背景
当前项目采用 Docker 多阶段构建的自动化流水线部署方式。每次前端上线时,都会重新从包含 puppeteer 的镜像中进行构建。由于 puppeteer 镜像体积较大、依赖复杂,导致整体构建时间较长。
然而实际情况是:puppeteer 服务本身逻辑稳定、改动极少,频繁重复构建并无必要。每次构建时都包含 puppeteer,导致资源浪费并拖慢主业务的发布流程。
因此,决定将 puppeteer 服务拆分成独立模块/镜像,与主业务解耦,以此实现如下目标:
- 缩短主业务构建时间
- 降低构建复杂度与失败率
- 提升服务模块复用与独立部署能力
什么是puppeteer
Puppeteer是由Google开发和维护的一款强大的Node.js库,它为开发人员提供了高级API,以编程方式操控Chromium浏览器。与传统的浏览器自动化工具相比,Puppeteer的独特之处在于它可以运行无头浏览器,即在没有UI界面的情况下运行浏览器实例。这意味着你可以在后台运行浏览器,执行各种任务,而无需手动操作浏览器界面。
Puppeteer的背后是Chromium浏览器,这是一款开源的浏览器项目,也是Google Chrome浏览器的基础。因此,Puppeteer具备了与Chrome相同的功能和兼容性。
Puppeteer的设计目标是为开发者提供一种简单而直观的方式来自动化浏览器操作。它提供了丰富的API,可以轻松地进行页面导航、元素查找、表单填写、数据提取等操作。你可以编写脚本来模拟用户在浏览器中的操作,从而实现自动化测试、网页截图、数据爬取等任务。
此外,Puppeteer还支持无头模式,这意味着浏览器在后台运行,不会显示界面。这使得Puppeteer非常适合在服务器环境中运行,例如自动化测试的CI/CD流水线、数据挖掘和网络爬虫等场景。
puppeteer 相关
puppeteer分为puppeteer 和puppeteer-core 两种,区别在于我们安装如果是puppeteer则会自动下载一个chromium,而我们安装puppeteer-core则不会下载chromium.我们使用puppeteer-core则要指定chromium路径,但是每个不同的版本,就对应不同的chromium,那我们如何下载对应版本puppeteer所对应的chromium呢?
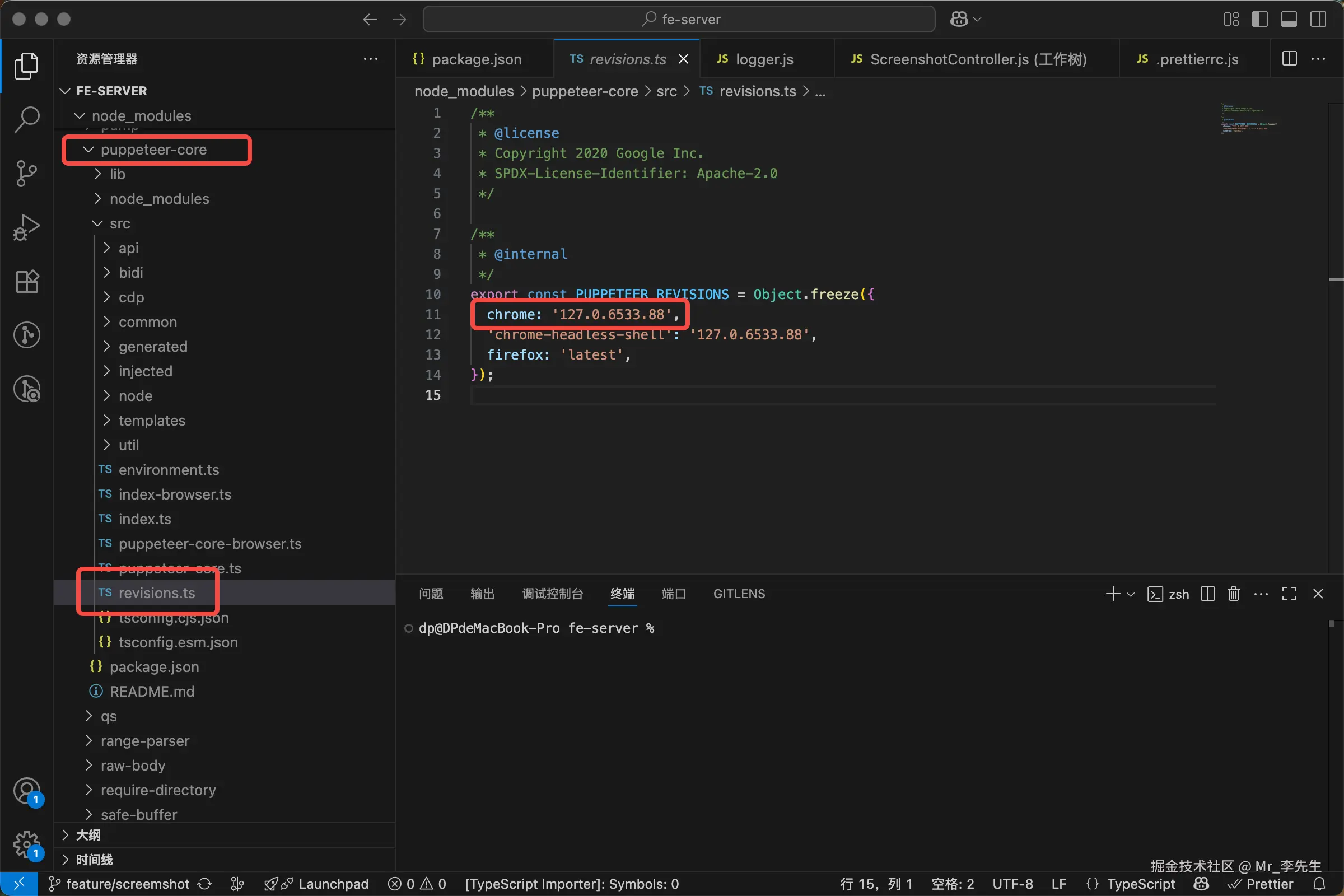 可以看到下载的puppeteer-core中
可以看到下载的puppeteer-core中 revisions.ts中说明了chrome所对应的测试版本信息 Chrome for Testing - 官方博客说明(中文版)
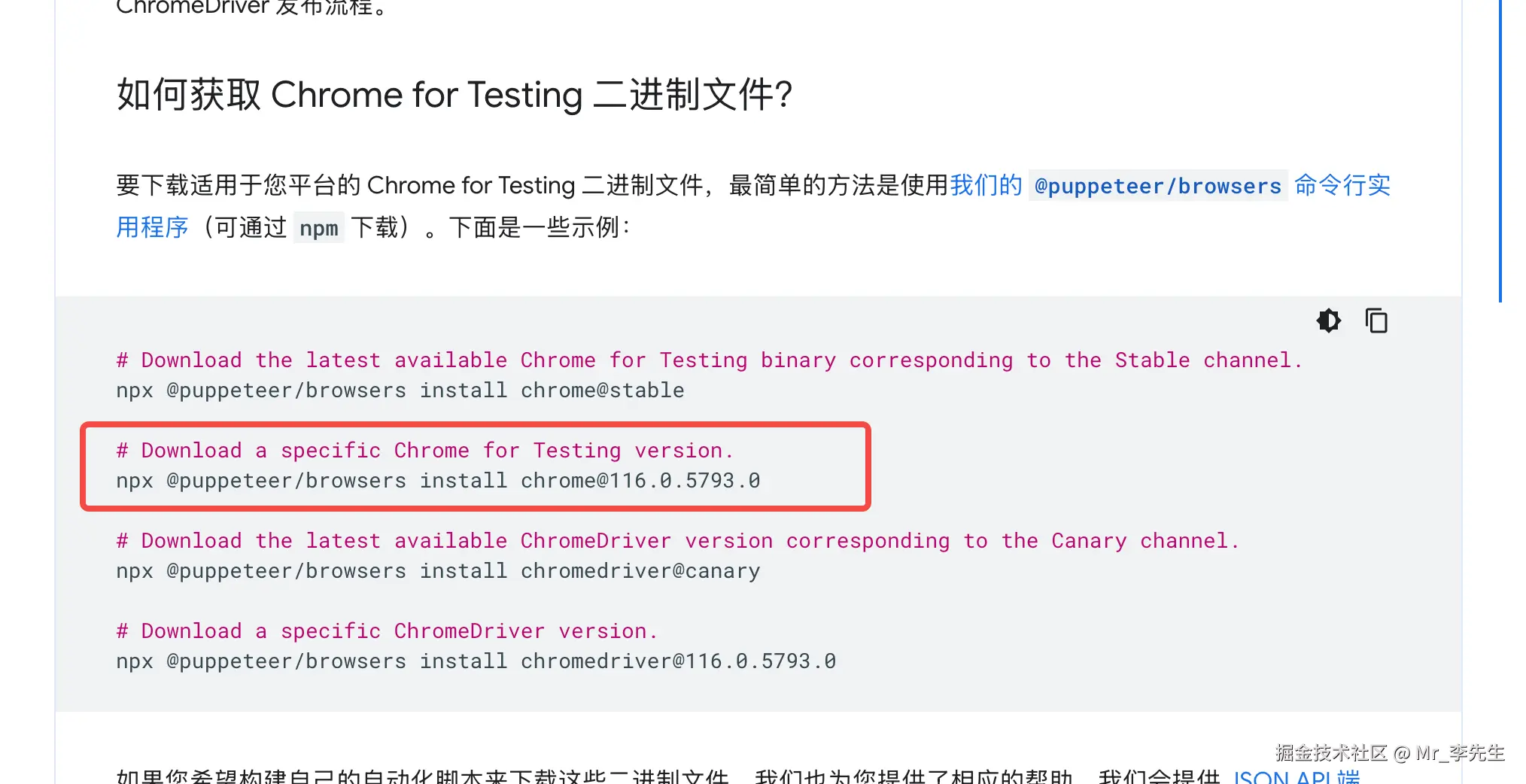 在谷歌的开发帮助文档中 使用puppeteer/browsers来下载对应的chromium 执行命令
在谷歌的开发帮助文档中 使用puppeteer/browsers来下载对应的chromium 执行命令
js
npx @puppeteer/browsers install chrome@127.0.6533.88这样就会在当前目录下载一个用于测试版本的chrome
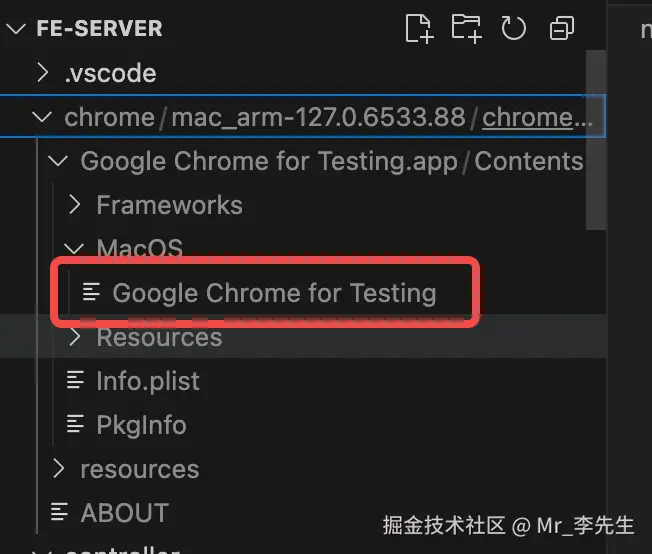 这样就下载好对应版本的chromium
这样就下载好对应版本的chromium
使用puppeteer 实现截图服务
由于使用的puppeteer-core 我们需要制定chromium的路径,我们是将服务迁移出来,因此提前封装了puppeteer的镜像,镜像内包含了chromium的位置,直接写死即可
js
const puppeteer = require('puppeteer-core');
const { logger } = require('../utils/logger');
const getScreenshot = async (req, res) => {
try {
const executablePath = '/root/.cache/puppeteer/chrome/linux-126.0.6478.126/chrome-linux64/chrome';
const targetUrl = decodeURIComponent(req.query.url) || 'https://www.bohrium.com/intro';
let width = parseInt(req.query.w) || 1280; // 默认宽度 1280
let height = parseInt(req.query.h) || 800; // 默认高度 800
const selector = req.query.slct || '';
const browser = await puppeteer.launch({
args: ['--no-sandbox', '--disable-setuid-sandbox'],
// 这里需要指定chromium的路径
executablePath,
});
const page = await browser.newPage();
// 访问目标网页
await page.goto(targetUrl, { waitUntil: 'networkidle2' });
if (selector) {
const el = await page.$('#' + selector);
const rect = await el.boundingBox();
width = parseInt(rect.width);
height = parseInt(rect.height);
}
// 设置视口大小
await page.setViewport({ width, height, deviceScaleFactor: 2 });
// 截图
const screenshot = await page.screenshot({ type: 'png' });
await browser.close();
// 设置响应头并发送图片
res.set('Content-Type', 'image/png');
res.send(screenshot);
} catch (error) {
console.error('Error taking screenshot:', error);
logger.error(`Error taking screenshot: ${JSON.stringify(error)}`);
res.status(500).send(`Error taking screenshot: ${JSON.stringify(error)}`);
}
};
module.exports = {
getScreenshot,
};最后
感谢mentor给个机会,让我参与到构建优化当中,当然自己很菜只负责了迁移这个服务,,并且有了一次独立构建一个项目,并且上线的经验