目录
[2.1 进入官网](#2.1 进入官网)
[2.2 查找QA数据集](#2.2 查找QA数据集)
[2.3 预览数据集](#2.3 预览数据集)
[2.4 创建虚拟环境](#2.4 创建虚拟环境)
[2.5 安装依赖](#2.5 安装依赖)
[2.6 下载数据集](#2.6 下载数据集)
[3.1 脚本提示词](#3.1 脚本提示词)
[3.2 执行转换脚本](#3.2 执行转换脚本)
[3.3 原数据与转换后数据对比](#3.3 原数据与转换后数据对比)

前言
如何转换成直接想要的数据格式?
目前并没有比较好用的制作数据集的工具,但是有一种更加灵活高效的方法就是:通过大模型生成指定的格式转换器脚本。这种方式能够帮助我们能够更快,更灵活,更高效的帮助我们实现数据格式定制。本文主要介绍的就是关于高效制作数据集的方法
一、明确数据格式
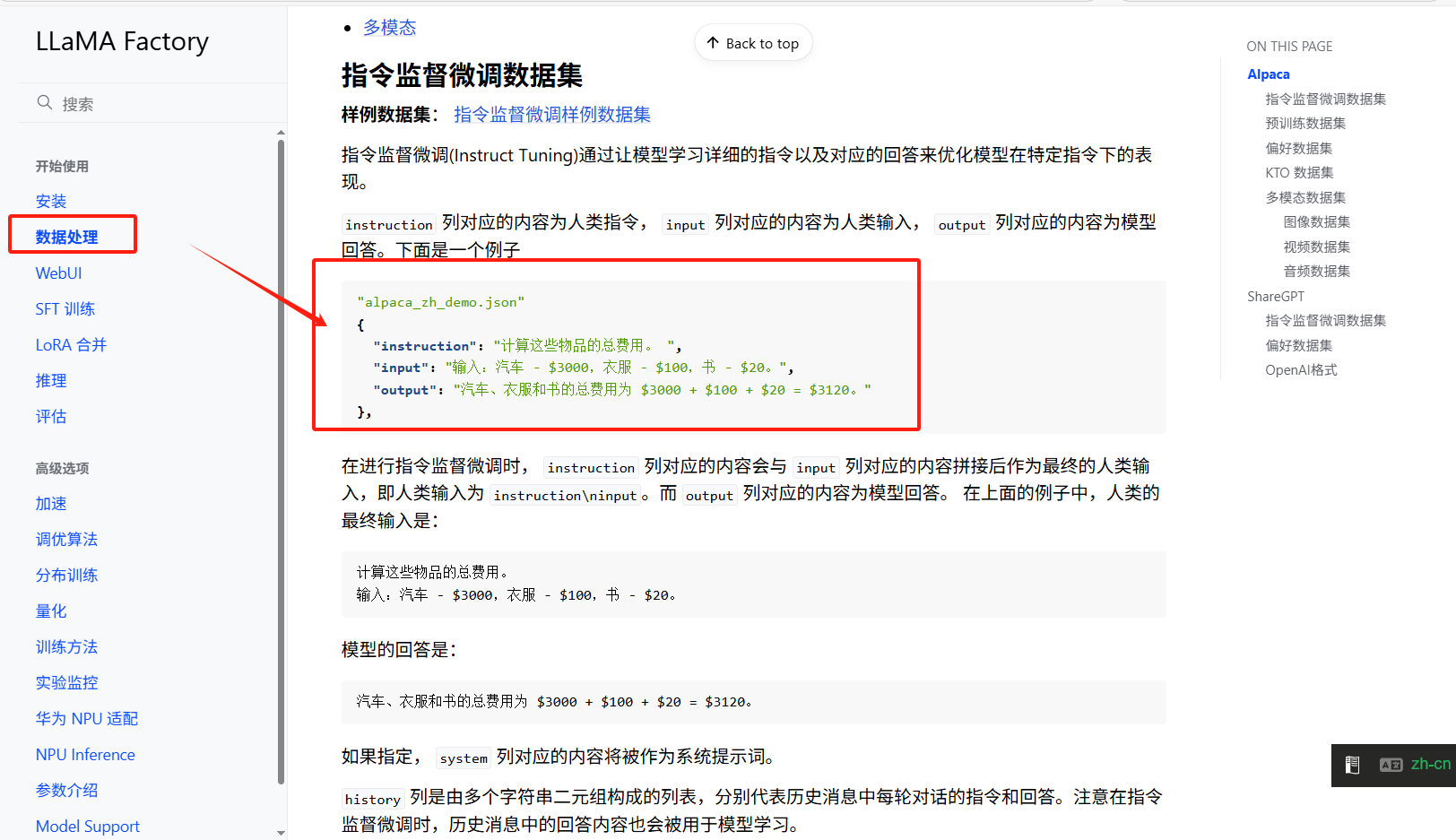
这里就以LLaMAFactory官方规定的数据格式(数据处理 - LLaMA Factory)为目标格式。
LLaMAFactory中就对训练的数据格式有明确的要求,但是我们拿到的数据不可能和它对的上,所以我们就可以通过脚本代码"批量转换",将数据格式批量做更改,省时省力。
以下是LLaMAFactory的两种常见格式
格式1:单轮对话格式
这是一种典型的数据格式
instruction(必选):表示的是问题;
input(可选):表述输入信息,可以为空;
output(必选):表示输出内容;
python{ "instruction": "计算这些物品的总费用。 ", "input": "输入:汽车 - $3000,衣服 - $100,书 - $20。", "output": "汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。" },
格式2:多轮对话格式
python[ { "instruction": "今天的天气怎么样?", "input": "", "output": "今天的天气不错,是晴天。", "history": [ [ "今天会下雨吗?", "今天不会下雨,是个好天气。" ], [ "今天适合出去玩吗?", "非常适合,空气质量很好。" ] ] } ]以上两种是比较常见数据形式,可根据要求制作符合要求的数据。
详细格式要求:常考官方文档
二、准备数据集
数据集这里演示的是从魔搭社区下载的数据集,也可以自己收集或制作一些数据,根据情况进行转换。
2.1 进入官网
官网地址:ModelScope 魔搭社区
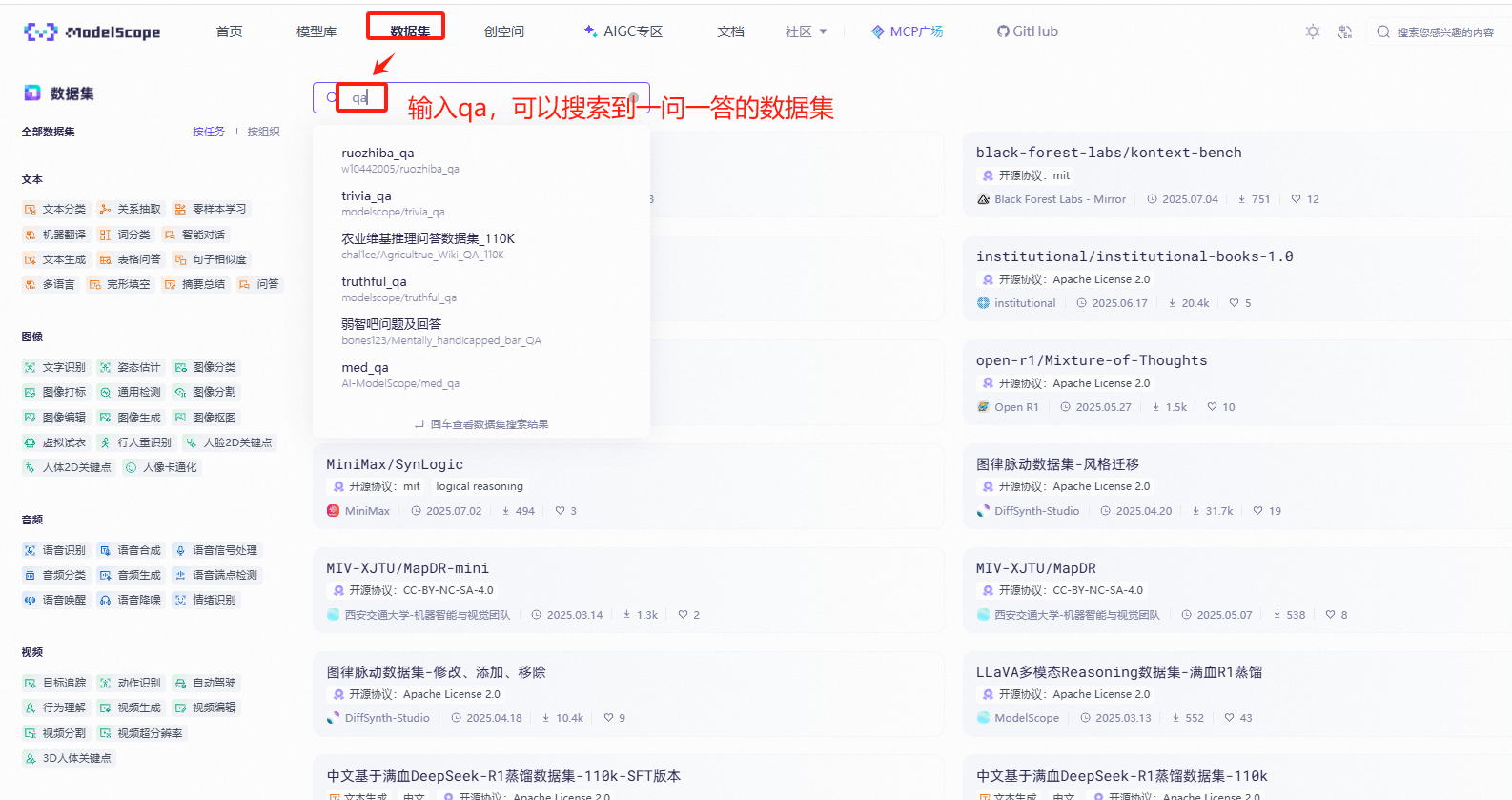
2.2 查找QA数据集
可自行选择一个QA数据集
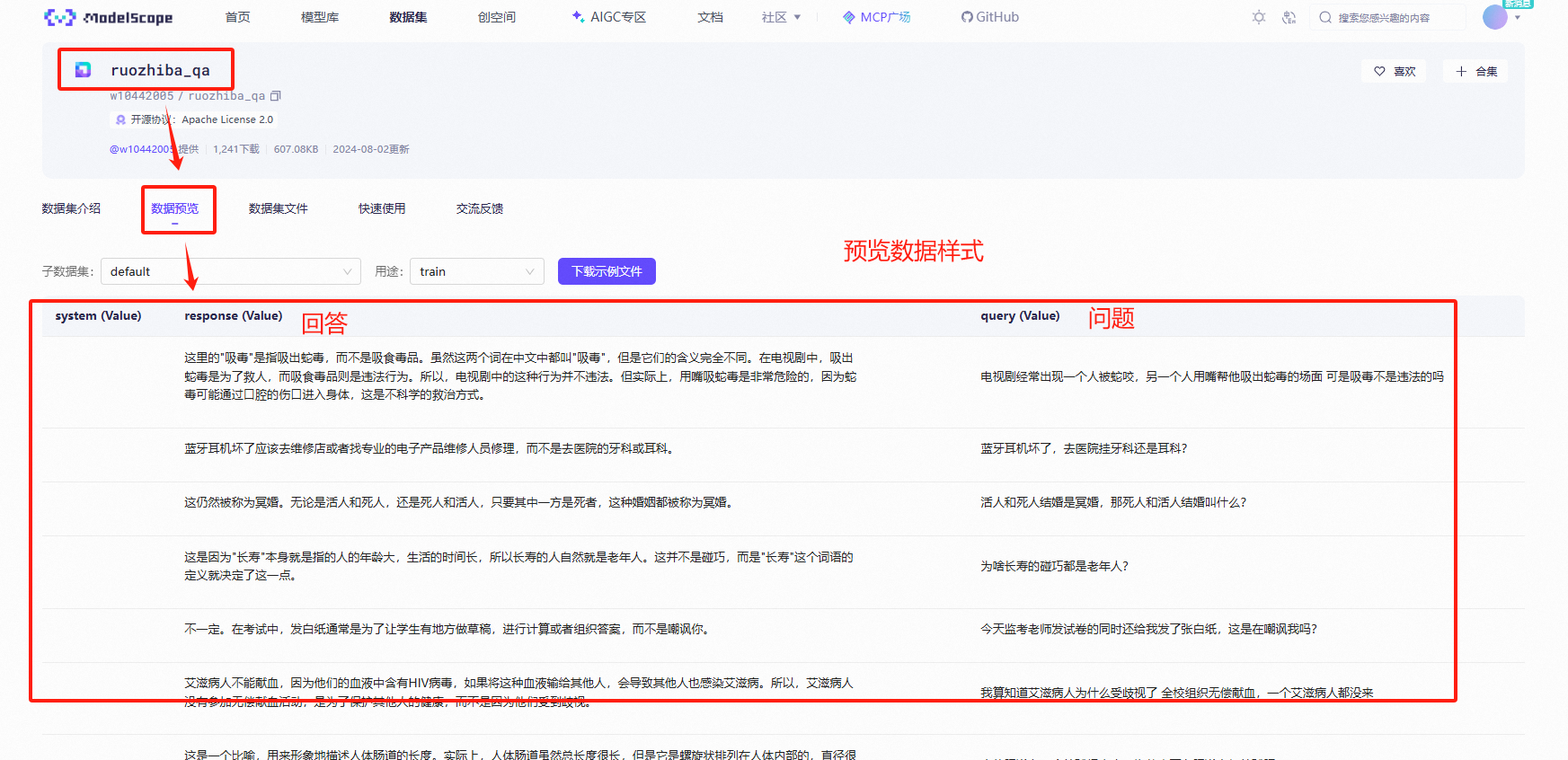
2.3 预览数据集
可以发现这个数据集和LLaMAFactory的要求格式会有些差异的,不过没关系,先下载;
这里选择【w10442005/ruozhiba_qa】这个数据集
2.4 创建虚拟环境
python
#创建虚拟环境
conda create -n download_data python=3.11
#激活虚拟环境
conda activate download_data2.5 安装依赖
python
#安装魔搭社区依赖
pip install modelscope==1.28.1
#addict 是一个用于简化字典访问和操作的 Python 库。
pip install addict
# 安装 packaging 库,用于处理版本号解析和比较,常用于依赖管理
pip install packaging
# 安装 datasets 库,用于加载和处理机器学习数据集
pip install datasets==3.6.0datasets和modelscope的版本可能存在不兼容问题,所以我这里加了指定版本。
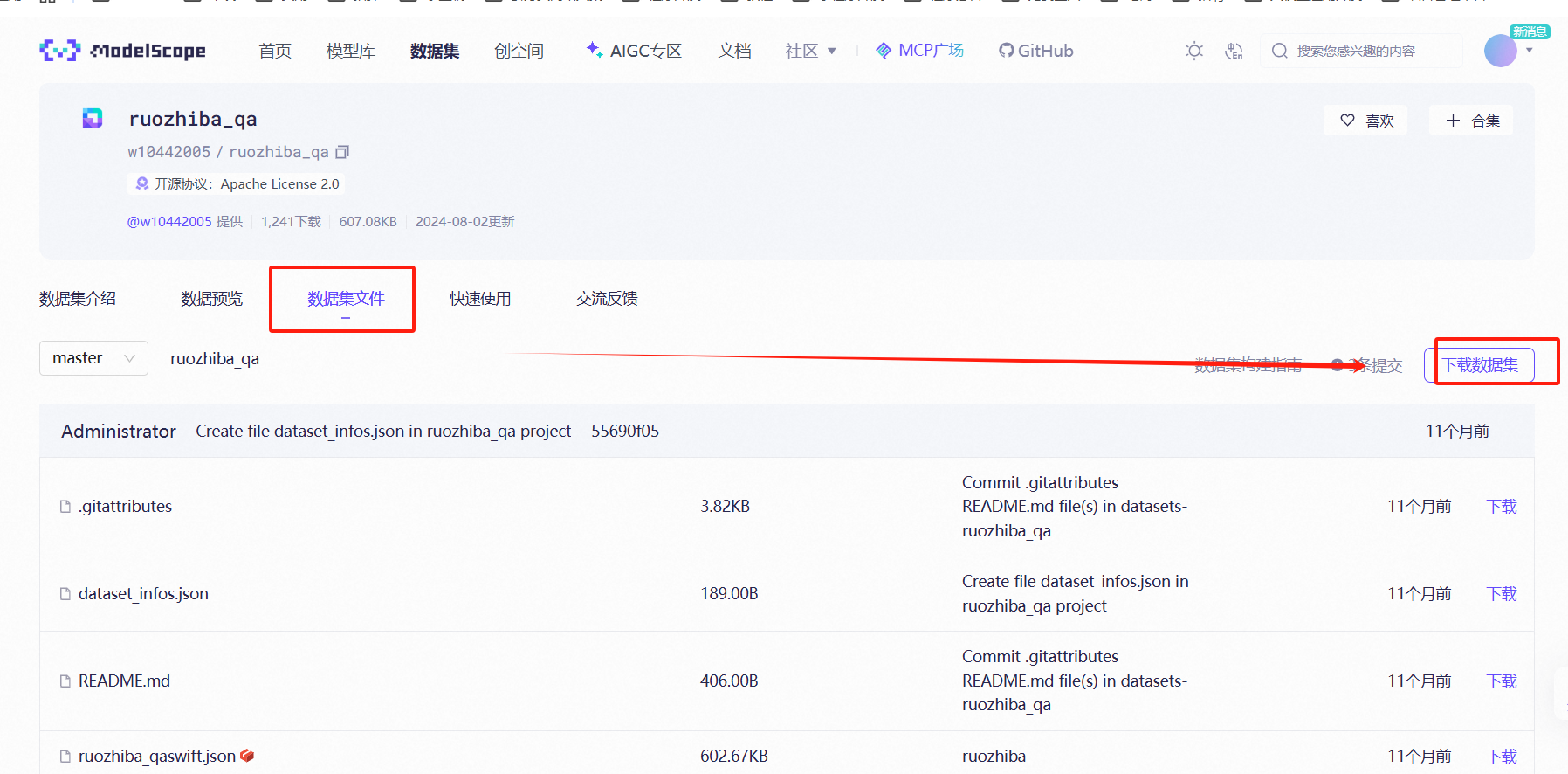
2.6 下载数据集
1、选择SDK下载方式
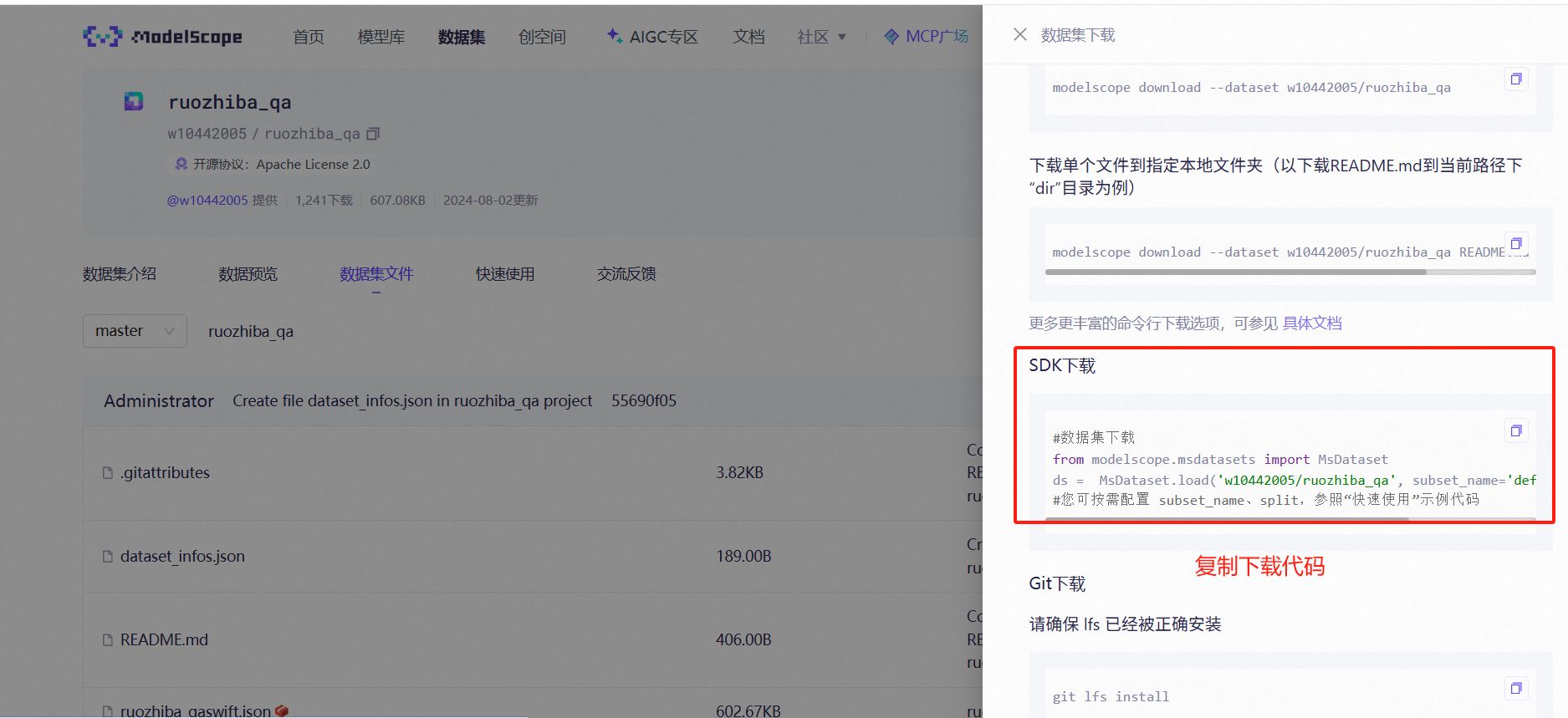
下载代码如下
python
from modelscope.msdatasets import MsDataset
ds = MsDataset.load(
'w10442005/ruozhiba_qa',
subset_name='default',
split='train',
cache_dir='/mnt/workspace/model/model_data')
print("下载成功")▲cache_dir='/mnt/workspace/model/model_data':在原来代码的基础上加了一个存储路径,这个存放路径自行选择;
2、执行下载代码
python
python /mnt/workspace/python_learning/download_data.py/mnt/workspace/python_learning/download_data.py:表示执行代码路径
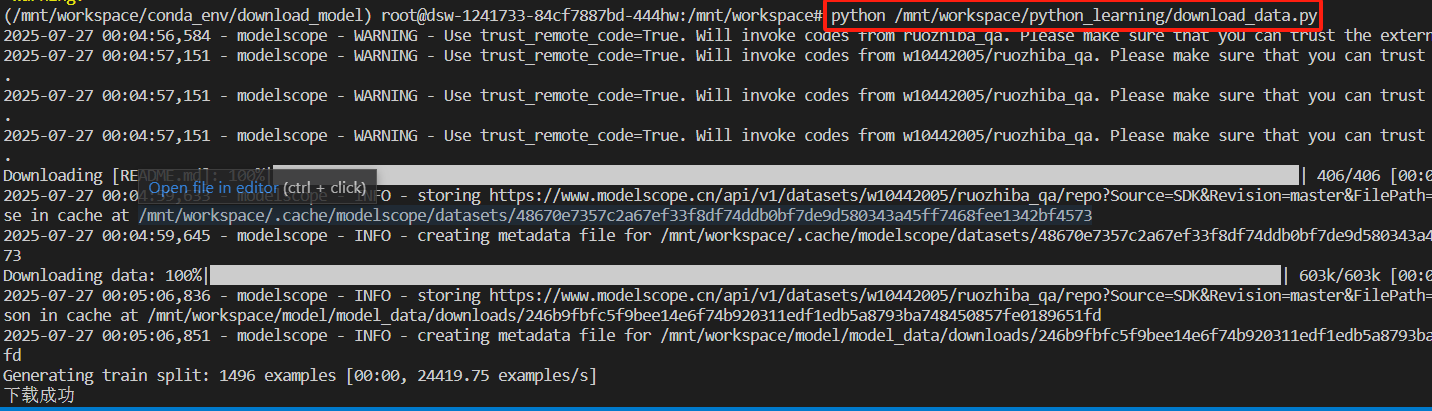
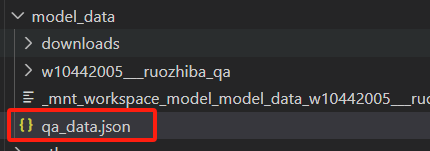
3、查看下载数据

因为这个数据集文件不是json文件,所以要新建一个json文件,把里面的内容复制过去,方便后序转换
三、转换数据格式
通过前面两步,已经明确了数据集的目标格式,并且也拿到了QA数据集,那接下来就是将下载的数据集转换成符合LLaMAFactory的数据集格式要求的格式。
**转换方式就是:**通过AI帮我们生成批量转换脚本。
3.1 脚本提示词
可以参考以下提示词,告诉AI你的需求,让AI给你生成合适的转换脚本。
【提示词要点说明】
▲数据文件输入输出格式要求为json格式;
▲转换与被转换的json数据格式样例;
▲明确转换与被转换的json数据相对应的标签;
python
帮我用Python写一个json数据格式转换脚本,输入输出为json格式文件
当前json数据格式示例为:
[
{
"system": "00000",
"query": "只剩一个心脏了还能活吗?",
"response": "能,人本来就只有一个心脏。"
},
{
"query": "爸爸再婚,我是不是就有了个新娘?",
"response": "不是的,你有了一个继母。\"新娘\"是指新婚的女方,而你爸爸再婚,他的新婚妻子对你来说是继母。"
},
{
"query": "樟脑丸是我吃过最难吃的硬糖有奇怪的味道怎么还有人买",
"response": "樟脑丸并不是硬糖,而是一种常见的驱虫药,不能食用。虽然它的味道可能不太好,但是由于其有效的驱虫效果,所以仍然有很多人会购买。"
},
...
]
转成目标格式示例为:
[
{
"instruction": "计算这些物品的总费用。 ",
"input": "",
"output": "汽车、衣服和书的总费用为 $3000 + $100 + $20 = $3120。"
},
]
query对应的是instruction,respose对应的是output3.2 执行转换脚本
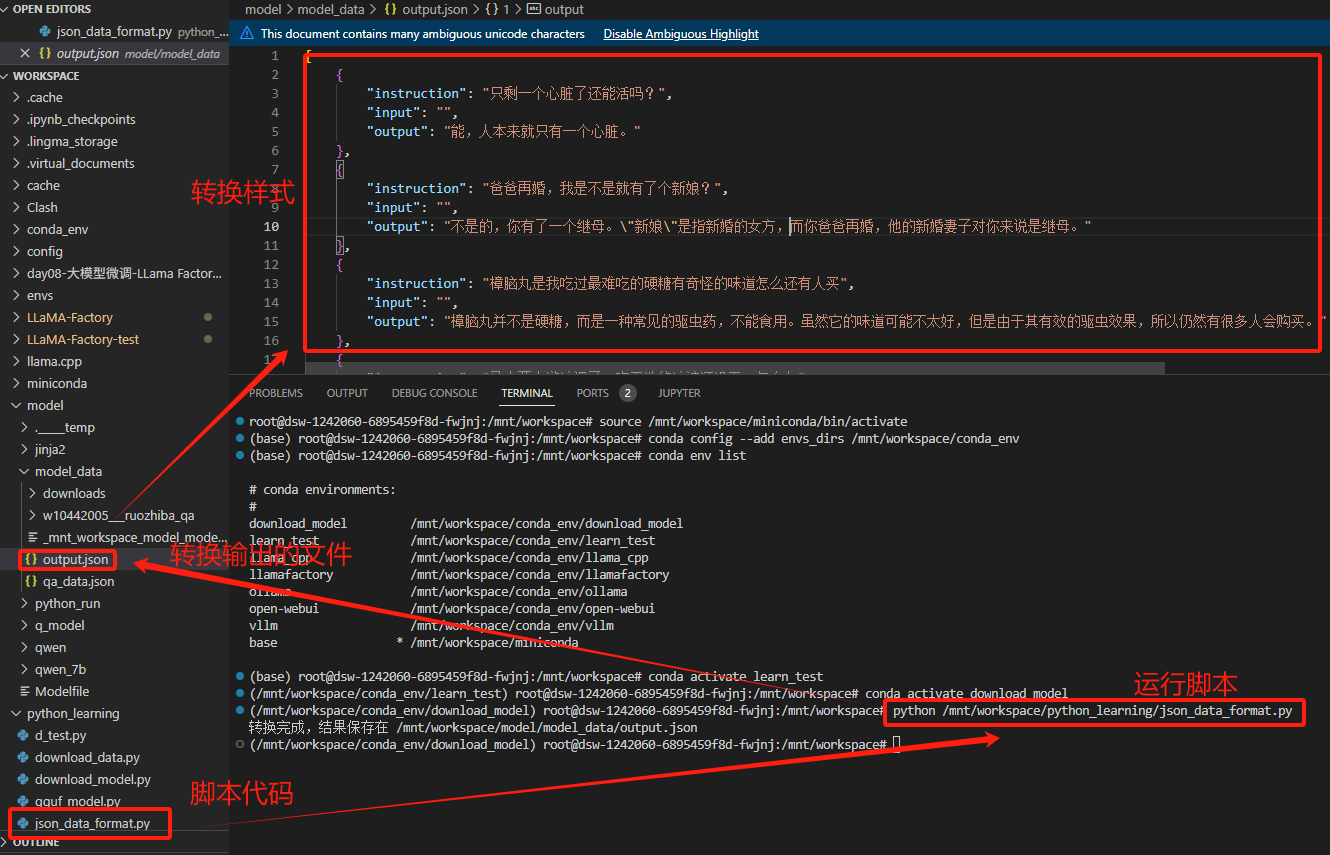
以下是我用ChatGPT生成的转换代码,一键即用;
【替换片段】
pythoninput_file = "./qa_data.json" #替换为你的输入文件路径 output_file = "./output.json" #替换为你的输出保存的文件路径▲./qa_data.json:替换为需要转换的json数据路径;
▲./output.json:替换为转换后存放的json数据路径;
python
import json
# 输入文件路径和输出文件路径
input_file = "./qa_data.json" #替换为你的输入文件路径
output_file = "./output.json" #替换为你的输出保存的文件路径
# 读取输入的 JSON 数据
with open(input_file, 'r', encoding='utf-8') as infile:
data = json.load(infile)
# 转换数据格式
converted_data = []
for item in data:
converted_item = {
"instruction": item["query"],
"input": "",
"output": item["response"]
}
converted_data.append(converted_item)
# 将转换后的数据写入输出的 JSON 文件
with open(output_file, 'w', encoding='utf-8') as outfile:
json.dump(converted_data, outfile, ensure_ascii=False, indent=4)
print("转换完成,结果保存在", output_file)以下是从执行脚本运行后,到转换的json数据格式展示
3.3 原数据与转换后数据对比
原数据格式
python
[
{
"system": "00000",
"query": "只剩一个心脏了还能活吗?",
"response": "能,人本来就只有一个心脏。"
},
{
"query": "爸爸再婚,我是不是就有了个新娘?",
"response": "不是的,你有了一个继母。\"新娘\"是指新婚的女方,而你爸爸再婚,他的新婚妻子对你来说是继母。"
},
{
"query": "樟脑丸是我吃过最难吃的硬糖有奇怪的味道怎么还有人买",
"response": "樟脑丸并不是硬糖,而是一种常见的驱虫药,不能食用。虽然它的味道可能不太好,但是由于其有效的驱虫效果,所以仍然有很多人会购买。"
},
...
]转换后的数据格式
python
[
{
"instruction": "只剩一个心脏了还能活吗?",
"input": "",
"output": "能,人本来就只有一个心脏。"
},
{
"instruction": "爸爸再婚,我是不是就有了个新娘?",
"input": "",
"output": "不是的,你有了一个继母。\"新娘\"是指新婚的女方,而你爸爸再婚,他的新婚妻子对你来说是继母。"
},
{
"instruction": "樟脑丸是我吃过最难吃的硬糖有奇怪的味道怎么还有人买",
"input": "",
"output": "樟脑丸并不是硬糖,而是一种常见的驱虫药,不能食用。虽然它的味道可能不太好,但是由于其有效的驱虫效果,所以仍然有很多人会购买。"
},
...
]四、总结
灵活利用现有工具去解决繁琐重复的任务,是我们必须具备的一项基本技能。虽然目前并没有比较好用的数据集制作工具,但是我们依旧可以通过AI工具去高效制作符合目标需求的格式数据集,最后总结以下流程:
1、明确数据格式 :**明确微调训练的格式需求。**只有明确格式需求,才能有效的进行微调训练,这也是非常重要的开头;
2、准备数据 :**自己制作或官方平台下载。**个人学习场景,可以自己制作收集自己要的数据,也可以通过魔搭社区或Huggingface平台下载;
3、数据格式转换 :**利用AI写转换脚本。**实际场景中,我们拿到的数据格式可能是各式各样的,不可能会和我们目标的需求格式完全相同,利用AI生成批量转换脚本能够灵活高效的提升转化数据的效率;
当前,学会如何利用现有工具,高效去解决问题是非常重要的一项技能。