1.概述
在AI场景中,数据的高效处理与实时更新是推动技术突破的关键基石,而高性能的数据转换框架则是连接数据与 AI 应用的重要桥梁。CocoIndex 作为一款适用于人工智能的超高性能实时数据转换框架,凭借其独特的增量处理功能,在数据处理领域展现出显著优势。它不仅能实现数据的实时转换,更在数据新鲜度上实现了质的飞跃,为 AI 应用提供了更精准、更及时的数据支撑。那么,CocoIndex 究竟是如何通过增量处理实现这些突破,又能为 AI 领域带来哪些变革?笔者将为大家一一介绍。
2.内容
专为人工智能领域量身打造的超高性能数据转换框架 ------CocoIndex,其核心引擎采用 Rust 语言编写,从底层架构保障了卓越的运行效率与稳定性。框架自带增量处理能力与数据血缘追踪功能,开箱即可投入使用,无需额外繁琐配置。更值得一提的是,它能为开发者带来卓越的开发效率,从项目启动的第 0 天起,便具备全面的生产环境就绪能力,大幅缩短从开发到落地的周期,为 AI 应用的数据处理环节提供坚实支撑。

CocoIndex 让 AI 驱动的数据转换过程变得异常简单,同时能轻松实现源数据与目标数据的实时同步,为 AI 应用的数据流转提供高效、可靠的保障。
无论是生成嵌入向量、构建知识图谱,还是其他任何超越传统 SQL 的数据转换任务,它都能高效胜任。
仅需约 100 行 Python 代码,便能在数据流中轻松声明转换逻辑,极大降低了开发门槛,让数据转换流程的搭建高效又简单。
# import
data['content'] = flow_builder.add_source(...)
# transform
data['out'] = data['content']
.transform(...)
.transform(...)
# collect data
collector.collect(...)
# export to db, vector db, graph db ...
collector.export(...)CocoIndex 秉持数据流编程模型理念,其设计逻辑清晰且透明:每个转换操作仅依据输入字段生成新字段,全程无隐藏状态,也不存在值的突变情况。这使得转换前后的所有数据都清晰可观察,且自带数据血缘追踪功能,让数据的来龙去脉一目了然。
尤为特别的是,开发者无需通过创建、更新、删除等操作来显式改变数据,只需为源数据集定义好转换规则或公式,便能实现数据的顺畅转换,大幅简化了开发流程。
CocoIndex 为不同数据源、数据目标及各类转换需求提供原生内置支持,无需额外适配即可快速接入。其采用标准化接口设计,让不同组件间的切换仅需一行代码即可完成,极大降低了系统扩展与迭代的复杂度。

CocoIndex 能够毫不费力地实现源数据与目标数据的精准同步,无需繁琐操作即可确保数据的一致性与时效性,为数据流转提供稳定可靠的保障。
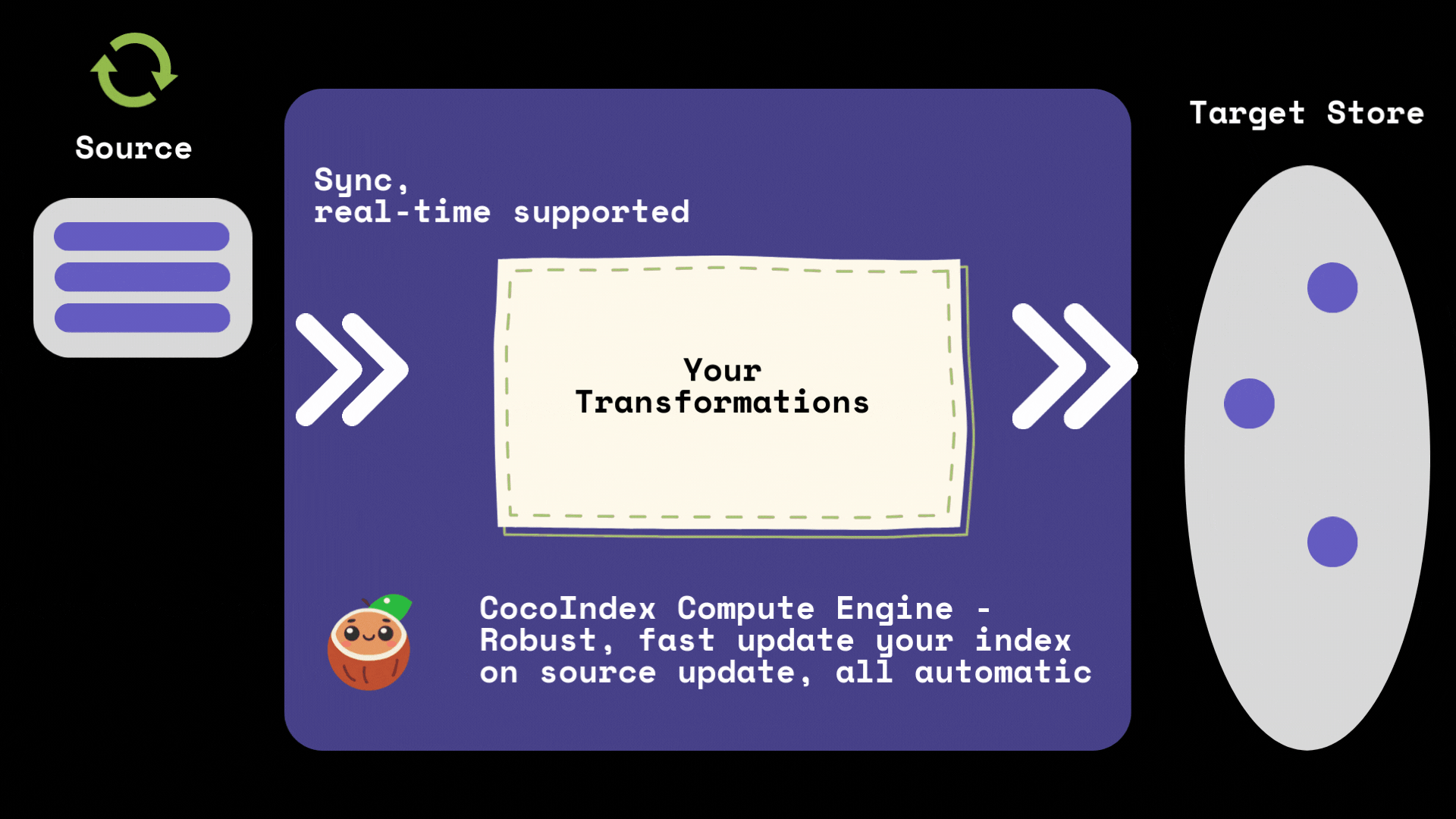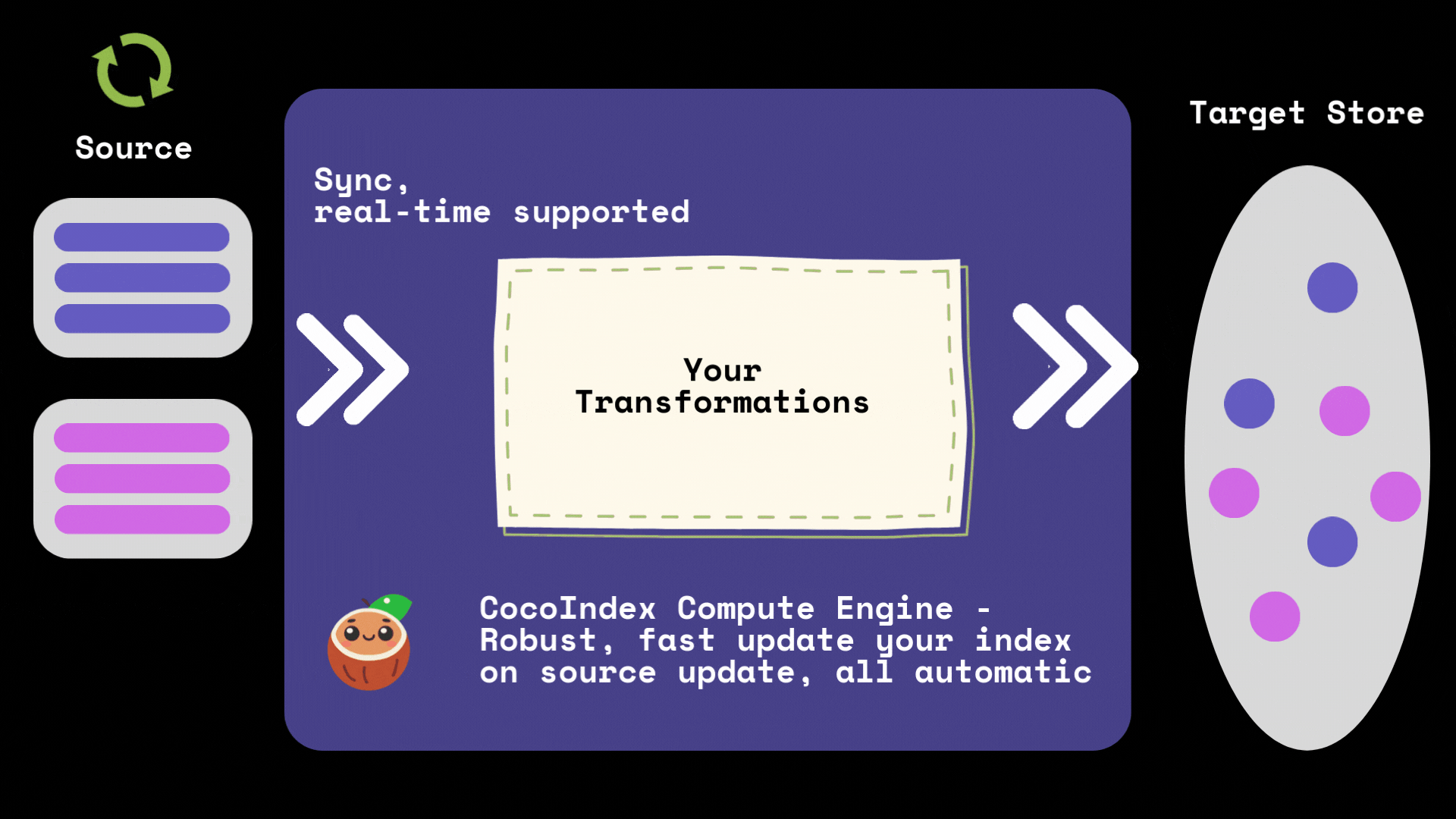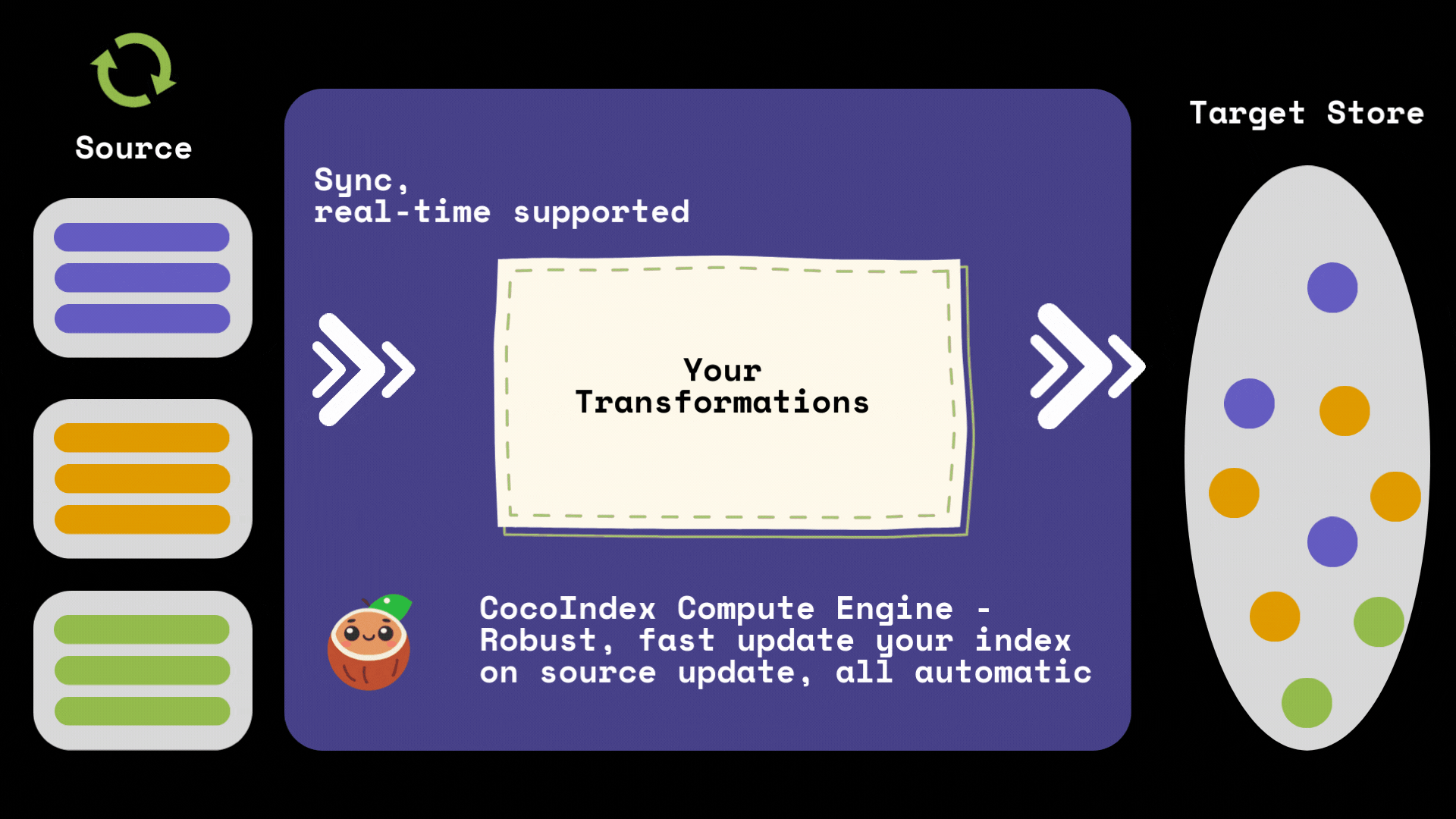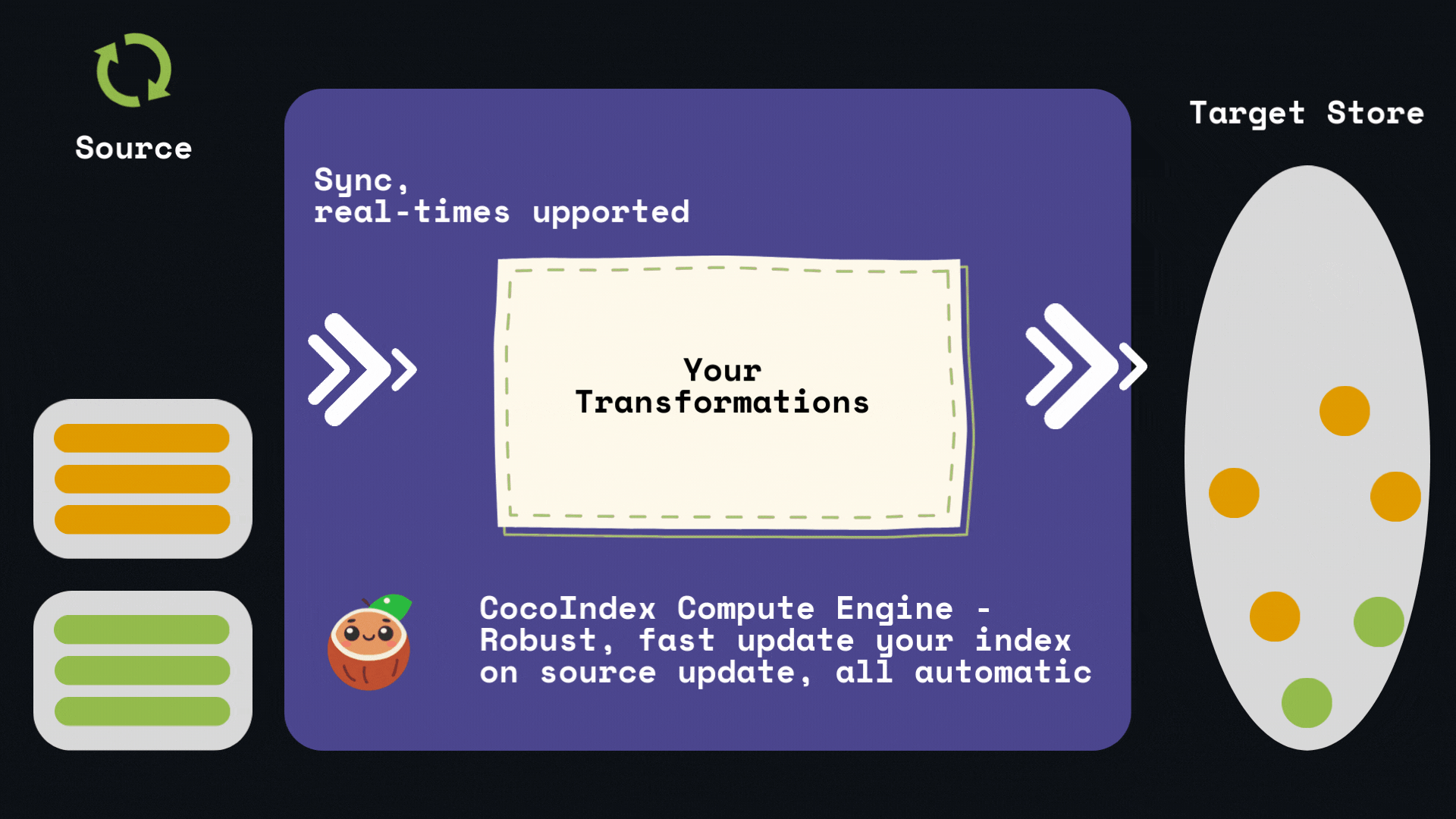
它提供开箱即用的增量索引支持:
- 当源数据或逻辑发生变更时,仅执行最小化的重计算;
- 仅对必要部分进行(重新)处理,同时尽可能复用缓存,大幅提升处理效率。
2.1 Python 与 Pip 环境准备
若想顺利完成本指南中的操作流程,需提前配置好以下环境:
- 安装 Python(支持 3.11 至 3.13 版本):建议通过 Python 官网下载对应版本,确保安装过程中勾选 "Add Python to PATH" 选项,方便后续命令行调用。
- 安装 pip(Python 包安装工具):通常 Python 3.4 及以上版本会默认捆绑 pip,若未安装,可通过 Python 官网提供的 get-pip.py 脚本进行安装,保障后续包管理操作顺畅。
🌴 快速安装 CocoIndex
完成上述环境准备后,只需在命令行中执行以下命令,即可一键安装并自动升级至最新版本的 CocoIndex:
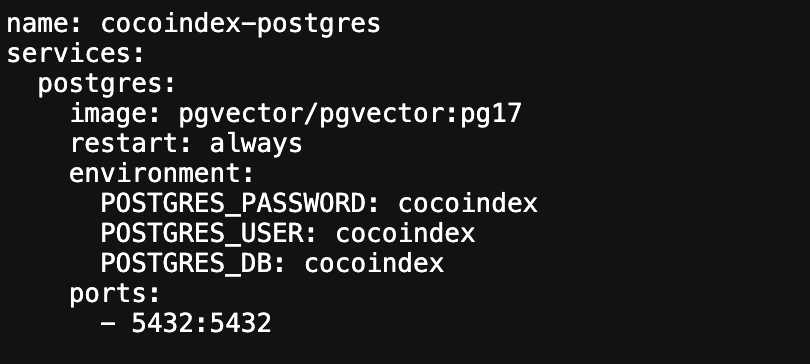
pip install -U cocoindex📦 安装 PostgreSQL
倘若您已拥有安装了 pgvector 扩展的 PostgreSQL 数据库,那么本步骤可以直接跳过。要是您还未安装 PostgreSQL 数据库,请按以下步骤操作:
首先,安装 Docker Compose🐳。Docker Compose 是用于定义和运行多容器 Docker 应用程序的工具,安装后能更便捷地管理容器化应用。您可以前往 Docker 官网,根据自身操作系统(如 Windows、macOS、Linux 等)的版本,下载并按照官方指引完成安装。
接着,使用我们提供的 docker compose 配置来启动一个供 cocoindex 使用的 PostgreSQL 数据库,只需执行以下命令:
docker compose -f <(curl -L https://raw.githubusercontent.com/cocoindex-io/cocoindex/refs/heads/main/dev/postgres.yaml) up -d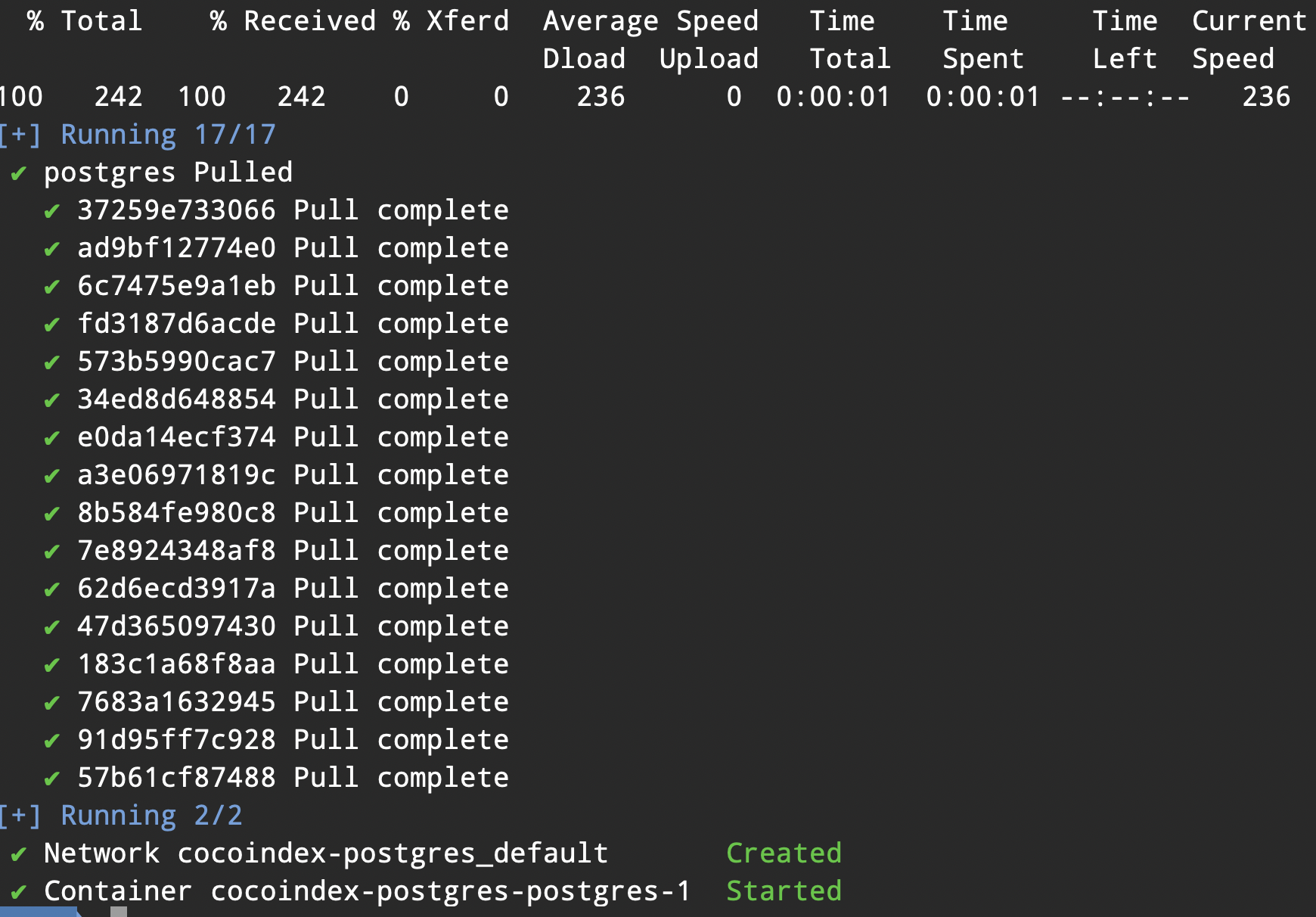
安装完成后,打开安装地址 https://raw.githubusercontent.com/cocoindex-io/cocoindex/refs/heads/main/dev/postgres.yaml 可以查看到对应的用户名和密码:
2.2 准备目录
1.创建项目目录
打开终端,为你的项目创建一个新目录并进入该目录:
mkdir cocoindex-quickstart
cd cocoindex-quickstart这一步的目的是为项目搭建一个独立的工作空间,通过专门的目录来管理后续的文件和操作,避免文件混乱。mkdir 命令用于创建名为 cocoindex-quickstart 的目录,cd 命令则切换到这个新目录,方便后续在该目录下进行所有与项目相关的操作。
2.准备索引所需的输入文件
需要将用于生成索引的输入文件整理到一个目录中(例如命名为 markdown_files)。
如果你已有现成的文件,只需将它们统一放入这个目录即可,确保文件格式符合索引工具的要求(这里示例为 markdown 格式)。
若暂时没有可用文件,可下载示例压缩包 markdown_files.zip,并将其解压到当前的 cocoindex-quickstart 目录下。解压后会自动生成 markdown_files 文件夹,里面包含演示用的示例文件,便于快速上手体验索引功能。
通过提前整理输入文件并统一存放,能让后续的索引创建过程更高效,也便于管理和维护文件资源。
2.3 定义索引流程
接下来,我们需要创建索引流程来处理准备好的文件。首先,创建一个名为 quickstart.py 的 Python 文件,并导入 cocoindex 库:
# quickstart.py
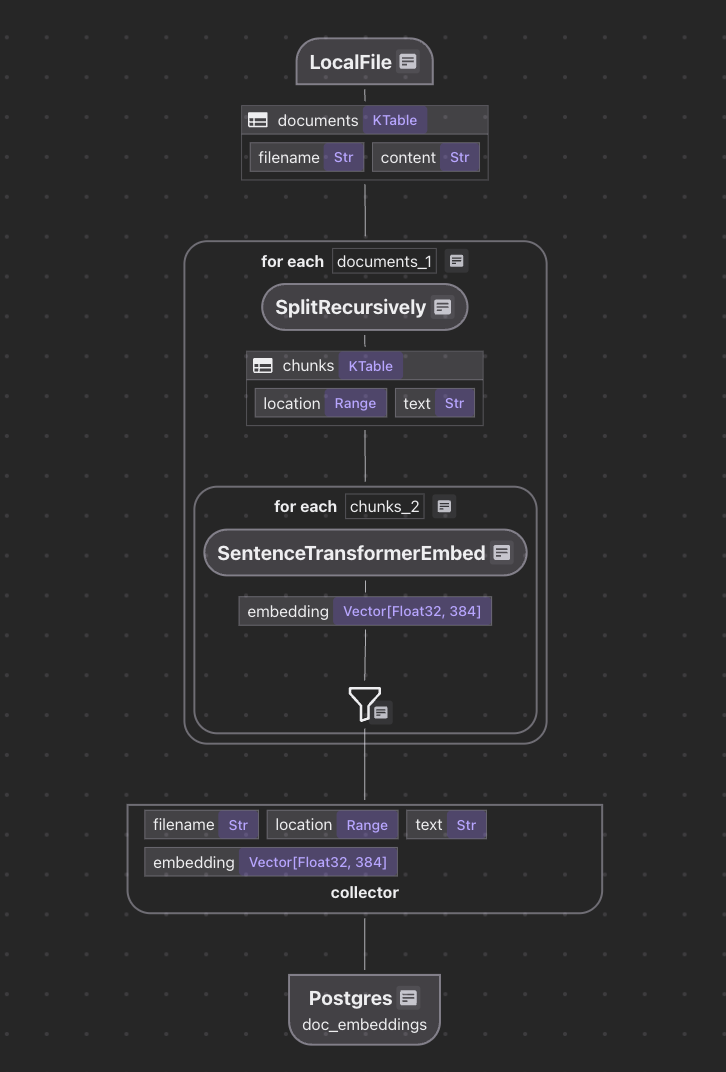
import cocoindex然后,我们可以按以下方式构建索引流程,实现从文件加载到索引创建的完整过程:
@cocoindex.flow_def(name="TextEmbedding")
def text_embedding_flow(flow_builder: cocoindex.FlowBuilder, data_scope: cocoindex.DataScope):
# 添加一个数据源,用于从目录中读取文件
data_scope["documents"] = flow_builder.add_source(
cocoindex.sources.LocalFile(path="markdown_files"))
# 添加一个收集器,用于收集将要导出到向量索引的数据
doc_embeddings = data_scope.add_collector()
# 转换每个文档的数据
with data_scope["documents"].row() as doc:
# 将文档分割为文本块,存储到`chunks`字段中
doc["chunks"] = doc["content"].transform(
cocoindex.functions.SplitRecursively(),
language="markdown", chunk_size=2000, chunk_overlap=500)
# 转换每个文本块的数据
with doc["chunks"].row() as chunk:
# 为文本块生成嵌入向量,存储到`embedding`字段中
chunk["embedding"] = chunk["text"].transform(
cocoindex.functions.SentenceTransformerEmbed(
model="sentence-transformers/all-MiniLM-L6-v2"))
# 将文本块数据收集到收集器中
doc_embeddings.collect(filename=doc["filename"], location=chunk["location"],
text=chunk["text"], embedding=chunk["embedding"])
# 将收集的数据导出到向量索引
doc_embeddings.export(
"doc_embeddings", # 表名
cocoindex.targets.Postgres(), # 目标数据库
primary_key_fields=["filename", "location"], # 主键字段
vector_indexes=[ # 向量索引定义
cocoindex.VectorIndexDef(
field_name="embedding", # 向量字段名
metric=cocoindex.VectorSimilarityMetric.COSINE_SIMILARITY) # 相似度计算方式
])这段代码通过 cocoindex 库定义了一个完整的文本向量嵌入流水线,核心目的是将原始 Markdown 文档转换为可用于语义检索的向量数据,并存储到数据库中。整体流程可分为 5 个关键步骤:
1. 流程定义
@cocoindex.flow_def(name="TextEmbedding")
def text_embedding_flow(flow_builder, data_scope):- 使用 @flow_def 装饰器声明一个名为 TextEmbedding 的流程,用于统一管理数据处理的各个环节。
- flow_builder 负责创建流程组件(如数据源、转换器),data_scope 负责管理数据的流转和存储(类似一个 "数据容器")。
2. 读取原始文件
data_scope["documents"] = flow_builder.add_source(
cocoindex.sources.LocalFile(path="markdown_files"))- 通过 LocalFile 数据源读取 markdown_files 目录下的所有文件(如 .md 文档)。
- 读取结果被存储在 data_scope"documents" 中,后续可通过这个键访问所有文档数据(包括文件名、内容等)。
3. 创建数据收集器
doc_embeddings = data_scope.add_collector()- 初始化一个收集器 doc_embeddings,用于临时存储处理后的文本块数据(如文本内容、向量嵌入等),为后续导出到数据库做准备。
4. 文本处理流水线(核心步骤)
这部分是流程的核心,通过嵌套的 with 语句实现对 "文档→文本块" 的层级处理:
文档分割为文本块:
with data_scope["documents"].row() as doc:
doc["chunks"] = doc["content"].transform(
cocoindex.functions.SplitRecursively(),
language="markdown", chunk_size=2000, chunk_overlap=500)- with data_scope"documents".row() as doc:遍历 documents 中的每个文档(doc 代表单个文档)。
- 使用 SplitRecursively 函数对文档内容(doc"content")进行分割:
- 针对 Markdown 格式优化(如避免在标题、列表中间分割)。
- 每个文本块最大长度为 2000 字符,相邻块重叠 500 字符(防止语义被割裂)。
- 分割后的文本块存储在 doc"chunks" 中,供下一步处理。
生成文本块的向量嵌入:
with doc["chunks"].row() as chunk:
chunk["embedding"] = chunk["text"].transform(
cocoindex.functions.SentenceTransformerEmbed(
model="sentence-transformers/all-MiniLM-L6-v2"))- with doc"chunks".row() as chunk:遍历当前文档的每个文本块(chunk 代表单个文本块)。
- 使用 SentenceTransformerEmbed 函数将文本块内容(chunk"text")转换为向量:
- 采用预训练模型 all-MiniLM-L6-v2(轻量级模型,适合快速生成高质量嵌入)。
- 向量嵌入结果存储在 chunk"embedding" 中,用于后续的语义相似度计算。
收集处理结果:
doc_embeddings.collect(
filename=doc["filename"], # 源文档名称
location=chunk["location"], # 文本块在原文档中的位置(如页码、段落索引)
text=chunk["text"], # 文本块内容
embedding=chunk["embedding"] # 向量嵌入
)- 将每个文本块的关键信息(来源、位置、内容、向量)收集到 doc_embeddings 中,形成结构化数据。
5. 导出到向量数据库
doc_embeddings.export(
"doc_embeddings", # 数据库表名
cocoindex.targets.Postgres(), # 目标存储:PostgreSQL数据库
primary_key_fields=["filename", "location"], # 联合主键(确保每条数据唯一)
vector_indexes=[ # 为向量字段创建索引
cocoindex.VectorIndexDef(
field_name="embedding", # 向量字段名
metric=COSINE_SIMILARITY # 用余弦相似度计算向量距离(适合文本语义匹配)
)
])- 将收集到的结构化数据导出到 PostgreSQL 数据库,生成一张名为 doc_embeddings 的表。
- 通过配置向量索引,使得后续可以高效地基于语义相似度查询(如 "查找与查询文本意思最接近的文档片段")。
这段代码实现了从 "原始文档" 到 "可检索向量数据" 的全自动化流程,核心价值在于:
标准化处理:通过流水线确保文本分割、向量生成的一致性。
语义化存储:将文本转换为向量后,支持基于语义而非关键词的检索。
工程化集成:直接对接数据库并创建索引,为后续应用(如知识库、智能检索系统)提供数据基础。
整个流程无需人工干预,适合批量处理文档并构建语义检索系统。
3.构建 Text Embedding 和语义检索
从本地 Markdown 文件构建 Text Embedding 索引并进行查询,代码如下:
from dotenv import load_dotenv
from psycopg_pool import ConnectionPool
from pgvector.psycopg import register_vector
from typing import Any
import cocoindex
import os
from numpy.typing import NDArray
import numpy as np
from datetime import timedelta
@cocoindex.transform_flow()
def text_to_embedding(
text: cocoindex.DataSlice[str],
) -> cocoindex.DataSlice[NDArray[np.float32]]:
"""
使用SentenceTransformer模型对文本进行嵌入处理。
这是索引构建和查询过程中共享的逻辑,因此将其提取为一个函数。
"""
# 你也可以切换到远程嵌入模型:
# return text.transform(
# cocoindex.functions.EmbedText(
# api_type=cocoindex.LlmApiType.OPENAI,
# model="text-embedding-3-small",
# )
# )
return text.transform(
cocoindex.functions.SentenceTransformerEmbed(
model="sentence-transformers/all-MiniLM-L6-v2"
)
)
@cocoindex.flow_def(name="TextEmbedding")
def text_embedding_flow(
flow_builder: cocoindex.FlowBuilder, data_scope: cocoindex.DataScope
) -> None:
"""
定义一个示例流程,用于将文本嵌入到向量数据库中。
"""
data_scope["documents"] = flow_builder.add_source(
cocoindex.sources.LocalFile(path="markdown_files"),
refresh_interval=timedelta(seconds=5), # 每5秒刷新一次文件
)
doc_embeddings = data_scope.add_collector()
with data_scope["documents"].row() as doc:
doc["chunks"] = doc["content"].transform(
cocoindex.functions.SplitRecursively(),
language="markdown",
chunk_size=2000,
chunk_overlap=500,
)
with doc["chunks"].row() as chunk:
chunk["embedding"] = text_to_embedding(chunk["text"])
doc_embeddings.collect(
filename=doc["filename"],
location=chunk["location"],
text=chunk["text"],
embedding=chunk["embedding"],
)
doc_embeddings.export(
"doc_embeddings",
cocoindex.targets.Postgres(),
primary_key_fields=["filename", "location"],
vector_indexes=[
cocoindex.VectorIndexDef(
field_name="embedding",
metric=cocoindex.VectorSimilarityMetric.COSINE_SIMILARITY,
)
],
)
def search(pool: ConnectionPool, query: str, top_k: int = 5) -> list[dict[str, Any]]:
# 获取表名,对应上面text_embedding_flow中导出的目标表
table_name = cocoindex.utils.get_target_default_name(
text_embedding_flow, "doc_embeddings"
)
# 使用上面定义的转换流程处理输入查询,获取嵌入向量
query_vector = text_to_embedding.eval(query)
# 执行查询并获取结果
with pool.connection() as conn:
register_vector(conn) # 注册向量类型支持
with conn.cursor() as cur:
cur.execute(
f"""
SELECT filename, text, embedding <=> %s AS distance
FROM {table_name} ORDER BY distance LIMIT %s
""",
(query_vector, top_k),
)
# 将距离转换为相似度分数(1 - 距离)
return [
{"filename": row[0], "text": row[1], "score": 1.0 - row[2]}
for row in cur.fetchall()
]
def _main() -> None:
# 初始化数据库连接池
pool = ConnectionPool(os.getenv("COCOINDEX_DATABASE_URL"))
# 循环运行查询以演示查询功能
while True:
query = input("输入搜索查询(按回车退出):")
if query == "":
break
# 使用数据库连接池和查询语句运行查询函数
results = search(pool, query)
print("\n搜索结果:")
for result in results:
print(f"[{result['score']:.3f}] {result['filename']}")
print(f" {result['text']}")
print("---")
print()
if __name__ == "__main__":
load_dotenv() # 加载环境变量
cocoindex.init() # 初始化cocoindex
_main()这段代码实现了一个完整的文本向量索引与检索系统,包含从本地 Markdown 文件构建向量索引,到通过用户输入进行语义搜索的全流程。整体结构可分为四个核心模块:
1. 文本嵌入转换函数(text_to_embedding)
@cocoindex.transform_flow()
def text_to_embedding(text: DataSlice[str]) -> DataSlice[NDArray[np.float32]]:- 这是一个共享转换逻辑,同时服务于索引构建和查询过程,确保文本处理方式一致。
- 功能:使用sentence-transformers/all-MiniLM-L6-v2模型将文本转换为向量嵌入。
- 灵活性:代码中注释了切换到 OpenAI 远程嵌入模型(如text-embedding-3-small)的方式,可根据需求选择本地或云端模型。
2. 索引构建流程(text_embedding_flow)
@cocoindex.flow_def(name="TextEmbedding")
def text_embedding_flow(flow_builder, data_scope) -> None:- 这是索引构建的核心流程,在之前代码基础上增加了文件自动刷新功能(refresh_interval=5秒),支持实时监测markdown_files目录的文件变化。
- 流程步骤:
- 数据读取:通过LocalFile源读取 Markdown 文件,每 5 秒刷新一次。
- 文本分割:使用SplitRecursively按 Markdown 格式分割文本(块大小 2000 字符,重叠 500 字符)。
- 向量生成:调用text_to_embedding函数为每个文本块生成向量。
- 数据收集:收集文件名、位置、文本内容和向量嵌入。
- 导出存储:将数据存入 PostgreSQL,以(filename, location)为联合主键,并为embedding字段创建余弦相似度索引。
3. 搜索功能实现(search函数)
def search(pool: ConnectionPool, query: str, top_k: int = 5) -> list[dict[str, Any]]:- 该函数实现了基于向量相似度的检索功能,是连接索引数据与用户查询的桥梁。
- 工作原理:
- 获取表名:通过工具函数自动获取索引存储的表名(与构建流程关联)。
- 生成查询向量:使用text_to_embedding.eval(query)将用户输入转换为向量(确保与索引向量同源)。
- 数据库查询:
- 连接 PostgreSQL 并注册向量类型支持。
- 执行 SQL 查询,使用<=>运算符计算查询向量与存储向量的距离(余弦距离)。
- 按距离排序并返回前top_k条结果。
- 结果转换:将距离值转换为相似度分数(1 - 距离),便于直观理解匹配程度。
4. 主程序入口(_main函数)
def _main() -> None:- 负责初始化系统并提供交互式查询界面:
- 环境配置:通过load_dotenv加载环境变量(如数据库连接 URL)。
- 连接池初始化:创建 PostgreSQL 连接池,优化数据库连接效率。
- 交互式查询:循环接收用户输入,调用search函数并格式化输出结果,直到用户按回车退出。
接下来,执行如下命令:
# 安装依赖
pip install -e .
# 配置
cocoindex setup main.py
# 更新索引
cocoindex update main.py
# 执行
python main.py
# CocoInsight工具
cocoindex server -ci main.py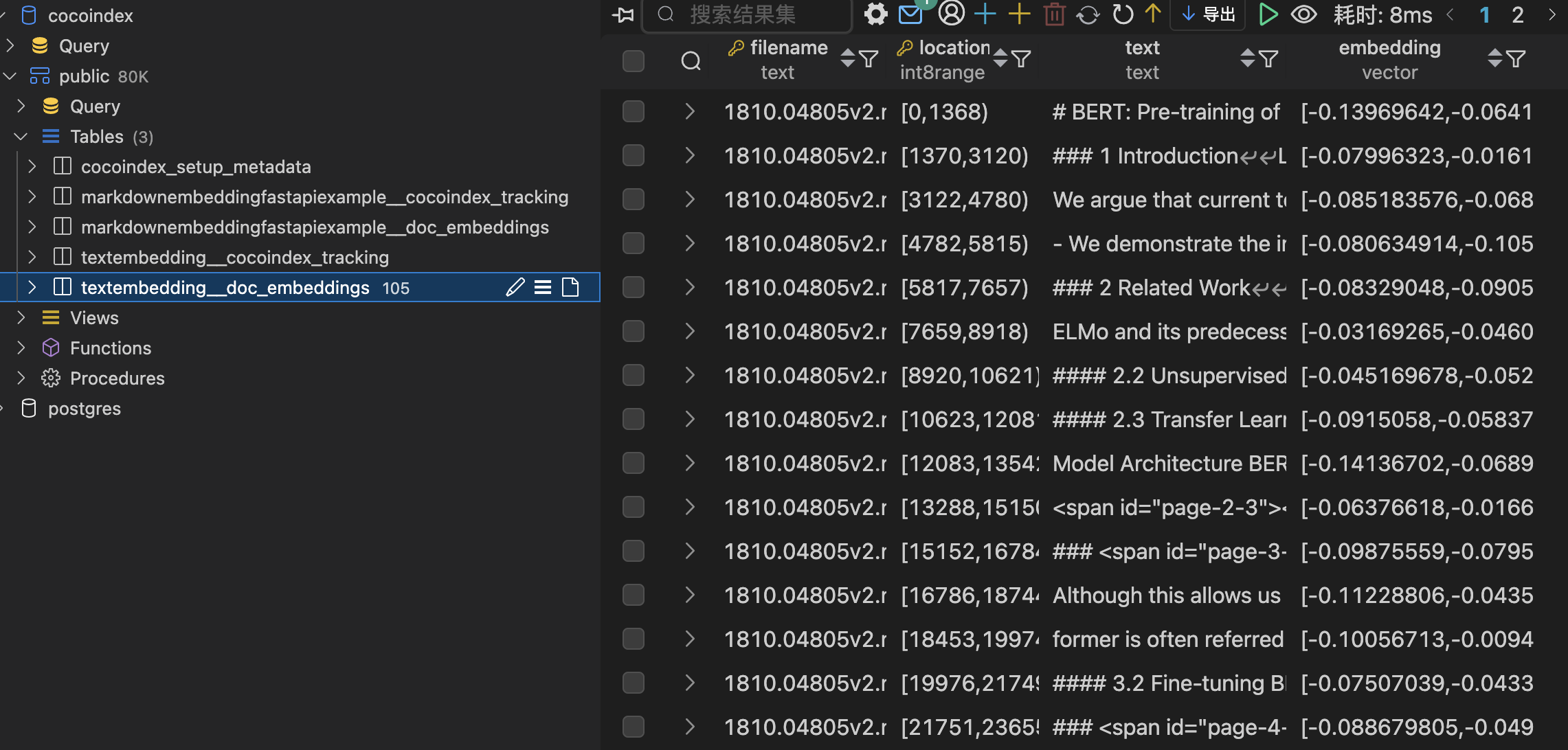
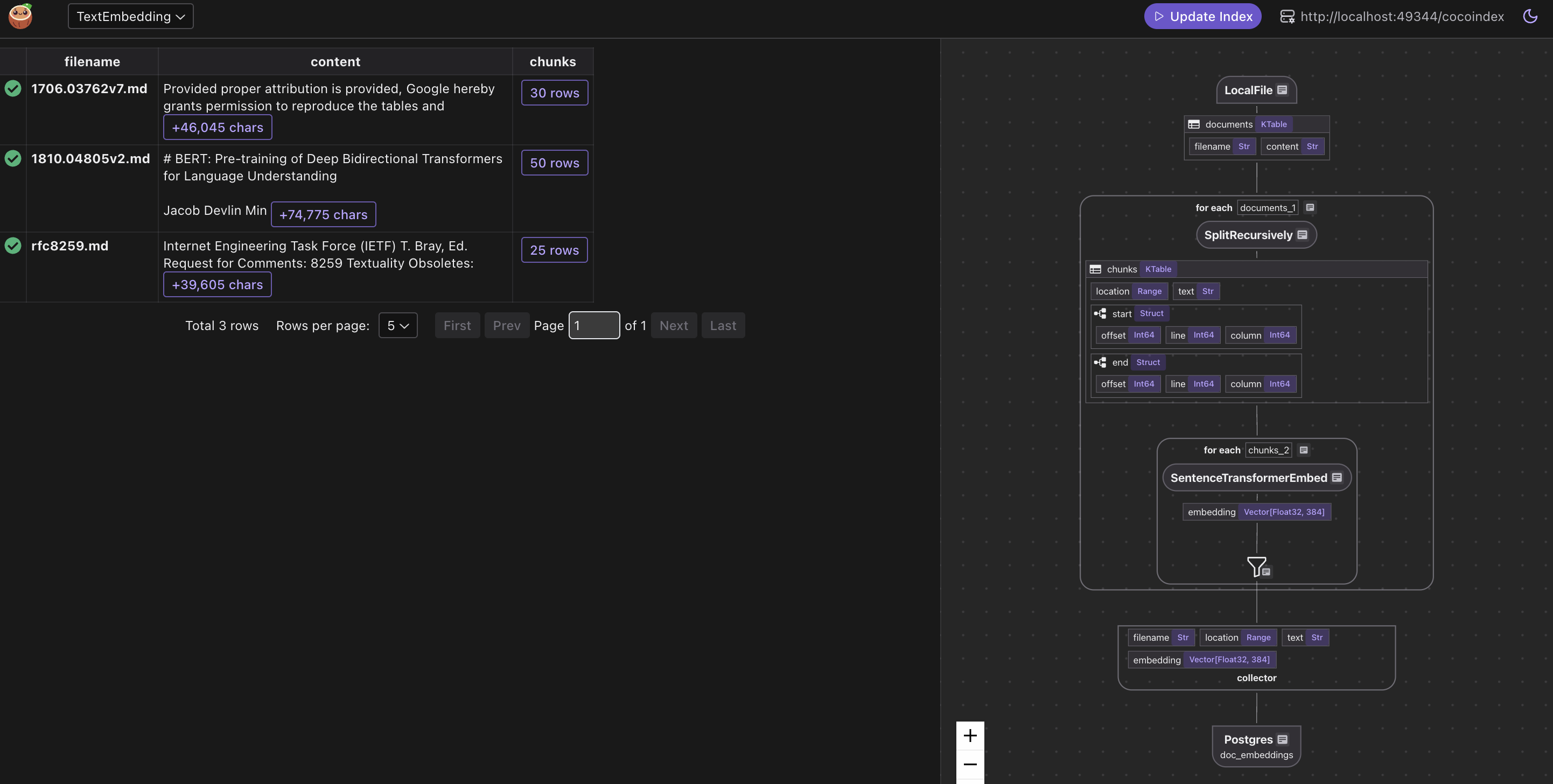
4.构建 FastAPI 在线语义检索服务
在本示例中,我们将基于本地的 markdown 文件构建文本嵌入索引,并通过 fastapi 提供一个简单的查询接口。
实现代码如下:
import cocoindex
import uvicorn
from dotenv import load_dotenv # 用于加载环境变量
from fastapi import FastAPI, Query # 用于创建API接口
from fastapi import Request
from psycopg_pool import ConnectionPool # PostgreSQL连接池
from contextlib import asynccontextmanager # 用于管理异步上下文
import os
@cocoindex.transform_flow()
def text_to_embedding(
text: cocoindex.DataSlice[str],
) -> cocoindex.DataSlice[list[float]]:
"""
使用SentenceTransformer模型将文本转换为嵌入向量。
这是索引构建和查询过程中共享的逻辑。
"""
return text.transform(
cocoindex.functions.SentenceTransformerEmbed(
model="sentence-transformers/all-MiniLM-L6-v2" # 使用的预训练模型
)
)
@cocoindex.flow_def(name="MarkdownEmbeddingFastApiExample")
def markdown_embedding_flow(
flow_builder: cocoindex.FlowBuilder, data_scope: cocoindex.DataScope
):
"""
定义一个示例流程,用于将Markdown文件嵌入到向量数据库中。
"""
# 从本地"files"目录添加Markdown文件作为数据源
data_scope["documents"] = flow_builder.add_source(
cocoindex.sources.LocalFile(path="files")
)
# 创建一个收集器,用于收集处理后的文档嵌入信息
doc_embeddings = data_scope.add_collector()
# 遍历每个文档
with data_scope["documents"].row() as doc:
# 将文档内容按Markdown格式分割成块
doc["chunks"] = doc["content"].transform(
cocoindex.functions.SplitRecursively(), # 递归分割函数
language="markdown", # 分割语言
chunk_size=2000, # 块大小
chunk_overlap=500, # 块重叠部分大小
)
# 遍历每个分割后的文本块
with doc["chunks"].row() as chunk:
# 为每个文本块生成嵌入向量
chunk["embedding"] = text_to_embedding(chunk["text"])
# 收集嵌入信息,包括文件名、位置、文本内容和嵌入向量
doc_embeddings.collect(
filename=doc["filename"],
location=chunk["location"],
text=chunk["text"],
embedding=chunk["embedding"],
)
# 将收集的嵌入信息导出到PostgreSQL数据库
doc_embeddings.export(
"doc_embeddings", # 导出名称
cocoindex.targets.Postgres(), # 目标数据库
primary_key_fields=["filename", "location"], # 主键字段
vector_indexes=[ # 向量索引定义
cocoindex.VectorIndexDef(
field_name="embedding", # 向量字段名
metric=cocoindex.VectorSimilarityMetric.COSINE_SIMILARITY, # 相似度度量方式
)
],
)
def search(pool: ConnectionPool, query: str, top_k: int = 5):
"""
搜索函数:根据查询文本在向量数据库中查找最相似的结果
"""
# 获取导出目标的默认表名
table_name = cocoindex.utils.get_target_default_name(
markdown_embedding_flow, "doc_embeddings"
)
# 对查询文本执行转换流程,获取嵌入向量
query_vector = text_to_embedding.eval(query)
# 执行查询并获取结果
with pool.connection() as conn: # 从连接池获取连接
with conn.cursor() as cur: # 创建游标
cur.execute(
f"""
SELECT filename, text, embedding <=> %s::vector AS distance
FROM {table_name} ORDER BY distance LIMIT %s
""",
(query_vector, top_k), # 查询参数
)
# 处理结果,将余弦距离转换为相似度分数
return [
{"filename": row[0], "text": row[1], "score": 1.0 - row[2]}
for row in cur.fetchall()
]
@asynccontextmanager
async def lifespan(app: FastAPI):
"""
FastAPI生命周期管理:初始化和清理资源
"""
load_dotenv() # 加载环境变量
cocoindex.init() # 初始化CocoIndex
# 创建数据库连接池
pool = ConnectionPool(os.getenv("COCOINDEX_DATABASE_URL"))
app.state.pool = pool # 将连接池存储在应用状态中
try:
yield # 应用运行期间
finally:
pool.close() # 关闭连接池
# 创建FastAPI应用实例
fastapi_app = FastAPI(lifespan=lifespan)
@fastapi_app.get("/search")
def search_endpoint(
request: Request,
q: str = Query(..., description="搜索查询文本"),
limit: int = Query(5, description="返回结果数量"),
):
"""
搜索接口:接收查询文本和结果数量,返回匹配的搜索结果
"""
pool = request.app.state.pool # 获取连接池
results = search(pool, q, limit) # 执行搜索
return {"results": results} # 返回结果
if __name__ == "__main__":
# 启动FastAPI服务
uvicorn.run(fastapi_app, host="0.0.0.0", port=8080)这段代码实现了一个基于 CocoIndex 框架的文本嵌入与检索系统,主要功能是将本地 Markdown 文件转换为向量表示并存储在 PostgreSQL 数据库中,同时提供一个 FastAPI 接口用于查询相似文本。整体流程可分为以下几个部分:
- 文本嵌入转换函数:text_to_embedding函数使用 SentenceTransformer 模型将文本转换为向量表示,这是索引构建和查询过程中共享的核心逻辑,确保了索引和查询使用相同的嵌入方式。
- 数据处理流程定义:markdown_embedding_flow函数定义了完整的数据处理流程:
- 从本地 "files" 目录读取 Markdown 文件
- 将文档内容分割成适当大小的文本块(考虑重叠部分)
- 为每个文本块生成嵌入向量
- 将处理结果(包括文件名、位置、文本内容和嵌入向量)导出到 PostgreSQL 数据库,并创建向量索引
- 搜索功能实现:search函数实现了向量相似性查询功能,通过将查询文本转换为嵌入向量,然后在 PostgreSQL 中使用向量索引查找最相似的文本块,并返回结果。
- FastAPI 接口:创建了一个/search接口,允许用户通过 HTTP 请求进行文本查询,返回匹配的结果及相似度分数。
- 资源管理:使用lifespan上下文管理器管理应用生命周期,包括初始化 CocoIndex、创建数据库连接池等资源,并在应用关闭时进行清理。
整个系统体现了 CocoIndex 框架在数据转换和索引构建方面的优势,同时结合 FastAPI 提供了便捷的查询接口,可用于构建基于本地文档的语义搜索应用。
本地环境执行如下命令:
# 在 .env 文件中修改
COCOINDEX_DATABASE_URL=postgres://cocoindex:cocoindex@localhost/cocoindex
# 安装依赖
pip install -r requirements.txt
# 配置
cocoindex setup main.py
#更新索引
cocoindex update main.py
# 启动服务
uvicorn main:fastapi_app --reload --host 0.0.0.0 --port 8000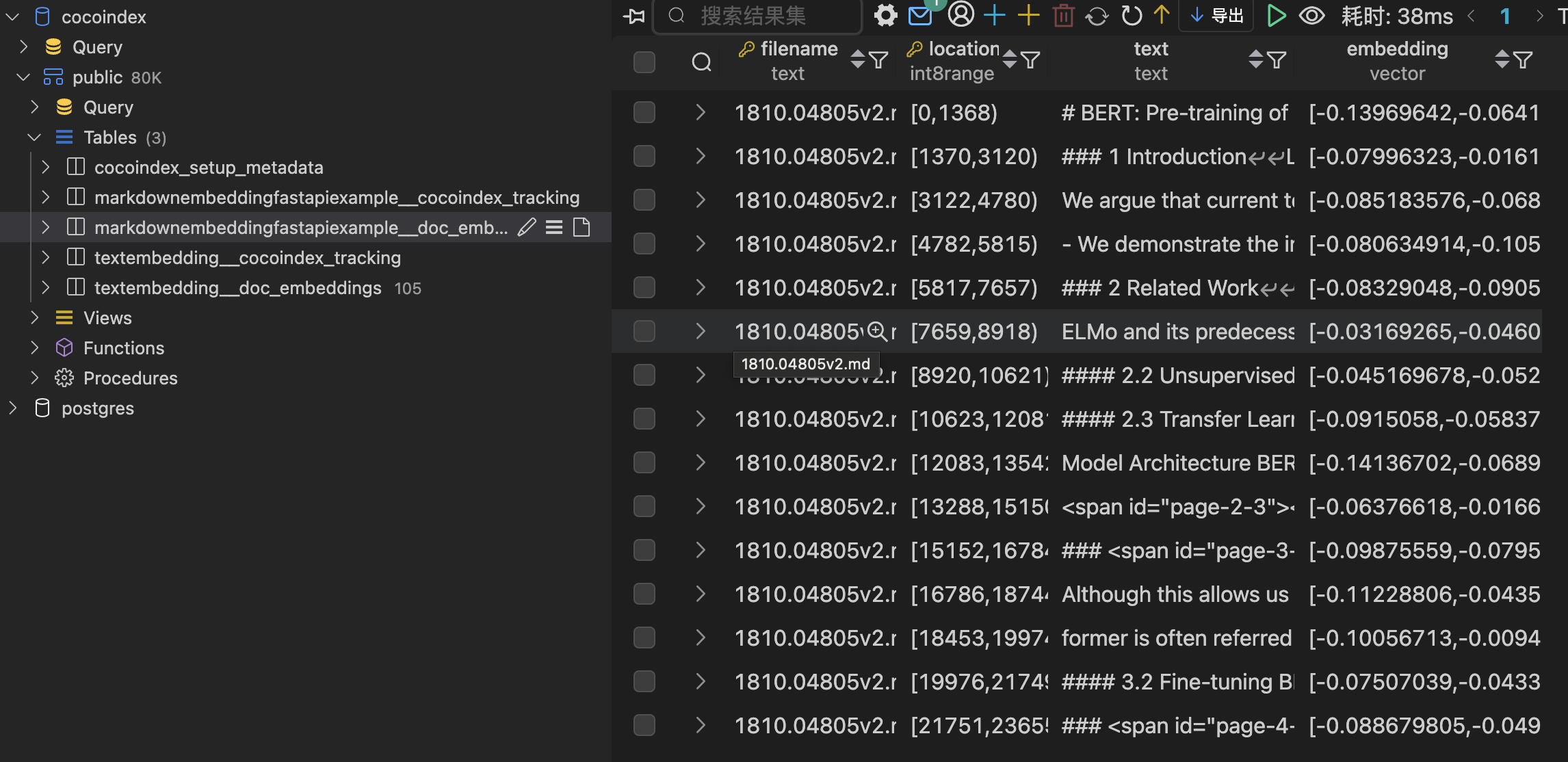
服务启动,我们可以访问地址进行语义搜索:
http://localhost:8000/search?q=model&limit=3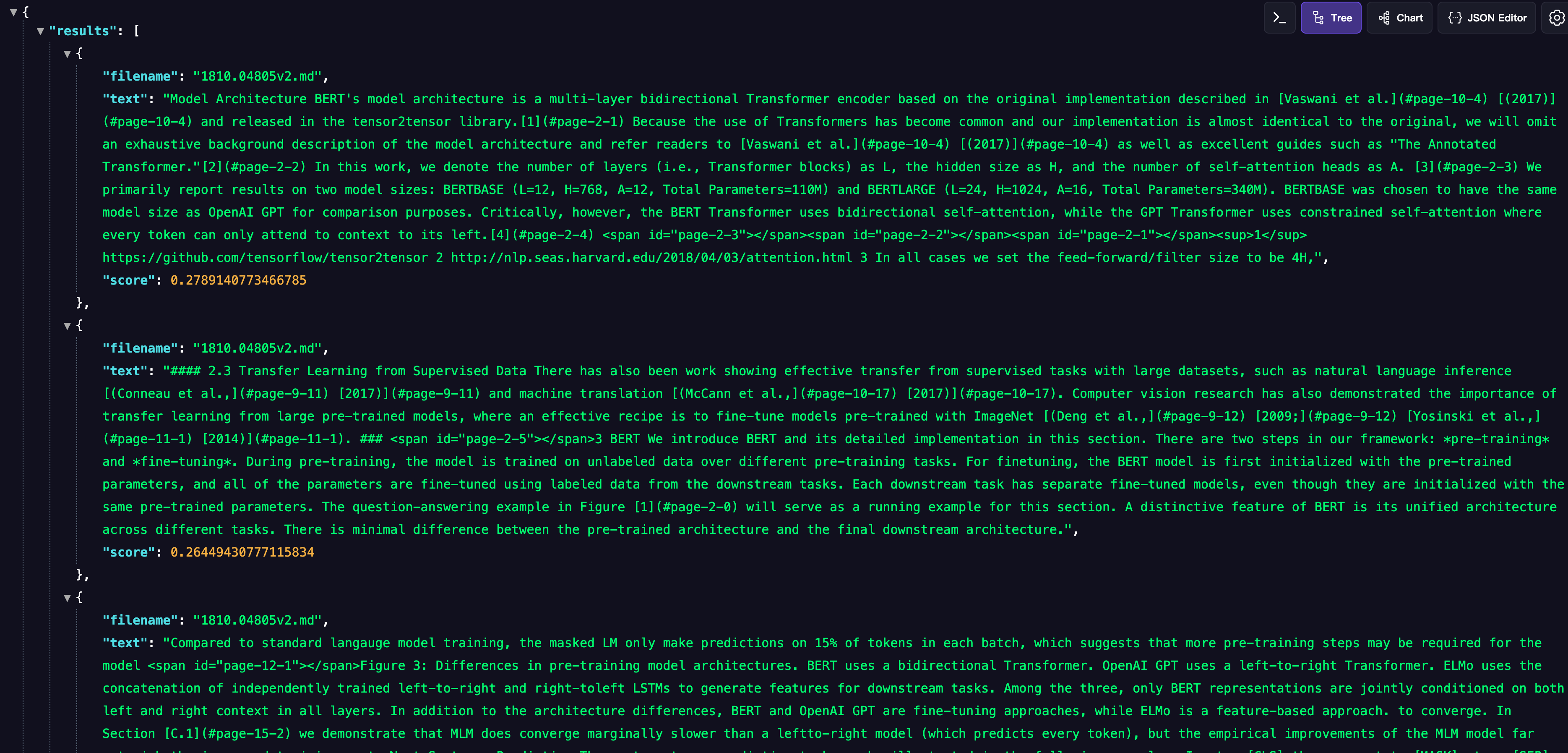
5.总结
CocoIndex 作为专为 AI 设计的超高性能数据转换框架,以 Rust 核心引擎为支撑,凭借增量处理、数据血缘追踪等开箱即用的特性,让复杂数据转换变得简单高效。无论是生成嵌入向量、构建知识图谱,还是处理超越传统 SQL 的任务,都能以极简代码快速实现,且从开发初期就具备生产就绪能力。其标准化接口与实时同步能力,完美适配 AI 场景中对数据新鲜度与处理效率的高要求,成为连接数据与 AI 应用的高效枢纽,大幅降低 AI 数据链路的开发与落地成本。
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出新书了《Hadoop与Spark大数据全景解析》、同时已出版的《深入理解Hive》、《Kafka并不难学》和《Hadoop大数据挖掘从入门到进阶实战》也可以和新书配套使用,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。关注下面公众号,根据提示,可免费获取书籍的教学视频。