根据指令生成响应。此外,对于包含场景文字(scene text)的数据集,我们在指令中加入 OCR token 作为辅助信息。
2.3 指令感知视觉特征提取
现有的 zero-shot 图像到文本生成方法(如 BLIP-2)在提取视觉特征时通常不考虑指令(instruction-agnostic),导致无论任务为何,LLM 接收的始终是一组静态的视觉表示。相比之下,instruction-aware 的视觉模型能够根据任务指令进行适应,并生成对当前任务最有利的视觉表示。当我们期望对于同一输入图像有不同的任务指令时,这种方法显然更具优势。
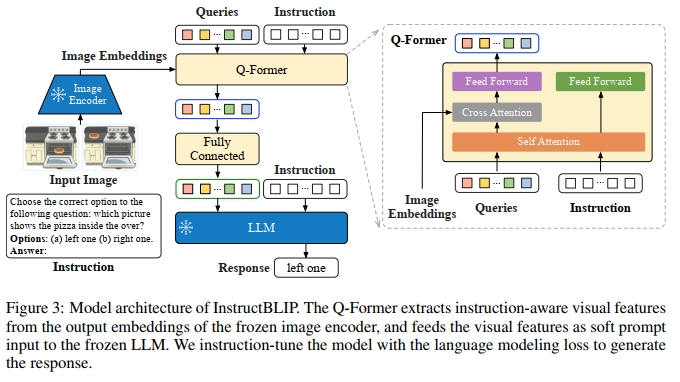
我们在图 3 中展示了 InstructBLIP 的架构。与 BLIP-2 20 类似,InstructBLIP 使用一个 Query Transformer(Q-Former)从冻结的图像编码器中提取视觉特征。Q-Former 的输入是一组可学习的 K 个查询嵌入(query embedding),它们通过交叉注意力机制与图像编码器的输出进行交互。Q-Former 的输出是一组 K 个编码后的视觉向量(每个查询嵌入对应一个向量),这些向量经过线性映射后被输入到冻结的 LLM 中。与 BLIP-2 一样,Q-Former 在 instruction tuning 之前通过两个阶段的图像-描述数据预训练完成初始化:第一阶段使用冻结的图像编码器对 Q-Former 进行 vision-language 表示学习;第二阶段将 Q-Former 的输出适配为 soft visual prompt,并输入到冻结的 LLM 中用于文本生成。在预训练完成后,我们对 Q-Former 进行 instruction tuning,此时 LLM 接收 Q-Former 输出的视觉编码与任务指令作为输入。
2.4 平衡训练数据集
在进行指令调优时,平衡训练数据集是一项重要策略。通过对不同数据集进行适当的平衡采样,可以避免某些数据集在训练过程中占主导地位,从而确保模型能够在多种任务上均衡地进行学习。这种方法特别有助于多任务学习场景,能够促进不同任务之间的相互学习,从而提升模型在各种任务上的泛化能力。
由于训练数据集数量庞大且每个数据集的规模差异显著,若均匀混合这些数据集,可能会导致模型对较小数据集过拟合,对较大数据集欠拟合。为了解决这个问题,我们提出了按照数据集大小的平方根或训练样本数量来采样数据集。一般来说,给定 D 个数据集,大小分别为 { S 1 , S 2 , ... , S D } \{ S _ { 1 } , S _ { 2 } , \ldots , S _ { D } \} {S1,S2,...,SD},从数据集 d 中选取一个数据样本的概率为:
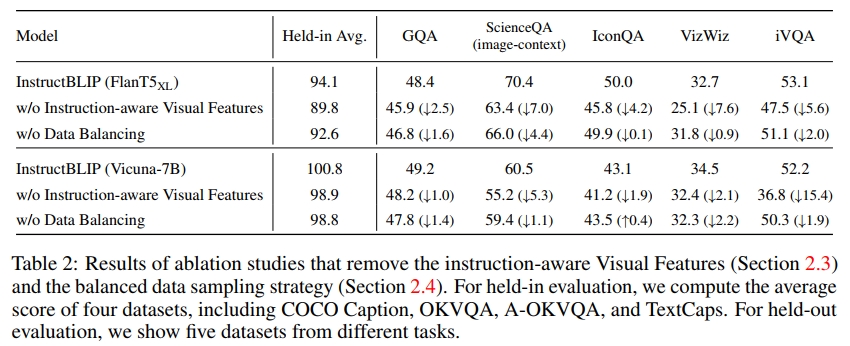
p d = S d ∑ i = 1 D S i \begin{array} { r } { p _ { d } = \frac { \sqrt { S _ { d } } } { \sum _ { i = 1 } ^ { D } \sqrt { S _ { i } } } } \end{array} pd=∑i=1DSi Sd ,在此公式的基础上,我们手动调整某些数据集的权重,以优化模型。这是由于数据集和任务之间存在固有差异,尽管它们的大小相似,但对训练强度的需求不同。具体而言,我们降低了 A-OKVQA(多项选择题)数据集的权重,并提高了 OKVQA(需要开放式文本生成)的权重。在表 2 中,我们展示了平衡数据集采样策略在 held-in 评估和 held-out 泛化任务中的整体性能提升。
2.5 Inference Methods
在推理阶段,我们根据不同数据集采用两种略有不同的生成方法进行评估。对于大多数数据集,如图像描述和开放式 VQA,我们直接提示 instruction-tuned 模型生成响应,然后与真实答案进行比较以计算评估指标。另一方面,对于分类任务和多项选择 VQA 任务,我们采用词汇排序方法,这一方法参考了之前的研究 46, 22, 21。具体来说,我们仍然提示模型生成答案,但将其词汇限制在候选列表中。接着,我们计算每个候选答案的对数似然(log-likelihood),并选择对数似然值最大的候选作为最终预测。该排序方法应用于 ScienceQA、IconQA、A-OKVQA(多项选择)、HatefulMemes、Visual Dialog、MSVD 和 MSRVTT 数据集。此外,对于二分类任务,我们将正负标签扩展为稍广泛的词汇集合,以便利用自然文本中的词频(例如,正类使用 yes 和 true,负类使用 no 和 false)。
对于视频问答任务,我们对每个视频均匀采样四帧。每帧分别通过图像编码器和 Q-Former 处理,提取的视觉特征被连接在一起,然后输入到 LLM 中。
2.6 实现细节
Architecture
得益于 BLIP-2 模块化架构设计的灵活性,我们可以迅速将模型适配到各种 LLM。在我们的实验中,我们采用了四种不同的 BLIP-2 变体,使用相同的图像编码器(ViT-g/14 10),但使用不同的冻结 LLM,包括 FlanT5-XL(3B)、FlanT5-XXL(11B)、Vicuna-7B 和 Vicuna-13B。FlanT5 7 是基于编码器-解码器 Transformer T5 34 的 instruction-tuned 模型。而 Vicuna 2 是最近发布的仅解码器 Transformer,从 LLaMA 41 上进行了 instruction-tuning。在视觉-语言 instruction tuning 过程中,我们从预训练的 BLIP-2 检查点初始化模型,并且只对 Q-Former 的参数进行微调,保持图像编码器和 LLM 不变。由于原始 BLIP-2 模型没有提供 Vicuna 的检查点,我们使用与 BLIP-2 相同的过程进行 Vicuna 的预训练。
Training and Hyper-parameters
我们使用 LAVIS 库 19 进行实现、训练和评估。所有模型均在最多 60K 步中进行 instruction-tuning,每 3K 步验证一次模型性能。对于每个模型,选择一个最佳的检查点,并用于所有数据集的评估。我们为 3B、7B 和 11/13B 模型分别采用了 192、128 和 64 的批量大小。优化器使用 AdamW 26,其中 β 1 = 0.9 , β 2 = 0.999 β_1 = 0.9,β_2 = 0.999 β1=0.9,β2=0.999,权重衰减为 0.05。此外,我们在初始的 1,000 步中应用了学习率的线性预热,从 1 0 − 8 10^{-8} 10−8 增加到 1 0 − 5 10^{-5} 10−5,然后使用余弦衰减,最低学习率为 0。所有模型在 16 台 Nvidia A100(40G)GPU 上进行训练,整个训练过程在 1.5 天内完成。
3. 实验结果与分析
3.1 Zero-shot 评估
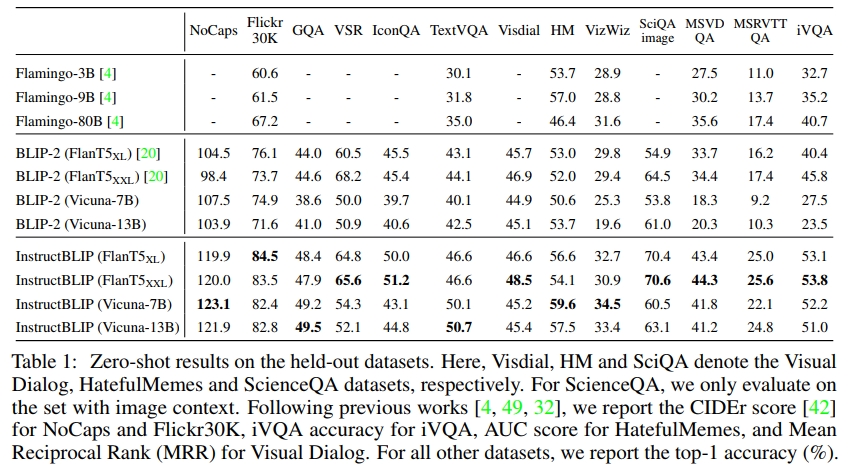
我们首先在 13 个 held-out 数据集上评估 InstructBLIP 模型,使用的指令见附录 E。我们将 InstructBLIP 与之前的 SOTA 模型 BLIP-2 和 Flamingo 进行比较。如表 1 所示,我们在所有数据集上都取得了新的零-shot SOTA 结果。InstructBLIP 在所有 LLM 上都显著超过了其原始的骨干网络 BLIP-2,展示了视觉-语言 instruction tuning 的有效性。例如,InstructBLIP FlanT5XL 相比于 BLIP-2 FlanT5XL,平均相对提升了 15.0%。
此外,instruction tuning 提升了对未见任务类别(例如视频 QA)的零-shot 泛化能力。尽管从未使用时序视频数据进行训练,InstructBLIP 在 MSRVTT-QA 数据集上仍取得了相较于之前 SOTA 最高 47.1% 的相对提升。最后,我们的最小 InstructBLIP FlanT5XL(4B 参数)在所有六个共享评估数据集上都超越了 Flamingo-80B,平均相对提升了 24.8%。
对于 Visual Dialog 数据集,我们选择报告平均倒数排名(MRR)而不是标准化折扣累积增益(NDCG)指标。这是因为 NDCG 偏向于通用且不确定的回答,而 MRR 更倾向于准确的回答32,因此 MRR 更符合零-shot 评估场景的需求。
3.2 指令调优技术的消融研究
为了研究指令感知视觉特征提取(第2.3节)和数据集平衡采样策略(第2.4节)的影响,我们在指令调优过程中进行了消融实验。如表2所示,去除视觉特征中的指令感知会显著降低所有数据集的性能。在涉及空间视觉推理(例如 ScienceQA)或时间视觉推理(例如 iVQA)的数据集上,性能下降尤为严重,因为输入到 Q-Former 的指令可以引导视觉特征关注图像中的重要区域。去除数据平衡策略会导致训练不稳定和不均匀,因为不同数据集在训练步骤上达到峰值的时机差异较大。多个数据集的进度不同步会损害整体性能。
3.3 定性评估
除了对公共基准的系统评估外,我们还进一步定性地检查了 InstructBLIP 在更多样的图像和指令上的表现。如图1所示,InstructBLIP 展现了其进行复杂视觉推理的能力。例如,它可以根据视觉场景合理推断发生了什么,并根据场景的位置推测灾难类型,基于如棕榈树等视觉证据进行外推。此外,InstructBLIP 能够将视觉输入与嵌入的文本知识相结合,并生成有信息量的响应,比如介绍一幅著名画作。更重要的是,在描述整体氛围时,InstructBLIP 展现了理解视觉图像隐喻含义的能力。最后,我们展示了 InstructBLIP 可以进行多轮对话,在生成新回应时有效考虑对话历史。
在附录B中,我们定性地将 InstructBLIP 与同时期的多模态模型(GPT-4 33、LLaVA 25、MiniGPT-4 52)进行了比较。尽管所有模型都能够生成长篇响应,但 InstructBLIP 的输出通常包含更多恰当的视觉细节,并展示了逻辑上连贯的推理步骤。更重要的是,我们认为长篇回答并非总是最优。例如,在附录的图2中,InstructBLIP 通过自适应调整响应长度直接回应用户意图,而 LLaVA 和 MiniGPT-4 则生成了冗长且不太相关的句子。InstructBLIP 的这些优势得益于多样化的指令调优数据和有效的架构设计。
3.4 指令调优 vs. 多任务学习

温馨提示:
阅读全文请访问"AI深语解构 " InstructBLIP:通过指令微调迈向通用视觉-语言模型