说到数据库,很多人会想到例如关系型数据库的mysql,oracle,非关系型数据库(NoSQL)mongo等,这里要介绍的是列式数据库clickhouse,他凭借其卓越的性能而广受好评,clickhouse数据库可实现在单台机器上每秒亿级数据处理的惊人性能,是高性能分析领域的首选引擎。clickhouse有四个突出的特点,性能强大,单机处理能力强,成本低,不支持事务,也因为这些特点,他通常被应用于报表分析,日志分析,广告营销等场景。
有读者可能会好奇,为什么clickhouse可以实现如此高的性能,而mysql等常规的数据库在遇到亿级数据时就会力不从心呢? 下面首先列举下mysql和clickhouse 在设计目标,数据结构等方面的不同,然后通过比较来一起探索clickhouse的特点以及其高性能的原因。
设计目标:
常见的数据库可以分为OLAP (联机分析处理) 和 OLTP (联机事务处理)两类,OLTP是实时线上业务处理,通常用于处理大量的、频繁的、短小的、基于事务的操作,而mysql就属于这一类,而OLAP是一种专门用来对大量历史数据进行多角度分析的技术,clickhouse就属于这一类,因此,从设计目标上,两者就不一致,mysql需要处理线上业务,需要保证事务的正确执行,而clickhouse直接就不支持事务,甚至不支持update和delete操作。
mysql和clickhouse的表结构设计理念也有区别,设计表结构时一般会参考数据库范式,遵守这些范式有助于设计出合理的数据库表结构,设计表时符合的范式等级越高,数据库冗余越小,进行mysql表设计时一般要遵守这些范式降低数据冗余,这样业务上才能更好的提高数据一致性和查询性能,但是clickhouse则相反,因为他的目标是用于分析海量数据,如果采用范式则需要多表关联查询,会极大降低性能,因此一般采用逆规范化,使用时尽量设计宽表,字段越多,越能从clickhouse的高性能中受益。
高范式的表适合事务处理,低范式的表适合分析处理。从中我们可以得出数仓建模的本质:逆规范化。数仓建模在本质上就是一个逆规范化的过程,将来自原始业务数据库的规范化数据还原为低范式的数据,用于快速分析。
数据结构:
mysql存储数据时,是将数据组织为B+树的结构,然后按页存储到磁盘中的,数据的增删改都需要保证B+树的数据结构,同时存储数据的这个B+树是按照其主键索引来排序组织的,数据按行存储在叶子节点中,如果有其他索引,则会按照其他索引的字段顺序再存储一个B+树,叶子节点存储对应数据的主键的值。
而clickhouse作为列示存储数据库,首先他是按照列进行数据存储的,每个列单独用一个文件分开进行存储,而mysql等oltp数据库一般都是按行存储,即一行中的所有数据是存放在一起的。 同时clickhouse底层存储数据的结构也和mysql不同,他是将数据按照主键索引的顺序进行按序存储,可以认为底层是个有序排序的数组。
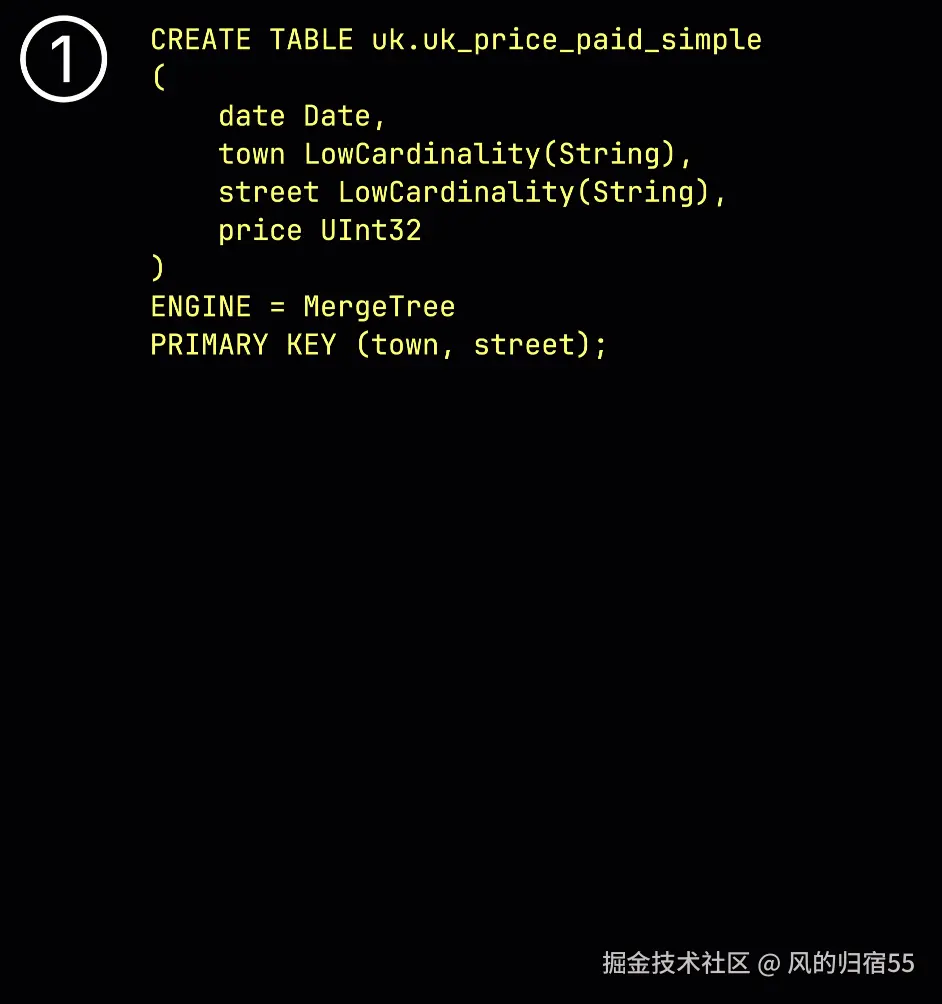
可以参考下图,clickhouse将一行数据按列分成不同文件,然后按照主键顺序,每一行的几个字段都存储到各自文件的对应位置。每8192行数据会作为一个底层存储的块写入到文件中,就是图中每个黄色的块,每个块中的数据都是按序存放的。clickhouse的主键索引数据是存放在primary.idx文件中,里面存储了每个块中最小的值以及对应的数据块号。
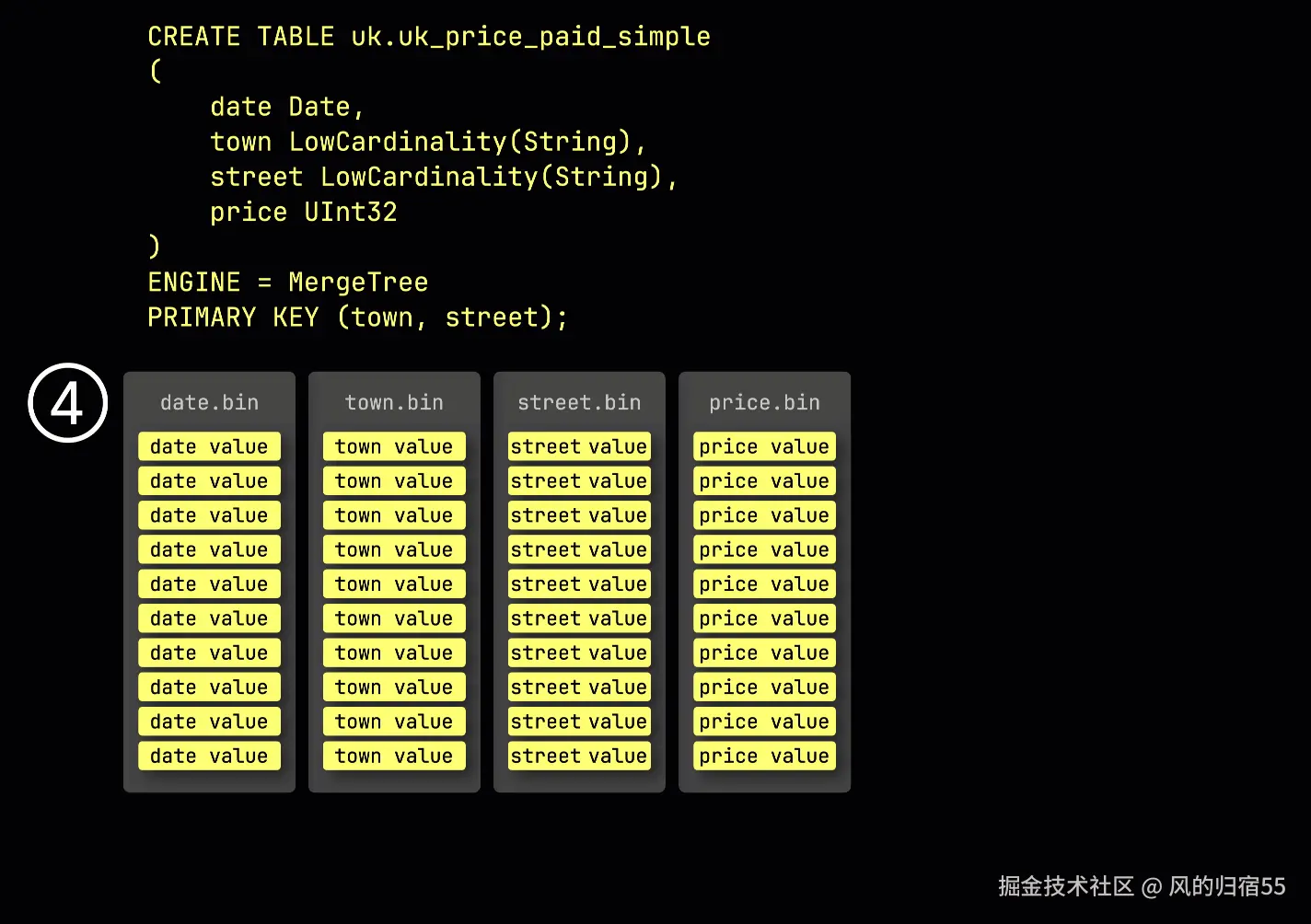
这里有必要说明下clickhouse的索引机制,clickhouse存储数据时底层并不是严格按照主键索引的顺序进行存储的,他是是通过lsm算法预排序数据,将某段时间插入的数据按照主键索引的顺序预排序后,生成segment然后存储,因此每一个segment都是有序的,但是多个segment不一定是按顺序的,因此也会有段合并,将多个段合并为一个有序的段提升查询效率。
数据查询过程:
mysql查询数据时,如果查询字段中有主键索引,则可以通过主键索引所在的B+树找到对应数据,其叶子节点里面就包含对应的整行的数据。 如果没有主键索引,但是有其他非聚簇索引字段,则可以从非聚簇索引的B+树中一层一层的找到叶子节点,里面有对应的主键索引的值,然后再按照查询主键索引的逻辑再走一遍查到具体数据。
clickhouse查询数据时,如果匹配到了主键索引,则会从primary.idx文件中获取到对应的数据所在的块,他不是直接匹配到数据存放在哪个块中,而是根据每个块的最小值排除掉那些肯定没有数据的块,再从可能有数据的块中进行数据查找。如果查询时没有匹配到主键索引,那只能进行全表查询了,效率会很差。
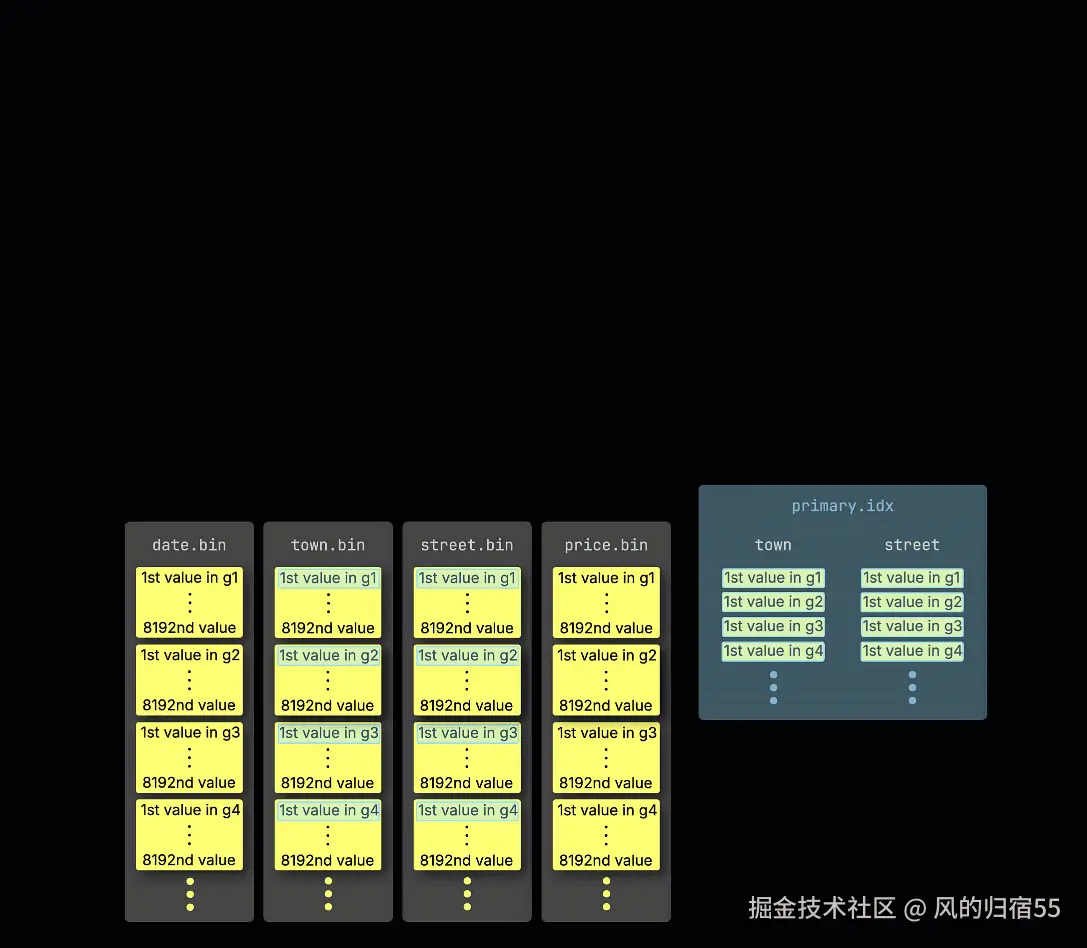
从这可以看出,clickhouse通过存储设计可以提高查询速度,但是他的结构设计也带来了劣势,比如针对非主键查询,mysql可以通过新建一个非主键索引来加速查询,而clickhouse因为其数据是按照主键的顺序存储的,就算建立了其他非主键的索引,也无法获得加速,只能进行全表扫描。
文件组织架构
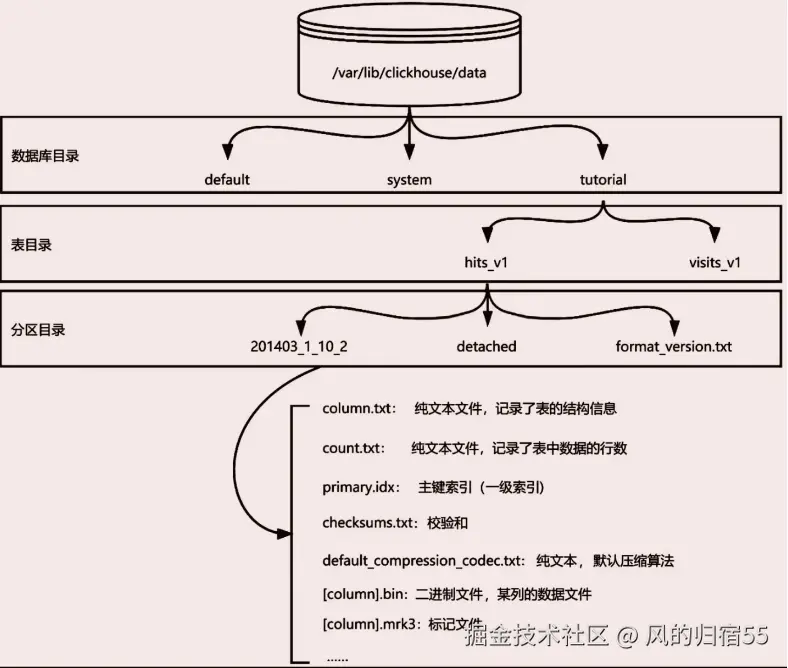
这里单独列一下clickhouse的文件组织结构,方便加深对clickhouse的了解。这里默认说明clickhouse最著名的存储引擎Mergetree的文件组织,他是将表,分区存储到对应的某个文件夹下,列使用列名作为文件名,存储在 bin格式的文件中。 数据由三种文件组成,数据文件(bin),索引文件(idx)和标记文件(mrk3),这三种文件丢失任何一个都会造成数据损坏,其他文件则不会。索引文件存储了每个数据块的最小值和对应的数据块名称,标记文件存储块的物理偏移量,两个文件一起才能完成索引功能,通过索引文件找到数据属于哪个块,通过标记文件找到块文件,而数据文件存储了数据,所以这三个文件损坏一个就会导致数据丢失。 其他文件:Columns.txt保存元数据,count.txt存储该分区下的行数。 其中需要注意的是,分区是一种管理数据的手段,不能加速数据查询。文件组织示例如下:
clickhouse的优缺点:
通过比较可以发现,clickhouse在数据存储结构上和mysql有极大的不同,这也是导致性能差异的原因。一个查询速度快慢主要是由io决定的,如果数据量够小,所有数据都能存入内存中的话,那其实读取速度不会相差太多,而clickhouse正式通过他的存储结构设计,尽量减少了磁盘I/O对他的影响,提高了他的读取性能。他速度快的主要原因有:
- 他是列存数据库,读取数据时只要查询指定列的数据,而mysql每次都需要把整行的数据从磁盘中读出来,因此clickhouse通过减少一次读取的数据量提高了速度
- clickhouse使用了预排序技术,他在插入数据时通过算法进行预排序,使得存入磁盘的数据是有序的,可以将大量的随机读转为顺序读,提高了范围查找的速度。
- clickhouse在存储数据时使用了压缩技术,减少了读取数据时的数据大小,进一步提高了查询速度
同时通过了解ck的架构,也能知道其优缺点:
- ck通过列存+压缩的存储引擎设计,降低了I/O的时间提升了性能,但是因为其列存的特性,如果一个查询需要用到他几乎所有的字段,那么他就无法提供太大的性能优势,因此使用ck需要设计宽表。
- ck的数据存储结构是通过索引进行排序后存储的,因此不需要B树结构的索引,提升了他查询的速度,但是如果需要从多个字段进行查询,ck就不行了,而B树索引可以通过建立多个索引来加速查询,因此ck适合一个表只有通过一个或者几个固定字段来查询的方式。不过这一点可以通过建立物化视图或者多个表来解决,它相当于是建立了一个和原表数据相同,但是主键不同的表,从而针对特定的查询实现查询加速的效果。
引出的一些思考
通过了解clickhouse的结构设计,我们可以得出一些方法论:
- 结构决定功能,因此不同结构的数据库有各自的优势和劣势,进行数据库选型时,要根据结构来选择最合适的。
- 要用结构解决功能问题,而不是用功能解决功能问题,遇到在某种特定结构下运行慢的情况时,要有限选择合适的架构,而不是通过特定的方式在不合适的架构上做兼容。
- 不要试图突破底层结构的限制,核心也是选择合适的架构。
架构也是取舍,你想获得一些特性,就得牺牲另一些特性。我们在设计架构时必须清醒地认识到这点,不要试图去设计各方面都优秀的架构,也不要试图去突破底层结构的限制。
通过架构决定功能这个思想,他可以指导我们,在架构设计时要根据业务需求设计出对应的技术架构,当了解一个新架构或者软件时,可以先分析其结构,同时通过其结构了解其未来可能会到达的瓶颈。设计架构时不要过度优化,要根据实际情况进行演进。
备注:引用部分节选自 ClickHouse性能之巅:从架构设计解读性能之谜,并且此文部分观点也都来自这本书,推荐一读